我掌握的新兴技术:利用腾讯混元大模型做简历自动优化系统
原创我掌握的新兴技术:利用腾讯混元大模型做简历自动优化系统
原创
创作背景:
本人做过多年技术面试官,主要负责领域为python,测试开发,业务开发等。每次对面试失败的同学,我都会耐心的给他简历讲一讲怎么优化怎么改,以便其在其他公司投递时候提高通过率,也不算白来我司面一次。
于是渐渐对简历优化上了瘾,后利用业余时间,专门帮助其他同学或粉丝进行简历优化工作,又过了很久,积攒下来不少优化经验,而待优化的简历其实大多数都是相同的毛病和问题,优化的手段也有一定的规律可循。最终,我决定做一套简历自动优化系统,这样一来可以方便大家不用再排队等待优化,二来也可以锻炼下自己的技术,没准这是一个可发展有前景的商业领域。
但一个难题挡住了我,那就是面对五花八门的简历,我一直没有办法利用代码进行自动化很好的解析和总结简历原文,这也让我的很多优化经验毫无用武之地。直到看到了【腾讯的AI模型-混元】,我知道,东风来了。
本文涵盖多个新颖设计和方案,具备一定的商业价值哦~
混元大模型:
地址:https://hunyuan.tencent.com/
混元大模型是由腾讯研发的大语言模型,具备强大的中文创作能力,复杂语境下的逻辑推理能力,以及可靠的任务执行能力。
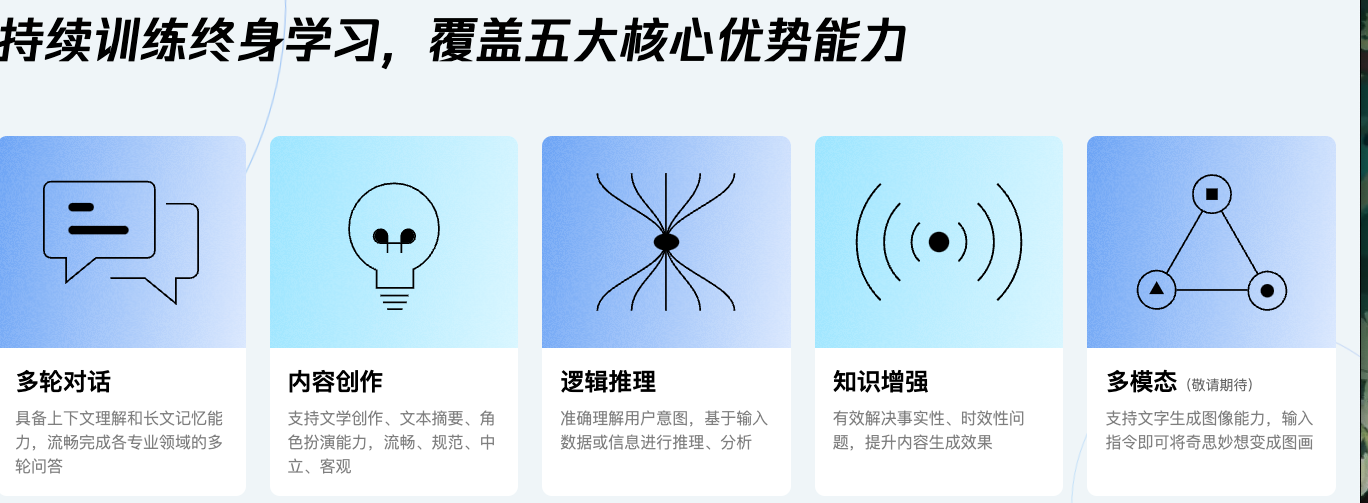
腾讯混元大模型由腾讯全链路自研的通用大语言模型,拥有超千亿参数规模,预训练语料超2万亿tokens,具有强大的中文理解与创作能力、逻辑推理能力,以及可靠的任务执行能力。
并且有高度集成化的混元助手【灵感】和已经开放的多个小工具:
小工具【灵感】地址:https://hunyuan.tencent.com/bot/inspiration

不过,我要的是更加底层,更加核心的混元对外可调用接口。
经过我一顿企业注册、实名认证等操作后,终于拿到了可调用的接口。不得不说,安全性上做的还是非常可靠的。
【申请链接】:https://console.cloud.tencent.com/hunyuan/senior-stats
这里就不细说过程了,混元的文档写的很清楚了,本文主要是在我拿到这个AI接口后,对简历自动优化系统的实际落地技术讲解。
简历优化系统
架构上选用了:B/S架构,python3 + django + vue + elmentUI的组合。
其中也运用了大量的优化算法,优化算法的入参基本都是混元模型进行一系列操作后给我的。
目前已经上了第一期,第二期还未优化完。
效果如图:

如上图所示,顶部可以设置优化意向,下列的具体优化算法会根据你所选的优化意向来决定结果,
下面有三列,左侧是原文粘贴,中间是生成的优化建议,右侧则是根据建议改正后的简历文案。
部分使用效果如下:


从这个系统设计到最终落地的过程中,我对人工智能的理解和使用上总结了很多,还有混元作为底层数据支持时的各种技巧。可以说,这是一次比较成功的实验,相信之后的日子里,随着我的算法不断更新和前端优化,还有混元的不断能力提升,这个简历优化系统会非常非常有发展前景哦~
(PS:前不久还有个小型技术公司的cto来找我谈合作,说看到了我对人工智能的理解和应用能力,想挖我过去.... 是真事哦~ )
开发过程:
因为流程图的东西太多看不清,就由我一点点说吧。大家感受一下复杂程度就可以了。
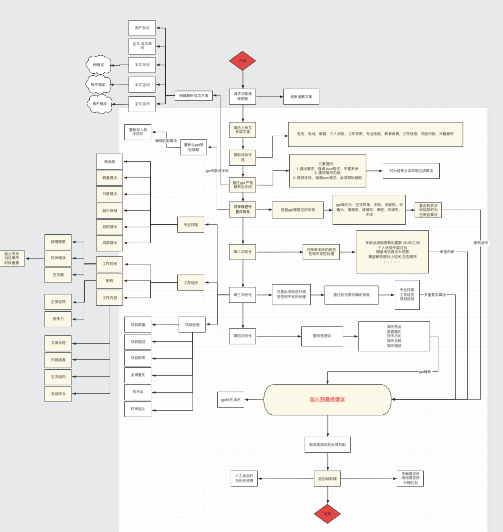
首先,平台架构上,共分为三大部分。
1. AI解析部分:包括用混元进行简历原文切割,原文解析,原文总结,结果打分,结果补充,提取关键数据,数据清洗,数据格式化等工作。
2. 优化算法部分:包括个人信息优化,专业技能优化,工作经历优化,项目经验优化,整体性优化等具体优化点。
3. 结果整合展示部分:生成优化结果,拼装成新简历,页面展示,新简历导出/下载等基础功能。
然后,是具体的每个部分的实现设计。
AI解析部分:
对简历原文的解析工作,包含了两个大层:对问题辅助层,对结果优化层。
每个大层包含了若干小层。
1. 对问题辅助层:
包含了:原文分解层,要求精简层,要求忠诚层,要求格式层,问题整合层。
2. 对结果优化层:
包含了:比对验证层,结果mock层,自然语境层,收集标注层,业务矫正层。
每个具体的层的存在意义和实现手段如下:
- 原文分解层。
意义:有效降低因简历原文过长导致解析准度下降的情况,降低前后文的重复词干扰和AI节点过长等问题。
实现手段:进行人工拆解和自动拆解俩个角度,用户可自行对简历分块粘贴,后台系统会根据简历关键标题字体和关键字俩个角度进行拆分。
- 要求精简层
意义:有效减少AI模型的回复文案长度,减少关键信息之外的无用文案,减少对结果精准提取的干扰,还有省tokens。
实现手段:对各种问题进行后缀补充,加上强制要求精简的命令口吻。

- 要求忠诚层
意义:避免出现AI模型进行联想然后回答出不存在的虚假回答。
实现手段:对各种问题进行后缀补充,加上强制要求不能联想,忠诚的只从原文提取答案的要求。
- 要求格式层
意义:避免结果格式随机,导致下游提取失败报错。
实现手段:对各种问题进行后缀补充,加上强制要求用json格式来回答,并且提前设置好json格式的字段名称。

- 问题整合层
意义:打破传统的AI模型在同一个session对话中必须一问一答的方式,在简历优化系统中,对多个连续的同类问题进行合并。
实现手段:所有的问题可随意的发出,并且都会先集合到本层的队列类,然后由本层进行整合后再对AI模型进行提问,保证了一问一答。
- 比对验证层
意义:对AI模型回答的结果进行比对验证,保证结果的正确性。
实现手段:主要从三个维度进行检查:
1. 找出 实际结果中缺少的 要求字段。
2. 找出 实际结果中额外的 非要求字段。
3. 验证 实际结果中每个字段是否真实,需要从原文中搜索并进行相似度得分来判断。
如果检查失败则调用对应的【对问题辅助层】的具体小层进行重新提问。
- 结果mock层
意义:提前收集结果,有效降低调试和开发阶段对模型AI接口的调用次数,因新返回值报错等问题,大量减少接口请求时间,提高开发效率,还节省tokens。
实现手段:和传统的接口mock不同,模型AI接口的返回值具备天然的不确定性,所以不能以某一次返回结果作为mock值,否则以此进行开发的代码不能兼容真正上线后的其他结果,于是,需要专门做个结果mock层来处理,前期对问题结果进行收集去重,后续用顺序调用的方式来测试代码。
- 自然语境层
意义:让生成的优化建议等结果变成更符合人类用户阅读的习惯和流畅度。
实现手段:简历优化的建议结果中,通常都是数据和表达式等,不利于用户读取,于是让AI模型进行重写成自然语言。

- 收集标注层
意义:对所有输入的简历和最终的建议进行结果收集,并且收集用户的打分和反馈,以便后续调整。
实现手段:前端设计用户反馈打分组件,后端新增数据表记录。
- 业务矫正层
意义:为了保证简历优化系统的成长,需要模型不断的保持学习,但因为无法干预公共大模型,又没有部署离线的本地小模型硬件,所以才设计出了一套新颖的业务矫正层方案,对大模型的结果不断的进行优化和矫正,让这个矫正力度和精准度不断提高的技术。
实现手段:做了一个四维度的数据矩阵,根据用户标注结果和AI模型的结果,修改这个数据矩阵,进行结果干预和修改,不断加强和扩充这个矩阵的数据量。比如针对1年以下工作经验的简历,大模型的结果总是要求很高,之后就通过这个业务矫正层的数据矩阵,来适当降低简历要求。
优化算法部分
优化算法作为第二个核心部分,主要覆盖的就是我多年优化简历积攒下来的具体经验。
这些经验转化为自动化代码的过程有俩种:
1. 训练业务矫正层 (上文已经提到了) 2. 对格式化数据的具体算法处理 (格式化数据来自于混元大模型)
优化算法一共分为五层:
1. 不合理层:对模型解析出来的不合理字段进行建议
包括【空字符串、未知、未提供、未确认、请提供、请填写、保密、未填写、不详、面议】等,这些字段可能是简历本身就这么写的,因为会影响到最终优化结果,所以要单独拿出来警示用户一个免责声明:仍然不写,优化结果可能不准确。
2. 优化意向层:根据用户页面填写的优化意向,对某些优化点进行标准调整。
包括各种技术和领域的数量,深度,成就,工作内容,数据量化等进行建议标准调整。
3. 简单字段层:对简单的基础优化点进行建议
包括个人信息、年龄、工龄、个人优势、期望薪资、所在地区、联系方式、邮箱、教育背景,兴趣爱好等进行建议。每种信息都有其长短,内容完整,描述,数值等的具体建议。比如你写的薪资是10-25k,算法就会建议你缩小区间,过大的区间会让hr产生你不自信,对自己定位不清晰,实力水分大等负面印象。比如你写的兴趣爱好经过AI模型的判断打分后和当前期望职业不匹配,甚至产生负面影响,则会进行警告和建议。
4. 复杂字段层:对复杂的优化点进行建议
包括专业技能(每个技能的熟练度、数量建议、行数建议、缺失领域、名称建议、成就建议),工作经历(工作时间、跳槽频繁、时间错误、远近顺序、起止写反、时段重叠、空白期、职称头衔、竞争力、工作内容、文案长短、内容涵盖、主次结构、数据量化、总结成长),项目经验(项目数量、项目描述、项目职责、业绩量化、技术点、时间起止)等优化点。这里的算法非常密集,共写了将近700行纯算法.... 这也是真正的技术壁垒了,需要的小伙伴可以留言获取一些。

5. 整体性优化层:如果说上列优化层都是对单独信息点进行优化,那么本层就是纵观全局,找出整篇简历的问题。
包括简历的篇幅、亮点、数据量化的多少、技术占比、简历错误等等,这里就是利用AI模型+算法,进行共同的建议部分。比如说整篇简历篇幅过长,达到了3页以上,其中某几个项目经验写的太过啰嗦。哪段工作职责和其他段工作职责写的太过一样像复制粘贴的。简历没有什么亮点,所有的内容都和其他粉丝的简历如出一辙,也没看到诸如具体作品、得奖、专利之类的内容。学历和工作背景也不出众。这种时候,系统不但会直接表名简历的这种弱竞争力的原因,还会贴心的靠AI模型生成一些符合简历的亮点或者作品用做参考(PS: 当然我是不赞成直接在简历中写假的东西的!)
结果整合展示部分
最后,就来到了收尾工作,也是我的弱项,碍于本人审美水准不高,所以前端样式设计上总是有点吃亏。本部分就是为日后给交互层做支撑所创建。
本层包括这些内容:生成优化结果,拼装成新简历,页面展示,新简历导出/下载等基础功能。
之前所有算法产生的优化建议,我都会生成两份。
其中一份利用混元AI模型变成人类用户能看到的自然语言,也就是上文提到的自然语境层。
另一份则是提交给混元AI模型,加上之前的简历原文部分内容,让AI根据建议进行重写。
最后,把建议和重写的结果,同时存放到数据库的同时返回给Vue前端,展示到用户的页面上。用户既可以根据建议自行修改简历,也可以直接导出或下载 AI模型生成的新简历,改一改就能用了!
好,这里就是目前第一版的简历优化平台~ 欢迎小伙伴提出改进建议,第二版正在紧锣密鼓的的研发中了~
最后,感谢腾讯云~ 我简历优化平台就部署在腾讯云服务器哦~ 现在租赁云服务器,各种优惠!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。