数据湖存储在大模型中的应用


9月5日,浪潮信息新产品“互联网+AIGC”行业巡展在深圳举行。本次巡展以“智算 开新局·创新机”为主题,腾讯云存储受邀分享数据湖存储在大模型中的应用,并在展区对腾讯云存储解决方案进行了全面的展示,引来众多参会者围观。
ChatGPT 的横空出世为市场带来了一道曙光,通用型人工智能在可预期的将来可以为各行各样带来生产力的提升。会中腾讯云高级产品经理林楠主要从大模型的发展回顾、对存储系统的挑战以及腾讯云存储在大模型领域中的解决方案等三个角度出发,阐述存储系统在大模型浪潮中可以做的事情。他表示:为了满足大模型领域的需求,达成提高性能、降低成本的双目标,腾讯云提供了完整的IaaS产品大模型解决方案。数据湖存储可以帮助企业一站式解决数据采集、清洗、训练和消费等环节的存储需求,有效降低存储成本,提升数据使用效率,为大模型的训练和应用提供更好的支持。

为什么模型越来越大
对存储系统而言,通用型人工智能也属于应用的一种,那么了解大模型的应用机制和核心需求对存储系统的设计也至关重要。回顾大模型的发展史,我们可以看到在过去的几年发展时间里,早期基于Transformer架构的模型使用小数据集、小参数量就可以完成训练,而现如今则快速迭代到需要大数据集,大参数量的架构。
研究人员关于大模型在通用型人工智能领域的模型性能表现展开了非常多的研究。大模型的“涌现”特性让越来越多人员认可了模型规模对性能表现的决定性作用。同时在OpenAI的研究中,研究人员也发现:在使用相同数量的计算资源进行训练时,更大的模型可以在更少的更新次数后达到最优的性能;模型性能随着训练数据量、模型参数规模的增加呈现幂律增长趋势。

大模型对存储系统的挑战
回顾GPT3的论文可以发现,大模型的整体框架中包括了数据的采集、清洗、预训练、微调、推理等多个阶段。我们从基础设施、数据和算法这三个层面来看大模型这一新的技术和应用形态到底需要的是什么。
在基础设施层面,最关键的其实是效率,通过高性能的GPU,网络和存储服务等基础服务,尽可能地压缩模型训练时间,提升资源利用率;同时,通过平台化的PaaS乃至SaaS服务,进一步提升基础设施的运维人效比,降低训练中断带来的损失。
在数据层面则需要解决数据质量的问题。如何从浩瀚的互联网中获取并存储大量公开数据集,并通过高效的数据预处理技术筛选出来高质量、可靠的训练数据集,是获取优秀模型性能的关键前置环节。
在算法层面则需要关注确保模型的产出符合业务预期,一方面是提供高质量的内容产出,另一方面则需要确保内容是符合相关规范和要求的。
所以,大模型的这些技术特点,总结出来是存储系统中的“多快好省”。“多”指支持海量分布式存储;“快”意味着解决数据快速访问和传输需求,提升GPU效率,降低训练成本;“好”需要解决内容质量和合规问题;“省”则强调通过软硬件技术降低实际成本。

腾讯云存储在大模型领域中的解决方案
为了应对大模型的技术需求,腾讯云在IaaS、PaaS和SaaS等不同产品方向均提供了多样的技术支持手段,主要体现为三个“快”:
- 数据读取快:GooseFS数据加速,提供高性能存储,为AI集群训练快速提供数据。
- 训练速度快:高性能计算集群HCC通过自研服务器提供最新代次A800、H800实例。通过TACO Train加速套件,提供软硬件协同优化,支持训练性能提升30%以上。
- 网络交换快:基于自研星脉网络架构,提供最高3.2Tbps RDMA网络,结合自研拥塞控制算法及TCCL集合通信库加速分布式训练通信效率。
在存储视角下,我们回顾大模型整体技术框架中会涉及存储诉求的环节:
- 数据采集环节。通过对象存储的海量分布式存储和高可用的公网接入能力,支持多种不同来源的结构化、半结构化、非结构化数据的快速接入。
- 数据清洗环节。真实用于训练用的数据量只有几十TB级,但原始数据集规模却异常庞大,可以达到PB级。数据清洗环节需要支持高效、可靠地将原始数据清洗成训练所需的产出。
- 数据训练环节。主要分为训练数据的预加载和Checkpoint写入两个环节。为了尽可能提升宝贵的GPU资源的利用率,这两环节都需要尽可能地压缩耗时,因此需要高IOPS、大吞吐的存储系统。
- 推理和应用环节。大模型的推理和应用环节对存储的诉求与当前大数据/AI中台对存储的需求大致相同,需要注意的是,基于生成式AI产出的内容更需要关注数据治理,确保内容的合规性。
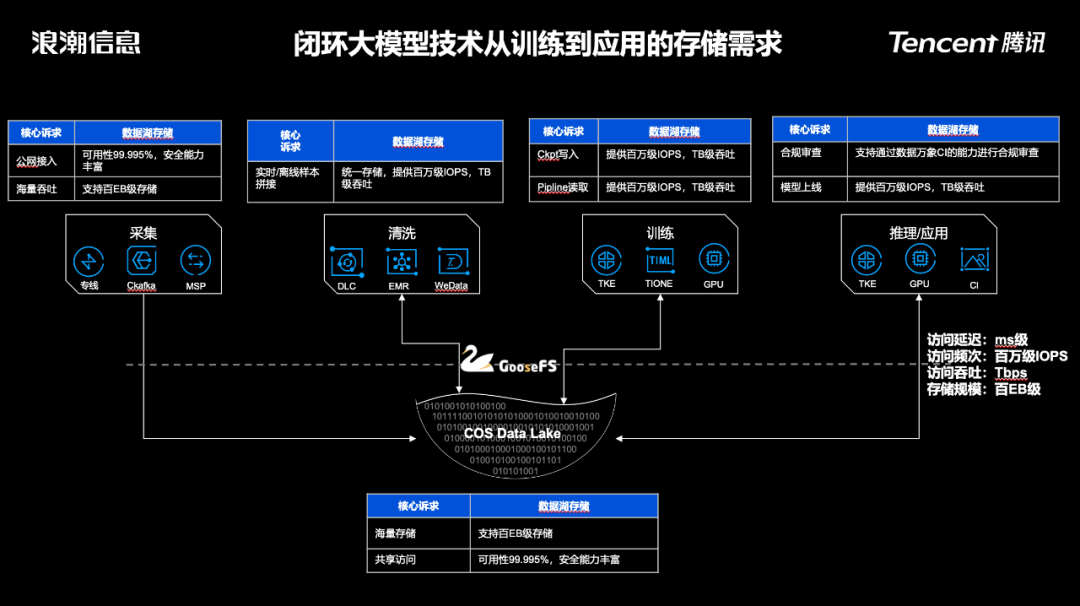
腾讯云存储团队针对大模型推出了综合性的数据湖存储解决方案,主要由对象存储、数据湖加速器GooseFS和数据万象CI等多款产品组成。
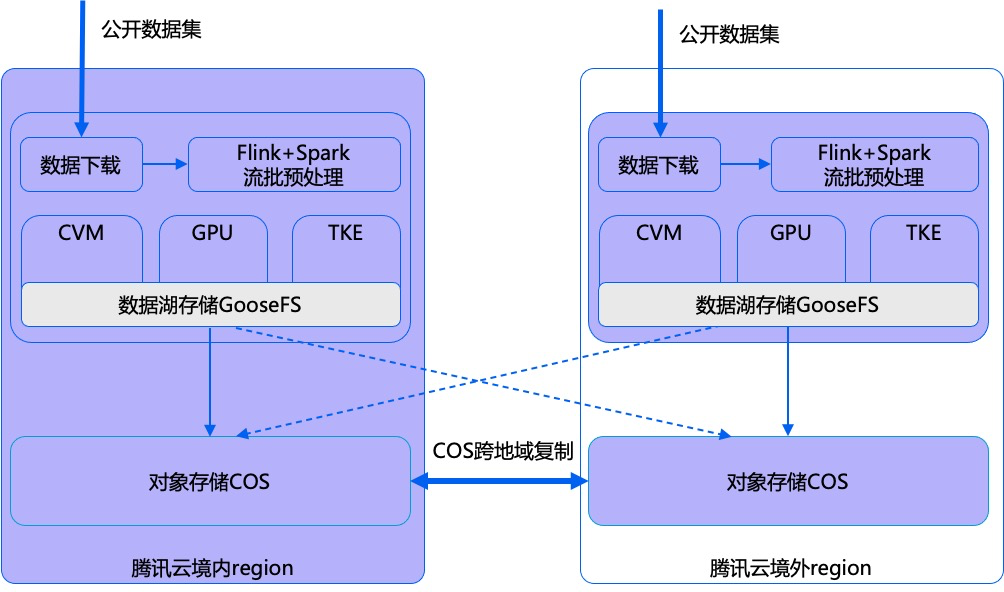
对象存储服务作为统一的数据存储池,提供了快速、便捷的公网接入、数据传输和海量存储能力。基于腾讯云自研的分布式对象存储引擎Yotta,它可支持单集群1万台服务器,单集群百EB级的存储;对象存储也提供了丰富的数据生命周期管理能力,可以很低成本地存储海量的公开数据集。
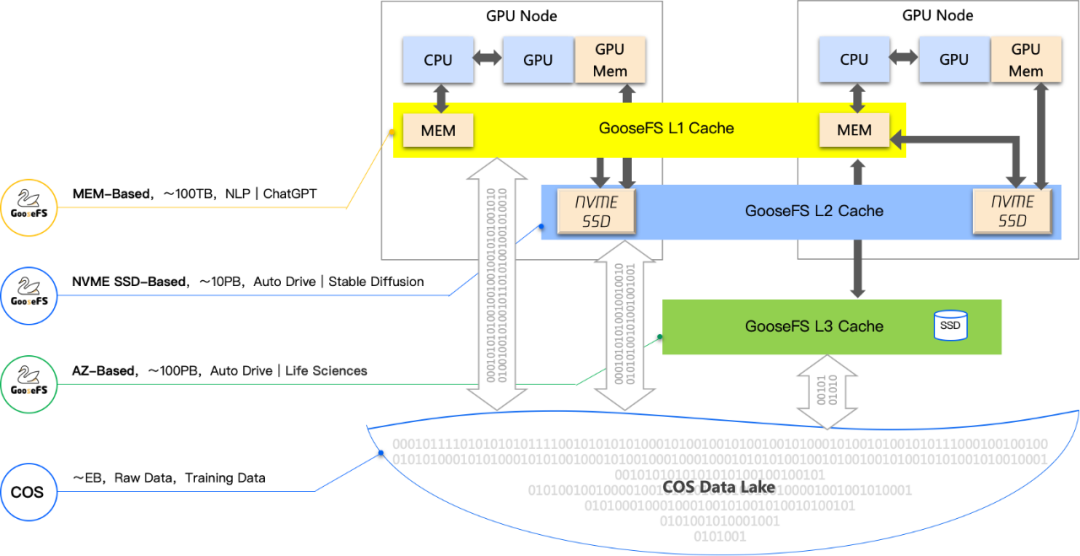
数据加速器GooseFS可以将训练数据加载到GPU内存、本地盘或者可用区全闪存储集群等不同级别的缓存中,缩短IO路径,提升数据访问性能。相比起从对象存储COS中直接读取,GooseFS可以提供亚毫秒级的数据访问延迟、百万级的IOPS和Tbps级别的吞吐能力,有效提升数据清洗和训练的效率。针对大模型的Checkpoint写入场景,我们还提供了GooseFSx这一全兼容POSIX语义的高性能存储服务,提供高速的数据写入能力。
数据万象是腾讯云提供的一站式智能平台,整合腾讯领先的AI技术,打造数据处理百宝箱,提供图片处理、媒体处理、内容审核、文件处理、AI内容识别、文档服务等全品类多媒体数据的处理能力。针对生成式AI的内容产出,数据万象能够基于腾讯内部的丰富业务实践,提供非常好的数据合规治理能力。

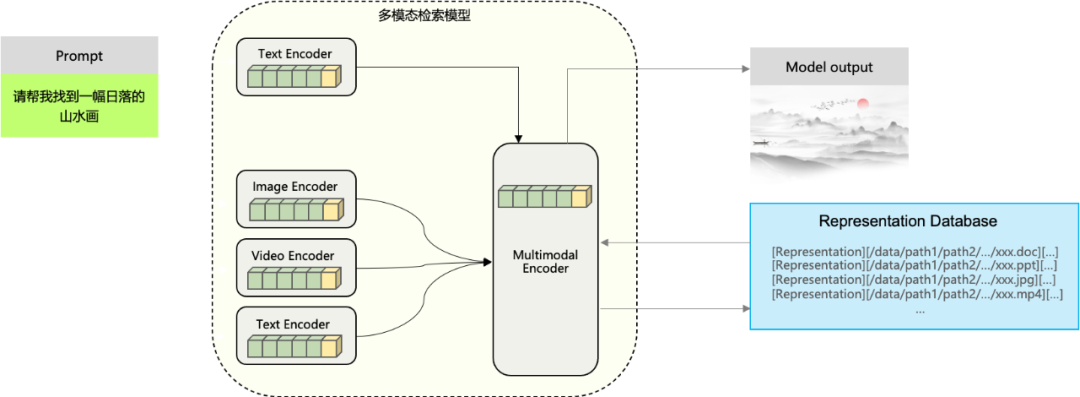
除了数据合规治理能力之外,数据万象还提供了多模态检索能力。这一能力是基于授权的商业数据和自有业务进行预处理抽取,机器翻译,模型清洗,图文配对,人工校对等处理工作,然后训练出来的一个垂直领域大模型;可以有效解决海量数据情况下智能检索的诉求。
上述的这一套完整的解决方案,腾讯云存储团队也通过TStor产品系列输出到私有化环境中,匹配私有大模型的客户诉求。TStor产品系列旨在打造“公私一体”的存储平台,将公有云存储能力延伸到私有环境中,提供可靠稳定的存储能力和数据处理能力。
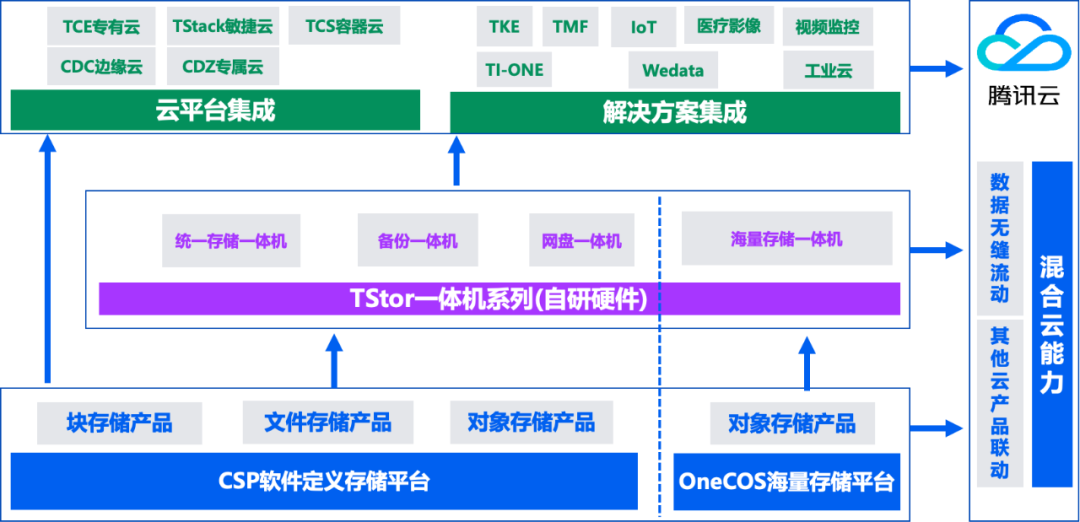
未来,基于大模型这一新技术的应用和业态将会日趋丰富。腾讯云存储将进一步提升存储的基础设施能力,丰富数据治理特性,为广大客户群体提供可靠、智能、高效的分布式存储底座。
扫描下方二维码??
获取《腾讯云对象存储解决方案手册》
