【爬虫】(三)lo4d.com

?
?
前言
因为毕设是基于机器学习的,所以需要大量的样本来训练模型和检验成果,因此,通过爬虫,在合法合规的情况下,爬取自己所需要的资源,在此进行记录;
本次爬取的网站是 https://www.lo4d.com/
总的代码都会在 运行 中贴出...
再次申明:本博文仅供学习使用,请勿他用!!! ?
成果
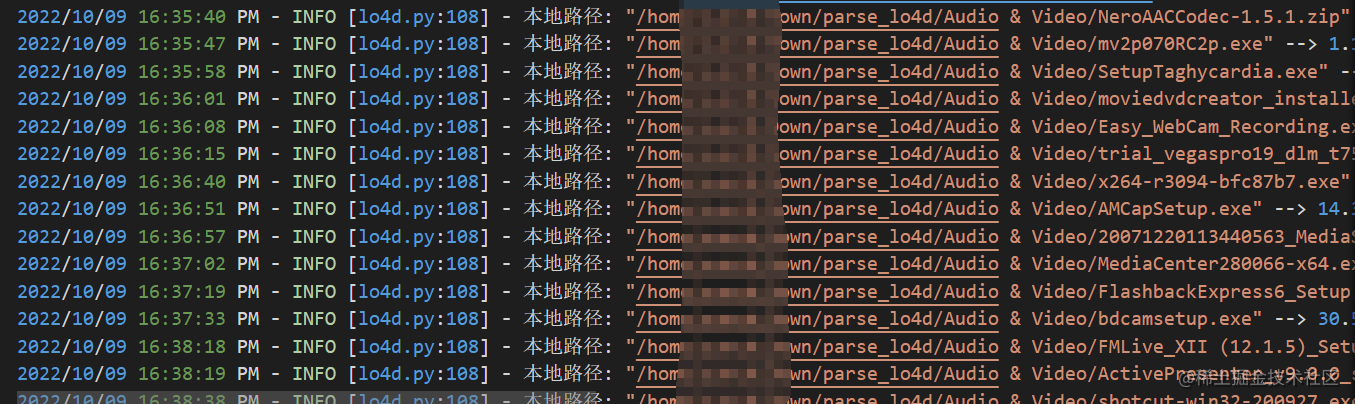
观察
页面还是比较简洁的,可以直接按目录分类来进行之后的操作;
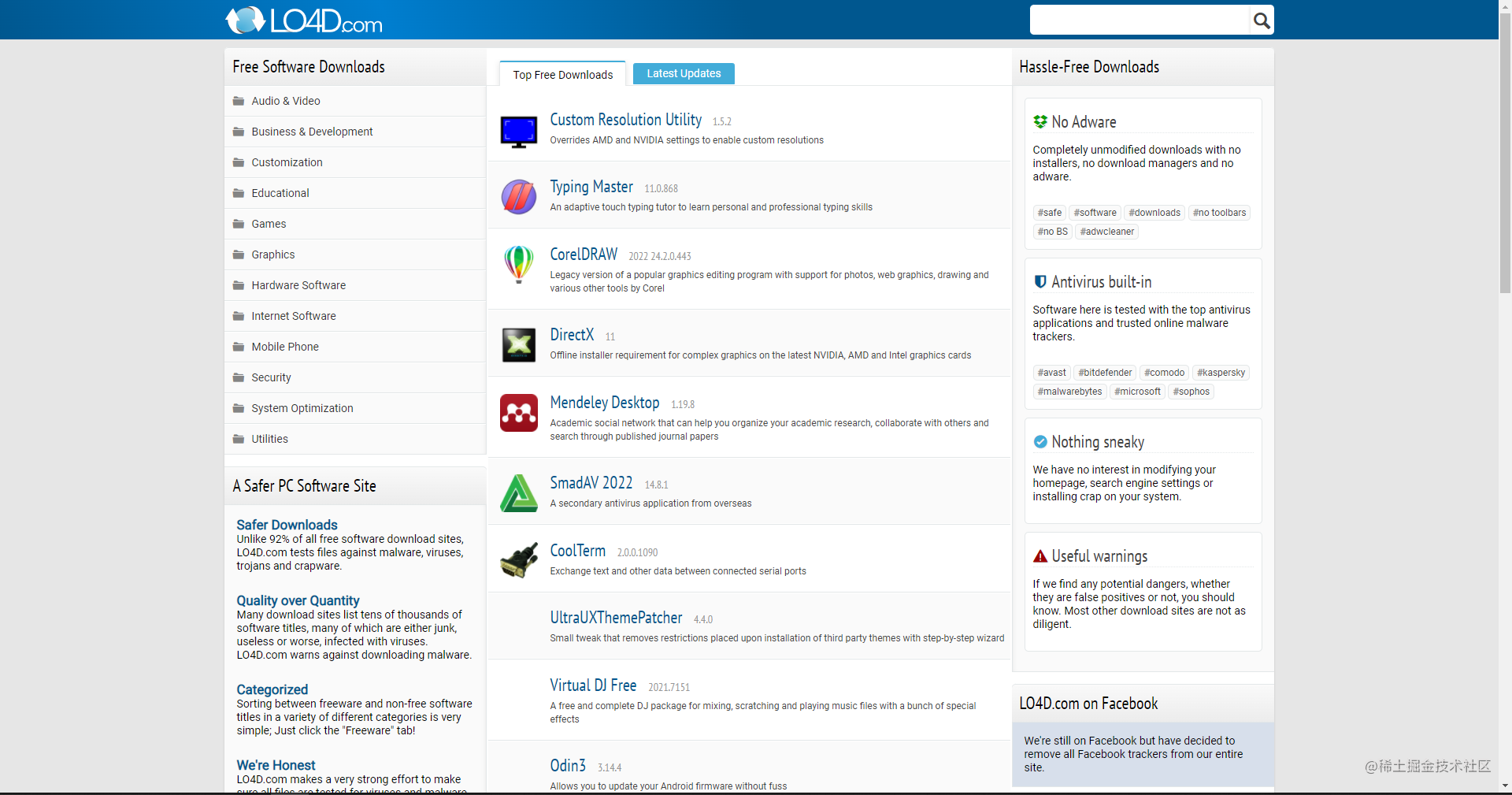
接下来就以 Audio & Video 目录为例进行操作;
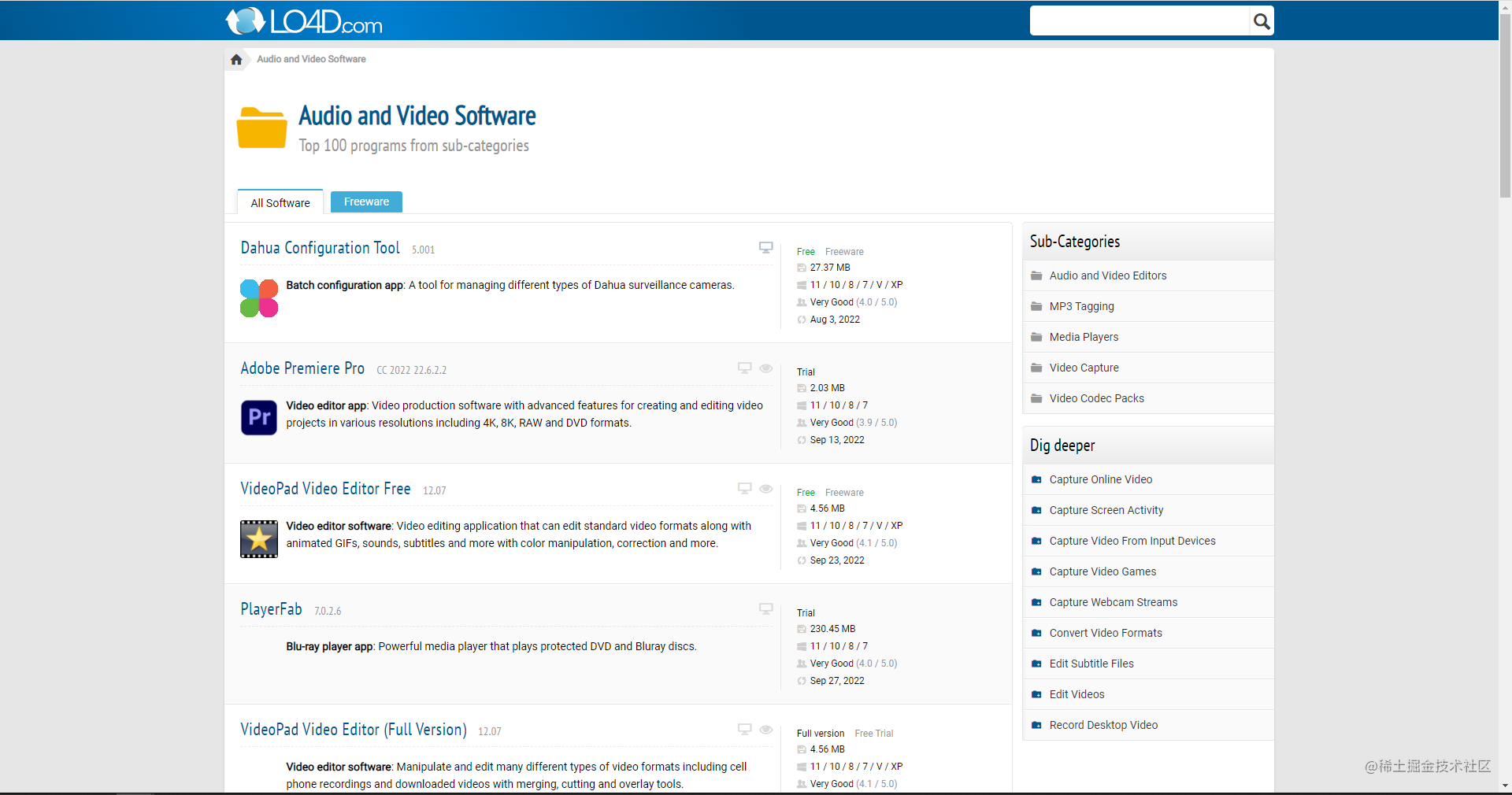
进入单个软件的详情页;
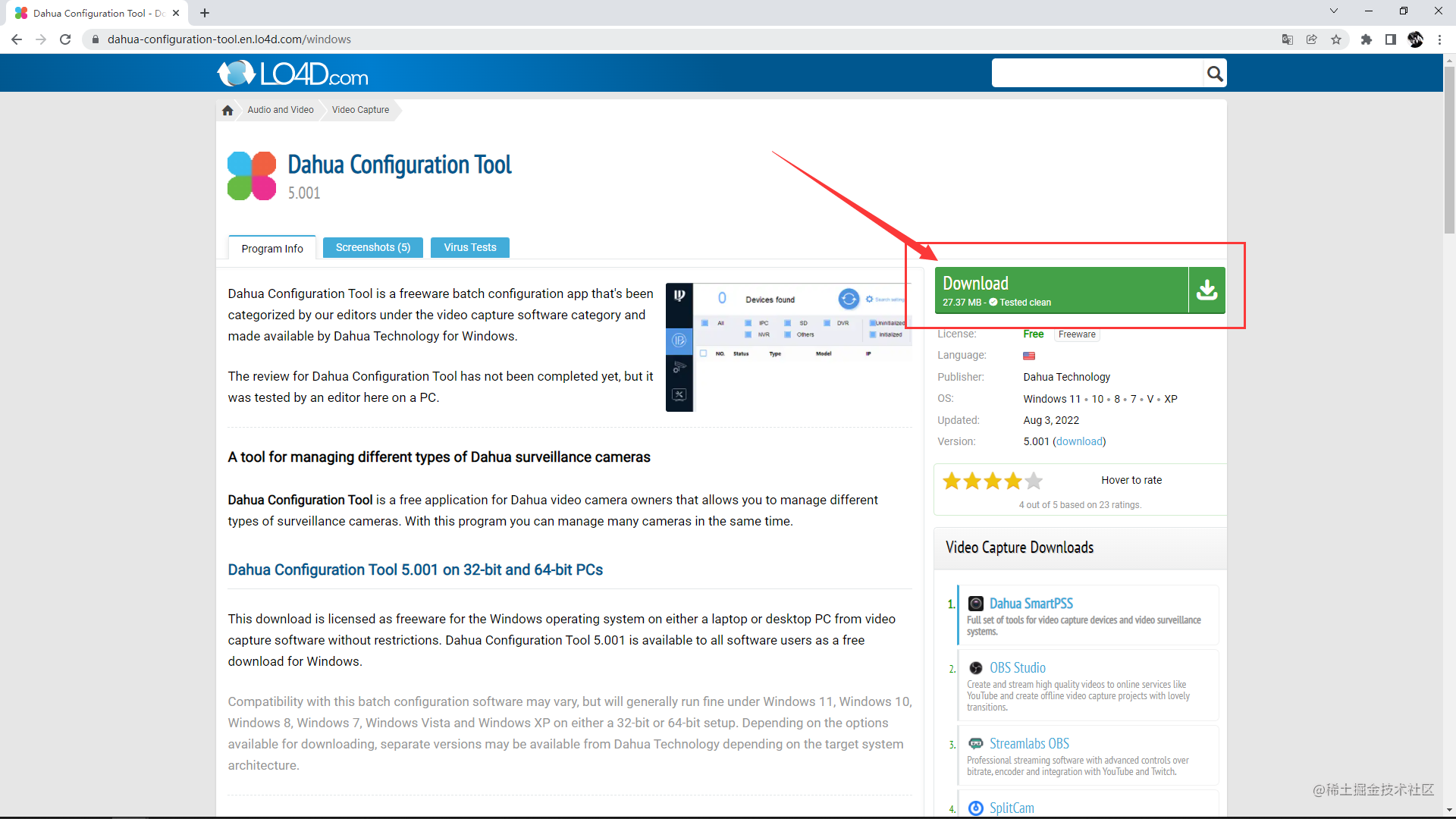
同时观察下载区域,以及相关的 URL;
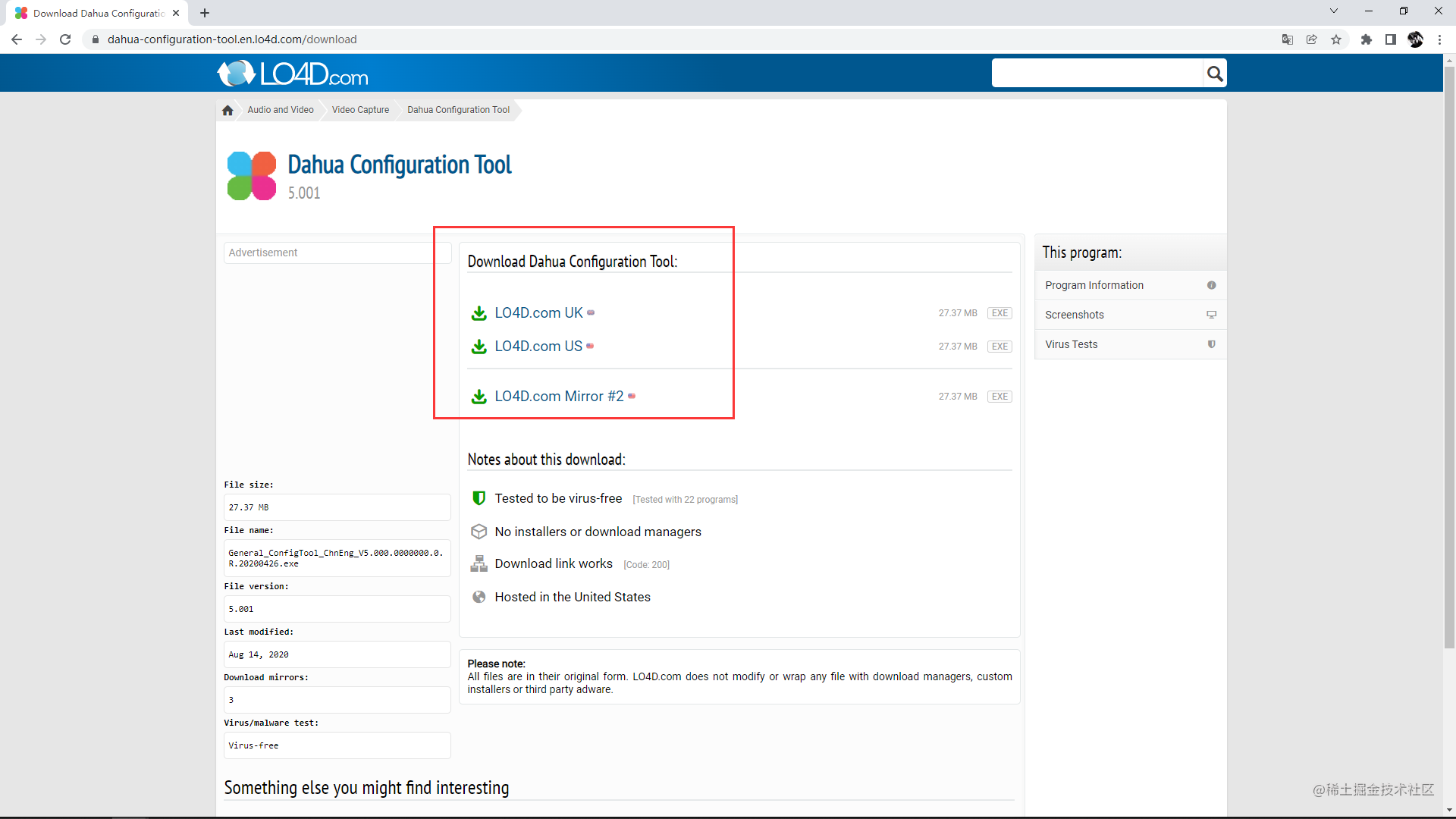
发现这个网站对于软件的详细信息展示的很到位,良心!
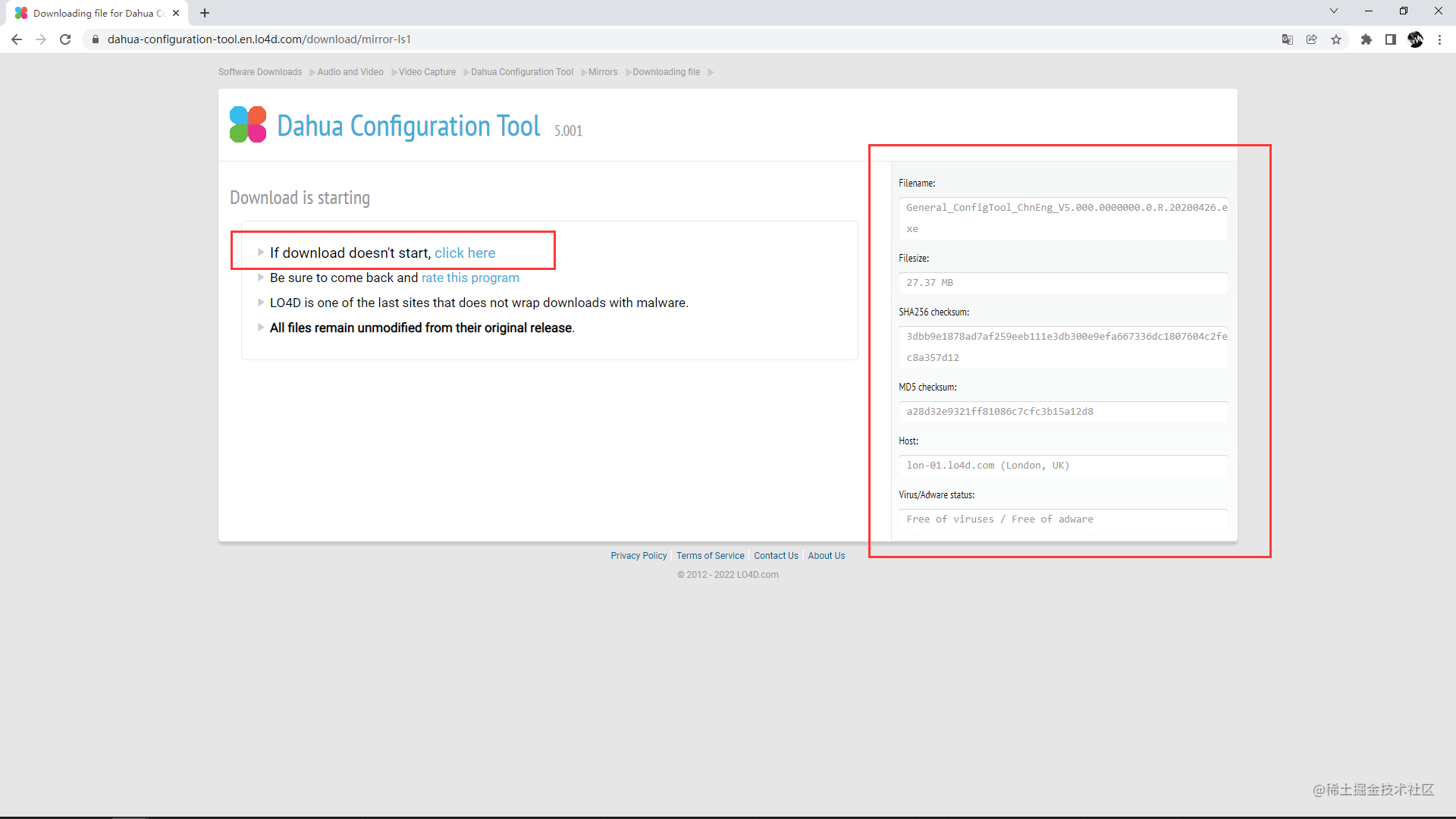
分析
大致浏览之后,接下来就是进行分析以及分步操作了;
1、先请求一下网页,看看是否能请求成功;
import requests
url = "https://en.lo4d.com/windows/audio-video-software"
print(requests.get(url, headers=headers, proxies=proxies).status_code)
# 2002、接下来随机点开一个文件的镜像网站看看能不能成功下载;
import requests
from lxml import etree
url = "https://videopad-free.en.lo4d.com/download/mirror-ex1"
resp = requests.get(url, headers=headers, proxies=proxies)
print(resp.status_code)
html = etree.HTML(resp.text)
href = html.xpath("/html/body/div[3]/div[2]/div/div[1]/div/ul/li[1]/a/@href")[0]
with open('test.exe', "wb") as f:
f.write(requests.get(href, headers=headers, proxies=proxies).content)
# 下载成功既然是具备可行性的,那么接下来就可以开始进入正式的分析过程了;
3、页数的话,随意看了几个目录,好像都不是很多,就到时候手动输入即可;
4、获取某页中的所有软件下载地址;
def get_detail_url(url):
html = etree.HTML(requests.get(url, headers=headers, proxies=proxies).text)
lis = html.xpath("/html/body/div[2]/div/main/ul/li")
urls = []
for li in lis:
urls.append(li.xpath("./article/h3/a/@href")[0].replace("/windows", "/download"))
return urls
5、锁定镜像区域,选择镜像地址,获取需要的信息;
def get_info(url):
html = etree.HTML(requests.get(url, headers=headers, proxies=proxies).text)
new_url = html.xpath("/html/body/div[2]/div/div[1]/main/div/section[1]/ul[1]/li[1]/a/@href")[0]
new_html = etree.HTML(requests.get(new_url, headers=headers, proxies=proxies).text)
down_url = new_html.xpath("/html/body/div[3]/div[2]/div/div[1]/div/ul/li[1]/a/@href")[0]
name = new_html.xpath("/html/body/div[3]/div[3]/dl/dd[1]/text()")[0]
info = {"name":name, "url":down_url}
return info
# {'name': 'vpsetup.exe', 'url': 'https://www.lo4d.com/get-file/videopad-free/507d856d49f52f00265b1037d4df1629/'}6、最后一步,实现下载;
def download(url):
info = get_info(url)
with open(info['name'], "wb") as f:
f.write(requests.get(info['url'], headers=headers, proxies=proxies).content)7、自己加上多线程,异常捕获等;
运行
这板块现在有版权风险,不能贴全部的代码,点这里; ?
后记
仅仅用来记录毕设期间所爬过的网站;
再次申明:本博文仅供学习使用,请勿他用!!!
? 上篇精讲:【爬虫】(二)windows10download.com
? 我是???????,期待你的关注;
? 创作不易,请多多支持;
? 系列专栏:?爬虫专栏
本文参与?腾讯云自媒体分享计划,分享自作者个人站点/博客。
原始发表:2022-10-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录