史上最大子宫内膜异位症单细胞图谱

都2023了,单细胞还在卷样品数量,这不,史上最大子宫内膜异位症单细胞图谱来了。2023年1月发表在Nature Genetics的:《Single-cell transcriptomic analysis of endometriosis》,接近40万个单细胞哦,样品可以分成如下所示的5个分组:
- 子宫内膜瘤(n = 8) ,
- 子宫内膜异位症(n = 28) ,
- 在位子宫内膜(n = 10) ,
- 未受影响的卵巢(n = 4)
- 无子宫内膜异位症的腹膜(n = 4)
纳入的是21个病人,也就是说同一个病人会多个部位取样,如下所示:

同一个病人会多个部位取样
因为是单细胞图谱,所以第一层次的降维聚类分群主要是分组展现一下即可:
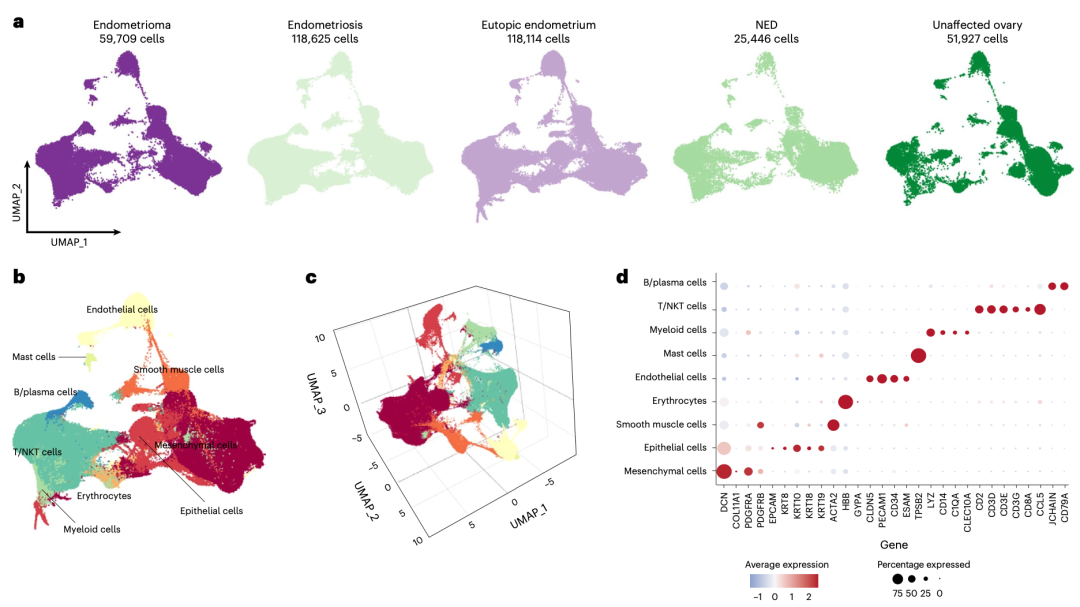
第一层次的降维聚类分群
主要是分成了:
- Mesenchymal cells, identified by expression of FAP, COL1A1 and PDGFRA/B, were the most abundant cell type present (n = 149,051 cells, 39.9% of cells
- NK/T cells were the second most prevalent cell type present, comprising 101,217 cells (27.1% of cells).
- Keratin (KRT7, KRT8, KRT10, KRT18, KRT19) or EPCAM-positive epithelial cells (n = 38,456 cells) represented 10.3% of the total population
- myeloid cells (n = 27,436 cells, 7.3% of the total population),
- smooth muscle cells (n = 18,314 cells, 4.9% of cells),
- endothelial cells (n = 23,226 cells, 6.2% of cells),
- B lymphocytes and plasma cells (n = 8,278 cells, 2.2% of cells),
- mast cells (n = 1,687 cells, 0.4% of cells).
可以看到跟肿瘤相关的单细胞转录组的表达量矩阵后的第一层次降维聚类分群没有区别,也是:
- immune (CD45+,PTPRC),
- epithelial/cancer (EpCAM+,EPCAM),
- stromal (CD10+,MME,fibo or CD31+,PECAM1,endo)
参考我前面介绍过 CNS图表复现08—肿瘤单细胞数据第一次分群通用规则,这3大单细胞亚群构成了肿瘤免疫微环境的复杂。绝大部分文章都是抓住免疫细胞亚群进行细分,包括淋巴系(T,B,NK细胞)和髓系(单核,树突,巨噬,粒细胞)的两大类作为第二次细分亚群。但是也有不少文章是抓住stromal 里面的fibo 和endo进行细分,并且编造生物学故事的。
单细胞亚群细分
前面的第一层次降维聚类分群只能说作为文章的figure1,分析的颗粒度肯定是不够,所以通常来说会挑选部分亚群进行细分,或者全部的亚群一个个轮流细分并且讨论,本文花费大量笔墨描述的是 82,735 mesenchymal cells identified 13 distinct clusters ,可以分成4大类:
- MME-positive endometrial-type stroma (EnS; 2 clusters; 4,290 cells),
- fibroblasts (9 clusters; 66,711 cells),
- smooth muscle cells (1 cluster; 1,735 cells)
- bland cells expressing the growth arrest specific 5 long noncoding RNA (GAS5+ cells; 1 cluster; 9,999 cells)
就是我们一直说的内皮细胞,成纤维细胞,平滑肌细胞,但是这个bland cells 确实让我有点意外,因为我之前提到的一直在pericyte(周细胞)。
表达量矩阵是可以公开获取的:https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE213216
可以很轻松下载到每个样品的表达量矩阵:
GSM6574509_sample1.tar.gz 51.6 Mb
GSM6574510_sample5.tar.gz 215.5 Mb
GSM6574511_sample7.tar.gz 601.9 Mb
GSM6574512_sample8.tar.gz 575.1 Mb
GSM6574513_sample9.tar.gz 291.5 Mb
GSM6574514_sample10.tar.gz 128.9 Mb
下载这些文件后走单细胞转录组流程即可, 可以做harmony或者CCA的整合,然后降维聚类分群,如果你对单细胞数据分析还没有基础认知,可以看基础10讲:
- 01. 上游分析流程
- 02.课题多少个样品,测序数据量如何
- 03. 过滤不合格细胞和基因(数据质控很重要)
- 04. 过滤线粒体核糖体基因
- 05. 去除细胞效应和基因效应
- 06.单细胞转录组数据的降维聚类分群
- 07.单细胞转录组数据处理之细胞亚群注释
- 08.把拿到的亚群进行更细致的分群
- 09.单细胞转录组数据处理之细胞亚群比例比较
值得一提的是因为已经是2023了,单纯的单细胞转录组其实有点单薄,所以本文也有少量的空间单细胞数据:
GSM6690475_BEME_346_barcodes.tsv.gz 8.0 Kb
GSM6690475_BEME_346_features.tsv.gz 325.6 Kb
GSM6690475_BEME_346_matrix.mtx.gz 11.8 Mb
GSM6690475_BEME_346_scalefactors_json.json.gz 175 b
GSM6690475_BEME_346_tissue_hires_image.png.gz 4.7 Mb
GSM6690475_BEME_346_tissue_positions_list.csv.gz 64.5 Kb
GSM6690475_D_V11F09-023_BEME346.tif.gz 420.5 Mb
GSM6690476_BEME-355G_scalefactors_json.json.gz 175 b
GSM6690476_BEME-355G_tissue_hires_image.png.gz 5.2 Mb
GSM6690476_BEME-355G_tissue_positions_list.csv.gz 63.7 Kb
GSM6690476_BEME_355G_barcodes.tsv.gz 11.2 Kb
GSM6690476_BEME_355G_features.tsv.gz 325.6 Kb
GSM6690476_BEME_355G_matrix.mtx.gz 13.0 Mb
GSM6690476_C_V11F09-023_BEME355G.tif.gz 467.6 Mb
学徒作业
下载前面的所有的样品的单细胞转录组表达量矩阵,每个样品独立的降维聚类分群和命名,然后技术细胞比例,看看是不是每个样品的细胞比例都是 Mesenchymal > NK/T cells > epithelial cells > myeloid
可以使用我们在《生信技能树》公众号的一个教程:这也能画?,所提到了一个很无聊的R包,名字是:scRNAstat ,它可以4行代码进行单细胞转录组的降维聚类分群,其实完全没有技术含量, 就是把 Seurat 流程的一些步骤包装成为了4个函数:
- basic_qc (查看数据质量)
- basic_filter (进行一定程度的过滤)
- basic_workflow (降维聚类分群)
- basic_markers(检查各个亚群的标记基因)
前面的下载全部的 .tar.gz 文件,然后读取成为sceList 后,需要不到20行代码,就可以批量完成全部的单细胞样品的各自独立的降维聚类分群的检验!
lapply(names(sceList) , function(x){
# x=names(sceList)[1]
print(x)
sce=sceList[[x]]
sce
dir.create( x )
sce = basic_qc(sce=sce,org='human',
dir = x)
sce
sce = basic_filter(sce)
sce = basic_workflow(sce,dir = x)
markers_figures <- basic_markers(sce,
org='human',
group='seurat_clusters',
dir = x)
p_umap = DimPlot(sce,reduction = 'umap',
group.by = 'seurat_clusters',
label.box = T, label = T,repel = T)
p=p_umap+markers_figures[[1]]
print(p)
ggsave(paste0('umap_markers_for_',x,'.pdf'),width = 12,height = 9)
#save(p,file = paste0('umap_markers_for_',x,'.Rdata'))
})
对每个样品我都快速完成了各自独立的降维聚类分群的检验,而且保存了图片以及图片背后的数据哦!如果你的内存比较小,也可以把前面的读取步骤跟下面的降维聚类分群步骤合并,这样无需存储每次单细胞数据对象啦!而且只需要背诵如下所示各个细胞亚群高表达量基因的列表:
# T Cells (CD3D, CD3E, CD8A),
# B cells (CD19, CD79A, MS4A1 [CD20]),
# Plasma cells (IGHG1, MZB1, SDC1, CD79A),
# Monocytes and macrophages (CD68, CD163, CD14),
# NK Cells (FGFBP2, FCG3RA, CX3CR1),
# Photoreceptor cells (RCVRN),
# Fibroblasts (FGF7, MME),
# Endothelial cells (PECAM1, VWF).
# epi or tumor (EPCAM, KRT19, PROM1, ALDH1A1, CD24).
# immune (CD45+,PTPRC), epithelial/cancer (EpCAM+,EPCAM),
# stromal (CD10+,MME,fibo or CD31+,PECAM1,endo)
就可以很容易给每个单细胞转录组样品的各个细胞亚群进行生物学命名!
赶快去看看是不是每个样品都有 比例过滤吧:Mesenchymal > NK/T cells > epithelial cells > myeloid