[腾讯云 Cloud studio 实战训练营] 制作Scrapy Demo爬取起点网月票榜小说数据
原创[腾讯云 Cloud studio 实战训练营] 制作Scrapy Demo爬取起点网月票榜小说数据
原创
首语
最近接触到了一个关于云开发的IDE,什么意思呢?
就是我们通常开发不是在电脑上吗,既要下载编译器,还要下载合适的编辑器,有的时候甚至还需要配置开发环境,有些繁琐。而这个云开发的IDE就是只需要一台能够上网的电脑就可以进行开发,完全不需要配置环境,下载编译器和编辑器。
Cloud Studio是什么
没错,这就是那一款云开发IDE。可以在浏览器上进行代码的编写,也可以将编写好的代码上传到你的Github或者Gitee。
Cloud Studio的优势
因为之前使用过JetBrains全家桶,所以就简单说一下对比,相较于传统的IDE来说,Clould Studio不需要下载安装即可在网页上使用。
相对来说更为方便,更为难得的是,Clould Studio在更为方便快捷的前提上,对比传统IDE的功能来讲,也都是具备的。
1. 代码纠错等基础功能
我们都知道,现在的IDE对于错误的代码不需要编译就可以标红提醒,因此Clould Studio也具备这样的功能,当然,代码补全这个很实用的功能也是具备的(对于我这种记忆力不好的人来说,这个功能还是很重要的)
2. 环境搭建
对于项目的环境搭建来说,由于Clould Studio收集了众多项目模板,因此对于需要的环境可以一键搭建,主打的就是一个方便快捷
也并不需要你创办虚拟环境,重新安装类库等,直接创建开发空间,就是一个独立的项目,不需要担心不同项目之间突然,冒出来一个问题。
也不需要为学校教了多门语言而苦恼多门语言的编译器安装与环境配置问题。
当时我学习java的时候确实为了环境配置而苦恼,只能说相见恨晚呐!
3. 链接云服务器
创建的项目运行后是在类似于云服务器上跑的,web项目也可以通过外网访问,工作空间内有分配的端口号和IP,也是非常的方便。
Clould Studio是使用ssh的方式来远程连接到,我们只需要在工作空间启动项目,然后就会出现这个按钮

点击后就会出现ssh的链接,使用对应的工具就可以远程链接了。
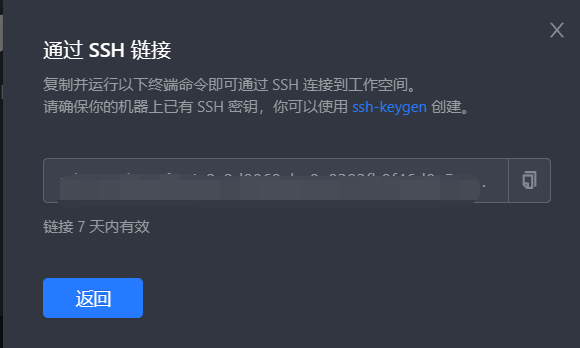
接下来我们就讲讲如何使用Clould Studio来制作我们的Scrapy Demo。
使用Clould Studio账号创建项目Demo
1. 注册创建Clould Studio账号
打开Clould Studio官方网站进行账号的注册登录:Clould Studio官网
在官网中我们可以看到对于Clould Studio的简单介绍:
而我们要使用的话就可以直接点击官网右上角的注册/登录按钮。
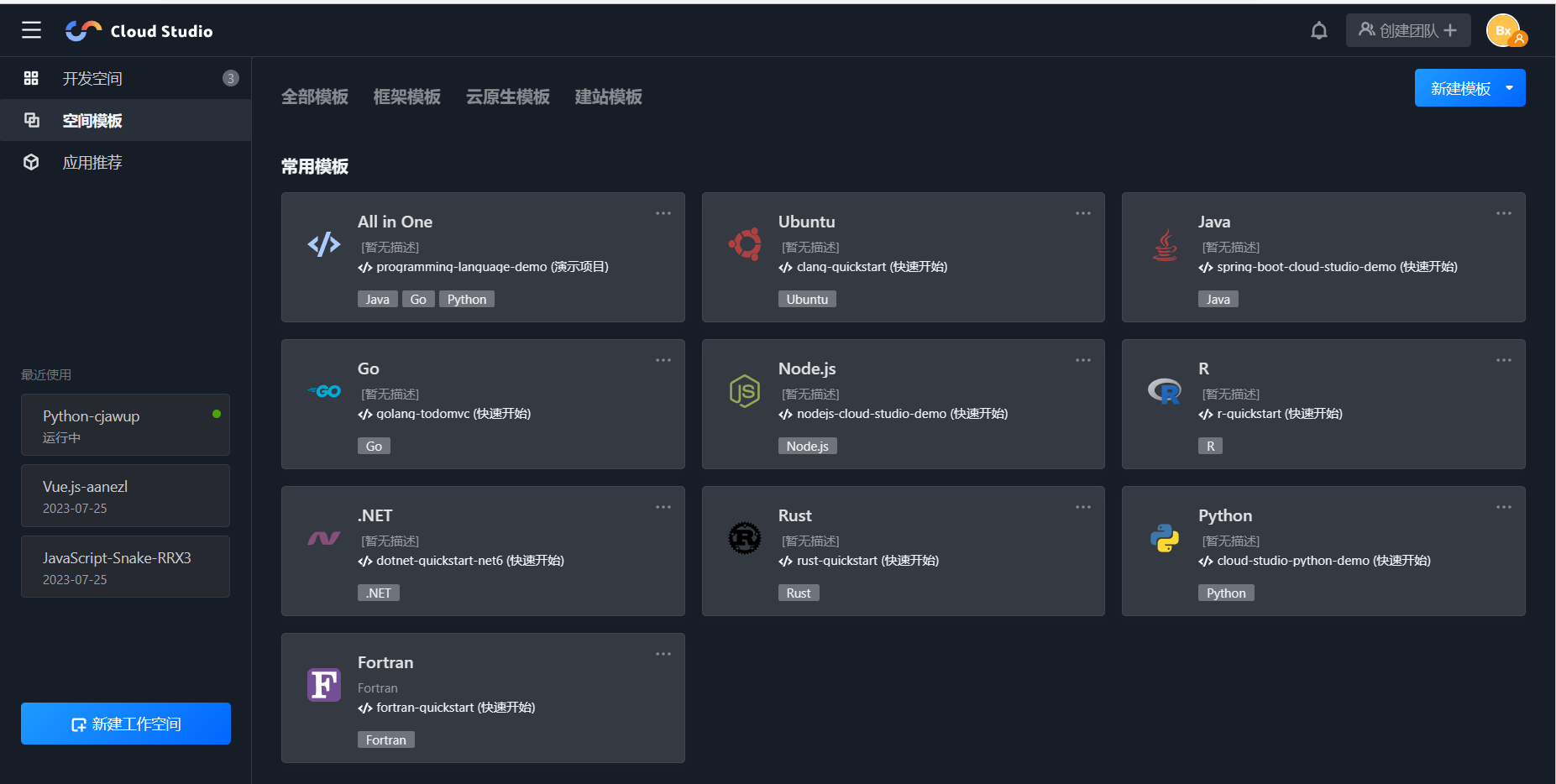
登录完成后回来到我们的工作空间(有个人和团体的)
2. 了解基本功能和内容
进入工作空间后,我们可以在左边看到一些木块,拢共分为三大类
- 开发空间——我们可以在开发空间看到我们创建的项目
- 空间模板——在空间模板里面有许多模板可以使用,不关你是python,java,C,vue语言,都有模板可供使用
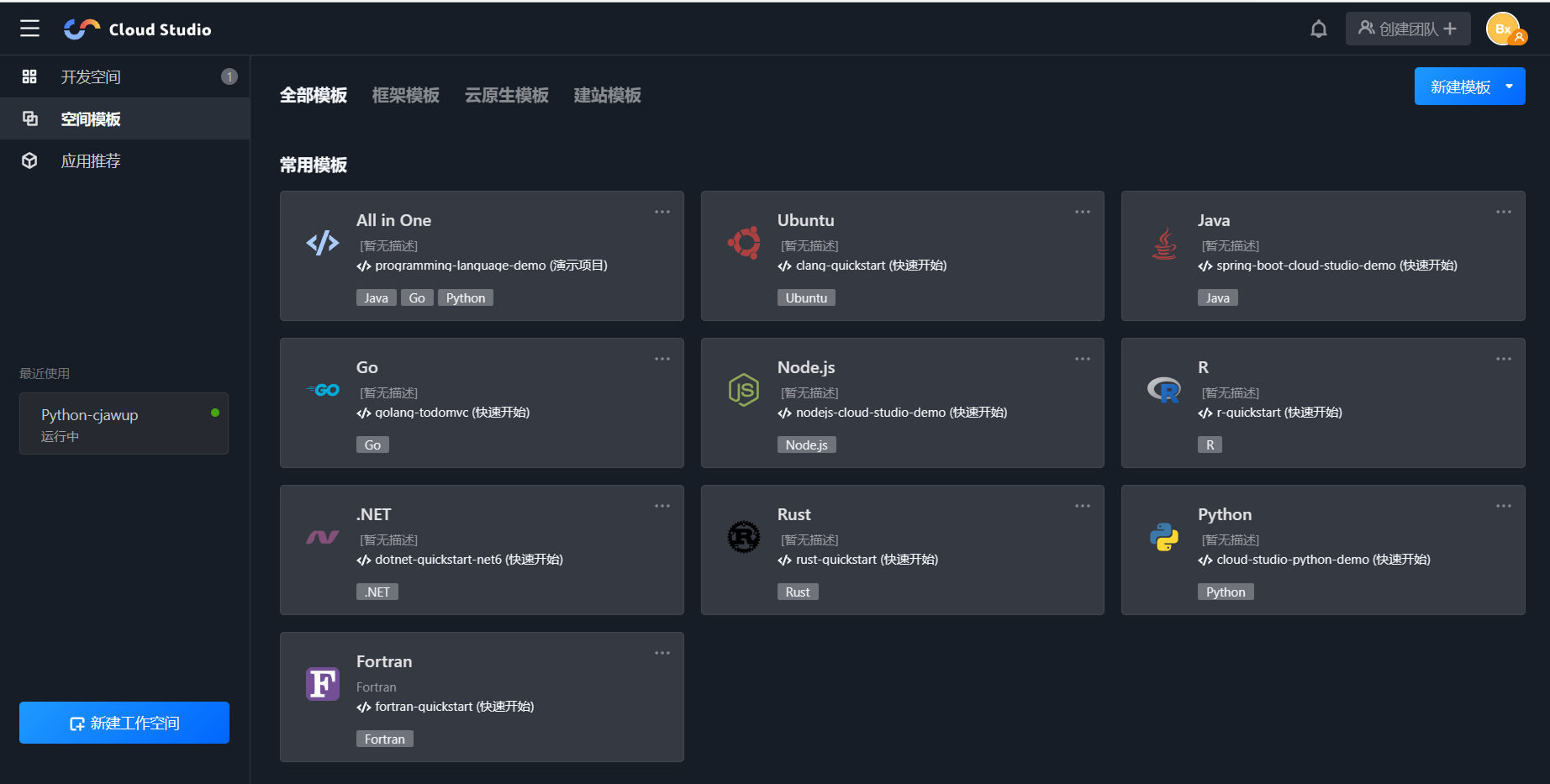
- 应用推荐——这里面是各位大佬制作好的项目,如果对某个项目感兴趣,想观摩源代码,我们只需要点击之后,点击Fork按钮,就可以将大佬们的项目copy到我们自己的工作空间。
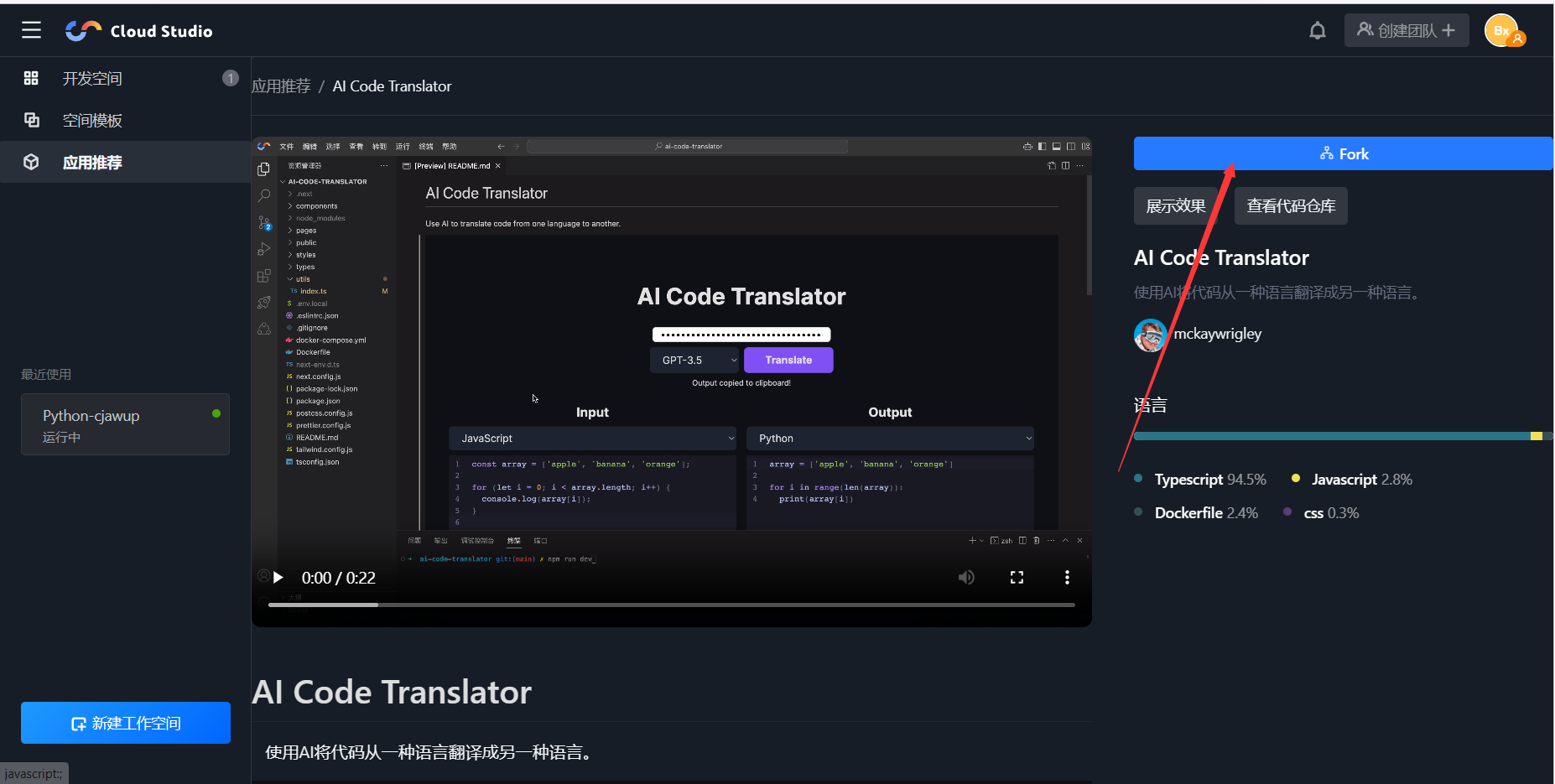
3. 创建Python模板
我们在空间模板中找到Python模板,然后点击一下就可以快速创建了,当然这需要一定的时间,不过时间也不长
我们的工作空间窗户建好之后,我们会发现自动运行了一个Demo
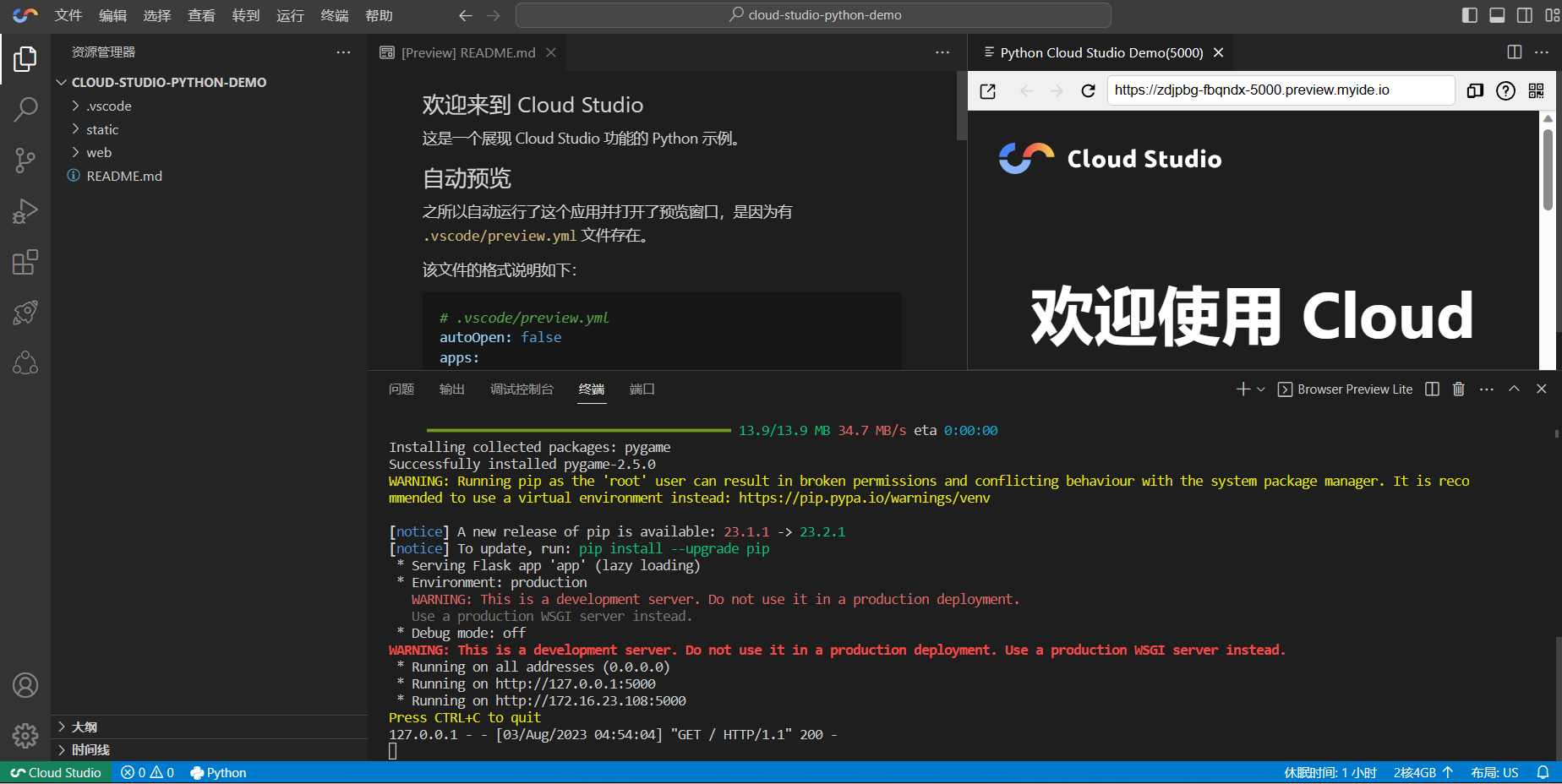
而在README文件中我们也可以看到关于这个Demo的相关介绍
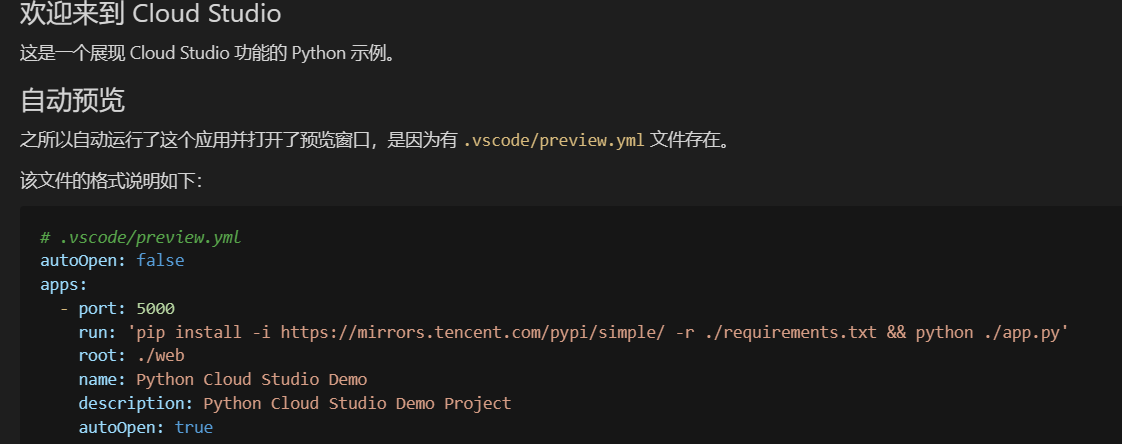
当然我们不想运行的话也是可以直接删掉的。
4. 使用pip下载Scrapy库
虽然我使用pip list命令发现已经初始化了很多类库,比如flask,pygame等比较常用的,但是Scrapy是没有的,同样的,我也并没有发现Django库,我们使用的话,最好先查看一下有没有我们需要的类库。
先将我们不需要的文件删除掉,然后打开终端
之后再使用我们的pip工具下载我们需要的类库pip install Scrapy
下载完成后以防万一,我们再使用pip list命令检查一下是否安装成功

安装成功后我们就可以开始创建项目了
5. 创建Scrapy项目
创建Scrapy项目需要在终端输出命令创建,可别下载完就把终端×了啊
Scrapy startproject 项目名
出现下图内容就是创建成果了,同样的,我们还可以直接观察我们工作空间的目录,创建完成后会出现一个与项目名称同名的目录,那就是创建成果了
6. 创建爬虫文件
还是我们的终端,打开后切换到我们的项目目录下面,开始创建爬虫文件
cd 项目名称 // 切换到项目根目录
scrapy genspider qidian_spider www.xxx.com // 创建名字为qidian_spider,域名为www.xxx.com的爬虫文件
显示这样就是我们的爬虫创建成果啦,当然爬虫开始工作还需要我们编写代码,现在还需要编写代码
先打开看看怎么个事
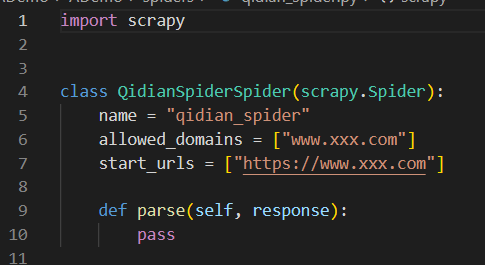
import scrapy # 使用的类库
class QidianSpiderSpider(scrapy.Spider):
name = "qidian_spider" # 爬虫名
allowed_domains = ["www.xxx.com"] # 通域名
start_urls = ["https://www.xxx.com"] #具体爬取的url
def parse(self, response):
#爬虫代码编写在这里
pass7. 确认爬取目标
爬取起点中文网月票榜上小说,获取小说名,作者名,连载状态,小说简介
我们要爬取某个网站,首先一点就是先获取到网站的URL,所以网站的URL就是:https://www.qidian.com/rank/yuepiao/
所以我们的代码中就可以修改url了
将start_urls = ["https://www.xxx.com"]
修改为start_urls = ["https://www.qidian.com/rank/yuepiao/"]
8. 修改项目配置
在没学Scrapy之前,我们都需要在确认网站url后填写headers头部信息,比如user_agent和cookies,那么在Scrapy中我们也需要填写这种头部信息
找到项目内的setting.py文件打开
将里面的内容修改加添加一些
将20行的ROBOTSTXT_OBEY = True改为ROBOTSTXT_OBEY = False
这个的意思是是否遵循机器人协议,默认是true,需要改为false
不然我们的爬虫有很多都无法爬取
添加代码:USER_AGENT:"你自己浏览器的请求头"
9. 编写爬取代码
import scrapy
class MonthlytickrtSpider(scrapy.Spider):
name = "qidian_spider"
allowed_domains = ["www.qidian.com"]
start_urls = ["https://www.qidian.com/rank/yuepiao/"]
def parse(self, response):
print("===============项目开始运行===============")
yuepiao_list = response.xpath('//div[@class="book-mid-info"]') # 月票榜小说数据列表
data_list = [] # 创建空列表容纳每一本小说的数据
"""
data_dic = {
也可以创建一个字典来存储
}
"""
for i in yuepiao_list:
book_name = i.xpath('h2/a/text()').extract()[0] # 小说名
book_author = i.xpath('p[1]/a[1]/text()').extract()[0] # 作者名
book_intro = i.xpath('p[@class="intro"]/text()').extract()[0] # 小说简介
book_type = i.xpath('p[1]/a[2]/text()').extract()[0] # 小说更新状态
book_src = i.xpath('h2/a/@href').extract()[0] # 小说链接
book_data = {
"小说名": book_name,
"作者": book_author,
"简介": book_intro,
"更新状态": book_type,
"链接": book_src,
# 将取到每个小说的数据存入字典中
}
data_list.append(book_data) # 将字典存入列表
# data_list[name] = book_data 将字典存入字典,以小说名为键
print(data_list) # 终端查看小说数据
return data_list好好好,代码已经写完了,那么我们来看看运行效果吧

可以看到我们的爬虫也是成功的爬取到了我们想要的数据,那么我们的数据如何保存下来呢?
有两种办法,一种是使用我们在Python基础学过的os模块,一种是Scrapy自带的数据保存方法
10. 数据保存
1. 使用Scrapy的方法保存
Scrapy给我们了四种保存数据的方式,分别是json, json line, xml, csv
不需要编写代码,只需要在运行项目的时候添加命令参数即可
scrapy crawl 项目名称 -o 文件名称.你想要的格式比如我们现在使用json的格式储存,我们只需要
scrapy crawl qidian_spider -o data.json这样我们就可以看到在根目录生成了一个json格式的data文件,我们点进去看看
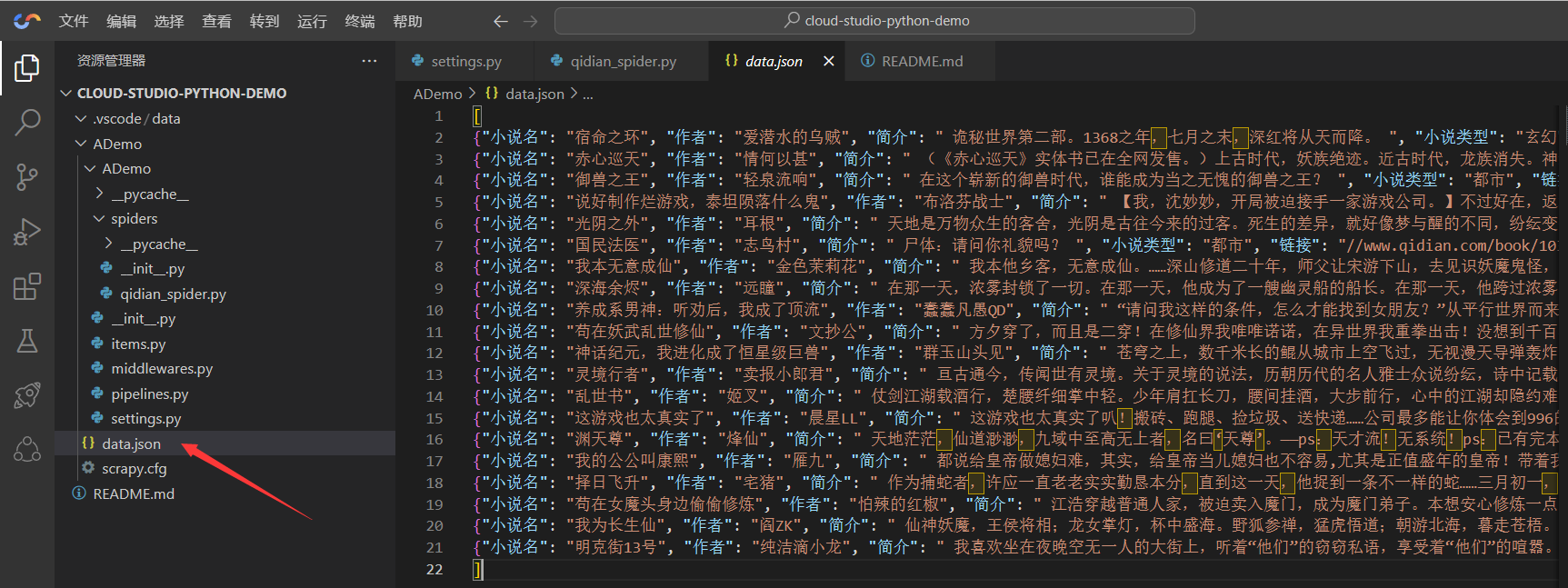
好了,这就成功了
2. 使用os模块保存数据
我们可以使用python自带的os模块来对文件进行操作
在爬虫里面添加的代码如下
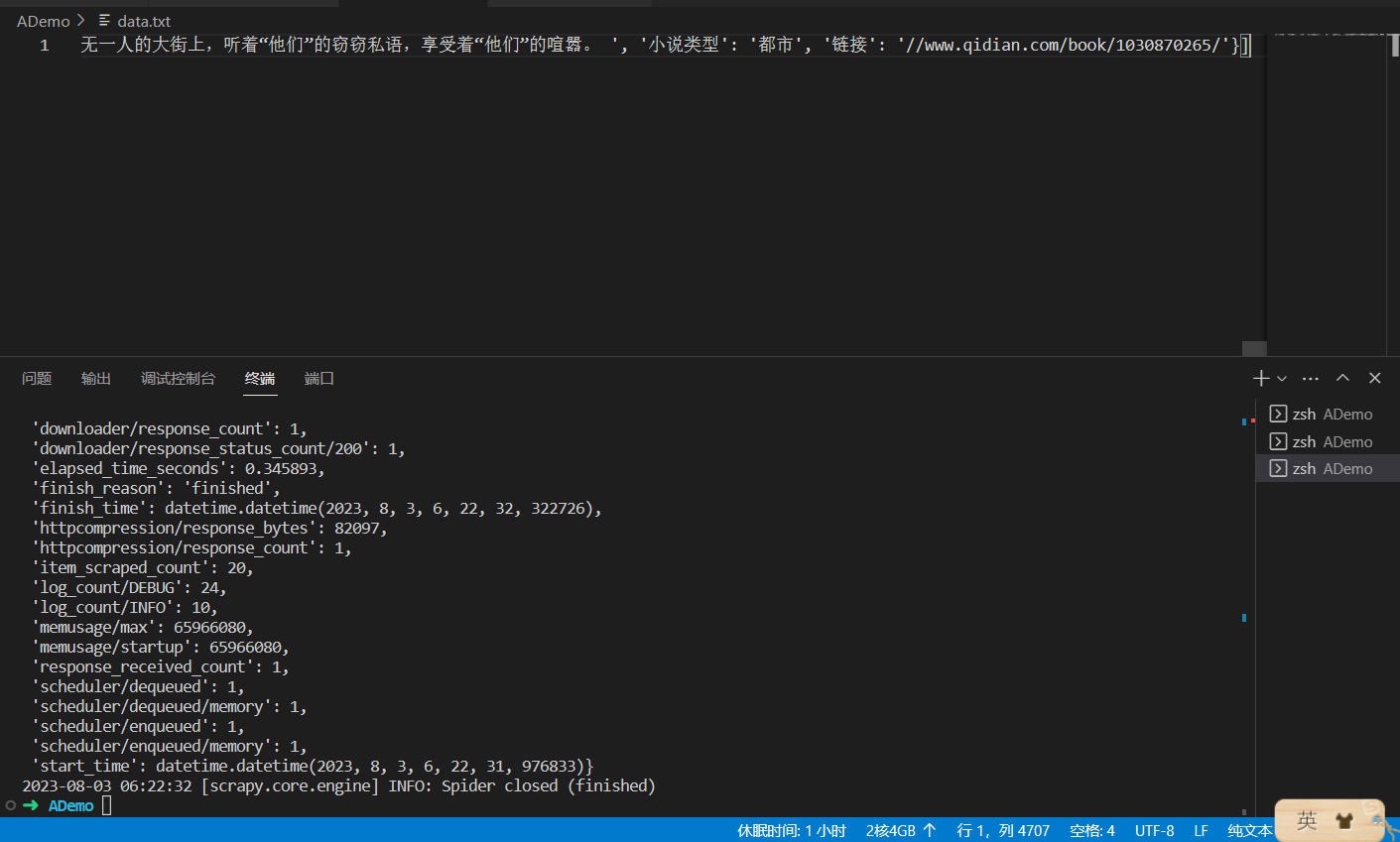
with open('data.txt','w') as f:
f.write(str(data_list))注意添加到函数下面,return上面
效果如图:
使用Git管理代码
1. 填写好项目的README文件
## 欢迎来到 Cloud Studio ##
这是布小禅使用Clould Studio尝试编写的一个小小的爬虫Python项目。
## 项目介绍
爬取起点小说网月票榜榜单内小说,书荒的书虫有福音了哈
使用Scrapy爬虫框架,当然也仅仅只是用了一点,属于是使用大炮打蚊子了
## 运行项目
常见的Scrapy运行,使用命令`srapy crawl 项目内模块名`。
需要注意的是,你需要在运行项目之前切换到项目内,而不是Clould Studio的默认目录,那样你会运行失败的2. 使用git将代码上传到Gitee
我们先打开终端,输入git init初始化代码仓库
然后
git add .
git commit -m "爬取起点月票榜数据"
git clone git remote add origin # 仓库链接
git push -u origin master # 上传gitee3. 项目完成销毁工作空间
先将工作空间关闭
退出之后回到工作空间,可以点击三个点删除

结语
相较于传统的IDE来说,Clould Studio更为的快捷和方便,不需要复杂的环境配置,不需要下载任何东西,只需要有一台能够连接互联网的电脑就可以进行开发工作了。
更为难能可贵的是,Clould Studio不仅仅没有因为快捷方便而舍弃了一部分功能,还在拥有大多数IDE功能的前提下增加了很多功能。比如新增的AI代码助手,模板一键搭建等都是很方便的。
以往除了vscode之外,我们想要一个全能的编辑器是很难,而Clould Studio就可以全能,什么语言它都兼容,而且写多个语言也不需要下载多个语言的编译器,就可以直接上手,为新手开发者和学生提供了很大的便利。
目前还没看到有缺点,是一款很优秀的软件,很适合入手。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。