MySQL binlog集市的项目小结
MySQL binlog集市的项目小结

这是学习笔记的第 2478篇文章
MySQL binlog集市的事情我们做了有一段时间了,最开始的初衷是异常操作的数据恢复,主要的痛点是如果发生了业务误操作,需要紧急恢复数据的时候,通常这些误操作是对于字典配置数据的变更,而要恢复的时候成本则太高了,举个极端的例子,1T数据量的数据库,要恢复的字典数据最有1M,但是很可能需要恢复1T的数据量作为代价,有点得不偿失,所以,我们对于binlog集市是希望尽可能完整的捕获数据库的数据变化,并且能够闪回恢复。
对于数据库异常恢复的主页面如下,提供环境信息和时间戳,基本就能够进行数据恢复了。
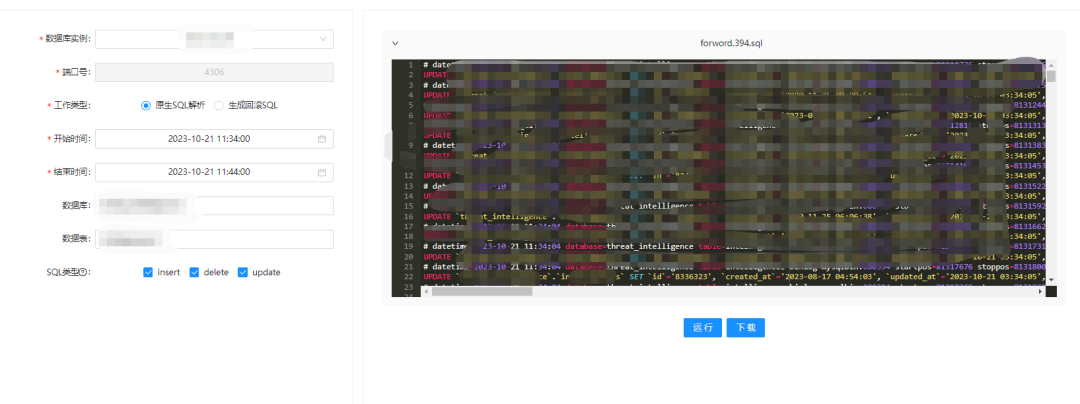
这个事情往前做一下,那就是通常误操作时提供的信息是有较大偏差的,比如12:10发生的操作,可能研发同学会信誓旦旦的说是12:08,到底那个时间段之内有没有相关的操作,我是把重心放在了定位环节,通过定位让整个数据恢复的代价变得最小,而且时间可控。我们按照时间轴(分钟,秒等维度)可以生成数据变化的明细情况,这样能够更加精准的定位异常问题和范围。
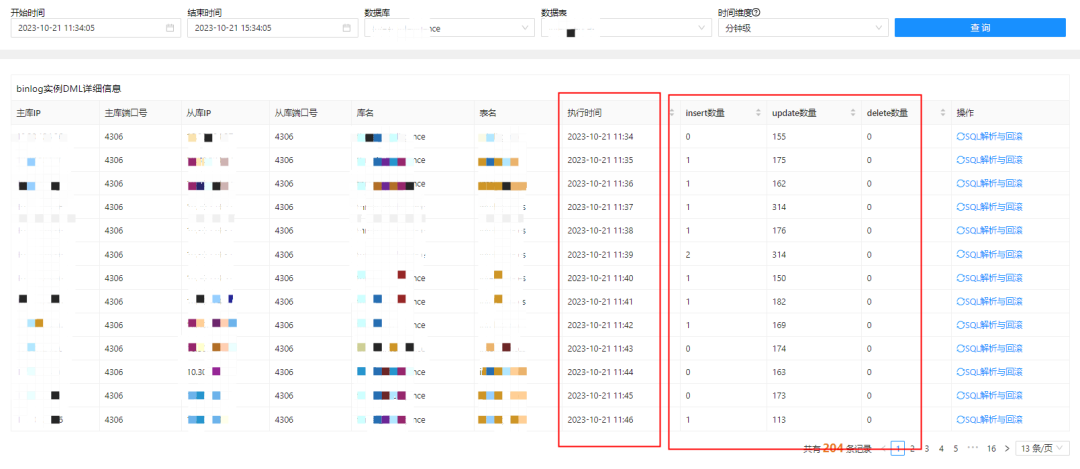
这个事情再往前做一下,那就是我们获得了某个实例的binlog数据变化明细,那么对于全平台的binlog变化则不在话下,当然这个过程比预想的要复杂一些,也着实解决了一些很细节的处理逻辑。放到全局,则是全平台的数据监测功能。
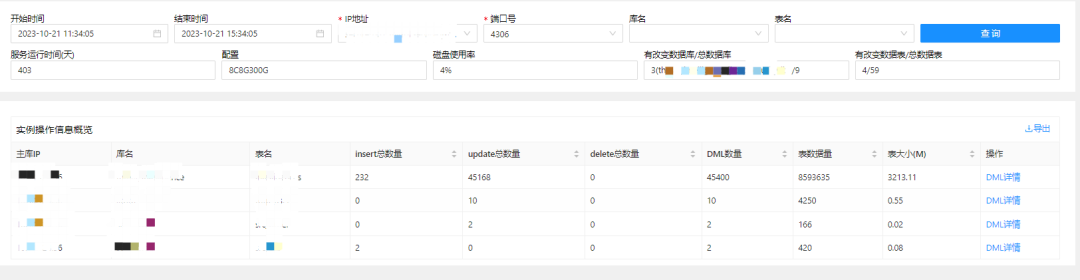
从全局视角,是可以通过实例维度看到数据变化的明细情况的,如下图所示:
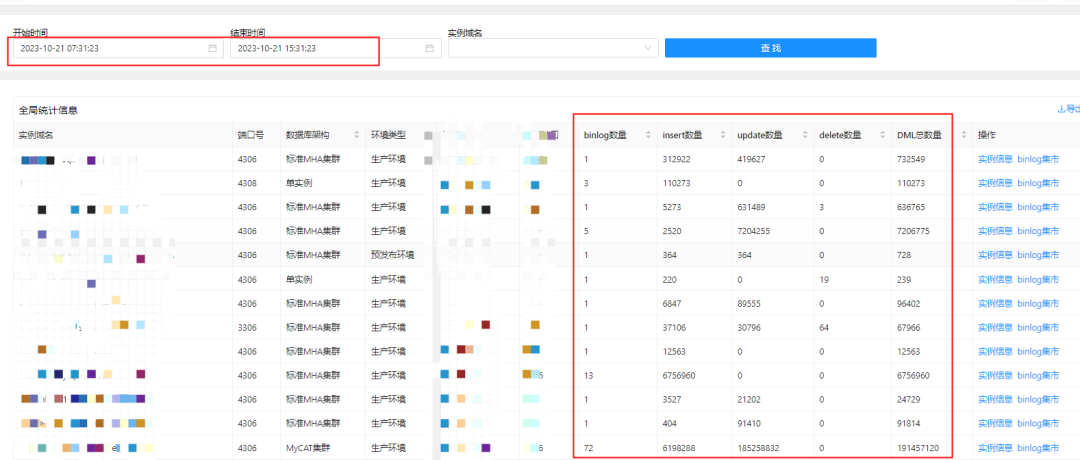
由此下钻,也可以看到具体的实例中的表数据变化明细。
以上是整个binlog集市的一些处理逻辑,总结一下,基础的定位是解决异常操作时的数据恢复,再这个基础上衍生出了附加价值,可以实现全局视角从全平台数据监测逐步下钻到某一张具体的表。
但是通过我的感受和大家的反馈,这个项目的成效平平。对此我开始总结和反思。
binlog集市的体系已经构建起来了,但是目前还没有真正发挥效用。
有三种可能:
1)本身binlog集市的服务本身就没有那大的业务价值
2)binlog集市的功能目前对于运维口开放,对于运维侧没有发挥价值
3)binlog集市对于研发来说闻所未闻,压根不知道
好了,我们已经具备这样的能力:可以提供每个数据库包括集群每时每秒发生的数据变化情况,可是这个数据有什么作用呢?这是一个扎心的问题,也是一个需要实际面对的问题。
如果是泛化的需求,很难发挥直接的效用,所以binlog集市需要能够发现并且解决一些问题。
发现什么问题,解决什么问题呢?这不是发难,而是盘点我们目前的状态,首先是定位,我们得对binlog集市有一个初步的定位,它不是万金油,而是解决具体场景的问题,期望需要和实际匹配,二来我们没有深入到研发侧做调研获得需求,三来也没有深入思考,偏执行层面。
首先需要明确,做binlog集市解决最核心的问题是异常操作场景下的数据快速恢复,在这个基础之上再去发挥更大的价值。
那么对于binlog集市恢复异常操作数据的功能,我们需要让这件事情有底,就得做一些辅助和验证:
1)保障binlog集市的稳定,怎么证明它是稳定的,需要有一些功能,性能等维度来说明辅证
2)我们到目前为止,是否做过3次以上的异常恢复演练,是否达到了预期的效果,3次是拍脑袋的说法,也可以是5次,10次
3)binlog集市不能做什么,什么情况需要规避,需要尤其注意,我们得知道这个服务的边界
4)对业务开放,让业务能够真正试用,和重点用户达成数据恢复的流程共识,什么时候需要我们介入,什么时候研发侧就可以自己处理了,当然异常发生时,我们得有知情权。
其次,我结合我的思考,还有一些是之前和研发的简单沟通所做的分析:
1)运维视角的宏观评估和分析:每天数据库中那么多的数据变化,每天的变化情况是如何的,每天产生多少的日志存储?说实话,绝大多数的DBA应该都不大了解,但是不代表这个信息不重要,如果某一天的日志量暴涨或者下跌明显,我如果在报警发生之前就得到这些信息,我认为这个工具是有效的
2)研发视角的宏观评估和分析:很多研发同事对于数据库的信息有一种无力感,比如这个数据库中有多少表,每个表有多少数据,他们很难得到这些信息,直接查询又担心出性能问题,哪些表数据变化比较多是他们比较关注的事情,毕竟这是他们自己的业务;
3)运维视角数据治理和优化:一个数据库中有几十上百张表,有哪些表是需要重点关注的?全平台有哪些表需要重点识别和关注,对于那些频繁发生数据变化的表,可能会提供优化的思路
4)数据量变化巡检:如果数据库中某张表的数据量暴涨和下跌,我们有没有机制发现,从单一的维度是很难分析出问题的,得有历史数据的支撑,还可以辅助一些预测,那这个问题的解决就高了一个层次
4)字典表变更轨迹追溯:数据表有字典表,状态表和日志表,这个里面研发侧更关注的还是字典表的数据变化,这种数据变化频率不高,但是变化的影响范围比较大。假设我们有了字典表变化的一种跟踪服务,那么发生异常的时候,可以优先排除是否有字典数据的变化
5)表结构变更后的信息订阅和同步:有些数据是需要通过数据流转持续发挥价值的,那么上游的字段发生变化(创建表,删除表,添加字段,删除字段,修改字段类型等),对于下游都是很大的影响,这些信息下游的同事应该是缺少一直机制去了解的
所以结合以上信息:
1)binlog集市的定位和核心功能就是异常场景下的数据快速恢复,那么就应该优先把这块事情做好
2)要让binlog集市发挥更大的作用,就需要提供一些服务化的功能,我建议是不用以binlog集市的视角去建设,而是从业务标签,实例的视角去做,一种是完善已有的运维服务,把binlog集市的一些能力集成进来,二来是规划独立的业务服务,需要业务视角,把binlog集市的一些功能集成起来,让运维和研发感受到实实在在的业务支撑效果。
热文: