手把手教你用 Python 去除图片和 PDF 水印
原创手把手教你用 Python 去除图片和 PDF 水印
原创
我们在平时的学习,工作和写作中,有时会遇到一些需要将图片的水印去除的场景。
虽然网络上有很多免费或者付费的软件可以帮助我们去除图片水印,但作为程序员,我们完全可以自己动手编程实现。
原理分析
假设我们需要将下面这张图片里的水印,使用 Python 代码去除。

图像是由像素组成的,每个像素代表图像中的一个小点,具有特定的颜色值。这些颜色值通常由红(R)、绿(G)、蓝(B)三个通道组成,有时还包括透明度通道(Alpha)。图像处理就是通过操作这些像素的颜色值来实现对图像的各种变换和效果。
我们首先使用微信聊天窗口里的快捷键 Alt+A 查看上图,发现白色背景色的 RGB 为 (255,255,255):

黑色字体的 RGB 值为 (148,148,148):

水印区域的 RGB 值为 (221,221,221):

通过仔细观察,我们发现,水印 RGB 之和与白色背景色的 RGB 之和比较接近,而与黑色字体的 RGB 之和有较大差异。
那么图片区水印的思路不就有了吗?遍历图片每一个像素,提取出其 RGB 值,将 RGB 三位值之和,与一个阈值进行比较,如果大于这个阈值,说明该像素对应的区域是水印,于是将这个像素的 RGB 值设置为白色背景色,也就是 (255,255,255) 即可。
那么这个阈值应该取多少合适呢?显然,黑色字体的 RGB 和(1483=444)必须小于这个阈值,而白色背景色 RGB 之和(2553=765)必须大于这个阈值。所以我们可以把阈值定为 600,尝试一下效果如何。
下面开始编写 Python 代码。
笔者开发了这段 Python 代码:
from itertools import product
from PIL import Image
img = Image.open('input.png')
width, height = img.size
for pos in product(range(width), range(height)):
if sum(img.getpixel(pos)[:3]) > 600:
img.putpixel(pos, (255,255,255))
img.save('output.png')上述代码执行之后,在当前文件夹下,自动生成了一个去除水印之后的 output.png 文件,内容如下:
可以看到,水印已经成功被移除了。
详细介绍代码的含义:
from itertools import product: 这一行导入了 Pythonitertools模块中的product函数。product函数用于生成多个可迭代对象的笛卡尔积,这些笛卡尔积后续用于遍历图片的每个像素点的坐标。from PIL import Image: 这一行导入了PIL库中的Image模块,用于处理图像。Image 模块提供了 getpixel 和 putpixel 方法,可以读取和设置像素值。img = Image.open('input.png'): 打开名为'input.png'的图片文件,并将其赋值给变量img。这个变量作为句柄,后续用于操作和处理图片。width, height = img.size: 获取图片的宽度和高度,并分别赋值给变量width和height。for pos in product(range(width), range(height)):: 使用product函数遍历图片的每个像素点的坐标。这里pos表示当前像素点的坐标,是一个包含两个元素的元组。if sum(img.getpixel(pos)[:3]) > 600:: 获取当前像素点的RGB值,使用getpixel方法,然后取前三个元素(即R、G、B通道),将它们相加。如果总和大于阈值600,说明该像素被判定为水印。img.putpixel(pos, (255, 255, 255)): 将当前像素点的颜色设置为白色(255, 255, 255),这就是去除水印的操作。img.save('output.png'): 将修改后的图片保存为'output.png'。
PDF 文件中的水印去除
有了图片去水印的基础之后,去除 PDF 文件的水印也就不再无从下手了。写作这篇文章的时候,我回忆起了高中数学老师对我们的谆谆教诲:高中数学解题技巧,就是一个不断的将陌生问题转化成熟悉问题的过程。
我们首先将 PDF 文件的内容,转换成图片,然后对图片进行去水印操作,这是我们熟悉的内容。将去除水印后的图片,重新保存成 PDF 文件即可。
我们用来测试的包含水印的 PDF 文件如下:
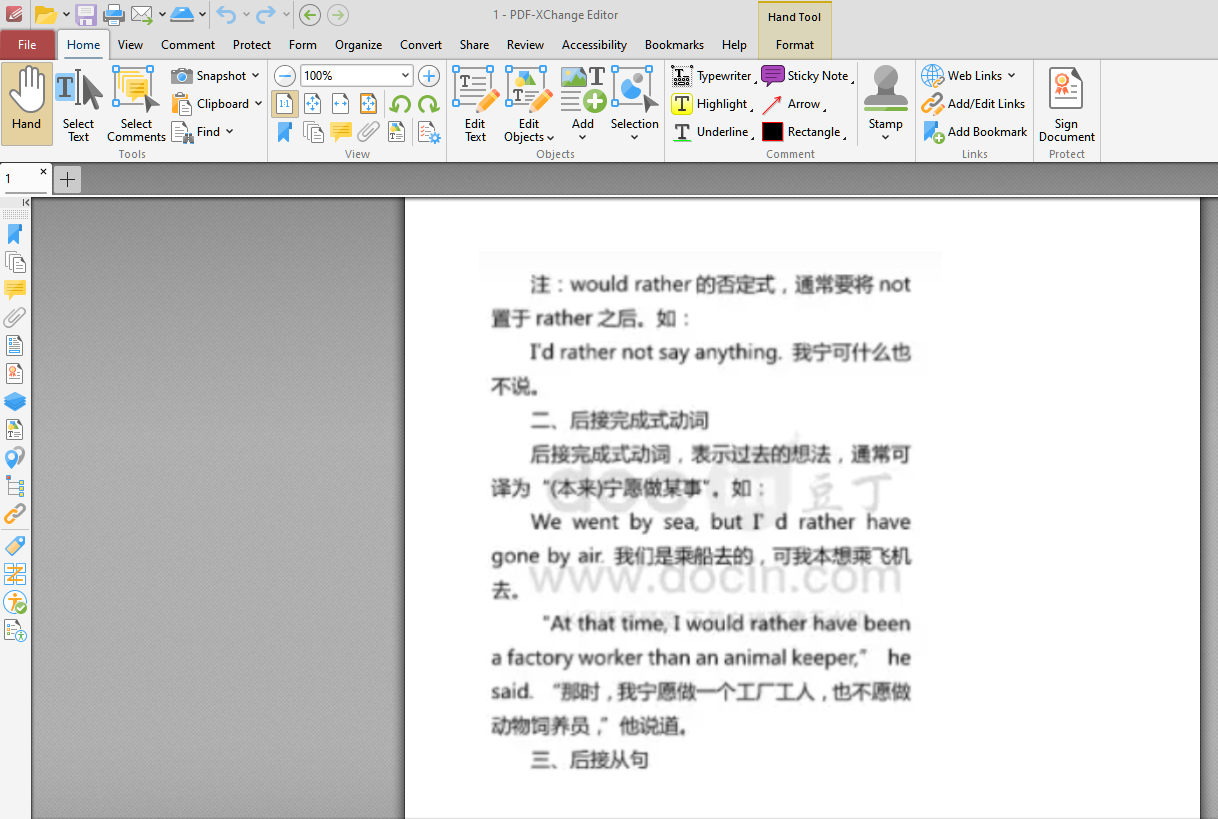
代码如下,将其另存为 2.py:
from itertools import product
import fitz
pdf = fitz.open("1.pdf");
page = pdf[0];
pixmap = page.get_pixmap()
for pos in product(range(pixmap.width), range(pixmap.height)):
rgb = pixmap.pixel(pos[0], pos[1])
if(sum(rgb) >= 600):
pixmap.set_pixel(pos[0], pos[1], (255, 255, 255))
pixmap.pil_save("2.png")
print("水印去除完成")这里我们使用了 PyMuPDF 库,所以需要使用 pip install PyMuPDF 首先安装。
使用命令行 python 2.py 执行之后,会在当前文件夹下生成一个去除完水印的图片文件 2.png
.
这段代码的功能是打开名为“1.pdf”的PDF文件,获取其第一页的位图表示,然后遍历每个像素点,检查其是否代表水印。如果是,则将该像素点的颜色设置为白色。最后,将修改后的位图保存为PNG格式的图像文件“2.png”,并输出提示信息“水印去除完成”。
有了 2.png 文件之后,我们再使用 Python PyMuPDF 的 convert_to_pdf 方法,将 png 文件重新转换成 PDF 文件即可。
代码如下:
import fitz
pdf = fitz.open()
imgdoc = fitz.open("2.png")
pdfbytes = imgdoc.conver_to_pdf()
imgpdf = fitz.open("pdf", pdfbytes)
pdf.insert_pdf(imgpdf)
pdf.save("3.pdf")
pdf.close()执行上述 Python 代码之后,在当前文件夹下生成了一个名为 3.pdf 的文件,打开如下图所示,可见水印已经被删除了:
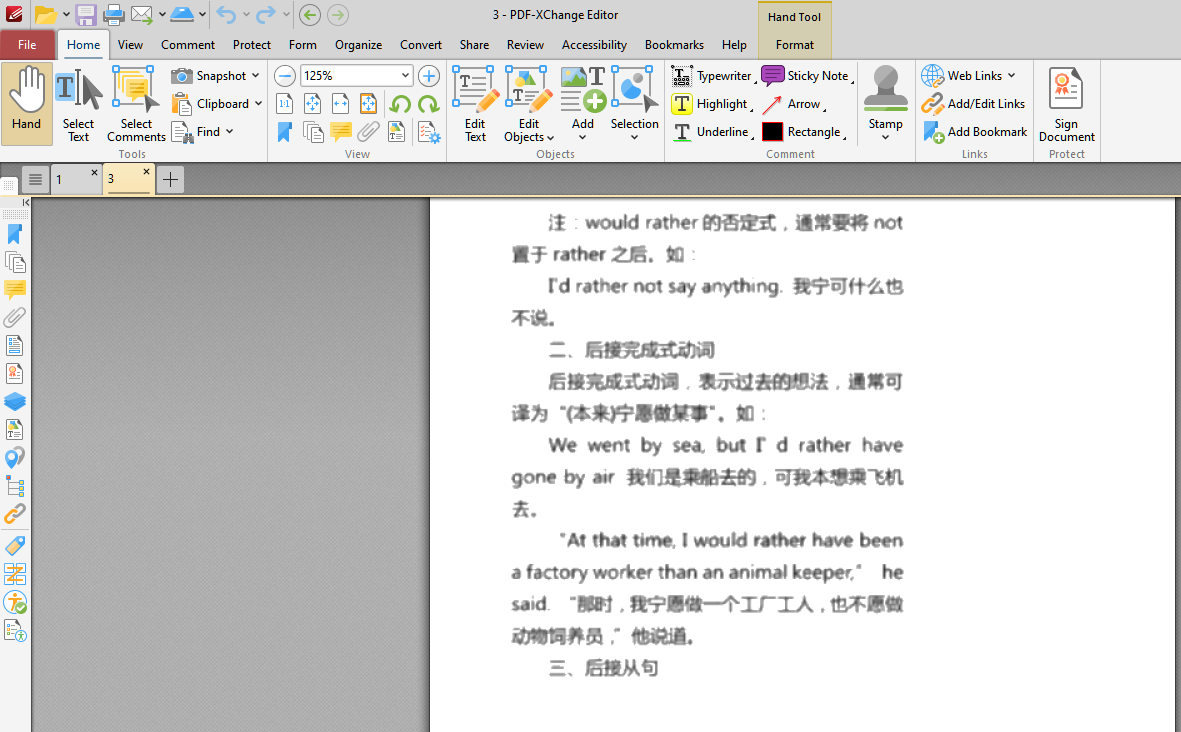
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。