组会系列 | Tokens-to-Token ViT:真正意义上击败了CNN
组会系列 | Tokens-to-Token ViT:真正意义上击败了CNN


导读:ViT在图像领域已经大放异彩,但是ViT在数据量不够巨大的情况下是逊色于ResNet的。于是ViT的升级版T2T-ViT横空出世了,速度更快性能更强。T2T-ViT相比于ViT,参数量和MACs(Multi-Adds)减少了200%,性能在ImageNet上又有2.5%的提升。T2T-ViT在和ResNet50模型大小差不多的情况下,在ImageNet上达到了80.7%的准确率。
项目代码:https://github.com/yitu-opensource/T2T-ViT
1.研究背景与动机:
Vision Transformer (ViT) 是最近的一种使用 Transformer 模型解决视觉任务的方法,这种模型在语言建模方面很受欢迎。然而,当在像 ImageNet 这样的中等规模数据集上从头开始训练时,ViT 的表现要低于卷积神经网络 (CNN)。ViT 的局限性包括其对输入图像进行简单的分词,未能建模包括边缘和线条在内的局部结构,以及具有冗余的注意力骨干设计,从而导致功能丰富性有限并且模型训练存在困难。
尽管视觉转换器(ViT)证明了全Transformer架构在视觉任务中是具有前途的,但是在从头开始训练中尚未达到类似大小的卷积神经网络(如ResNets)的表现水平(例如,ImageNet)。我们假设ViT的这种性能差距来源于ViT的两个主要限制:
- 由于ViT是采用硬拆分对原图像分块,然后做Linear Projection得到embedding。但是通过实验发现,这种基于原图像的简单tokenization并没有很好地学到图像的边缘或者线条这种低级特征,导致ViT算法的学习效率不高,难以训练,因此ViT需要大量的数据进行训练。
- ViT的关注骨干不适用于视觉任务,其中包含了冗余部分,导致特征丰富度有限且模型训练困难。

本文首先分析了 Resnet50、Vision Transformer 和 T2T Transformer 的特征可视化。其中,绿框标注的是浅层特征,如边缘和线条;红框标注的是零值或过大值。
我们首先来看看熟悉的 CNN。在比较浅的层中,网络学习到更多的是结构信息,比如对这只小狗边缘的刻画。随着层数加深,通道数变深,特征也越来越抽象。
ViT(视觉transformer)的特征却非常不同:结构信息建模较差(我觉得可能是这是因为没有类似 CNN 卷积核划窗的操作,导致对于局部信息捕捉不够?) ,而全局关系(例如整只狗)可以被所有注意力块捕获。当直接将图像分割为固定长度的标记时,纯ViT无视局部结构。 除此之外,在一些特征图出现了极值,如全白和全黑的特征,对于最终预测可能是没有贡献的。这意味着ViT的支持骨干不像ResNets那样高效,并且在训练样本不足时提供的特征丰富度有限。
但是本文的T2T Transformer。通过 Token to Token 结构 ,它在浅层的时候也能建模出结构信息,同时也避免了极值的出现。
2.贡献
?首次通过精心设计变压器架构(T2T模块和高效骨干),我们展示了ViT可以在ImageNet上不需要在JFT-300M上进行预训练的不同复杂度上胜过CNN。
?我们开发了一种新的渐进式token化方法,可为ViT提供优越性能,还提出了T2T模块,通过逐步聚合相邻token来结构化图像为token(token到token),从而可以建模周围token所代表的局部结构,并可以减少token长度。
?我们展示了CNN的架构工程能够使ViT的骨架设计受益,以提高特征的丰富性并减少冗余。通过大量实验,我们发现深窄的架构设计对ViT效果最佳。
3.方法
3.1 T2T Pipeline
由于基础的ViT的骨干网络中有许多无效通道(图2),我们计划为我们的T2T-ViT找到一个有效的骨干网络,以减少冗余并提高特征丰富性。因此,我们探索了不同的ViT架构设计,并借鉴了一些CNN的设计来提高骨干网络效率和增强学习到的特征的丰富性。
由于每个Transformer层都具有类似ResNets的跳跃连接,因此一个直接的想法是应用DenseNet [21]的密集连接来增加连接性和特征丰富性,或者应用Wide-ResNets或ResNeXt结构来改变ViT骨干网络中的通道维度和头数。我们从CNN到ViT探索了五种不同的架构设计:
1. 密集连接,如DenseNet [21];
2. 深窄与浅宽结构,如WideResNets
3. 通道注意力,如Squeeze-an-Excitation(SE)网络
4. 多头注意力层中更多拆分头,如ResNeXt
5. Ghost操作,如GhostNet
作者对这些结构转移进行了广泛的实验。经验性地发现:
- 更深更窄(Deep Narrow)ViT结构比更浅更宽(Shallow Wide )的性能更好
- DenseNet的密集concat结构均使ViT和T2T-ViT性能下降
- SE注意力模块 均能提升ViT和T2T-ViT的性能
- ResNext结构对于ViT和T2T-ViT的 性能提升很微弱
- GhostNet结构可以 进一步压缩模型大小,但同样会损失一定性能
基于上述实验,作者选择了Deep Narrow的结构形式,如下图所示
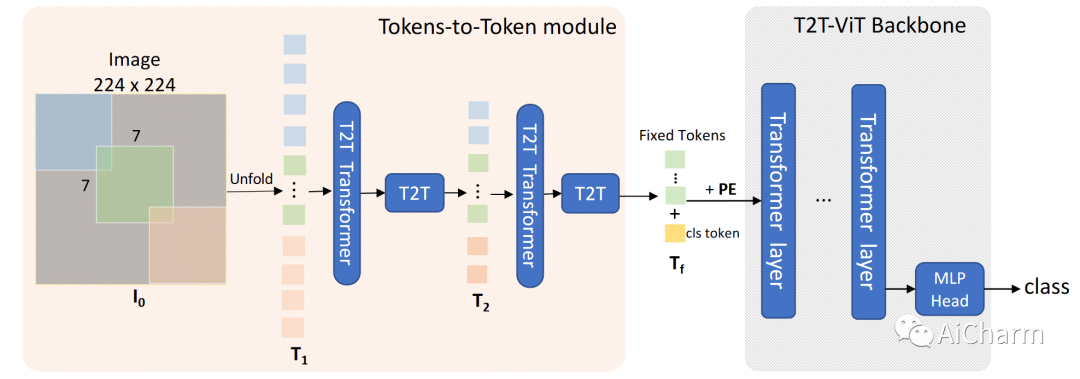
T2T-ViT由两部分组成:Tokens-to-Token (T2T)模块和T2T-ViT主干。T2T模块存在各种可能的设计选择。T2T-ViT主干从T2T模块中取得具有固定长度的token作为输入,与ViT相同;但是具有较小的隐藏维度(256-512)和MLP大小(512-1536)的深狭架构设计。
3.2 Token to Token :Progressive Tokenization
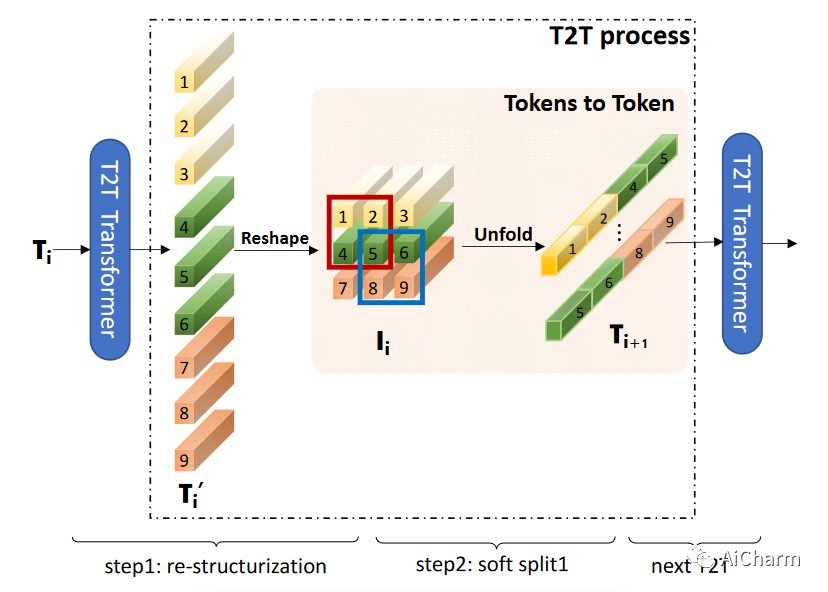
Token-to-Token (T2T) 模块旨在克服 ViT 中简单分词的局限性。它逐步将图像结构化为标记,并对局部结构信息进行建模,通过这种方式可以迭代地减少标记长度。每个 T2T 过程有两个步骤:重构(step 1)和软分割 (SS)(step 2)。

3.2.1 re-structurization 重构
上图中所示的重组过程。假设存在一个来自前置变换层的token序列T,它将通过自注意力块(图中的T2T Transformer)进行转换:T' = MLP(MSA(T)), 然后,将标记T'在空间维度上重塑为图像,得到 I = Reshape(T')。
3.2.2 soft spliit 软分割
相比Vision Transformer是将二维图片展平成一维向量(也叫token),然后送入到Transoformer结构里。
T2T为了捕捉局部信息,它将所有的token通过reshape操作,恢复成二维(重构),然后利用一个unfold一个划窗操作,属于一个窗口的tokens,会连接成一个更长的token,然后送入到Transformer中。

这样会逐渐减少token的数量,但随之而来token的长度会增加很多(因为多个tokens连接在一个token),因此后续模型也降低了维度数目,以平衡计算量。
在进行软分割时,每个patch的大小为k×k,重叠s,对图像进行p填充,其中k-s类似于卷积操作的步幅。因此,对于重构图像I∈Rh×w×c,软分割后输出的token T0的长度为:

通过以上重构和软分割的迭代,T2T模块可以逐步减少token的长度并转换图像的空间结构。T2T模块中的迭代过程可以公式化:

4. Experiments
4.1 T2T-ViT on ImageNet
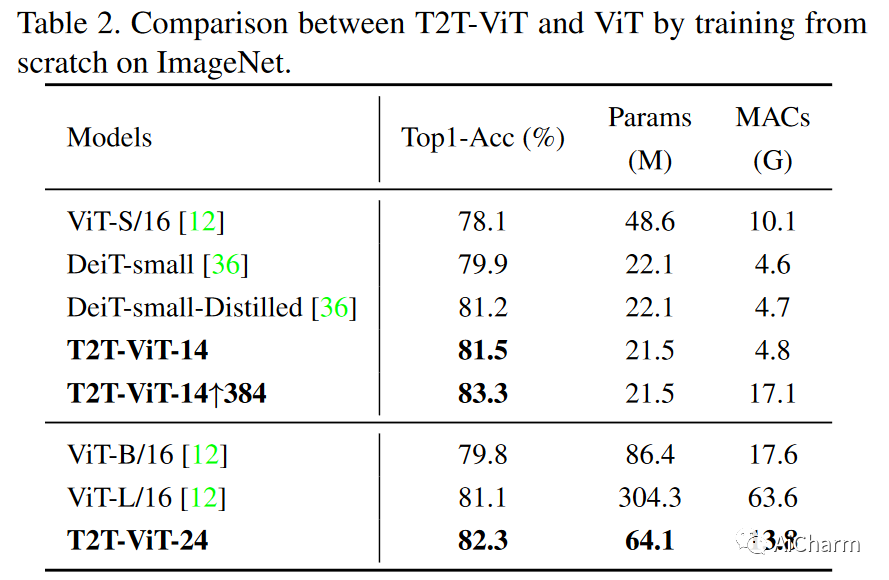
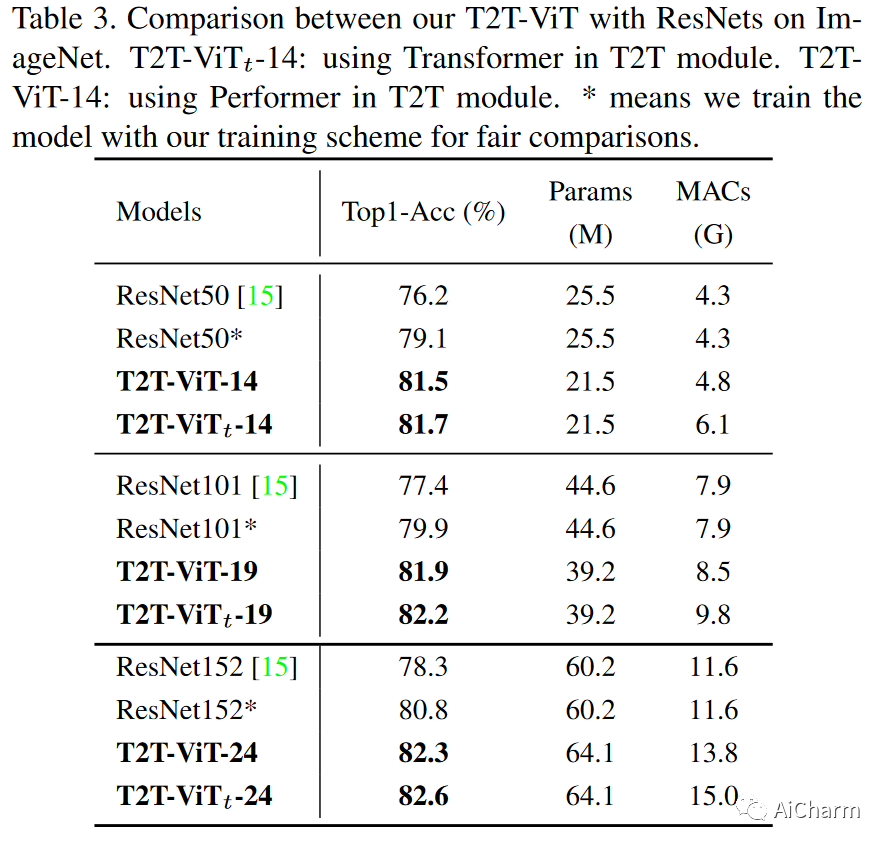
在ImageNet上的实验中,我们将默认图像大小设置为224×224,除了某些特定情况外,还采用一些常见的数据增强方法,如mixup 和cutmix ,用于CNN和ViT&T2T-ViT模型训练,因为ViT模型需要更多的训练数据才能达到合理的性能。我们使用AdamW作为优化器和余弦学习率衰减训练这些模型310个epoch。实验设置的详细信息在附录中给出。我们在T2T模块中同时使用了Transformer层和Performer层来构建我们的模型,从而得到了T2T-ViTt-14/19/24(Transformer)和T2T-ViT14/19/24(Performer)模型。
4.2 From CNN to ViT

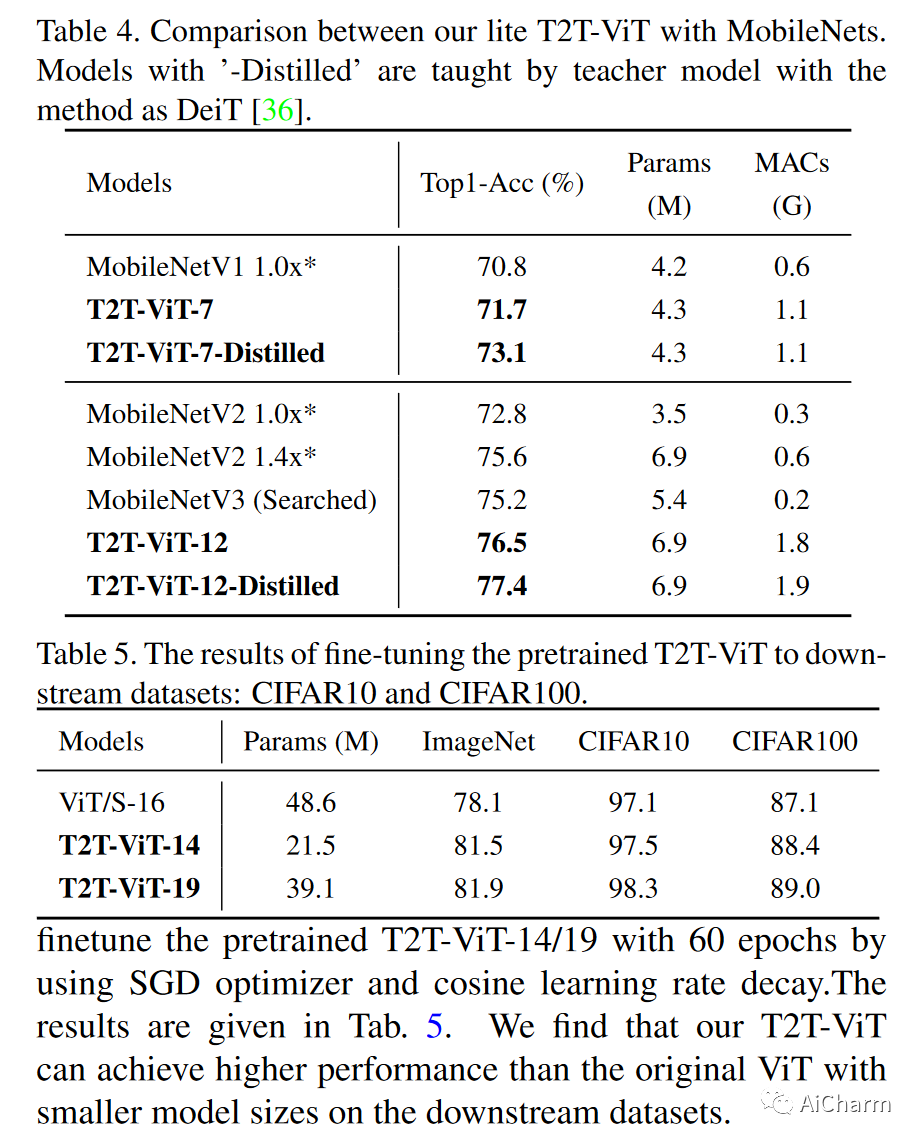
为了寻找Vision Transformer的高效骨干结构,我们在实验中应用了DenseNet结构、Wide-ResNet结构(宽或窄通道维度)、SE块(通道注意力)、ResNeXt结构(在多头注意力中使用更多头)和从CNN到ViT的Ghost操作。这些架构设计的细节在附录中给出。从表6中对“从CNN到ViT”的实验结果可以发现,SE(ViT-SE)和Deep-Narrow结构(ViT-DN)都有助于ViT,但最有效的结构是Deep-Narrow结构,该结构减小了模型大小和MACs近2倍,并在基线模型ViT-S/16上带来了0.9%的改善。
5.Conclusion
在这项工作中,提出了一种新的T2T-ViT模型,可以从头开始在ImageNet上进行训练,并达到与CNN甚至更好的性能。T2T-ViT有效地对图像的结构信息进行建模,并增强特征丰富性,克服了ViT的局限性。它引入了新的token到token(T2T)过程,逐步将图像token化为token并结构化聚合token。我们还探索了来自CNN的各种架构设计选择,以改善T2T-ViT的性能,并实证发现深窄的架构比浅宽的结构表现更好。当从头开始在ImageNet上进行训练时,我们的T2TViT在模型大小相似的情况下,比ResNets的性能更好,比MobileNets的性能相当。它为进一步开发基于变压器的视觉任务模型铺平了道路。