深度学习和深度强化学习的特征提取网络

标题:Backbones-Review:Feature Extraction Networks for Deep Learning and Deep Reinforcement Learning Approaches
作者:Omar Elharroussa,Younes Akbaria, Noor Almaadeeda and Somaya Al-Maadeeda
编辑:郑欣欣@一点人工一点智能
01 主要解决问题
当前时代,人工智能与日常生活密切相关:例如,ChatGPT正在改变我们的工作方式;人脸识别技术助力市场精确营销;机器人借助高效的视觉/雷达算法实现目标跟踪和避障等功能(图1)。
在人工智能领域,计算机视觉任务需依赖相应的特征提取器,以学习大规模图像数据中的物体特征和规律。本文旨在对各类用于特征提取的图像主干网络进行全面的总结和分析。同时,本文收集了不同计算机视觉任务对应的特征提取主干网络,涵盖图像分类、目标检测、人脸识别、光学分割、动作识别等领域。
02 常见的主干网路
特征提取在数据分析领域中占据着至关重要的地位,其作用在于从原始数据中抽取有价值的信息。
伴随着机器学习和深度学习技术的进步,神经网络在性能和处理数据量方面取得了突破性的成果。尤其随着卷积神经网络CNN的兴起,使得处理海量数据成为可能,并在图像特征提取中得到广泛应用。主干网络指的是用于特征提取的架构或网络。本文对深度学习模型中采用的主干网络进行了详尽阐述。
A.?ResNet
ResNet(残差网络)是一种CNN结构,旨在通过引入残差连接来解决深度神经网络中的梯度消失问题。它由Kaiming He等在2015年《Deep Residual Learning for Image Recognition》中首次提出。ResNet在多个计算机视觉任务中表现出了优异的性能,包括图像分类、目标检测和语义分割等。
ResNet的核心特点是残差连接,这是通过短路连接(skip connections)实现的。短路连接将浅层的输出直接与深层的输出相加,从而使得神经网络可以学习残差映射。
这种机制有助于解决梯度消失问题,因为残差连接允许梯度在反向传播过程中直接跨越多个层。通过这种方式,ResNet可以实现非常深的网络结构,例如100层、1000层甚至更深,同时保持良好的收敛性能。
ResNet的主要组成部分包括:输入层、残差块(Residual Block)、池化层和分类层,如图2所示。
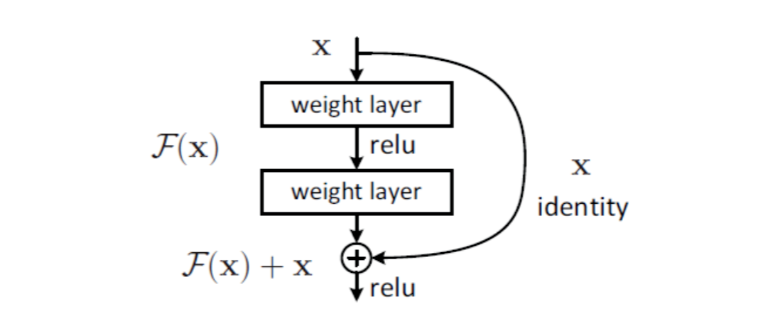
在残差块中,通常采用两个或三个连续的卷积层(例如1x1、3x3、1x1卷积结构),并在卷积层之间使用批量归一化(Batch Normalization)和ReLU激活函数。残差连接将输入直接与卷积层的输出相加,形成残差映射。池化层用于减少特征图的尺寸,提高模型的抽象能力。最后,在分类层中,使用全局平均池化和Softmax函数进行分类。ResNet具有以下主要特点:
残差连接:通过短路连接实现残差映射,有助于解决梯度消失问题。
深度可扩展性:由于残差连接的引入,ResNet可以实现非常深的网络结构,同时保持良好的收敛性能。
高性能:ResNet在多个计算机视觉任务中表现出了优异的性能,例如在ILSVRC 2015图像分类任务中取得了冠军。
总之,ResNet通过引入残差连接解决了深度神经网络中的梯度消失问题,实现了非常深的网络结构。这种网络结构在多个计算机视觉任务中具有优异的性能和广泛的应用价值。
B. GoogleNet
GoogleNet,又称Inception网络,由Szegedy等人于2014年提出。该网络在ILSVRC-2014上取得了优异的表现,凭借其创新性的设计理念和优越的性能,GoogleNet在计算机视觉领域产生了深远的影响。GoogleNet的主要特点如下:
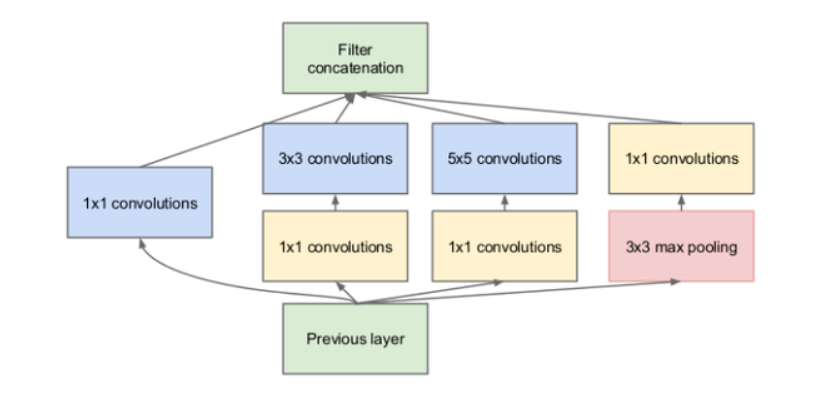
Inception模块:GoogleNet引入了Inception模块,其基本思想是在同一层网络内采用多尺度的卷积操作。具体来说,Inception模块结合了1x1、3x3、5x5的卷积核以及池化层,从而能够在不同尺度下捕捉图像特征,它的结构如图3所示。1x1卷积核的引入还有效减小了计算复杂度,提高了计算效率。
网络深度:GoogleNet具有22层的深度,相比其前辈如AlexNet和VGG等,GoogleNet的深度显著增加。这使得网络能够捕获更丰富的图像特征,提高分类准确率。
辅助分类器:为缓解梯度消失问题,GoogleNet在网络的中间层引入了辅助分类器。这些辅助分类器与网络的主要输出共同参与训练过程,提高了梯度传播效果。
全局平均池化:GoogleNet在网络的最后一层使用全局平均池化代替了全连接层。这样的设计降低了模型的参数量,减小了过拟合的风险,同时简化了网络结构。
总之,GoogleNet以其独特的Inception模块、辅助分类器和全局平均池化等设计理念,在计算效率和性能方面取得了显著的优势。这些创新性的特点使得GoogleNet成为了计算机视觉领域的一个重要里程碑。
C. DenseNet
DenseNet,全称Densely Connected Convolutional Networks,由Huang等人于2016年提出。与其他常见的深度学习模型相比,DenseNet的核心特点是其密集连接方式,这一特点在一定程度上提高了模型的性能和计算效率。DenseNet的网络结构及特点如下:
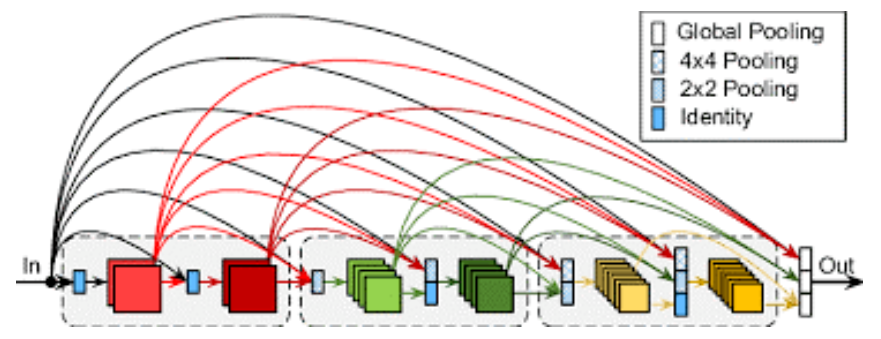
密集连接:DenseNet的主要创新在于引入了密集连接(dense connection)的概念。在DenseNet中,每个卷积层的输出都会与该层之后的所有卷积层的输入相连接。这种密集连接方式有助于提高特征重用,减小梯度消失问题,从而增强了网络的表达能力(如图4)。
增长率(Growth Rate):增长率是DenseNet中的一个重要参数,用于控制每个卷积层输出特征图的数量。较小的增长率有助于降低模型参数量和计算复杂度。
瓶颈层(Bottleneck Layer):为了降低计算量,DenseNet在卷积层之前引入了瓶颈层,通常采用1x1卷积核。瓶颈层的作用是减小输入特征图的数量,从而降低计算成本。
传递特征图(Feature Map Reuse):由于DenseNet中的密集连接方式,特征图在各个卷积层之间进行重复利用。这种传递特征图的方式有助于减小模型参数量,提高训练效率。
分层(Dense Block):DenseNet将网络结构分为多个密集连接的卷积层组,每个Dense Block之间通过过渡层连接。过渡层通常包括批量归一化、1x1卷积和2x2平均池化层。过渡层的作用是减小特征图的尺寸和数量,从而进一步降低计算成本。
总之,DenseNet凭借其独特的密集连接方式、增长率、瓶颈层和分层结构等特点,在计算效率和性能方面具有优越性。这些创新性的设计理念使DenseNet在计算机视觉领域取得了显著的成果。
D. SqueezeNet
SqueezeNet是一种轻量级的CNN网络,由Iandola等人于2016年提出。SqueezeNet的设计目标是在保持预测准确性的同时,尽量减少模型参数量和计算复杂度,从而适应资源受限的设备和环境。SqueezeNet的网络结构及特点如下:
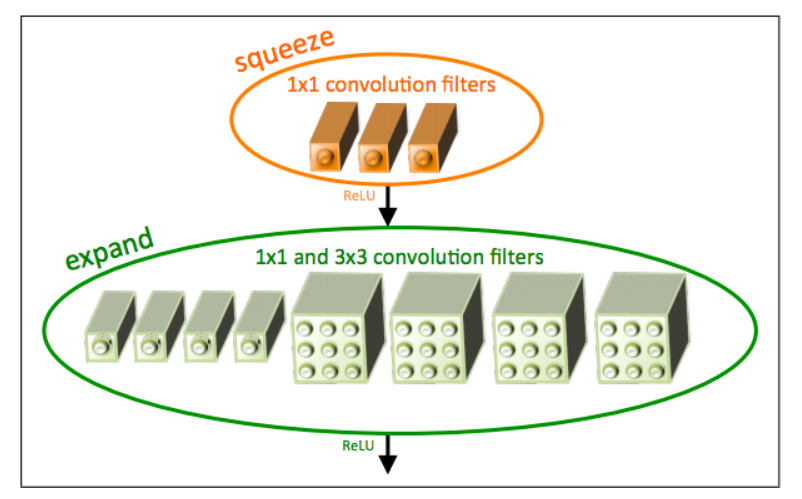
Fire模块:SqueezeNet的核心组成部分是Fire模块,这一模块由一个Squeeze层和一个Expand层组成。Squeeze层采用1x1卷积核,用于降低特征图的通道数(即压缩特征图)。Expand层则包含1x1和3x3卷积核,负责将特征图通道数扩张回原来的大小,其网络结构见图5。
微小卷积核:SqueezeNet大量采用1x1卷积核,减少了计算量和参数数量。这种设计使得SqueezeNet在保持预测性能的同时,具有较小的计算成本和内存占用。
减少3x3卷积核的数量:SqueezeNet通过在Fire模块中引入Squeeze层,间接减少了3x3卷积核的使用。这有助于降低模型参数量和计算复杂度。
延迟下采样:SqueezeNet将下采样操作(如池化)延迟到网络的后期,以保留更多的特征信息。这种策略在一定程度上提高了SqueezeNet的预测性能。
全局平均池化:与其他现代卷积神经网络类似,SqueezeNet在网络的最后一层采用全局平均池化,以减少参数数量,降低过拟合风险。
综上所述,SqueezeNet以其独特的Fire模块、微小卷积核、减少3x3卷积核数量、延迟下采样和全局平均池化等设计理念,在资源受限的设备和环境中具有较高的计算效率和性能。这些创新性的设计使得SqueezeNet在轻量级深度学习模型领域具有显著的优势。
E. MobileNet
MobileNet是一种轻量级的CNN网络,旨在为移动和嵌入式设备提供实时计算能力。它的主要特点是在保持高度精确的情况下降低计算复杂性和内存占用。MobileNet的网络结构主要依赖于两个核心技术:深度可分离卷积(Depthwise Separable Convolution)和宽度多样性(Width Multiplier),其网络结构见图6。
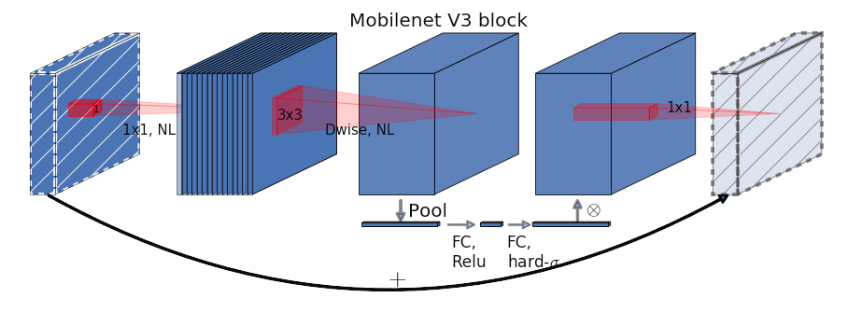
深度可分离卷积:MobileNet利用深度可分离卷积将传统卷积操作分解为两个独立的操作,从而减少计算量和参数数量。深度可分离卷积包括两个步骤:深度卷积和逐点卷积。
深度卷积:应用于每个输入通道的空间卷积,而不是在所有通道上应用卷积。这减少了计算量和参数数量。
逐点卷积:使用1x1卷积核,在深度卷积之后对通道进行组合。这保留了空间信息,同时实现通道之间的特征组合。
宽度多样性:MobileNet通过引入宽度乘数(α)来进一步减小模型大小和计算量。这允许用户在不同的资源限制下调整网络。α的值介于0和1之间,它会影响网络中每一层的通道数量。减小α值将减少模型的复杂性,但可能会降低模型的准确性。
MobileNet的特点可以概括如下:
计算效率:通过深度可分离卷积和宽度乘数技术,MobileNet显著降低了计算复杂性,使得模型在移动和嵌入式设备上更加高效。
参数数量减少:深度可分离卷积降低了模型参数的数量,从而减小了存储需求和内存占用。
灵活性:宽度乘数提供了一种灵活的方法来调整网络结构,以满足不同设备的性能需求。
保持精确性:尽管模型的大小和计算量减小,但MobileNet在各种计算机视觉任务上仍然具有相对较高的准确性。
F. WideResNet
Wide Residual Networks (WideResNet) 通过增加网络的宽度来提高性能。它是基于经典的残差网络ResNet发展而来的,继承了ResNet的深度和跳跃连接等特性。以下是WideResNet的网络结构与特点的概述:
网络结构:WideResNet的基本结构由多个残差单元(如图7所示)堆叠而成。每个残差单元由两个或多个卷积层组成,这些卷积层之间的输出特征图数量相同,但比传统ResNet的对应层更宽。通过增加每个残差单元内的卷积层的宽度,WideResNet实现了在保持较低深度的同时获得较高性能。
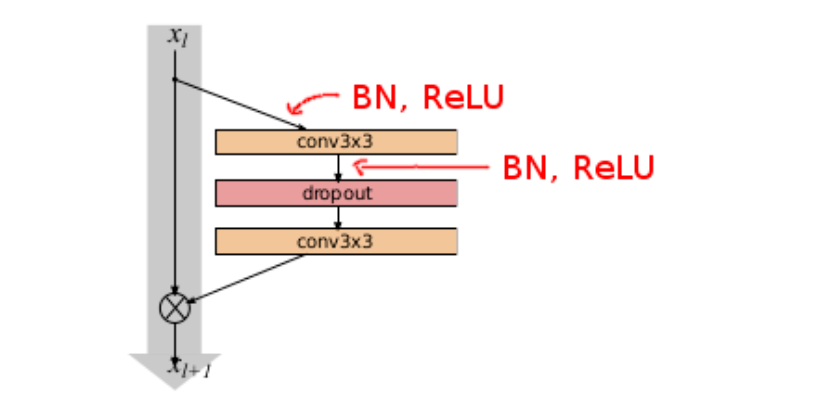
跳跃连接:WideResNet继承了ResNet中的跳跃连接特性。这些连接可以跳过一个或多个卷积层,从而直接将输入特征图与输出特征图相加。这种跳跃连接有助于解决梯度消失问题,从而实现更深的网络结构。
参数数量:相较于具有相同性能的更深的网络,WideResNet具有较少的参数数量。通过增加宽度而非深度,WideResNet能够在减小模型复杂度和计算量的同时保持较高的性能。
训练效果:WideResNet在多个图像分类任务上表现优异,如CIFAR-10、CIFAR-100和ImageNet等。相较于传统的ResNet,在相同深度下,WideResNet通常可以取得更好的性能。
广泛应用:WideResNet在计算机视觉领域的许多任务中具有广泛的应用,如图像分类、目标检测、语义分割等。同时,它可以作为其他复杂网络结构的基础组件,如在网络中引入注意力机制等。
总之,WideResNet通过增加网络宽度而非深度,在保持较低复杂度和计算量的同时实现了较高的性能,具有广泛的应用前景。
G. EfficientNet
EfficientNet通过对模型深度、宽度和分辨率的同时缩放来实现高效的性能。这种网络结构在保持计算效率的同时,实现了显著的性能提升。以下是EfficientNet的网络结构与特点的概述:
网络结构:EfficientNet的基本结构是基于Inverted Residual with Linear Bottleneck(MBConv)的卷积层。MBConv结构包括一个扩张卷积Expansion Convolution层、一个深度可分离卷积Depthwise Convolution层和一个逐点卷积Ppointwise Convolution层,以及相应的非线性激活函数和跳跃连接。
复合缩放:EfficientNet的核心思想是复合缩放,即在三个维度上(深度、宽度和分辨率)同时缩放模型,如图8所示。通过这种方法,EfficientNet能够更有效地利用计算资源,在不同计算能力的硬件上实现更高的性能。
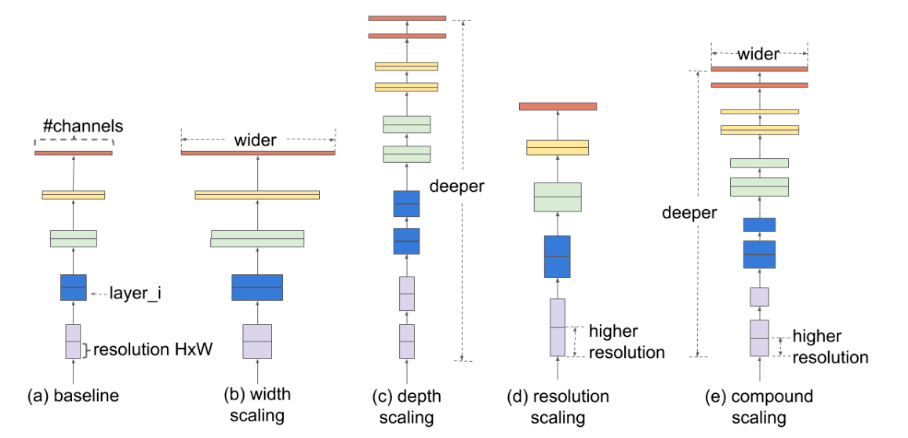
均匀缩放:EfficientNet提出了一种均匀缩放策略,即在每个维度上使用相同的缩放因子。这种策略可以在不过度增加计算复杂度的情况下,平衡各个维度的资源分配。
AutoML:EfficientNet的基本网络结构(EfficientNet-B0)是通过神经架构搜索(NAS)技术自动生成的。随后,作者使用复合缩放策略生成了一系列更大的EfficientNet变体(如EfficientNet-B1至EfficientNet-B7),以适应不同计算能力的硬件和任务需求。
性能优越:EfficientNet在多个计算机视觉任务中取得了显著的性能提升,如ImageNet图像分类、COCO目标检测和分割等。相较于其他同类模型,EfficientNet在保持较低计算量和参数量的同时,实现了较高的准确率。
广泛应用:EfficientNet在计算机视觉领域具有广泛的应用,包括图像分类、目标检测、语义分割等任务。同时,由于其高效性,EfficientNet也适合部署在资源受限的设备上,如移动设备和嵌入式系统。
总之,EfficientNet通过复合缩放策略实现了高效的性能,同时具有较低的计算复杂度和参数量,这使得EfficientNet在计算机视觉领域具有广泛的应用。
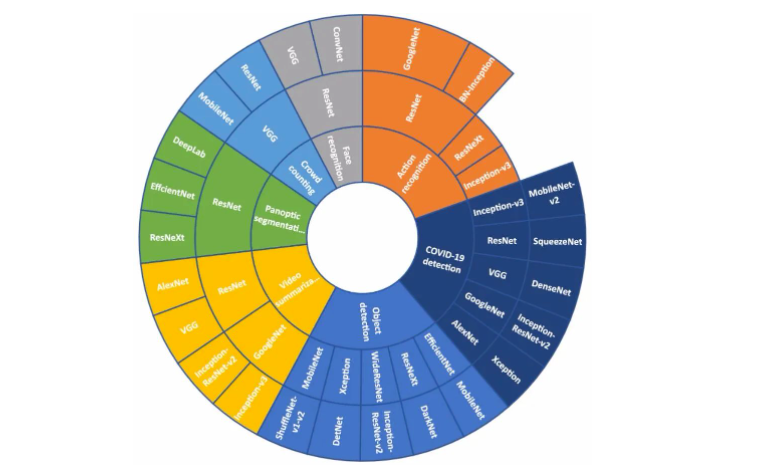
03? 不同任务下主干网络表现
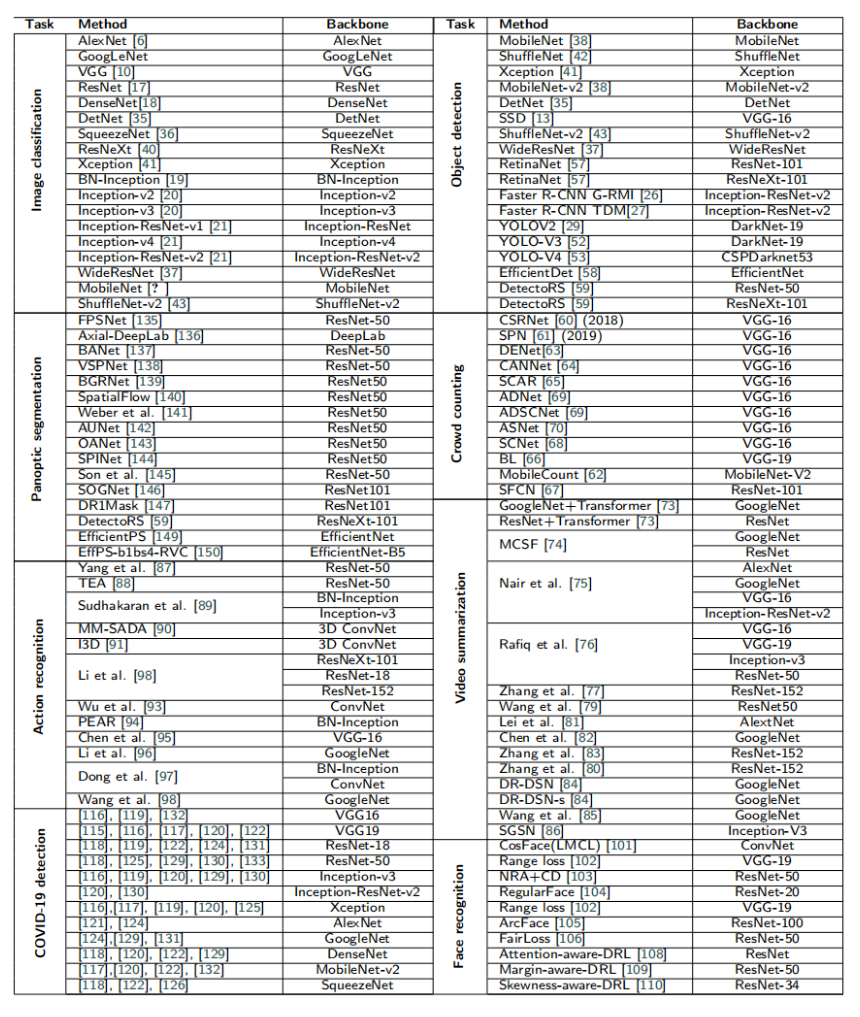
主干网络是深度学习领域中广泛应用于各种视觉任务的基础网络结构。它们通常用于提取图像特征,并可与其他模块结合以完成特定的视觉任务。本文将概述几种视觉任务(包括图像分类、目标检测和语义分割)以及在这些任务中表现优异的主干网络。
(1)图像分类:图像分类任务的目标是将输入图像分配给预定义类别。在此任务中,广泛使用的主干网络包括:
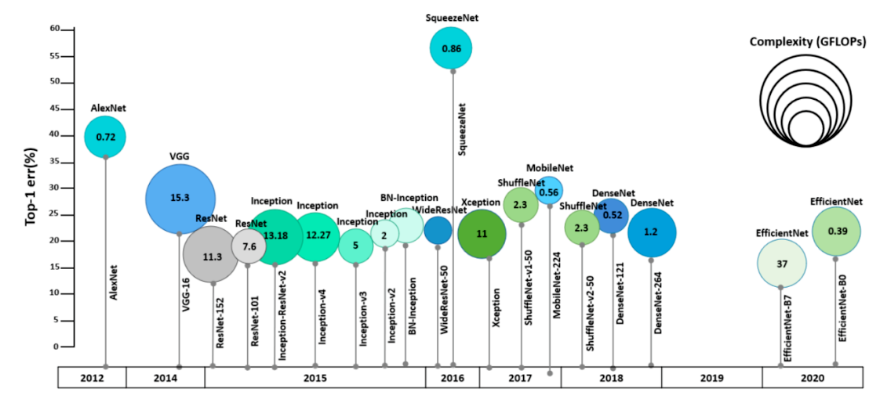
AlexNet:2012年开创性的深度学习模型,突破了图像分类任务的性能瓶颈。
VGGNet:使用连续的3x3卷积层构建,易于理解且具有良好的性能。
ResNet:引入残差连接来解决深度神经网络中的梯度消失问题,实现了非常深的网络结构。
DenseNet:通过密集连接提高特征重用,降低参数数量,提高模型效率。这些网络在大规模图像分类任务(如ImageNet)中表现出色,具有较高的准确率和较低的误差率(图9)。
(2)目标检测:目标检测任务的目标是在图像中定位并分类物体。主干网络通常与Region Proposal Network(RPN)和其他检测组件结合使用。在此任务中,流行的主干网络包括:
R-CNN系列(包括R-CNN、Fast R-CNN和Faster R-CNN):通常与VGGNet、ResNet等网络结合使用,实现了较高的检测性能。
YOLO系列:将目标检测任务视为回归问题,实现了高速实时检测,通常与自定义轻量级主干网络结合使用。
SSD:采用多尺度特征图进行检测,通常与VGGNet、ResNet等网络结合使用,实现了较好的检测性能和速度权衡。
(3)语义分割:语义分割任务的目标是将图像中的每个像素分配给预定义类别。主干网络通常与上采样模块(如反卷积、双线性插值等)结合以实现像素级预测。在此任务中,常用的主干网络包括:
FCN:全卷积网络,首次将卷积神经网络成功应用于语义分割任务,通常与VGGNet等网络结合使用。
U-Net:采用对称编码-解码结构,并使用跳跃连接进行特征传播,通常与定制主干网络结合使用。
DeepLab系列:利用空洞卷积(Atrous Convolution)和空洞空间金字塔池化(ASPP)模块捕捉多尺度信息,通常与ResNet、Xception等网络结合使用。DeepLab系列在语义分割任务中实现了优异的性能。
(4)实例分割:实例分割任务的目标是将图像中的每个像素分配给预定义类别,同时区分属于同一类别的不同物体实例。主干网络通常与目标检测和像素级预测模块结合以实现实例级预测。在此任务中,主要的主干网络包括:
Mask R-CNN:在Faster R-CNN的基础上引入一个额外的分支来预测像素级掩码,通常与ResNet、ResNeXt等网络结合使用,实现了实例分割任务的高性能。
(5)姿态估计:姿态估计任务的目标是检测人体关键点并估计人体姿势。主干网络通常与关键点检测和关联模块结合以实现姿态预测。在此任务中,主要的主干网络包括:
OpenPose:采用多阶段卷积神经网络,通常与VGGNet等网络结合使用,实现了实时多人姿态估计。
HRNet:高分辨率网络,保持高分辨率特征图以实现更精确的关键点检测,通常与定制主干网络结合使用。
(6)光流估计:光流估计任务的目标是计算图像序列中的像素运动。主干网络通常与光流预测模块结合以实现光流估计。在此任务中,主要的主干网络包括:
FlowNet:采用对称编码-解码结构,并使用跳跃连接进行特征传播,通常与定制主干网络结合使用。
总之,不同视觉任务下的主干网络表现取决于任务需求和主干网络设计。
例如,在图像分类任务中,ResNet、DenseNet等网络表现优异;而在目标检测、语义分割和实例分割等任务中,通常会采用R-CNN系列、YOLO系列、SSD、U-Net、DeepLab系列和Mask R-CNN等网络。这些主干网络可根据任务需求进行优化和调整,以在各种视觉任务中实现良好的性能。
在表1所示的各类视觉任务中,选用卷积神经网络进行特征提取或作为深度强化学习模型的特征抽取部分是基于理论依据的。视觉神经网络模型的设计与目标任务和设备计算能力密切相关,而选定一个优秀的主干网络将对最终的检测效果产生决定性影响。
04 结论
深度学习依赖于大量数据以进行训练。因此,深度学习面临的主要挑战在于数据集的数量有限以及质量未达到理想水平。
以医学领域为例,深度强化学习常被应用于辅助诊断过程。然而,在罕见疾病的情况下,可用于神经网络模型学习的数据样本不足。
深度学习模型的性能与其采用的网络结构密切相关,但其在发现潜在规律和理解能力方面仍有待提高(泛化性能不佳)。在数据标注方面,深度学习仍然依赖人力对大量原始图像数据进行精确标注,以便进行有监督学习,因此这项工作目前仍需投入大量人力和物力。
展望未来,研究人员将更多地关注图像增强和数据增强技术。
此外,深度强化学习也将在自动标注方面发挥更大作用。本文概述了深度学习网络的骨干,并对每个网络提供了详细的描述。此外,本文收集了为视觉任务选择合适骨干的实验结果,并根据所使用的骨干进行比较。
本文系转载,前往查看
如有侵权,请联系?cloudcommunity@tencent.com 删除。
本文系转载,前往查看
如有侵权,请联系?cloudcommunity@tencent.com 删除。