组会系列 | Visual Saliency Transformer: 视觉显著性检测Tranformer
组会系列 | Visual Saliency Transformer: 视觉显著性检测Tranformer


导读:目前先进的显著性目标检测方法在很大程度上依赖于卷积神经网络架构。而我们选择从序列到序列的角度来重新思考这个任务,通过建模长范围依赖来进行显著性预测,这是无法用卷积实现的。具体来说,我们为RGB和RGB-D显著性目标检测这两个任务提出了一个基于Transformer的统一模型,命名为Visual Saliency Transformer (VST)。它将原始图片裁剪成图片块后作为输入,接着利用Transformer在图片块之间传播全局上下文信息。不同于Vision Transformer (ViT)方法里的传统架构,我们在Transformer架构下利用多层级tokens融合方法和一个新提出的token上采样方法,来获得高分辨率的显著性检测结果。我们还设计了一个基于token的多任务解码器,它可以通过两个任务相关的tokens和一个新提出的patch-task-attention来同时进行显著性检测和边缘检测。我们提出的VST模型在RGB和RGB-D显著性检测两个任务上都超过了先前的方法。更加重要的是,我们提出的架构不仅为显著性检测领域提供了一个全新的视角,而且还为基于Transformer架构的密集型预测任务提供了一个新的范式。
项目代码:https://github.com/nnizhang/VST
1.研究背景与动机:
目前,基于卷积神经网络架构的先进的显著性检测方法虽然已经取得了很好的效果,但是在学习全局信息方面仍存在一定缺陷。对于显著性目标检测而言,全局上下文信息和全局对比度非常重要。
然而,由于卷积操作是在局部滑动窗口中提取特征,因此以前基于卷积神经网络架构的方法很难去探索关键的全局信息。
Transformer 方法 在编码器和解码器中多次堆叠自注意力层,从而在每一层都实现了全局长范围依赖建模。因此,将 Transformer 引入显著性检测来探索全局长范围依赖是非常可行的。
但是将 ViT应用于显著性检测并不容易。主要有以下2个问题:
- 如何利用纯 Transformer 模型解决密集型任务是一个需要解决的问题;
- ViT[2] 将图片处理成非常粗糙的尺寸,如何将 ViT 适应到显著性检测任务上来获取高分辨率的预测结果也是需要解决的。
2.贡献
为了解决这些问题,首次从序列到序列建模的新视角,基于纯Transformer架构,设计了一个新型的统一模型,用于RGB和RGB-D SOD。作者设计了一个基于 token 的多任务解码器,并通过引入任务相关的 tokens 来学习决策。
作者还提出了一个新的 patch-task-attention 机制,以生成密集预测结果,并为密集型预测任务中使用 Transformer 提供了新的范式。受到先前利用边缘检测来提高显著性检测性能的方法的启发,设计了多任务解码器,通过引入显著性 token 和边缘 token 来实现同时进行显著性检测和边缘检测。
作者还提出了一个新的 RT2T 转化算法,即反向 T2T 转化算法,可以将每个 token 扩展为多个子 token 来实现对 tokens 的上采样。并将它们与编码器中的低层级 tokens 进行融合,以获得最终的全分辨率显著图。
此外,还使用了跨模态 Transformer 来探究 RGB-D 显著性检测中多模态信息之间的相互作用。最终,我们提出的 VST 模型在参数量和计算成本相当的情况下,在 RGB 和 RGB-D 显著性检测上都超过了现有的先进方法。
3.方法
3.1 VST Pipeline
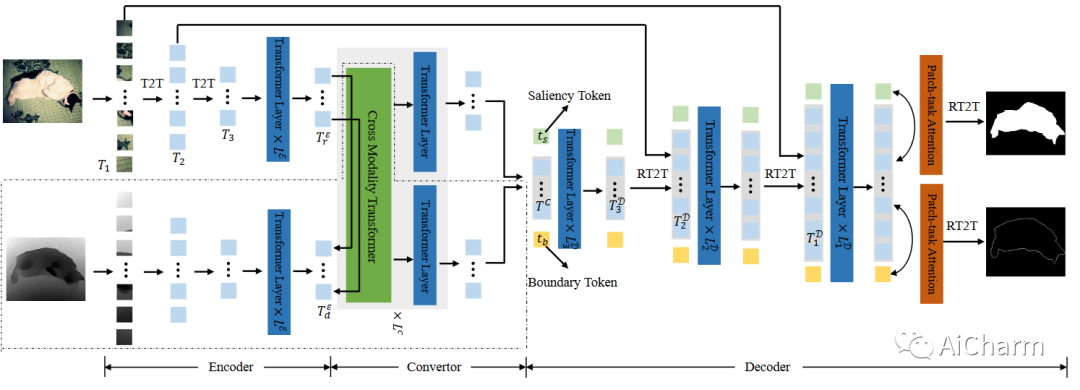
ViT 将每个图像分成一系列扁平化的二维块,然后采用变换器进行图像分类。T2T-ViT 采用 T2T 模块来建模局部结构,从而生成多尺度令牌特征。在这项工作中,我们采用 T2T-ViT 作为骨干,并提出了一种新颖的多任务解码器和一个反向T2T token上采样方法。值得注意的是,我们使用任务相关token的方式与之前的模型不同。在此之前,class-token直接通过在token嵌入上采用多层感知机用于图像分类。然而,我们无法直接从单个任务token中获得密集预测结果。因此,我们建议在patch-token和task-token之间执行patch-task-attention ,以预测显着性和边界图。
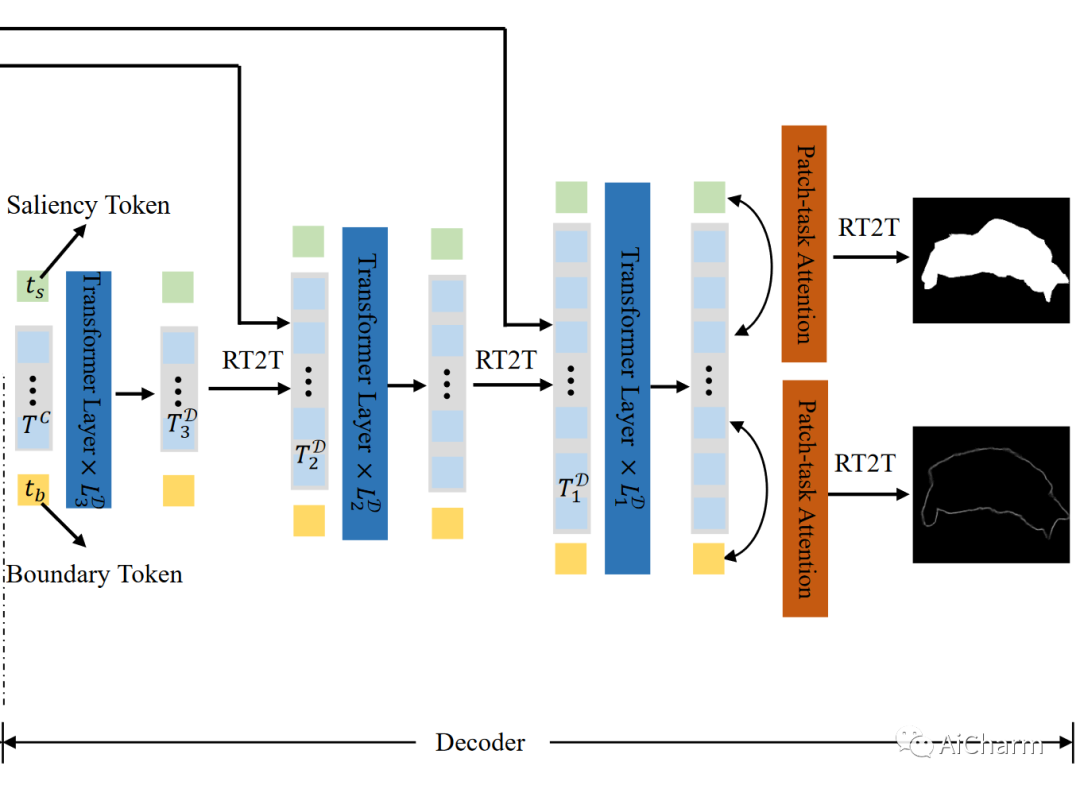
VST 的整体框架如图 1 所示。首先,编码器从裁剪后的图片块序列中生成多层级的 tokens。然后,转化器将 patch tokens 转换到解码器空间,同时使用 RGB-D 数据进行多模态信息融合。最后,解码器通过与任务相关的 tokens 和 patch-task-attention 同时预测显著图和边缘图,并使用 RT2T 算法对 patch tokens 进行上采样。
3.2 Transformer Encoder
与其他基于CNN的SOD方法类似,它们经常使用预训练图像分类模型,如VGG 和ResNet 作为其编码器的主干以提取图像特征,我们采用预训练的T2T-ViT 模型(上一篇组会系列解析的模型)作为我们的主干。
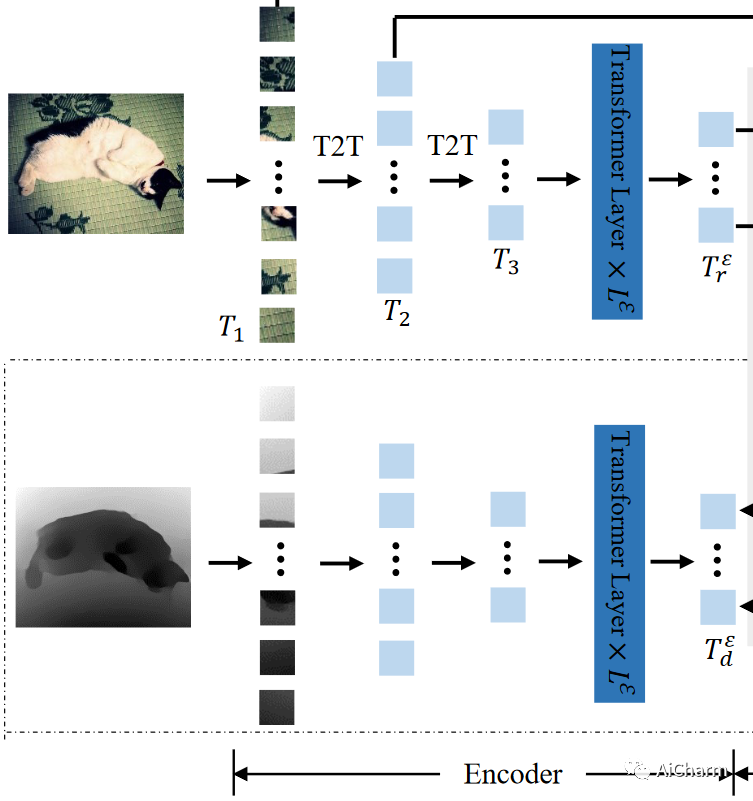
3.2 Transformer Convertor
与在变压器编码器和解码器之间插入一个转换器模块,用来将编码器得到的patch tokens从编码器空间转化到解码器空间。
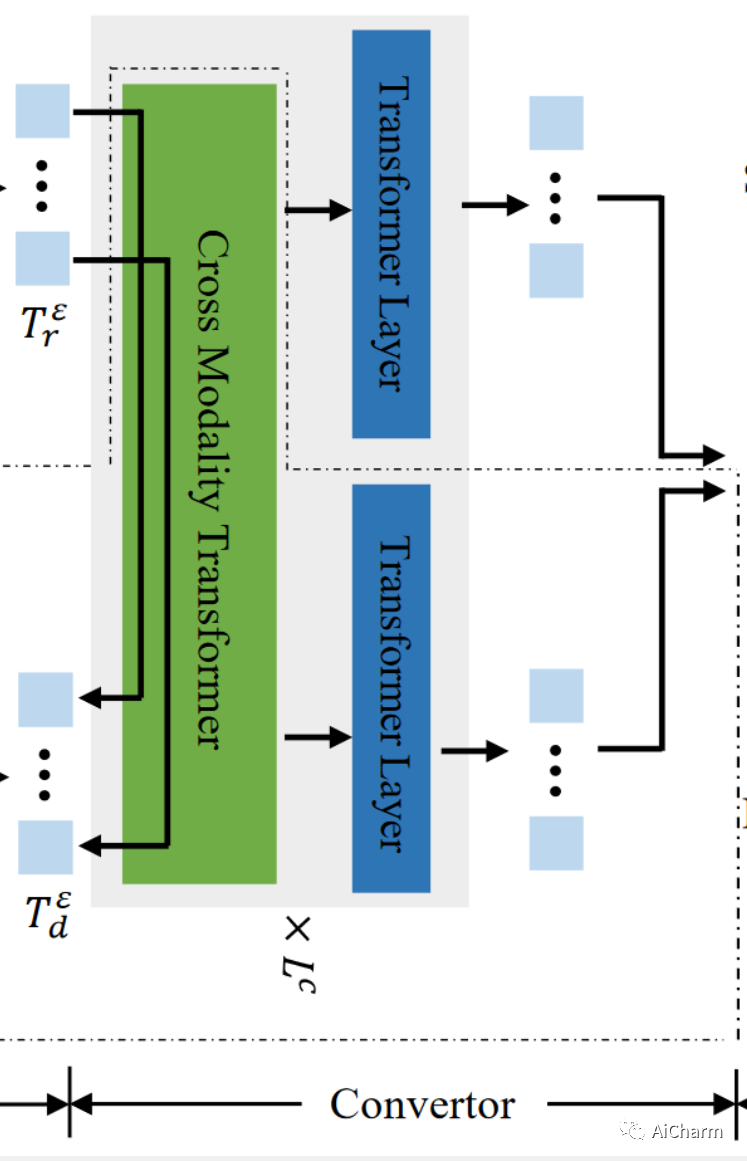
1.RGB-D转化器
对于RGB-D显著性检测,作者设计了一个跨模态Transformer(CMT)来融合从编码器中提取到的RGB patch tokens 和深度patch tokens 。具体来说,我们修改了标准的self-attention层来传播RGB图像和深度数据之间的长范围跨模态依赖,具体方案如下:
首先,类似于标准的self-attention层,我们通过三个线性投影操作将 转化成查询 , 键 和值 。同时用另外三个线性投影操作将 也进行转化,得到 、 和 。
接着,我们计算来自一种模态的查询和另一种模态的键之间的attention,然后和值加权求和得到最终的输出,整个过程可表示成:
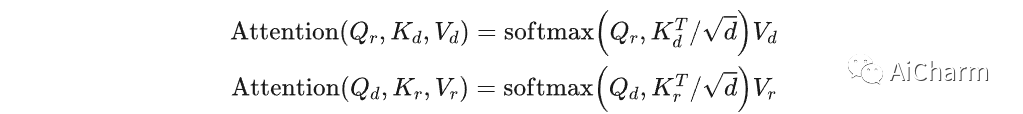
经过上述流程后,我们又给RGB patch tokens和深度patch tokens分别应用一个标准的transformer层。最后,我们将获得的RGB patch tokens和深度patch tokens级联起来并投影得到最终转化后的patch tokens 。
2. RGB 转化器
对于RGB显著性检测,直接在RGB patch tokens 上应用标准的transformer层来获得转化后的patch tokens 。
3.3 Multi-task Transformer Decoder
解码器旨在将patch-token 解码为显著性图。因此,我们提出了一种新的token上采样方法,以及多级token融合和基于token的多任务解码器。
1.Token上采样
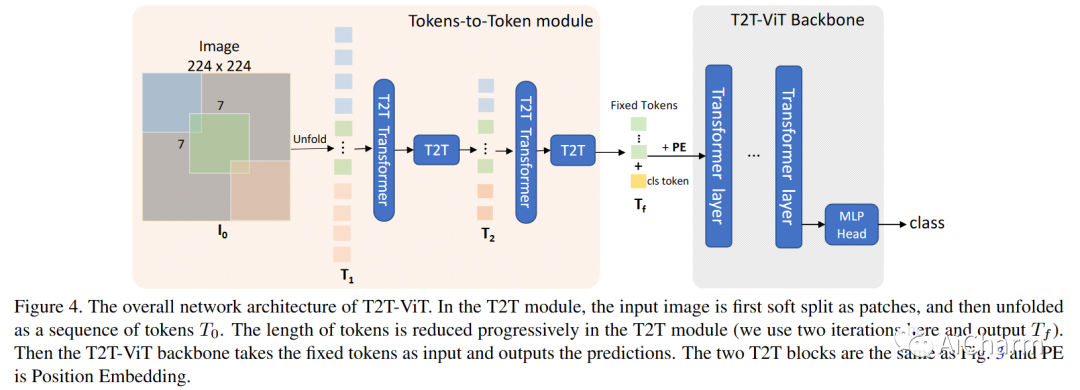
假设H和W是图片的高和宽,我们得到的 的长度相对较小,只有 。所以我们认为直接用 来预测显著图无法得到满意的结果。因此,我们选择先上采样 然后再进行预测。大多数基于卷积神经网络的方法通常采用双线性插值来恢复特征图的尺寸,而我们在transformer的架构下设计了一种新的token上采样方法。如图2(a)所示,T2T模块[3]将邻近的tokens整合从而逐步地缩减tokens的长度。受到T2T的启发,我们提出了一种RT2T(反向T2T)的转换,通过将每个token扩展成多个子token来达到上采样tokens的目的,如图2(b)所示。
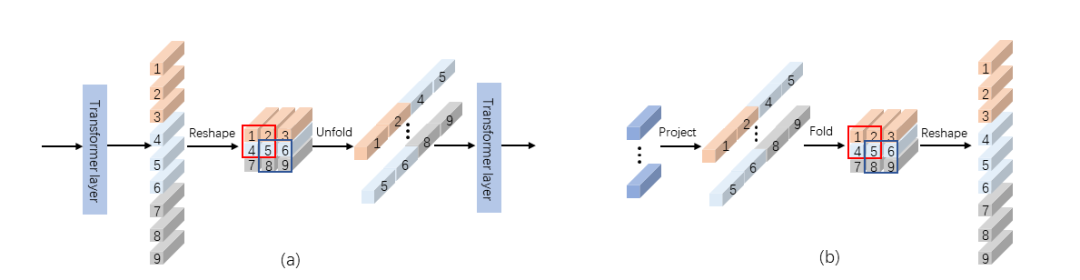
图 2.(a) T2T 模块[3] (b) 本文所提出的RT2T上采样方法
具体来说,我们首先使用一个线性投影将patch tokens的维度从 扩展到 。接下来,类似于T2T[3]中的soft split操作,我们将每一个token看作成一个 图像块,相邻的patches之间重叠为 ,zero-padding为 ,即可将tokens折叠(fold)为图像。最后,我们将图像重新reshape成tokens,即得到上采样后的tokens。
2. 多级token融合
我们利用来自 T2T-ViT 编码器的具有更长长度的低级 token,即 和 ,以提供准确的局部结构信息。对于 RGB 和 RGB-D SOD,仅使用来自 RGB 变压器编码器的低级 token。具体而言,通过串联和线性投影逐步融合 和 与上采样的 patch token。然后,接着采用一个transformer层来获得decoder tokens 。整个过程的公式化表示如下:
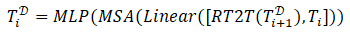
[,] 表示沿着token的嵌入维度进行级联操作,“Linear”表示级联后采用的线性投影来降低维度。其中 。
3. 基于token的多任务解码器
受现有的纯变压器方法的启发,图像分类在patch-token序列中添加了一个cls-token,我们也利用任务相关的token来预测结果。然而,不能直接在task-token嵌入上使用MLP来获得密集预测结果。因此,建议在patch-token和task-token之间执行patch-task-attention 来执行SOD。此外,受SOD模型中广泛使用的边界检测的启发,作者还采用多任务学习策略来共同执行显着性和边界检测,从而利用后者来帮助提高前者的性能。
为此,本文设计了两个与任务相关的tokens, 即显著性token 和边缘token 。在每一个解码器层级,将显著性token 和边缘token 与patch tokens 串联在一起,接着利用transformer层来处理它们。如此一来,这两个任务相关的tokens可以通过与patch tokens的交互中学习到与图像相关的显著性检测和边缘检测模式。之后,我们将更新后的patch tokens作为输入,结合所提出的token上采样和多层级token融合的方法来得到上采样后的patch tokens 。接下来,在下一个层级 上重新利用已经更新后的 和 去更新它们和 。重复上述过程直到到达最后一个解码器层级。
为了得到显著性和边缘预测结果,在最后一个解码器中对patch tokens 与显著性token 和边缘token 之间执行patch-task-attention。接下来,我们采用patch-task-attention去获得与任务相关的patch tokens:
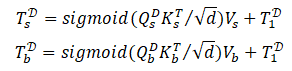
这里在计算attention时用sigmoid激活是因为只存在一个键。
因为 和 是1?4尺寸的,所以我们再用一次RT2T方法将它们上采样到全尺寸。最后,分别应用两个线性变换和sigmoid激活将它们投影到[0, 1]之间,之后reshape成2D的显著性图和边缘图,即为最终输出的结果。
4.Experiments
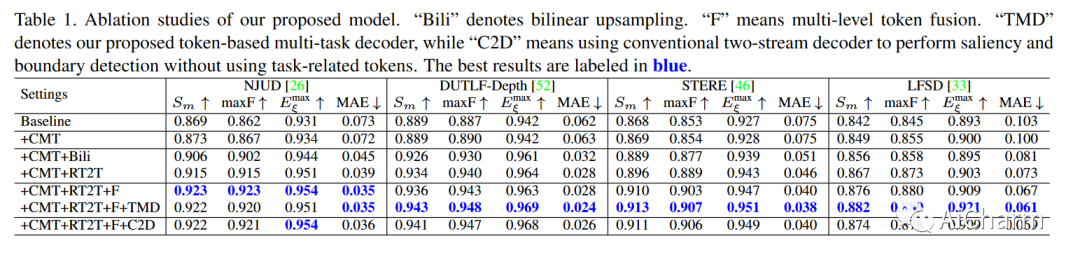
4.1 Ablation Study
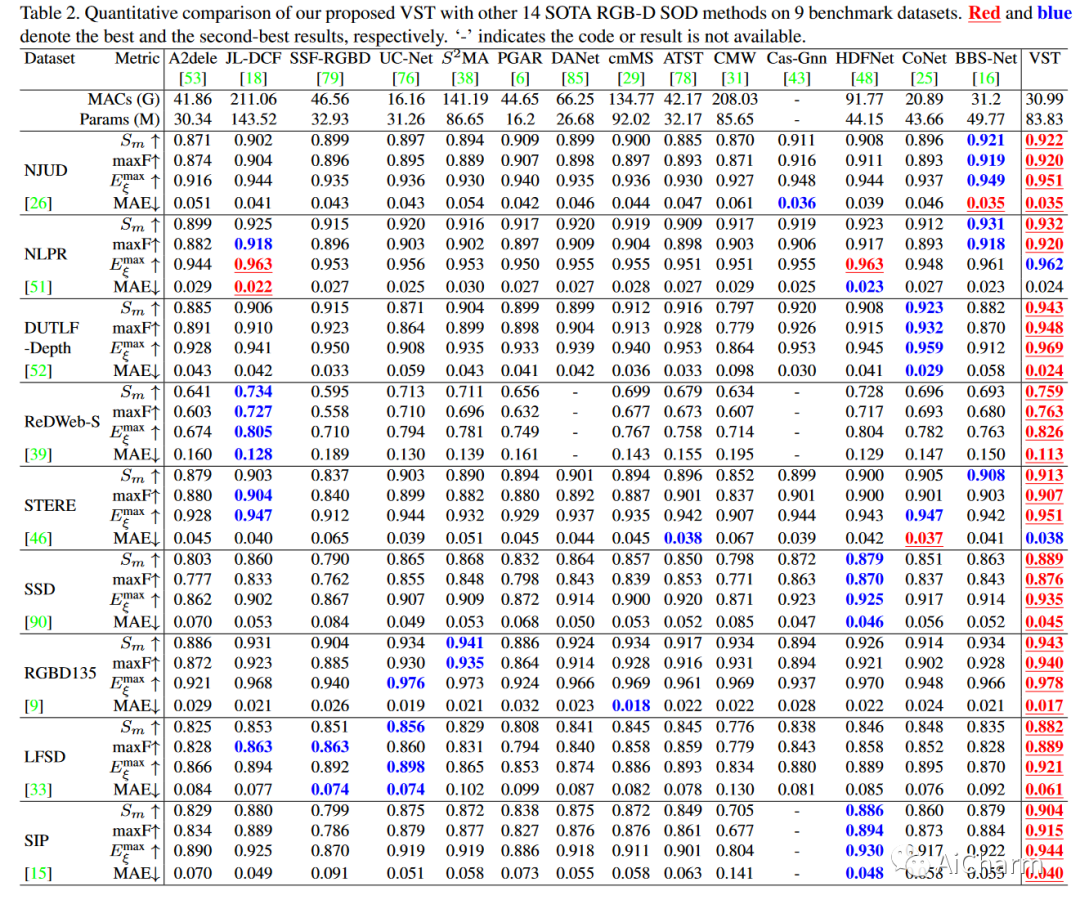
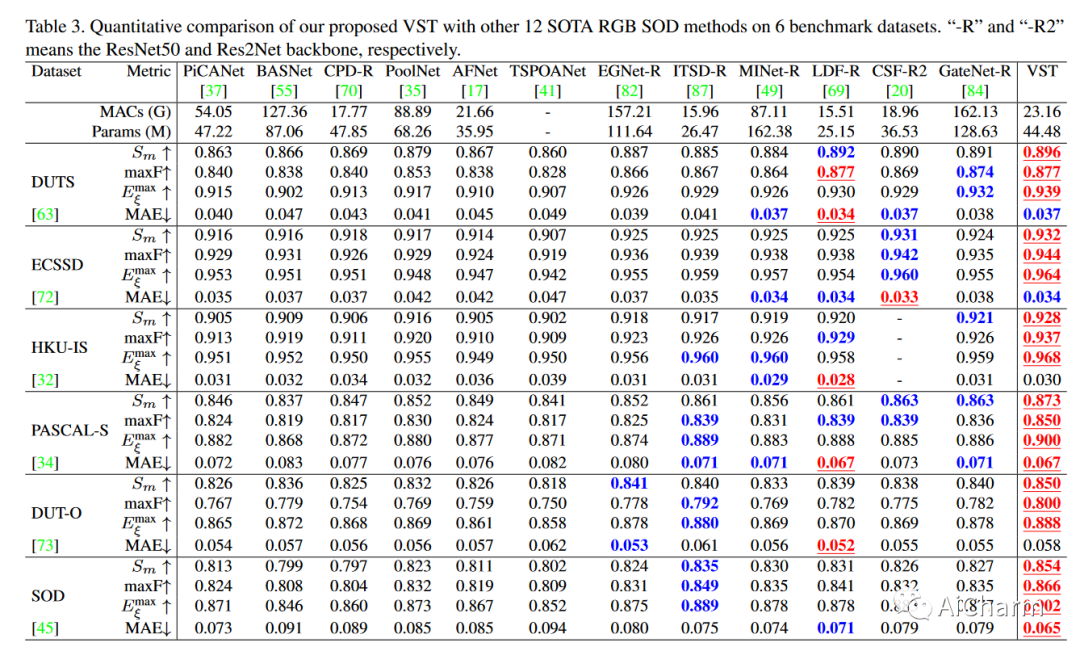
4.2 Comparison with State-of-the-Art Methods

5.Conclusion
在本文中,我们首次从序列到序列的角度重新思考 SOD,并基于纯Transformer开发了一种新颖的统一模型,用于处理 RGB 和 RGB-D SOD。为了应对在密集预测任务中应用Transformer的困难,我们在Transformer框架下提出一种新的token上采样方法,并融合了多级patch- token。我们还通过引入任务相关token和一种新颖的patch-task-attention设计了一个多任务解码器,以共同执行显着性和边界检测。我们的 VST 模型在不依赖重型计算成本的情况下为 RGB 和 RGB-D SOD 实现了最先进的结果,从而展示了其巨大的有效性。我们还为如何在密集预测任务中使用变形器设定了一个新的范例。