分布式存储和分布式计算,这么好懂!
分布式存储和分布式计算,这么好懂!


分布式存储和分布式计算到底是什么?
本文就来为你详细讲解一下~~
原来,它们这么好懂!
01
大数据的分布式存储
Google的文件系统GFS是一个典型的分布式文件系统,也是一个分布式存储的具体实现方式。日常的工作和生活中使用的网盘也是一个典型的分布式文件系统。
下图展示了GFS的基本架构。

将数据存入一个分布式文件系统,需要解决两个问题——如何存储海量的数据和如何保证数据的安全。如果从技术上解决了这两个问题,就能够实现一个分布式文件系统来存储大数据,并且保证数据的安全。
而解决的方案就是采用分布式集群,即采用多个节点组成一个分布式环境。
下面分别讨论实现的细节,从而引出Hadoop的分布式文件系统HDFS的基本架构和实现原理。
1. 如何存储海量的数据
因为需要存储海量的大数据,所以不能采用传统的单机模式进行存储。
解决的方法也非常简单,既然一个节点或一个服务器无法存储,就采用多个节点或多个服务器一起存储,即分布式存储,进而开发一个分布式文件系统来实现数据的分布式存储。
一个分布式文件系统存储数据的基本逻辑如下图所示。
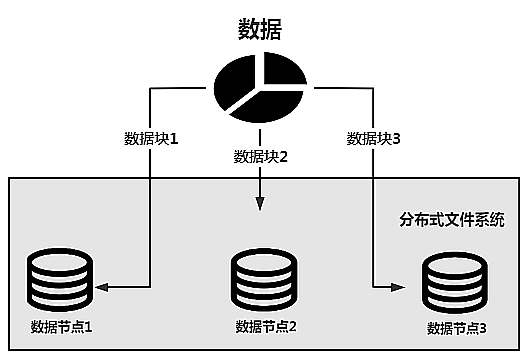
数据会被分隔存储到不同的数据节点上,从而实现海量数据的存储。假设数据量的大小是20GB,而每个数据节点的存储空间只有8GB,就无法把这些数据存储在一个节点上。
但是现在有3个这样的节点,假设每个节点的存储空间依然是8GB,那么总的大小就是24GB,就可以把这20GB的数据存储在由这3个节点组成的分布式文件系统上。
如果这3个数据节点都已经存储满了,就可以向该文件系统中加入新的数据节点,如数据节点4、数据节点5……从而实现数据节点的水平扩展。
从理论上说,这样的扩展可以扩展到无穷,从而实现海量数据的存储。如果把上图架构对应到Hadoop的分布式文件系统HDFS中,数据节点就是DataNode。
这里还有另一个问题——数据存储在分布式文件系统中时,是以数据块为单位进行存储的,例如:从Hadoop 2.x版本开始,HDFS默认的数据块大小是128MB。
提示:
数据块是一个逻辑单位,而不是一个物理单位,也就是说,数据块的128MB和数据实际的物理大小不是一一对应的。
这里举一个简单的例子。
假设需要存储的数据是300MB,使用128MB的数据块进行分隔存储,数据就会被分隔成3个单元。前两个单元的大小都是128MB,和HDFS默认的数据块大小一致,而第三个单元的实际大小为44MB,即占用的物理空间是44MB。但是第三个单元占用的逻辑空间大小依然是一个数据块的大小,如果在HDFS中,就依然是128M。换句话来说,第三个数据块没有存满。
2. 如何保证数据的安全
数据以数据块的形式存储在数据节点上,如果某个数据节点出现了问题或宕机了,就无法正常地访问存储在该节点上的数据块。如何保证数据块的安全呢?
Google的GFS借鉴了冗余的思想来解决这个问题。简单来说,数据块的冗余就是将同一个数据块多存储几份,并将它们存储在不同的数据节点上,这样即使某个数据节点出现了问题,也可以从其他节点上获取数据块信息,如下图所示。
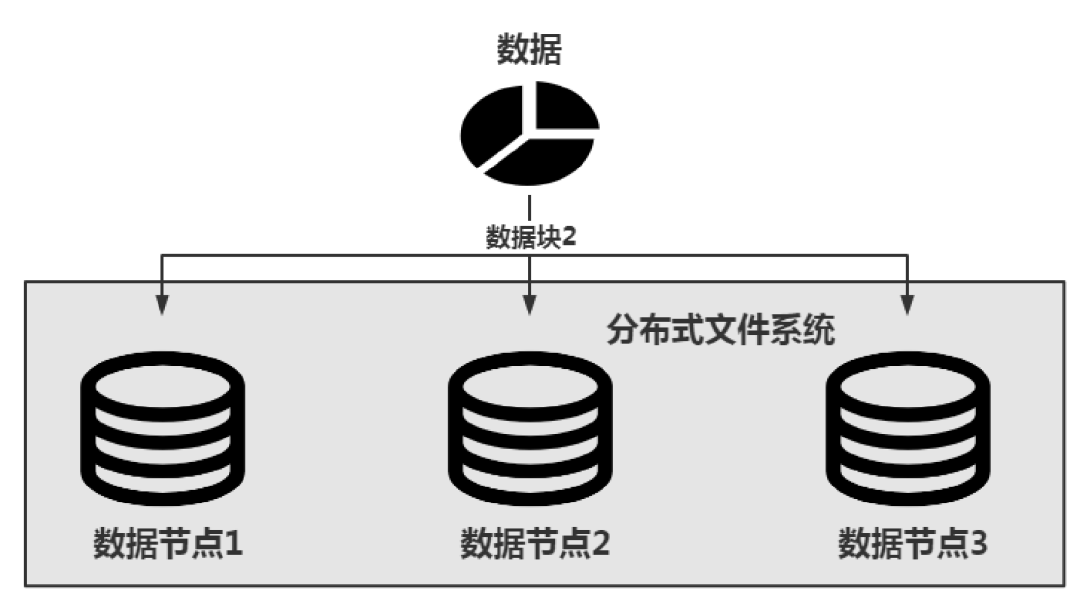
在上图中,数据块2同时存储在了3个数据节点上,即冗余度为3,这样就可以从任何一个数据节点上获取该数据块的信息了。
提示:
数据冗余思想的引入解决了分布式文件系统中的数据安全问题,但是会造成存储空间的浪费。
在HDFS体系架构中,除了前面提到的DataNode数据节点,还有NameNode和SecondaryNameNode。
HDFS是一种主从架构,主节点是NameNode,从节点是DataNode。HDFS的基本架构如下图所示。

02
大数据的分布式计算
大数据的存储可以采用分布式文件系统,那么如何解决大数据的计算问题呢?
和大数据存储的思想一样,由于数据量庞大,无法采用单机环境来完成计算任务。
既然单机环境无法完成计算任务,就使用多台服务器一起执行计算任务,从而组成一个分布式计算的集群来完成大数据的计算任务。基于这样的思想,Google提出了MapReduce计算模型。
提示:
Google提出的MapReduce是一种处理大数据的计算模型,它和具体的编程语言没有关系。
Hadoop体系中实现了MapReduce计算模型。Hadoop是采用Java语言实现的框架,因此在Hadoop中开发的MapReduce程序也是一个Java程序。
众所周知,MongoDB也支持MapReduce计算模型,而MongoDB中的编程语言是JavaScript,所以在MongoDB中开发MapReduce程序需要使用JavaScript语言。
Google为什么会提出MapReduce计算模型呢?其主要目的是解决PageRank的问题,即网页排名的问题。因此在介绍MapReduce计算模型之前,有必要先介绍一下PageRank。Google作为一个搜索引擎,具有强大的搜索功能。
每一个搜索结果都是一个HTML网页,即Page。那么如何决定网页的排列顺序呢?这就需要给每个网页打一个分数,即Rank值。Rank值越大,对应的Page在搜索结果中就越靠前。PageRank的一个简单示例如下图所示。
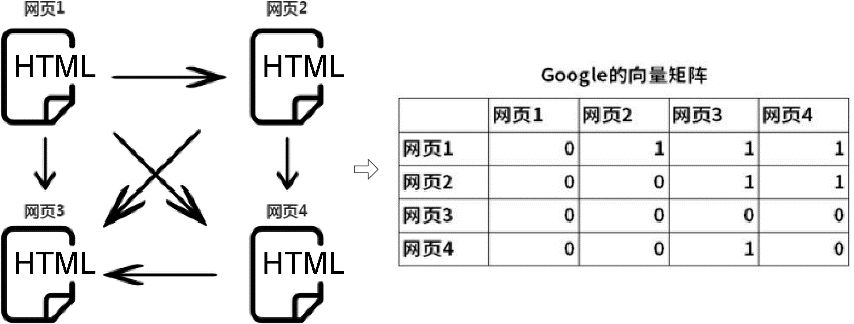
这个示例以4个HTML的网页来展示。网页与网页之间可以通过<a>标签的超级链接从一个网页跳转到另一个网页。
假设,网页1链接跳转到了网页2、网页3和网页4;网页2链接跳转到了网页3和网页4;网页3没有链接跳转到其他的网页;网页4链接跳转到了网页3。
如果用1表示网页之间存在链接跳转关系,用0表示不存在链接跳转关系,并以行为单位,就可以建立一个Google的向量矩阵来表示网页之间的跳转关系。这里得到的向量矩阵将是一个4×4的矩阵。通过计算这个矩阵就可以得到每个网页的权重值,而这个权重值就是Rank值,从而进行网页搜索结果的排名。
但是在实际情况下得到的这个Google的向量矩阵是非常庞大的。例如,网络爬虫从全世界的网站上爬取回来了1亿个网页,存储在分布式文件系统中,而网页之间又存在链接跳转的关系。这时候建立的Google的向量矩阵将会是1亿×1亿的庞大矩阵。这样庞大的矩阵无法使用一台计算机来完成计算。如何解决这个庞大矩阵的计算问题将是PageRank的关键。在这样的问题背景下,Google提出了MapReduce计算模型。
MapReduce的核心思想其实只有6个字,即先拆分、再合并。通过这样的方式,不管得到的向量矩阵有多大,都可以进行计算。拆分的过程叫作Map,而合并的过程叫作Reduce。MapReduce处理数据的基本过程如下图所示。
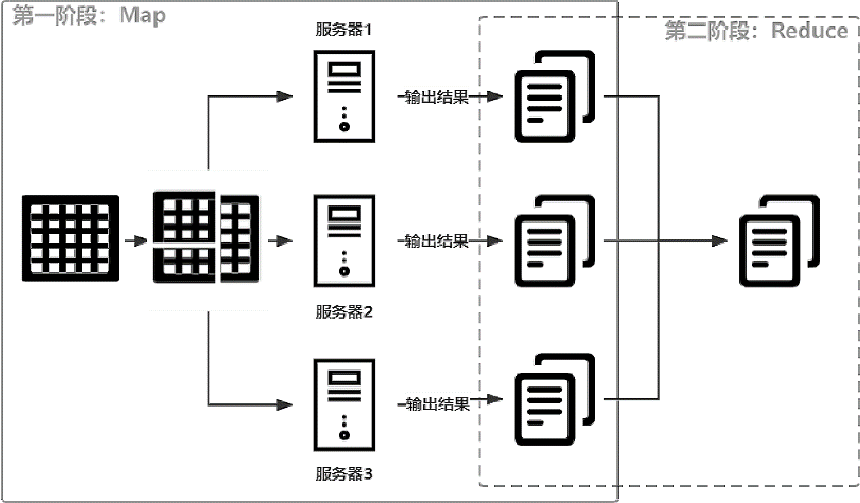
在上图的示例中,假设有一个庞大的矩阵要进行计算,由于无法在一台计算机上完成,因此将矩阵进行拆分,首先将其拆分为4个小矩阵,只要拆分到足够小,让一台计算机能够完成计算即可。
- 每台计算机计算其中的一个小矩阵,得到部分结果,这个过程就叫作Map,如上图中实线方框的部分。
- 将Map的输出结果进行二次计算,从而得到大矩阵的结果,这个过程就叫作Reduce,如上图中虚线方框的部分。
通过Map和Reduce,不管Google的向量矩阵有多大,都可以计算出最终的结果。在Hadoop中使用Java语言实现了这样的计算方式,这样的思想也被借鉴到了Spark和Flink中。例如,Spark中的核心数据模型是RDD,它由分区组成,每个分区被一个Spark的Worker从节点处理,从而实现了分布式计算。
在Hadoop中执行MapReduce任务的输出日志信息如下图所示。

通过输出的日志可以看出,Hadoop的MapReduce任务被拆分成了两个阶段,即Map阶段和Reduce阶段。当Map执行完成后,接着执行Reduce,并且Map处理完的数据结果将会作为Reduce的输入。
本文分享自 博文视点Broadview 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与?腾讯云自媒体分享计划? ,欢迎热爱写作的你一起参与!