2023大数据挑战赛全国六强团队获奖经验+ppt分享(三)
2023大数据挑战赛全国六强团队获奖经验+ppt分享(三)


团队名称
不是吧,阿Sir
团队成员
马千里(华东师范大学)
马镭(华东师范大学)
陶思宇(上海科技大学)
团队名次
全国第四名
赛题描述说明介绍
2023大数据挑战赛赛题说明+决赛评分标准回顾
参赛分享与收获
很庆幸能够在三千多个选手中挤进决赛,比赛最可惜的一点是,在初赛后半阶段以及复赛第一个星期,我们都在尝试端到端的建模方式,但最终方案中没有使用这些方法,耽误了我们大量的时间。我们尝试了Word2Vec(trace,log)、VAE(trace)、Multi-Scale ResNet(trace,log)、BERT-Tokenizer(log)等方式,但是在复赛中效果远不如树模型,我们认为主要原因是题目给到的半结构化数据中实际包含的信息并不多,而结构化的Metirc中蕴含了极大量的信息。
我们自认为做的比较亮眼的地方在于:
1. 使用了ExtraTree作为基模型。这是之前比赛留下来的经验。该模型在小样本及特征不稳定情形下表现较好,而且运行速度极快,这使得我们组算法效率是最高的(但这题不考察效率)。
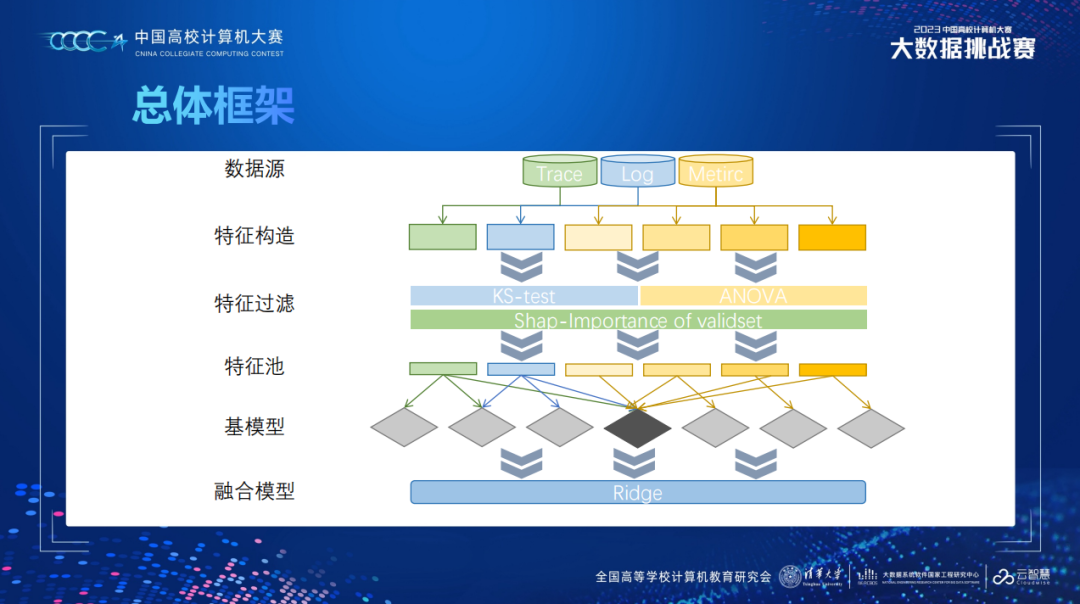
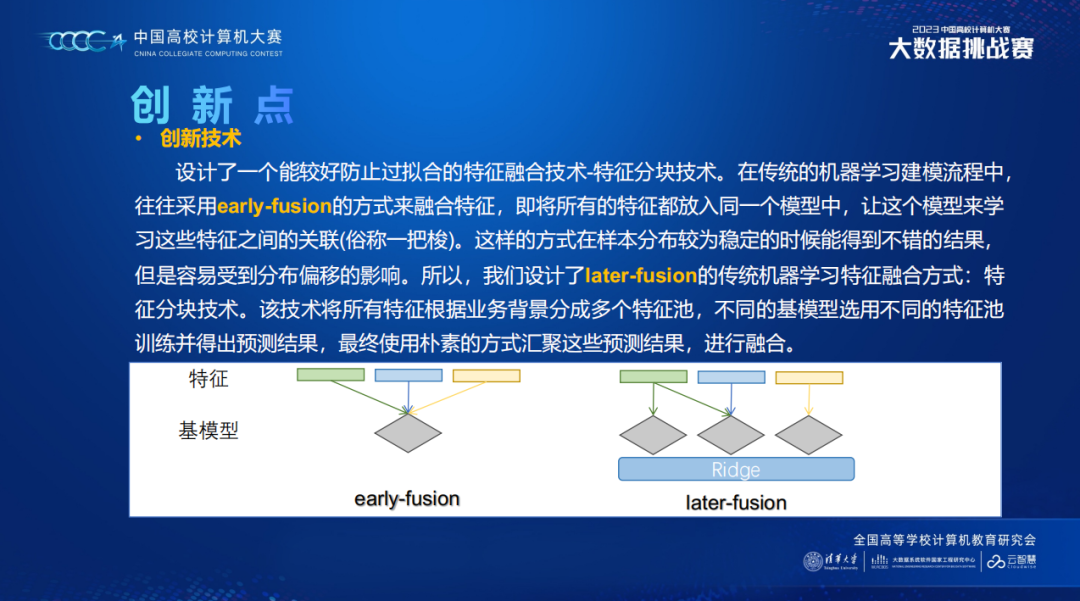
2. 使用了later-fusion的方式融合特征。简单来说就是用不同的基模型提取不同源的特征,然后用融合模型来融合结果。而不是一个模型学习全部特征。这样的方式在工业生产中的好处是可以增量式更新特征,坏处是难以学到特征交互。这种融合方式在其他比赛一般都是累赘,但这题很容易过拟合于训练集,所以我们的融合方式相对有效。
3. 使用统计方法及验证集的特征重要性来选择特征。其他比赛做筛选的常规做法是用模型输出的重要性来筛选特征,但这题特征分布并不稳定且特征维度极高。这样的选择方式在数据分布不稳定的情况下,能得到较好的反馈。
再谈谈收获,从入坑竞赛至今,其他的比赛基本都是树模型一把梭,然后从数据分析入手来刷榜,而我们参加这题的主要目的就是学习并挑战自己。我们试了之前试验过的几乎所有方法,以及尝试了很多比较新颖的网络,这让我们对这些算法有了更深的理解。
决赛答辩ppt分享












编辑:文婧
校对:林亦霖