IJCAI2023 | 当符号学习遇到推荐系统: 基于概率逻辑推理的序列推荐方法
IJCAI2023 | 当符号学习遇到推荐系统: 基于概率逻辑推理的序列推荐方法

TLDR: 本文探索了深度学习和符号学习方法的结合,用以增强序列推荐模型的逻辑推理能力。通过解耦特征嵌入和逻辑嵌入,使序列推荐同时受益于相似性匹配(感知能力)和逻辑推理(认知能力)。

论文:arxiv.org/abs/2304.11383 代码:github.com/Huanhuaneryuan/SR-PLR
研究动机
序列推荐算法已被成功应用于多种实际场景,比如电商、广告、短视频等。尽管当前的深度序列推荐算法取得了不错的推荐效果,其大部分算法都是基于相似性匹配的感知模型。最近的神经符号学习方法取得了巨大的进步,因此将神经符号学习的认知推理能力赋能传统的推荐模型,能够让序列推荐算法同时拥有感知和认知的双重能力,进而提升用户的使用体验。
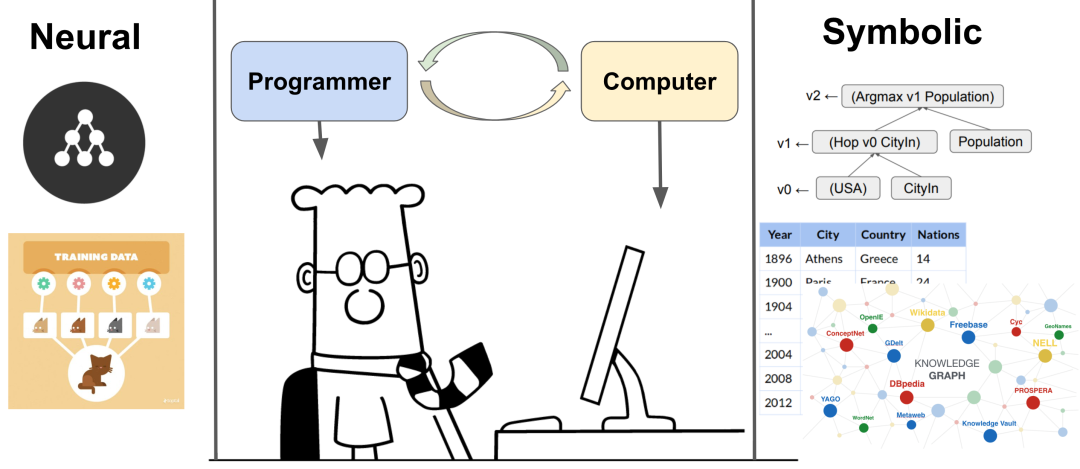
深度学习和符号学习是人工智能领域中经常使用的两种不同方法。前者是基于数据驱动的学习范式。但如果其没有明确的常识性知识和认知推理,这些对数据要求很高的策略通常很难被概括。相反,后者通过使用逻辑运算符(比如与、或、非等)可以高效的来执行语言理解或逻辑推理任务。基于深度学习的序列推荐算法(如SASRec 等)通过计算历史交互表示和目标物品表示之间的相似性来学习物品的表示并生成推荐。然而,与仅仅计算相似度分数不同,基于符号学习的模型更注重基于用户的认知推理过程进行预测。例如,用户在购买笔记本电脑后,可能更喜欢购买键盘,而不是类似的笔记本电脑。
因此,将深度学习擅长的相似性匹配能力和符号学习擅长的认知推理能力相结合,能够合理高效的利用两者的优势。例如,符号学习可以为从深度学习学到的潜在特征提供一个更灵活的逻辑结构。此外,深度学习的引入使符号学习和推理过程的端到端训练成为可能。然而,将神经符号学习集成到序列推荐算法存在两个挑战。首先,近期的逻辑推理模型是基于嵌入特征的。特征描述和逻辑表示被耦合在同一个嵌入中,这使得模型很难区分哪个潜在特征对特征表示或逻辑推理有贡献。其次,他们大多假设用户的偏好是静态的,并以确定的方式嵌入用户和物品。这种方式忽略了用户的品味充满不确定性,并在不断变化,这就造成了不恰当的推荐。
所提方法
本文旨在利用逻辑推理能力来增强基于深度学习的序列推荐模型,并提出了一个名为概率逻辑推理的序列推荐的通用框架。具体结构可参考下图。在本框架中,特征表示(Feature representation)和逻辑表示(logic representation)在不同的网络中是解耦的,这使得该模型可以从相似性匹配和逻辑推理中双重获益。
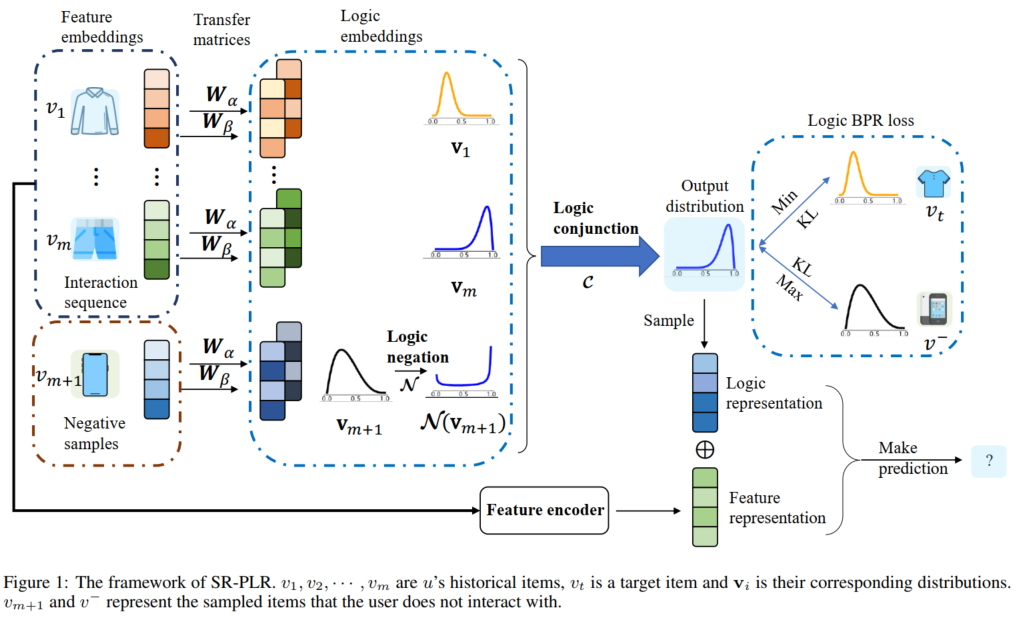
具体来说,对于特征部分,以基于深度学习的序列推荐方法(如SASRec、GRU4Rec等)为骨干模型,学习序列的强大潜在表征。该部分包含嵌入层和特征编码模块。对于嵌入层,将物品的ID信息嵌入到物品嵌入矩阵
中,其中
为嵌入维度,
为物品集合。给定用户
的历史交互序列
,其初始嵌入
为
,其中
表示序列中第
个物品的嵌入。特征编码模块将用户的历史序列编码为用户特征表示
。
对于逻辑部分,分为三个步骤,即概率逻辑嵌入、概率逻辑算子以及概率推理。对于概率逻辑嵌入部分,本文提到了两个转移矩阵(
和
),将原始特征嵌入转换为几个独立的Beta分布来表示历史物品。

其中Beta分布是定义在[0,1]上的连续概率分布,其概率密度函数为
。对于
的每个维度用独立的
分布而不是单个值来表征不确定性。注意,假设物品表示遵循Beta分布而不是高斯分布,因为目标是保证这些Beta嵌入上的概率逻辑算子是封闭的。
对于概率逻辑算子部分,对这些分布进行两个封闭的概率逻辑运算(即AND,NOT),用KL散度来推断出目标物品的分布。
其中,概率否(NOT)算子
为逻辑表示
的倒数:
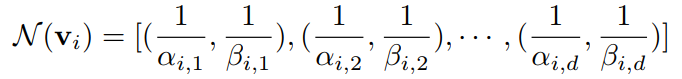
可以看出,
自然满足否的性质,即
.此外,如上图所示,算子
可以将高概率密度反向到低密度,使得
可以表示用户不喜欢的物品
。
对于概率合(AND)算子,给定用户历史交互序列
和其对应的逻辑嵌入
,具体的概率合算子
定义为:

其中,
和
为按位求和/乘积,
通过注意力机制来学习不同物品的重要性。显然,所定义的概率合算子满足
的性质。
对于逻辑推理部分,利用成对损失来优化该逻辑网络的参数:

其中,
为负样本
的嵌入。
最后,从传统的序列方法中获得的特征表示
与从输出Beta分布中采样的逻辑表示
相连接,以进行预测。
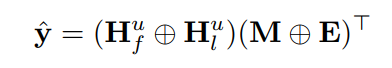
其中,
。推荐任务的损失函数为交叉熵损失:
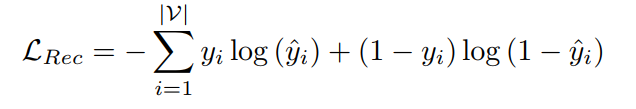
因此,总的损失函数为推荐任务的交叉熵损失和逻辑优化的KL损失,即:
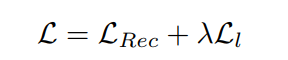
实验效果
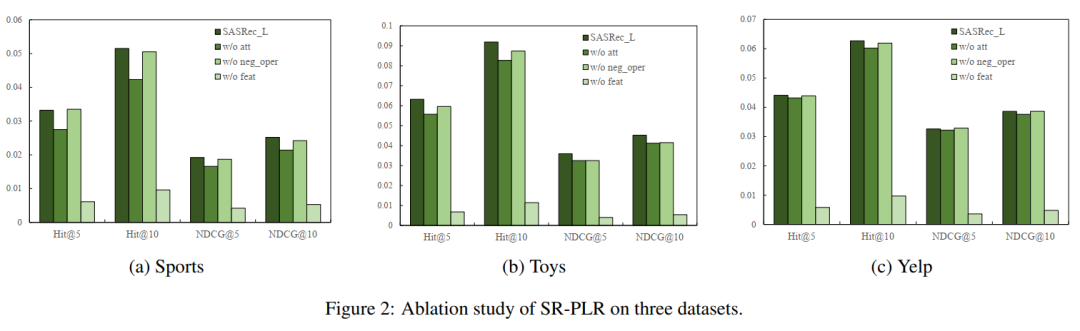
本文在三个数据集上对多个基线方法和基于逻辑的推荐算法进行了对比,实验结果展示了本方法的优越性。

随后,在多个数据集上测试了本方法所提出的不同子模块,验证了所提出方法的有效性。