每日学术速递7.18

点击下方卡片,关注「AiCharm」公众号
Subjects: cs.CV
1.HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models

标题:HyperDreamBooth:用于文本到图像模型快速个性化的超网络
作者:Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Wei Wei, Tingbo Hou, Yael Pritch, Neal Wadhwa, Michael Rubinstein, Kfir Aberman
文章链接:https://arxiv.org/abs/2307.06949
项目代码:https://hyperdreambooth.github.io/






摘要:
个性化已成为生成人工智能领域的一个突出方面,能够在不同背景和风格下综合个体,同时保持其身份的高保真度。然而,个性化过程在时间和内存要求方面提出了固有的挑战。微调每个个性化模型需要大量的 GPU 时间投入,并且存储每个主题的个性化模型对存储容量要求很高。为了克服这些挑战,我们提出了 HyperDreamBooth——一种能够从单个人图像高效生成一小组个性化权重的超网络。通过将这些权重组合到扩散模型中,再加上快速微调,HyperDreamBooth 可以在各种背景和风格中生成人脸,具有较高的主题细节,同时还保留模型对不同风格和语义修改的关键知识。我们的方法在大约 20 秒内实现了面部个性化,比 DreamBooth 快 25 倍,比文本反转快 125 倍,仅使用一张参考图像,并且具有与 DreamBooth 相同的质量和风格多样性。此外,我们的方法生成的模型比普通 DreamBooth 模型小 10000 倍。项目页面:此 https URL
2.Domain-Agnostic Tuning-Encoder for Fast Personalization of Text-To-Image Models

标题:用于文本到图像模型快速个性化的领域无关调整编码器
作者:Moab Arar, Rinon Gal, Yuval Atzmon, Gal Chechik, Daniel Cohen-Or, Ariel Shamir, Amit H. Bermano
文章链接:https://arxiv.org/abs/2307.06925
项目代码:https://datencoder.github.io/



摘要:
文本到图像(T2I)个性化允许用户通过在自然语言提示中结合自己的视觉概念来指导创意图像生成过程。最近,基于编码器的技术已成为 T2I 个性化的一种新的有效方法,减少了对多个图像和较长训练时间的需求。然而,大多数现有编码器仅限于单类域,这阻碍了它们处理不同概念的能力。在这项工作中,我们提出了一种与领域无关的方法,不需要任何专门的数据集或有关个性化概念的先验信息。我们引入了一种新颖的基于对比的正则化技术,通过将预测的标记推向最接近的现有 CLIP 标记,保持对目标概念特征的高保真度,同时保持预测的嵌入接近潜在空间的可编辑区域。我们的实验结果证明了我们方法的有效性,并显示了学习的标记如何比非正则化模型预测的标记更具语义性。这带来了更好的表示,实现了最先进的性能,同时比以前的方法更灵活。
3.In-context Autoencoder for Context Compression in a Large Language Model

标题:用于大型语言模型中上下文压缩的上下文自动编码器
作者:Tao Ge, Jing Hu, Xun Wang, Si-Qing Chen, Furu Wei
文章链接:https://arxiv.org/abs/2307.06945
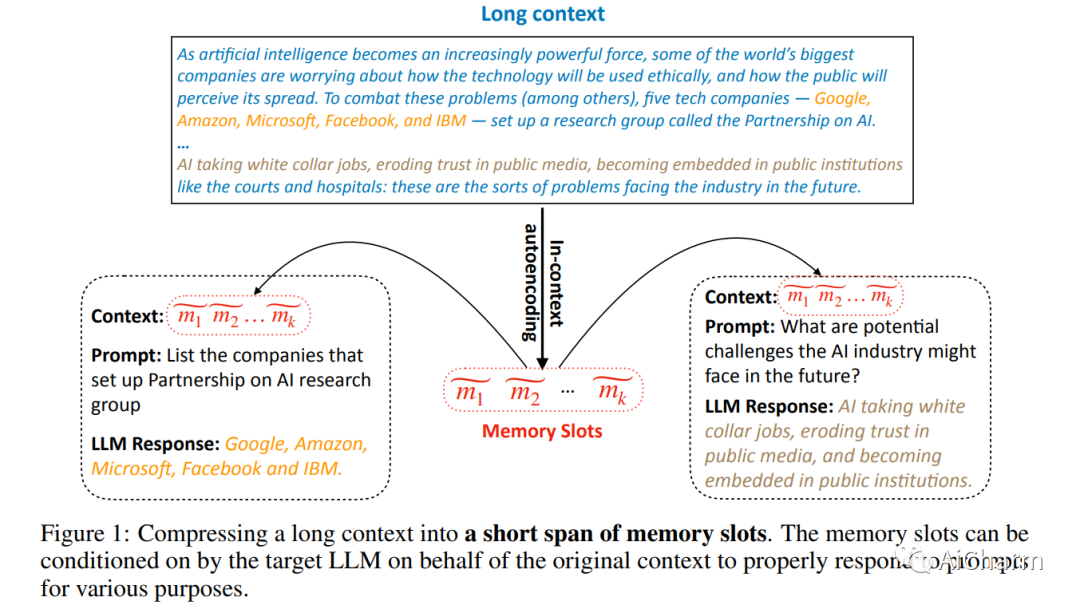







摘要:
我们提出了上下文自动编码器(ICAE),用于大型语言模型(LLM)中的上下文压缩。ICAE 有两个模块:一个采用 LLM 的 LoRA 的可学习编码器,用于将长上下文压缩到有限数量的内存槽中;以及一个固定解码器,它是目标 LLM,可以根据各种目的调节内存槽。我们首先使用自动编码和语言建模目标对大量文本数据对 ICAE 进行预训练,使其能够生成准确、全面地表示原始上下文的内存槽。然后,我们根据少量指令数据对预训练的 ICAE 进行微调,以增强其与各种提示的交互,从而产生所需的响应。我们的实验结果表明,通过我们提出的预训练和微调范例学习的 ICAE 可以有效地产生具有 4× 上下文压缩的内存槽,目标 LLM 可以很好地调节它以响应各种提示。这些有希望的结果表明,ICAE 对其解决长上下文问题的新颖方法及其在实践中减少 LLM 推理的计算和内存开销的潜力具有重要意义,这表明 LLM 上下文管理方面的进一步研究工作。我们的代码和数据将很快发布。
推荐阅读

点击卡片,关注「AiCharm」公众号
喜欢的话,请给我个在看吧!
