每日学术速递7.16

点击下方卡片,关注「AiCharm」公众号
Subjects: cs.CV
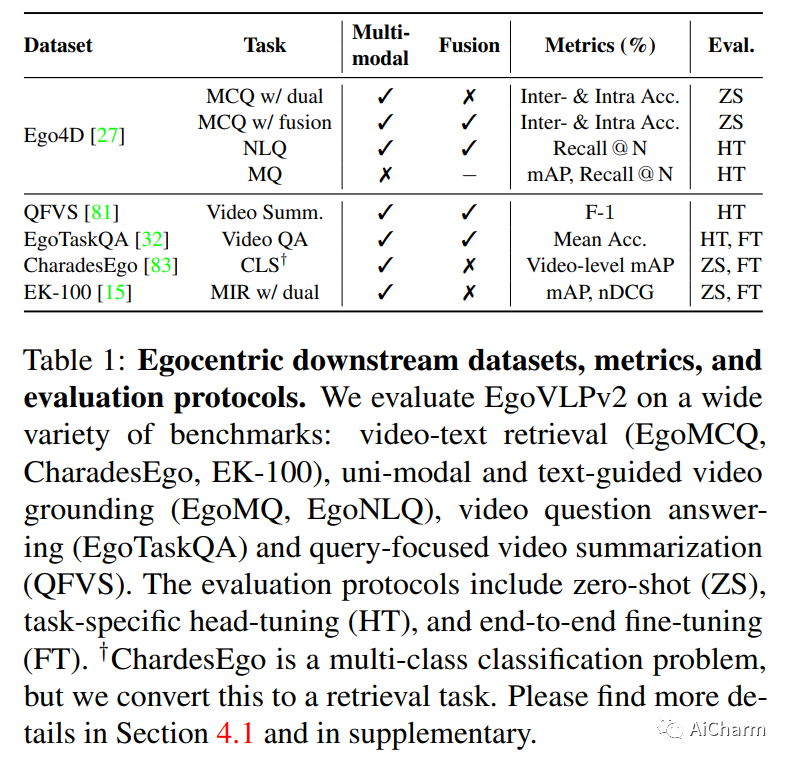
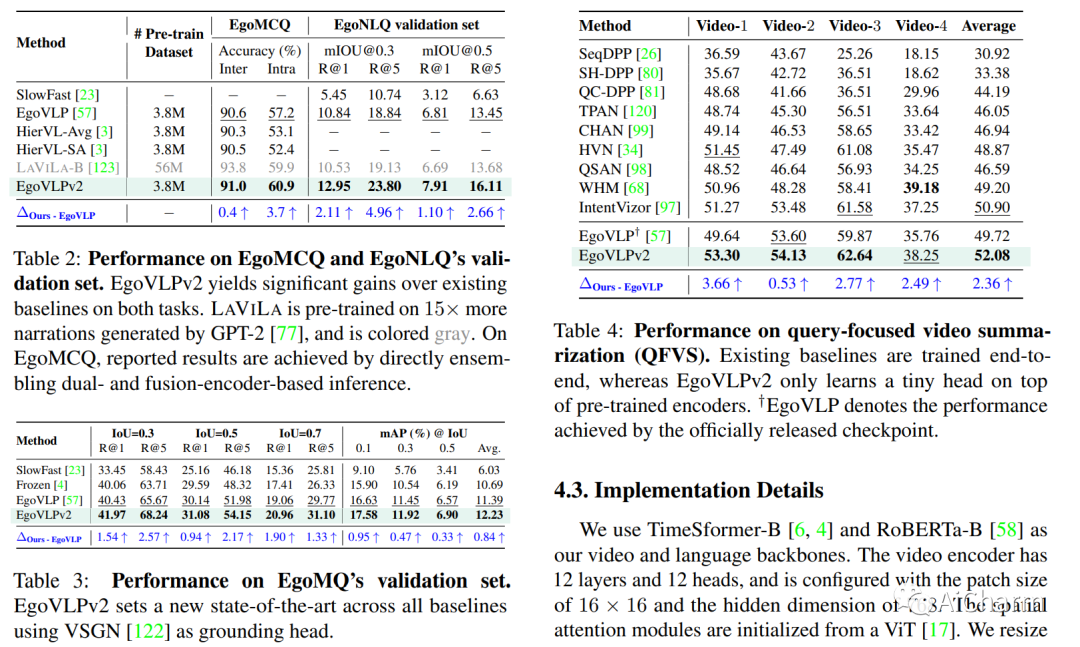
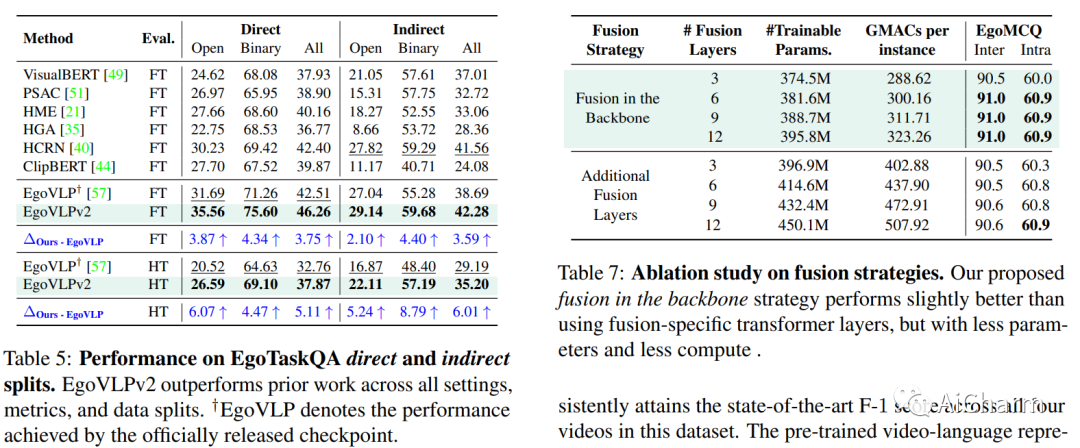
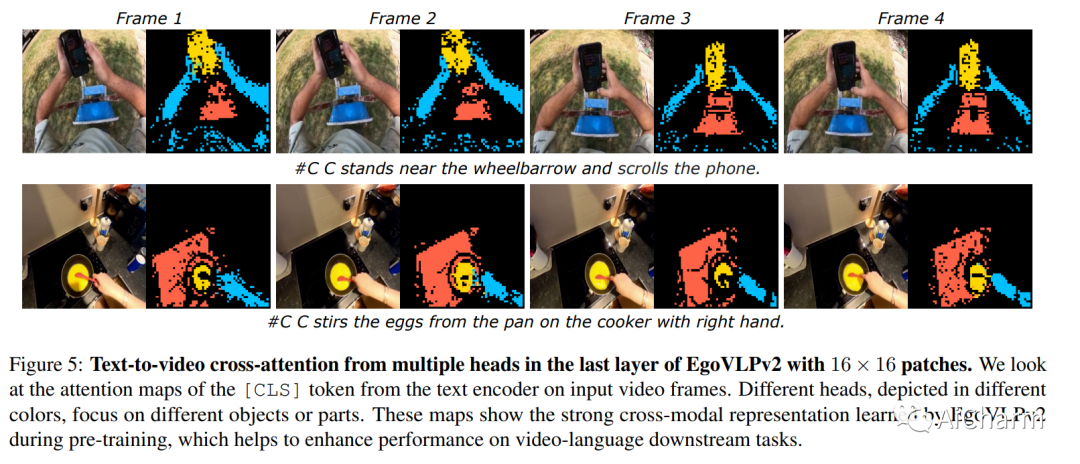
1.EgoVLPv2: Egocentric Video-Language Pre-training with Fusion in the Backbone

标题:EgoVLPv2:以自我为中心的视频语言预训练,主干融合
作者:Shraman Pramanick, Yale Song, Sayan Nag, Kevin Qinghong Lin, Hardik Shah, Mike Zheng Shou, Rama Chellappa, Pengchuan Zhang
文章链接:https://arxiv.org/abs/2307.05463
项目代码:https://shramanpramanick.github.io/EgoVLPv2/
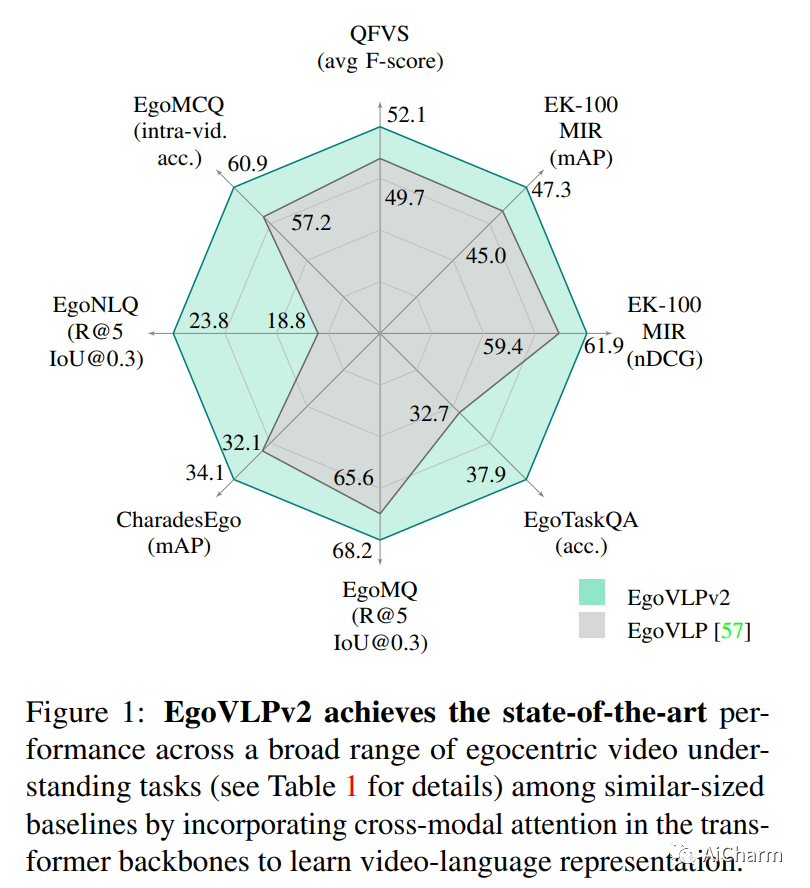
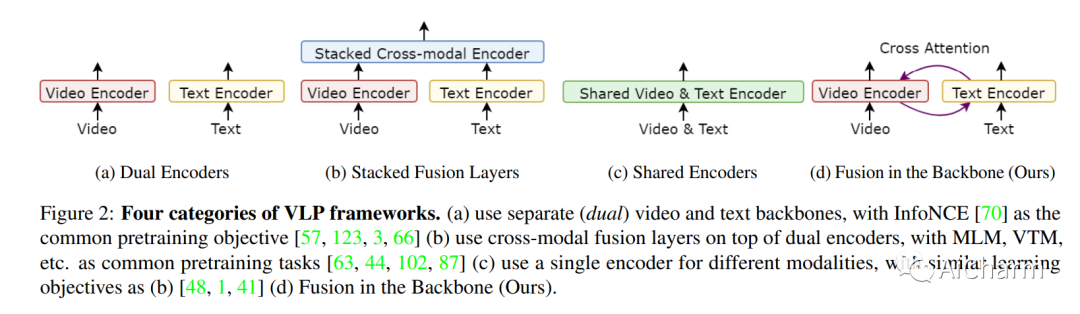
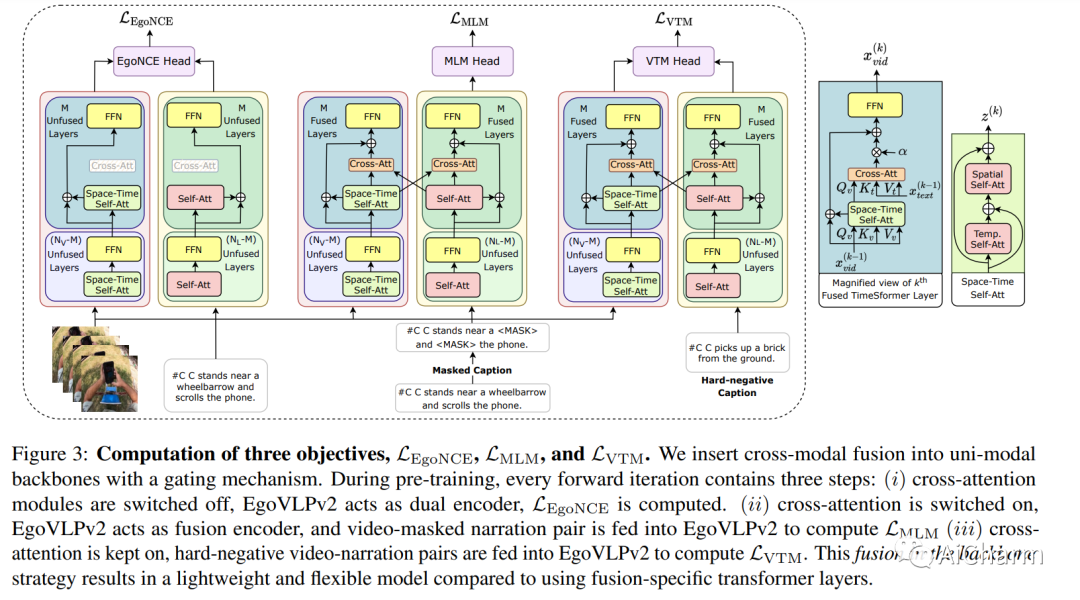
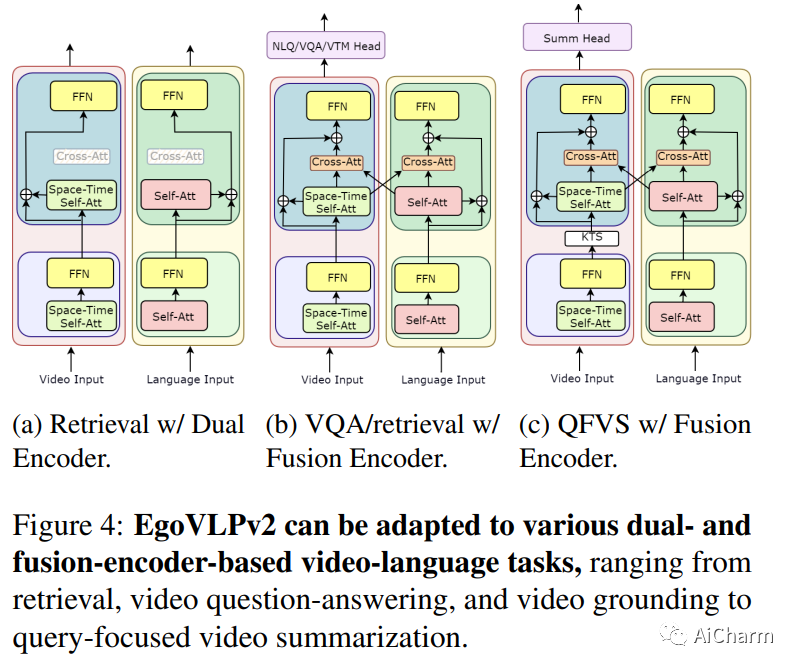
摘要:
视频语言预训练(VLP)由于其泛化到各种视觉和语言任务的能力而变得越来越重要。然而,现有的以自我为中心的 VLP 框架利用单独的视频和语言编码器,并且仅在微调期间学习特定于任务的跨模式信息,限制了统一系统的开发。在这项工作中,我们引入了第二代以自我为中心的视频语言预训练(EgoVLPv2),它通过将跨模态融合直接纳入视频和语言主干中,比上一代有了重大改进。EgoVLPv2在预训练期间学习强大的视频文本表示,并重用跨模态注意力模块以灵活高效的方式支持不同的下游任务,降低微调成本。此外,我们在主干策略中提出的融合比堆叠额外的融合特定层更轻量级且计算效率更高。对各种 VL 任务的大量实验证明了 EgoVLPv2 的有效性,它在所有下游的强大基线上实现了一致的最先进性能。我们的项目页面可以在此 https URL 找到。
2.Efficient 3D Articulated Human Generation with Layered Surface Volumes

标题:具有分层表面体积的高效 3D 铰接人体生成
作者:Yinghao Xu, Wang Yifan, Alexander W. Bergman, Menglei Chai, Bolei Zhou, Gordon Wetzstein
文章链接:https://arxiv.org/abs/2307.05462
项目代码:https://www.computationalimaging.org/publications/lsv/



摘要:
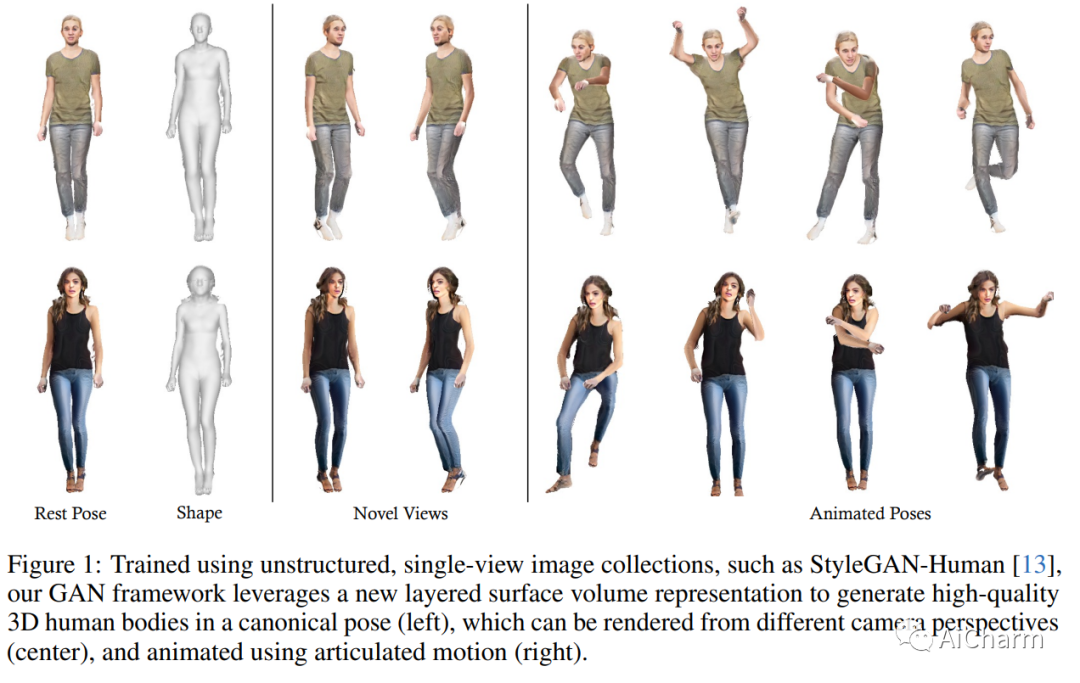
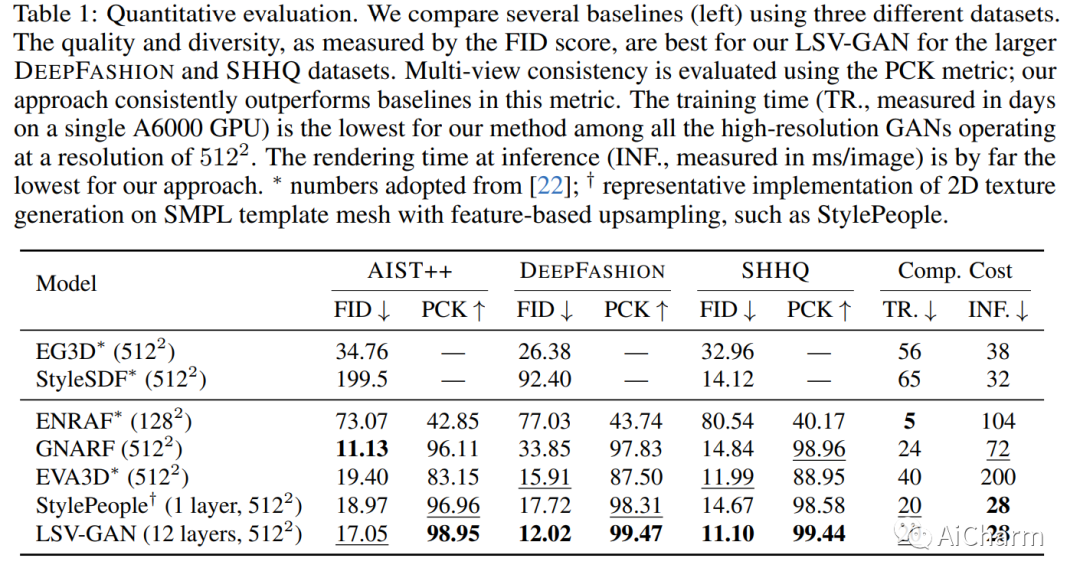
在从虚拟现实到社交平台的各种应用中,获取高质量且多样化的 3D 关节式数字人力资产至关重要。3D 生成对抗网络 (GAN) 等生成方法正在迅速取代费力的手动内容创建工具。然而,现有的 3D GAN 框架通常依赖于利用模板网格(速度快但质量有限)或体积(容量大但渲染速度慢)的场景表示,从而限制了 GAN 设置中的 3D 保真度。在这项工作中,我们引入分层表面体积 (LSV) 作为铰接式数字人类的新 3D 对象表示。LSV 在传统模板周围使用多个纹理网格层来表示人体。这些层使用具有快速可微分光栅化的 alpha 合成进行渲染,并且它们可以被解释为将其容量分配给模板周围有限厚度的流形的体积表示。与传统的单层模板不同,传统的单层模板难以表现头发或配饰等精细的表面外细节,我们的表面体积自然地捕获了这些细节。LSV 可以进行铰接,并且它们在 GAN 设置中表现出卓越的效率,其中 2D 生成器学习合成各个层的 RGBA 纹理。我们的 LSV-GAN 在非结构化、单视图 2D 图像数据集上进行训练,可以生成高质量且视图一致的 3D 关节式数字人类,而不需要视图不一致的 2D 上采样网络。
3.Test-Time Training on Video Streams

标题:视频流测试时训练
作者:Renhao Wang, Yu Sun, Yossi Gandelsman, Xinlei Chen, Alexei A. Efros, Xiaolong Wang
文章链接:https://arxiv.org/abs/2307.05014
项目代码:https://video-ttt.github.io/


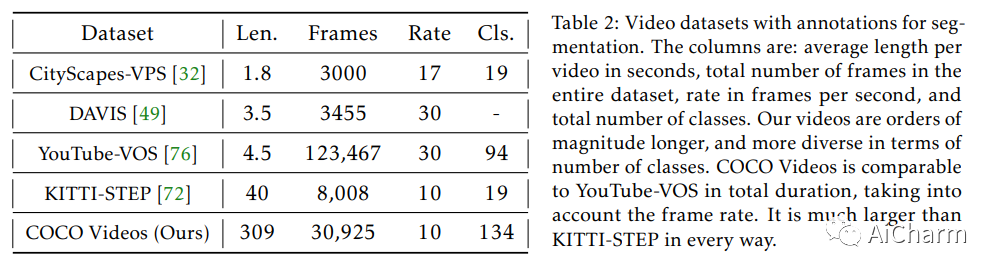

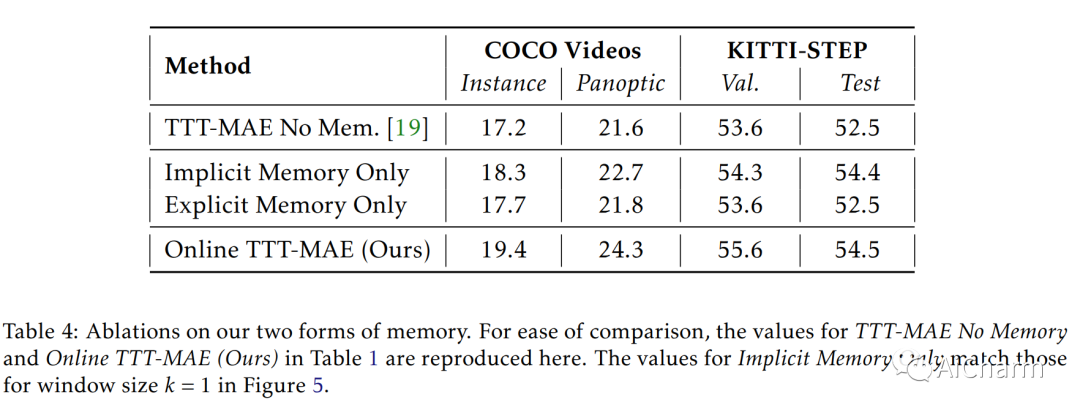
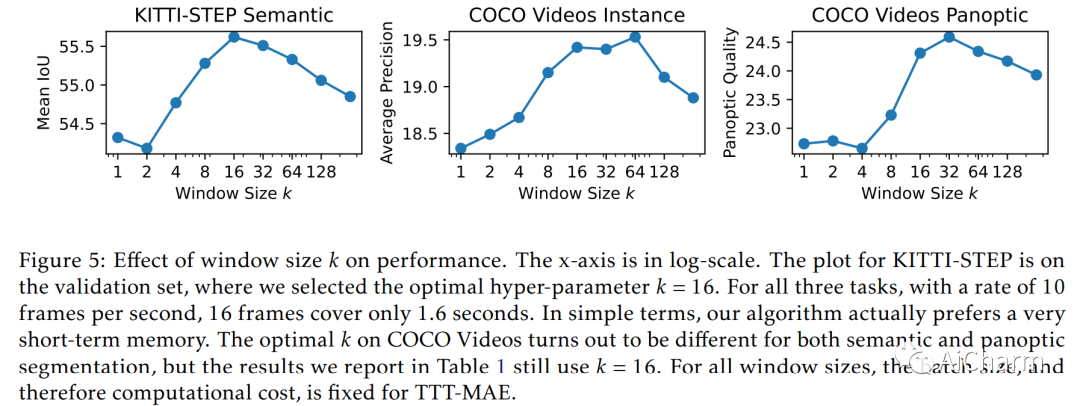
摘要:
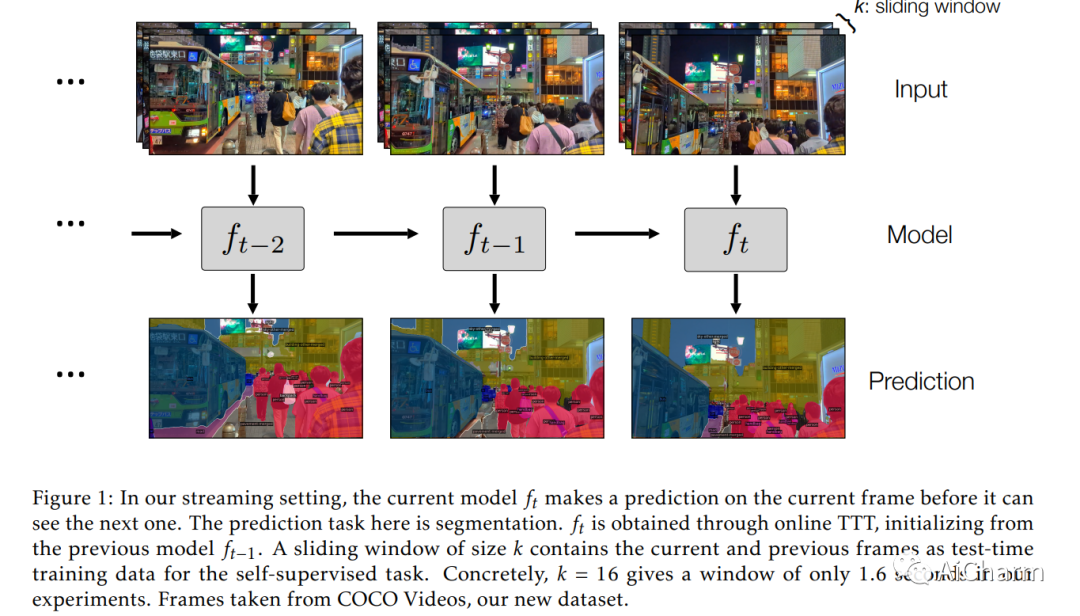
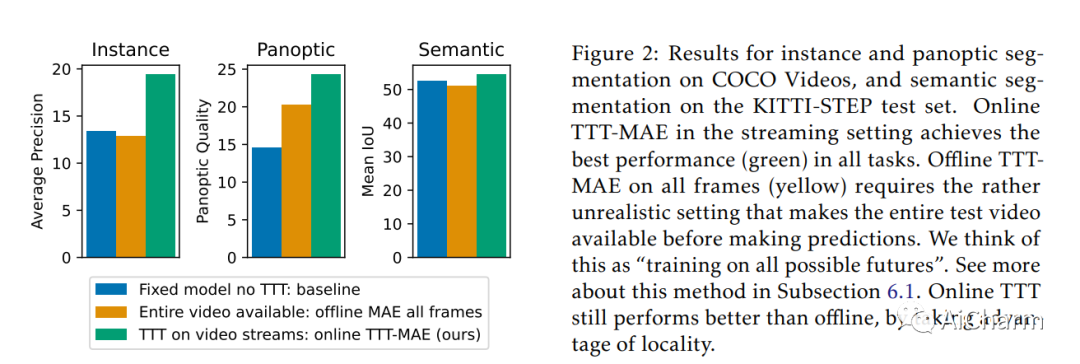
之前的工作已经建立了测试时训练(TTT)作为通用框架,以进一步改进测试时训练的模型。在对每个测试实例进行预测之前,使用自监督任务(例如使用屏蔽自动编码器进行图像重建)在同一实例上训练模型。我们将 TTT 扩展到流设置,其中多个测试实例(在我们的例子中为视频帧)按时间顺序到达。我们的扩展是在线 TTT:当前模型是从之前的模型初始化的,然后在当前帧和之前的一小部分帧窗口上进行训练。在三个真实世界数据集上,在线 TTT 在四项任务上显着优于固定模型基线。例如,全景分割的相对改进为 45% 和 66%。令人惊讶的是,在线 TTT 的性能也优于其离线变体,后者可以访问更多信息,对整个测试视频中的所有帧进行训练,无论时间顺序如何。这与之前使用合成视频的发现不同。我们将本地化概念定义为在线 TTT 相对于线下 TTT 的优势。我们分析了局部性与消融的作用以及基于偏差-方差权衡的理论。