每日学术速递7.15

点击下方卡片,关注「AiCharm」公众号
Subjects: cs.CV
1.Collaborative Score Distillation for Consistent Visual Synthesis

标题:协作分数蒸馏以实现一致的视觉合成
作者:Subin Kim, Kyungmin Lee, June Suk Choi, Jongheon Jeong, Kihyuk Sohn, Jinwoo Shin
文章链接:https://arxiv.org/abs/2307.04787
项目代码:https://subin-kim-cv.github.io/CSD/





摘要:
大规模文本到图像扩散模型的生成先验可以在不同的视觉模式上实现广泛的新一代和编辑应用程序。然而,当使这些先验适应复杂的视觉模式(通常表示为多个图像(例如视频))时,在一组图像之间实现一致性具有挑战性。在本文中,我们采用一种新颖的方法来应对这一挑战,即协作分数蒸馏(CSD)。CSD 基于 Stein 变分梯度下降 (SVGD)。具体来说,我们建议将多个样本视为 SVGD 更新中的“粒子”,并结合它们的评分函数来同步提取一组图像上的生成先验。因此,CSD 有助于跨 2D 图像的信息无缝集成,从而在多个样本之间实现一致的视觉合成。我们展示了 CSD 在各种任务中的有效性,包括全景图像、视频和 3D 场景的可视化编辑。我们的结果强调了 CSD 作为增强样本间一致性的通用方法的能力,从而扩大了文本到图像扩散模型的适用性。
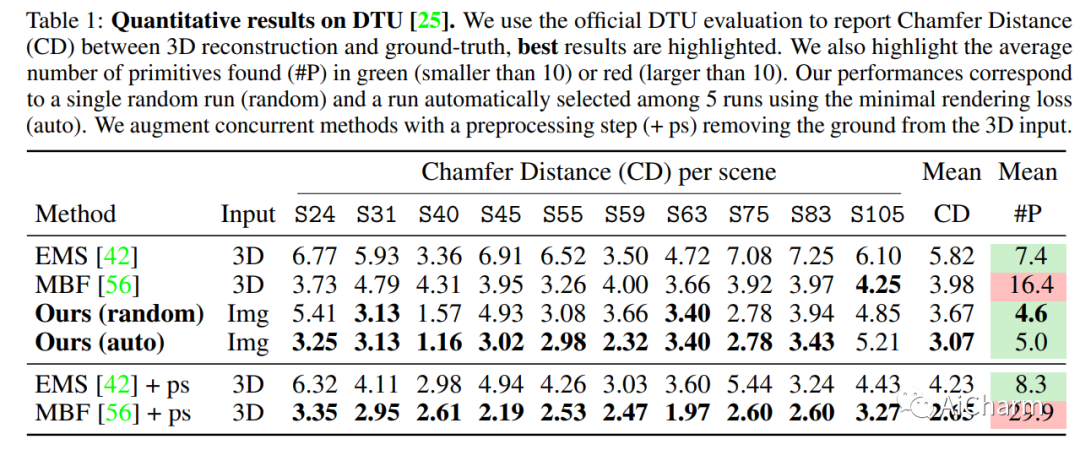
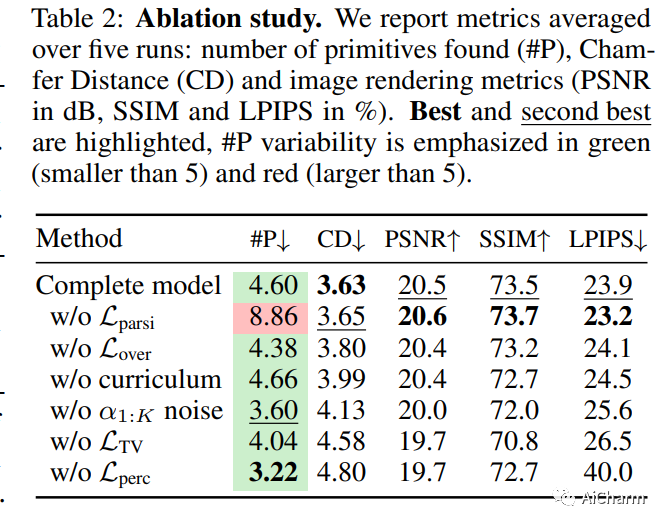
2.Differentiable Blocks World: Qualitative 3D Decomposition by Rendering Primitives

标题:可微块世界:通过渲染基元进行定性 3D 分解
作者:Tom Monnier, Jake Austin, Angjoo Kanazawa, Alexei A. Efros, Mathieu Aubry
文章链接:https://arxiv.org/abs/2307.05473
项目代码:https://www.tmonnier.com/DBW/




摘要:
给定场景的一组校准图像,我们提出了一种通过 3D 图元生成简单、紧凑且可操作的 3D 世界表示的方法。虽然许多方法专注于恢复高保真 3D 场景,但我们专注于将场景解析为由一小组纹理图元组成的中级 3D 表示。这种表示是可解释的、易于操作并且适合基于物理的模拟。此外,与依赖 3D 输入数据的现有基元分解方法不同,我们的方法通过可微渲染直接对图像进行操作。具体来说,我们将基元建模为纹理超二次网格,并从头开始优化其参数,并降低图像渲染损失。我们强调为每个基元建模透明度的重要性,这对于优化至关重要,并且还可以处理不同数量的基元。我们表明,生成的纹理基元忠实地重建了输入图像并准确地对可见 3D 点进行建模,同时提供了不可见对象区域的非模态形状补全。我们将我们的方法与 DTU 不同场景的最新方法进行比较,并展示其在 BlendedMVS 和 Nerfstudio 的现实捕捉中的稳健性。我们还展示了如何使用我们的结果轻松编辑场景或执行物理模拟。代码和视频结果可从此 https URL 获取。
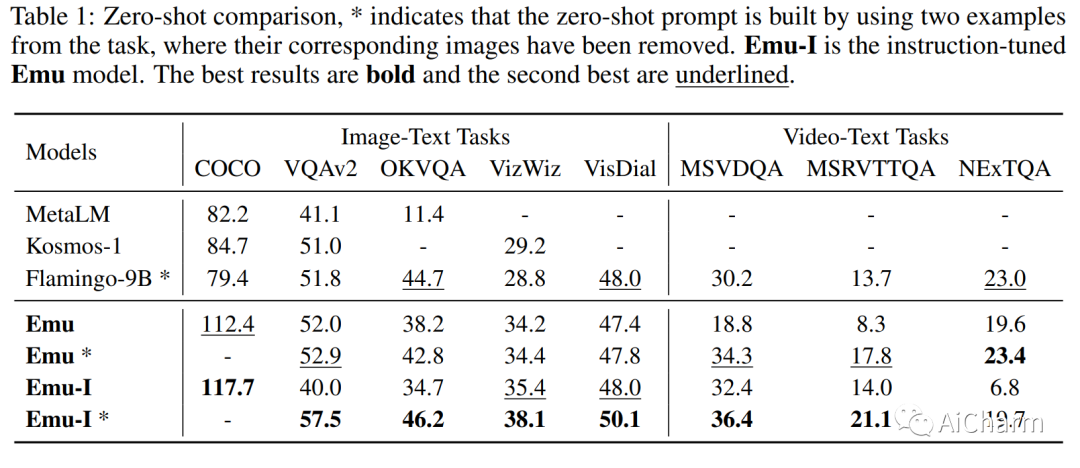
3.Generative Pretraining in Multimodality

标题:多模态生成预训练
作者:Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, Yueze Wang, Hongcheng Gao, Jingjing Liu, Tiejun Huang, Xinlong Wang
文章链接:https://arxiv.org/abs/2307.05222
项目代码:https://github.com/baaivision/Emu





摘要:
我们提出了 Emu,一种基于 Transformer 的多模态基础模型,它可以在多模态上下文中无缝生成图像和文本。这种杂食模型可以通过一个模型适用于所有自回归训练过程,不加区别地接受任何单模态或多模态数据输入(例如,交错的图像、文本和视频)。首先,视觉信号被编码为嵌入,并与文本标记一起形成交错的输入序列。然后,以对下一个文本标记进行分类或对多模态序列中的下一个视觉嵌入进行回归的统一目标,对 Emu 进行端到端训练。这种多功能的多模态使得能够大规模探索不同的预训练数据源,例如具有交错帧和文本的视频、具有交错图像和文本的网页,以及网络规模的图像文本对和视频文本对。Emu 可以作为图像到文本和文本到图像任务的通用多模态接口,并支持上下文图像和文本生成。在广泛的零样本/少样本任务中,包括图像字幕、视觉问答、视频问答和文本到图像生成,与最先进的大型多模态模型相比,Emu 表现出了卓越的性能。通过指令调整实现的多模式助手等扩展功能也具有令人印象深刻的性能。
推荐阅读
CVPR 2023 | 南洋理工、商汤提出E3DGE:2D图片秒出3D形象
ACL 2023奖项公布:3篇最佳论文、39篇杰出论文,多家国内机构上榜


SIGGRAPH 2023论文奖公布,山大、港大获奖,北大、腾讯光子获提名


点击卡片,关注「AiCharm」公众号
喜欢的话,请给我个在看吧!
