人工智能新生代:掌握向量数据库 与大模型深度结合
原创人工智能新生代:掌握向量数据库 与大模型深度结合
原创
【选题思路】
随着人工智能模型规模不断扩大,如何让这些“大模型”更高效地为用户服务成为重要课题。向量数据库正是在此背景下应运而生的一款数据库,它利用向量来高效地存储和检索模型数据,大大提升了查询效率
【写作提纲】
1.什么是向量数据库
2.向量数据库工作原理
3.向量数据库分类
4.对比分析
5.向量数据库在大模型中的应用
6.向量索引优化
7.应用领域
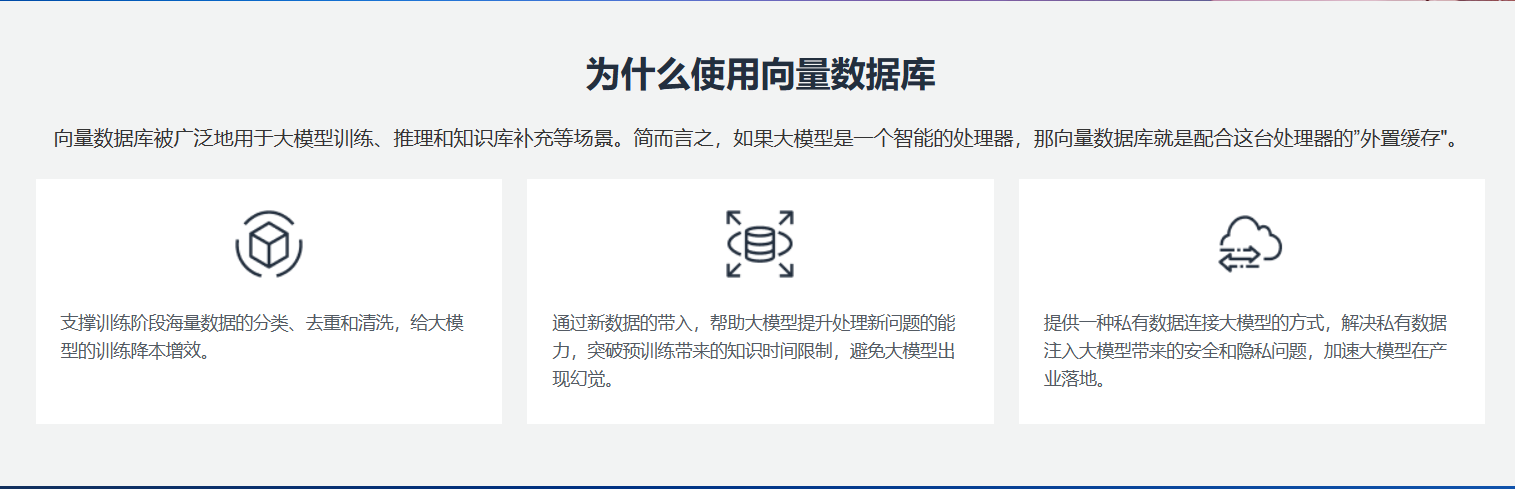
8.基于大语言模型构建行业智能应用为什么需要向量数据库?
9.未来与展望
10总结
腾讯云向量数据库(Tencent Cloud VectorDB)是一款全托管的自研企业级分布式数据库服务,单索引支持 10 亿级向量规模,可支持百万级 QPS 及毫秒级查询延迟。不仅能提高大模型回答的准确性,还可广泛应用于推荐系统、自然语言处理等领域。

什么是向量数据库

过往,承担数据组织的是传统关系型数据库。但它更适合用来应对结构化的数据。 大模型和神经网络,更多面对的是海量的非结构化数据,比如文本、音频、视频、关系等。它们有一种专门的处理方式:“向量化”。想要按这种”脑回路“组织数据,需要一个专门的数据库——向量数据库。把复杂的非结构化数据通过向量化(embedding),处理统一成多维空间里的坐标值,通过计算向量之间的相似度或距离,快速定位最相关的近似值。

向量数据库(Vector Database)是一类新的非关系型数据库,它使用数学上的线性代数技术来存储和处理结构化与非结构化数据。
向量数据库会将数据对象映射为固定维度的向量,并将这些向量以高效的密集格式存储在内存或硬盘上。与传统关系数据库不同,它不需要事先定义固定的数据库架构,可以很方便地添加新字段。
向量数据库工作原理

简单来说,向量数据库的工作流程如下:
数据预处理阶段,将非结构化数据转换为数值向量表示;
向量表示阶段,将处理后的向量表示固定化为固定维度向量;
向量存储阶段,将向量表示采用高效的格式(如TF-IDF、LSH等)进行存储管理;
向量检索阶段,利用向量之间的距离计算(如cosine相似度)快速定位与查询向量相似的结果向量。
以TF-IDF为例,它通过统计每个词在单个文档和整个语料库中的出现频率,从而映射文档为稠密的向量表示,并利用余弦相似度进行文档匹配。
向量数据库分类

根据存储格式和检索算法的不同,主流向量数据库主要包括:
倒排索引向量数据库:利用倒排索引表将词转换为文档ID列表,类似Elasticsearch。
TF-IDF向量数据库:使用TF-IDF值将文档表示为稠密向量,类似Anthropic Vector Database。
射线树向量数据库:使用射线树结构来提高高维向量距离查询效率,类似Faiss。
本地感知哈希向量数据库:使用LSH算法进行近似最近邻查询,类似Nephrite。
代表作:milvus
Milvus 是一个开源的向量数据库,旨在支持嵌入相似性搜索和 AI 应用程序。Milvus 使非结构化数据搜索更易于访问,无论部署环境如何,都能提供一致的用户体验。
Milvus 2.0 是一个云原生向量数据库,存储和计算在设计上是分开的。这个 Milvus 的重构版本中的所有组件都是无状态的,以增强弹性和灵活性

对比分析

传统的话比如我们的NoSQL和SQL。
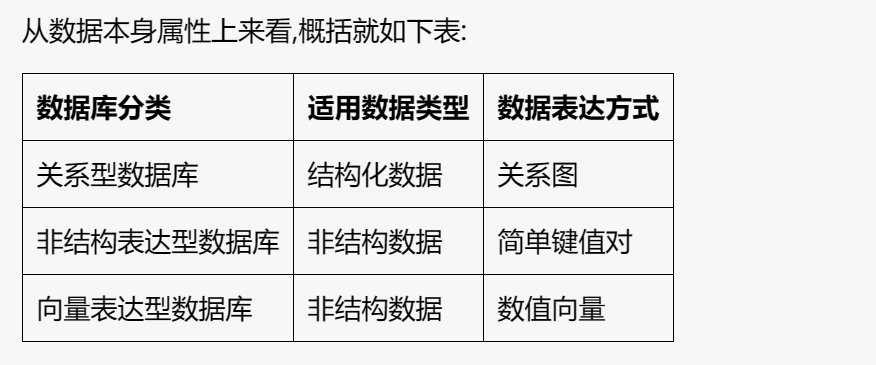
根据数据表达能力分类数据库
关系表达型数据库:以表格的关系图形表达结构数据,代表为关系型数据库。
非结构表达型数据库:采用键值、文档等简单方式直接表达非结构数据,代表为键值数据库和文档数据库。
向量表达型数据库:采用线性代数技术,将非结构数据以定长数字向量的形式表达,代表为向量数据库。
主要区别有几个大的方向
数据建模方式
传统数据库通常使用表格和关系模型进行数据建模,将数据存储为结构化的行和列。而向量数据库则将#数据表示为向量
数据查询方式
传统数据库使用SQL语言进行查询,通过指定条件和关系来获取所需的数据。而向量数据库则通过计算向量之间的相似度来进行查询
数据处理能力

向量数据库在处理高维向量和大规模数据时具有出色的性能和效率。它采用高度优化的向量索引和查询算法,能够在海量数据中快速定位和检索相似的向量。而传统数据库在处理复杂的数据关系和跨多个表的查询时往往效率较低。
支持向量的SQL 数据库
腾讯的PostgreSQL, Clickhouse
与关系数据库相比,向量数据库的优势在于:
不需要事先定义数据结构,更易扩展;
基于向量距离计算,支持模糊匹配而非精确查询;
以压缩密集格式高效存储与检索大量向量数据。
而与非结构化文档数据库相比:
以数值表示替代病文档,支持更丰富的查询操作;
底层算法优化,检索效率更高;
融合深度学习能力,支持动态学习特征.
在大模型应用场景下,向量数据库正体现出更突出的优势。下一部分我们将介绍其在此方面的典型应用案例。

向量数据库在大模型中的应用

思源推理服务:利用向量数据库管理模型的知识图谱,支持更快的问答与断言检索。
Anthropic助手:使用向量数据库提升自然语言对话模型产生更符合上下文语义的回答。
机器翻译服务:利用向量数据库加速语义知识图谱匹配,为机器翻译提供背景信息支持。
情感分析系统:结合向量数据库管理语料情感知识,有效识别用户需求情感倾向。
医疗决策支持:利用向量数据库管理医学知识与病例,助力复杂临床问题诊断。

向量数据库的应用

人脸识别
向量数据库可以存储大量的人脸向量数据,并通过向量索引技术实现快速的人脸识别和比对。
图像搜索
向量数据库可以存储大量的图像向量数据,并通过向量索引技术实现快速的图像搜索和相似度匹配。
音频识别
向量数据库可以存储大量的音频向量数据,并通过向量索引技术实现快速的音频识别和匹配。
自然语言处理
向量数据库可以存储大量的文本向量数据,并通过向量索引技术实现快速的文本搜索和相似度匹配。
推荐系统
向量数据库可以存储大量的用户向量和物品向量数据,并通过向量索引技术实现快速的推荐和相似度匹配。
数据挖掘
向量数据库可以存储大量的向量数据,并通过向量索引技术实现快速的数据挖掘和分析。

搜索引擎优化,倒排表存储增量TF-IDF向量提升相关度计算。
向量索引优化

向量索引是提升搜索效率的关键。常见的优化算法包括:
NMSLIB: 支持KMeans等结构优化加速最近邻查询
HNSW:采用非平衡多级索引降低查询复杂度
FAISS:利用优化的技术如Product Quantization实现实时Similarity搜索
ANNOY:通过路树索引近邻搜索提供实时推荐
信息检索、文档聚类等通过向量表示实现语义级匹配。
域识别、命名实体提取通过向量表征增强学习进行分类。
推荐系统构建用户画像,通过向量相似度实现个性化推荐。
生物信息学通过向量化序列/结构进行快速比对分析

通过向量数据库有效管理,这些大模型服务可实现更高效的知识检索,从而为用户提供 personalized 的服务体验。
基于大语言模型构建行业智能应用为什么需要向量数据库?
向量数据库可以高效管理行业知识,为模型提供结构化查询接口。大语言模型不再依赖内部知识,实现真正外接智能。
将结构化非结构数据统一表示为向量,为模型提供统一数据接口。有利于大模型学习行业专业术语及相关模式。
支持基于距离的近似匹配查询,满足模型对语义相似知识的实时访问需求。
通过学习优化接口,模型可以联合向量数据库进行在线升级,迅速消化新产生的业务知识。
以医疗问诊机器人为例,若利用向量数据库管理医学知识,包括:
症状-疾病对应向量表
疾病-检查项目对应向量表
疾病-处方对应向量表
则大语言模型在为患者解答时,可以基于用户描述的症状进行以下高效操作:
在症状表中利用余弦相似度查找可能对应的疾病
查找这些疾病在其他表中的相关信息如检查项与处方,选择可能性高的给出建议
如果建议不恰当,利用知识图谱进行修正后重新呈现
同时记录交互过程进行模型在线学习,不断优化处理能力
这样,基于向量数据库管理的行业知识图谱,可以有效帮助大语言模型实现从“通用”到“专业”的过渡,并实现更高效智能服务。这就是向量数据库在构建行业智能上不可或缺的角色所在。
留意语义检索是否不断成为各行业“人工智能最佳实践”。未来,包括知识图谱构建与优化在内,向量数据库技术的应用空间将更广阔。它将助力大语言模型变成行业智能引擎的一个重要组成部分。

未来,随着人工智能的发展,大模型和向量数据库必将进行更深层次的融合,共同打造出智能知识处理与服务体系。这将进一步推动人工智能走向工业化应用。
参考链接:
https://github.com/milvus-io/milvus
https://aws.amazon.com/cn/campaigns/what-is-a-vector-database/
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。