【论文解读】Salesforce开源多模态BLIP-2,在图文交互场景下获得了SOTA的结果
【论文解读】Salesforce开源多模态BLIP-2,在图文交互场景下获得了SOTA的结果

一、论文信息
- 论文名称:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- 作者团队:Salesforce Research
- 论文地址:
https://arxiv.org/pdf/2301.12597.pdf - 项目链接:
https://github.com/salesforce/LAVIS/tree/main/projects/blip2
二、论文简介
1. 问题:
大模型时代,预训练这个过程变得越来越有挑战,GPU资源和费用都是不小的数目。
2. 解决措施:
作者团队提出了BLIP-2,它是一种通用且高效预训练的策略,能够基于现有的预训练image encoders和预训练大语言模型(两者的模型参数都冻结)进行图像和语言预训练(vision-languange pretraining)。BLIP-2能够基于一个两阶段预训练的轻量级Querying Transformer (简称: Q-Former) 缩小模态距离(图像与文本)。【Q-Former是一个轻量级的 transformer,使用一组可学习的检索向量(query vectors)从冻结的 image encoder 中来抽取图像特征。】
png-01
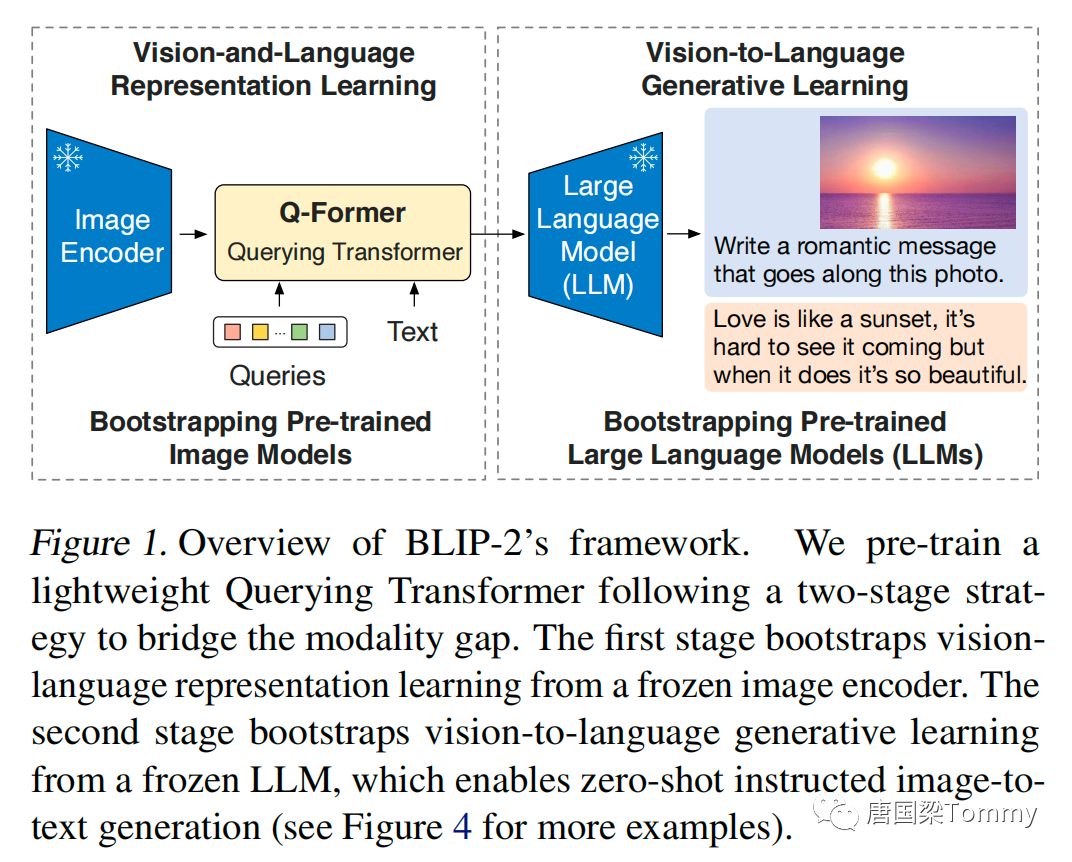
2.1 第一预训练阶段:从冻结的image encoder引导图像-语言表示学习(vision-language representation learning)
图像-语言表示学习的作用是迫使Q-Former学习与文本相关的图像表示(visual representation)
2.2 第二预训练阶段:从冻结的语言模型引导图像到语言的生成式学习(vision-to-language generative learning)
通过连接Q-Former的输出与冻结的LLM进行图像到语言生成式学习,训练Q-Former以至于它输出的图像表示能够被LLM理解。
3. 成果:
BLIP-2相比较于现有的多模态方法,它以更少的训练参数量在多个不同的视觉-语言任务上都获得了最好的结果。
三、创新点
1. BLIP-2有效利用冻结的预训练图像模型和语言模型,在两阶段预训练(表示学习阶段和生成学习阶段)过程中,使用Q-Former缩小模态间的距离。
2. 通过大语言模型(LLM)助力,BLIP-2通过提示能够基于自然语言指令的方式进行zero-shot图文生成。
3. 由于使用了单模态的模型和轻量级的Q-Former,BLIP-2比现有的方法在计算方面更高效。
四、核心算法
1. 模型架构
png-02
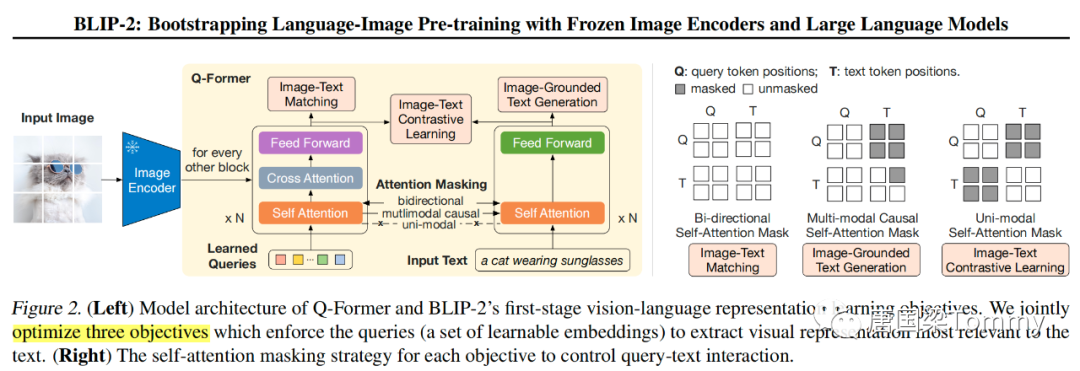
1.1 根据上图所示,Q-Former包含两个transformer子模块,它们共享同样的self-attention层。
(1)一个 image transformer 与冻结的 image encoder 进行交互,用于图像特征提取;
(2)一个 text transformer 被当作 text encoder 和 text decoder;
1.2 具体过程如下:
① 创建一组可学习的检索向量(query embeddings),然后输入到 image transformer中;
② queries与自注意力层相互作用,并且通过cross-attention层与冻结的图像特征(frozen image features)进行交互;
③ 此外,queries能够通过同样的自注意力层与文本进行交互;
④ 基于预训练任务,应用不同的 self-attention masks 来控制 query-text 交互;
1.3 参数信息
① Q-Former的初始化权重是BERT_base的权重,cross-attention层的权重是随机初始化;
② Q-Former包含188M参数;
③ 使用了32个query,每个query的维度是768;
④ Z表示output query,维度是:(32 X 768);
2. 从冻结的Image Encoder中引导图像-语言表示学习 (Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder)
在表示学习阶段,将Q-Former与冻结的image encoder进行连接,使用图像-文本对进行预训练。训练Q-Former的目的是学习提取与文本相关的图像特征。
以下是3个优化目标,它们共享同样的输入格式和模型参数。
2.1 图文对比学习 Image-Text Contrastive Learning (ITC)
(1) 目的:学习对齐图像特征和文本特征,使得它们的互信息最大化;
(2) 过程:
① 对齐image transformer的输出检索表示( Z )与text transformer的文本表示( t ),这里的t是[CLS]的输出向量。
② 由于Z包含多个输出向量(每个query对应一个向量),首先计算每个query与t的成对相似性(pairwise similarity),然后选择最相似的一个图像-文本对。
③ 为了避免信息泄露,使用单模态的self-attention mask,因为queries和文本彼此之间不可见。
2.2 基于图像的文本生成 Image-grounded Text Generation (ITG)
(1) 目的:将输入图像作为条件,训练Q-Former生成文本。
(2) 过程:
① Q-Former架构并不允许冻结的image encoder与text tokens之间有直接的交互,因为生成文本所需的信息由queries首先提取,然后通过自注意力层传递给文本的tokens。因此,queries被用来提取包含相关文本信息的图像特征。
② 使用单模态的因果自注意力mask来控制query-text之间的交互。
③ 使用 [DEC] 替换 [CLS],作为给decoding mask提供信号的第一个text token。
2.3 图文匹配 Image-Text Matching (ITM)
(1) 目的:学习图像与文本表示之间细粒度的对齐。
(2) 过程:
① 这是一个二分类任务,模型用于预测该图像-文本对是否匹配(正样本 VS 负样本)。
② 使用了一个双向自注意力mask,所有的queries和文本都可以相互访问;
③ 输出查询向量 Z (output query embeddings) 能够捕获多模态的信息,然后将 Z 输入到一个二分类的线性分类器中获取一个logit,接着对所有的queries计算平均的logits,将其作为输出匹配得分。
3. 从冻结的LLM中引导图像到语言生成式学习 (Bootstrap Vision-to-Language Generative Learning from a Frozen LLM)
3.1 框架
png-03

在生成式预训练阶段,将Q-Former (附有冻结的image encoder)连接到冻结的LLM,目的是利用LLM的语言生成能力。
3.2 过程
(1) 使用全连接层FC将输出查询向量(Z,output query embeddings)映射到LLM的文本向量的维度,然后将映射的query向量添加输入文本向量。
(2) 实验过程中包含两种类型的LLM,分别是:decoder-based LLMs 和 encoder-decoder-based LLMs
① decoder-based LLMs : 用语言模型损失进行预训练,基于Q-Former输出的图像特征,用冻结的LLM进行文本生成。
② encoder-decoder-based LLMs : 用prefix语言模型损失进行预训练,将text分成两部分。prefix text与图像特征进行拼接,作为LLM encoder的输入。suffix text通常被当作LLM decoder的生成目标。
4. 模型预训练
4.1 预训练数据
(1) 129M images , 包含 COCO, Visual Genome, CC3M, CC12M, SBU
(2) 115M images, LAION400M
(3) 使用CapFilt方法生成网页图片的合成字幕,使用BLIP_large字幕模型生成10条字母,对字幕进行排序。为每张图片保留 top-2 字母,并在预训练阶段随机选择一个字幕。
4.2 预训练的image encoder和LLM
(1) 冻结的 image encoder
使用了最优的两个预训练vision transformer模型:
① ViT-L/14 from CLIP ② ViT-g/14 from EVA-CLIP
(2) 冻结的语言模型
① decoder-base LLMs : 无监督训练的OPT模型家族
② encoder-decoder-based LLMs : 基于指令训练的FlanT5模型家族
4.3 预训练设置
(1) 第一阶段预训练
① 250K steps
② batch size : ViT-L 2320, ViT-g 1680
(2) 第二阶段预训练
① 80k steps;
② batch size : OPT 1920 , FlanT5 1520
(3) 在预训练阶段,将冻结的ViTs和LLM的参数精读转换为FP16,除了FlanT5使用BFloat16;
五、实验
png-04
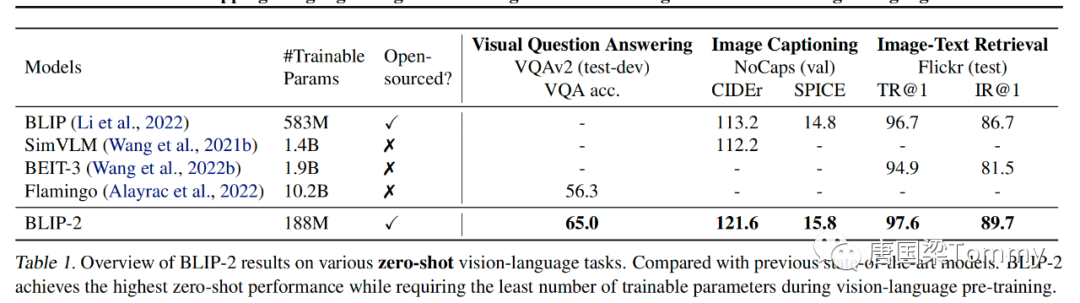
5.1 Instructed Zero-shot Image-to-Text Generation
5.1.1 Zero-shot VQA
png-05
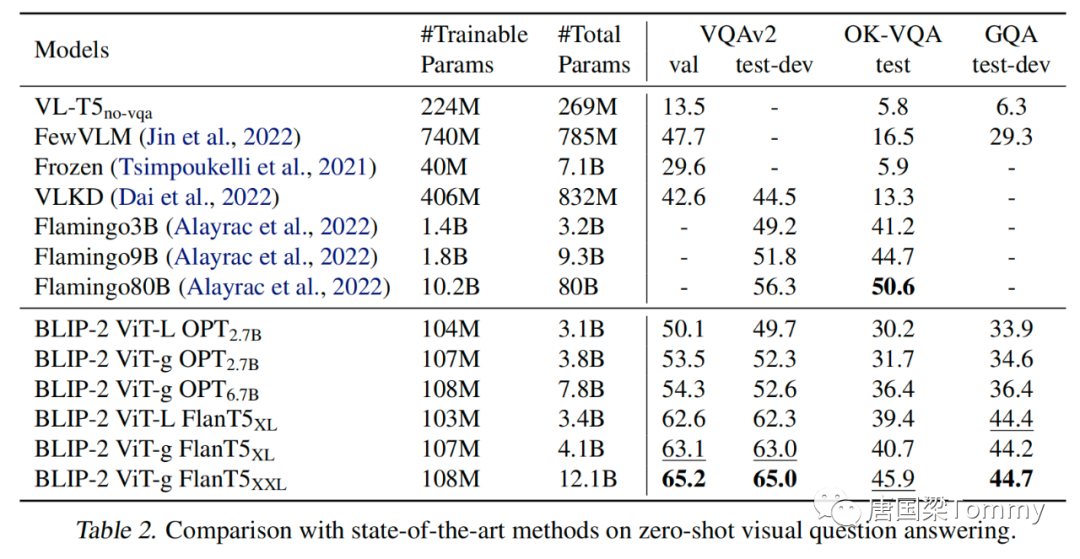
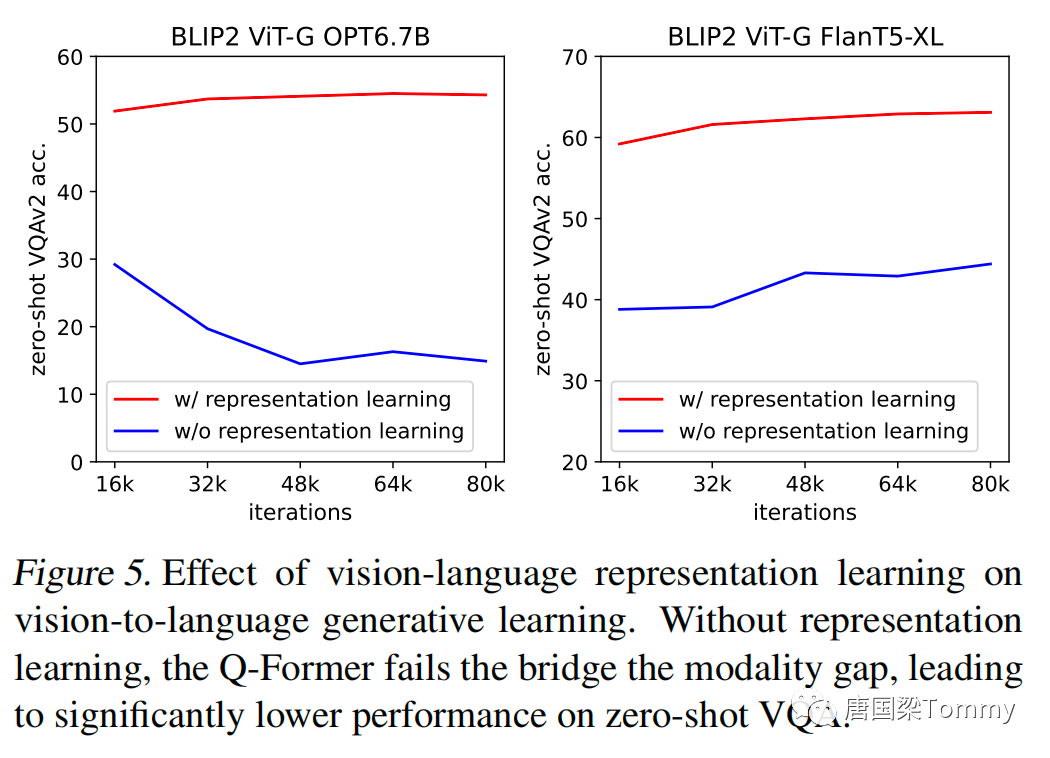
5.1.2 Effect of Vision-Language Representation Learning
png-06
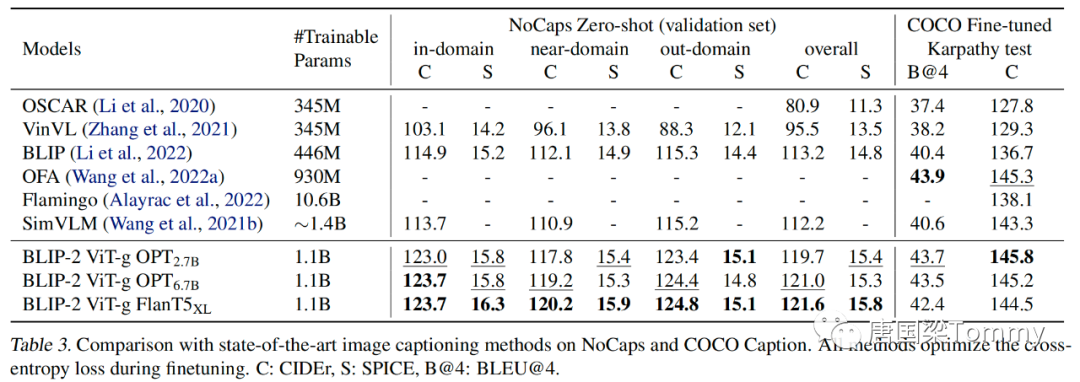
5.2 Image Captioning
png-07
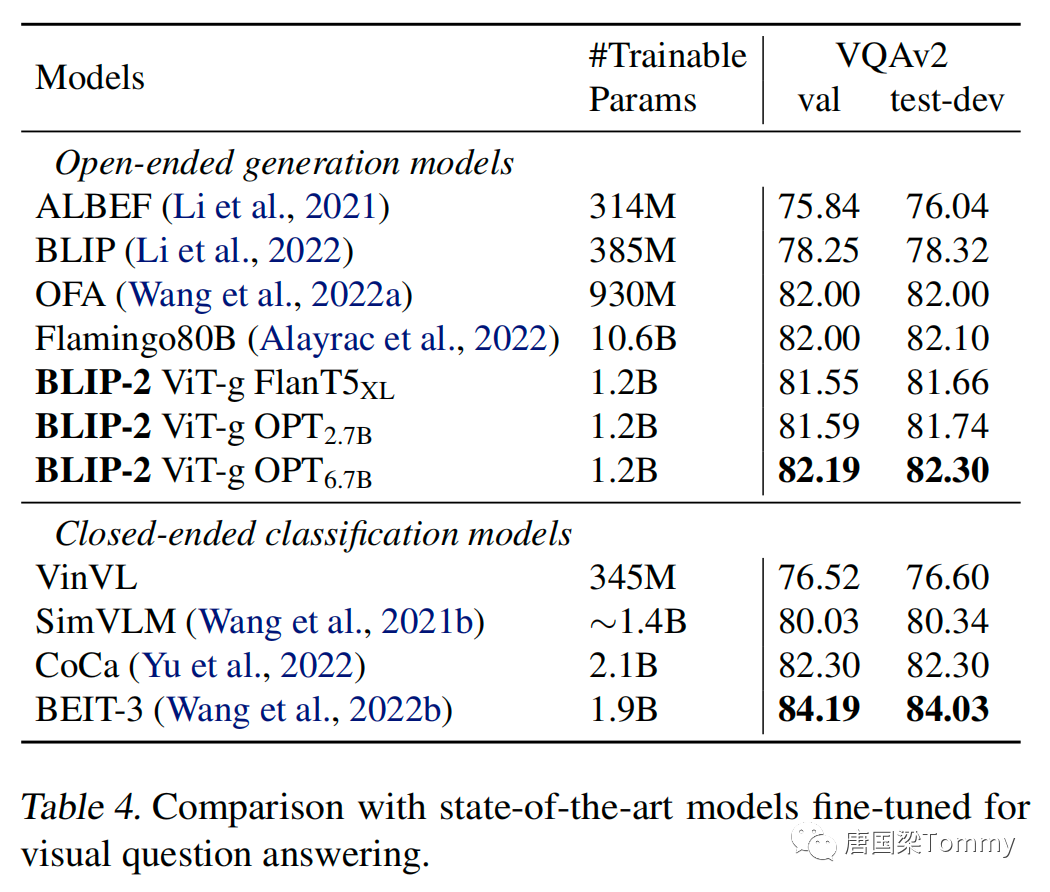
5.3 Visual Question Answering
png-08
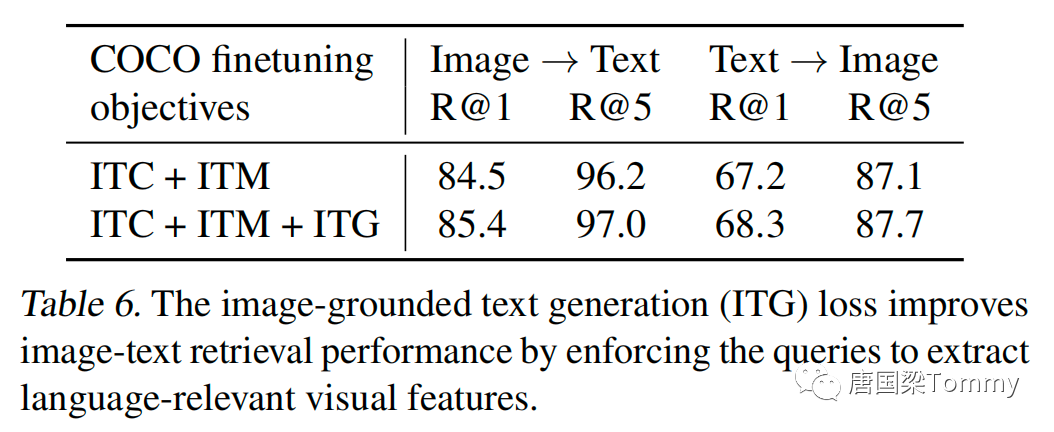
5.4 Image-Text Retrieval
png-09
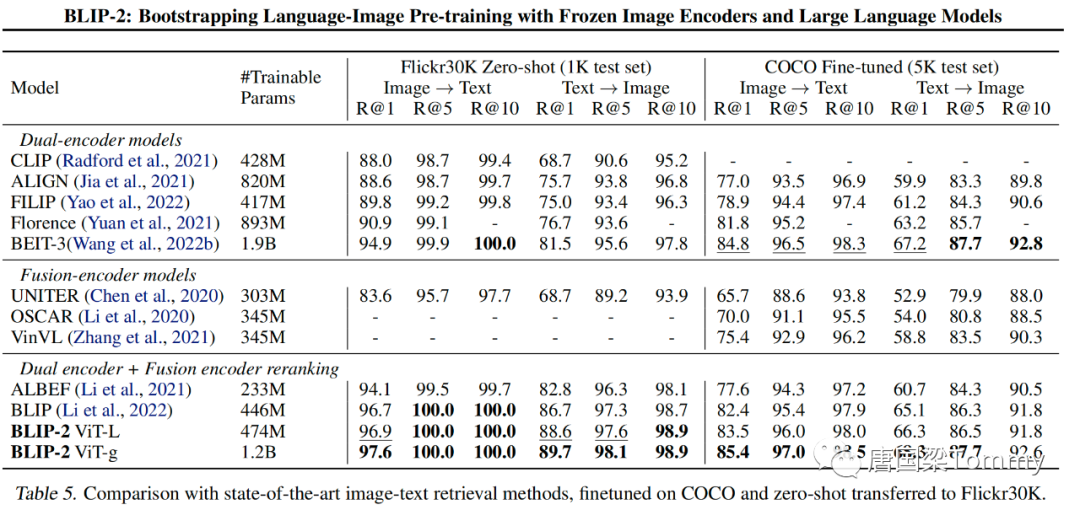
png-10
六、结论
1. BLIP-2,是一种通用且计算效率高的vision-language预训练方法,它利用冻结的预训练 image encoder 和 LLM。
2. BLIP-2 在各种 vision-language 任务上实现了最优的表现,同时在预训练期间具有少量可训练参数。BLIP-2 还展示了zero-shot提示图像到文本生成的涌现能力。