如何将本地transformer模型部署到Elasticsearch
原创如何将本地transformer模型部署到Elasticsearch
原创

在本月早些时候,Elastic发布了Elasticsearch Relevance Engine(Elasticsearch相关性引擎),该引擎通过多种方式,为用户提供提高相关性的能力,其中特别重要的一点,就是允许开发人员在 Elastic 中管理和使用自己的transformer模型。
但是从各种示例中,我们看到的都是从HuggingFace上直接下载模型,然后上传到Elasticsearch当中。就如下例:

eland会访问HuggingFace,并从https://huggingface.co/elastic/distilbert-base-uncased-finetuned-conll03-english,下载模型。

但是,这种方式对于很多企业来说并不方便,原因包括:
- 自有模型是根据企业私有数据训练出来的,大多数情况下,不应该上传到HuggingFace并进行传播。
- 很多企业的生产环境有网络访问限制,并不能直接访问HuggingFace
因此,本文将介绍,如果将本地训练好的模型,直接通过eland上传到Elasticsearch。
本地模型的格式要求
要将自己训练的自有模型上传到elasticsearch,模型必须具备特定的格式。具体的要求可以参考HuggingFace上同类模型所需要提交的内容,特别是参考Elasticsearch所支持的模型架构在HuggingFace上的文件结构:
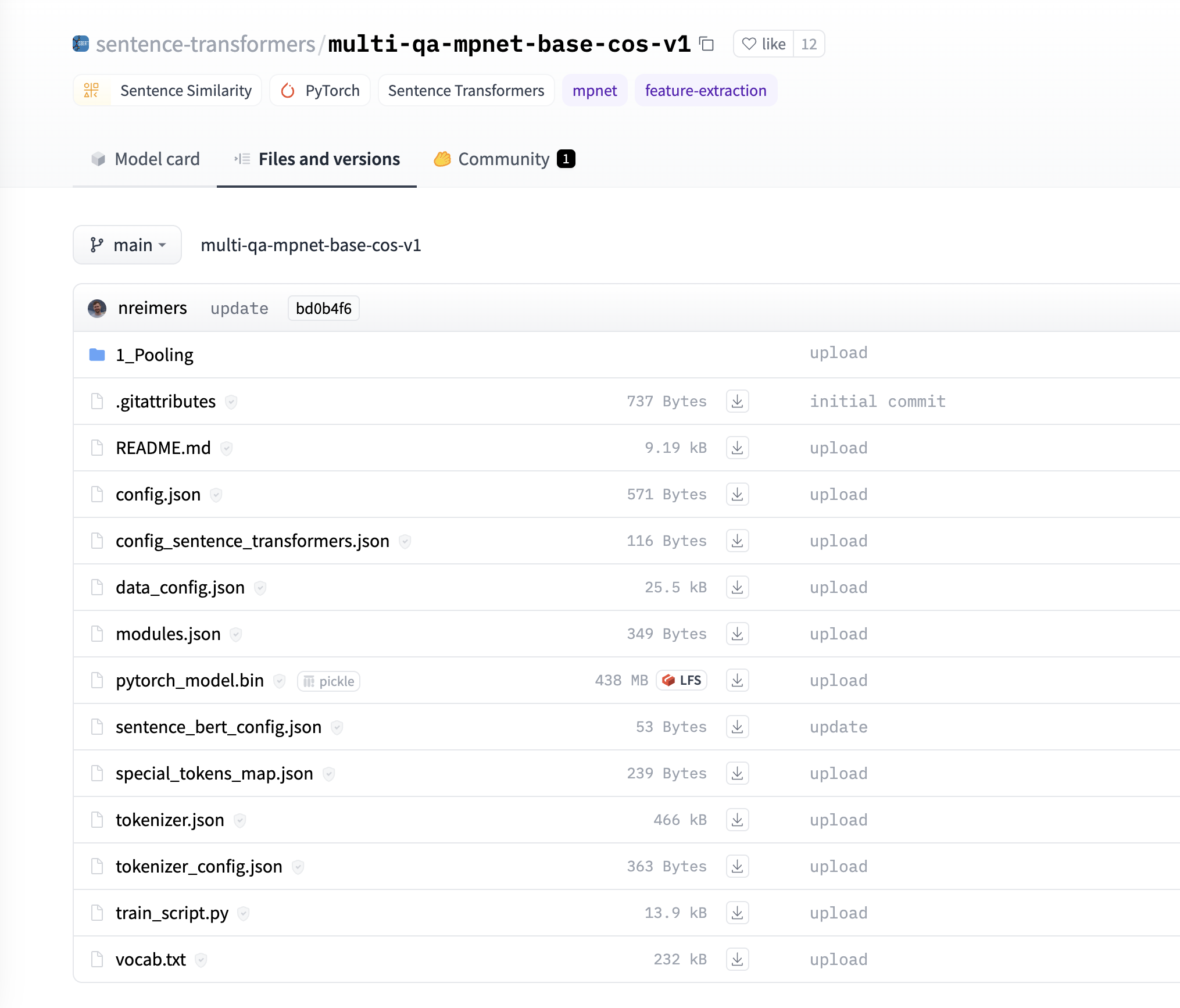
通常来说会包括:
- 模型权重文件(.bin、.pt、.pth等):这是您训练好的PyTorch模型的权重文件,包含了模型的参数。
- 配置文件(.json、.yaml等):这是描述您的模型架构和超参数的配置文件,例如模型的层数、隐藏层大小、注意力机制等。
- Tokenizer文件(.json、.txt等):这是用于将文本转换为模型可接受的输入格式的分词器文件。它可以是预训练的分词器文件或您自己训练的分词器。
- 附加代码文件(.py):如果您在训练模型时使用了自定义的代码文件(如自定义损失函数、数据预处理等),则需要将这些文件一并提交。
- README文件(.md、.txt等):这是一个说明文档,包含了有关您上传模型的详细信息,例如模型的用途、示例代码和使用方法等。
举个例子,以下是一个在BERT上构建的中文问答模型的结构:
~/bert-base-chinese-qa$ tree
.
├── README.md
├── config.json
├── pytorch_model.bin
├── special_tokens_map.json
├── tokenizer_config.json
└── vocab.txt这里就包含了模型权重文件:pytorch_model.bin, 配置文件:config.json、tokenizer_config.json,Tokenizer文件:special_tokens_map.json。
本地模型准备
通常来说,我们需要自己训练模型并做好准备的,这里,不对这种情况进行过多的说明。
另一种情况是,企业仍然想用HuggingFace上的共享模型资源,但是又不想每次都通过eland去重新下载模型,或者说生产环境对于HuggingFace网络的访问有限制,我们可以先将HuggingFace上面的模型下载到本地,然后每次通过本地的模型进行部署。
具体操作包括:
- 系统中需要安装Git和Git Large File Storage
- 从 Hugging Face 中选择您要使用的模型。(有关受支持架构的更多信息, 请参阅兼容的第三方模型,这里需要明确的是,有“兼容的第三方模型”列表并不意味着其他所有的模型就是不兼容的,只是没有经过测试。只要是Pytorch+BERT的、ES支持的NLP任务的模型,经过调整,通常都可以使用。可参考:Elastic 进阶教程:在Elasticsearch中部署中文NER模型)
- 从 Hugging Face 上 clone 所选模型到本地。例如:
git clone https://huggingface.co/dslim/bert-base-NER比如,上面的命令会在目录中生成模型的本地副本bert-base-NER。
lex@lex-demo-2:~$ git clone https://huggingface.co/dslim/bert-base-NER
Cloning into 'bert-base-NER'...
remote: Enumerating objects: 58, done.
remote: Counting objects: 100% (1/1), done.
remote: Total 58 (delta 0), reused 0 (delta 0), pack-reused 57
Unpacking objects: 100% (58/58), 114.09 KiB | 7.61 MiB/s, done.
Filtering content: 100% (4/4), 1.61 GiB | 76.55 MiB/s, done.
lex@lex-demo-2:~$ cd bert-base-NER/
lex@lex-demo-2:~/bert-base-NER$ tree
.
├── README.md
├── added_tokens.json
├── config.json
├── flax_model.msgpack
├── model.safetensors
├── pytorch_model.bin
├── special_tokens_map.json
├── tf_model.h5
├── tokenizer_config.json
└── vocab.txt在上传时,eland会首先检查是否存在config.json文件,如果不存在,会报以下错误:
OSError: Can't load config for '/PATH/TO/MODEL'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. Otherwise, make sure '/PATH/TO/MODEL' is the correct path to a directory containing a config.json file也会检查pytorch_model.bin文件,如果不存在,会报以下错误:
OSError: Error no file named pytorch_model.bin found in directory /Users/lex.li/.cache/huggingface/hub/models--bert-base-uncased/snapshots/0a6aa9128b6194f4f3c4db429b6cb4891cdb421b but there is a file for Flax weights. Use `from_flax=True` to load this model from those weights.本地模型上传
使用eland_import_hub_model脚本来安装本地模型,本地模型将通过--hub-model-id参数来配置:
eland_import_hub_model \
--url 'XXXX' \
--hub-model-id /PATH/TO/MODEL \
--task-type ner \
--es-username elastic --es-password XXX \
--es-model-id bert-base-ner比如,上例中,我们可将 --hub-model-id /PATH/TO/MODEL \ 修改为 --hub-model-id bert-base-NER \ 。特别要主要的是,当我们提供本地路径的时候,必须是字母或者数字开头,也就是,我们不能用 ./ 或者 / 开头。否则,会遇到如下错误:
elasticsearch.BadRequestError: BadRequestError(400, 'action_request_validation_exception', "Validation Failed: 1: Invalid model_id; '__users__lex.li__es_lab__bert-base-chinese-qa' can contain lowercase alphanumeric (a-z and 0-9), hyphens or underscores; must start and end with alphanumeric;")所以,在运行eland的时候,需要将当前目录切换到模型文件夹所在目录,并且只提供文件夹名作为路径参数。
总结
本文介绍了如何将本地训练好的transformer模型,直接通过eland上传到Elasticsearch,从而实现在Elastic中管理和使用自己的模型。这样可以避免每次都从HuggingFace下载模型,或者解决生产环境的网络访问限制。本文还介绍了本地模型的格式要求,以及使用eland_import_hub_model脚本的具体步骤和注意事项。希望本文对您有所帮助,如果您有任何问题或建议,请在评论区留言。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。