LangChain学习笔记——Model IO
原创LangChain学习笔记——Model IO
原创
前言
什么是LangChain
LangChain 是一个开发由语言模型驱动的应用程序的框架。
LanChain基于为LangChain Model Application提供一下能力而设计:
- 上下文感知能力:将语言模型连接到上下文源(prompt instructions, few shot examples, content to ground its response in, etc.
- 推理能力:依靠语言模型进行推理(关于如何根据提供的上下文进行回答、采取什么操作等)
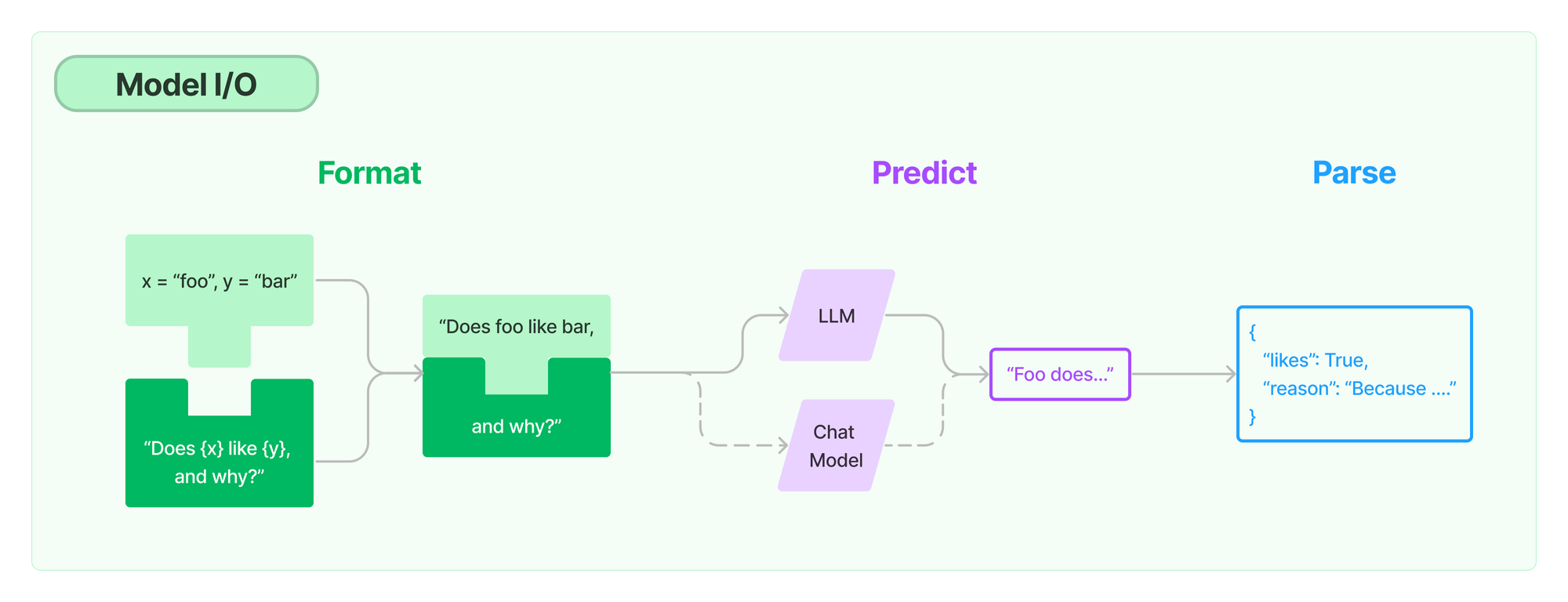
Model I/O
对于任何 Language Model Application 来说,Model都是最核心的部分。
LangChain 提供了与任何 Model 进行交互的的构建模块。以下是 LangChain 为 Model I/O 这一流程抽象的三个重要组件:
- Prompts: 模板化、动态选择和管理模型输入
- Language models: 通过通用接口调用语言模型
- Output parsers: 从模型输出中提取信息
Language Models
LangChain 中的 Language Model 模块是真正与 Language Model 进行交互的 Building Block
当前 LangChain 主要为下面两种类型的 Language Model 提供接口和集成:
- LLMs: 将文本字符串作为输入并返回文本字符串的模型(
text in?text out) - Chat models: 由语言模型支持但将聊天消息列表作为输入并返回聊天消息的模型 (
chat message in?chat message out,chat message一般有text+role组成,role通常包括s**ystem,human,ai)**
LLMs
Large Language Model(LLM)是LangChain的核心组件, 通过text in ? text out模式来使用的Language Model。
LangChain提供一个标准接口来与许多不同的LLM进行交互, 在 中可以看到当前收录的各种LLMs。 所有 LLM 都实现了Runnable 接口,该接口附带 invoke ,ainvoke,?batch,?abatch,?stream,?astreamdeng 方法的默认实现..
from langchain.llms.openai import OpenAI
llm = OpenAI()
response = llm.invoke("四大名著指的是什么?")
print(response)输出:
(LLM) ? language_model python3 00_language_model.py
四大名著指的是《西游记》、《水浒传》、《红楼梦》和《三国演义》。
(LLM) ? language_modelChat Models
Chat Model 是 LLM 的变体。Chat Model 底层仍然使用的是 LLM,但是它提供的 Interface 有了比较大的差异。
Chat Model 抽象了Chat这一场景下的使用模式,由text in ? text out模式变成了chat message in ? chat message out
LangChain目前支持的chat message类型有 AIMessage 、 HumanMessage、 SystemMessage、 FunctionMessage和 ChatMessage. 其中 ChatMessage可以接受任意角色参数。
from langchain.chat_models import ChatOpenAI
from langchain.schema.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="你一名唐诗鉴赏专家"),
HumanMessage(content="《蜀道难》"),
]
chat = ChatOpenAI()
print(chat.invoke(messages))输出:
(LLM) ? language_model python3 00_chat_modes.py
content='《蜀道难》是唐代文学家李白创作的一首抒发壮志豪情的长诗。这首诗以描写艰难险阻的蜀道为背景,表达了李白对生活困难的挑战精神和不屈的意志。\n\n诗中首先描绘了蜀道的险峻和艰难,以山峰陡峭、道路崎岖为景,展现了蜀道的险阻和危险,同时也反映了人生道路的曲折困难。诗中用“青泥何盘盘,百步九折萦岩峦”来形容蜀道的险峻,这种描写手法生动地表现了蜀道的险阻之处。\n\n接着,诗人转而描绘了自己在蜀道上的行进,以及在艰难险阻中的坚持和奋斗。诗人用“路尽灯火落,石堕天坛空”来描述路途的终点和自己的迷茫,以及用“崖峡千寻翠”来形容自己与险峰相对的壮丽景色。这种对比描写,既表现了诗人在困难中的坚持,也表达了对自然景色的赞美。\n\n最后,诗人表达了自己的豪情壮志和不屈的决心。他用“昨夜四无邻,今宵五陵六扇”来表达自己的孤独和辛苦,以及用“想当年,金戈铁马,气吞万里如虎”来表达自己的豪情壮志。这种豪情壮志的表达,体现了李白追求自由、奔放的个性和对人生的乐观态度。\n\n《蜀道难》以其雄浑豪情和独特的描写手法,展现了李白的文学才华和个人精神。它通过对自然景色和个人经历的描绘,表达了对困难的挑战和对生活的热爱,具有浓厚的时代气息和艺术魅力。'
(LLM) ? language_modelPrompts
Prompts 即提示词,在 Language Model 中,Prompts是指用户的一些列指令和输入。
Prompts 用于指导Model的响应,帮助 Language Model 理解上下文,并生成相关和连贯的输出(如回答问题、拓写句子和总结问题)。 Prompts 是决定 Language Model 输出内容的唯一输入。
语言模型的提示是用户提供的一组指令或输入,用于指导模型的响应,帮助它理解上下文并生成相关且连贯的基于语言的输出,例如回答问题、完成句子或进行对话. LangChain provides several classes and functions to help construct and work with prompts.
Langchain 提供了许多类和函数用于帮助构建和补充Prompt。 Prompt templates 和Example selectors 是其中最重要的构建模块。
- Prompt templates: 将 Model 的输入模板化、参数化
- Example selectors: 动态选择要包含在 Prompts 中的Example
Prompt Templates
Prompt Template 是预定义的一系列指令和输入参数的prompt模版,支持output instruction(输出格式指令), partial input(提前指定部分输入参数), examples(输入输出示例)等。
LangChain 的 Prompt Templates 提供了创建和使用prompt模板的工具。
下面是一个Prompt 模板的简单示例(使用了 PromptTemplate 包)
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI()
#### PromptTemplate ####
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}"
)
prompt = prompt_template.format(adjective="funny", content="chickens")
print(prompt)
print(llm.invoke(prompt))输出:
(LLM) ? prompt_template python3 00.py
Tell me a funny joke about chickens
content='Why did the chicken go to the seance?\n\nTo talk to the other side!'
(LLM) ? prompt_templatePrompts Templates 也提供了 ChatPromptTemplate 的支持
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI()
#### ChatPromptTemplate ####
chat_template = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful ai bot, your name is {name}"),
("human", "Hello, how are you doing?"),
("ai", "I am doing well, thanks!"),
("human", "{content}"),
]
)
messages = chat_template.format_messages(name="windeal", content="What is your name")
print(messages)
print(llm(messages))输出:
(LLM) ? prompt_template python3 00.py
[SystemMessage(content='You are a helpful ai bot, your name is windeal'), HumanMessage(content='Hello, how are you doing?'), AIMessage(content='I am doing well, thanks!'), HumanMessage(content='What is your name')]
content='My name is Windeal. How can I assist you today?'
(LLM) ? prompt_templateExample Selects
Prompts Templates 提供了灵活的,将部分内容参数化的构建Prompts的方式,但还不够。在一些场景中我们可能需要让 LLM完成更高质量的推理回答。这时简单的 instruction + input的prompt
已经不足以满足需求。 如果能为prompt补充一些针对具体问题的示例,通常能够获得更好的输出。
LangChain 提供了 Example Selects 这一组件,用于在有大量示例时,从中选择需要包含在 Prompt 中的示例。
Example Selects 的基类接口如下:
class BaseExampleSelector(ABC):
"""Interface for selecting examples to include in prompts."""
@abstractmethod
def select_examples(self, input_variables: Dict[str, str]) -> List[dict]:
"""Select which examples to use based on the inputs."""它需要定义的唯一方法是 select_examples 方法。该方法接受输入变量,然后返回示例列表。如何选择这些示例取决于每个具体的实现。
Output Parsers
Output Parsers 即输出解析器。
LLM 的输出通常是text, 但很多时候,我们希望它能以固定的格式输出,以便解析成结构化的数据。 LangChain 将这一能力抽象成组件 Output Parsers
LangChain 中的 Output Parsers 是帮助构建输出的类,这些类需要实现以下两个方法methods:
get_format_instructions: 该方法以字符串的方式返回有关如何格式化语言模型输出的说明parse: 一种接收字符串(假设是语言模型的响应)并将其解析为某种结构的方法。
LangChain提供了一些列预定义的类,以下是一些常用的预定义的 Output Parsers
CommaSeparatedListOutputParser: 以List(逗号分隔的列表)形式输出应答。DatetimeOutputParser: 将 LLM 输出解析为日期时间格式PydanticOutputParser: 指定任意 JSON 模式并查询 LLM 以获得符合该模式的 JSON 输出。StructuredOutputParser:返回有多个文本字段的数据结构OutputFixingParser: 包装一个额外的输出解析器,如果第一个解析器失败,它会调用另一个 LLM 来修复任何错误。RetryOutputParser: 在遇到异常时再次尝试以获得更好的响应。
使用示例:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
from typing import List
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms.openai import OpenAI
from langchain.pydantic_v1 import BaseModel, Field, validator
class Book(BaseModel):
name: str = Field(description="书名")
author: str = Field(description="作者")
# Here's another example, but with a compound typed field.
class Actor(BaseModel):
book_list: List[Book] = Field(description="书籍列表")
parser = PydanticOutputParser(pydantic_object=Actor)
prompt = PromptTemplate(
template="请介绍{subject}相关内容. \n{format_instructions}\n",
input_variables=["subject"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
llm = OpenAI()
_input = prompt.format_prompt(subject="中国四大名著")
output = llm(_input.to_string())
print(parser.parse(output))输出:
(LLM) ? output_parsers python3 json_parsers.py
book_list=[Book(name='《红楼梦》', author='曹雪芹'), Book(name='《西游记》', author='吴承恩'), Book(name='《三国演义》', author='罗贯中'), Book(name='《水浒传》', author='施耐庵')]
(LLM) ? output_parsers原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。