基于HTTP流式传输的长时响应体验提升

在我们应用开发中偶尔遇到某个请求需要后端进行大量计算的情况,这种情况下,按照传统的前后端协同方式,前端需要等待后端慢慢计算,会放一个loading效果,而长时间的loading对用户的体验并不友好,而如果后端采用异步方式,在接收到前端请求后立即返回,过一段时间完成计算后再让前端请求一次,又会让界面上的数据在这段等待时间中处于老的不正确的数据情况,因此,我们需要找到一种既可以避免异步发送数据让用户误认为结果错误,又可以避免长时响应让用户等待焦虑的方法,利用流式传输,可以将结果分片返回,从而让界面实时发生变化,又可以减少前后端多次交互带来的编码困难。
HTTP流式传输
这里的流式传输是指借鉴流媒体技术,在数据传输中实现持续可用的不间断的传输效果。流式传输可以依赖http, rtmp, rtcp, udp...等等网络协议,在本文的场景下,我们主要探讨的是HTTP流式传输。
我们都知道,HTTP是基于TCP的无状态的一次性使用的连接协议,在我们日常的开发过程中,从客户端发起数据请求到服务端把数据一次性吐给客户端,就完成了这一次连接,随后它就关闭了。我们姑且不讨论TCP反复的开启和关闭带来的性能损耗。我们要探讨的是,在HTTP1.1中默认开启的Keep-Alive模式,当客户端和服务端都支持该模式时,一个TCP连接会维持打开,直到客户端不再回答服务端的ACK。而开启Keep-Alive之后,一次HTTP连接就可以维持较长时间的连接状态,配合Transfer-Encoding:chunked报文, 客户端和服务端基于底层的Socket,实现持续的服务端将数据发送给客户端。
Connection: keep-alive
Transfer-Encoding: chunked另一种方式是客户端通过Range报文,主动要求服务端返回的数据范围:
Connection: keep-alive
Range: bytes=0-100此时,服务端会报:
Accept-Ranges: bytes
Connection: keep-alive
Content-Range: bytes 0-100/5243
Content-Length: 101此时的Content-Length只返回当前片段的长度。
Nodejs实现流式传输
由于Nodejs内部实现了Stream,且很多实现的基础都是Stream例如http, file等。我们用nodejs可以轻松实现流式传输:
const http = require("http");
http
.createServer(async function (req, res) {
res.writeHead(200, {
"Content-Type": "text/plain;charset=utf-8",
"Transfer-Encoding": "chunked",
"Access-Control-Allow-Origin": "*",
});
for (let index = 0; index < chunks.length; index++) {
setTimeout(() => {
const content = chunks[index];
res.write(JSON.stringify(content));
}, index * 1000);
}
setTimeout(() => {
res.end();
}, chunks.length * 1000);
})
.listen(3000, () => {
console.log("app starting at port 3000");
});这里的核心点就在于res.write,在http模块中,res本身就是一个基于流实现的响应对象,res.write则是向流中写入内容(相当于append)。
浏览器端实现流式接收
在大部分浏览器内部也实现了流,我们可以通过Streams API了解当前浏览器已经提供的各种接口。而在http请求场景中,全局的fetch函数为我们提供了非常便捷的接入方法。
const res = await fetch('xxx');
for await (let chunk of res.body) {
console.log(chunk);
}fetch返回的响应对象中.body就是一个流,在for await语法的加持下,我们都不需要做过多的处理,就可以用chunk来更新界面上显示的数据。不过可惜的是,目前for await只对firefox加持,因此我们还是必须按照一个ReadableStream的使用方式来从res.body中读取数据:
const utf8Decoder = new TextDecoder("utf-8");
const res = await fetch('http://localhost:3000');
const reader = res.body.getReader();
const processor = async () => {
const { done, value } = await reader.read();
clearInterval(timer);
if (done) {
return;
}
const chunk = utf8Decoder.decode(value, { stream: true });
const item = JSON.parse(chunk);
console.log(item);
await processor();
}
await processor();上面标红的reader.read()返回结果和generator的逻辑一致,只是不知道为什么chrome没有实现next接口。
原文地址:https://www.tangshuang.net/8744.html
效果对比
接下来,我们用没有经过处理的实现,和经过处理的实现来做一个感性的对比。
首先我们来看下传统方式的效果:
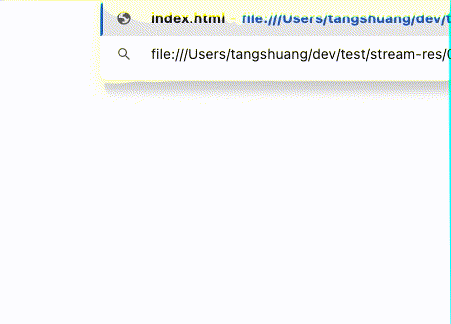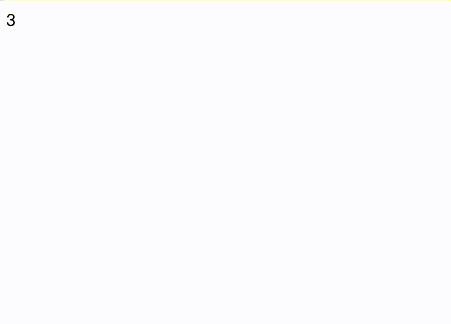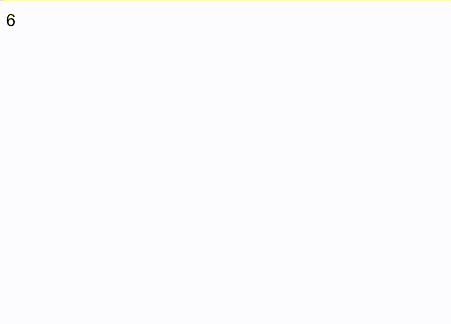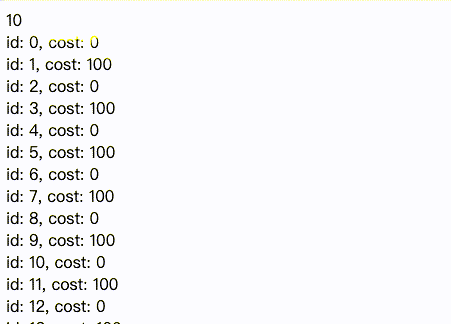
可以看到,我们用一个计时器来作为loading效果,当时间进入10s之后,所有数据回来了,于是我们一次性将全部数据渲染到界面上。
服务端代码如下:
const http = require("http");
const ids = new Array(200).fill(0).map((_, i) => i);
const getData = (id) => new Promise((resolve) => {
const cost = id % 2 * 100;
setTimeout(() => resolve({ id, cost }), cost);
});
http
.createServer(async (req, res) => {
res.writeHead(200, {
"Access-Control-Allow-Origin": "*",
});
const startTime = Date.now();
const results = [];
const run = async (i = 0) => {
const id = ids[i];
if (i >= ids.length) {
return;
}
const data = await getData(id);
results.push(data);
await run(i + 1);
};
await run();
const endTime = Date.now();
res.end(JSON.stringify(results));
console.log('Cost:', endTime - startTime);
})
.listen(3000);客户端代码如下:
<!DOCTYPE html>
<div id="root"></div>
<script>
const root = document.querySelector('#root');
let count = 0;
const timer = setInterval(() => {
count ++;
root.innerHTML = count;
}, 1000);
const startTime = Date.now();
fetch('http://localhost:3000').then(res => res.json()).then((data) => {
console.log(data);
const endTime = Date.now();
const cost = endTime - startTime;
console.log(cost);
clearInterval(timer);
data.forEach((item) => {
const el = document.createElement('div');
el.innerHTML = `id: ${item.id}, cost: ${item.cost}`;
root.appendChild(el);
});
});
</script>当然,这里面还有一些优化空间,比如在服务端用Promise.all来一次性执行全部任务。但是,无论如何优化,底层思维都是一次性拿到全部数据之后再渲染,因此,loading过程中,是没有数据展示的。
接下来看下基于流的效果:

可以看到,页面一打开,数据就一条一条的逐步被渲染,虽然全部的数据回来也需要10s左右,但是,在这过程中,我们可以看到界面上一部分数据已经被渲染出来。
服务端代码如下:
const http = require("http");
const ids = new Array(200).fill(0).map((_, i) => i);
const getData = (id) => new Promise((resolve) => {
const cost = id % 2 * 100;
setTimeout(() => resolve({ id, cost }), cost);
});
http
.createServer(async (req, res) => {
res.writeHead(200, {
"Transfer-Encoding": "chunked",
"Access-Control-Allow-Origin": "*",
'Content-Type': 'text/plain',
});
const startTime = Date.now();
const run = async (i = 0) => {
const id = ids[i];
if (i >= ids.length) {
return;
}
const data = await getData(id);
res.write(JSON.stringify(data));
await run(i + 1);
};
await run();
const endTime = Date.now();
res.end();
console.log('Cost:', endTime - startTime);
})
.listen(3000);客户端代码如下:
<!DOCTYPE html>
<div id="root"></div>
<script>
const utf8Decoder = new TextDecoder("utf-8");
async function init() {
const root = document.querySelector('#root');
let count = 0;
const timer = setInterval(() => {
count ++;
root.innerHTML = count;
}, 1000);
const startTime = Date.now();
const res = await fetch('http://localhost:3000');
const reader = res.body.getReader();
const processor = async () => {
const { done, value } = await reader.read();
clearInterval(timer);
if (done) {
return;
}
const chunk = utf8Decoder.decode(value, { stream: true });
const item = JSON.parse(chunk);
const el = document.createElement('div');
el.innerHTML = `id: ${item.id}, cost: ${item.cost}`;
root.appendChild(el);
await processor();
}
await processor();
const endTime = Date.now();
const cost = endTime - startTime;
console.log(cost);
}
init();
</script>可以发现,总体代码的结构是一致的,只是在传输和获取数据的地方不同,随之渲染的过程也不同。这也说明,在现有的系统中,实现这种传输方式的迁移,是可行的,不会对原有项目的整体架构带来大的变化。
其他场景
本文设想的场景是,一个列表中,每一条数据后端都需要花一定的时间,整个列表的总时间就比较长。针对这一场景,我们采用流式传输的方法,可以让列表可以逐条渲染或更新,从而可以让用户在较快的时间里,获得前面的数据。而这种流式传输,现在已经在前端被广泛使用,甚至被某些框架作为其架构的底层选型。我个人也想到了一些场景,供你参考:
- 长列表
- 数据表格实时更新,例如股票市场行情
- 较长的文章
- 将网页分为多个chunk,每一个chunk对应页面中的一块,首屏chunk放在最前面,这样可以更快让用户看到界面
- 打字机效果,例如实时翻译字幕、ChatGPT的回复
- 用户提交后需要大量计算,可以先返回一个chunk,让前端提示用户已经成功,等计算完再返回真正的chunk,更新界面数据
- 古老的聊天室,在服务端,当收到别人发送的消息时,通过一个chunk发送给自己的浏览器,这样我们就不需要自己架设socket
- 由粗糙逐渐细腻的渲染,例如先发送较少的模型数据,形成一个轮廓,然后再逐渐发送更多数据,将模型的颜色、细节等进行填充
- 分段式操作的场景,例如文件下载,用户点击下载按钮后,服务端要进行压缩打包等,需要一段时间,在打包过程中,还会发现其中某个文件存在问题,要将问题反馈给前端,完成打包之后才返回给前端打包好的文件
- 随机渲染,例如不同的用户处在地图的不同点,我们优先返回该点的地图信息,然后再逐渐往外扩散
总之,流式传输的特性决定了我们可以在较长的时间里,持续地接收数据,实现界面的同步。