kafka 集群部署
原创kafka 集群部署
原创
一、环境配置
1.关闭防火墙,关闭selinux(每个节点操作)
systemctl stop firewalld systemctl disable firewalld 关闭selinux
vim /etc/sysconfig/selinux SELINUX=disabled 注:需要重启服务器后生效
配置主机名(每个节点操作)
hostnamectl set-hostname kafka1 hostnamectl set-hostname kafka2 hostnamectl set-hostname kafka3 编辑host 文件 (每个节点操作)
vim /etc/hosts
172.17.6.14 kafka1
172.17.6.15 kafka2
172.17.6.16 kafka3 二、部署zookeeper集群
1.下载安装
tar -zxf zookeeper-3.4.14.tar.gz
mv zookeeper-3.4.14 /usr/local/
cd /usr/local/
ln -s zookeeper-3.4.14 zookeeper 2.编辑配置文件
cd /usr/local/zookeeper/conf
vim zoo.cfg
#zookeeper 服务器与客户端心跳时间,单位ms
tickTime=2000
#Leader和Follower初始连接时能容忍的最多心跳数( tickTime的数量),这里表示为10*2s
initLimit=10
##Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
syncLimit=5
#定义数据目录和日志存储目录
dataDir=/data/zookeeper/zkdata
dataLogDir=/data/zookeeper/zklog
# 访问 zookeeper的端口
clientPort=2181
# 客户端连接超时时间ms
maxClientCnxns=600
#添加集群信息
server.1=kafka1:2888:3888
server.2=kafka2:2888:3888
server.3=kafka3:2888:38883. 将配置复制到其他节点
scp /usr/local/zookeeper kafka2:/usr/local/
scp /usr/local/zookeeper kafka3:/usr/local/ 4.在每个节点上创建数据目录和日志目录
mkdir -p /data/zookeeper/zkdata
mkdir -p /data/zookeeper/zklog 5.在每个节点生成节点id
#在kafka1 节点操作
echo 1 > /data/zookeeper/zkdata/myid
#在kafka2 节点操作
echo 2 > /data/zookeeper/zkdata/myid
#在kafka3 节点操作
echo 3 > /data/zookeeper/zkdata/myid 6.配置systemd 来管理zookeeper
vim /usr/lib/systemd/system/zookeeper.service
[Unit]
Description=systemctl zookeeper
[Service]
Type=forking
ExecStart=/usr/local/zookeeper/bin/zkServer.sh start
ExecStop=/usr/local/zookeeper/bin/zkServer.sh stop
ExecReload=/usr/local/zookeeper/bin/zkServer.sh restart
RestartSec=3
StartLimitBurst=5
Restart=always
[Install]
WantedBy=multi-user.target复制到其它节点
#复制到kafka2
cp /usr/lib/systemd/system/zookeeper.service kafka2:/usr/lib/systemd/system/
#复制到kafka2
cp /usr/lib/systemd/system/zookeeper.service kafka2:/usr/lib/systemd/system/7.启动zookeeper
#在每个节点操作
systemctl daemon-reload
systemctl start zookeeper
systemctl enable zookeeper 三、部署kafka集群
这里生产环境使用kafka_2.11-2.2.0 来进行部署
1.下载安装
wget https://archive.apache.org/dist/kafka/2.2.0/kafka_2.12-2.2.0.tgz
tar -zxf kafka_2.12-2.2.0.tgz
mv kafka_2.12-2.2.0 /usr/local/
ln -s /usr/local/kafka 2.编辑配置文件 /usr/local/kafka/config/server.properties
#定义broker id,不能重复,只能为数字
broker.id=1
listener.security.protocol.map=PUBLIC_CLIENT:PLAINTEXT,PLAINTEXT:PLAINTEXT
listeners=PLAINTEXT://172.17.6.14:9092,PUBLIC_CLIENT://0.0.0.0:59092
advertised.listeners=PLAINTEXT://172.17.6.14:9092,PUBLIC_CLIENT://82.157.76.227:59092
#处理网络请求的线程数量
num.network.threads=4
#处理磁盘io的线程数量
num.io.threads=4
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#socket请求的最大字节数。为了防止内存溢出,message.max.bytes必然要小于此值
socket.request.max.bytes=104857600
#定义topic数据储路径
log.dirs=/data/kafka/kafka-logs
#每个topic的默认分区数
num.partitions=30
#用来读取日志文件的线程数量,对应每一个log.dirs 若此参数为2 log.dirs 为2个目录 那么就会有4个线程来读取
num.recovery.threads.per.data.dir=1
#元数据内部主题“__consumer_offsets”和“__transaction_state”的复制因子,默认为3 ,建议大于1。
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=2
transaction.state.log.min.isr=2
kafka offset的过期时间,单位为分钟
offsets.retention.minutes=10080
#用于定期检查offset过期数据的检查周期,单位ms
offsets.retention.check.interval.ms=600000
#消费组自动提交的位置,默认为latest (earliest)
auto.offset.reset=latest
#消息的过期时间,单位小时
log.retention.hours=720
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
# 连接zookeeper的集群地址
zookeeper.connect=172.17.6.14:2181,172.17.6.15:2181,172.17.6.16:2181
zookeeper.connection.timeout.ms=6000
#推迟消费组接收到成员加入请求后本应立即开启的rebalance,默认为3ms
group.initial.rebalance.delay.ms=3ms
#broker能接收的单条最大消息的大小,默认1M
message.max.bytes=15728640
replica.fetch.max.bytes=15728640
# 是否开启删除topic
delete.topic.enable=true
#是否开启自动创建topic
auto.create.topics.enable=true3. 将配置复制到其它节点
scp -r /usr/local/kafka kafka2:/usr/local/
scp -r /usr/local/kafka kafka3:/usr/local/ 4.在每个节点创建kafka数据目录
mkdir -p /data/kafka/kafka-logs 编辑kafka2 的配置
broker.id=2
listeners=PLAINTEXT://172.17.6.15:9092,PUBLIC_CLIENT://0.0.0.0:59092
advertised.listeners=PLAINTEXT://172.17.6.15:9092,PUBLIC_CLIENT://82.157.76.227:59092注:PUBLIC_CLIENT 为定义的外网地址 ,如果没有外网环境,此配置可以取消。
编辑kafka3 的配置
broker.id=3
listeners=PLAINTEXT://172.17.6.15:9092,PUBLIC_CLIENT://0.0.0.0:59092
advertised.listeners=PLAINTEXT://172.17.6.16:9092,PUBLIC_CLIENT://82.157.76.227:590925.配置systemd 来管理kafka
vim /usr/lib/systemd/system/kafka.service
[Unit]
Description=Kafka Service
[Service]
Type=forking
LimitNOFILE=102400
Environment=JAVA_HOME=/usr/local/jdk8
ExecStart=/usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh
RestartSec=3
StartLimitBurst=5
Restart=always
[Install]
WantedBy=multi-user.target复制到其他节点
cp /usr/lib/systemd/system/kafka.service kafka2:/usr/lib/systemd/system/
cp /usr/lib/systemd/system/kafka.service kafka3:/usr/lib/systemd/system/6.启动kafka服务
systemctl daemon-reload
systemctl start kafka
systemctl enable kafka 四、kafka 运维管理
4.1 使用kafka 命令进行管理
1.创建 topic
./bin/kafka-topics.sh --bootstrap-server broker_host:port --create --topic my_topic_name \
--partitions 20 --replication-factor 3 --config x=y 注 :此命令是在kafka部署目录中操作
参数 详解 :
--bootstrap-server : kafka集群地址
--create :执行创创建操作
--topic :topic名称
--partitions :topic 的分区数
--replication-factor topic 的副本
--config: 可选,创建 topic指定topic参数 配置
2.修改topic
增加topic分区数
./bin/kafka-topics.sh --bootstrap-server broker_host:port --alter --topic my_topic_name \
--partitions 30 --alter 表示修改topic的参数配置
添加配置
./bin/kafka-configs.sh --bootstrap-server broker_host:port --entity-type topics --entity-name my_topic_name --alter --add-config x=y 删除配置
./bin/kafka-configs.sh --bootstrap-server broker_host:port --entity-type topics --entity-name my_topic_name --alter --delete-config x 删除一个topic
./bin/kafka-topics.sh --bootstrap-server broker_host:port --delete --topic my_topic_name 3.检查消费组offset
./bin/kafka-consumer-groups.sh --bootstrap-server broker_host:port--describe --group my-group --describe 显示表示信息
--group 消费组名称
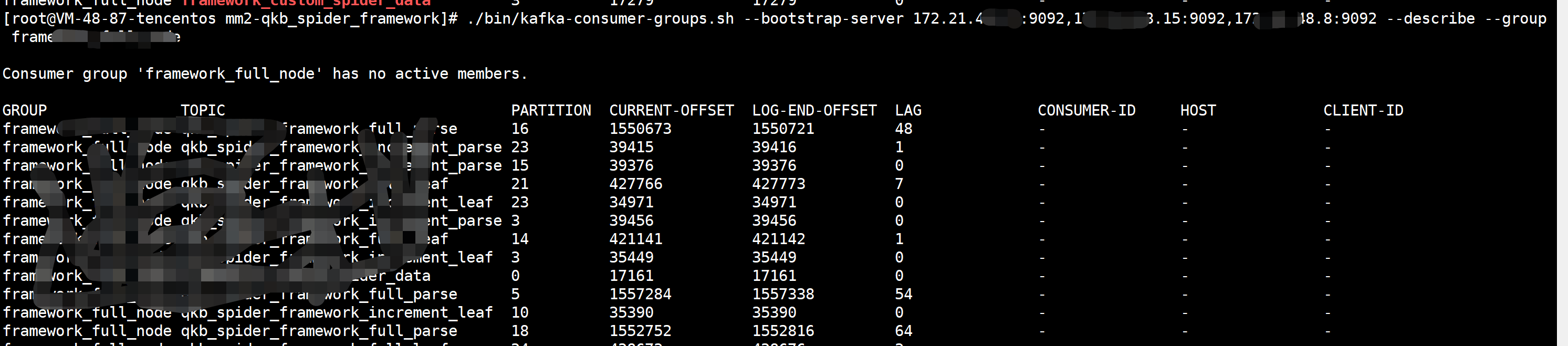
4.消费组管理
列出消费组
./bin/kafka-consumer-groups.sh --bootstrap-server broker_host:port --list --members:此选项提供消费者组中所有活跃成员的列表
./bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group --members 要手动删除一个或多个消费者组
./bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --delete --group my-group --group my-other-group 将消费组的offset 重置为最新
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --reset-offsets --group consumergroup1 --topic topic1 --to-latest 它有 3 个执行选项:
- --execute : 执行 --reset-offsets 进程。
- --export :将结果导出为 CSV 格式。
--reset-offsets 还有以下场景可供选择(至少必须选择一种场景):
- --to-datetime <String: datetime> :将偏移量重置为日期时间的偏移量。格式:'YYYY-MM-DDTHH:mm:SS.sss'
- --to-earliest :将偏移量重置为最早的偏移量。
- --to-latest :将偏移量重置为最新偏移量。
- --shift-by <Long: number-of-offsets> :重置偏移量,将当前偏移量移动“n”,其中“n”可以是正数或负数。
- --from-file :将偏移量重置为 CSV 文件中定义的值。
- --to-current :将偏移量重置为当前偏移量。
- --by-duration <String:uration> :将偏移量重置为从当前时间戳开始按持续时间偏移。格式:'PnDTnHnMnS'
- --to-offset :将偏移量重置为特定偏移量。
请注意,超出范围的偏移将调整为可用的偏移端。例如,如果偏移结束为10,偏移移位请求为15,则实际上会选择10处的偏移。
4.2 使用kafka-ui 进行管理(推荐)
4.2.1 kafka-ui 环境部署
注:kafka ui 这里用的是docker 镜像,需要提前部署docker环境
#创建 kafka ui 启动脚本
vim restart_kafka-ui.sh
docker rm -f kafka-ui || echo " OK……!"
docker run --name=kafka-ui -p 80:8080 \
-e KAFKA_CLUSTERS_0_NAME=kafka1 \
-e KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=172.17.6.14:9092,172.17.6.15:9092,172.17.6.16:9092 \
--detach provectuslabs/kafka-ui:master
参数说明: KAFKA_CLUSTERS_0_NAME=kafka1 表示 第一个集群。kafka-ui 可以同时管理多个集
浏览器访问 : http://IP_server:80
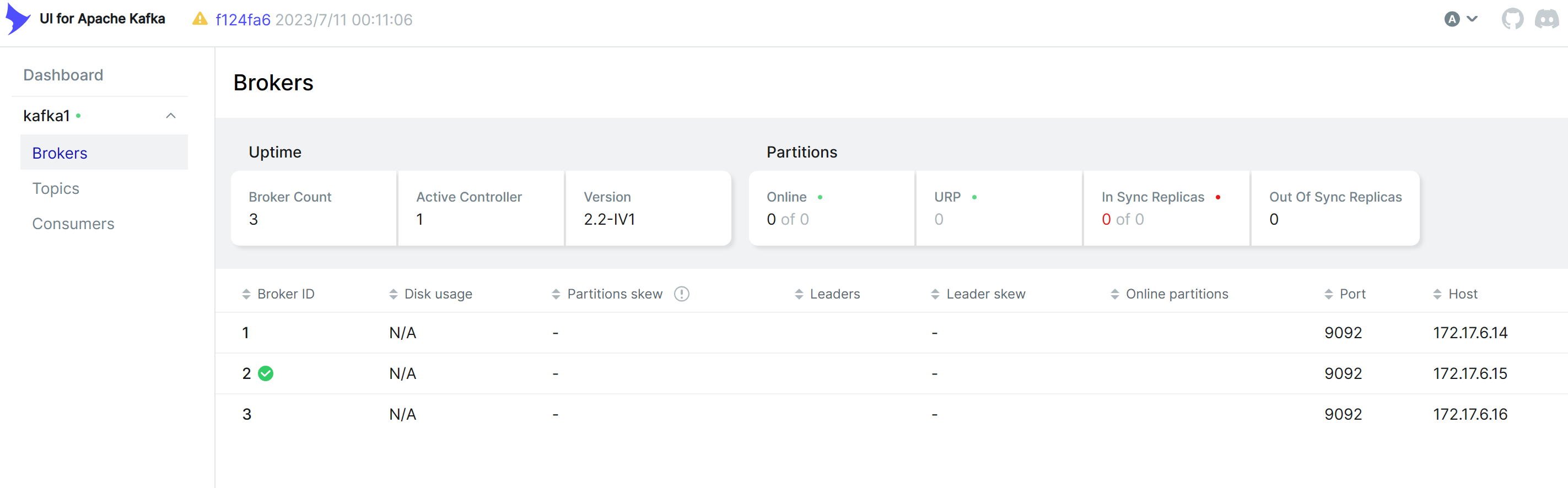
查看broker状态

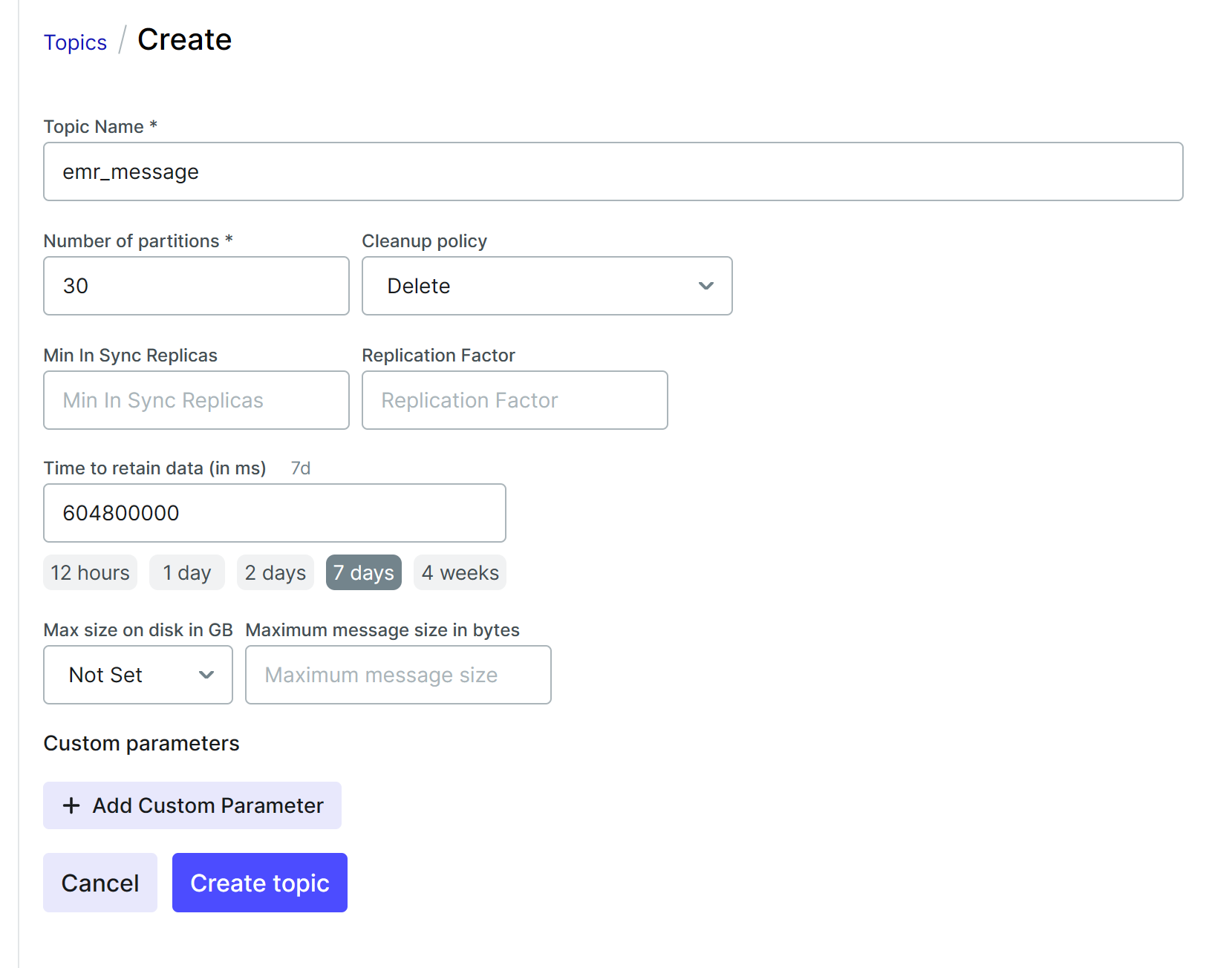
创建topic


原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。