SPSS Modeler用K-means(K-均值)聚类、CHAID、CART决策树分析31省市土地利用情况和GDP数据
原创SPSS Modeler用K-means(K-均值)聚类、CHAID、CART决策树分析31省市土地利用情况和GDP数据
原创
全文链接:http://tecdat.cn/?p=32840
原文出处:拓端数据部落公众号
随着经济的快速发展和城市化进程的不断推进,土地资源的利用和管理成为了一项极为重要的任务。而对于全国各省市而言,如何合理利用土地资源,通过科学的方法进行规划和管理,是提高土地利用效率的关键。
本文旨在应用SPSS Modeler,帮助客户采用K-means(K-均值)聚类、CHAID、CART决策树等方法,对31个省市的土地利用情况数据进行分析和建模,以期提供科学有效的土地利用规划和管理策略。
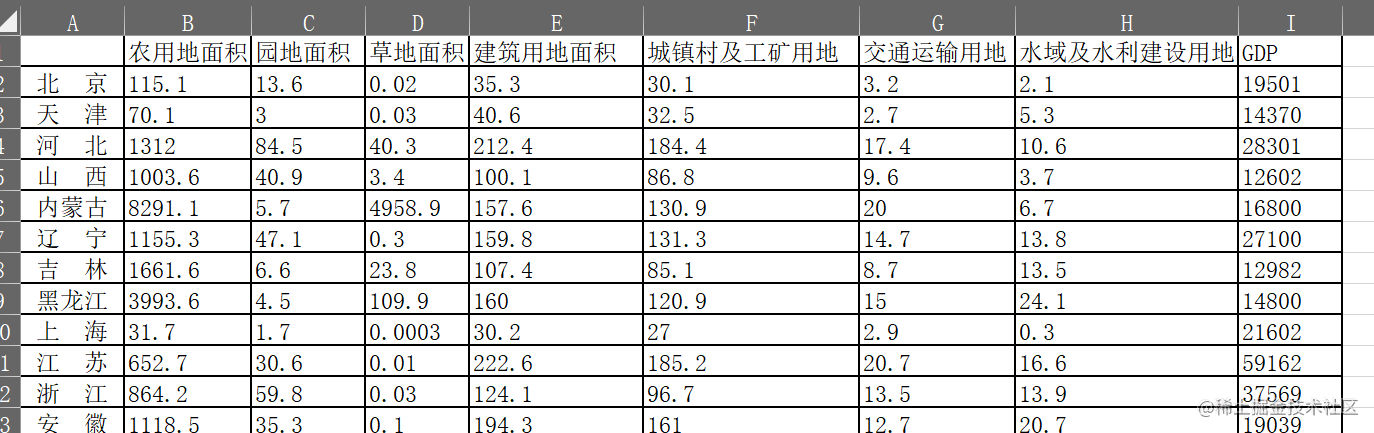
31省市土地利用情况数据
数据流
本文使用的数据来自于国家统计局发布的31省市土地利用情况数据,选取31个省市作为研究对象,并选取了包括草地、耕地、园地、林地、水域和建设用地等7种土地类型的利用情况数据。然后,使用SPSS Modeler进行数据清洗、聚类、决策树等步骤,最终得到模型结果。
K-means(K-均值)聚类
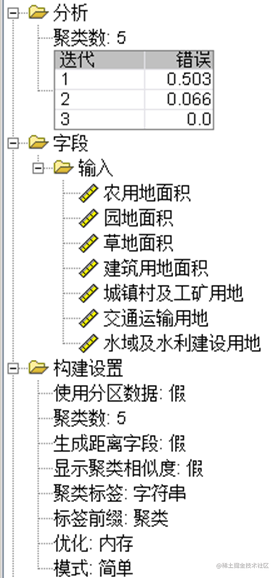
在对完整的数据集进行初步分析后,本文采用K-means聚类算法对数据集进行聚类分析。在聚类过程中,我们首先需要确定聚类的个数k。根据肘部法则和轮廓系数法则,我们得出最终选择k=5为较为合适的聚类数目。通过SPSS Modeler的K-means节点进行计算,得到了以下聚类概况、聚类类别和散点图结果。





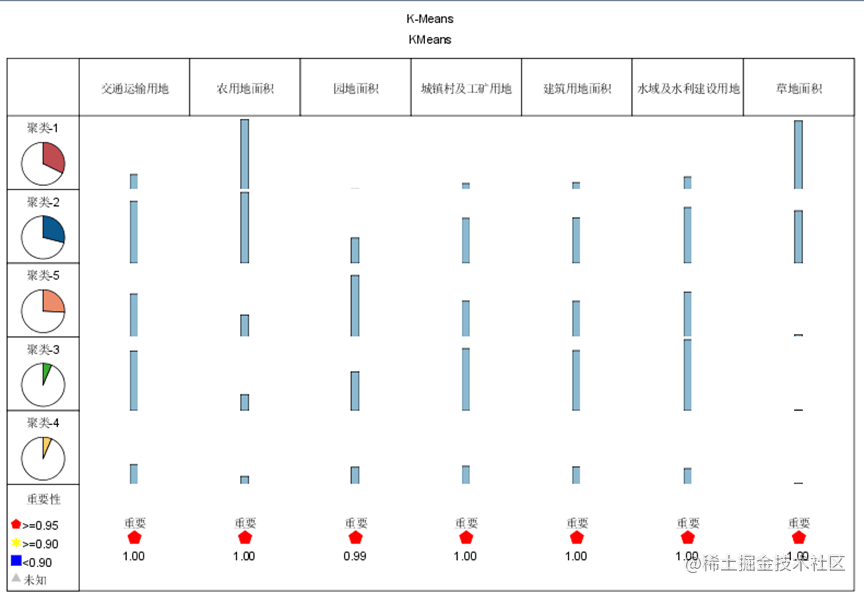
聚类概况
聚类类别
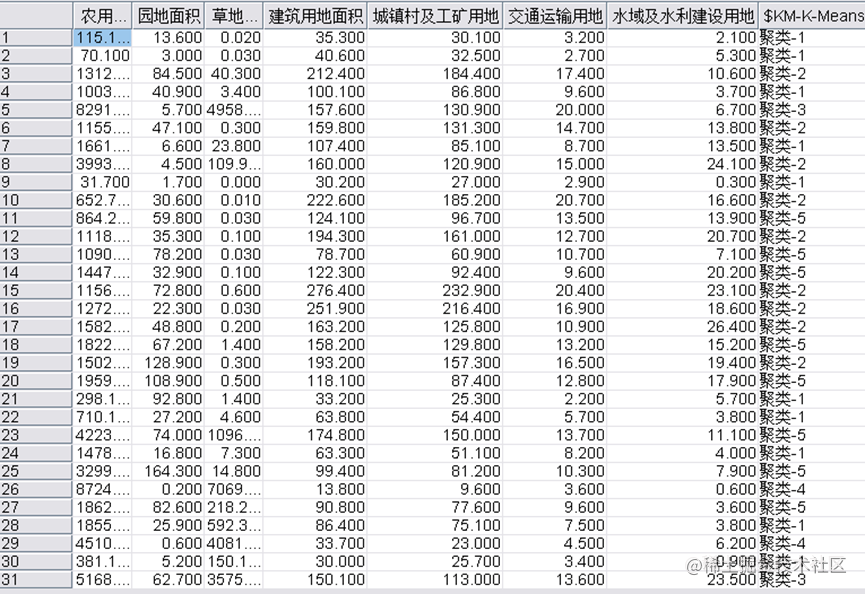
通过分类结果我们不难看出,同类省份基本上是相邻省份,或是区域类型(沿海、内陆)相似的省份,对于同类省份,我们可以采取相似的管理制度,使同等级省份得到更好的发展,也可以利用政策方式让高等级省份带动低等级省份发展。
CHAID决策树
在进行完K-means聚类分析后,为了更好地了解各个类别的特征和关系,本文使用CHAID决策树算法对数据集GDP的影响因素进行进一步的分析。首先使用SPSS Modeler的CHAID节点进行计算,得到以下变量重要性和决策树结果。
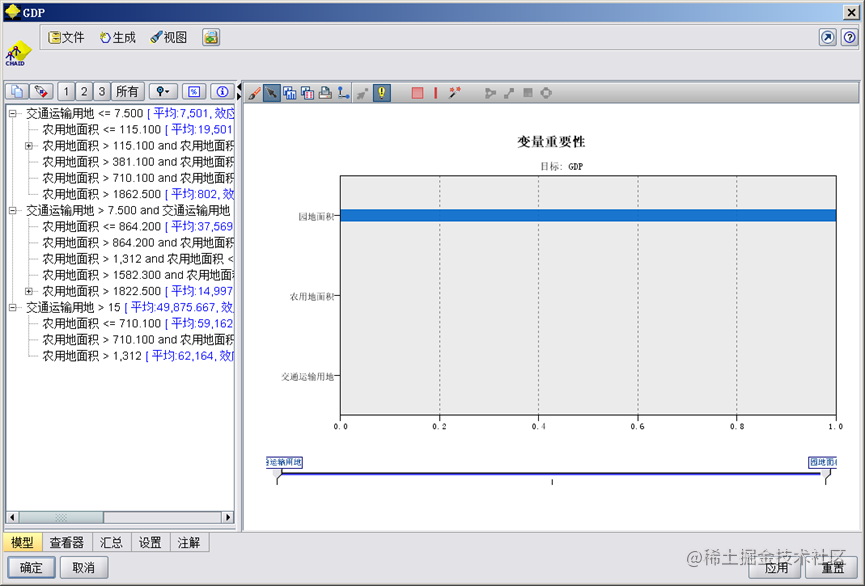
变量重要性
在CHAID决策树算法中,我们使用卡方值(χ2)来表征每个变量的重要性。具体而言,卡方值越大,则该变量在分类中起到的作用越大。在本文的分析中,最具有代表性的变量是园地、农用地和交通用地比重。
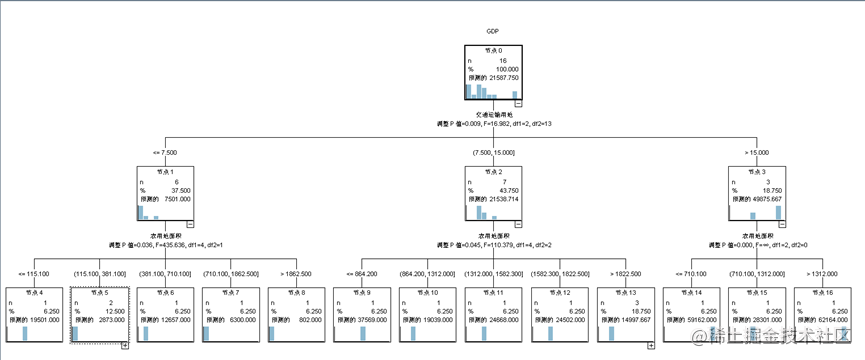
决策树结果
通过CHAID决策树算法,我们得到了以下的决策树模型。其中每个叶子节点代表一类,而每个内部节点包含了一个决策规则,用于判断不同属性值的记录应该属于哪一个分支。在决策树中房地产用地比重、建设用地比重和城市扩张程度等变量对分类结果有较大的影响。

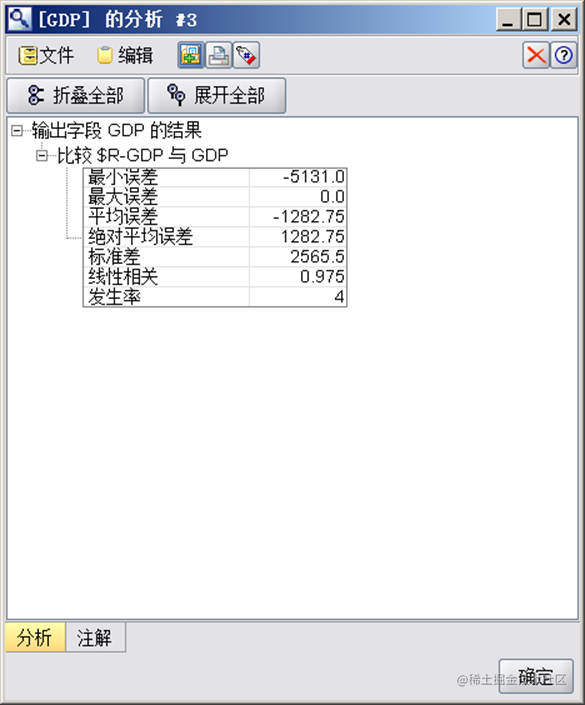
模型误差
为了检验CHAID决策树模型的性能,我们采用随机抽样的方法将数据集分为训练集和测试集,然后利用训练集来训练模型,并使用测试集来验证模型的预测精度。
CART决策树:
除了使用CHAID决策树算法外,本文还采用了CART决策树算法对数据进行建模。通过SPSS Modeler的C&RT节点进行计算,得到以下变量重要性和决策树结构。 ?
变量重要性
在CART决策树算法中,我们使用基尼指数(Gini Index)来衡量每个变量的重要性。具体而言,基尼指数越小,则该变量在分类中起到的作用越大。在本文的分析中,最具有代表性的变量是交通、建筑和工矿用地面积。
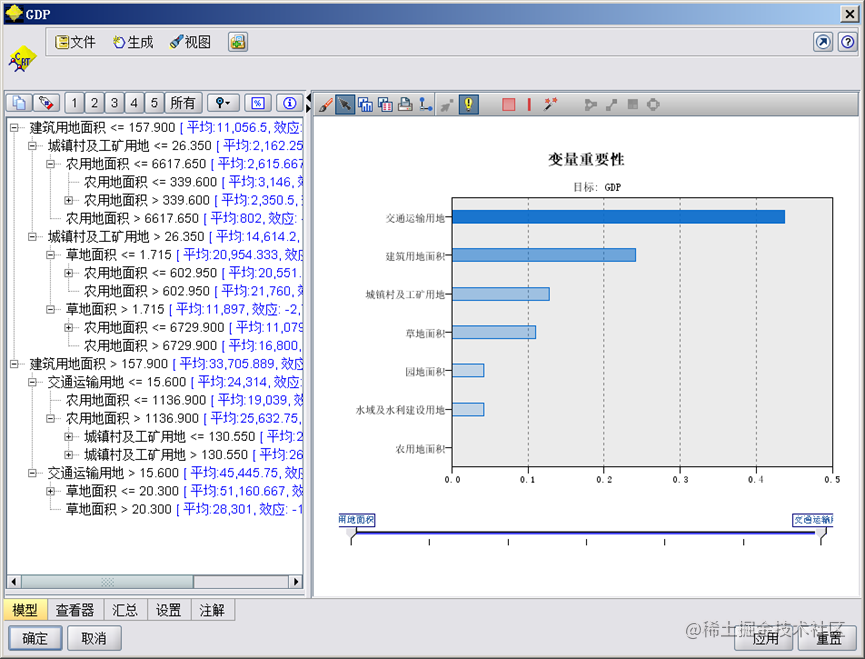
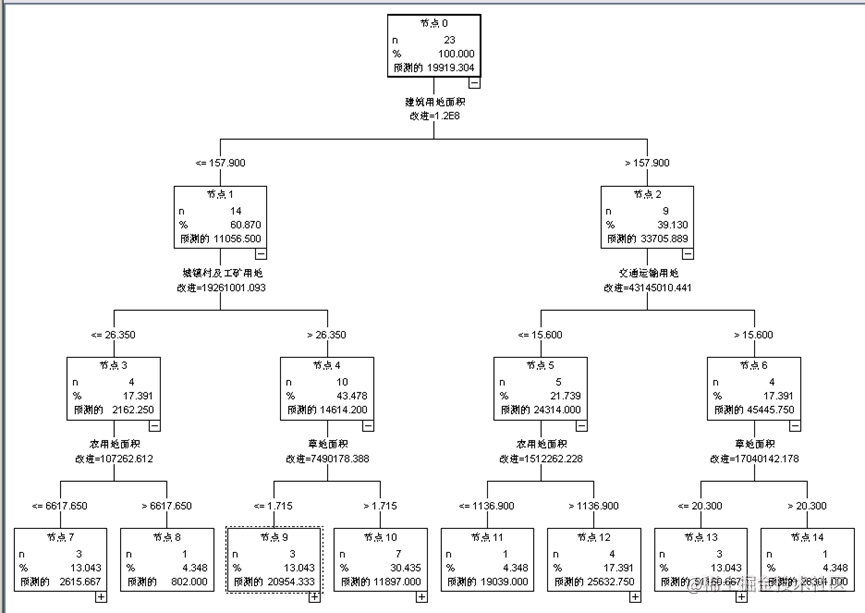
决策树结构
通过CART决策树算法,我们得到了以下的决策树模型。在该模型中,每个内部节点代表一个判断规则,而每个叶子节点代表一个分类。最终的分类结果与CHAID决策树模型比较相似,也可提供对土地利用管理的一些启示。

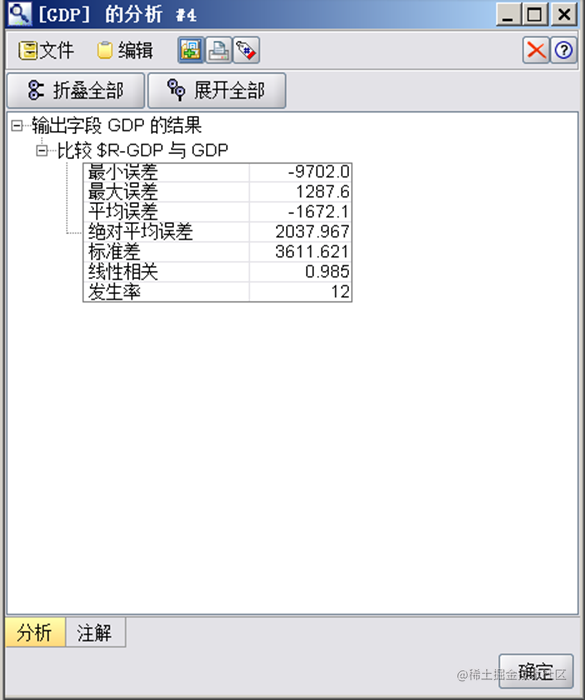
模型误差结果:
同样采用随机抽样的方法将数据集分为训练集和测试集,使用训练集训练模型,并使用测试集验证模型预测的准确性。
结论:
最终我们得到了以下结果文件:
本文旨在应用SPSS Modeler,采用K-means(K-均值)聚类、CHAID、CART决策树等方法,对31个省市的土地利用情况数据进行分析和建模,并为科学有效的土地利用规划和管理策略提供参考。通过聚类和决策树分析,我们得出以下结论:
1.不同省市的土地利用存在显著差异,按主要利用类型可分为5类;
2.交通、建筑用地面积比重是主要影响土地利用的因素;
3.通过CHAID和CART决策树算法,我们可以较精确地对不同地区的土地利用进行分类,并提出相应的管理建议。
本文的研究结论对于全国土地资源的利用和管理具有一定的参考价值,其方法也可以在其他领域中得到应用和推广。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。