软件测试|web自动化测试神器playwright教程(二十)
原创软件测试|web自动化测试神器playwright教程(二十)
原创
霍格沃兹测试开发Muller老师
发布于 2023-07-31 18:30:54
发布于 2023-07-31 18:30:54
前言
我们都知道,selenium可以实现Chrome浏览器的复用,绕过登录步骤,实现cookie的复用,playwright同样也可以实现该功能。
环境设置
我们在使用selenium进行浏览器复用时,需要提前将Chrome浏览器配置到我们的环境变量中,具体步骤如下:
- 找到Chrome浏览器的安装路径,如下图:
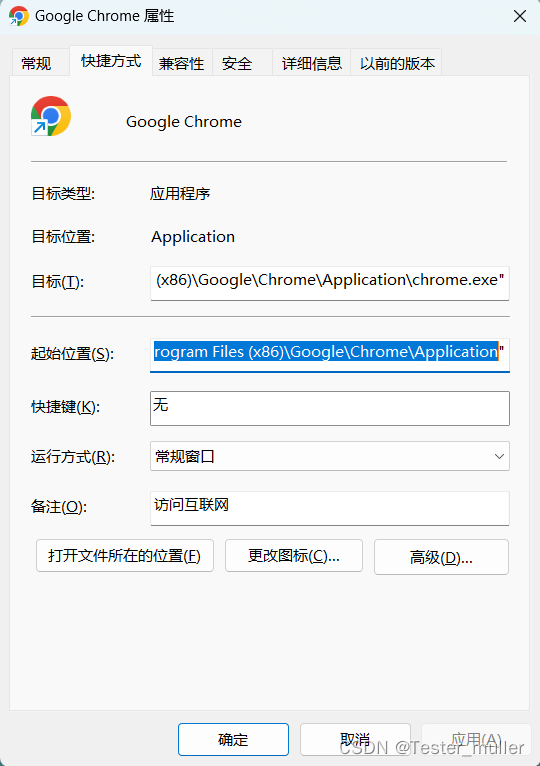
- 将'C:\Program Files (x86)\Google\Chrome\Application'配置到环境变量中,如下图:

- 打开cmd输入命令启动chrome浏览器
- --remote-debugging-port 是指定运行端口,只要没被占用就行,一般为9222
- --user-data-dir 指定运行浏览器的运行数据,新建一个干净目录,不影响系统原来的数据
示例如下:
chrome --remote-debugging-port=9222 --user-data-dir="xxxxxx"运行命令将打开新的浏览器界面,如下图:

参数:
- --incognito 隐私模式打开
- -–start-maximized:窗口最大化
- --new-window:直接打开网址
playwright 复用浏览器
当页面打开后,可以使用connect_over_cdp()方法接管前面已经打开的浏览器,获取到context 上下文,通过上下文再获取到page对象。我们以在企业微信的通讯录添加成员为例。
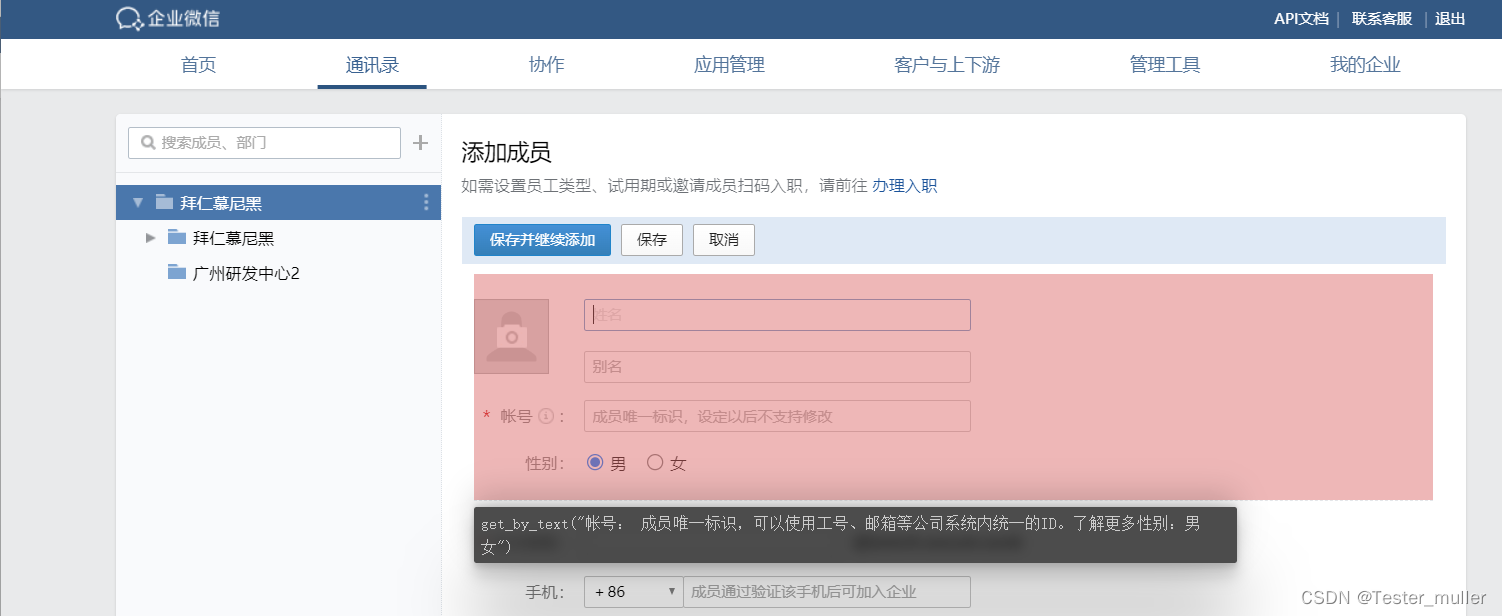
代码如下:
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://work.weixin.qq.com/wework_admin/loginpage_wx?redirect_uri=https%3A%2F%2Fwork.weixin.qq.com%2Fwework_admin%2Fframe")
page.goto("https://work.weixin.qq.com/wework_admin/frame")
page.get_by_role("link", name="通讯录", exact=True).click()
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)当我们成功访问网站后,只需要按照页面步骤添加成员即可完成操作。
总结
本文主要介绍了playwright对已打开的浏览器的操作,playwright与selenium一样,都支持对浏览器的复用,帮助我们避开登录操作。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录