NumPy 初学者指南中文第三版:1~5

原文:NumPy: Beginner’s Guide - Third Edition 协议:CC BY-NC-SA 4.0 译者:飞龙
一、NumPy 快速入门
让我们开始吧。 我们将在不同的操作系统上安装 NumPy 和相关软件,并看一些使用 NumPy 的简单代码。 本章简要介绍了 IPython 交互式 shell。 SciPy 与 NumPy 密切相关,因此您将看到 SciPy 名称出现在此处和那里。 在本章的最后,您将找到有关如何在线获取更多信息的指南,如果您陷入困境或不确定解决问题的最佳方法。
在本章中,您将涵盖以下主题:
- 在 Windows,Linux 和 Macintosh 上安装 Python,SciPy,matplotlib,IPython 和 NumPy
- 回顾一下 Python
- 编写简单的 NumPy 代码
- 了解 IPython
- 浏览在线文档和资源
Python
NumPy 基于 Python,因此您需要安装 Python。 在某些操作系统上,已经安装了 Python 。 但是,您需要检查 Python 版本是否与要安装的 NumPy 版本对应的 。 Python 有许多实现,包括商业实现和发行版。 在本书中,我们将集中在标准 CPython 实现上,该实现可确保与 NumPy 兼容。
实战时间 – 在不同的操作系统上安装 Python
NumPy 具有用于 Windows,各种 Linux 发行版和 MacOSX 的二进制安装程序。 如果您愿意的话,还有源代码的发行版。 您需要在系统上安装 Python 2.4.x 或更高版本。 我们将完成在以下操作系统上安装 Python 所需的各个步骤:
Debian 和 Ubuntu:Python 可能已经安装在 Debian 和 Ubuntu 上,但是开发版通常不是。 在 Debian 和 Ubuntu 上,使用以下命令安装python和python-dev包:
$ [sudo] apt-get install python
$ [sudo] apt-get install python-devWindows:Windows Python 安装程序,可从这里获取。 在此网站上,我们还可以查找 MacOSX 的安装程序以及 Linux,UNIX 和 MacOSX 的源归档。
Mac:Python 已预装在 MacOSX 上。 我们还可以通过 MacPorts,Fink,Homebrew 或类似项目来获取 Python。
例如,通过运行以下命令来安装 Python 2.7 端口:
$ [sudo] port install python27线性代数包(LAPACK)不需要存在,但如果存在,NumPy 会检测到它,并在安装阶段使用它。 建议您安装 LAPACK 进行认真的数值分析,因为它具有有用的数值线性代数函数。
刚刚发生了什么?
我们在 Debian,Ubuntu,Windows 和 MacOSX 上安装了 Python。
Python 帮助系统
在开始介绍 NumPy 之前,让我们简要介绍一下 Python 帮助系统,以防万一您忘记了它的工作方式或不太熟悉它。 Python 帮助系统允许您从交互式 Python shell 中查找文档。 外壳程序是交互式程序,它接受命令并为您执行命令。
实战时间 – 使用 Python 帮助系统
根据您的操作系统,您可以使用特殊应用(通常是某种终端)访问 Python shell。
在这样的终端中,键入以下命令以启动 Python Shell:
$ python您将收到一条简短的消息,其中包含 Python 版本和其他信息以及以下提示:
>>>在提示符下键入以下内容:
>>> help()出现另一条消息,提示更改如下:
help>例如,如果按消息提示输入keywords,则会得到一个关键字列表。 topics命令给出了主题列表。 如果您在提示符下键入任何主题名称(例如LISTS),则会获得有关该主题的其他信息。 键入q退出信息屏幕。 同时按Ctrl + D返回正常的 Python 提示符:
>>>再次同时按下Ctrl + D将结束 Python Shell 会话。
刚刚发生了什么?
我们了解了 Python 交互式外壳和 Python 帮助系统。
基本算术和变量赋值
在“实战时间 – 使用 Python 帮助系统”部分,我们使用 Python Shell 查找文档。 我们也可以使用 Python 作为计算器。 这种方式只是一个复习,因此,如果您是 Python 的新手,我建议您花一些时间来学习基础知识。 如果您全神贯注,那么学习基本的 Python 应该花不了几个星期的时间。
实战时间 – 使用 Python 作为计算器
我们可以使用 Python 作为计算器,如下所示:
在 Python Shell 中,如下添加 2 和 2:
>>> 2 + 2
4将 2 和 2 相乘:
>>> 2 * 2
4将 2 和 2 相除如下:
>>> 2/2
1如果您之前进行过编程,则可能知道除法有些技巧,因为除法的类型不同。 对于计算器,结果通常是足够的,但是以下除法可能与您期望的不符:
>>> 3/2
1我们将在本书的后面几章中讨论此结果的含义。 取 2 的立方,如下所示:
>>> 2 ** 3
8刚刚发生了什么?
我们将 Python Shell 用作计算器,并执行了加法,乘法,除法和乘幂运算。
实战时间 – 为变量赋值
在 Python 中为变量赋值的方式与大多数编程语言相似。
例如,将2的值赋给名为var的变量,如下所示:
>>> var = 2
>>> var
2我们定义了变量并为其赋值。 在此 Python 代码中,变量的类型不固定。 我们可以将变量放入一个列表中,该列表是对应于值的有序序列的内置 Python 类型。 将var赋为一个列表,如下所示:
>>> var = [2, 'spam', 'eggs']
>>> var
[2, 'spam', 'eggs']我们可以使用其索引号将列表项赋为新值(从 0 开始计数)。 将第一个列表元素赋为新值:
>>> var
['ham', 'spam', 'eggs']我们还可以轻松交换值。 定义两个变量并交换它们的值:
>>> a = 1
>>> b = 2
>>> a, b = b, a
>>> a
2
>>> b
1刚刚发生了什么?
我们为变量和 Python 列表项赋值。 本节绝不详尽; 因此,如果您在挣扎,请阅读附录 B,“其他在线资源”,以找到推荐的 Python 教程。
print()函数
如果您有一段时间没有使用 Python 编程或者是 Python 新手,可能会对 Python2 与 Python3 的讨论感到困惑。 简而言之,最新版本的 Python3 与旧版本的 Python2 不向后兼容,因为 Python 开发团队认为某些问题是根本问题,因此需要进行重大更改。 Python 团队已承诺将 Python2 维护到 2020 年。这对于仍然以某种方式依赖 Python2 的人们来说可能是个问题。 print()函数的结果是我们有两种语法。
实战时间 – 使用print()函数进行打印
我们可以使用print()函数打印 ,如下所示:
旧语法如下:
>>> print 'Hello'
Hello新的 Python3 语法如下:
>>> print('Hello')
Hello现在,括号在 Python3 中是必需的。在本书中,我尝试尽可能多地使用新语法。 但是,出于安全考虑,我使用 Python2。 为了强制执行语法,本书中每个带有print()调用的 Python2 脚本均以:
>>> from __future__ import print_function尝试使用旧的语法以获取以下错误消息:
>>> print 'Hello'
File "<stdin>", line 1
print 'Hello'
^
SyntaxError: invalid syntax要打印换行符,请使用以下语法:
>>> print()要打印多个项目,请用逗号分隔它们:
>>> print(2, 'ham', 'egg')
2 ham egg默认情况下,Python 用空格分隔打印的值,然后将输出打印到屏幕上。 您可以自定义这些设置。 通过键入以下命令来了解有关此函数的更多信息:
>>> help(print)您可以通过输入q再次退出。
刚刚发生了什么?
我们了解了print()函数及其与 Python2 和 Python3 的关系。
代码注释
代码注释是最佳做法,其目的是使您自己和其他编码者更加清楚代码(请参阅这里)。 通常,公司和其他组织对代码注释有政策,例如注释模板。 在本书中,为了简洁起见,我没有以这种方式注释代码,因为书中的文字应使代码清晰。
实战时间 – 注释代码
最基本的注释以井号开始,一直持续到该行的末尾:
具有此类注释的注释代码如下:
>>> # Comment from hash to end of line但是,如果哈希符号在单引号或双引号之间,则我们有一个字符串,它是字符的有序序列:
>>> astring = '# This is not a comment'
>>> astring
'# This is not a comment'我们也可以将多行注释为一个块。 如果您想编写更详细的代码说明,这将很有用。 注释多行,如下所示:
"""
Chapter 1 of NumPy Beginners Guide.
Another line of comment.
"""由于明显的原因,我们将这种类型的注释称为三引号。 它还用于测试代码。 您可以在第 8 章,“确保测试的质量”中了解有关测试的信息。
if语句
Python 中的if语句与其他语言(例如 C++ 和 Java)的语法有些不同。 最重要的区别是缩进很重要,我希望您知道这一点。
实战时间 – 使用if语句来决策
我们可以通过以下方式使用if语句:
检查数字是否为负,如下所示:
>>> if 42 < 0:
... print('Negative')
... else:
... print('Not negative')
...
Not negative在前面的示例中,Python 判定42不为负。 else子句是可选的。 比较运算符等效于 C++ ,Java 和类似语言中的运算符。
Python 还具有用于多个测试的链式分支逻辑复合语句,类似于 C++,Java 和其他编程语言中的switch语句。 确定数字是负数,0 还是正数,如下所示:
>>> a = -42
>>> if a < 0:
... print('Negative')
... elif a == 0:
... print('Zero')
... else:
... print('Positive')
...
Negative这次,Python 判定42为负。
刚刚发生了什么?
我们学习了如何在 Python 中执行分支逻辑。
for循环
Python 具有for语句,其目的与 C++ ,Pascal,Java 和其他语言中的等效构造相同。 但是,循环的机制有些不同。
实战时间 – 使用循环来重复指令
我们可以通过以下方式使用for循环:
循环显示有序序列(例如列表),并按以下方式打印每个项目:
>>> food = ['ham', 'egg', 'spam']
>>> for snack in food:
... print(snack)
...
ham
egg
spam请记住,与往常一样,缩进在 Python 中很重要。 我们使用内置的range()或xrange()函数遍历一系列值。 在某些情况下,后者的功能会稍微更有效。 按以下步骤 2 循环编号1-9:
>>> for i in range(1, 9, 2):
... print(i)
...
1
3
5
7range()函数的start和step参数是可选的,默认值为1。 我们还可以提早结束循环。 遍历数字0-9并在到达3时跳出循环:
>>> for i in range(9):
... print(i)
... if i == 3:
... print('Three')
... break
...
0
1
2
3
Three循环在3处停止,我们没有打印更高的数字。 除了退出循环,我们也可以退出当前迭代。 打印数字0-4,跳过3,如下所示:
>>> for i in range(5):
... if i == 3:
... print('Three')
... continue
... print(i)
...
0
1
2
Three
4由于出现continue语句,当我们到达3时未执行循环的最后一行。 在 Python 中,for循环可以附加一个else语句。 添加else子句,如下所示:
>>> for i in range(5):
... print(i)
... else:
... print(i, 'in else clause')
...
0
1
2
3
4
(4, 'in else clause')Python 最后执行else子句中的代码。 Python 也有一个while循环。 我没有使用它太多,因为我认为for循环更有用。
刚刚发生了什么?
我们学习了如何在带循环的 Python 中重复指令。 本节包含break和continue语句,它们退出并继续循环。
Python 函数
函数是可调用的代码块。 我们用给它们的名称来调用函数。
实战时间 – 定义函数
让我们定义以下简单函数:
通过以下方式打印Hello和给定名称:
>>> def print_hello(name):
... print('Hello ' + name)
...调用函数如下:
>>> print_hello('Ivan')
Hello Ivan某些函数没有参数,或者参数具有默认值。 为函数提供默认的参数值,如下所示:
>>> def print_hello(name='Ivan'):
... print('Hello ' + name)
...
>>> print_hello()
Hello Ivan通常,我们要返回一个值。 定义一个将输入值加倍的函数,如下所示:
>>> def double(number):
... return 2 * number
...
>>> double(3)
6刚刚发生了什么?
我们学习了如何定义函数。 函数可以具有默认参数值和返回值。
Python 模块
包含 Python 代码的文件被称为模块。 一个模块可以导入其他模块,其他模块中的函数以及模块的其他部分。 Python 模块的文件名以.py结尾。 模块的名称与文件名减去.py后缀相同。
实战时间 – 导入模块
导入模块可以通过以下方式完成:
例如,如果文件名是mymodule.py,则按以下方式导入它:
>>> import mymodule标准的 Python 发行版具有math模块。 导入后,按如下所示在模块中列出函数和属性:
>>> import math
>>> dir(math)
['__doc__', '__file__', '__name__', '__package__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign', 'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'hypot', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'modf', 'pi', 'pow', 'radians', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'trunc']在math模块中调用pow()函数:
>>> math.pow(2, 3)
8.0注意语法中的点。 我们还可以直接导入一个函数,并以其短名称调用它。 导入并调用pow()函数,如下所示:
>>> from math import pow
>>> pow(2, 3)
8.0Python 使我们可以为导入的模块和函数定义别名。 现在是介绍我们将用于 NumPy 的导入约定以及将大量使用的绘图库的好时机:
import numpy as np
import matplotlib.pyplot as plt刚刚发生了什么?
我们学习了有关模块,导入模块,导入函数,模块中的调用函数以及本书的导入约定的知识。 Python 复习到此结束。
Windows 上的 NumPy
在 Windows 上安装 NumPy 非常简单。 您只需要下载安装程序,向导就会指导您完成安装步骤。
实战时间 – 在 Windows 上安装 NumPy,matplotlib,SciPy 和 IPython
在 Windows 上安装 NumPy 是必要的,但是幸运的是,这是我们将详细介绍的简单任务。 建议您安装 matplotlib,SciPy 和 IPython。 但是,对于这本书来说不需要使用它们。 我们将采取的动作如下:
- 从 SourceForge 网站下载适用于 Windows 的 NumPy 安装程序。
根据您的 Python 版本选择适当的 NumPy 版本。 在上一个屏幕截图中,我们选择了numpy-1.9.2-win32-superpack-python2.7.exe。
- 双击打开 EXE 安装程序,如以下屏幕快照所示:
- 现在,我们可以看到对 NumPy 及其功能的描述。 单击下一步。
- 如果您安装了 Python ,则应自动检测到它。 如果未检测到,则您的路径设置可能不正确。 在本章的结尾,我们列出了资源,以防您安装 NumPy 时遇到问题。
- 在此示例中,找到了 Python 2.7。 如果找到 Python,请单击“下一步”。 否则,请单击“取消”并安装 Python(如果没有 Python,则无法安装 NumPy)。 点击下一步。 这是无可挽回的地方。 很好,但是最好确保要安装到正确的目录,依此类推。 现在开始真正的安装。 可能还要等一下。
使用 Enthought Canopy 发行版安装 SciPy 和 matplotlib。 可能需要将
msvcp71.dll文件放在您的C:\Windows\system32目录中, 您可以从这里获得。在 IPython 网站上提供 Windows IPython 安装程序。
刚刚发生了什么?
我们在 Windows 上安装了 NumPy,SciPy,matplotlib 和 IPython。
Linux 上的 NumPy
在 Linux 上安装 NumPy 及其相关的推荐软件取决于您所拥有的发行版。 我们将讨论如何从命令行安装 NumPy,尽管您可能可以使用图形安装程序。 取决于您的发行版。 安装 matplotlib,SciPy 和 IPython 的命令是相同的-仅包名称不同。 建议安装 matplotlib,SciPy 和 IPython,但这是可选的。
实战时间 – 在 Linux 上安装 NumPy,matplotlib,SciPy 和 IPython
大多数 Linux 发行版具有 NumPy 包。 对于某些最流行的 Linux 发行版,我们将介绍必要命令 :
在 RedHat 上安装 NumPy:按照命令行中的说明运行:
$ yum install python-numpy在 Mandriva 上安装 NumPy:要在 Mandriva 上安装 NumPy,请运行以下命令行指令:
$ urpmi python-numpy在 Gentoo 上安装 NumPy:要在 Gentoo 上安装 NumPy,请运行以下命令行指令:
$ [sudo] emerge numpy在 Debian 和 Ubuntu 上安装 NumPy:在 Debian 或 Ubuntu 上,在命令行上输入以下内容:
$ [sudo] apt-get install python-numpy下表概述了 Linux 发行版以及 NumPy,SciPy,matplotlib 和 IPython 的相应包名称:
Linux 发行版 | NumPy | SciPy | matplotlib | IPython |
|---|---|---|---|---|
Arch Linux | python-numpy | python-scipy | python-matplotlib | ipython |
Debian | python-numpy | python-scipy | python-matplotlib | ipython |
Fedora | numpy | python-scipy | python-matplotlib | ipython |
Gentoo | dev-python/numpy | scipy | matplotlib | ipython |
OpenSUSE | python-numpy, python-numpy-devel | python-scipy | python-matplotlib | ipython |
Slackware | numpy | scipy | matplotlib | ipython |
MacOSX 上的 NumPy
您可以使用 GUI 安装程序(并非所有版本都可以)在 MacOSX 上安装 NumPy,matplotlib 和 SciPy,也可以使用端口管理器(例如 MacPorts)通过命令行安装,HomeBrew 或 Fink,具体取决于您的偏好。 您还可以使用脚本来安装。
实战时间 – 使用 MacPorts 或 Fink 安装 NumPy,SciPy,matplotlib 和 IPython
另外,我们可以通过 MacPorts 路由或通过 Fink 安装 NumPy,SciPy,matplotlib 和 IPython。 以下安装步骤显示了如何安装所有这些包:
使用 MacPorts 安装:输入以下命令:
$ [sudo] port install py-numpy py-scipy py-matplotlib py-ipython使用 Fink 安装:Fink 也提供用于 NumPy 的包-scipy-core-py24 ,scipy-core-py25和scipy-core-py26。 SciPy 包为scipy-py24,scipy-py25和scipy-py26。 我们可以使用以下命令,将 NumPy 和其他推荐的包安装到 Python 2.7 上:
$ fink install scipy-core-py27 scipy-py27 matplotlib-py27刚刚发生了什么?
我们在带有 MacPorts 和 Fink 的 MacOSX 上安装了 NumPy 和其他推荐的软件。
从源代码构建
我们可以使用git检索 NumPy 的源代码,如下所示:
$ git clone git://github.com/numpy/numpy.git numpy或者,从这里下载源。
使用以下命令在/usr/local中安装:
$ python setup.py build
$ [sudo] python setup.py install --prefix=/usr/local要构建,我们需要一个 C 编译器,例如 GCC 和python-dev或python-devel包中的 Python 头文件。
数组
在完成 NumPy 的安装之后,是时候看看 NumPy 数组了。 在进行数值运算时,NumPy 数组比 Python 列表更有效 。 与等效的 Python 代码相比,NumPy 代码需要更少的显式循环。
实战时间 – 相加向量
假设我们要添加两个分别称为a和b的向量。向量在数学上是指一维数组。 我们将在第 5 章学习有关矩阵和ufunc的内容,它们涉及代表矩阵的专用 NumPy 数组。 向量a保留整数0至n的平方,例如,如果n等于3,则 a 等于(0,1, 4)。 向量b包含整数0至n的立方,因此,如果n等于3,则b等于(0,1, 8)。 您将如何使用普通 Python 做到这一点? 在提出解决方案后,我们将其与 NumPy 等效项进行比较。
使用纯 Python 相加向量:以下函数使用不带 NumPy 的纯 Python 解决了向量相加问题:
def pythonsum(n):
a = range(n)
b = range(n)
c = []
for i in range(len(a)):
a[i] = i ** 2
b[i] = i ** 3
c.append(a[i] + b[i])
return c使用 NumPy 相加向量:以下是与 NumPy 达到相同结果的函数:
def numpysum(n):
a = np.arange(n) ** 2
b = np.arange(n) ** 3
c = a + b
return c请注意,numpysum()不需要for循环。 此外,我们使用了 NumPy 的arange()函数,该函数为我们创建了一个整数0至n的 NumPy 数组。 arange()函数已导入; 这就是为什么它以numpy为前缀的原因(实际上,习惯上是通过np的别名来缩写它)。
有趣的来了。 序言提到,在数组操作方面,NumPy 更快。 NumPy 快多少? 以下程序将通过为numpysum()和pythonsum()函数测量经过的时间(以微秒为单位)向我们展示。 它还打印向量和的最后两个元素。 让我们检查是否通过使用 Python 和 NumPy 得到了相同的答案:
##!/usr/bin/env/python
from __future__ import print_function
import sys
from datetime import datetime
import numpy as np
"""
Chapter 1 of NumPy Beginners Guide.
This program demonstrates vector addition the Python way.
Run from the command line as follows
python vectorsum.py n
where n is an integer that specifies the size of the vectors.
The first vector to be added contains the squares of 0 up to n.
The second vector contains the cubes of 0 up to n.
The program prints the last 2 elements of the sum and the elapsed time.
"""
def numpysum(n):
a = np.arange(n) ** 2
b = np.arange(n) ** 3
c = a + b
return c
def pythonsum(n):
a = range(n)
b = range(n)
c = []
for i in range(len(a)):
a[i] = i ** 2
b[i] = i ** 3
c.append(a[i] + b[i])
return c
size = int(sys.argv[1])
start = datetime.now()
c = pythonsum(size)
delta = datetime.now() - start
print("The last 2 elements of the sum", c[-2:])
print("PythonSum elapsed time in microseconds", delta.microseconds)
start = datetime.now()
c = numpysum(size)
delta = datetime.now() - start
print("The last 2 elements of the sum", c[-2:])
print("NumPySum elapsed time in microseconds", delta.microseconds)1000,2000和3000向量元素的程序的输出如下:
$ python vectorsum.py 1000
The last 2 elements of the sum [995007996, 998001000]
PythonSum elapsed time in microseconds 707
The last 2 elements of the sum [995007996 998001000]
NumPySum elapsed time in microseconds 171
$ python vectorsum.py 2000
The last 2 elements of the sum [7980015996, 7992002000]
PythonSum elapsed time in microseconds 1420
The last 2 elements of the sum [7980015996 7992002000]
NumPySum elapsed time in microseconds 168
$ python vectorsum.py 4000
The last 2 elements of the sum [63920031996, 63968004000]
PythonSum elapsed time in microseconds 2829
The last 2 elements of the sum [63920031996 63968004000]
NumPySum elapsed time in microseconds 274刚刚发生了什么?
显然,NumPy 比等效的普通 Python 代码快得多。 可以肯定的是,无论是否使用 NumPy,我们都会得到相同的结果。 但是,打印结果在表示形式上有所不同。 请注意,numpysum()函数的结果没有任何逗号。 怎么会? 显然,我们不是在处理 Python 列表,而是在处理 NumPy 数组。 在“前言”中提到,NumPy 数组是用于数值数据的专用数据结构。 在下一章中,我们将了解有关 NumPy 数组的更多信息。
小测验 – arange()函数的功能
Q1. arange(5)做什么?
- 创建一个由 5 个元素组成的 Python 列表,其值是 1-5。
- 创建一个 Python 列表,其中包含 5 个元素的值 0-4。
- 创建一个值为 1-5 的 NumPy 数组。
- 创建一个值为 0-4 的 NumPy 数组。
- 以上都不是。
勇往直前 – 继续分析
我们用来比较 NumPy 和常规 Python 速度的程序不是很科学。 我们至少应该重复两次测量。 能够计算一些统计量(例如平均时间)将非常不错。 另外,您可能想向朋友和同事显示测量图。
提示
可以在联机文档和本章末尾列出的资源中找到帮助提示。 NumPy 具有统计函数,可以为您计算平均值。 我建议使用 matplotlib 生成图。 第 9 章“matplotlib 绘图”,简要介绍了 matplotlib。
IPython – 交互式 Shell
科学家和工程师习惯于进行实验。 科学家出于实验目的创建了 IPython。 许多人认为 IPython 提供的交互式环境是 MATLAB, Mathematica 和 Maple。 您可以浏览这里来获取更多信息,包括安装的说明。
IPython 是免费开源的,可用于 Linux,UNIX,MacOSX 和 Windows。 IPython 作者仅要求您在使用 IPython 的任何科学著作中引用 IPython。 以下是 IPython 的基本功能列表:
- 制表符补全
- 历史机制
- 内联编辑
- 能够使用
%run调用外部 Python 脚本 - 访问系统命令
pylab开关- 访问 Python 调试器和分析器
pylab开关导入所有 SciPy,NumPy 和 matplotlib 包。 没有此开关,我们将必须导入我们需要的每个包。
我们需要做的就是在命令行中输入以下指令:
$ ipython --pylab
IPython 2.4.1 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
Using matplotlib backend: MacOSX
In [1]: quit()quit()命令或Ctrl + D退出 IPython Shell。 我们可能希望能够返回到我们的实验。 在 IPython 中,很容易保存会话供以后使用:
In [1]: %logstart
Activating auto-logging. Current session state plus future input saved.
Filename : ipython_log.py
Mode : rotate
Output logging : False
Raw input log : False
Timestamping : False
State : active假设我们有在当前目录中制作的向量加法程序。 运行脚本,如下所示:
In [1]: ls
README vectorsum.py
In [2]: %run -i vectorsum.py 1000您可能还记得,1000指定向量中的元素数。 %run的-d开关使用c启动脚本的ipdb调试器。 n逐步执行代码。 在ipdb提示符下键入quit退出调试器:
In [2]: %run -d vectorsum.py 1000
*** Blank or comment
*** Blank or comment
Breakpoint 1 at: /Users/…/vectorsum.py:3提示
在ipdb>提示符下输入c启动脚本。
><string>(1)<module>()
ipdb> c
> /Users/…/vectorsum.py(3)<module>()
2
1---> 3 import sys
4 from datetime import datetime
ipdb> n
>
/Users/…/vectorsum.py(4)<module>()
1 3 import sys
----> 4 from datetime import datetime
5 import numpy
ipdb> n
> /Users/…/vectorsum.py(5)<module>()
4 from datetime import datetime
----> 5 import numpy
6
ipdb> quit我们还可以通过将-p选项传递给%run:来分析脚本
In [4]: %run -p vectorsum.py 1000
1058 function calls (1054 primitive calls) in 0.002 CPU seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.001 0.001 0.001 0.001 vectorsum.py:28(pythonsum)
1 0.001 0.001 0.002 0.002 {execfile}
1000 0.000 0.0000.0000.000 {method 'append' of 'list' objects}
1 0.000 0.000 0.002 0.002 vectorsum.py:3(<module>)
1 0.000 0.0000.0000.000 vectorsum.py:21(numpysum)
3 0.000 0.0000.0000.000 {range}
1 0.000 0.0000.0000.000 arrayprint.py:175(_array2string)
3/1 0.000 0.0000.0000.000 arrayprint.py:246(array2string)
2 0.000 0.0000.0000.000 {method 'reduce' of 'numpy.ufunc' objects}
4 0.000 0.0000.0000.000 {built-in method now}
2 0.000 0.0000.0000.000 arrayprint.py:486(_formatInteger)
2 0.000 0.0000.0000.000 {numpy.core.multiarray.arange}
1 0.000 0.0000.0000.000 arrayprint.py:320(_formatArray)
3/1 0.000 0.0000.0000.000 numeric.py:1390(array_str)
1 0.000 0.0000.0000.000 numeric.py:216(asarray)
2 0.000 0.0000.0000.000 arrayprint.py:312(_extendLine)
1 0.000 0.0000.0000.000 fromnumeric.py:1043(ravel)
2 0.000 0.0000.0000.000 arrayprint.py:208(<lambda>)
1 0.000 0.000 0.002 0.002<string>:1(<module>)
11 0.000 0.0000.0000.000 {len}
2 0.000 0.0000.0000.000 {isinstance}
1 0.000 0.0000.0000.000 {reduce}
1 0.000 0.0000.0000.000 {method 'ravel' of 'numpy.ndarray' objects}
4 0.000 0.0000.0000.000 {method 'rstrip' of 'str' objects}
3 0.000 0.0000.0000.000 {issubclass}
2 0.000 0.0000.0000.000 {method 'item' of 'numpy.ndarray' objects}
1 0.000 0.0000.0000.000 {max}
1 0.000 0.0000.0000.000 {method 'disable' of '_lsprof.Profiler' objects}这使我们对程序的运作有了更多的了解。 此外,我们现在可以确定性能瓶颈。 %hist命令显示命令历史记录:
In [2]: a=2+2
In [3]: a
Out[3]: 4
In [4]: %hist
1: _ip.magic("hist ")
2: a=2+2
3: a希望您同意 IPython 是一个非常有用的工具!
在线资源和帮助
当我们处于 IPython 的pylab模式时,可以使用help命令打开 NumPy 函数的手册页。 不必知道函数名称。 我们可以输入几个字符,然后让制表符完成工作。 例如,让我们浏览arange()函数的可用信息:
In [2]: help ar<Tab>
In [2]: help arange另一种选择是在函数名称后添加问号:
In [3]: arange?有关 NumPy 和 SciPy 的主要文档网站在这个页面上。 通过此网页,我们可以在 NumPy 参考中浏览用户指南和一些教程。
流行的 Stack Overflow 软件开发论坛有数百个标记为numpy的问题。 要查看它们,请转到这里。
如果您确实感到困惑,或者想随时了解 NumPy 开发的信息,则可以订阅 NumPy 讨论邮件列表。 电子邮件地址为<numpy-discussion@scipy.org>。 每天的电子邮件数量不是很高,几乎没有垃圾邮件可言。 最重要的是,积极参与 NumPy 的开发人员还回答了讨论组提出的问题。 完整列表可以在这个页面中找到。
对于 IRC 用户,在 irc://irc.freenode.net 上有一个 IRC 频道。 该通道称为#scipy,但是您也可以询问 NumPy,因为 SciPy 用户也了解 NumPy,因为 SciPy 基于 NumPy。 任何时候,SciPy 频道上至少有 50 名成员。
总结
在本章中,我们安装了 NumPy 和其他推荐的软件,这些软件将在本书的某些部分中使用。 我们启动了向量加法程序,并确信 NumPy 具有出色的性能。 向您介绍了 IPython 交互式 Shell。 此外,您还浏览了可用的 NumPy 文档和在线资源。
在下一章中,您将深入了解并探索一些基本概念,包括数组和数据类型。
二、从 NumPy 基本原理开始
在安装 NumPy 并使一些代码正常工作之后,该介绍 NumPy 的基础知识了。
我们将在本章中介绍的主题如下:
- 数据类型
- 数组类型
- 类型转换
- 数组创建
- 索引
- 切片
- 形状操作
在开始之前,让我对本章中的代码示例进行一些说明。 本章中的代码段显示了几个 IPython 会话的输入和输出。 回想一下,在第 1 章, “NumPy 快速入门”中引入了 IPython,它是科学计算选择的交互式 Python shell。 IPython 的优点是--pylab开关可以导入许多科学计算 Python 包,包括 NumPy,并且不需要显式调用print()函数来显示变量值。 其他功能还包括轻松的并行计算和 Web 浏览器中持久工作表形式的笔记本界面。
但是,本书随附的源代码是使用import和print语句的常规 Python 代码。
NumPy 数组对象
NumPy 具有一个名为ndarray的多维数组对象。 它由两部分组成:
- 实际数据
- 一些描述数据的元数据
大多数数组操作都保持原始数据不变。 更改的唯一方面是元数据。
在上一章中,我们已经学习了如何使用arange()函数创建数组。 实际上,我们创建了一个包含一组数字的一维数组。 ndarray对象可以具有多个维度。
NumPy 数组通常是同质的(“实战时间 – 创建记录数据类型”部分中介绍了一种异类的特殊数组类型)—数组中的项目必须是同一类型。 好处是,如果我们知道数组中的项目属于同一类型,则很容易确定数组所需的存储大小。
NumPy 数组从 0 开始索引,就像在 Python 中一样。 数据类型由特殊对象表示。 我们将在本章中全面讨论这些对象。
让我们再次使用arange()函数创建一个数组。 使用以下代码获取数组的数据类型:
In: a = arange(5)
In: a.dtype
Out: dtype('int64')数组a的数据类型为int64(至少在我的机器上),但是如果使用 32 位 Python,则可能会得到int32作为输出。 在这两种情况下,我们都处理整数(64 位或 32 位)。 除了数组的数据类型外,了解其形状也很重要。
在第 1 章, “NumPy 快速入门”中,我们演示了如何创建向量(实际上是一维 NumPy 数组)。 向量通常用于数学中,但是大多数时候,我们需要更高维的对象。 确定我们在几分钟前创建的向量的形状。 以下代码是创建向量的示例:
In [4]: a
Out[4]: array([0, 1, 2, 3, 4])
In: a.shape
Out: (5,)如您所见,向量具有五个元素,其值范围从0到4。 数组的shape属性是一个元组,在这种情况下为 1 个元素的元组,其中包含每个维度的长度。
注意
Python 中的元组是一个不变的(不能更改)值序列。 创建元组后,不允许我们更改元组元素的值或追加新元素。 这使元组比列表更安全,因为您不能偶然对其进行突变。 元组的常见用例是作为函数的返回值。 有关更多示例,请查看第 3 章的“元组介绍”部分,可在 diveintopython.net 上获得。
实战时间 – 创建多维数组
既然我们知道如何创建向量,就可以创建多维 NumPy 数组了。 创建数组后,我们将再次想要显示其形状:
创建一个2x2数组:
In: m = array([arange(2), arange(2)])
In: m
Out:
array([[0, 1],
[0, 1]])显示数组形状:
In: m.shape
Out: (2, 2)刚刚发生了什么?
我们使用值得信赖和喜爱的arange()和array()函数创建了一个2 x 2的数组。 没有任何警告,array()函数出现在舞台上。
array()函数根据您提供给它的对象创建一个数组。 该对象必须是类似数组的,例如 Python 列表。 在前面的示例中,我们传入了一个数组列表。 该对象是array()函数的唯一必需参数。 NumPy 函数倾向于具有许多带有预定义默认值的可选参数。 在 IPython shell 中使用此处提供的help()函数查看此函数的文档:
In [1]: help(array)或使用以下速记:
In [2]: array?当然,您可以在此示例中将array替换为您感兴趣的另一个 NumPy 函数。
小测验 – ndarray的形状
Q1. ndarray的形状如何存储?
- 它存储在逗号分隔的字符串中。
- 它存储在列表中。
- 它存储在元组中。
勇往直前 – 创建三乘三的数组
现在创建一个三乘三的数组应该不难 。 试试看,检查数组形状是否符合预期。
选择元素
我们有时需要选择数组的特定元素。 我们将看一下如何执行此操作,但是,首先,再次创建一个2 x 2数组:
In: a = array([[1,2],[3,4]])
In: a
Out:
array([[1, 2],
[3, 4]])这次是通过将列表列表传递给array()函数来创建数组的。 现在,我们将逐一选择矩阵的每个项目。 请记住,索引从0:开始编号
In: a[0,0]
Out: 1
In: a[0,1]
Out: 2
In: a[1,0]
Out: 3
In: a[1,1]
Out: 4如您所见,选择数组的元素非常简单。 对于数组a,我们只使用符号a[m,n],其中m和n是数组中该项的索引(数组的维数比本示例中的还要多)。 此屏幕快照显示了一个简单的数组示例:

NumPy 数值类型
Python 具有整数类型,浮点类型和复杂类型; 但是,这还不足以进行科学计算,因此,NumPy 拥有更多的数据类型 ,它们的精度取决于存储要求。
注意
整数代表整数,例如 -1、0 和 1。浮点数对应于数学中使用的实数,例如分数或无理数,例如pi。 由于计算机的工作方式,我们能够精确地表示整数,但是浮点数是近似值。 复数可以具有通常用i或j表示的虚部。 根据定义,i是 -1 的平方根。 例如,2.5 + 3.7i是一个复数(有关更多信息,请参阅这里)。
在实践中,我们甚至需要更多具有不同精度的类型,因此,该类型的内存大小也有所不同。 大多数 NumPy 数值类型都以数字结尾。 该数字表示与该类型关联的位的数目。 下表(根据 NumPy 用户指南改编)概述了 NumPy 数值类型:
类型 | 描述 |
|---|---|
bool | 布尔(True或False)存储为位 |
inti | 平台整数(通常为int32或int64) |
int8 | 字节(-128 至 127) |
int16 | 整数(-32768 至 32767) |
int32 | 整数(-2 ** 31到2 ** 31 -1) |
int64 | 整数(-2 ** 63到2 ** 63 -1) |
uint8 | 无符号整数(0 到 255) |
uint16 | 无符号整数(0 到 65535) |
uint32 | 无符号整数(0 到2 ** 32-1) |
uint64 | 无符号整数(0 到2 ** 64-1) |
float16 | 半精度浮点数:符号位,5 位指数,10 位尾数 |
float32 | 单精度浮点数:符号位,8 位指数,23 位尾数 |
float64或float | 双精度浮点数:符号位,11 位指数,52 位尾数 |
complex64 | 复数,由两个 32 位浮点数表示(实部和虚部) |
complex128或complex | 复数,由两个 64 位浮点数表示(实部和虚部) |
对于浮点类型,我们可以使用此处提供的finfo()函数来请求信息:
In: finfo(float16)
Out: finfo(resolution=0.0010004, min=-6.55040e+04, max=6.55040e+04, dtype=float16)对于每种数据类型,都有一个对应的转换函数:
In: float64(42)
Out: 42.0
In: int8(42.0)
Out: 42
In: bool(42)
Out: True
In: bool(0)
Out: False
In: bool(42.0)
Out: True
In: float(True)
Out: 1.0
In: float(False)
Out: 0.0许多函数都有一个数据类型参数,该参数通常是可选的:
In: arange(7, dtype=uint16)
Out: array([0, 1, 2, 3, 4, 5, 6], dtype=uint16)重要的是要知道您不允许将复数转换为整数或浮点数。 尝试执行触发TypeError的 ,如以下屏幕截图所示:

将复数转换为浮点数也是如此。
注意
Python 中的异常是一种异常情况,我们通常会尝试避免这种情况。 TypeError是 Python 内置的异常,当我们为参数指定错误的类型时发生。
j部分是复数的虚数系数。 但是,您可以将浮点数转换为复数,例如complex(1.0)。
数据类型对象
数据类型对象是numpy.dtype类。 再次,数组具有数据类型。 确切地说,NumPy 数组中的每个元素都具有相同的数据类型。 数据类型对象可以告诉您数据的大小(以字节为单位)。 以字节为单位的大小由dtype 类的itemsize属性给出:
In: a.dtype.itemsize
Out: 8字符代码
包括字符代码是为了与数字向后兼容。 数字是 NumPy 的前身。 虽然不建议使用,但此处提供代码,因为它们会在多个位置出现。 相反,我们应该使用dtype对象。 下表显示了字符代码:
类型 | 字符码 |
|---|---|
整数 | i |
无符号整数 | u |
单精度浮点 | f |
双精度浮点 | d |
布尔型 | b |
复数 | D |
字符串 | S |
Unicode | U |
无 | V |
查看以下代码以创建单精度浮点数数组:
In: arange(7, dtype='f')
Out: array([ 0., 1., 2., 3., 4., 5., 6.], dtype=float32)同样,这将创建一个复数数组。
In: arange(7, dtype='D')
Out: array([ 0.+0.j, 1.+0.j, 2.+0.j, 3.+0.j, 4.+0.j, 5.+0.j, 6.+0.j])dtype构造器
Python 类具有函数,如果它们属于一个类,则这些函数称为方法。 其中某些方法是特殊的, 用于创建新对象。 这些专门方法称为构造器。
注意
您可以在这个页面上阅读有关 Python 类的更多信息。
我们有多种创建数据类型的方法。 以浮点数据为例:
使用通用的 Python 浮点数:
In: dtype(float)
Out: dtype('float64')用字符代码指定一个单精度浮点数:
In: dtype('f')
Out: dtype('float32')使用双精度浮点字符代码:
In: dtype('d')
Out: dtype('float64')我们可以给数据类型构造器一个两个字符的代码。 第一个字符表示类型,第二个字符是一个数字,用于指定类型中的字节数(数字 2、4 和 8 对应于 16、32 和 64 位浮点数):
In: dtype('f8')
Out: dtype('float64')可以使用sctypeDict.keys()函数找到所有完整数据类型名称的列表:
In: sctypeDict.keys()
Out: [0, …
'i2',
'int0']dtype属性
dtype类具有许多有用的属性。 例如,通过dtype的属性获取有关数据类型的字符代码的信息:
In: t = dtype('Float64')
In: t.char
Out: 'd'dtype属性对应于数组元素的对象类型:
In: t.type
Out: <type 'numpy.float64'>dtype类的str属性给出了数据类型的字符串表示形式。 它以代表字节序的字符开头(如果合适),然后是一个字符代码,后跟一个与每个数组项所需的字节数相对应的数字。 字节序在这里指 ,即在 32 位或 64 位字中对字节进行排序的方式。 按照大端顺序,最高有效字节先存储,由>指示。 以低字节序排列,最低有效字节先存储,由<指示:
In: t.str
Out: '<f8'实战时间 – 创建记录数据类型
记录数据类型是一种异构数据类型,可以认为它代表电子表格或数据库中的一行。 为了提供记录数据类型的示例,我们将为商店股票创建一条记录。 记录包含商品名称,40 个字符的字符串,商店中商品的数量(由 32 位整数表示)以及最后由 32 位浮点数表示的价格。 这些连续的步骤显示了如何创建记录数据类型:
创建记录:
In: t = dtype([('name', str_, 40), ('numitems', int32), ('price', float32)])
In: t
Out: dtype([('name', '|S40'), ('numitems', '<i4'), ('price', '<f4')])查看类型(我们也可以查看字段的类型):
In: t['name']
Out: dtype('|S40')如果不为array()函数提供数据类型,则将假定它正在处理浮点数。 现在要创建数组,我们实际上必须指定数据类型; 否则,我们将获得TypeError:
In: itemz = array([('Meaning of life DVD', 42, 3.14), ('Butter', 13, 2.72)], dtype=t)
In: itemz[1]
Out: ('Butter', 13, 2.7200000286102295)刚刚发生了什么?
我们创建了一个记录数据类型,它是一个异构数据类型。 该记录包含一个名称,该名称为字符串,数字为整数,以及以浮点数表示的价格。 该示例的代码可以在本书代码捆绑中的record.py文件中找到。
一维切片和索引
一维 NumPy 数组的切片就像 Python 列表的切片一样工作。 从索引3到7中选择一个数组 ,该数组提取元素3至6:
In: a = arange(9)
In: a[3:7]
Out: array([3, 4, 5, 6])通过步骤 2 从索引0到7中选择元素,如下所示:
In: a[:7:2]
Out: array([0, 2, 4, 6])同样,与 Python 中一样,使用负索引并使用以下代码片段反转数组:
In: a[::-1]
Out: array([8, 7, 6, 5, 4, 3, 2, 1, 0])实战时间 – 切片和索引多维数组
ndarray类支持在多个维度上切片。 为了方便 ,我们一次用省略号指代许多尺寸。
为了说明这一点,请使用arange()函数创建一个数组并调整其形状:
In: b = arange(24).reshape(2,3,4)
In: b.shape
Out: (2, 3, 4)
In: b
Out:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])数组b具有24元素,其值从0至23,我们将其重构为2×3×4的三维数组。 我们可以将其可视化为一个两层楼的架构,每层有 12 个房间,3 行和 4 列(或者我们可以将其视为包含工作表,行和列的电子表格)。 您可能已经猜到了,reshape()函数会更改数组的形状。 我们给它一个整数元组,对应于新的形状。 如果维度与数据不兼容,则会引发异常。
我们可以使用其三个坐标(即楼层,列和行)选择一个房间。 例如,可以表示行和第一列中的房间(我们可以有 0 层,房间 0,这只是一个惯例)。 由以下各项组成:
In: b[0,0,0]
Out: 0如果我们不在乎楼层,但仍然想要第一列和第一行,则将第一个索引替换为a:(冒号),因为我们只需要指定楼层号并省略其他指标:
In: b[:,0,0]
Out: array([ 0, 12])选择此代码中的第一层:
In: b[0]
Out:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])我们也可以这样写:
In: b[0, :, :]
Out:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])省略号(…)替换了多个冒号,因此,前面的代码等效于此:
In: b[0, ...]
Out:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])此外,在第一层获得第二行:
In: b[0,1]
Out: array([4, 5, 6, 7])带有步长的切片:此外,还要选择此选择的每隔一个元素:
In: b[0,1,::2]
Out: array([4, 6])带有省略号的切片:如果我们要选择第二列中两层的所有房间,而不管是哪一行,请键入以下代码:
In: b[...,1]
Out:
array([[ 1, 5, 9],
[13, 17, 21]])同样,通过编写以下代码段,选择第二行中的所有房间,而不管楼层和列如何:
In: b[:,1]
Out:
array([[ 4, 5, 6, 7],
[16, 17, 18, 19]])如果我们要在第一层第二栏中选择房间,请输入以下内容:
In: b[0,:,1]
Out: array([1, 5, 9])使用负索引:如果我们要选择第一层,最后一列,然后输入以下代码段:
In: b[0,:,-1]
Out: array([ 3, 7, 11])如果我们要选择一楼的房间,则将最后一列颠倒过来,然后输入以下代码片段:
In: b[0,::-1, -1]
Out: array([11, 7, 3])选择该片的第二个元素,如下所示:
In: b[0,::2,-1]
Out: array([ 3, 11])反转一维数组的命令将起始放到末尾,如下所示:
In: b[::-1]
Out:
array([[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]],
[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]]])刚刚发生了什么?
我们使用几种不同的方法对多维 NumPy 数组进行了切片。 该示例的代码可以在本书代码捆绑中的slicing.py文件中找到。
实战时间 – 处理数组形状
我们已经了解了reshape()函数。 另一个重复执行的任务是将数组展平。 展平多维 NumPy 数组时,结果是具有相同数据的一维数组。
展开(ravel):使用ravel()函数完成:
In: b
Out:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
In: b.ravel()
Out:
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23])展开(flatten):适当的命名函数flatten()与ravel()相同,但flatten()总是分配新的内存,而ravel()可能会返回数组的视图。 视图是共享数组的一种方法,但是您需要对视图小心 ,因为修改视图会影响基础数组,因此会影响其他视图。 数组副本更安全; 但是,它使用更多的内存:
In: b.flatten()
Out:
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23])使用元组设置形状:除了reshape()函数外,我们还可以直接使用元组设置形状,如下所示:
In: b.shape = (6,4)
In: b
Out:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]])如您所见,这将直接更改数组。 现在,我们有了一个六乘四的数组。
转置:在线性代数中,转置矩阵很常见。
注意
线性代数是数学的一个分支,其中涉及矩阵。 矩阵是向量的二维等效项,并且包含矩形或正方形网格中的数字。 转置矩阵需要以使矩阵行变为矩数组的方式翻转矩阵,反之亦然。 可汗学院开设了关于线性代数的课程,其中包括矩阵中的转置矩阵。
我们也可以使用以下代码来做到这一点:
In: b.transpose()
Out:
array([[ 0, 4, 8, 12, 16, 20],
[ 1, 5, 9, 13, 17, 21],
[ 2, 6, 10, 14, 18, 22],
[ 3, 7, 11, 15, 19, 23]])调整大小:resize()方法的作用与reshape()函数相同,但是修改了它在数组上执行的操作:
In: b.resize((2,12))
In: b
Out:
array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]])刚刚发生了什么?
我们使用ravel()函数,flatten()函数,reshape()函数和resize()方法操纵 NumPy 数组的形状,如下表所示:
函数 | 描述 |
|---|---|
ravel() | 此函数返回一维数组,其数据与输入数组相同,并不总是返回副本 |
flatten() | 这是ndarray的方法,它会展平数组并始终返回数组的副本 |
reshape() | 此函数修改数组的形状 |
resize() | 此函数更改数组的形状,并在必要时添加输入数组的副本 |
该示例的代码在本书代码捆绑的shapemanipulation.py文件中。
堆叠
数组可以水平,深度或垂直堆叠。 为此,我们可以使用vstack(),dstack(),hstack(),column_stack(),row_stack()和concatenate()函数。
实战时间 – 堆叠数组
首先,设置一些数组:
In: a = arange(9).reshape(3,3)
In: a
Out:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
In: b = 2 * a
In: b
Out:
array([[ 0, 2, 4],
[ 6, 8, 10],
[12, 14, 16]])水平堆叠:从水平堆叠开始,形成一个ndarray对象的元组,并将其提供给hstack()函数,如下所示:
In: hstack((a, b))
Out:
array([[ 0, 1, 2, 0, 2, 4],
[ 3, 4, 5, 6, 8, 10],
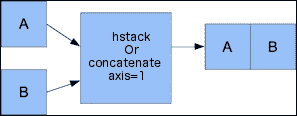
[ 6, 7, 8, 12, 14, 16]])使用concatenate()函数可以达到以下效果(此处的axis参数等效于笛卡尔坐标系中的轴,并且对应于数组尺寸):
In: concatenate((a, b), axis=1)
Out:
array([[ 0, 1, 2, 0, 2, 4],
[ 3, 4, 5, 6, 8, 10],
[ 6, 7, 8, 12, 14, 16]])此图显示了concatenate()函数的水平堆叠:
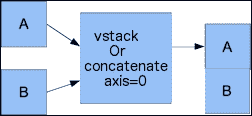
垂直堆叠:通过垂直堆叠,再次形成元组。 这次,它被赋予vstack()函数,如下所示:
In: vstack((a, b))
Out:
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 0, 2, 4],
[ 6, 8, 10],
[12, 14, 16]])concatenate()函数在将轴设置为 0 时产生相同的结果。这是axis参数的默认值:
In: concatenate((a, b), axis=0)
Out:
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 0, 2, 4],
[ 6, 8, 10],
[12, 14, 16]])下图显示了具有concatenate()函数的垂直堆叠:
深度堆叠:另外,使用dstack()和元组的深度堆叠,沿第三个轴(深度)堆叠了数组的列表。 例如,将图像数据的二维数组彼此堆叠在一起:
In: dstack((a, b))
Out:
array([[[ 0, 0],
[ 1, 2],
[ 2, 4]],
[[ 3, 6],
[ 4, 8],
[ 5, 10]],
[[ 6, 12],
[ 7, 14],
[ 8, 16]]])列堆叠:使用column_stack()函数按列将一维数组堆叠如下:
In: oned = arange(2)
In: oned
Out: array([0, 1])
In: twice_oned = 2 * oned
In: twice_oned
Out: array([0, 2])
In: column_stack((oned, twice_oned))
Out:
array([[0, 0],
[1, 2]])二维数组以hstack()的方式堆叠:
In: column_stack((a, b))
Out:
array([[ 0, 1, 2, 0, 2, 4],
[ 3, 4, 5, 6, 8, 10],
[ 6, 7, 8, 12, 14, 16]])
In: column_stack((a, b)) == hstack((a, b))
Out:
array([[ True, True, True, True, True, True],
[ True, True, True, True, True, True],
[ True, True, True, True, True, True]], dtype=bool)是的,您猜对了! 我们用==运算符比较了两个数组。
注意
==运算符用于比较 Python 对象是否相等。 当应用于 NumPy 数组时,运算符将执行逐元素比较。 有关 Python 比较运算符的更多信息,请查看这里。
行堆叠:NumPy 当然也具有执行行堆叠的函数。 它称为row_stack(),对于一维数组,它只是将行中的数组堆叠为二维数组:
In: row_stack((oned, twice_oned))
Out:
array([[0, 1],
[0, 2]])二维数组的row_stack()函数结果等于vstack()函数结果:
In: row_stack((a, b))
Out:
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 0, 2, 4],
[ 6, 8, 10],
[12, 14, 16]])
In: row_stack((a,b)) == vstack((a, b))
Out:
array([[ True, True, True],
[ True, True, True],
[ True, True, True],
[ True, True, True],
[ True, True, True],
[ True, True, True]], dtype=bool)刚刚发生了什么?
我们水平,深度和垂直堆叠数组。 我们使用了vstack(),dstack(),hstack(),column_stack(),row_stack()和concatenate()函数,如下表所示:
| 函数 | 描述 | | --- | --- | | `vstack()` | 此函数垂直堆叠数组 | | `dstack()` | 此函数沿第三轴深度堆叠数组 | | `hstack()` | 此函数水平堆叠数组 | | `column_stack()` | 此函数将一维数组堆叠为列以创建二维数组 | | `row_stack()` | 此函数垂直堆叠数组 | | `concatenate()` | 此函数连接数组的列表或元组 |
此示例的代码在本书的代码包的stacking.py文件中。
分割
可以在垂直,水平或深度方向拆分数组。 涉及的函数是hsplit(),vsplit(),dsplit()和split()。 我们既可以拆分为相同形状的数组,也可以指示拆分之后应该发生的位置。
实战时间 – 分割数组
以下步骤演示了数组的拆分:
水平分割:随后的代码将数组沿水平轴分割为三个大小和形状相同的片段:
In: a
Out:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
In: hsplit(a, 3)
Out:
[array([[0],
[3],
[6]]),
array([[1],
[4],
[7]]),
array([[2],
[5],
[8]])]将它与带有附加参数axis=1的split()函数调用进行比较:
In: split(a, 3, axis=1)
Out:
[array([[0],
[3],
[6]]),
array([[1],
[4],
[7]]),
array([[2],
[5],
[8]])]垂直分割:vsplit()沿垂直轴分割:
In: vsplit(a, 3)
Out: [array([[0, 1, 2]]), array([[3, 4, 5]]), array([[6, 7, 8]])]split()函数和axis=0也沿垂直轴分割:
In: split(a, 3, axis=0)
Out: [array([[0, 1, 2]]), array([[3, 4, 5]]), array([[6, 7, 8]])]深度分割:dsplit()函数毫不奇怪地是深度拆分。 分割前先创建一个排列为 3 的数组:
In: c = arange(27).reshape(3, 3, 3)
In: c
Out:
array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]],
[[18, 19, 20],
[21, 22, 23],
[24, 25, 26]]])
In: dsplit(c, 3)
Out:
[array([[[ 0],
[ 3],
[ 6]],
[[ 9],
[12],
[15]],
[[18],
[21],
[24]]]),
array([[[ 1],
[ 4],
[ 7]],
[[10],
[13],
[16]],
[[19],
[22],
[25]]]),
array([[[ 2],
[ 5],
[ 8]],
[[11],
[14],
[17]],
[[20],
[23],
[26]]])]刚刚发生了什么?
我们使用hsplit(),vsplit(),dsplit()和split()函数拆分数组。 这些功能拆分的轴是不同的。 该示例的代码在本书代码捆绑的splitting.py文件中。
数组属性
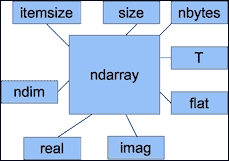
除了shape,和dtype属性外,ndarray还有许多其他属性,如下表所示:
ndim属性提供了维度数:
In: b
Out:
array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]])
In: b.ndim
Out: 2size属性包含元素数。 如下所示:
In: b.size
Out: 24itemsize属性提供数组中每个元素的字节数:
In: b.itemsize
Out: 8如果需要数组所需的字节总数,可以查看nbytes。 这只是itemsize和size属性的乘积:
In: b.nbytes
Out: 192
In: b.size * b.itemsize
Out: 192T属性具有transpose()函数的相同效果,如下所示:
In: b.resize(6,4)
In: b
Out:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]])
In: b.T
Out:
array([[ 0, 4, 8, 12, 16, 20],
[ 1, 5, 9, 13, 17, 21],
[ 2, 6, 10, 14, 18, 22],
[ 3, 7, 11, 15, 19, 23]])如果数组的等级低于 2,我们将只获得数组的视图:
In: b.ndim
Out: 1
In: b.T
Out: array([0, 1, 2, 3, 4])NumPy 中的复数用j.表示。例如,创建具有复数的数组,如以下代码所示:
In: b = array([1.j + 1, 2.j + 3])
In: b
Out: array([ 1.+1.j, 3.+2.j])real属性为我们提供了数组的实部,或者如果数组仅包含实数,则为数组本身:
In: b.real
Out: array([ 1., 3.])imag属性包含数组的虚部:
In: b.imag
Out: array([ 1., 2.])如果数组包含复数,则数据类型也将自动变为复数:
In: b.dtype
Out: dtype('complex128')
In: b.dtype.str
Out: '<c16'flat属性返回一个numpy.flatiter对象。 这是获取flatiter的唯一方法-我们无权访问flatiter构造器。 平面迭代器使我们能够像遍历平面数组一样遍历数组,如以下示例所示:
In: b = arange(4).reshape(2,2)
In: b
Out:
array([[0, 1],
[2, 3]])
In: f = b.flat
In: f
Out: <numpy.flatiter object at 0x103013e00>
In: for item in f: print item
.....:
0
1
2
3可以直接通过flatiter对象获取元素:
In: b.flat[2]
Out: 2并且,还可以直接获取多个元素:
In: b.flat[[1,3]]
Out: array([1, 3])flat属性是可设置的。 设置flat属性的值会导致覆盖整个数组的值:
In: b.flat = 7
In: b
Out:
array([[7, 7],
[7, 7]])或者,它也可能导致覆盖所选元素的值:
In: b.flat[[1,3]] = 1
In: b
Out:
array([[7, 1],
[7, 1]])下图显示了ndarray类的不同类型的属性:
实战时间 – 转换数组
使用tolist()函数将 NumPy 数组转换为 Python 列表:
转换为列表:
In: b
Out: array([ 1.+1.j, 3.+2.j])
In: b.tolist()
Out: [(1+1j), (3+2j)]函数astype()将数组转换为指定类型的数组:
In: b
Out: array([ 1.+1.j, 3.+2.j])
In: b.astype(int)
/usr/local/bin/ipython:1: ComplexWarning: Casting complex values to real discards the imaginary part
#!/usr/bin/python
Out: array([1, 3])注意
从 NumPy 复杂类型(而不是普通的 Python 版本)转换为int时,我们将丢失虚部。 astype()函数还接受类型名称作为字符串。
In: b.astype('complex')
Out: array([ 1.+1.j, 3.+2.j])这次我们不会显示任何警告,因为我们使用了正确的数据类型。
刚刚发生了什么?
我们将 NumPy 数组转换为列表和不同数据类型的数组。 该示例的代码在本书代码捆绑的arrayconversion.py文件中。
总结
在本章中,您学习了很多有关 NumPy 的基础知识:数据类型和数组。 数组有几个描述它们的属性。 您了解到这些属性之一是数据类型,在 NumPy 中,数据类型由完整的对象表示。
就像 Python 列表一样,可以以高效的方式对 NumPy 数组进行切片和索引。 NumPy 数组具有处理多个维度的附加功能。
数组的形状可以通过多种方式进行操作-堆叠,调整大小,调整形状和拆分。 本章演示了许多用于形状处理的便捷函数。
了解了基础知识之后,是时候进入第 3 章,“熟悉常用函数”了,其中包括了基本函数。 统计和数学函数。
三、熟悉常用函数
在本章中,我们将介绍常见的 NumPy 函数。 特别是,我们将通过一个涉及历史股价的示例来学习如何从文件加载数据。 此外,我们还将了解 NumPy 的基本数学和统计函数。
我们将学习如何读写文件。 此外,我们还将品尝 NumPy 中的函数式编程和线性代数的可能性。
在本章中,我们将涵盖以下主题:
- 数组上的函数
- 从文件加载数组
- 将数组写入文件
- 简单的数学和统计函数
文件 I/O
首先,我们将学习如何使用 NumPy 进行文件 I/O。 数据通常存储在文件中。 如果您无法读取和写入文件,您将走不远。
实战时间 – 读写文件
作为文件 I/O 的示例,我们将创建一个单位矩阵并将其内容存储在文件中。
注意
在本章和其他章中,我们将按照约定使用以下行导入 NumPy:
import numpy as np
请执行以下步骤:
可以使用eye()函数创建单位矩阵。 我们需要给eye()函数的唯一参数是个数。 因此,例如对于一个二乘二的矩阵,编写以下代码:
i2 = np.eye(2)
print(i2)输出为:
[[ 1\. 0.]
[ 0\. 1.]]使用savetxt()函数将数据保存在纯文本文件中。 指定我们要在其中保存数据的文件的名称以及包含数据本身的数组:
np.savetxt("eye.txt", i2)应该在与 Python 脚本相同的目录中创建名为eye.txt的文件。
刚刚发生了什么?
读写文件是数据分析的必要技能。 我们使用savetxt()写入文件。 我们使用eye()函数制作了一个单位矩阵。
注意
除了文件名,我们还可以提供文件句柄。 文件句柄是许多编程语言中的术语,它表示指向文件的变量,例如邮政地址。 有关如何在 Python 中获取文件句柄的更多信息,请参考这里。
您可以自己检查内容是否符合预期。 可以从图书支持网站下载此示例的代码(请参阅save.py)。
import numpy as np
i2 = np.eye(2)
print(i2)
np.savetxt("eye.txt", i2))逗号分隔值文件
经常遇到逗号分隔值(CSV)格式的文件。 通常,CSV 文件只是数据库中的转储。 通常,CSV 文件中的每个字段都对应一个数据库表列。 众所周知,电子表格程序(例如 Excel)也可以生成 CSV 文件。
实战时间 – 从 CSV 文件加载
我们如何处理 CSV 文件? 幸运的是,loadtxt()函数可以方便地读取 CSV 文件,拆分字段并将数据加载到 NumPy 数组中。 在以下示例中,我们将加载苹果(公司而不是水果)的历史股价数据。 数据为 CSV 格式,是本书代码集的一部分。 第一列包含一个标识股票的符号。 在我们的情况下,它是AAPL。 第二个是dd-mm-yyyy格式的日期。 第三列为空。 然后,依次获得开盘价,最高价,最低价和收盘价。 最后但并非最不重要的是当天的交易量。 这是一行的样子:
AAPL,28-01-2011, ,344.17,344.4,333.53,336.1,21144800目前,我们仅对收盘价和交易量感兴趣。 在前面的示例中,将是336.1和21144800。 将收盘价和成交量存储在两个数组中,如下所示:
c,v=np.loadtxt('data.csv', delimiter=',', usecols=(6,7), unpack=True)如您所见,数据存储在data.csv文件中。 由于我们正在处理 CSV 文件,因此已将定界符设置为(comma)。 通过元组设置usecols参数以获得与收盘价和交易量相对应的第七和第八字段。 unpack参数设置为True,这意味着数据将被解包并分配给分别保持收盘价和交易量的c和v变量。
交易量加权平均价格
交易量加权平均价格(VWAP)在金融中非常重要。 它代表金融资产的平均价格(请参阅 https://www.khanacademy.org/math/probability/descriptive-statistics/old-stats-videos/ v / statistics-the-average )。 的数量越大,价格走势通常越明显。 VWAP 通常用于算法交易中,并使用交易量值作为权重进行计算。
实战时间 – 计算交易量加权平均价格
以下是我们将要采取的行动:
将数据读入数组。
计算 VWAP:
from __future__ import print_function
import numpy as np
c,v=np.loadtxt('data.csv', delimiter=',', usecols=(6,7), unpack=True)
vwap = np.average(c, weights=v)
print("VWAP =", vwap)输出如下:
VWAP = 350.589549353刚刚发生了什么?
那不是很难,不是吗? 我们只是调用了average()函数,并将其weights参数设置为将v数组用于权重。 顺便说一下,NumPy 还具有计算算术平均值的函数。 这是所有权重均等于1的未加权平均值。
mean()函数
mean()函数是相当友好,并不是那么卑鄙。 此函数计算数组的算术平均值。
注意
的算术平均值是由以下公式给出的 :
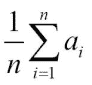
它对数组a中的值求和,然后将总和除以元素数n。
让我们看看它的运行情况 :
print("mean =", np.mean(c))结果,我们得到以下打印输出:
mean = 351.037666667时间加权平均价格
在金融领域,**时间加权平均价格(TWAP)**是另一种平均价格指标。 现在,我们也计算 TWAP。 这实际上只是一个主题的变体。 这个想法是,最近的报价更为重要,因此我们应该给近期的价格赋予更大的权重。 最简单的方法是使用arange()函数创建一个数组,该函数将值从零增加到收盘价数组中的元素数量。 这不一定是正确的方法。 实际上,本书中有关股票价格分析的大多数示例只是说明性的。 以下是 TWAP 代码:
t = np.arange(len(c))
print("twap =", np.average(c, weights=t))它产生以下输出:
twap = 352.428321839TWAP 甚至高于平均值。
小测验 - 计算加权平均值
Q1. 哪个函数返回数组的加权平均值?
weighted_averagewaverageaverageavg
勇往直前 – 计算其他平均值
尝试使用开盘价进行相同的计算。 计算数量和其他价格的平均值。
值的范围
通常,我们不仅希望知道中间值的一组值的平均值或算术平均值,还希望知道极端值,整个范围(最高和最低值) 。 我们在此处使用的样本数据每天已经具有这些值-高价和低价。 但是,我们需要知道高价的最高价和低价的最低价。
实战时间 – 找到最高和最低值
min()和max()函数是我们要求的答案。 执行以下步骤以找到最高和最低值:
首先,再次阅读我们的文件,并将高价和低价的值存储到数组中:
h,l=np.loadtxt('data.csv', delimiter=',', usecols=(4,5), unpack=True)唯一更改的是usecols参数,因为高价和低价位于不同的列中。
以下代码获取价格范围:
print("highest =", np.max(h))
print("lowest =", np.min(l))这些是返回的值:
highest = 364.9
lowest = 333.53现在,很容易获得中点,因此留给您练习。
NumPy 允许我们使用名为ptp()的函数来计算数组的传播。 ptp()函数返回数组的最大值和最小值之间的差。 换句话说,它等于max(array) - min(array)。 调用ptp()函数:
print("Spread high price", np.ptp(h))
print("Spread low price", np.ptp(l))您将看到以下文本:
Spread high price 24.86
Spread low price 26.97刚刚发生了什么?
我们为价格定义了最高到最低值的范围。 通过将max()函数应用于高价数组,可以得出最高值。 同样,通过将min()函数调用到低价数组可以找到最低值。 我们还使用ptp()函数计算了峰峰距离:
from __future__ import print_function
import numpy as np
h,l=np.loadtxt('data.csv', delimiter=',', usecols=(4,5), unpack=True)
print("highest =", np.max(h))
print("lowest =", np.min(l))
print((np.max(h) + np.min(l)) /2)
print("Spread high price", np.ptp(h))
print("Spread low price", np.ptp(l))统计
股票交易商对最可能的收盘价感兴趣。 常识认为,由于随机波动,当价格围绕均值波动时,这应该接近某种平均水平。 算术平均值和加权平均值是找到值分布中心的方法。 但是,它们都不健壮,并且都对异常值敏感。 Outliers是远大于或小于数据集中典型值的极值。 通常,异常值是由罕见现象或测量误差引起的。 例如,如果我们的收盘价为一百万美元,这将影响我们的计算结果。
实战时间 – 执行简单的统计
我们可以使用某种这种阈值来消除异常值,但是有更好的方法。 它被称为中位数,基本上是选取一组排序值的中间值。 数据的一半低于中位数,另一半高于中位数。 例如,如果我们具有值 1、2、3、4 和 5,则中位数将为 3,因为它位于中间。
这些是计算中位数的步骤:
创建一个新的 Python 脚本并将其命名为simplestats.py。 您已经知道如何将数据从 CSV 文件加载到数组中。 因此,复制该行代码并确保它仅获得收盘价。 代码应如下所示:
c=np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)对我们有用的函数称为median()。 我们将调用它并立即打印结果。 添加以下代码行:
print("median =", np.median(c))该程序将输出以下输出:
median = 352.055由于这是我们第一次使用median()函数,因此我们想检查一下是否正确。 显然,我们可以通过浏览文件并找到正确的值来做到这一点,但这并不有趣。 相反,我们将通过对收盘价数组进行排序并打印排序后的数组的中间值来模拟中值算法。 msort()函数为我们做第一部分。 调用该函数,存储排序后的数组,然后打印它:
sorted_close = np.msort(c)
print("sorted =", sorted_close)这将输出以下输出:

是的,它有效! 现在让我们获取排序数组的中间值:
N = len(c)
print "middle =", sorted[(N - 1)/2]上面的代码片段为我们提供了以下输出:
middle = 351.99嘿,那和median()函数给我们的值不同。 怎么会? 经过进一步调查,我们发现median()函数的返回值甚至没有出现在文件中。 甚至更陌生! 向 NumPy 团队提交错误之前,让我们看一下文档:
$ python
>>> import numpy as np
>>> help(np.median)这个谜题很容易解决。 事实证明,我们的朴素算法仅适用于奇数长度的数组。 对于偶数长度的数组,median是根据中间两个数组值的平均值计算得出的。 因此,键入以下代码:
print("average middle =", (sorted[N /2] + sorted[(N - 1) / 2]) / 2)This prints the following output:
average middle = 352.055我们关注的另一个统计指标是方差。 “方差”告诉我们变量的变化量。 在我们的案例中,它还告诉我们投资有多高风险,因为股价变化过大必然会给我们带来麻烦。
计算收盘价的方差(使用 NumPy,这只是一种方法):
print("variance =", np.var(c))这为我们提供了以下输出:
variance = 50.1265178889并不是说我们不信任 NumPy 或其他任何东西,而是让我们使用文档中的方差定义仔细检查。 请注意,此定义可能与您的统计书中的定义不同,但这在统计领域非常普遍。
注意
population variance定义为与平均值的偏差平方的平均值,除以数组中元素的数量:
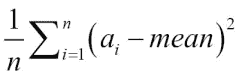
一些书告诉我们将数组中的元素数除以 1(这称为样本方差):
print("variance from definition =", np.mean((c - c.mean())**2))The output is as follows:
variance from definition = 50.1265178889刚刚发生了什么?
也许您注意到了一些新东西。 我们突然在c数组上调用了mean()函数。 是的,这是合法的,因为ndarray类具有mean()方法。 这是为了您的方便。 现在,请记住这是可能的。 此示例的代码可以在simplestats.py中找到:
from __future__ import print_function
import numpy as np
c=np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)
print("median =", np.median(c))
sorted = np.msort(c)
print("sorted =", sorted)
N = len(c)
print("middle =", sorted[(N - 1)/2])
print("average middle =", (sorted[N /2] + sorted[(N - 1) / 2]) / 2)
print("variance =", np.var(c))
print("variance from definition =", np.mean((c - c.mean())**2))股票收益
在学术文献中,更常见的是基于收盘价的股票收益和对数收益进行分析。 简单的回报就是从一个值到下一个值的变化率。 对数收益或对数收益是通过取所有价格的对数并计算它们之间的差来确定的。 在高中时,我们了解到:
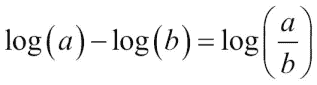
因此,对数返回还可以测量变化率。 收益是无量纲的,因为在除法操作中,我们将美元除以美元(或其他某种货币)。 无论如何,投资者最有可能对收益的方差或标准差感兴趣,因为这代表了风险。
实战时间 – 分析股票收益
执行以下步骤来分析股票收益:
首先,让我们计算简单的收益。 NumPy 具有diff()函数,该函数返回一个由两个连续数组元素之间的差构成的数组。 这有点像微积分中的差异(价格相对于时间的导数)。 要获得回报,我们还必须除以前一天的值。 但是我们必须小心。 diff()返回的数组比收盘价数组短一个元素。 经过仔细考虑,我们得到以下代码:
returns = np.diff( arr ) / arr[ : -1]注意,我们不使用除数中的最后一个值。 标准差等于方差的平方根。 使用std()函数计算标准差:
print("Standard deviation =", np.std(returns))结果为以下输出:
Standard deviation = 0.0129221344368对数收益率或对数收益率甚至更容易计算。 使用log()函数获取收盘价的自然对数,然后在结果上释放diff()函数:
logreturns = np.diff(np.log(c))通常,我们必须检查输入数组没有零或负数。 如果是这样,我们将得到一个错误。 但是,股价始终是正数,因此我们不必检查。
我们很可能会对回报为正的日子感兴趣。 在当前设置中,我们可以使用where()函数获得下一个最好的结果,该函数返回满足条件的数组的索引。 只需输入以下代码:
posretindices = np.where(returns > 0)
print("Indices with positive returns", posretindices)这为数组元素提供了多个索引,这些索引作为元组为正,可通过打印输出两侧的圆括号识别:
Indices with positive returns (array([ 0, 1, 4, 5, 6, 7, 9, 10, 11, 12, 16, 17, 18, 19, 21, 22, 23, 25, 28]),)在投资中,波动率衡量金融证券的价格变化。 历史波动率是根据历史价格数据计算得出的。 如果您想知道历史波动率(例如,年度或每月波动率),则对数收益很有趣。 年度波动率等于对数回报率的标准差,即其平均值的比率除以一年的营业日数的平方根,通常假设为 252。 使用std()和mean()函数进行计算,如以下代码所示:
annual_volatility = np.std(logreturns)/np.mean(logreturns)
annual_volatility = annual_volatility / np.sqrt(1./252.)
print(annual_volatility)请注意sqrt()函数中除法的 。 由于在 Python 中,整数除法与浮点除法的工作原理不同,因此我们需要使用浮点数来确保获得正确的结果。 以下代码类似地给出了每月波动率:
print("Monthly volatility", annual_volatility * np.sqrt(1./12.))刚刚发生了什么?
我们使用diff()函数计算了简单的股票收益,该函数计算了连续元素之间的差异。 log()函数计算数组元素的自然对数。 我们用它来计算对数收益。 在本节的最后,我们计算了年度和每月波动率(请参阅returns.py):
from __future__ import print_function
import numpy as np
c=np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)
returns = np.diff( c ) / c[ : -1]
print("Standard deviation =", np.std(returns))
logreturns = np.diff( np.log(c) )
posretindices = np.where(returns > 0)
print("Indices with positive returns", posretindices)
annual_volatility = np.std(logreturns)/np.mean(logreturns)
annual_volatility = annual_volatility / np.sqrt(1./252.)
print("Annual volatility", annual_volatility)
print("Monthly volatility", annual_volatility * np.sqrt(1./12.))日期
您有时星期一发烧吗?还是星期五发烧? 有没有想过股市是否会遭受这些现象的困扰? 好吧,我认为这当然值得广泛研究。
实战时间 – 处理日期
首先,我们将读取收盘价数据。 其次,我们将根据星期几来划分价格。 第三,我们将针对每个工作日计算平均价格。 最后,我们将找出一周中哪一天的平均数最高,而哪一天的平均数最低。 在我们开始之前提请您注意:您可能会倾向于使用结果在一天中购买股票而在另一天出售。 但是,我们没有足够的数据来做出这种决定。
程序员讨厌日期,因为它们是如此复杂! NumPy 非常面向浮点运算。 因此,我们需要付出更多的努力来处理日期。 自己尝试一下; 将以下代码放入脚本中或使用本书随附的脚本:
dates, close=np.loadtxt('data.csv', delimiter=',',
usecols=(1,6), unpack=True)执行脚本,将出现以下错误:
ValueError: invalid literal for float(): 28-01-2011现在,执行以下步骤来处理日期:
显然,NumPy 试图将日期转换为浮点数。 我们要做的是明确告诉 NumPy 如何转换日期。 为此,loadtxt()函数具有一个特殊的参数。 该参数称为“转换器”,是将列与所谓的转换器函数链接在一起的字典。 编写转换器函数是我们的责任。 写下函数:
# Monday 0
# Tuesday 1
# Wednesday 2
# Thursday 3
# Friday 4
# Saturday 5
# Sunday 6
def datestr2num(s):
return datetime.datetime.strptime(s, "%d-%m-%Y").date().weekday()我们将datestr2num()函数日期指定为字符串,例如28-01-2011。 首先使用指定的格式%d-%m-%Y将字符串转换为datetime对象。 顺便说一下,这是标准的 Python,与 NumPy 本身无关。 其次, datetime对象变成一天。 最后,在日期上调用工作日方法以返回数字。 如您在注释中所读,数字是介于 0 和 6 之间。0 是例如星期一,6 是星期日。 当然,实际数字对于我们的算法并不重要; 它仅用作标识。
现在,连接我们的日期转换器函数:
dates, close=np.loadtxt('data.csv', delimiter=',', usecols=(1,6), converters={1: datestr2num}, unpack=True)
print "Dates =", datesThis prints the following output:
Dates = [ 4\. 0\. 1\. 2\. 3\. 4\. 0\. 1\. 2\. 3\. 4\. 0\. 1\. 2\. 3\. 4\. 1\. 2\. 4\. 0\. 1\. 2\. 3\. 4\. 0\. 1\. 2\. 3\. 4.]如您所见,没有星期六和星期日。 周末不开放交易。
现在,我们将制作一个数组,其中每个星期的每一天都有五个元素。 将数组的值初始化为0:
averages = np.zeros(5)该数组将保存每个工作日的平均值。
我们已经了解了where函数,该函数返回符合指定条件的元素的数组索引。 take()函数可以使用这些索引并获取相应数组项的值。 我们将使用take()函数来获取每个工作日的收盘价。 在下面的循环中,我们遍历日期值 0 到 4,也就是星期一至星期五。 我们每天都使用where()函数获取索引,并将其存储在indices数组中。 然后,我们使用take()函数检索与索引相对应的值。 最后,计算每个工作日的平均值并将其存储在“ averages”数组中,如下所示:
for i in range(5):
indices = np.where(dates == i)
prices = np.take(close, indices)
avg = np.mean(prices)
print("Day", i, "prices", prices, "Average", avg)
averages[i] = avg该循环显示以下输出:
Day 0 prices [[ 339.32 351.88 359.18 353.21 355.36]] Average 351.79
Day 1 prices [[ 345.03 355.2 359.9 338.61 349.31 355.76]] Average 350.635
Day 2 prices [[ 344.32 358.16 363.13 342.62 352.12 352.47]] Average 352.136666667
Day 3 prices [[ 343.44 354.54 358.3 342.88 359.56 346.67]] Average 350.898333333
Day 4 prices [[ 336.1 346.5 356.85 350.56 348.16 360\. 351.99]] Average 350.022857143如果需要,可以继续进行操作,找出哪一天的平均值最高,哪一天最低。 但是,使用max()和min()函数很容易找到它,如下所示:
top = np.max(averages)
print("Highest average", top)
print("Top day of the week", np.argmax(averages))
bottom = np.min(averages)
print("Lowest average", bottom)
print("Bottom day of the week", np.argmin(averages))The output is as follows:
Highest average 352.136666667
Top day of the week 2
Lowest average 350.022857143
Bottom day of the week 4刚刚发生了什么?
argmin()函数返回averages数组中最小值的索引。 返回的索引为4,它对应于星期五。 argmax()函数返回averages数组中最大值的索引。 返回的索引为2,它对应于星期三(请参阅weekdays.py):
from __future__ import print_function
import numpy as np
from datetime import datetime
## Monday 0
## Tuesday 1
## Wednesday 2
## Thursday 3
## Friday 4
## Saturday 5
## Sunday 6
def datestr2num(s):
return datetime.strptime(s, "%d-%m-%Y").date().weekday()
dates, close=np.loadtxt('data.csv', delimiter=',', usecols=(1,6), converters={1: datestr2num}, unpack=True)
print("Dates =", dates)
averages = np.zeros(5)
for i in range(5):
indices = np.where(dates == i)
prices = np.take(close, indices)
avg = np.mean(prices)
print("Day", i, "prices", prices, "Average", avg)
averages[i] = avg
top = np.max(averages)
print("Highest average", top)
print("Top day of the week", np.argmax(averages))
bottom = np.min(averages)
print("Lowest average", bottom)
print("Bottom day of the week", np.argmin(averages))勇往直前 – 查看 VWAP 和 TWAP
嘿,那很有趣! 对于样本数据,似乎星期五是最便宜的一天,而星期三是您的苹果股票最值钱的一天。 忽略我们只有很少的数据这一事实,有没有更好的方法来计算平均值? 我们是否也应该涉及体积数据? 进行时间加权平均可能对您更有意义。 搏一搏! 计算 VWAP 和 TWAP。 您可以在本章开始时找到一些有关如何执行此操作的提示。
实战时间 – 使用datetime64数据类型
在 NumPy 1.7.0 中引入了datetime64数据类型。
要了解datetime64数据类型,请启动 Python Shell 并导入 NumPy,如下所示:
$ python
>>> import numpy as np从字符串创建datetime64 (如果愿意,可以使用其他日期):
>>> np.datetime64('2015-04-22')
numpy.datetime64('2015-04-22')在上述代码中,我们为 2015 年 4 月 22 日(恰好是地球日)创建了datetime64。 我们使用YYYY-MM-DD格式,其中Y表示年份,M表示月份,D表示月份的日期。 NumPy 使用 ISO 8601 标准。 这是代表日期和时间的国际标准。 ISO 8601 允许使用YYYY-MM-DD,YYYY-MM和YYYYMMDD格式。 检查自己,如下所示:
>>> np.datetime64('2015-04-22')
numpy.datetime64('2015-04-22')
>>> np.datetime64('2015-04')
numpy.datetime64('2015-04')默认情况下,ISO 8601 使用本地时区。 可以使用格式T[hh:mm:ss]指定时间。 例如,定义 1677 年 1 月 1 日晚上 8:19。 如下:
>>> local = np.datetime64('1677-01-01T20:19')
>>> local
numpy.datetime64('1677-01-01T20:19Z')此外,格式为hh:mm的字符串指定相对于 UTC 时区的偏移量。 创建具有9小时偏移的datetime64,如下所示:
>>> with_offset = np.datetime64('1677-01-01T20:19-0900')
>>> with_offset
numpy.datetime64('1677-01-02T05:19Z')最后的Z代表 Zulu 时间,有时也称为 UTC。
彼此减去两个datetime64对象:
>>> local - with_offset
numpy.timedelta64(-540,'m')减法创建一个 NumPy timedelta64对象,在这种情况下,该对象指示540分钟的差异。 我们还可以为datetime64对象增加或减少天数。 例如,2015 年 4 月 22 日恰好是星期三。 使用arange()函数,创建一个数组,该数组包含从 2015 年 4 月 22 日到 2015 年 5 月 22 日的所有星期三:
>>> np.arange('2015-04-22', '2015-05-22', 7, dtype='datetime64')
array(['2015-04-22', '2015-04-29', '2015-05-06', '2015-05-13', '2015-05-20'], dtype='datetime64[D]')请注意,在这种情况下,必须指定dtype参数,否则 NumPy 认为我们正在处理字符串。
刚刚发生了什么?
我们了解了 NumPy datetime64类型。 这种数据类型使我们可以轻松地操纵日期和时间。 它的功能包括简单的算术运算和使用常规 NumPy 函数创建数组。
每周汇总
我们在先前的“实战时间”部分中使用的数据是当天结束的数据。 本质上,它是根据某一天的贸易数据汇总的汇总数据。 如果您对市场感兴趣并且拥有数十年的数据,则可能希望进一步汇总和压缩数据。 让我们总结一下苹果股票的数据以给我们每周的摘要。
实战时间 – 汇总数据
我们将汇总的数据将用于整个工作周,从星期一到星期五。 在数据覆盖的期间内,总统日 2 月 21 日有一个假期。 碰巧是星期一,美国证券交易所在这一天关闭。 结果,样本中没有这一天的输入。 样本的第一天是星期五,这很不方便。 使用以下说明汇总数据:
为简化起见,只需看一下样本中的前三周,以后便可以进行改进:
close = close[:16]
dates = dates[:16]我们将基于前面的“实战时间”部分的代码。
开始,我们将在示例数据中找到第一个星期一。 回想一下,星期一在 Python 中的代码为0。 这就是我们在where()函数中的条件。 然后,我们将需要提取索引为0的第一个元素。 结果将是一个多维数组。 使用ravel()函数将其展平:
# get first Monday
first_monday = np.ravel(np.where(dates == 0))[0]
print("The first Monday index is", first_monday)这将打印以下输出:
The first Monday index is 1下一步的逻辑步骤是在样本中的上一个星期五之前找到星期五。 逻辑类似于查找第一个星期一的逻辑,星期五的代码为 4。 此外,我们正在寻找索引为 2 的倒数第二个元素:
# get last Friday
last_friday = np.ravel(np.where(dates == 4))[-2]
print("The last Friday index is", last_friday)这将为我们提供以下输出:
The last Friday index is 15接下来,创建一个包含三个星期中所有天的索引的数组:
weeks_indices = np.arange(first_monday, last_friday + 1)
print("Weeks indices initial", weeks_indices)使用split()函数将数组拆分为大小为5的片段:
weeks_indices = np.split(weeks_indices, 3)
print("Weeks indices after split", weeks_indices)这将数组拆分如下:
Weeks indices after split [array([1, 2, 3, 4, 5]), array([ 6, 7, 8, 9, 10]), array([11, 12, 13, 14, 15])]在 NumPy 中,数组尺寸称为轴。 现在,我们将使用apply_along_axis()函数。 该函数调用我们将提供的另一个函数,以对数组的每个元素进行操作。 当前,我们有一个包含三个元素的数组。 每个数组项对应于我们样本中的一个星期,并包含相应项的索引。 通过提供我们的函数名称summarize()来调用apply_along_axis()函数,我们将在稍后对其进行定义。 此外,指定轴或尺寸号(例如1),要操作的数组以及summarize()函数的可变参数个数(如果有):
weeksummary = np.apply_along_axis(summarize, 1, weeks_indices, open, high, low, close)
print("Week summary", weeksummary)对于每周,summarize()函数会返回一个元组,该元组包含一周的开盘价,最高价,最低价和收盘价,类似于日末数据:
def summarize(a, o, h, l, c):
monday_open = o[a[0]]
week_high = np.max( np.take(h, a) )
week_low = np.min( np.take(l, a) )
friday_close = c[a[-1]]
return("APPL", monday_open, week_high, week_low, friday_close)注意,我们使用take()函数从索引中获取实际值。 使用max()和min()函数可以轻松计算一周的高值和低值。 周中营业时间是一周中第一天(周一)营业。 同样,收盘价是一周中最后一天(周五)的收盘价:
Week summary [['APPL' '335.8' '346.7' '334.3' '346.5']
['APPL' '347.89' '360.0' '347.64' '356.85']
['APPL' '356.79' '364.9' '349.52' '350.56']]使用 NumPy savetxt()函数将数据存储在文件中:
np.savetxt("weeksummary.csv", weeksummary, delimiter=",", fmt="%s")如您所见,已经指定了文件名,我们要存储的数组,定界符(在本例中为逗号)以及我们要在其中存储浮点数的格式。
格式字符串以百分号开头。 第二个是可选标志。 —flag表示左对齐,0表示左填充为零,+表示以+或-开头。 第三是可选宽度。 宽度表示最小字符数。 第四,点后跟与精度相关的数字。 最后,有一个字符说明符。 在我们的示例中,字符说明符是字符串。 字符代码描述如下:
|
字符码
|
描述
|
| — | — |
| c | 字符 |
| d或i | 有符号十进制整数 |
| e或E | e或E的科学记数法。 |
| f | 十进制浮点数 |
| g,G | 使用e,E或f中的较短者 |
| o | 八进制 |
| s | 字符串 |
| u | 无符号十进制整数 |
| x,X | 无符号十六进制整数 |
在您喜欢的编辑器中查看生成的文件,或在命令行中键入:
$ cat weeksummary.csv
APPL,335.8,346.7,334.3,346.5
APPL,347.89,360.0,347.64,356.85
APPL,356.79,364.9,349.52,350.56刚刚发生了什么?
我们做了某些编程语言甚至无法做到的事情。 我们定义了一个函数,并将其作为参数传递给apply_along_axis()函数。
注意
这里描述的编程范例称为函数式编程。 您可以在这个页面上阅读有关 Python 中函数式编程的更多信息。
apply_along_axis()的函数巧妙地传递了summarize()函数的参数(请参见weeksummary.py):
from __future__ import print_function
import numpy as np
from datetime import datetime
## Monday 0
## Tuesday 1
## Wednesday 2
## Thursday 3
## Friday 4
## Saturday 5
## Sunday 6
def datestr2num(s):
return datetime.strptime(s, "%d-%m-%Y").date().weekday()
dates, open, high, low, close=np.loadtxt('data.csv', delimiter=',', usecols=(1, 3, 4, 5, 6), converters={1: datestr2num}, unpack=True)
close = close[:16]
dates = dates[:16]
## get first Monday
first_monday = np.ravel(np.where(dates == 0))[0]
print("The first Monday index is", first_monday)
## get last Friday
last_friday = np.ravel(np.where(dates == 4))[-1]
print("The last Friday index is", last_friday)
weeks_indices = np.arange(first_monday, last_friday + 1)
print("Weeks indices initial", weeks_indices)
weeks_indices = np.split(weeks_indices, 3)
print("Weeks indices after split", weeks_indices)
def summarize(a, o, h, l, c):
monday_open = o[a[0]]
week_high = np.max( np.take(h, a) )
week_low = np.min( np.take(l, a) )
friday_close = c[a[-1]]
return("APPL", monday_open, week_high, week_low, friday_close)
weeksummary = np.apply_along_axis(summarize, 1, weeks_indices, open, high, low, close)
print("Week summary", weeksummary)
np.savetxt("weeksummary.csv", weeksummary, delimiter=",", fmt="%s")勇往直前 – 改进代码
更改代码以处理假期。 计时代码以查看由于apply_along_axis()而导致的加速有多大。
平均真实范围
平均真实范围(ATR)是衡量股票价格波动的技术指标。 ATR 计算不再重要,但将作为几个 NumPy 函数(包括maximum()函数)的示例。
实战时间 – 计算平均真实范围
要计算 ATR,请执行以下步骤 :
ATR 基于N天(通常是最近 20 天)的低价和高价。
N = 5
h = h[-N:]
l = l[-N:]我们还需要知道前一天的收盘价:
previousclose = c[-N -1: -1]对于每一天,我们计算以下内容:
每日范围-最高价和最低价之差:
h – l最高价和上一个收盘价之间的区别:
h – previousclose前一个收盘价与低价之间的差异:
previousclose – lmax()函数返回数组的最大值。 基于这三个值,我们计算出所谓的真实范围,即这些值的最大值。 现在,我们对跨数组的元素方式的最大值感兴趣,这意味着数组中第一个元素的最大值,数组中第二个元素的最大值,依此类推。 为此,请使用 NumPy maximum()函数而不是max()函数:
truerange = np.maximum(h - l, h - previousclose, previousclose - l)创建一个大小为N的atr数组,并将其值初始化为0:
atr = np.zeros(N)数组的第一个值就是truerange数组的平均值:
atr[0] = np.mean(truerange)使用以下公式计算其他值:
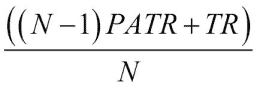
在此,PATR 是前一天的 ATR; TR 是真实范围:
for i in range(1, N):
atr[i] = (N - 1) * atr[i - 1] + truerange[i]
atr[i] /= N刚刚发生了什么?
我们形成了三个数组,分别用于三个范围-每日范围,今天的高点和昨天的收盘价之间的差距,以及昨天的收盘价和今天的低点之间的差距。 这告诉我们股票价格变动了多少,因此,它的波动性如何。 该算法要求我们找到每天的最大值。 我们之前使用的max()函数可以为我们提供数组中的最大值,但这不是我们想要的。 我们需要整个数组的最大值,因此我们需要三个数组中的第一个元素,第二个元素等等的最大值。 在前面的“实战时间”部分中,我们看到了maximum()函数可以做到这一点。 此后,我们计算了真实范围值的移动平均值(请参见atr.py):
from __future__ import print_function
import numpy as np
h, l, c = np.loadtxt('data.csv', delimiter=',', usecols=(4, 5, 6), unpack=True)
N = 5
h = h[-N:]
l = l[-N:]
print("len(h)", len(h), "len(l)", len(l))
print("Close", c)
previousclose = c[-N -1: -1]
print("len(previousclose)", len(previousclose))
print("Previous close", previousclose)
truerange = np.maximum(h - l, h - previousclose, previousclose - l)
print("True range", truerange)
atr = np.zeros(N)
atr[0] = np.mean(truerange)
for i in range(1, N):
atr[i] = (N - 1) * atr[i - 1] + truerange[i]
atr[i] /= N
print("ATR", atr)在以下各节中,我们将学习更好的方法来计算移动均线。
勇往直前 – 使用minimum()函数
除了maximum()函数外,还有minimum()函数。 您可能会猜到它在做什么。 使其成为一个小脚本,或者在 IPython 中启动一个交互式会话来测试您的假设。
简单移动均线
简单移动均线(SMA)通常用于分析时序数据。 为了计算它,我们定义了一个N周期的移动窗口,在本例中为N天。 我们沿着数据移动此窗口,并计算窗口内值的平均值。
实战时间 – 计算简单移动均线
移动平均值只需几个循环和mean()函数即可轻松计算,但 NumPy 具有更好的选择-convolve()函数。 毕竟,SMA 只是具有相等权重的卷积,或者,如果您愿意,可以是未加权的。
注意
卷积是两个函数的数学运算,定义为两个函数之一反转和移位后,两个函数的乘积积分。
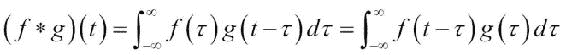
使用以下步骤来计算 SMA:
使用ones()函数创建一个大小为N的数组,并将元素初始化为 1,然后将该数组除以N以给我们权重:
N = 5
weights = np.ones(N) / N
print("Weights", weights)对于N = 5,这将为我们提供以下输出:
Weights [ 0.2 0.2 0.2 0.2 0.2]现在,使用以下权重调用convolve()函数:
c = np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)
sma = np.convolve(weights, c)[N-1:-N+1]从convolve()返回的数组中,我们提取了大小为N的中心的数据。 以下代码使用matplotlib构成了一个时间值和曲线数组,我们将在下一章中介绍:
c = np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)
sma = np.convolve(weights, c)[N-1:-N+1]
t = np.arange(N - 1, len(c))
plt.plot(t, c[N-1:], lw=1.0, label="Data")
plt.plot(t, sma, '--', lw=2.0, label="Moving average")
plt.title("5 Day Moving Average")
plt.xlabel("Days")
plt.ylabel("Price ($)")
plt.grid()
plt.legend()
plt.show()在下面的图表中,平滑虚线是 5 天均线,锯齿状细线是收盘价:
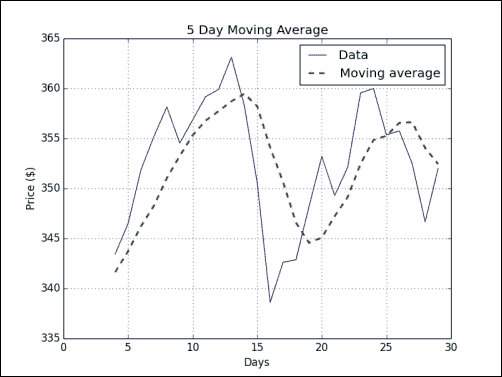
刚刚发生了什么?
我们为收盘价计算了 SMA。 事实证明,SMA 只是一种信号处理技术—具有权重1/N的卷积,其中N是移动平均窗口的大小。 我们了解到ones()函数可以创建一个带有 1 的数组,而convolve()函数可以计算具有指定权重的数据集的卷积(请参见sma.py):
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as plt
N = 5
weights = np.ones(N) / N
print("Weights", weights)
c = np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)
sma = np.convolve(weights, c)[N-1:-N+1]
t = np.arange(N - 1, len(c))
plt.plot(t, c[N-1:], lw=1.0, label="Data")
plt.plot(t, sma, '--', lw=2.0, label="Moving average")
plt.title("5 Day Moving Average")
plt.xlabel("Days")
plt.ylabel("Price ($)")
plt.grid()
plt.legend()
plt.show()指数移动均线
指数移动均线(EMA)是 SMA 的一种流行替代方法。 此方法按指数方式减小权重。 过去点的权重呈指数下降,但从未达到零。 在计算权重时,我们将学习exp()和linspace()函数。
实战时间 – 计算指数移动平均值
给定一个数组,exp()函数将计算每个数组元素的指数。 例如,在以下代码中查看 :
x = np.arange(5)
print("Exp", np.exp(x))它给出以下输出:
Exp [ 1\. 2.71828183 7.3890561 20.08553692 54.59815003]linspace()函数将起始值,终止值以及可选的数组大小作为参数。 它返回一个均匀间隔的数字数组。 这是一个例子:
print("Linspace", np.linspace(-1, 0, 5))这将为我们提供以下输出:
Linspace [-1\. -0.75 -0.5 -0.25 0\. ]为我们的数据计算 EMA:
现在,返回权重,使用exp()和linspace()进行计算:
N = 5
weights = np.exp(np.linspace(-1., 0., N))使用ndarray sum()方法标准化权重:
weights /= weights.sum()
print("Weights", weights)对于N = 5,我们得到以下权重:
Weights [ 0.11405072 0.14644403 0.18803785 0.24144538 0.31002201]之后,使用我们在 SMA 部分中了解的convolve()函数并绘制结果:
c = np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)
ema = np.convolve(weights, c)[N-1:-N+1]
t = np.arange(N - 1, len(c))
plt.plot(t, c[N-1:], lw=1.0, label='Data')
plt.plot(t, ema, '--', lw=2.0, label='Exponential Moving Average')
plt.title('5 Days Exponential Moving Average')
plt.xlabel('Days')
plt.ylabel('Price ($)')
plt.legend()
plt.grid()
plt.show()这给了我们一个不错的图表,在该图表中,收盘价再次是锯齿状细线,而 EMA 是平滑虚线:
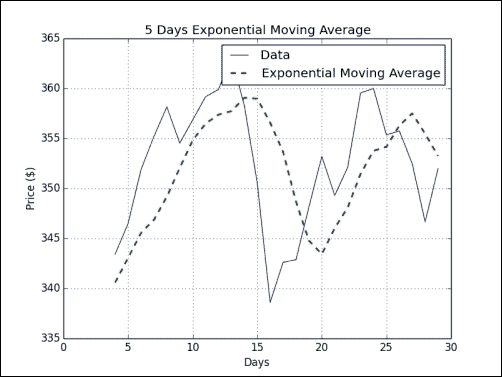
刚刚发生了什么?
我们计算了收盘价的 EMA。 首先,我们使用exp()和linspace()函数计算指数递减的权重。 linspace()函数为我们提供了元素间隔均匀的数组,然后,我们计算了这些数字的指数。 为了将权重标准化,我们将调用ndarray sum()方法。 此后,我们应用了在 SMA 部分中学到的convolve()技巧(请参阅ema.py):
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(5)
print("Exp", np.exp(x))
print("Linspace", np.linspace(-1, 0, 5))
## Calculate weights
N = 5
weights = np.exp(np.linspace(-1., 0., N))
## Normalize weights
weights /= weights.sum()
print("Weights", weights)
c = np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)
ema = np.convolve(weights, c)[N-1:-N+1]
t = np.arange(N - 1, len(c))
plt.plot(t, c[N-1:], lw=1.0, label='Data')
plt.plot(t, ema, '--', lw=2.0, label='Exponential Moving Average')
plt.title('5 Days Exponential Moving Average')
plt.xlabel('Days')
plt.ylabel('Price ($)')
plt.legend()
plt.grid()
plt.show()布林带
布林带是另一个技术指标。 是的,有成千上万个。 此名称以其发明人的名字命名,并指示金融证券价格的范围。 它由三个部分组成:
- 一个简单的移动均线。
- 高于此移动平均值的两个标准差的上限-标准差是从所计算的移动平均值的相同数据中得出的。
- 低于移动均线两个标准差的较低频带。
实战时间 – 布林带
我们已经知道如何计算 SMA。 因此,如果您需要刷新内存,请阅读本章中的“实战时间 – 计算简单平均”部分。 本示例将介绍 NumPy fill()函数。 fill()函数将数组的值设置为标量值。 该函数应比array.flat = scalar更快,或者应在循环中一对一地设置数组的值。 执行以下步骤以布林带包络:
从包含移动平均值的名为sma的数组开始,我们将遍历与那些值相对应的所有数据集。 形成数据集后,计算标准差。 注意,在某个点上,有必要计算每个数据点与相应平均值之间的差。 如果没有 NumPy,我们将遍历这些点,并从相应的平均值中逐个减去每个值。 但是,NumPy fill()函数允许我们构造一个元素设置为相同值的数组。 这样一来,我们就可以节省一个循环并一次性减去数组:
deviation = []
C = len(c)
for i in range(N - 1, C):
if i + N < C:
dev = c[i: i + N]
else:
dev = c[-N:]
averages = np.zeros(N)
averages.fill(sma[i - N - 1])
dev = dev - averages
dev = dev ** 2
dev = np.sqrt(np.mean(dev))
deviation.append(dev)
deviation = 2 * np.array(deviation)
print(len(deviation), len(sma))
upperBB = sma + deviation
lowerBB = sma - deviation要进行绘图,我们将使用以下代码(现在不必担心;我们将在第 9 章“matplotlib 绘图”中了解其工作原理):
t = np.arange(N - 1, C)
plt.plot(t, c_slice, lw=1.0, label='Data')
plt.plot(t, sma, '--', lw=2.0, label='Moving Average')
plt.plot(t, upperBB, '-.', lw=3.0, label='Upper Band')
plt.plot(t, lowerBB, ':', lw=4.0, label='Lower Band')
plt.title('Bollinger Bands')
plt.xlabel('Days')
plt.ylabel('Price ($)')
plt.grid()
plt.legend()
plt.show()以下是显示数据的布林带的图表。 中间的锯齿状细线表示收盘价,而穿过它的虚线,更平滑的线是移动均线:
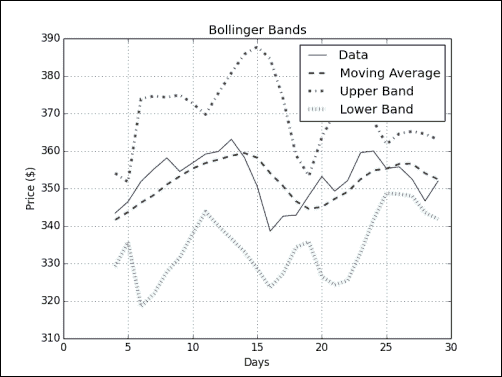
刚刚发生了什么?
我们制定了包围数据收盘价的布林带。 更重要的是,我们熟悉 NumPy fill()函数。 此函数用标量值填充数组。 这是fill()函数的唯一参数(请参见bollingerbands.py):
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as plt
N = 5
weights = np.ones(N) / N
print("Weights", weights)
c = np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)
sma = np.convolve(weights, c)[N-1:-N+1]
deviation = []
C = len(c)
for i in range(N - 1, C):
if i + N < C:
dev = c[i: i + N]
else:
dev = c[-N:]
averages = np.zeros(N)
averages.fill(sma[i - N - 1])
dev = dev - averages
dev = dev ** 2
dev = np.sqrt(np.mean(dev))
deviation.append(dev)
deviation = 2 * np.array(deviation)
print(len(deviation), len(sma))
upperBB = sma + deviation
lowerBB = sma - deviation
c_slice = c[N-1:]
between_bands = np.where((c_slice < upperBB) & (c_slice > lowerBB))
print(lowerBB[between_bands])
print(c[between_bands])
print(upperBB[between_bands])
between_bands = len(np.ravel(between_bands))
print("Ratio between bands", float(between_bands)/len(c_slice))
t = np.arange(N - 1, C)
plt.plot(t, c_slice, lw=1.0, label='Data')
plt.plot(t, sma, '--', lw=2.0, label='Moving Average')
plt.plot(t, upperBB, '-.', lw=3.0, label='Upper Band')
plt.plot(t, lowerBB, ':', lw=4.0, label='Lower Band')
plt.title('Bollinger Bands')
plt.xlabel('Days')
plt.ylabel('Price ($)')
plt.grid()
plt.legend()
plt.show()勇往直前 – 切换到指数移动均线
通常选择 SMA 来使布林带居中。 第二个最受欢迎的选择是 EMA,因此请尝试作为练习。 如果需要指针,可以在本章中找到合适的示例。
检查fill()函数是否更快或与array.flat = scalar一样快,或循环设置该值。
线性模型
科学中的许多现象都有一个相关的线性关系模型。 NumPy linalg包处理线性代数计算。 我们首先假设可以基于线性关系从N以前的价格中得出价格值。
实战时间 – 使用线性模型预测价格
保持开放态度 ,让我们假设可以将股票价格p表示为先前值的线性组合,也就是说,这些值的总和乘以我们需要确定的某些系数:
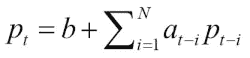
用线性代数术语,可以归结为最小二乘法。
注意
天文学家 Legendre 和 Gauss 彼此独立,于 1805 年左右发明了最小二乘法。 该方法最初用于分析天体的运动。 该算法将残差平方和(measured和predicted值之间的差)最小化:
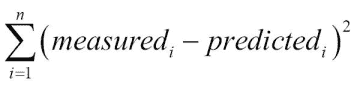
秘籍如下所示:首先,形成一个包含N个价格值的向量b:
```py
b = c[-N:]
b = b[::-1]
print("b", x)
```
结果如下:
```py
b [ 351.99 346.67 352.47 355.76 355.36]
```其次,将矩阵A预先初始化为N x N并包含零:
A = np.zeros((N, N), float)
Print("Zeros N by N", A)屏幕上应打印以下内容:
Zeros N by N [[ 0\. 0\. 0\. 0\. 0.]
[ 0\. 0\. 0\. 0\. 0.]
[ 0\. 0\. 0\. 0\. 0.]
[ 0\. 0\. 0\. 0\. 0.]
[ 0\. 0\. 0\. 0\. 0.]]第三,对于b中的每个值,使用N个之前的价格值填充矩阵A:
for i in range(N):
A[i, ] = c[-N - 1 - i: - 1 - i]
print("A", A)现在,A看起来像这样:
A [[ 360\. 355.36 355.76 352.47 346.67]
[ 359.56 360\. 355.36 355.76 352.47]
[ 352.12 359.56 360\. 355.36 355.76]
[ 349.31 352.12 359.56 360\. 355.36]
[ 353.21 349.31 352.12 359.56 360\. ]]目的是通过解决最小二乘问题来确定满足我们的线性模型的系数。 使用 NumPy linalg包的lstsq()函数执行此操作:
(x, residuals, rank, s) = np.linalg.lstsq(A, b)
print(x, residuals, rank, s)The result is as follows:
[ 0.78111069 -1.44411737 1.63563225 -0.89905126 0.92009049] [] 5 [ 1.77736601e+03 1.49622969e+01 8.75528492e+00 5.15099261e+00 1.75199608e+00]返回的元组包含我们所追求的系数x,一个包含残差的数组,矩阵A的秩以及A的奇异值。
一旦有了线性模型的系数,就可以预测下一个价格值。 计算系数的点积(使用 NumPy 的dot()函数)和最后一次已知的N价格:
print(np.dot(b, x))点积是以下项的线性组合,系数b和x的乘积。结果,我们得到:
357.939161015我抬起头来; 第二天的实际收盘价为353.56。 因此,我们对N = 5的估算与预期相差不远。
刚刚发生了什么?
我们今天预测了明天的股价。 如果这在实践中可行,我们可以提早退休! 瞧,这本书毕竟是一笔不错的投资! 我们为预测设计了线性模型。 财务问题被简化为线性代数。 NumPy 的linalg包具有实用的lstsq()函数,可帮助我们完成当前的任务,估计线性模型的系数。 在获得解决方案后,我们将数字插入了 NumPy dot()函数中,该函数通过线性回归为我们提供了一个估计值(请参见linearmodel.py):
from __future__ import print_function
import numpy as np
N = 5
c = np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)
b = c[-N:]
b = b[::-1]
print("b", b)
A = np.zeros((N, N), float)
print("Zeros N by N", A)
for i in range(N):
A[i, ] = c[-N - 1 - i: - 1 - i]
print("A", A)
(x, residuals, rank, s) = np.linalg.lstsq(A, b)
print(x, residuals, rank, s)
print(np.dot(b, x))趋势线
趋势线是股票图表上许多所谓的枢轴点中的线。 顾名思义,该线的趋势描绘了价格发展的趋势。 过去,交易员在纸上绘制趋势线,但如今,我们可以让计算机为我们绘制趋势线。 在本节中,我们将使用一种非常简单的方法,该方法在现实生活中可能不会很有用,但应很好地阐明原理。
实战时间 – 绘制趋势线
执行以下步骤绘制趋势线:
首先,我们需要确定枢轴点。 我们假设它们等于最高价,最低价和收盘价的算术平均值:
h, l, c = np.loadtxt('data.csv', delimiter=',', usecols=(4, 5, 6), unpack=True)
pivots = (h + l + c) / 3
print("Pivots", pivots)从支点来看,我们可以推断出所谓的阻力和支撑位。 支撑位是价格反弹的最低水平。 阻力位是价格反弹的最高位。 这些不是自然现象,它们只是估计。 基于这些估计,可以绘制支撑和阻力趋势线。 我们将每日点差定义为高价和低价之差。
定义一个函数以使数据行适合y = at + b的行。 该函数应返回a和b。 这是应用 NumPy linalg包的lstsq()函数的另一个机会。 将线方程式重写为y = Ax,其中A = [t 1]和x = [a b]。 使用 NumPy ones_like()的形式A,该数组创建一个数组,其中所有值均等于1,并使用输入数组作为该数组尺寸的模板:
def fit_line(t, y):
A = np.vstack([t, np.ones_like(t)]).T
return np.linalg.lstsq(A, y)[0]假设支撑位是在枢轴下方的一个每日价差,并且阻力位是支撑点和支撑趋势线的一个每日价差:
t = np.arange(len(c))
sa, sb = fit_line(t, pivots - (h - l))
ra, rb = fit_line(t, pivots + (h - l))
support = sa * t + sb
resistance = ra * t + rb目前,我们掌握了绘制趋势线的所有必要信息。 但是,检查在支撑位和阻力位之间落多少点是明智的。 显然,如果只有一小部分数据位于趋势线之间,则此设置对我们没有用。 为波段之间的点建立条件,并根据以下条件使用where()函数进行选择:
condition = (c > support) & (c < resistance)
print("Condition", condition)
between_bands = np.where(condition)这些是打印条件值:
Condition [False False True True True True True False False True False False
False False False True False False False True True True True False False True True True False True]仔细检查值:
print(support[between_bands])
print( c[between_bands])
print( resistance[between_bands])where()函数返回的数组具有rank 2,因此在调用len()函数之前先调用ravel()函数:
between_bands = len(np.ravel(between_bands))
print("Number points between bands", between_bands)
print("Ratio between bands", float(between_bands)/len(c))您将得到以下结果:
Number points between bands 15
Ratio between bands 0.5作为额外的奖励,我们获得了一个预测模型。 推断第二天的阻力和支撑位:
print("Tomorrows support", sa * (t[-1] + 1) + sb)
print("Tomorrows resistance", ra * (t[-1] + 1) + rb)This results in the following output:
Tomorrows support 349.389157088
Tomorrows resistance 360.749340996确定支撑和阻力估计之间有多少个点的另一种方法是使用[]和intersect1d()。 在[]运算符中定义选择标准,并将结果与??intersect1d()函数相交:
a1 = c[c > support]
a2 = c[c < resistance]
print("Number of points between bands 2nd approach" ,len(np.intersect1d(a1, a2)))毫不奇怪,我们得到:
Number of points between bands 2nd approach 15再一次,绘制结果:
plt.plot(t, c, label='Data')
plt.plot(t, support, '--', lw=2.0, label='Support')
plt.plot(t, resistance, '-.', lw=3.0, label='Resistance')
plt.title('Trend Lines')
plt.xlabel('Days')
plt.ylabel('Price ($)')
plt.grid()
plt.legend()
plt.show()在下图中,我们获得了价格数据以及相应的支撑线和阻力线:
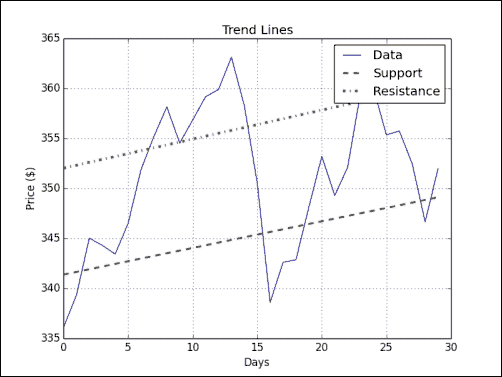
刚刚发生了什么?
我们绘制了趋势线,而不必弄乱标尺,铅笔和纸质图表。 我们使用 NumPy vstack(),ones_like()和lstsq()函数定义了可以使数据适合行的函数。 我们拟合数据以定义支撑和阻力趋势线。 然后,我们找出了在支撑和阻力范围内的点。 我们使用两种产生相同结果的独立方法进行了此操作。
第一种方法使用带有布尔条件的where()函数。 第二种方法使用[]运算符和intersect1d()函数。 intersect1d()函数从两个数组返回一个公共元素数组(请参见trendline.py):
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as plt
def fit_line(t, y):
''' Fits t to a line y = at + b '''
A = np.vstack([t, np.ones_like(t)]).T
return np.linalg.lstsq(A, y)[0]
## Determine pivots
h, l, c = np.loadtxt('data.csv', delimiter=',', usecols=(4, 5, 6), unpack=True)
pivots = (h + l + c) / 3
print("Pivots", pivots)
## Fit trend lines
t = np.arange(len(c))
sa, sb = fit_line(t, pivots - (h - l))
ra, rb = fit_line(t, pivots + (h - l))
support = sa * t + sb
resistance = ra * t + rb
condition = (c > support) & (c < resistance)
print("Condition", condition)
between_bands = np.where(condition)
print(support[between_bands])
print(c[between_bands])
print(resistance[between_bands])
between_bands = len(np.ravel(between_bands))
print("Number points between bands", between_bands)
print("Ratio between bands", float(between_bands)/len(c))
print("Tomorrows support", sa * (t[-1] + 1) + sb)
print("Tomorrows resistance", ra * (t[-1] + 1) + rb)
a1 = c[c > support]
a2 = c[c < resistance]
print("Number of points between bands 2nd approach" ,len(np.intersect1d(a1, a2)))
## Plotting
plt.plot(t, c, label='Data')
plt.plot(t, support, '--', lw=2.0, label='Support')
plt.plot(t, resistance, '-.', lw=3.0, label='Resistance')
plt.title('Trend Lines')
plt.xlabel('Days')
plt.ylabel('Price ($)')
plt.grid()
plt.legend()
plt.show()ndarray的方法
NumPy ndarray类具有在数组上工作的许多方法。 大多数情况下,这些方法返回数组。 您可能已经注意到,NumPy 库的许多功能部分在ndarray类中具有相同的名称和功能。 这主要是由于 NumPy 的历史发展。
ndarray方法的列表很长,因此我们无法涵盖所有??方法。 我们先前看到的mean(),var(),sum(),std(),argmax(),argmin()和mean()函数也是ndarray方法。
实战时间 – 剪切和压缩数组
以下是ndarray方法的一些示例。 执行以下步骤来裁剪和压缩数组:
clip()方法返回一个裁剪后的数组,以便将所有大于最大值的值设置为最大值,而将小于最小值的值设置为最小值。 将值为 0 到 4 的数组裁剪为 1 和 2 的数组:
a = np.arange(5)
print("a =", a)
print("Clipped", a.clip(1, 2))这给出以下输出:
a = [0 1 2 3 4]
Clipped [1 1 2 2 2]ndarray compress()方法根据条件返回一个数组。 例如,看下面的代码:
a = np.arange(4)
print(a)
print("Compressed", a.compress(a > 2))这将返回以下输出:
[0 1 2 3]
Compressed [3]刚刚发生了什么?
我们创建了数组 ,其值是0至3,并根据a > 2条件选择了带有compress()函数的最后一个元素。
阶乘
许多编程书籍都有一个计算阶乘的示例。 我们不应该违背这一传统。
实战时间 – 计算阶乘
ndarray类具有prod()方法,该方法计算数组中元素的乘积。 执行以下步骤来计算阶乘:
计算8的阶乘。 为此,请生成一个值从 1 到 8 的数组,并对其调用prod()函数:
b = np.arange(1, 9)
print("b =", b)
print("Factorial", b.prod())用袖珍计算器检查结果:
b = [1 2 3 4 5 6 7 8]
Factorial 40320很好,但是如果我们想知道从 1 到 8 的所有阶乘,该怎么办?
没问题! 调用cumprod()方法,该方法计算数组的累加乘积:
print("Factorials", b.cumprod())又是袖珍计算器时间了:
Factorials [ 1 2 6 24 120 720 5040 40320]刚刚发生了什么?
我们使用 prod()和cumprod()函数来计算阶乘(请参阅ndarraymethods.py):
from __future__ import print_function
import numpy as np
a = np.arange(5)
print("a =", a)
print("Clipped", a.clip(1, 2))
a = np.arange(4)
print(a)
print("Compressed", a.compress(a > 2))
b = np.arange(1, 9)
print("b =", b)
print("Factorial", b.prod())
print("Factorials", b.cumprod())缺失值和折刀重采样
由于错误或技术问题,数据通常会丢失值。 即使我们不缺少值,我们也可能有理由怀疑某些值。 一旦我们对数据值产生怀疑,我们在本章中学会计算的诸如算术平均值之类的派生值也将变得可疑。 由于这些原因,通常尝试估算算术平均值,方差和标准差的可靠性。
一种简单但有效的方法,称为折刀重采样。 折刀重采样背后的想法是通过一次保留一个值来从原始数据集中系统地生成数据集。 实际上,我们正在尝试确定如果至少一个值是错误的,将会发生什么。 对于每个新生成的数据集,我们重新计算算术平均值,方差和标准差。 这使我们知道这些值可以变化多少。
实战时间 – 使用nanmean(),nanvar()和nanstd()函数处理 NaN
我们将对数据进行折刀重采样。 通过将每个值设置为非数字(NaN),将省略这些值。 然后,可以使用nanmean(),nanvar()和nanstd()计算算术均值,方差和标准差。
首先,按如下所示初始化30 x 3数组以进行估算:
estimates = np.zeros((len(c), 3))通过在循环的每次迭代中将一个值设置为 NaN 来遍历值并生成新的数据集。 对于每个新值集,计算估计值:
for i in xrange(len(c)):
a = c.copy()
a[i] = np.nan
estimates[i,] = [np.nanmean(a), np.nanvar(a), np.nanstd(a)]打印每个估计的方差(如果您愿意,也可以打印均值或标准差):
print("Estimates variance", estimates.var(axis=0))屏幕上打印以下内容:
Estimates variance [ 0.05960347 3.63062943 0.01868965]刚刚发生了什么?
我们使用折刀重采样估计了小型数据集的算术平均值,方差和标准差的方差。 这使我们知道算术平均值,方差和标准差有多少变化。 该示例的代码可以在本书的代码包的jackknife.py文件中找到:
from __future__ import print_function
import numpy as np
c = np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)
## Initialize estimates array
estimates = np.zeros((len(c), 3))
for i in xrange(len(c)):
# Create a temporary copy and omit one value
a = c.copy()
a[i] = np.nan
# Compute estimates
estimates[i,] = [np.nanmean(a), np.nanvar(a), np.nanstd(a)]
print("Estimates variance", estimates.var(axis=0))总结
本章向我们介绍了许多常见的 NumPy 函数。 还提到了一些常用的统计函数。
在浏览完常见的 NumPy 函数之后,我们将在下一章继续介绍方便的 NumPy 函数,例如polyfit(),sign()和piecewise()。
四、为您带来便利的便利函数
如我们所见,NumPy 具有大量函数。 这些函数中的许多函数只是为了方便起见,知道这些函数将大大提高您的生产率。 这包括选择数组某些部分(例如,基于布尔条件)或处理多项式的函数。 本章提供了一个计算相关性示例,使您可以使用 NumPy 进行数据分析。
在本章中,我们将涵盖以下主题:
- 数据选择与提取
- 简单的数据分析
- 收益相关的示例
- 多项式
- 线性代数函数
在第 3 章,“熟悉常用函数”中,我们有一个数据文件可以使用。 在本章中,情况有所改善-我们现在有两个数据文件。 让我们使用 NumPy 探索数据。
相关
您是否注意到某些公司的股价会紧随其后,通常是同一行业的竞争对手? 理论上的解释是,由于这两家公司属于同一类型的业务,因此它们面临着相同的挑战,需要相同的材料和资源,并争夺相同类型的客户。
您可能想到了许多可能的对,但是您需要检查一下真实的关系。 一种方法是查看两种股票的股票收益的相关性和因果关系。 高相关性意味着某种关系。 但是,这并不是因果关系的证明,尤其是如果您没有使用足够的数据。
实战时间 – 交易相关货币对
在本节中,我们将使用两个样本数据集,其中包含日末价格数据。 第一家公司是必和必拓(BHP),该公司活跃于石油,金属和钻石的开采。 第二个是淡水河谷(VALE),这也是一家金属和采矿公司。 因此,活动有一些重叠,尽管不是 100%。 要评估相关偶对,请按照下列步骤操作:
首先,从本章示例代码目录中的 CSV 文件加载数据,特别是两种证券的收盘价,并计算收益。 如果您不记得该怎么做,请参阅第 3 章,“熟悉常用函数”中的示例。
协方差告诉我们两个变量如何一起变化;无非就是相关性:
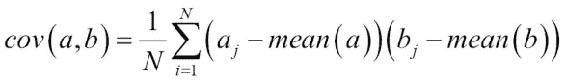
使用cov()函数从返回值计算协方差矩阵(并非严格如此,但这可以让我们演示一些矩阵运算):
covariance = np.cov(bhp_returns, vale_returns)
print("Covariance", covariance)协方差矩阵如下:
Covariance [[ 0.00028179 0.00019766]
[ 0.00019766 0.00030123]]使用diagonal()方法查看对角线上的值:
print("Covariance diagonal", covariance.diagonal())协方差矩阵的对角线值如下:
Covariance diagonal [ 0.00028179 0.00030123]请注意,对角线上的值彼此不相等。 这与相关矩阵不同。
使用trace()方法计算轨迹,即对角线值的总和:
print("Covariance trace", covariance.trace())协方差矩阵的跟踪值如下:
Covariance trace 0.00058302354992将两个向量的相关性定义为协方差,除以向量各自标准偏差的乘积。 向量a和b的等式如下:
print(covariance/ (bhp_returns.std() * vale_returns.std()))相关矩阵如下:
[[ 1.00173366 0.70264666]
[ 0.70264666 1.0708476 ]]我们将用相关系数来衡量我们偶对的相关性。 相关系数取介于 -1 和 1 之间的值。 根据定义,一组值与自身的相关性为 1。 这将是理想值; 但是,我们也会对较低的值感到满意。 使用corrcoef()函数计算相关系数(或更准确地说,相关矩阵):
print("Correlation coefficient", np.corrcoef(bhp_returns, vale_returns))系数如下:
[[ 1\. 0.67841747]
[ 0.67841747 1\. ]]对角线上的值仅是BHP和VALE与它们自身的相关性,因此等于 1。在任何可能性下,都不会进行任何实际计算。 由于相关性是对称的,因此其他两个值彼此相等,这意味着BHP与VALE的相关性等于VALE与BHP的相关性。 似乎这里的相关性不是那么强。
另一个要点是,正在考虑的两只股票是否同步。 如果两只股票的差额是与均值之差的两个标准差,则认为它们不同步。
如果它们不同步,我们可以发起交易,希望它们最终能够再次恢复同步。 计算两种证券的收盘价之间的差异,以检查同步:
difference = bhp - vale检查最后的价格差异是否不同步; 请参阅以下代码:
avg = np.mean(difference)
dev = np.std(difference)
print("Out of sync", np.abs(difference[-1] – avg) > 2 * dev)不幸的是,我们还不能交易:
Out of sync False绘图需要matplotlib;这将在第 9 章"matplotlib 绘图”中讨论。 可以按以下方式进行绘制:
t = np.arange(len(bhp_returns))
plt.plot(t, bhp_returns, lw=1, label='BHP returns')
plt.plot(t, vale_returns, '--', lw=2, label='VALE returns')
plt.title('Correlating arrays')
plt.xlabel('Days')
plt.ylabel('Returns')
plt.grid()
plt.legend(loc='best')
plt.show()结果图如下所示:
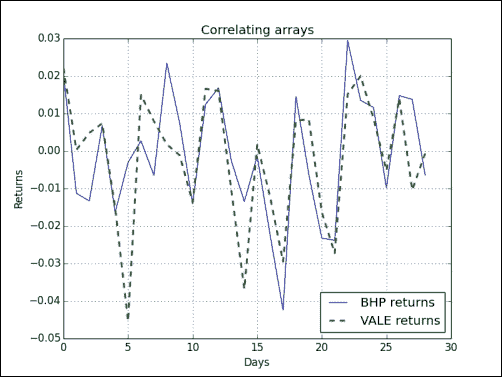
刚刚发生了什么?
我们分析了BHP和VALE收盘价的关系。 确切地说,我们计算了他们的股票收益的相关性。 我们通过 corrcoef()函数实现了这一目标。 此外,我们看到了如何计算可以从中得出相关性的协方差矩阵。 另外,我们演示了diagonal()和trace()方法,它们分别为我们提供对角线值和矩阵迹线。 有关源代码,请参见本书代码包中的correlation.py文件:
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as plt
bhp = np.loadtxt('BHP.csv', delimiter=',', usecols=(6,), unpack=True)
bhp_returns = np.diff(bhp) / bhp[ : -1]
vale = np.loadtxt('VALE.csv', delimiter=',', usecols=(6,), unpack=True)
vale_returns = np.diff(vale) / vale[ : -1]
covariance = np.cov(bhp_returns, vale_returns)
print("Covariance", covariance)
print("Covariance diagonal", covariance.diagonal())
print("Covariance trace", covariance.trace())
print(covariance/ (bhp_returns.std() * vale_returns.std()))
print("Correlation coefficient", np.corrcoef(bhp_returns, vale_returns))
difference = bhp - vale
avg = np.mean(difference)
dev = np.std(difference)
print("Out of sync", np.abs(difference[-1] - avg) > 2 * dev)
t = np.arange(len(bhp_returns))
plt.plot(t, bhp_returns, lw=1, label='BHP returns')
plt.plot(t, vale_returns, '--', lw=2, label='VALE returns')
plt.title('Correlating arrays')
plt.xlabel('Days')
plt.ylabel('Returns')
plt.grid()
plt.legend(loc='best')
plt.show()小测验 - 计算协方差
Q1. 哪个函数返回两个数组的协方差?
covariancecovarcovcvar
多项式
您喜欢微积分吗? 好吧,我喜欢它! 微积分学中的一种思想是泰勒展开,即代表无穷级数的可微函数(请参见这里和这里)。
注意
泰勒级数的定义如下所示:
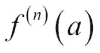
在此定义中,是在点a上计算的函数f的n阶导数。
实际上,这意味着我们可以使用高阶多项式来估计任何可微的,因此是连续的函数。 然后,我们假设较高学位的条款可以忽略不计。
实战时间 – 拟合多项式
NumPy polyfit()函数拟合多项式的一组数据点,即使基础函数不是连续的:
继续使用BHP和VALE的价格数据,查看其收盘价之间的差异,并将其拟合为三次方的多项式:
bhp=np.loadtxt('BHP.csv', delimiter=',', usecols=(6,), unpack=True)
vale=np.loadtxt('VALE.csv', delimiter=',', usecols=(6,), unpack=True)
t = np.arange(len(bhp))
poly = np.polyfit(t, bhp - vale, 3)
print("Polynomial fit", poly)多项式拟合(在此示例中,选择了三次多项式)如下:
Polynomial fit [ 1.11655581e-03 -5.28581762e-02 5.80684638e-01 5.79791202e+01]您看到的数字是多项式的系数。 用polyval()函数和我们从拟合中得到的多项式对象外插到下一个值:
print("Next value", np.polyval(poly, t[-1] + 1))我们预测的下一个值将是:
Next value 57.9743076081理想情况下,BHP和VALE的收盘价之间的差异应尽可能小。 在极端情况下,它有时可能为零。 使用roots()函数找出多项式拟合何时达到零:
print( "Roots", np.roots(poly))多项式的根如下:
Roots [ 35.48624287+30.62717062j 35.48624287-30.62717062j -23.63210575 +0.j ]在微积分课上,您可能学到的另一件事是找到“极值”,这些极值可能是最大值或最小值。 从微积分中记住,这些是我们函数的导数为零的点。 用polyder()函数来微分多项式拟合:
der = np.polyder(poly)
print("Derivative", der)导数多项式的系数如下:
Derivative [ 0.00334967 -0.10571635 0.58068464]获取导数的根:
print("Extremas", np.roots(der))我们得到的极值如下:
Extremas [ 24.47820054 7.08205278]让我们使用polyval()函数仔细检查并计算拟合值:
vals = np.polyval(poly, t)现在,使用argmax()和argmin()函数找到最大值和最小值:
vals = np.polyval(poly, t)
print(np.argmax(vals))
print(np.argmin(vals))这为我们提供了以下屏幕快照中所示的预期结果。 好的,结果并不完全相同,但是,如果我们退回到步骤 1,我们可以看到t是通过 arange()函数定义的:
7
24绘制数据并对其拟合 ,以得到以下曲线:
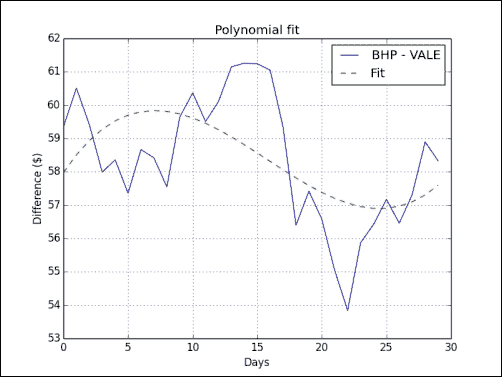
显然,平滑线是拟合的,而锯齿线是基础的数据。 但是由于不太适合,您可能需要尝试更高阶的多项式。
刚刚发生了什么?
我们使用 polyfit()函数将数据拟合为多项式。 我们了解了用于计算多项式值的polyval()函数,用于返回多项式的根的roots()函数以及用于返回多项式导数的polyder()函数( 参见polynomials.py):
from __future__ import print_function
import numpy as np
import sys
import matplotlib.pyplot as plt
bhp=np.loadtxt('BHP.csv', delimiter=',', usecols=(6,), unpack=True)
vale=np.loadtxt('VALE.csv', delimiter=',', usecols=(6,), unpack=True)
t = np.arange(len(bhp))
poly = np.polyfit(t, bhp - vale, 3)
print("Polynomial fit", poly)
print("Next value", np.polyval(poly, t[-1] + 1))
print("Roots", np.roots(poly))
der = np.polyder(poly)
print("Derivative", der)
print("Extremas", np.roots(der))
vals = np.polyval(poly, t)
print(np.argmax(vals))
print(np.argmin(vals))
plt.plot(t, bhp - vale, label='BHP - VALE')
plt.plot(t, vals, '-—', label='Fit')
plt.title('Polynomial fit')
plt.xlabel('Days')
plt.ylabel('Difference ($)')
plt.grid()
plt.legend()
plt.show()勇往直前 – 改进拟合
您可以做很多事情来改进拟合。 例如,尝试使用其他幂,因为在本节中选择了三次多项式。 考虑在拟合之前对数据进行平滑处理。 平滑数据的一种方法是移动平均值。 您可以在第 3 章,“熟悉常用函数”中找到简单和 EMA 计算的示例。
余量
交易量是在投资中非常重要的变量; 它表明价格走势有多大。 平衡交易量指标是最简单的股票价格指标之一。 它基于当日和前几日的收盘价以及当日的交易量。 对于每一天,如果今天的收盘价高于昨天的收盘价,那么余额表上的交易量的值等于今天的交易量。 另一方面,如果今天的收盘价低于昨天的收盘价,那么资产负债表上交易量指标的值就是资产负债表上的交易量与今天的交易量之差。 但是,如果收盘价没有变化,那么余额表上的交易量的值为零。
实战时间 – 平衡交易量
换句话说,我们需要乘以收盘价和交易量的符号。 在本节中,我们研究解决此问题的两种方法:一种使用 NumPy sign()函数,另一种使用 NumPy piecewise()函数。
将BHP数据加载到close和volume数组中:
c, v=np.loadtxt('BHP.csv', delimiter=',', usecols=(6, 7), unpack=True)计算绝对值的变化。 用diff()函数计算收盘价的变化。 diff()函数计算两个连续数组元素之间的差,并返回包含这些差的数组:
change = np.diff(c)
print("Change", change)收盘价变化如下:
Change [ 1.92 -1.08 -1.26 0.63 -1.54 -0.28 0.25 -0.6 2.15 0.69 -1.33 1.16
1.59 -0.26 -1.29 -0.13 -2.12 -3.91 1.28 -0.57 -2.07 -2.07 2.5 1.18
-0.88 1.31 1.24 -0.59]NumPy 的sign()函数返回数组中每个元素的符号。 -1 表示负数,1 表示正数,否则返回 0。 将sign()函数应用于change数组:
signs = np.sign(change)
print("Signs", signs)更改数组的符号如下:
Signs [ 1\. -1\. -1\. 1\. -1\. -1\. 1\. -1\. 1\. 1\. -1\. 1\. 1\. -1\. -1\. -1\. -1\. -1.
-1\. -1\. -1\. 1\. 1\. 1\. -1\. 1\. 1\. -1.]另外,我们可以用piecewise()函数来计算 。 顾名思义,piecewise()函数逐段求值函数 。 使用适当的返回值和条件调用该函数:
pieces = np.piecewise(change, [change < 0, change > 0], [-1, 1])
print("Pieces", pieces)这些标志再次显示如下:
Pieces [ 1\. -1\. -1\. 1\. -1\. -1\. 1\. -1\. 1\. 1\. -1\. 1\. 1\. -1\. -1\. -1\. -1\. -1.
-1\. -1\. -1\. 1\. 1\. 1\. -1\. 1\. 1\. -1.]检查结果是否相同:
print("Arrays equal?", np.array_equal(signs, pieces))结果如下:
Arrays equal? True余额的大小取决于前一个收盘价的变化,因此我们无法在样本的第一天进行计算:
print("On balance volume", v[1:] * signs)余额余额如下:
[ 2620800\. -2461300\. -3270900\. 2650200\. -4667300\. -5359800\. 7768400.
-4799100\. 3448300\. 4719800\. -3898900\. 3727700\. 3379400\. -2463900.
-3590900\. -3805000\. -3271700\. -5507800\. 2996800\. -3434800\. -5008300.
-7809799\. 3947100\. 3809700\. 3098200\. -3500200\. 4285600\. 3918800.
-3632200.]刚刚发生了什么?
我们计算了取决于收盘价变化的余额数量。 使用 NumPy sign()和piecewise()函数,我们遍历了两种不同的方法来确定更改的符号(请参见obv.py),如下所示:
from __future__ import print_function
import numpy as np
c, v=np.loadtxt('BHP.csv', delimiter=',', usecols=(6, 7), unpack=True)
change = np.diff(c)
print("Change", change)
signs = np.sign(change)
print("Signs", signs)
pieces = np.piecewise(change, [change < 0, change > 0], [-1, 1])
print("Pieces", pieces)
print("Arrays equal?", np.array_equal(signs, pieces))
print("On balance volume", v[1:] * signs)模拟
通常,您会想先尝试一下。 玩耍,试验,但最好不要炸东西或变脏! NumPy 非常适合进行实验。 我们将使用 NumPy 模拟交易日,而不会实际亏损。 许多人喜欢逢低买入,换句话说,等待股票价格下跌之后再购买。 一个变种是等待价格下跌一小部分,例如比当天的开盘价低 0.1%。
实战时间 – 使用vectorize()避免循环
vectorize()函数是 ,这是另一个可以减少程序循环次数的技巧 。 请按照以下步骤计算一个交易日的利润:
首先,加载数据:
o, h, l, c = np.loadtxt('BHP.csv', delimiter=',', usecols=(3, 4, 5, 6), unpack=True)vectorize()函数与 Python map()函数的 NumPy 等效。 调用vectorize()函数,并将其作为参数作为calc_profit()函数:
func = np.vectorize(calc_profit)现在,我们可以应用func(),就好像它是一个函数一样。 将我们获得的的func()函数结果应用于价格数组:
profits = func(o, h, l, c)calc_profit()函数非常简单。 首先,我们尝试以较低的开盘价购买。 如果这超出每日范围,那么很明显,我们的尝试失败,没有获利,或者我们蒙受了损失,因此将返回 0。否则,我们以收盘价卖出利润仅仅是买入价和收盘价之间的差。 实际上,查看相对利润实际上更有趣:
def calc_profit(open, high, low, close):
#buy just below the open
buy = open * 0.999
# daily range
if low < buy < high:
return (close - buy)/buy
else:
return 0
print("Profits", profits)假设有两天的利润为零,既没有净收益也没有亏损。 选择交易日并计算平均值:
real_trades = profits[profits != 0]
print("Number of trades", len(real_trades), round(100.0 * len(real_trades)/len(c), 2), "%")
print("Average profit/loss %", round(np.mean(real_trades) * 100, 2))交易摘要如下所示:
Number of trades 28 93.33 %
Average profit/loss % 0.02作为乐观主义者,我们对赢得大于零的交易感兴趣。 选择获胜交易的天数并计算平均值:
winning_trades = profits[profits > 0]
print("Number of winning trades", len(winning_trades), round(100.0 * len(winning_trades)/len(c), 2), "%")
print("Average profit %", round(np.mean(winning_trades) * 100, 2))获胜行业统计如下:
Number of winning trades 16 53.33 %
Average profit % 0.72另外,作为悲观主义者,我们对小于零的亏损交易感兴趣。 选择亏损交易的天数并计算平均值:
losing_trades = profits[profits < 0]
print("Number of losing trades", len(losing_trades), round(100.0 * len(losing_trades)/len(c), 2), "%")
print("Average loss %", round(np.mean(losing_trades) * 100, 2))亏损交易统计如下:
Number of losing trades 12 40.0 %
Average loss % -0.92刚刚发生了什么?
我们对函数进行向量化,这是避免使用循环的另一种方法。 我们用一个函数模拟了一个交易日,该函数返回了每天交易的相对利润。 我们打印了亏损交易和获胜交易的统计摘要(请参见simulation.py):
from __future__ import print_function
import numpy as np
o, h, l, c = np.loadtxt('BHP.csv', delimiter=',', usecols=(3, 4, 5, 6), unpack=True)
def calc_profit(open, high, low, close):
#buy just below the open
buy = open * 0.999
# daily range
if low < buy < high:
return (close - buy)/buy
else:
return 0
func = np.vectorize(calc_profit)
profits = func(o, h, l, c)
print("Profits", profits)
real_trades = profits[profits != 0]
print("Number of trades", len(real_trades), round(100.0 * len(real_trades)/len(c), 2), "%")
print("Average profit/loss %", round(np.mean(real_trades) * 100, 2))
winning_trades = profits[profits > 0]
print("Number of winning trades", len(winning_trades), round(100.0 * len(winning_trades)/len(c), 2), "%")
print("Average profit %", round(np.mean(winning_trades) * 100, 2))
losing_trades = profits[profits < 0]
print("Number of losing trades", len(losing_trades), round(100.0 * len(losing_trades)/len(c), 2), "%")
print("Average loss %", round(np.mean(losing_trades) * 100, 2))勇往直前 – 分析连续的获胜和失败
尽管平均利润为正,但了解我们是否必须承受连续亏损也很重要。 如果是这种情况,我们可能只剩下很少甚至没有资本,那么平均利润就无关紧要。
找出是否有这样的损失。 如果需要,您还可以找出是否有长时间的连胜纪录。
平滑
嘈杂的数据很难处理,因此我们经常需要进行一些平滑处理。 除了计算移动平均值外,我们还可以使用 NumPy 函数之一来平滑数据。
hanning()函数是由加权余弦形成的窗口函数 ):
在上式中, N对应于窗口的大小。 在后面的章节中,我们将介绍其他窗口函数。
实战时间 – 使用hanning()函数进行平滑处理
我们将使用 hanning()函数来平滑股票收益数组,如以下步骤所示:
调用hanning()函数来计算特定长度窗口的权重(在本示例中为 8),如下所示:
N = 8
weights = np.hanning(N)
print("Weights", weights)权重如下:
Weights [ 0\. 0.1882551 0.61126047 0.95048443 0.95048443 0.61126047
0.1882551 0\. ]使用具有标准化权重的convolve()计算BHP和VALE报价的股票收益:
bhp = np.loadtxt('BHP.csv', delimiter=',', usecols=(6,), unpack=True)
bhp_returns = np.diff(bhp) / bhp[ : -1]
smooth_bhp = np.convolve(weights/weights.sum(), bhp_returns)[N-1:-N+1]
vale = np.loadtxt('VALE.csv', delimiter=',', usecols=(6,), unpack=True)
vale_returns = np.diff(vale) / vale[ : -1]
smooth_vale = np.convolve(weights/weights.sum(), vale_returns)[N-1:-N+1]使用以下代码使用matplotlib进行绘图:
t = np.arange(N - 1, len(bhp_returns))
plt.plot(t, bhp_returns[N-1:], lw=1.0)
plt.plot(t, smooth_bhp, lw=2.0)
plt.plot(t, vale_returns[N-1:], lw=1.0)
plt.plot(t, smooth_vale, lw=2.0)
plt.show()该图表如下所示:
上图的细线是股票收益,粗线是平滑的结果。 如您所见,这些线交叉了几次。 这些点可能很重要,因为趋势可能在那里更改了 。 或者至少,BHP与VALE的关系可能已更改。 这些拐点可能经常发生,因此我们可能希望展望未来。
将平滑步骤的结果拟合为多项式,如下所示:
K = 8
t = np.arange(N - 1, len(bhp_returns))
poly_bhp = np.polyfit(t, smooth_bhp, K)
poly_vale = np.polyfit(t, smooth_vale, K)接下来,我们需要评估在上一步中找到的多项式彼此相等的情况。 归结为减去多项式并找到所得多项式的根。 使用polysub()减去多项式:
poly_sub = np.polysub(poly_bhp, poly_vale)
xpoints = np.roots(poly_sub)
print("Intersection points", xpoints)这些点如下所示:
Intersection points [ 27.73321597+0.j 27.51284094+0.j 24.32064343+0.j
18.86423973+0.j 12.43797190+1.73218179j 12.43797190-1.73218179j
6.34613053+0.62519463j 6.34613053-0.62519463j]我们得到的数字很复杂,这对我们不利(除非存在假想时间)。 使用isreal()函数检查哪些数字是实数:
reals = np.isreal(xpoints)
print("Real number?", reals)结果如下:
Real number? [ True True True True False False False False]一些数字是实数,因此请使用select()函数选择它们。 select()函数根据条件列表从选项列表中获取元素来形成数组:
xpoints = np.select([reals], [xpoints])
xpoints = xpoints.real
print("Real intersection points", xpoints)实际交点如下:
Real intersection points [ 27.73321597 27.51284094 24.32064343 18.86423973 0\. 0\. 0\. 0.]我们设法得到一些零。 trim_zeros()函数从一维数组中去除前导零和尾随零。 使用trim_zeros()函数消除零:
print("Sans 0s", np.trim_zeros(xpoints))零消失了,输出如下所示:
Sans 0s [ 27.73321597 27.51284094 24.32064343 18.86423973]刚刚发生了什么?
我们将hanning()函数应用于包含股票收益的数组。 我们用 polysub()函数减去了两个多项式。 然后,我们使用isreal()函数检查实数 ,然后使用select()函数选择实数。 最后,我们使用trim_zeros()函数从数组中剥离了零(请参见smoothing.py):
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as plt
N = 8
weights = np.hanning(N)
print("Weights", weights)
bhp = np.loadtxt('BHP.csv', delimiter=',', usecols=(6,), unpack=True)
bhp_returns = np.diff(bhp) / bhp[ : -1]
smooth_bhp = np.convolve(weights/weights.sum(), bhp_returns)[N-1:-N+1]
vale = np.loadtxt('VALE.csv', delimiter=',', usecols=(6,), unpack=True)
vale_returns = np.diff(vale) / vale[ : -1]
smooth_vale = np.convolve(weights/weights.sum(), vale_returns)[N-1:-N+1]
K = 8
t = np.arange(N - 1, len(bhp_returns))
poly_bhp = np.polyfit(t, smooth_bhp, K)
poly_vale = np.polyfit(t, smooth_vale, K)
poly_sub = np.polysub(poly_bhp, poly_vale)
xpoints = np.roots(poly_sub)
print("Intersection points", xpoints)
reals = np.isreal(xpoints)
print("Real number?", reals)
xpoints = np.select([reals], [xpoints])
xpoints = xpoints.real
print("Real intersection points", xpoints)
print("Sans 0s", np.trim_zeros(xpoints))
plt.plot(t, bhp_returns[N-1:], lw=1.0, label='BHP returns')
plt.plot(t, smooth_bhp, lw=2.0, label='BHP smoothed')
plt.plot(t, vale_returns[N-1:], '--', lw=1.0, label='VALE returns')
plt.plot(t, smooth_vale, '-.', lw=2.0, label='VALE smoothed')
plt.title('Smoothing')
plt.xlabel('Days')
plt.ylabel('Returns')
plt.grid()
plt.legend(loc='best')
plt.show()勇往直前 – 平滑变化
试用其他平滑函数 – hamming(),blackman(),bartlett()和kaiser()。 它们的工作方式几乎与hanning()函数相同。
初始化
到目前为止,在本书中,我们遇到了一些用于初始化数组的便捷函数。 full()和full_like()函数最近被添加到 NumPy,以使初始化更加容易。
以下简短的 Python 会话显示了这两个函数的(缩写)文档:
$ python
>>> import numpy as np
>>> help(np.full)
Return a new array of given shape and type, filled with `fill_value`.
>>> help(np.full_like)返回形状和类型与给定数组相同的完整数组。
实战时间 – 使用full()和full_like()函数创建值初始化的数组
让我们演示full()和full_like()函数的工作方式。 如果您还不在 Python shell 中,请输入以下 :
$ python
>>> import numpy as np使用充满数字 42 的full()函数创建一个二分之一的数组,如下所示:
>>> np.full((1, 2), 42)
array([[ 42., 42.]])从输出可以推断出,数组元素是浮点数,这是 NumPy 数组的默认数据类型。 指定整数数据类型,如下所示:
>>> np.full((1, 2), 42, dtype=np.int)
array([[42, 42]])full_like()函数查看输入数组的元数据,并使用该信息创建一个填充有指定值的新数组。 例如,在使用linspace()函数创建数组之后,将其用作full_like()函数的模板:
>>> a = np.linspace(0, 1, 5)
>>> a
array([ 0\. , 0.25, 0.5 , 0.75, 1\. ])
>>> np.full_like(a, 42)
array([ 42., 42., 42., 42., 42.])同样,我们有一个充满42的数组。 要将数据类型更改为整数,请键入以下内容:
>>> np.full_like(a, 42, dtype=np.int)
array([42, 42, 42, 42, 42])刚刚发生了什么?
我们使用full()和full_like()函数创建了数组。 full()函数用数字42填充数组。 full_like()函数使用输入数组的元数据来创建新数组。 这两个函数都可以指定数据类型。
总结
我们使用corrcoef()函数计算了两只股票的股票收益率的相关性。 另外,我们演示了diagonal() 和trace()函数,它们可以为我们提供矩阵的对角线和迹线。
我们使用polyfit()函数将数据拟合为多项式。 我们了解了用于计算多项式值的polyval()函数,用于返回多项式根的roots()函数以及用于返回多项式导数的polyder()函数。
我们看到full()函数用数字填充数组,full_like()函数使用输入数组的元数据创建一个新数组。 这两个函数都可以指定数据类型。
希望您提高了工作效率,因此我们可以在下一章继续使用矩阵和通用函数(ufuncs)。
五、使用矩阵和ufunc
本章介绍矩阵和通用函数(ufuncs)。 矩阵在数学上是众所周知的,在 NumPy 中也具有表示。 通用函数适用于数组,逐元素或标量。 ufuncs 期望一组标量作为输入,并产生一组标量作为输出。 通用函数通常可以映射到它们的数学对应物,例如加,减,除,乘等。 我们还将介绍三角函数,按位和比较通用函数。
在本章中,我们将介绍以下主题:
- 矩阵创建
- 矩阵运算
- 基本函数
- 三角函数
- 按位函数
- 比较函数
矩阵
NumPy 中的矩阵是ndarray的子类。 我们可以使用特殊的字符串格式创建矩阵。 就像在数学中一样,它们是二维的。 正如您期望的那样,矩阵乘法不同于正常的 NumPy 乘法。 幂运算符也是如此。 我们可以使用mat(),matrix()和bmat()函数创建矩阵。
实战时间 – 创建矩阵
如果输入已经是矩阵或ndarray,则mat()函数不会复制。 调用此函数等效于调用matrix(data, copy=False)。 我们还将演示转置和求逆矩阵。
行用分号分隔,值用空格分隔。 使用以下字符串调用mat()函数以创建矩阵:
A = np.mat('1 2 3; 4 5 6; 7 8 9')
print("Creation from string", A)矩阵输出应为以下矩阵:
Creation from string [[1 2 3]
[4 5 6]
[7 8 9]]如下将矩阵转换为具有T属性的矩阵:
print("transpose A", A.T)以下是转置矩阵:
transpose A [[1 4 7]
[2 5 8]
[3 6 9]]可以使用I属性将矩阵反转,如下所示:
print("Inverse A", A.I)逆矩阵打印如下(请注意,这是O(n<sup class="calibre54">3</sup>)操作,这意味着需要平均三次时间):
Inverse A [[ -4.50359963e+15 9.00719925e+15 -4.50359963e+15]
[ 9.00719925e+15 -1.80143985e+16 9.00719925e+15]
[ -4.50359963e+15 9.00719925e+15 -4.50359963e+15]]不使用字符串创建矩阵,而是使用数组:
print("Creation from array", np.mat(np.arange(9).reshape(3, 3)))新创建的数组如下所示:
Creation from array [[0 1 2]
[3 4 5]
[6 7 8]]刚刚发生了什么?
我们使用mat()函数创建了矩阵。 我们将使用T属性将矩阵转置,并使用I属性将其反转(请参见matrixcreation.py):
from __future__ import print_function
import numpy as np
A = np.mat('1 2 3; 4 5 6; 7 8 9')
print("Creation from string", A)
print("transpose A", A.T)
print("Inverse A", A.I)
print("Check Inverse", A * A.I)
print("Creation from array", np.mat(np.arange(9).reshape(3, 3)))从其他矩阵创建矩阵
有时,我们想由其他较小的矩阵创建矩阵。 我们可以通过bmat()函数来实现。 b在这里代表块矩阵。
实战时间 – 从其他矩阵创建矩阵
我们将从两个较小的矩阵创建一个矩阵,如下所示:
首先,创建一个2×2单位矩阵:
A = np.eye(2)
print("A", A)单位矩阵如下所示:
A [[ 1\. 0.]
[ 0\. 1.]]创建另一个类似于A的矩阵,并将其乘以 2:
B = 2 * A
print("B", B)第二个矩阵如下:
B [[ 2\. 0.]
[ 0\. 2.]]从字符串创建复合矩阵。 字符串使用与mat()函数相同的格式-使用矩阵而不是数字:
print("Compound matrix\n", np.bmat("A B; A B"))复合矩阵如下所示:
Compound matrix
[[ 1\. 0\. 2\. 0.]
[ 0\. 1\. 0\. 2.]
[ 1\. 0\. 2\. 0.]
[ 0\. 1\. 0\. 2.]]刚刚发生了什么?
我们使用bmat()函数从两个较小的矩阵创建了一个块矩阵。 我们给该函数一个字符串,其中包含矩阵名称,而不是数字(请参见bmatcreation.py):
from __future__ import print_function
import numpy as np
A = np.eye(2)
print("A", A)
B = 2 * A
print("B", B)
print("Compound matrix\n", np.bmat("A B; A B"))小测验 – 使用字符串定义矩阵
Q1. mat()和bmat()函数接受的字符串中的行分隔符是什么?
- 分号
- 句号
- 逗号
- 空格
通用函数
通用函数(ufuncs)期望一组标量作为输入并产生一组标量作为输出。 它们实际上是 Python 对象,它们封装了函数的行为。 通常,我们可以将ufunc映射到它们的数学对应项,例如加,减,除,乘等。 通常,通用函数由于其特殊的优化以及在本机级别上运行而更快。
实战时间 – 创建通用函数
我们可以使用 NumPy 和frompyfunc()函数从 Python 函数创建ufunc,如下所示:
定义一个 Python 函数,该函数回答关于宇宙,存在和其他问题的最终问题(来自《银河系漫游指南》 ,道格拉斯·亚当,Pan Books,如果您还没有阅读,可以安全地忽略这一点!):
def ultimate_answer(a):到目前为止,没有什么特别的。 我们给函数命名为ultimate_answer()并定义了一个参数a。
使用zeros_like()函数,创建一个形状与a相同的所有零组成的结果:
result = np.zeros_like(a)现在,将初始化数组的元素设置为答案42,然后返回结果。 完整的函数应显示在下面的代码片段中。 flat属性使我们可以访问平面迭代器,该迭代器允许我们设置数组的值。
def ultimate_answer(a):
result = np.zeros_like(a)
result.flat = 42
return result用frompyfunc()创建一个ufunc;指定1作为输入参数的数量,然后指定1作为输出参数的数量:
ufunc = np.frompyfunc(ultimate_answer, 1, 1)
print("The answer", ufunc(np.arange(4)))一维数组的结果如下所示:
The answer [42 42 42 42]使用以下代码对二维数组执行相同的操作:
print("The answer", ufunc(np.arange(4).reshape(2, 2)))二维数组的输出如下所示:
The answer [[42 42]
[42 42]]刚刚发生了什么?
我们定义了一个 Python 函数。 在此函数中,我们使用zeros_like()函数,根据输入参数的形状将数组的元素初始化为零。 然后,使用ndarray的flat属性,将数组元素设置为最终答案42(请参见answer42.py):
from __future__ import print_function
import numpy as np
def ultimate_answer(a):
result = np.zeros_like(a)
result.flat = 42
return result
ufunc = np.frompyfunc(ultimate_answer, 1, 1)
print("The answer", ufunc(np.arange(4)))
print("The answer", ufunc(np.arange(4).reshape(2, 2)))通用函数的方法
函数如何具有方法? 如前所述,通用函数不是函数,而是表示函数的 Python 对象。 通用函数具有五种重要方法,如下:
ufunc.reduce(a[, axis, dtype, out, keepdims])ufunc.accumulate(array[, axis, dtype, out])ufunc.reduceat(a, indices[, axis, dtype, out])ufunc.outer(A, B)ufunc.at(a, indices[, b])])])
实战时间 – 将ufunc方法应用于add函数
让我们在add()函数上调用前四个方法:
通用函数沿指定元素的连续轴递归地减少输入数组。 对于add()函数,约简的结果类似于计算数组的总和。 调用reduce()方法:
a = np.arange(9)
print("Reduce", np.add.reduce(a))精简数组应如下所示:
Reduce 36accumulate()方法也递归地遍历输入数组。 但是,与reduce()方法相反,它将中间结果存储在一个数组中并返回它。 如果使用add()函数,则结果等同于调用cumsum()函数。 在add()函数上调用accumulate()方法:
print("Accumulate", np.add.accumulate(a))累积的数组如下:
Accumulate [ 0 1 3 6 10 15 21 28 36]reduceat()方法的解释有点复杂,因此让我们对其进行调用并逐步了解其算法。 reduceat()方法需要输入数组和索引列表作为参数:
print("Reduceat", np.add.reduceat(a, [0, 5, 2, 7]))结果如下所示:
Reduceat [10 5 20 15]第一步与索引0和5有关。 此步骤可减少索引0和5之间的数组元素的运算:
print("Reduceat step I", np.add.reduce(a[0:5]))步骤 1 的输出如下:
Reduceat step I 10第二步涉及索引5和2。 由于2小于5,因此返回索引为5的数组元素:
print("Reduceat step II", a[5])第二步产生以下输出:
Reduceat step II 5第三步涉及索引2和7。 此步骤可减少索引2和7之间的数组元素的运算:
print("Reduceat step III", np.add.reduce(a[2:7]))第三步的结果如下所示:
Reduceat step III 20第四步涉及索引7。 此步骤导致从索引7到数组末尾的数组元素减少操作:
print("Reduceat step IV", np.add.reduce(a[7:]))第四步结果如下所示:
Reduceat step IV 15outer()方法返回一个具有等级的数组,该等级是其两个输入数组的等级的总和。 该方法适用于所有可能的输入数组元素对。 在add()函数上调用outer()方法:
print("Outer", np.add.outer(np.arange(3), a))外部总和的输出结果如下:
Outer [[ 0 1 2 3 4 5 6 7 8]
[ 1 2 3 4 5 6 7 8 9]
[ 2 3 4 5 6 7 8 9 10]]刚刚发生了什么?
我们将通用函数的前四种方法reduce(),accumulate(),reduceat()和outer()应用于add()函数(请参见ufuncmethods.py):
from __future__ import print_function
import numpy as np
a = np.arange(9)
print("Reduce", np.add.reduce(a))
print("Accumulate", np.add.accumulate(a))
print("Reduceat", np.add.reduceat(a, [0, 5, 2, 7]))
print("Reduceat step I", np.add.reduce(a[0:5]))
print("Reduceat step II", a[5])
print("Reduceat step III", np.add.reduce(a[2:7]))
print("Reduceat step IV", np.add.reduce(a[7:]))
print("Outer", np.add.outer(np.arange(3), a))算术函数
通用算术运算符+,-和*分别隐式链接到通用函数的加,减和乘。 这意味着在 NumPy 数组上使用这些运算符之一时,将调用相应的通用函数。 除法涉及一个稍微复杂的过程。 与数组分割有关的三个通用函数是divide(),true_divide()和floor_division()。 两个运算符对应于除法:/和//。
实战时间 – 分割数组
让我们来看一下数组分割的作用:
divide()函数将截断整数除法和普通浮点除法:
a = np.array([2, 6, 5])
b = np.array([1, 2, 3])
print("Divide", np.divide(a, b), np.divide(b, a))divide()函数的结果如下所示:
Divide [2 3 1] [0 0 0]如您所见,截断发生了。
函数true_divide()更接近于除法的数学定义。 整数除法返回浮点结果,并且不会发生截断:
print("True Divide", np.true_divide(a, b), np.true_divide(b, a))true_divide()函数的结果如下:
True Divide [ 2\. 3\. 1.66666667] [ 0.5 0.33333333 0.6 ]floor_divide()函数总是返回整数结果。 等效于调用divide()函数之后调用floor()函数。 floor()函数丢弃浮点数的小数部分并返回一个整数:
print("Floor Divide", np.floor_divide(a, b), np.floor_divide(b, a))
c = 3.14 * b
print("Floor Divide 2", np.floor_divide(c, b), np.floor_divide(b, c))floor_divide()函数调用导致:
Floor Divide [2 3 1] [0 0 0]
Floor Divide 2 [ 3\. 3\. 3.] [ 0\. 0\. 0.]默认情况下,/运算符等效于调用divide()函数:
from __future__ import division但是,如果在 Python 程序的开头找到此行,则将调用true_divide()函数。 因此,此代码将如下所示:
print("/ operator", a/b, b/a)The result is shown as follows:
/ operator [ 2\. 3\. 1.66666667] [ 0.5 0.33333333 0.6 ]//运算符等效于调用floor_divide()函数。 例如,查看以下代码片段:
print("// operator", a//b, b//a)
print("// operator 2", c//b, b//c)//运算符结果如下所示:
// operator [2 3 1] [0 0 0]
// operator 2 [ 3\. 3\. 3.] [ 0\. 0\. 0.]刚刚发生了什么?
divide()函数会执行截断整数除法和常规浮点除法。 true_divide()函数始终返回浮点结果而没有任何截断。 floor_divide()函数始终返回整数结果; 结果与通过连续调用divide()和floor()函数(请参见dividing.py)获得的相同:
from __future__ import print_function
from __future__ import division
import numpy as np
a = np.array([2, 6, 5])
b = np.array([1, 2, 3])
print("Divide", np.divide(a, b), np.divide(b, a))
print("True Divide", np.true_divide(a, b), np.true_divide(b, a))
print("Floor Divide", np.floor_divide(a, b), np.floor_divide(b, a))
c = 3.14 * b
print("Floor Divide 2", np.floor_divide(c, b), np.floor_divide(b, c))
print("/ operator", a/b, b/a)
print("// operator", a//b, b//a)
print("// operator 2", c//b, b//c)勇往直前 – 尝试__future__.division
通过实验确认导入__future__.division的影响。
模运算
我们可以使用 NumPy mod(),remainder()和fmod()函数来计算模或余数。 同样,我们可以使用%运算符。 这些函数之间的主要区别在于它们如何处理负数。 该组中的奇数是fmod()函数。
实战时间 – 计算模数
让我们调用前面提到的函数:
remainder()函数以元素为单位返回两个数组的其余部分。 如果第二个数字为 0,则返回 0:
a = np.arange(-4, 4)
print("Remainder", np.remainder(a, 2))remainder()函数的结果如下所示:
Remainder [0 1 0 1 0 1 0 1]mod()函数的功能与remainder()函数的功能完全相同:
print("Mod", np.mod(a, 2))mod()函数的结果如下所示:
Mod [0 1 0 1 0 1 0 1]%运算符只是remainder()函数的简写:
print("% operator", a % 2)%运算符的结果如下所示:
% operator [0 1 0 1 0 1 0 1]fmod()函数处理负数的方式与mod()和%的处理方式不同。 余数的符号是被除数的符号,除数的符号对结果没有影响:
print("Fmod", np.fmod(a, 2))fmod()结果打印如下:
Fmod [ 0 -1 0 -1 0 1 0 1]刚刚发生了什么?
我们向 NumPy 演示了mod(),remainder()和fmod()函数,它们计算模或余数(请参见modulo.py):
from __future__ import print_function
import numpy as np
a = np.arange(-4, 4)
print("Remainder", np.remainder(a, 2))
print("Mod", np.mod(a, 2))
print("% operator", a % 2)
print("Fmod", np.fmod(a, 2))斐波那契数
斐波那契数 基于递归关系:
用 NumPy 代码直接表达这种关系是困难的。 但是,我们可以用矩阵形式表示这种关系,也可以按照黄金比例公式:
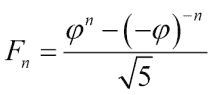
与
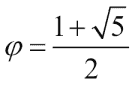
这将介绍matrix()和rint()函数。 matrix()函数创建矩阵, 数字四舍五入到最接近的整数,但结果不是整数。
实战时间 – 计算斐波纳契数
矩阵可以表示斐波那契递归关系。 我们可以将斐波纳契数的计算表示为重复的矩阵乘法:
如下创建斐波那契矩阵:
F = np.matrix([[1, 1], [1, 0]])
print("F", F)斐波那契矩阵如下所示:
F [[1 1]
[1 0]]通过从 8 减去 1 并取矩阵的幂,计算出第 8 个斐波那契数(忽略 0)。 斐波那契数然后出现在对角线上:
print("8th Fibonacci", (F ** 7)[0, 0])斐波那契数如下:
8th Fibonacci 21“黄金比例”公式(又称为“Binet”公式)使我们能够计算斐波纳契数,并在最后进行四舍五入。 计算前八个斐波那契数:
n = np.arange(1, 9)
sqrt5 = np.sqrt(5)
phi = (1 + sqrt5)/2
fibonacci = np.rint((phi**n - (-1/phi)**n)/sqrt5)
print("Fibonacci", fibonacci)前八个斐波那契数如下:
Fibonacci [ 1\. 1\. 2\. 3\. 5\. 8\. 13\. 21.]刚刚发生了什么?
我们用两种方法计算了斐波那契数。 在此过程中,我们了解了用于创建矩阵的matrix()函数。 我们还了解了rint()函数,该函数将数字四舍五入到最接近的整数,但不将类型更改为整数(请参见fibonacci.py):
from __future__ import print_function
import numpy as np
F = np.matrix([[1, 1], [1, 0]])
print("F", F)
print("8th Fibonacci", (F ** 7)[0, 0])
n = np.arange(1, 9)
sqrt5 = np.sqrt(5)
phi = (1 + sqrt5)/2
fibonacci = np.rint((phi**n - (-1/phi)**n)/sqrt5)
print("Fibonacci", fibonacci)勇往直前 – 时间计算
您可能想知道哪种方法更快,因此请继续并确定时间。 用frompyfunc()创建通用的斐波那契函数,并对其计时。
利萨如曲线
所有标准的三角函数,例如sin,cos,tan等,都由 NumPy 中的通用函数表示)。利萨如曲线是使用三角函数的一种有趣方式。 我记得在物理实验室的示波器上制作了李沙育的数字。 两个参数方程式描述了这些图形:
x = A sin(at + π/2)
y = B sin(bt)实战时间 – 绘制利萨如曲线
利萨如的数字是由A,B,a和b四个参数确定的 。 为了简单起见,我们将A和B设置为1:
将具有linspace()函数的t从-pi初始化为具有201点的pi:
a = 9
b = 8
t = np.linspace(-np.pi, np.pi, 201)使用sin()函数和np.pi计算x:
x = np.sin(a * t + np.pi/2)使用sin()函数计算y:
y = np.sin(b * t)如下图所示:
plt.plot(x, y)
plt.title('Lissajous curves')
plt.grid()
plt.show()a = 9和b = 8的结果如下:
刚刚发生了什么?
我们用上述参数方程式绘制了利萨如曲线,其中A=B=1,a=9和b=8。 我们使用了sin()和linspace()函数,以及 NumPy pi常量(请参见lissajous.py):
import numpy as np
import matplotlib.pyplot as plt
a = 9
b = 8
t = np.linspace(-np.pi, np.pi, 201)
x = np.sin(a * t + np.pi/2)
y = np.sin(b * t)
plt.plot(x, y)
plt.title('Lissajous curves')
plt.grid()
plt.show()方波
方波也是您可以在示波器上查看的那些整洁的东西之一。 正弦波可以很好地将其近似为 。 毕竟,方波是可以用无限傅立叶级数表示的信号。
注意
傅立叶级数是以著名数学家让·巴蒂斯特·傅立叶(Jean-Baptiste Fourier)命名的,一系列正弦和余弦项之和。
代表方波的该特定系列的公式如下:
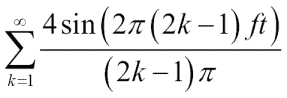
实战时间 – 绘制方波
就像上一节一样,我们将初始化t。 我们需要总结一些术语。 术语数量越多,结果越准确; k = 99应该足够。 为了绘制方波,请按照下列步骤操作:
我们将从初始化t和k开始。 将该函数的初始值设置为0:
t = np.linspace(-np.pi, np.pi, 201)
k = np.arange(1, 99)
k = 2 * k - 1
f = np.zeros_like(t)使用sin()和sum()函数计算函数值:
for i, ti in enumerate(t):
f[i] = np.sum(np.sin(k * ti)/k)
f = (4 / np.pi) * f要绘制的代码与上一节中的代码几乎相同:
plt.plot(t, f)
plt.title('Square wave')
plt.grid()
plt.show()用k = 99生成的所得方波如下:
刚刚发生了什么?
我们使用 sin()函数生成了方波,或者至少是它的近似值。 输入值通过 linspace()函数进行组装,而k值通过arange()函数进行组装(请参见squarewave.py):
import numpy as np
import matplotlib.pyplot as plt
t = np.linspace(-np.pi, np.pi, 201)
k = np.arange(1, 99)
k = 2 * k - 1
f = np.zeros_like(t)
for i, ti in enumerate(t):
f[i] = np.sum(np.sin(k * ti)/k)
f = (4 / np.pi) * f
plt.plot(t, f)
plt.title('Square wave')
plt.grid()
plt.show()勇往直前 – 摆脱循环
您可能已经注意到代码中存在一个循环。 使用 NumPy 函数摆脱它,并确保性能也得到改善。
锯齿波和三角波
锯齿波和三角波也是在示波器上容易看到的现象。 就像方波一样,我们可以定义无限傅立叶级数。 三角波可以通过获取锯齿波的绝对值来找到。 表示一系列锯齿波的公式如下:
实战时间 – 绘制锯齿波和三角波
就像上一节一样,我们初始化t。 同样,k = 99应该足够。 为了绘制锯齿波和三角波,请按照下列步骤操作:
将该函数的初始值设置为zero:
t = np.linspace(-np.pi, np.pi, 201)
k = np.arange(1, 99)
f = np.zeros_like(t)使用sin()和sum()函数计算函数值:
for i, ti in enumerate(t):
f[i] = np.sum(np.sin(2 * np.pi * k * ti)/k)
f = (-2 / np.pi) * f绘制锯齿波和三角波很容易,因为三角波的值应等于锯齿波的绝对值。 绘制波形,如下所示:
plt.plot(t, f, lw=1.0, label='Sawtooth')
plt.plot(t, np.abs(f), '--', lw=2.0, label='Triangle')
plt.title('Triangle and sawtooth waves')
plt.grid()
plt.legend(loc='best')
plt.show()在下图中,三角形波是带有虚线的波:
刚刚发生了什么?
我们使用sin()函数绘制了锯齿波 。 我们将输入值与linspace()函数组合在一起,并将k值与arange()函数组合在一起。 通过取绝对值从锯齿波中产生一个三角波(请参见sawtooth.py):
import numpy as np
import matplotlib.pyplot as plt
t = np.linspace(-np.pi, np.pi, 201)
k = np.arange(1, 99)
f = np.zeros_like(t)
for i, ti in enumerate(t):
f[i] = np.sum(np.sin(2 * np.pi * k * ti)/k)
f = (-2 / np.pi) * f
plt.plot(t, f, lw=1.0, label='Sawtooth')
plt.plot(t, np.abs(f), '--', lw=2.0, label='Triangle')
plt.title('Triangle and sawtooth waves')
plt.grid()
plt.legend(loc='best')
plt.show()勇往直前 – 摆脱循环
如果您选择接受 ,那么您面临的挑战是摆脱程序中的循环。 它应该可以与 NumPy 函数一起使用,并且性能应该得到改善。
按位和比较函数
按位函数是整数或整数数组的位,因为它们是通用函数。 运算符^,&,|,<<,>>等具有其 NumPy 对应物。 比较运算符,例如<,>和==等也是如此。 这些运算符使您可以做一些巧妙的技巧,从而提高性能; 但是,它们会使您的代码难以理解,因此请谨慎使用。
实战时间 – 翻转位
现在,我们将介绍三个技巧:检查整数的符号是??否不同,检查数字是否为2的幂,以及计算作为2的幂的数字的模数。 我们将展示一个仅用于运算符的符号,以及一个使用相应的 NumPy 函数的符号:
第一个技巧取决于XOR或^运算符。 XOR运算符也称为不等式运算符; 因此,如果两个操作数的符号位不同,则XOR运算将导致负数。
下面的真值表说明了XOR运算符:
输入 1 | 输入 2 | 异或 |
|---|---|---|
True | True | False |
False | True | True |
True | False | True |
False | False | False |
^运算符对应于bitwise_xor()函数,<运算符对应于less()函数:
x = np.arange(-9, 9)
y = -x
print("Sign different?", (x ^ y) < 0)
print("Sign different?", np.less(np.bitwise_xor(x, y), 0))结果为 ,如下所示:
Sign different? [ True True True True True True True True True False True True
True True True True True True]
Sign different? [ True True True True True True True True True False True True
True True True True True True]正如预期的那样,除零以外,所有符号均不同。
2 的幂由 1 表示,后跟一系列二进制表示的尾随零。 例如,10,100或1000。 比 2 的幂小 1 的数字将由一排二进制 1 表示。 例如,11,111或1111(或十进制中的3,7和15)。 现在,如果我们对 2 的幂,和比它小 1 的整数进行“与”运算,则应该得到 0。
AND运算符的真值表如下所示:
输入 1 | 输入 2 | AND |
|---|---|---|
True | True | True |
False | True | False |
True | False | False |
False | False | False |
&的 NumPy 对应项是bitwise_and(),==的对应项是equal()通用函数:
print("Power of 2?\n", x, "\n", (x & (x - 1)) == 0)
print("Power of 2?\n", x, "\n", np.equal(np.bitwise_and(x, (x - 1)), 0))The result is shown as follows:
Power of 2?
**[-9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 8]**
[False False False False False False False False False True True True
False True False False False True]
Power of 2?
**[-9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 8]**
[False False False False False False False False False True True True
False True False False False True]当计算整数的 2 的幂的模数时,例如 4、8、16 等,计算 4 的模数的技巧实际上起作用。 左移导致值加倍。我们在上一步中看到,从 2 的幂中减去 1 会导致二进制表示形式的数字带有一行诸如 11、111 或 1111 之类的数字。 这基本上给了我们一个掩码。 用这样的数字按位与,得到的余数为 2。 NumPy 的<<的等价物是left_shift()通用函数:
print("Modulus 4\n", x, "\n", x & ((1 << 2) - 1))
print("Modulus 4\n", x, "\n", np.bitwise_and(x, np.left_shift(1, 2) - 1))The result is shown as follows:
Modulus 4
**[-9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 8]**
[3 0 1 2 3 0 1 2 3 0 1 2 3 0 1 2 3 0]
Modulus 4
**[-9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 8]**
[3 0 1 2 3 0 1 2 3 0 1 2 3 0 1 2 3 0]刚刚发生了什么?
我们介绍了三点技巧:检查整数的符号是??否不同,检查数字是否为2的幂,并计算数字的模数为2的幂。 我们看到了运算符^,&,<<和<的 NumPy 对应项(请参见bittwidling.py):
from __future__ import print_function
import numpy as np
x = np.arange(-9, 9)
y = -x
print("Sign different?", (x ^ y) < 0)
print("Sign different?", np.less(np.bitwise_xor(x, y), 0))
print("Power of 2?\n", x, "\n", (x & (x - 1)) == 0)
print("Power of 2?\n", x, "\n", np.equal(np.bitwise_and(x, (x - 1)), 0))
print("Modulus 4\n", x, "\n", x & ((1 << 2) - 1))
print("Modulus 4\n", x, "\n", np.bitwise_and(x, np.left_shift(1, 2) - 1))花式索引
at()方法是在 NumPy 1.8 中添加的 。 此方法允许原地建立花式索引。 花式索引是不涉及整数或切片的索引 ,这是正常的索引。 原地意味着将对我们操作的数组进行修改。
at()方法的签名为ufunc.at(a, indices[, b])。 indices数组指定要操作的元素。 我们仅需要b数组用于具有两个操作数的通用函数。 以下“实战时间”部分给出了at()方法的示例 。
实战时间 – 使用at()方法为 ufuncs 原地建立索引
要演示方法的工作方式,请启动 Python 或 IPython shell 并导入 NumPy。 您现在应该知道如何执行此操作。
创建一个由七个随机整数组成的数组,该整数从-3到3,种子为42:
>>> a = np.random.random_integers(-3, 3, 7)
>>> a
array([ 1, 0, -1, 2, 1, -2, 0])当我们在编程中谈论随机数字时,我们通常会谈论伪随机数。 这些数字看起来是随机的,但实际上是使用种子来计算的。
将sign()通用函数的at()方法应用于第四和第六个数组元素:
>>> np.sign.at(a, [3, 5])
>>> a
array([ 1, 0, -1, 1, 1, -1, 0])刚刚发生了什么?
我们使用at()方法来选择数组元素,并执行原地操作-确定符号。 我们还学习了如何创建随机整数。
总结
在本章中,您学习了关于矩阵和通用函数的知识。 我们介绍了如何创建矩阵,并研究了通用函数如何工作。 您简要介绍了算术,三角函数,按位和比较通用函数。
在下一章中,您将介绍 NumPy 模块。