字节电商场景基于Apache Hudi的落湖实践
字节电商场景基于Apache Hudi的落湖实践

本文为火山引擎Apache Hudi技术社区分享会第九期嘉宾分享提炼文章,本文主要介绍了在处理电商流量数据场景时,LAS对传统数据流架构做出的优化改进。从归档标签和延迟数据处理的角度出发,LAS提出了一种新的入湖方案,该方案能够有效地降低开发与运维成本,保证数据的时效性和稳定性。最后还会为大家带来LAS团队对此方案的未来规划。

文|朱烨 字节跳动电商数据工程师
业务背景
字节跳动早期为了快速支持业务,对于电商流量数据采用Lambda的设计架构,由于当前电商流量数据随着建设的深入和精细化的运营,设计架构的弊端也愈发凸显。
尤其因为实时离线模型和加工逻辑割裂,导致在支持业务的过程时需要盘点彼此的数据链路和加工口径,造成开发的成本过高,而且无法快速的响应用户需求。同时,由于双方口径维护不同步,也会导致很高的运维成本。
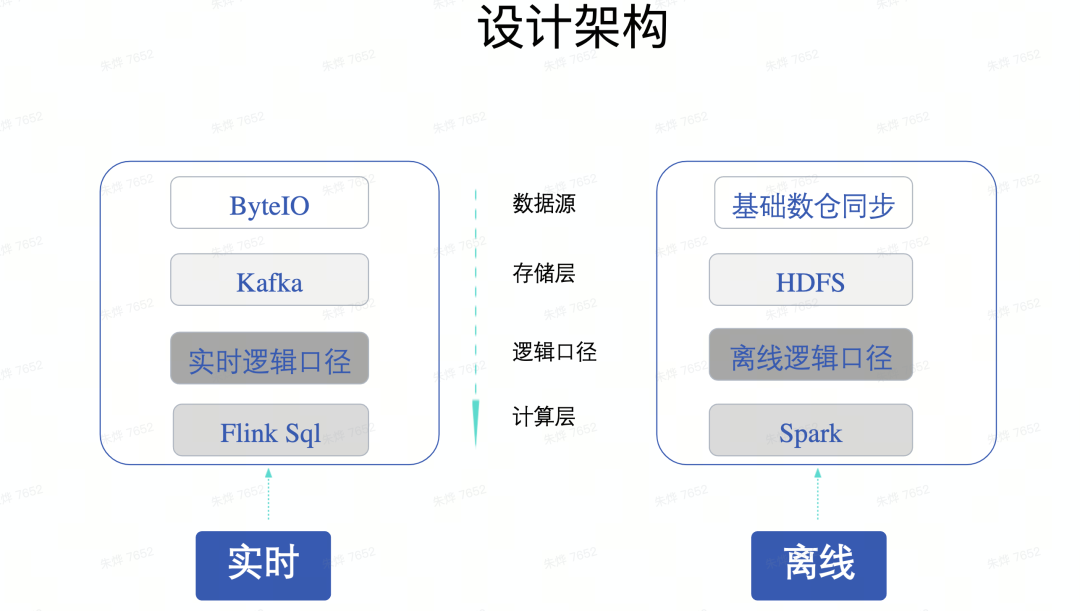
以下便是传统的Lambda架构,由于其流批独立的特点,会带来如下显著几个问题,包括代码维护、逻辑割裂、链路冗余与运行时效问题。

基于上述传统架构存在的问题,我们希望对其做出合理的改进,建设出维护成本低、逻辑统一、时效性高的数据处理架构,主要期待能够实现以下的目标:
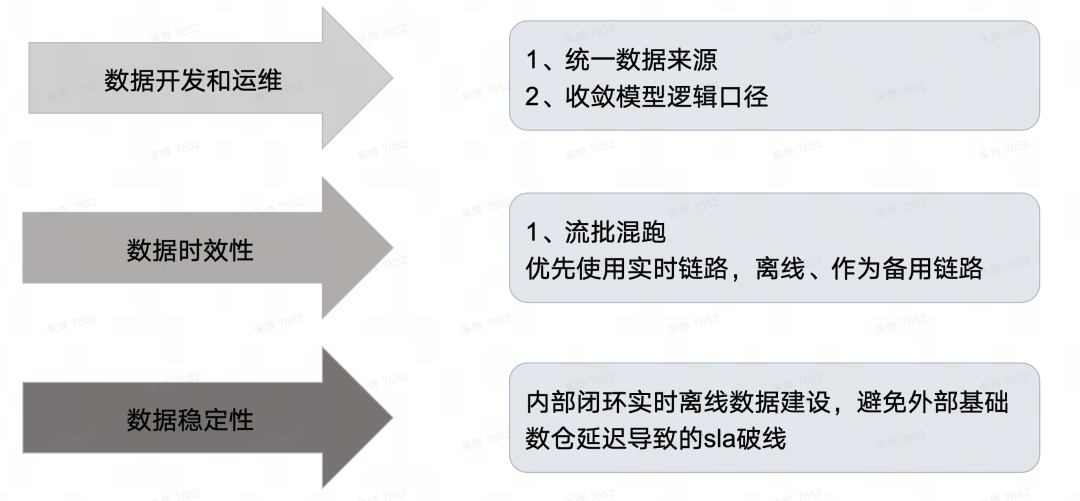
上文为大家讲解了传统的Lambda架构在处理越来越精细化的电商流量数据时的局限性和弊端,并且针对这些问题介绍了我们的改进目标。
接下来将从数据入湖逻辑、归档标签生成、延迟数据处理以及实时数据稳定性保障4个方面分析讲解我们升级的数据入湖方案。
ODS落湖方案
流量数据作为任何产品都是重中之重的数据,当前C端流量小时级数据大约延迟在4~6 小时,对下游数据及时产出以及签署SLA有很大影响,故此将原有技术方案升级。
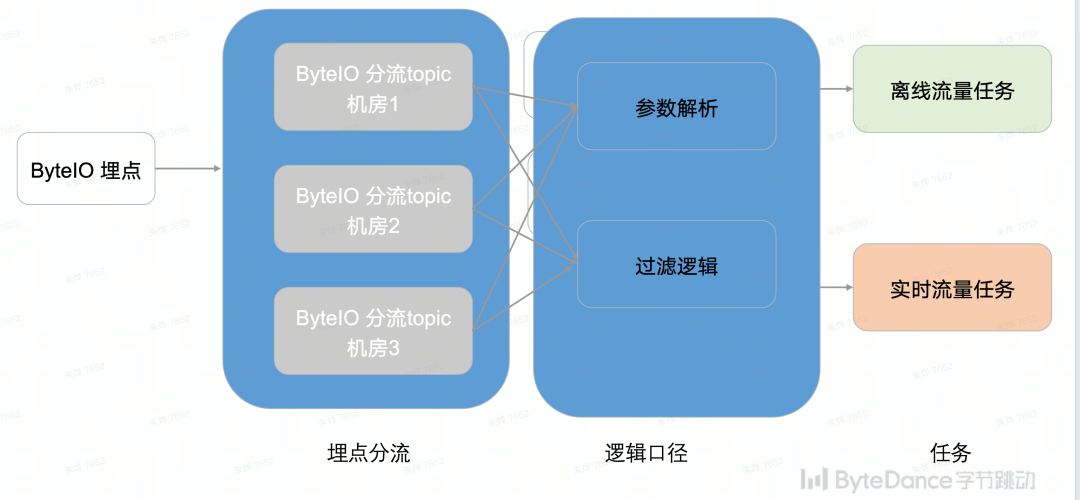
在批流复用的场景下,上游数据实时入湖,下游离线任务一般会小时或天级或 10 分钟粒度调度批量处理数据。
离线任务如果完全基于系统时间进行调度,一旦上游链路产生故障,导致数据大批量延迟,则会产生数据空洞和数据漂移问题。
这就对ByteLake提出了归档能力的诉求,包括数据入湖逻辑、归档标签生成和延迟数据处理。下面将会分别从四个方面进行讨论。
数据入湖逻辑
数据按照业务时间(event_time)实时写入所属分区(date/hour),支持FlinkSQL方式入湖,业务有SQL加工逻辑。数据入湖逻辑如下:
- ? 消费上游数据时,每条记录生成一个Record(col_1, col_2, event_time, date, hour)
- ? Record实时写入Hudi对应分区数据文件(基于Record的分区值date/hour定位要写入的分区)
- ? Flink Checkpoint触发Hudi事务提交,每次提交会记录这一次CP新增的文件名,以及数据量、记录数等一些统计信息。提交成功后,下游对这一批数据才可见。
归档标签生成
延迟会带来数据的缺失。例如,当实时 ODS 表发生延迟时,ODS 的 hour='01' 表数据量会缺失,如缺失 10% 的加购点击。
默认情况下,ODS 的下游 DWD表按时更新,所造成的影响是加购点击量少计算了 10%。针对这种情况,需要及时发现、拉回溯。相较而言更优的方式是尽早发现延迟、阻断调度、处理延迟。
Flink Checkpoint 与 Hudi 的事务提交强相关,每次 CP 会触发一次 ByteLake 事务提交,提交后数据对下游可见。当业务分区数据就绪后可自动生成归档标签,下游离线任务基于归档标签的生成触发调度。
归档标签生成#currentMinEventTime:全局最小业务时间 #minEventTime:当前 CP 最小业务时间 #partitionEventTime:未归档的分区对应的时间戳 currentMinEventTime = Math.max(minEventTime, currentMinEventTime); // 更新全局最小业务时间 while (currentMinEventTime - tagDuration > partitionEventTime) { // 判断分区是否归档 tag_success(partitionEventTime); // 给对应分区打标签 partitionEventTime = partitionEventTime + 1day/1hour/10min; // 向后增加一个分区时间 }延迟数据处理
对延迟数据的处理主要分为如下几个步骤:
- ? 在数据实时入湖过程中会记录全局最小event_time;
- ? 每次触发Flink CP时,在事物提交阶段,会使用这次 CP 的最小 event_time 与上一次写入的分区时间求差值,如果差值超过指定的等待时间,则认为上一次的分区,会在对应分区目录下创建 _SUCCESS 文件,完成这个分区的归档。
在前两个步骤基础上, Hudi 会判断 Record(col_1, col_2, event_time, date, hour) 对应的分区是否已经存在 SUCCESS 标签(是否已经归档)false:不做任何改动,正常写入true:rewrite Record 分区值 Record(col_1, col_2, event_time, date, hour + 1)实时数据稳定性保障
对于实时数据的稳定性问题,我们采取如下方案对其进行保障,通过离线 Hive 表来记录两条链路就绪的记录,通过信号设置来检测并触发下游,基本步骤如下:

上述方案能够实现自动化切换,无需人工介入,同时对上游任务状态感知灵敏(测试后比方案二约延迟 5min),还能够记录备份链路&实时链路生效时间,长期对比观测,方便优化链路。
ODS落湖总结
Flink 消费消息队列写入 Hudi 的方案可以在低延迟的前提下(1 hour 内),同时保证数据量(天级、小时级)与离线 DWD 数据表的一致性达到 99.99% 以上。
未来规划
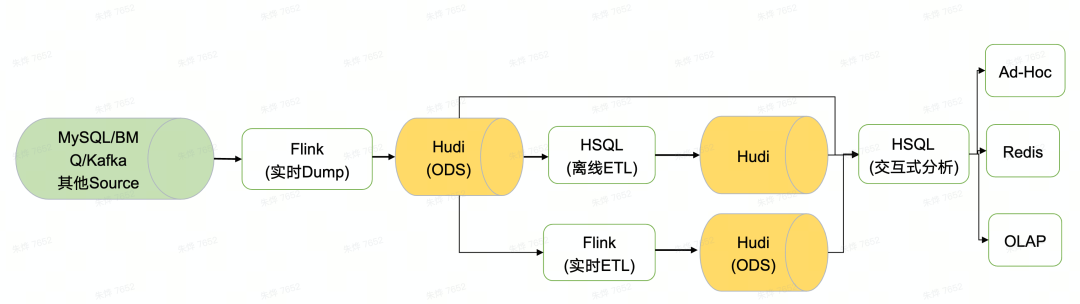
基于 Hudi 的 ODS 落湖方案在未来的规划主要从以下三个方面展开:
第一,实现流批一体技术方案在DWD& DWM数据层落地 第二,可以在当前ODS基础上做一些etl逻辑,落地到DWD层 第三,选取一些场景(eg:大促)做流批一体(ODS -> DWD-> DWM -> OLAP -> report)整个链路
以上就是字节跳动针对电商流量数据处理场景中基于Hudi的ODS落湖实践。