【算法】BloomFilter概念和原理以及业务中的应用场景
原创【算法】BloomFilter概念和原理以及业务中的应用场景
原创
互联网小阿祥
发布于 2023-05-28 22:19:05
发布于 2023-05-28 22:19:05
思考:海量数据下去重,如果是非数值类型的话如何判断?1.什么是布隆过滤器
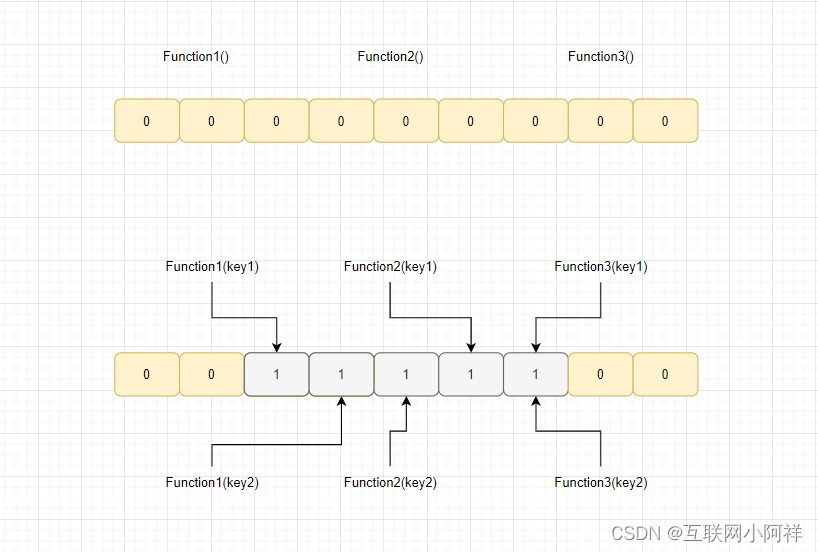
- 1970年由布隆提出的一种空间效率很高的概率型数据结构,它可以用于检索一个元素是否在一个集合中。
- 由只存0或1的位数组和多个hash算法, 进行判断数据 【一定不存在或者可能存在的算法】。
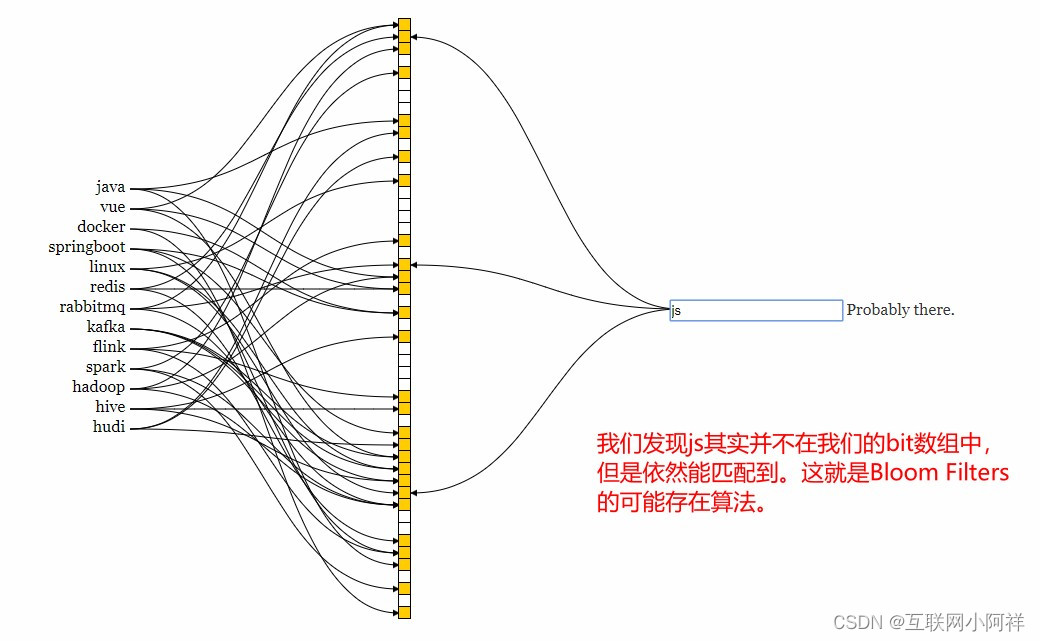
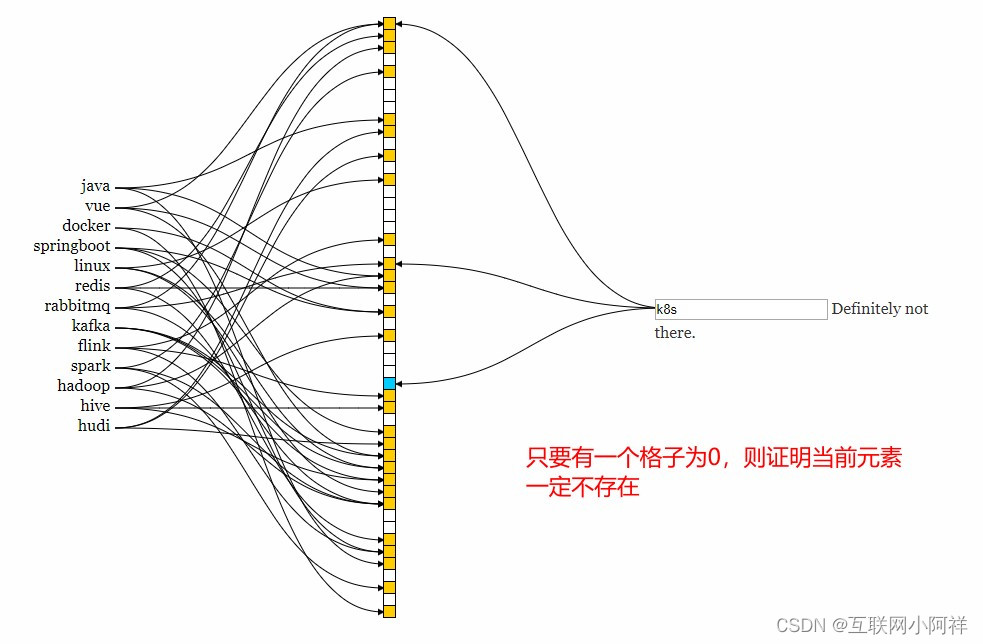
- 如果这些bit数组 有任何一个0,则被判定的元素一定不在; 如果都是1则被检元素很可能在。
- 对比bitmap位图,布隆过滤器适合更多类型元素,通过hash值转换。
在这里插入图片描述
- 原理
- 将元素添加到一个bitmap数组中,每个散列函数将元素映射到bitmap数组中的一个位置
- 如果该位置已经被占用,则将该位置置为1,否则置为0
- 当要查询一个元素是否存在时,只需要计算该元素的散列值,并检查bitmap数组中对应的位置是否已经被置为1
- 如果都是1,则该元素可能存在,否则肯定不存在。
- 优点
- 占用空间小,查询速度快,空间效率和查询时间都远远超过一般的算法
- 缺点
- 有一定的误识别率,有一定的误识别率,即某个元素可能存在,但实际上并不存在。
- 删除困难,因为无法确定某个位置是由哪个元素映射而来的
- 案例测试地址:https://www.jasondavies.com/bloomfilter/
在这里插入图片描述
在这里插入图片描述
- 记住结论:不存在的一定不存在,存在的不一定存在
- 注意点
- 布隆过滤器存在误判率,数组越小,所占的空间越小,误判率越高;如果要降低误判率,则数组越长,但所占空间越大
- 最大限度的避免误差, 选取的位数组应尽量大, hash函数的个数尽量多, 但空间占用的浪费和性能的下降
- 业务选择的时候, 需要误判率与bit数组长度和hash函数数量的平衡
- 布隆过滤器不能直接删除元素,因为所属的bit可能多个元素有使用
- 如果要删除则需要重新生成布隆过滤器,或者把布隆过滤器改造成带引用计数的方式
- 如何解决布隆过滤器不支持删除的问题
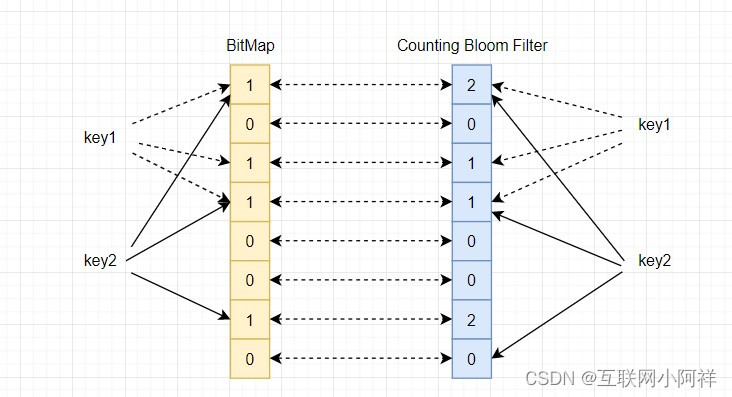
- Counting Bloom Filter将标准 Bloom Filter位数组的每一位扩展为一个小的计数器(counter),在插入元素时给对应的k(k为哈希函数个数)个Counter的值分别加1,删除元素时给对应的k个Counter的值分别减1。Counting Bloom Filter通过多占用几倍的存储空间的代价,给Bloom Filter增加了删除操作。
在这里插入图片描述
2.BloomFilter业务中的应用场景
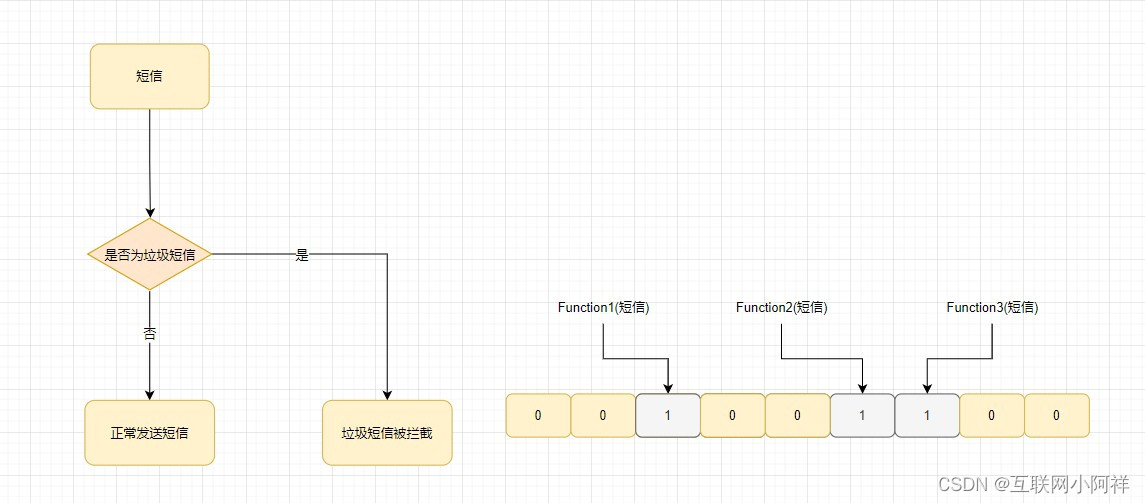
(1)海量数据下垃圾邮件解决方案(垃圾短信、黑名单同理)
- 收集一组具有特定特征的垃圾邮件样本,这些样本可以是文本内容或其他特征,比如发件人、收件人等
- 将这些样本的特征信息进行哈希处理,并将处理后的结果存储在布隆过滤器中。
- 接下来,当有新的电子邮件到达时,将该邮件的特征信息也进行哈希处理,并且与布隆过滤器中的信息进行比较
- 如果布隆过滤器中存在该邮件的特征信息,则判断该邮件为垃圾邮件;如果不存在,则判断该邮件为正常邮件
在这里插入图片描述
(2)解决缓存穿透解决方案
- 什么是缓存穿透(查询不存在数据)
- 查询一个不存在的数据,由于缓存是不命中的,如发起为id为“-1”不存在的数据
- 如果从存储层查不到数据则不写入缓存,导致这个不存在的数据每次请求都要到存储层去查询,
- 大量查询不存在的数据,可能DB就挂掉了,是黑客利用不存在的key频繁攻击应用的一种方式
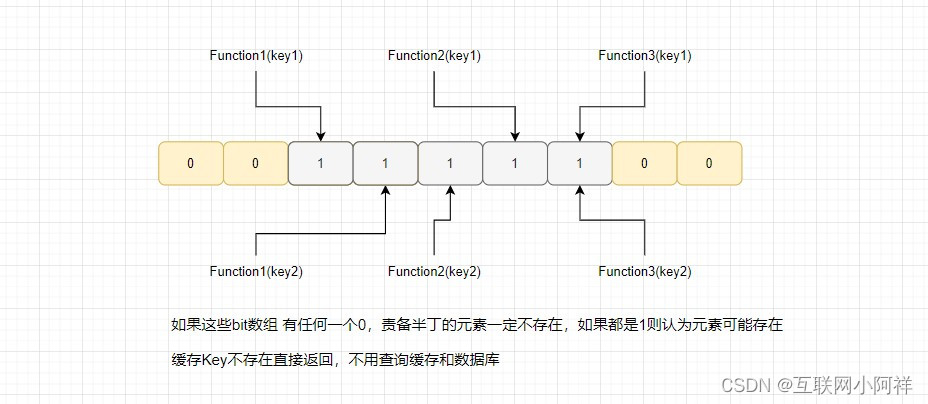
- 将所有要【缓存的数据】经过处理后存储布隆过滤器中,即对应的bit上是1
- 当外部请求发起时,首先会把请求的参数 通过哈希算法处理,获得相应的哈希值;
- 根据哈希值计算出位数组中的位置,如果全部计算的hash值对于的bit存储都是1
- 则表示数据在合理中,从缓存读出(缓存失效则从数据库中取出)
- 如果计算的hash值对于的bit存储存在一个是0或以上,则表示这条数据不合理,直接返回数据不存在,不查缓存和数据库
- 如果布隆过滤器认为值不存在,那么值一定是不存在的,无需查询缓存也无需查询数据库
在这里插入图片描述
(3)爬虫URL去重和分库分表注册手机号唯一性解决方案
大量的网页爬取,通过解析已经爬取页面中的网页链接,然后再爬取这些链接对应的网页
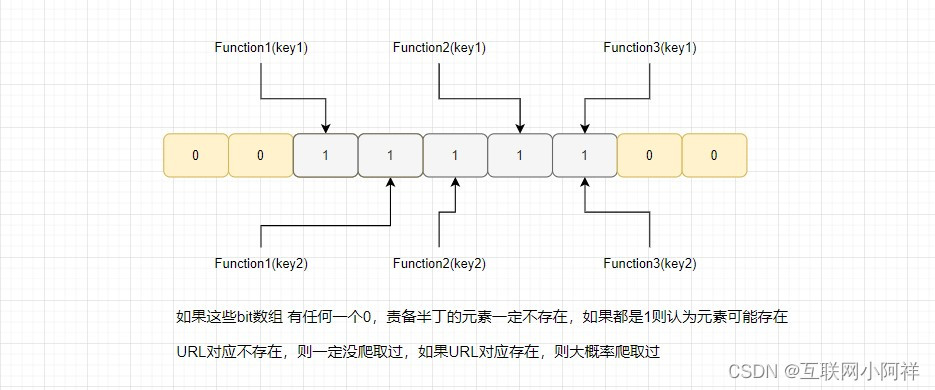
同一个网页链接有可能被包含在多个页面中,会导致爬虫在爬取的过程中,重复爬取相同的网页- 创建布隆过滤器,根据业务数据量设置位数组的大小,将位数组全部设置为0;
- 将每个URL地址通过哈希算法处理,获得相应的哈希值;
- 根据哈希值计算出位数组中的位置,将位数组中的位置设置为1;
- 当新的URL地址进入时,重复上述步骤计算出对应的位置
- 检查位数组中的位置是否为0,如果是0,则表示该URL地址一定没被爬取过;
- 如果URL地址不存在,经过爬虫处理后,则将其对应的位置设置为1,以表示该URL地址已经存在;
- 重复上述步骤,直到所有的URL地址都处理完毕,完成去重。
- 具体的SpringBoot整合案例请看我的另外一篇文章:【案例实战】爬虫URL去重实战-SpringBoot2.x+Guava布隆过滤器
在这里插入图片描述
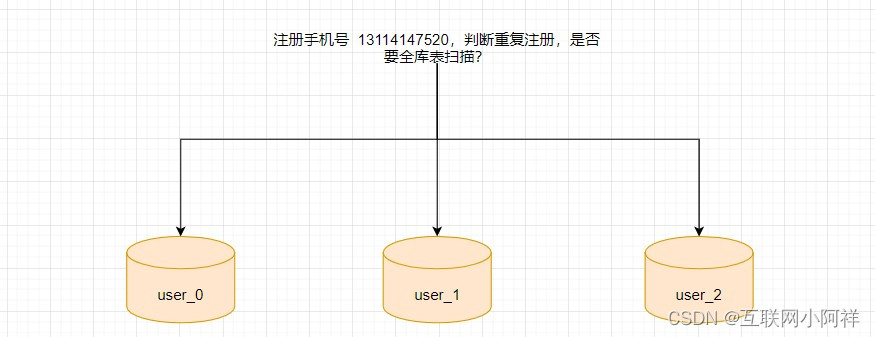
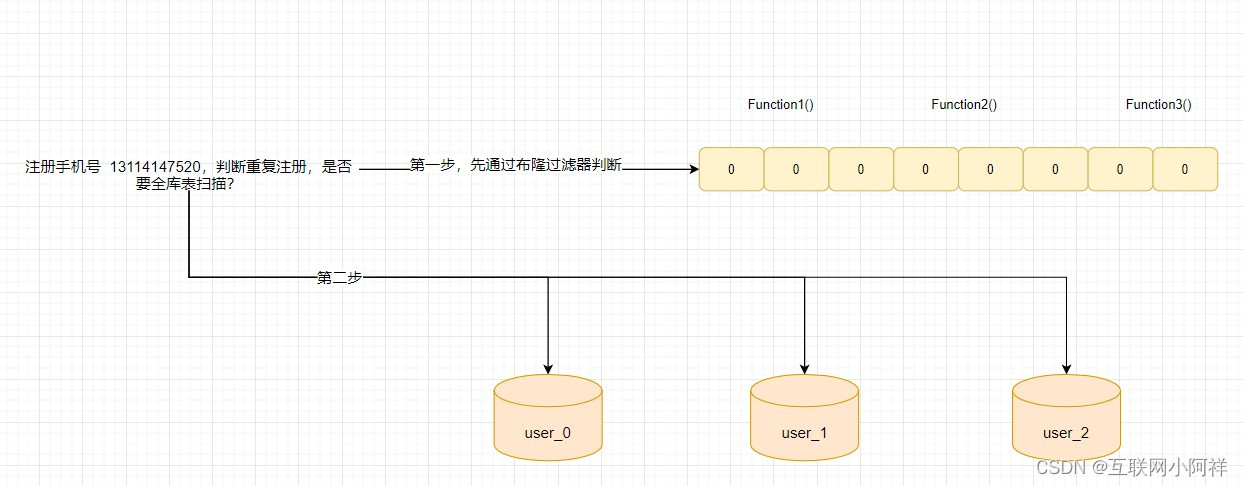
(4)海量数据下-分库分表下手机号重复注册解决方案
- 一般业务里面的partitionKey是不可变动的,所以不能用手机号作为分片键(换手机号需求是存在的)
- 所以业务里面的分片键,多数是固定的业务id,比如user_id
在这里插入图片描述
- 创建布隆过滤器,根据业务数据量设置位数组的大小,将位数组全部设置为0;
- 把要注册的手机号通过通过哈希算法处理,获得相应的哈希值;
- 根据哈希值计算出位数组中的位置,如果对应的位数组中的位置有存在0,则一定是未注册的
- 如果经过多个hash函数处理,对应的位数组中都是1,则认为是注册过的
- 最后如果用户注册成功后,将位数组中的位置设置为1
- 根据哈希值计算出位数组中的位置,如果对应的位数组中的位置有存在0,则一定是未注册的
- 如果经过多个hash函数处理,对应的位数组中都是1,则认为是注册过的
- 最后如果用户注册成功后,将位数组中的位置设置为1
在这里插入图片描述
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
相关产品与服务
短信
腾讯云短信(Short Message Service,SMS)可为广大企业级用户提供稳定可靠,安全合规的短信触达服务。用户可快速接入,调用 API / SDK 或者通过控制台即可发送,支持发送验证码、通知类短信和营销短信。国内验证短信秒级触达,99%到达率;国际/港澳台短信覆盖全球200+国家/地区,全球多服务站点,稳定可靠。