什么?你还没有自己的ChatGPT?搭建ChatGPT使用DDD领域思想对接公众号交互
原创什么?你还没有自己的ChatGPT?搭建ChatGPT使用DDD领域思想对接公众号交互
原创
前言
《什么?你还没有自己的ChatGPT?》就在昨天 ChatGPT 爆出严重 BUG team 模式可以无限邀请 3.5 的用户来玩 4.0 的功能那么我也是第一时间上车啦,然后我发在了我的开源群里面并且喊一群大佬白嫖,结果他们说你的这个 ChatGPT 咋搭建的喊我发布一篇教程文章那么它来了!!!
在ChatGPT的历程中,我们目睹了人工智能的惊人发展,从初步的对话模型到如今的ChatGPT,这一演变不仅仅是技术上的进步,更是人类思维的辉煌体现。随着时间的推移,ChatGPT逐渐成为人们生活中不可或缺的一部分,为交流、学习和创新提供了无限可能。
有用于绘画的、角色扮演的、代码生成器的、代码解析等一系列问题 ChatGPT 都可以帮助到我们,虽然官方可以免费玩 ChatGPT3.5 模型但是对于开发者来说想拥有自己的则就需要 API,那么 API 官方是需要钱的所以本篇文章就来啦! 搭建一个自己的 ChatGPT 白嫖 3.5 的 API KEY,首先致敬一下 ‘秦始皇’ 你不认识没事待会就认识了,本篇文章将从零搭建我们的 ChatGPT 并且对接个人公众号进行一对一回复是不是很棒? 我今天早上从零开始搭建搞了我两个多小时可想而知本篇文章花费了多少时间如果喜欢的、对您帮助了的麻烦点个赞加收藏哟~
原本是要使用混元大模型来接入的但是 API 需要企业申请,虽然我有你们可能没有则就没有进行操作了,但是我会在结尾继续扩展混元的代码实现对接,冲冲冲快来学习吧,搭建你自己的对话软件! 本篇三万多字完完整整搭建属于你自己的GPT

本篇文章涉及到搭建 ChatGPT 以及后面根据 Proxy Api 搭建服务进行对接公众号并且使用 DDD 领域驱动思想搭建 SpringBoot 项目、使用会话工厂基于最好用的 okHttp 搭建 OpenAI 请求详细介绍看下图

在准备开始先贴一张效果图,如下介入公众号实现对话
准备
首先我们的准备工作
- 服务器一台 需要搭建 docker、nginx、jdk
- 一个 github 的账号要满 180 天以上的
- 会一点 Java 开发的因为要写对接公众号文本回复的功能
- 一个个人的订阅号(公众号) 没有的直接注册就完事,so easy to happy!
- 最重要的OpenAI账号,没有的直接注册现在注册犹如喝水一样简单
前往购买腾讯云服务器年末回馈聚划算: https://curl.qcloud.com/Ukg0wxww

服务器配置
这才一百块有需要的闭着眼睛冲 OK?

配置选择 centOs 7.6

其余的就是搭建部署应用的环境了我就不详细介绍,当做你们是有 linux 基础的大佬了
搭建部署应用环境
下面的安装方式都是来至于 JPOM 稳稳当当
安装全套环境
此脚本会自动检查当前环境中是否存在:jdk、mvn、node,如果不存在则执行安装
curl -fsSL https://jpom.top/docs/install.sh | bash -s Server jdk+mvn+node+default安装Docker
可以使用一步步来,也可以使用一件安装(推荐一步步来一键安装我没操作过)
# 下载并安装Docker所需要的软件包
sudo yum install -y yum-utils
# 添加Docker官方的yum仓库地址
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# 设置阿里云镜像的yum仓库地址
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 更新yum缓存
sudo yum makecache fast
# 安装新版Docker
sudo yum install -y docker-ce docker-ce-cli containerd.io一条命令安装docker
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun在线安装 JDK 1.8
https://jpom.top/pages/feb7c1/#%E5%89%8D%E8%A8%80
默认路径:/usr/java/xxxx
版本:1.8
来源:https://mirrors.tuna.tsinghua.edu.cn/Adoptium/
curl -fsSL https://jpom.top/docs/install.sh | bash -s Server jdk+only-module+default在线安装 Nginx
#gcc安装,nginx源码编译需要
yum install -y gcc-c++
#PCRE pcre-devel 安装,nginx 的 http 模块使用 pcre 来解析正则表达式
yum install -y pcre pcre-devel
#zlib安装,nginx 使用zlib对http包的内容进行gzip
yum install -y zlib zlib-devel
#OpenSSL 安装,强大的安全套接字层密码库,nginx 不仅支持 http 协议,还支持 https(即在ssl协议上传输http)
yum install -y openssl openssl-devel使用 wget 命令下载
mkdir -p /usr/local/nginx && cd /usr/local/nginx
#下载版本号可根据目前官网最新稳定版自行调整
wget -O nginx-1.20.2.tar.gz https://nginx.org/download/nginx-1.20.2.tar.gz编译 nginx
#根目录使用ls命令可以看到下载的nginx压缩包,然后解压
tar -zxvf nginx-1.20.2.tar.gz
#解压后进入目录
cd nginx-1.20.2
#使用默认配置
./configure
# 编译安装
make
make install
# 启动nginx
cd /usr/local/nginx
./sbin/nginx测试访问是否成功,出现下面的图片内容则完美成功了

上面的就是基本的环境啦 10 分钟差不多搞定期间绝对不会有任何的报错我都操作了好几次呢!!
PandoraNext-让你呼吸更顺畅的ChatGPT
简单介绍
Pandora Cloud + Pandora Server + Shared Chat + BackendAPI Proxy + Chat2API = PandoraNext
PandoraNext 是 zhile(秦始皇)所写文档地址:潘多拉文档
- 更强大,但还是那个让你呼吸顺畅的ChatGPT。支持GPTs,最新UI。
- 支持多种登录方式:(相当于Pandora Cloud)
- 账号/密码
- Access Token
- Session Token
- Refresh Token
- Share Token
- 可内置tokens(可使用上述所有Token),支持设置密码。(相当于Pandora Server)
这里我们就只需要使用到他的 Prox API 调用代理到 chat.openai.com 国内直接访问是过不去的具体的我这里就不详细说明懂得都懂哈~
那么废话不多说我们直接开始搭建 PandoraNext 打开文档,可以看到三种部署方式我们直接选择 Docker 最方便的上面我们已经搭建完毕了

搭建 PandoraNext 网页版本
这里有服务器的则用服务器没有的就本地也行, 这里我就以 MacOS 为例使用本地搭建一个 PandoraNext
??: Linux 服务器和我的操作一摸一样一直的操作即可懂吗, 不是基于本地则跳过这里看下面的 ??: Proxy 模式 不支持 本地调用
Docker Desktop: https://docs.docker.com/desktop/install/mac-install/
??: 请提前安装电脑版本的 Docker Desktop 这里我就不带着来啦,跟着官方文档走就完事了
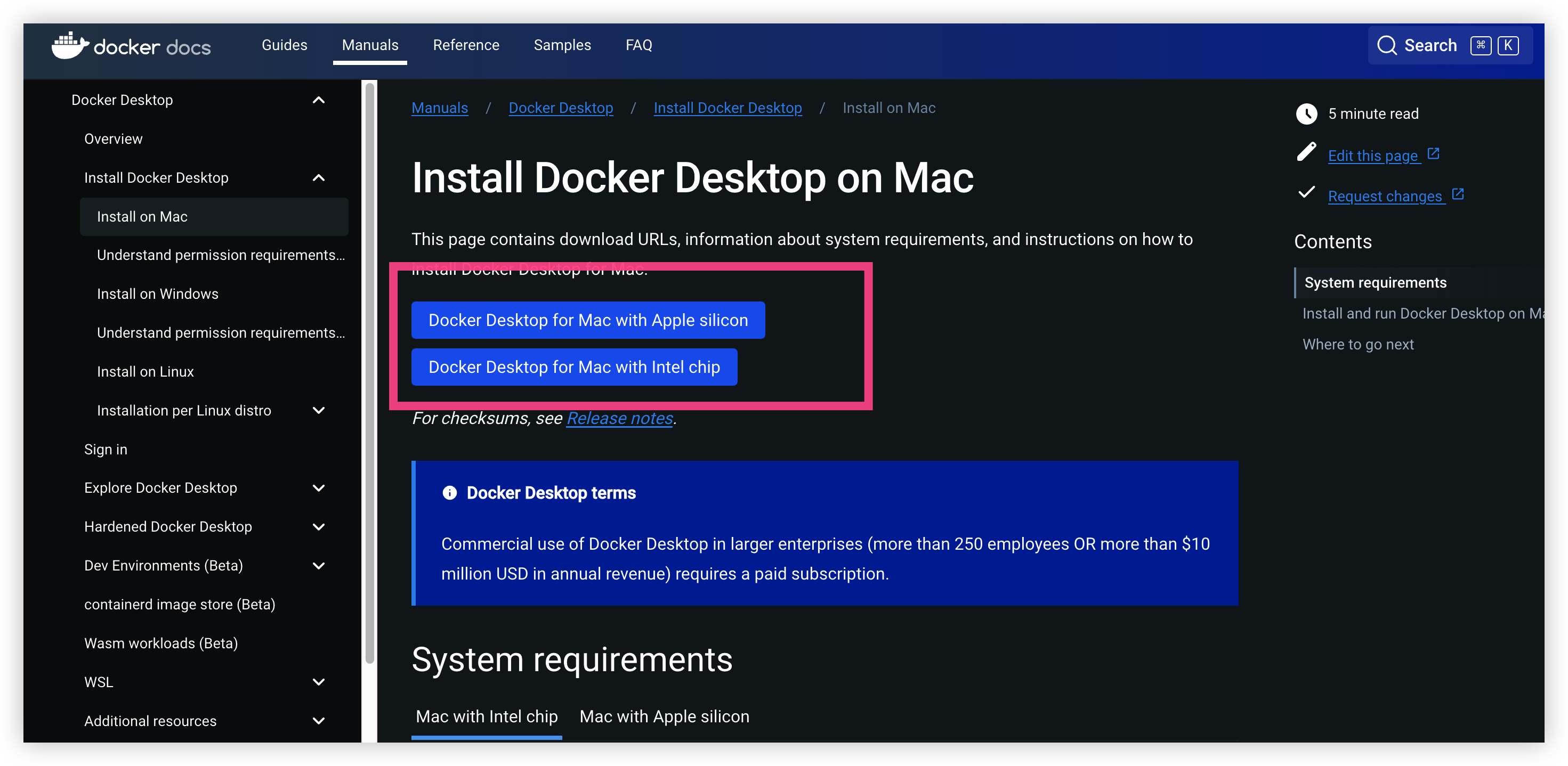
下载完毕后就是这样子

记得配置一下国内加速下载

"registry-mirrors": [
"https://xv6jnj6e.mirror.aliyuncs.com"
]然后重启完毕即可,接下来打开终端
新建目录结构

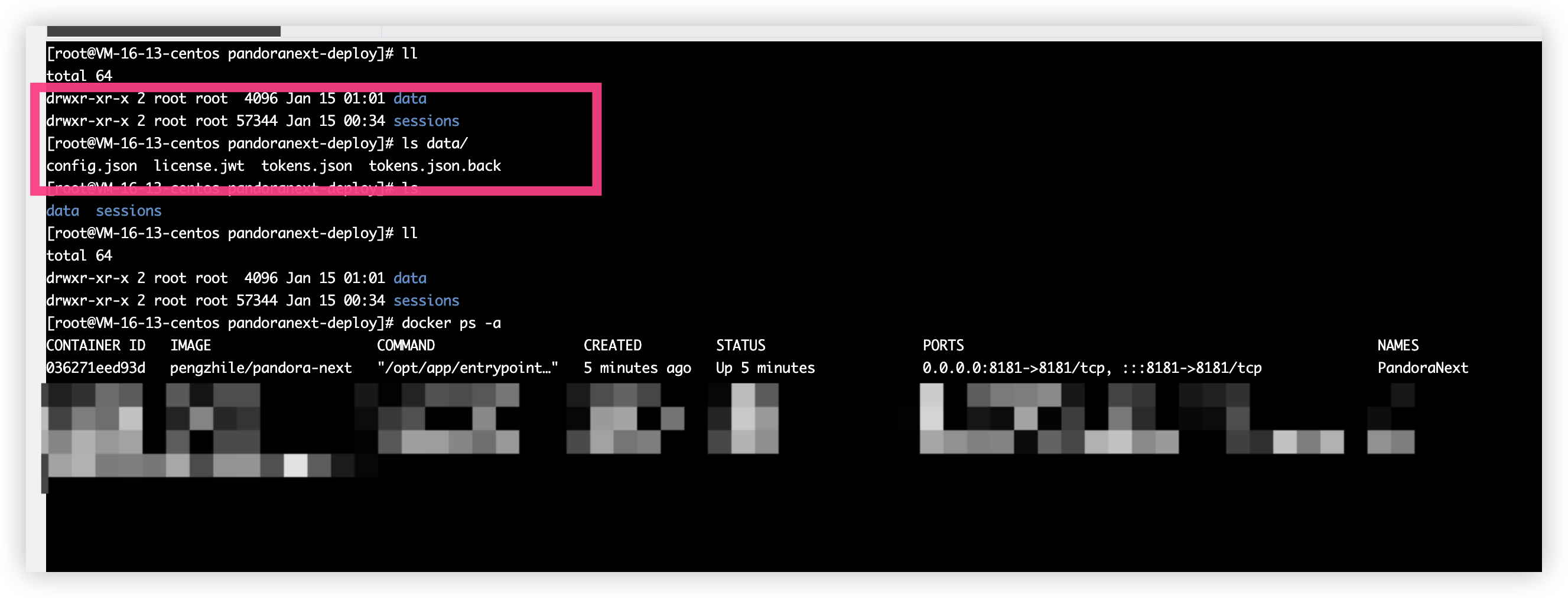
我们新增一个文件夹叫做 pandoranext-deploy 里面的文件根据图片来
mkdir -p data session

在 data 当中新增 config.json 文件、tokens.json 文件即可
touch config.json tokens.json

config.json 配置说明
这里是默认的配置文件官方扒拉下来的,我们只需要更改其中
license_id、 site_password、setup_password、proxy_api_prefix 四个参数即可
{
"bind": "0.0.0.0:8181",
"tls": {
"enabled": false,
"cert_file": "",
"key_file": ""
},
"timeout": 600,
"proxy_url": "",
"license_id": "非常重要",
"public_share": false,
"site_password": "你的网页访问密码",
"setup_password": "管理配置的密码",
"server_tokens": true,
"proxy_api_prefix": "prox api 请求前缀",
"isolated_conv_title": "*",
"disable_signup": false,
"auto_conv_arkose": false,
"proxy_file_service": true,
"custom_doh_host": "",
"captcha": {
"provider": "",
"site_key": "",
"site_secret": "",
"site_login": false,
"setup_login": false,
"oai_username": false,
"oai_password": false,
"oai_signup": false
},
"whitelist": null
}License_id 凭证
用于唯一潘多拉服务指定你的License Id
- 在这里获取:https://dash.pandoranext.com(opens in a new tab)
- 登录你的 GitHub 账号根据年限来分配你使用多少 token 额度
- 注意检查不要复制到多余的空格等不可见字符。
- 如果config.json中没有填写license_id字段,启动会报错License ID is required。
- 没有固定IP的情况,IP变动后会自动尝试重新拉取。
复制 License_id 到 config.json 当中

?? 授权我们身边复制哪个都可以在服务器当中直接输入

回车下载完毕,将会出现一个 license.jwt 的一个文件

那么基础配置我们已经完成了,接下来我们直接搭建潘多拉服务
setup_password
当你设置了这个密码,你就可以通过<你部署的站点>/setup这样的地址进行一些设置,如:在线配置config.json、tokens.json、热重载等
??: 请注意密码强度要求:不少于8位,且同时包含数字和字母!
site_password
设置整站密码,需要先输入这个密码,正确才能进行后续的页面访问。 充分保障你部署站点的私密性,杜绝不明流量占用,以及满足小圈子分享的需求
??: 请注意密码强度要求:不少于8位,且同时包含数字和字母!
proxy_api_prefix
这是一个非常重要的参数,正确的设置才能让你部署的PandoraNext开启proxy模式(你可以通过启动时的日志中Mode是否包含proxy来判断)
??: 请注意密码强度要求:不少于8位,且同时包含数字和字母!
最终整体修改
我这里就全部统一了
"license_id": "前面的许可证",
"site_password": "yangbuyiya123",
"setup_password": "yangbuyiya123",
"proxy_api_prefix": "yangbuyiya123",以上的配置都来自于 config.json 别搞错了哦
tokens.json 配置
这里文件的作用用于网页版本的访问/shared.html 则会(共享 chatgpt)别人访问可直接使用
在 proxy 模式当中是不起效果的所以这里简单说说你们感兴趣的可以研究一下
在 tokens.json 文件当中写入
{
"token1": {
// 这里支持多种token还支持账号密码授权(推荐账号密码) 比如 "token": "你的账号&密码"
"token": "access token / session token / refresh token / share token / username & password",
"password": "12345"
}
}感兴趣可以去看看详细文档: https://docs.pandoranext.com/zh-CN/configuration/tokens
那么我们的基础配置就已经全部配置完毕,接下来我们进行搭建潘多拉服务
拉取 PandoraNext 镜像
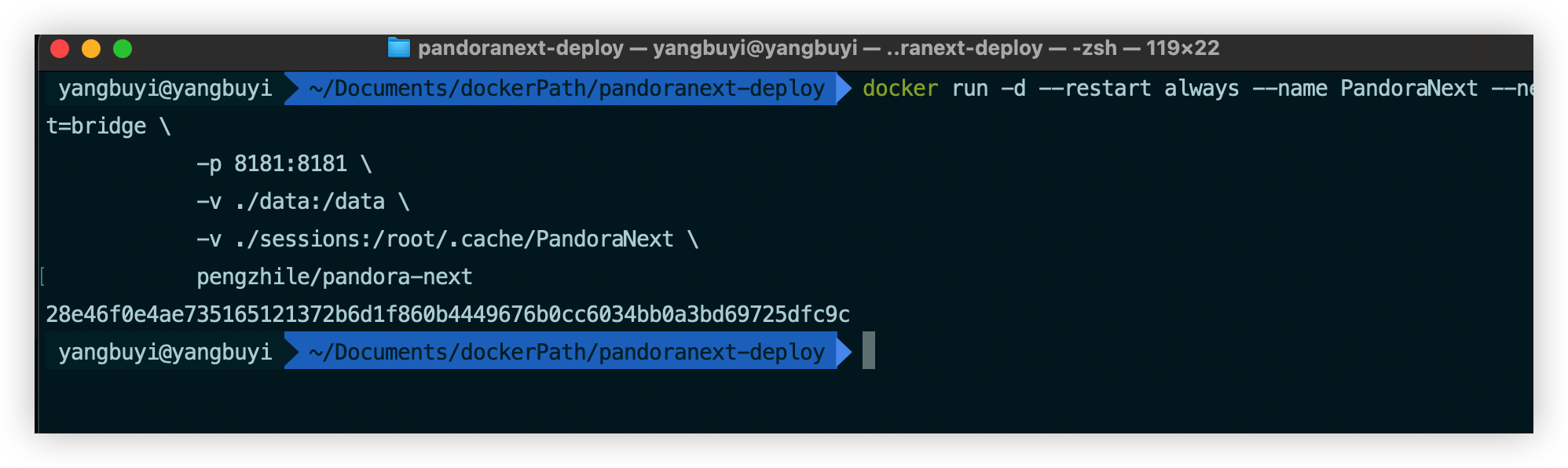
docker pull pengzhile/pandora-next运行容器我们进入到开始最外层的 pandoranext-deploy 目录当中,Linux 服务器也是这样子嗷
docker run -d --restart always --name PandoraNext --net=bridge \
-p 8181:8181 \
-v ./data:/data \
-v ./sessions:/root/.cache/PandoraNext \
pengzhile/pandora-next使用混元大模型解释一下这代码
这是一个使用 Docker 运行一个名为 pengzhile/pandora-next 的容器的命令。下面是这个命令的解释:
docker run: 这是 Docker 的基本命令,用于创建并运行一个新的容器。-d: 这个选项表示以分离模式(detached mode)运行容器。这意味着容器将在后台运行,而不是在前台占用终端。--restart always: 这个选项表示容器应该始终在系统启动时自动启动,即使在系统重启后也是如此。--name PandoraNext: 这个选项为容器指定了一个名称,这里是PandoraNext。--net=bridge: 这个选项表示容器将连接到 Docker 默认的桥接网络。-p 8181:8181: 这个选项将主机的端口 8181 映射到容器的端口 8181。这意味着从主机发往容器的 8181 端口的流量将被转发到容器内部的 8181 端口。-v ./data:/data: 这个选项将主机的./data目录挂载到容器的/data目录。这意味着容器内部对/data目录的任何更改都将反映在主机的./data目录中。-v ./sessions:/root/.cache/PandoraNext: 这个选项将主机的./sessions目录挂载到容器的/root/.cache/PandoraNext目录。这意味着容器内部对/root/.cache/PandoraNext目录的任何更改都将反映在主机的./sessions目录中。pengzhile/pandora-next: 这是要运行的 Docker 镜像的名称。
总之,这个命令创建并运行了一个名为 PandoraNext 的容器,使用了 pengzhile/pandora-next 镜像。容器在后台运行,并且在系统启动时自动启动。容器的端口 8181 被映射到主机的端口 8181,并且容器内部的 /data 和 /root/.cache/PandoraNext 目录分别挂载到了主机的 ./data 和 ./sessions 目录。
启动网页版本
直接回车等待运行成功,很快就成功了嗷
接下来我们访问 PandoraNext 服务 IP:8181 你是 Linux 服务器则使用你的 IP:端口
?? 服务器记得去云厂商配置安全组放行 8181 端口

这后面就是输入你自己的 ChatGPT 账号和密码登录了


登录成功后进入到主页面,我滴妈完全复刻官方的 UI 样式,会话记录也存在和官方一摸一样,唯一不一样的就是不需要小飞机来带我们过去玩啦~

我们可以试着来进行对话,那么对话也会消耗我们的额度,就是一开始用 github 登录的网站
额度查看: https://dash.pandoranext.com

Proxy 模式 Api 请求
?? Proxy 模式 不支持 本地调用 前面的基本配置都在 linux 服务器执行一边即可
如果去了解过 ChatGPT 的 API 请求就会知道他是需要钱的来购买 token,那么我们进行了白嫖就白嫖到底 PandoraNext 支持直接全代理转发到官方的 API 实现无差异调用只是中间加了一层代理非常的丝滑
在之前我们在 config.json 当中设置了 proxy_api_prefix 为 xxxx 我们则需要通过这个来进行访问官方的 API
假设你的proxy_api_prefix为 yangbuyiya123,你的bind为 127.0.0.1:8181
则你的BaseURL为:http://127.0.0.1:8181/yangbuyiya123,这是以下所有接口的前缀
官方的具体接口: https://platform.openai.com/docs/api-reference
我们则使用这个接口来操作一下

API 调用进行对话
使用 IP:8181/proxy_api_prefix 加上官方的接口 /v1/chat/completions
curl http://服务器IP:8181/yangbuyiya123/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7
}'可以看到我们需要去获取一下 Authorization token 这个 token 就是 access_token
但是 PandoraNext 进行了处理需要生成 PandoraNext 的 share token 往下看
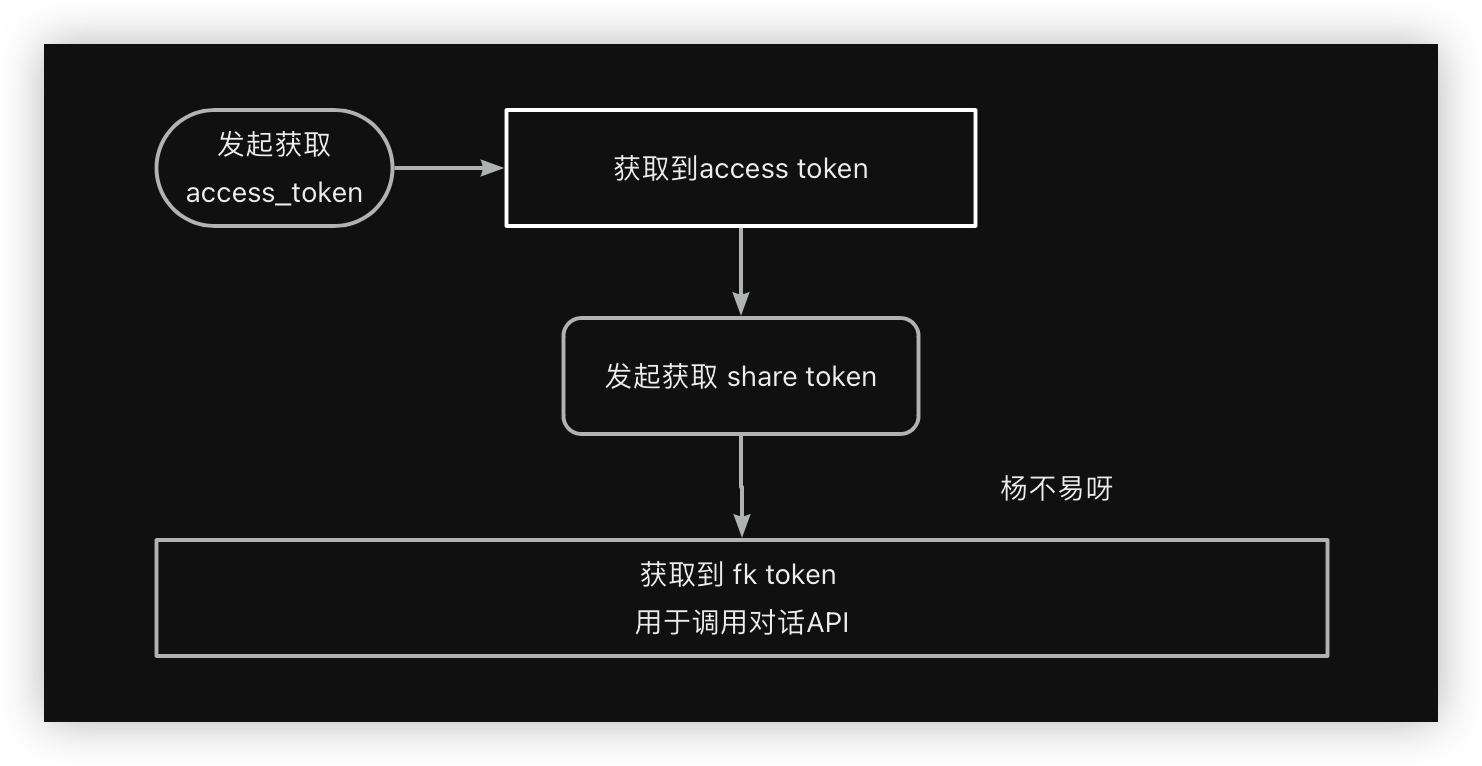
PandoraNext 专有接口
获取 access token 登录
?? 接口消耗为1:100
curl http://服务器IP:8181/yangbuyiya123/api/auth/login' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'username=user%40mail.com' \
-d 'password=abc123'- 接口为POST请求。
- 参数username为你的ChatGPT账号。
- 参数password为你的ChatGPT密码。
- 接口将同时返回access token和session token,注意保存。
继续我们来获取 access_token

返回参数: {"access_token":"输出出来的token","token_type":"Bearer"}
获取 share token Fk 调用
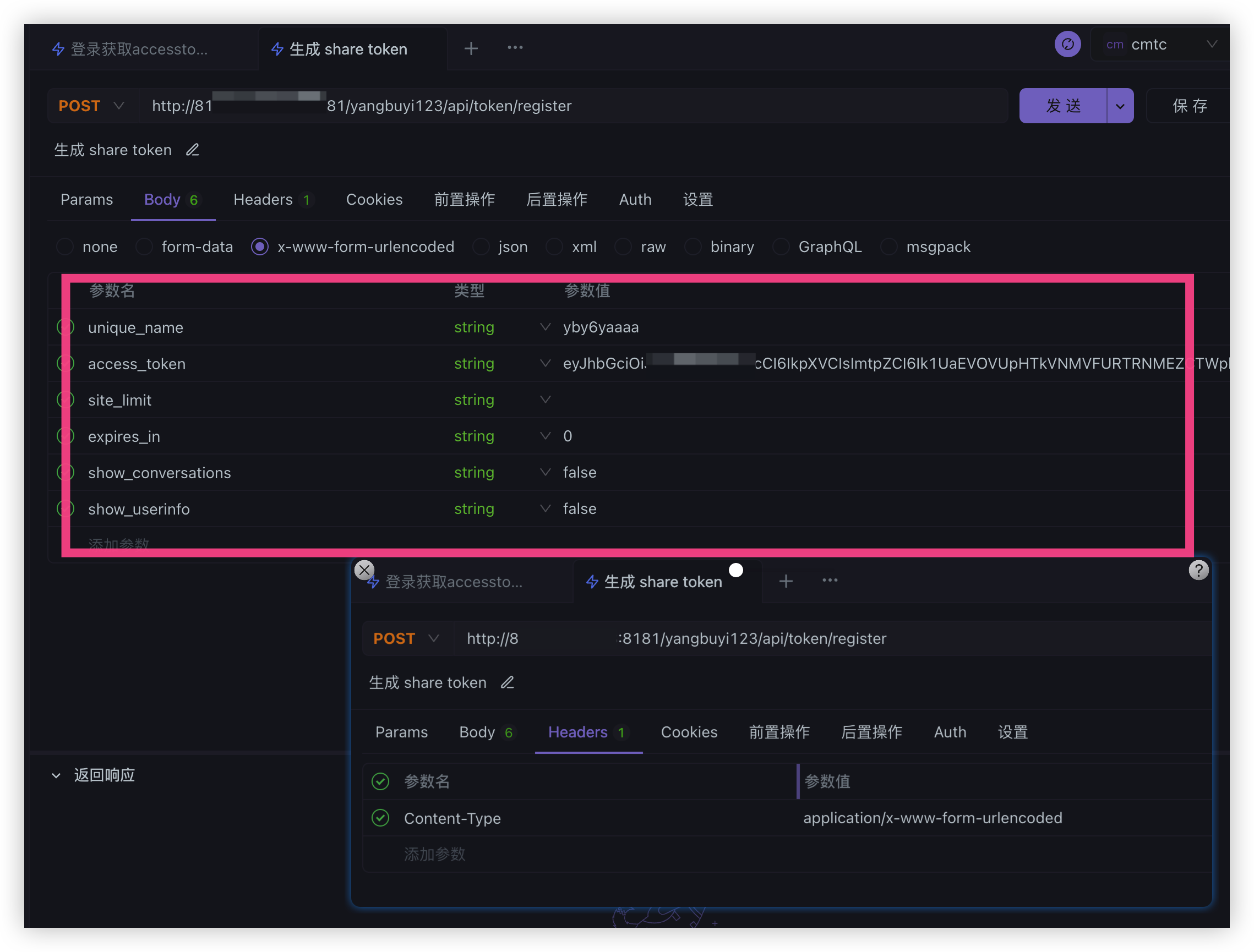
curl 'http://127.0.0.1:8181/yangbuyi123/api/token/register' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'unique_name=abcdefg' \
-d 'access_token=eyxxxx' \
-d 'site_limit=https%3A%2F%2Fchat.oaifree.com' \
-d 'expires_in=0' \
-d 'show_conversations=false' \
-d 'show_userinfo=false'- 接口为POST请求。
- 参数unique_name为你的share token的唯一标识,可以随意填写。
- 参数access_token为你的access token。
- 参数site_limit 直接为空就行。
- 参数expires_in为你的share token的有效期,单位为秒,如果你不想限制有效期,可以填写0(默认),则有效期跟随你的access token。
- 参数show_conversations为是否显示对话列表,如果你不希望此share token展示其他用户的会话,可以填写false(默认)。
- 参数show_userinfo为是否显示用户信息,如果你不想显示用户信息,可以填写false(默认)。如果不显示用户信息,GPTs中有些功能可能无法正常使用。
- 接口返回share token和其相关信息。

获取到了 Fk token 那么就可以直接请求了冲冲冲啊!!!
紧接着进行调研对话 ChatGPT3.5 模型
调用成功! 是不是很 so easy to happy 切菜一样?
那么接下来我们就是进入代码编程的学习了,准备好了吗发车咯~
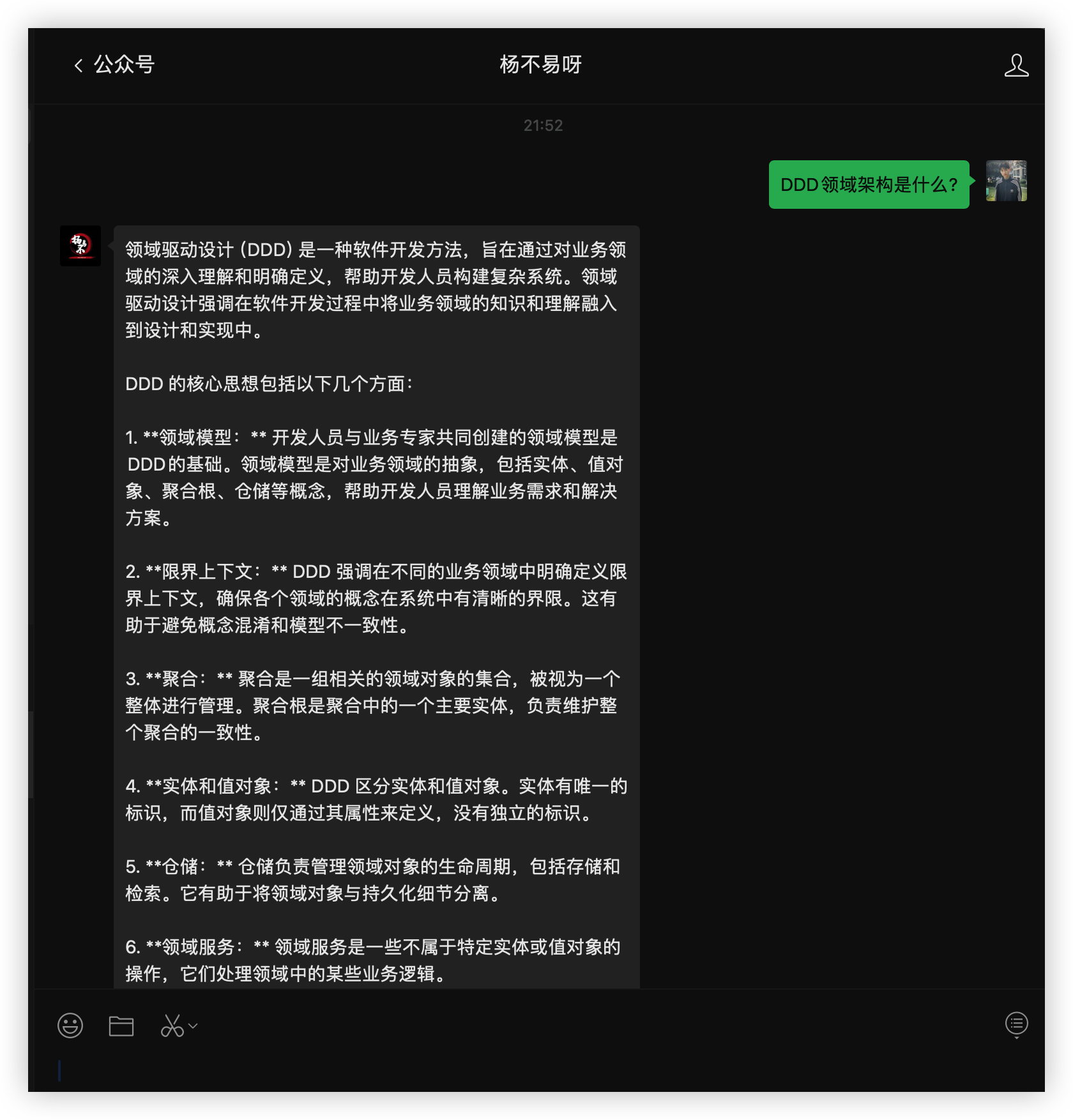
DDD领域驱动 我滴妈到底是什么啊?
说实话我也就才看了一两篇文章,先给大家用我自己的理解基本说说它是啥吧,大佬别喷我呜呜呜评论区直接教导我就行,说的有不对的地方还请指导一二~
领域驱动设计(英文:Domain-Driven Design,缩写DDD)是一种模型驱动设计的方法,通过领域模型捕捉领域知识,使用领域模型构造更易维护但是 DDD 落地是有难度的它没有一个实体的落地应用,那么 MVC 它就有一套死死的规范
MVC 就是三层的架构从控制层(controller) -> 服务层(service) -> 数据交互层(Dao) 一套流水线,但是我们在配合使用复杂项目的场景我们会发现发现这里的PO、VO、实体对象在 Service 层相互调用长期以往就会导致属性字段数量被撑大和出现一些对当前服务的 PO 实体无用的属性字段,因为别的服务也引用了这个 PO 可能就会新增一点属性字段(我图方便我有时候就这样子)
DDD 架构首先解决这个问题就是属于自己领域(domain)范围内的逻辑封装起来这就是 DDD 设计其中的一点,详细的就是它希望在分治层面合理切割问题空间为更小规模的若干子问题,而问题越小就容易被理解和处理,做到高内聚低耦合。这也是康威定律所提到的,解决复杂场景的设计主要分为:分治、抽象和知识。
DDD 的架构模型
- 用户接口层(User Interface Layer):相当于是 MVC 的 Controller。
- 应用层(Application Layer):相当于接口定义。
- 领域层(Domain Layer):系统的核心,负责表达业务概念,业务状态信息以及业务规则。即包含了该领域(问题域)所有复杂的业务知识抽象和规则定义。
- 基础设施层(Infrastructure Layer):为领域模型提供持久化机制,以及其他层提供通用的技术支持能力,如消息通信,通用工具,配置等的实现。
具体的我就不多说了推荐腾讯的 DDD 概念与方法 从腾讯视频架构重构,看DDD的概念与方法 还有小傅哥的这篇文章我也是跟着小傅哥(京东大佬)来学习的 从MVC到DDD,该如何下手重构?
接下来我们开始项目实战,来搭建 ChatGPT 应用和对接公众号进行聊天对话
项目工程搭建
项目搭建新建项目名称 yby6PandoraChatGPTJDK 17 也可以 JDK1.8 无所谓都可以
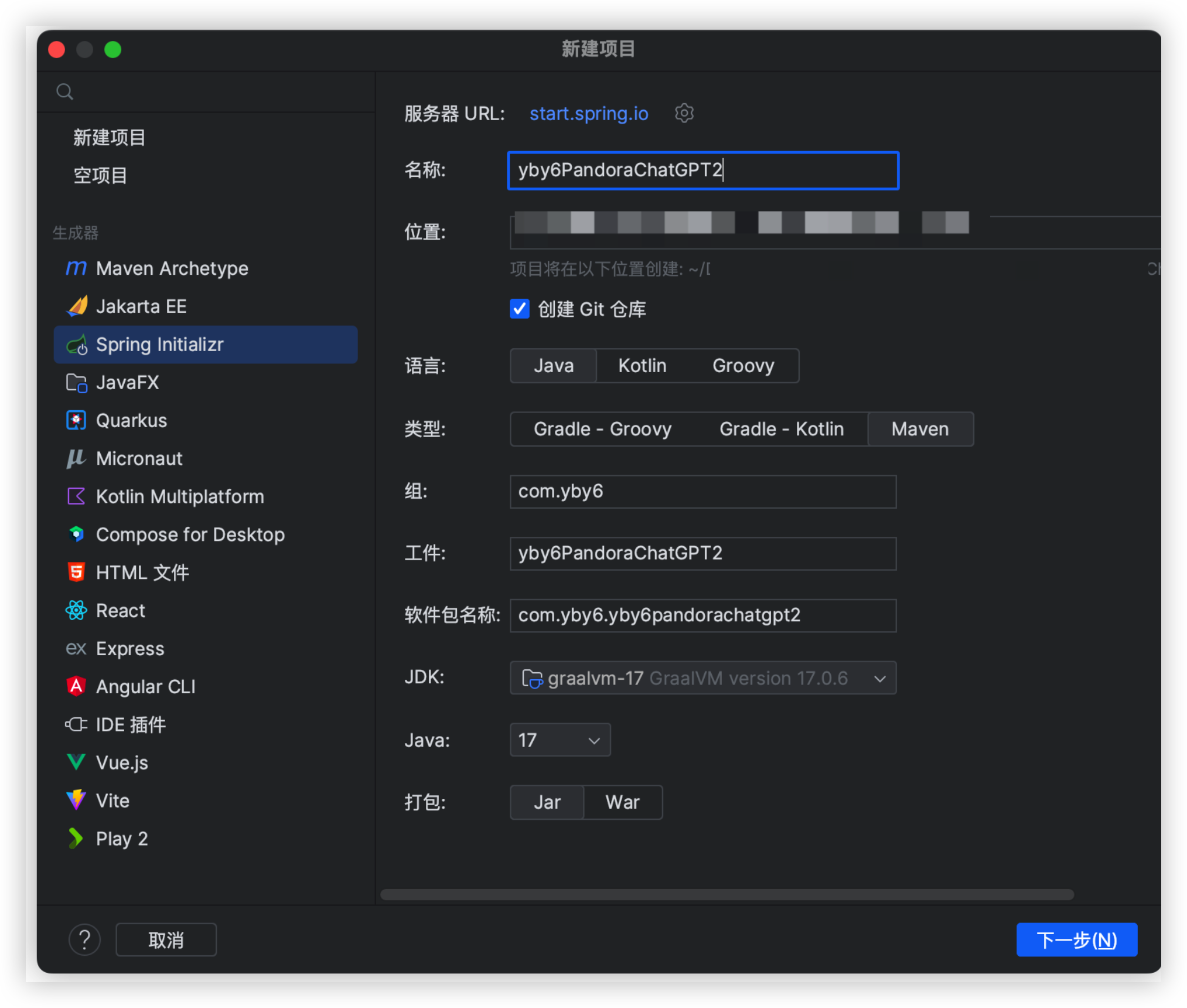
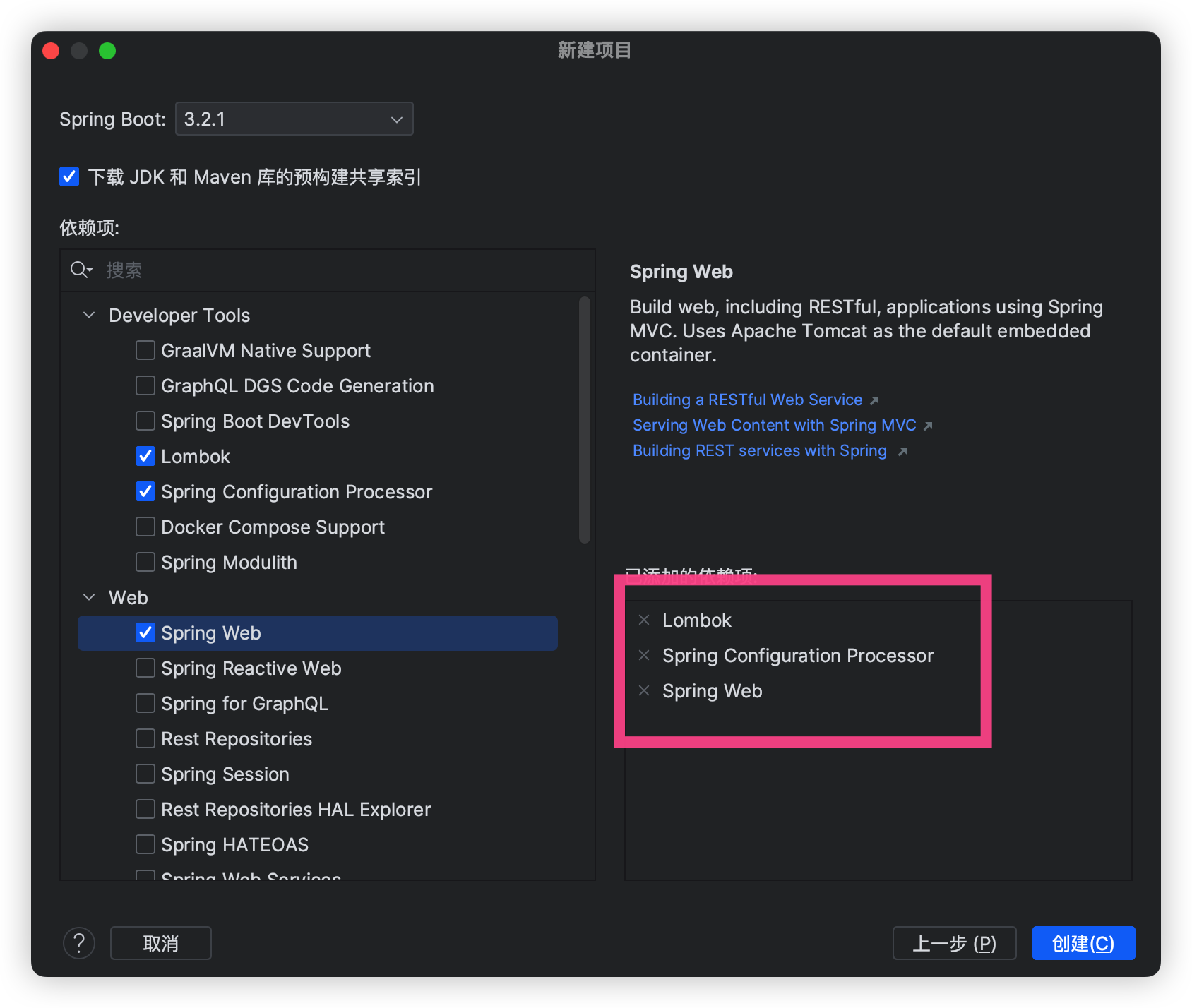
整体的架构就是如此

搭建 DDD 架构
我们来创建 DDD 架构 如下

DDD 的架构模型
- 用户接口层(User Interface Layer):相当于是 MVC 的 Controller
- 应用层(Application Layer):相当于接口定义
- 领域层(Domain Layer):系统的核心负责表达业务概念业务状态信息以及业务规则即包含了该领域(问题域)所有复杂的业务知识抽象和规则定义
- 基础设施层(Infrastructure Layer):为领域模型提供持久化机制以及其他层提供通用的技术支持能力如消息通信、通用工具、配置等的实现
如果懒的那就下载初始化DDD架构每一个领域文件夹下面我都进行了注释方便理解每一层是干嘛用的
程序对接一下问答
还记得我们前面的 Proxy 模式 Api 请求吗,我们继续使用 apifox 来调用一下并且拿到发送请求代码
?? 如果 token 失效请看目录
PandoraNext 专有接口重新生成 Share token 简称 FK
那么继续先进行手动发送一次请求,然后会出现实际请求点进去
有很多请求代码我们直接看 Java 直接给我们都搞好了呀
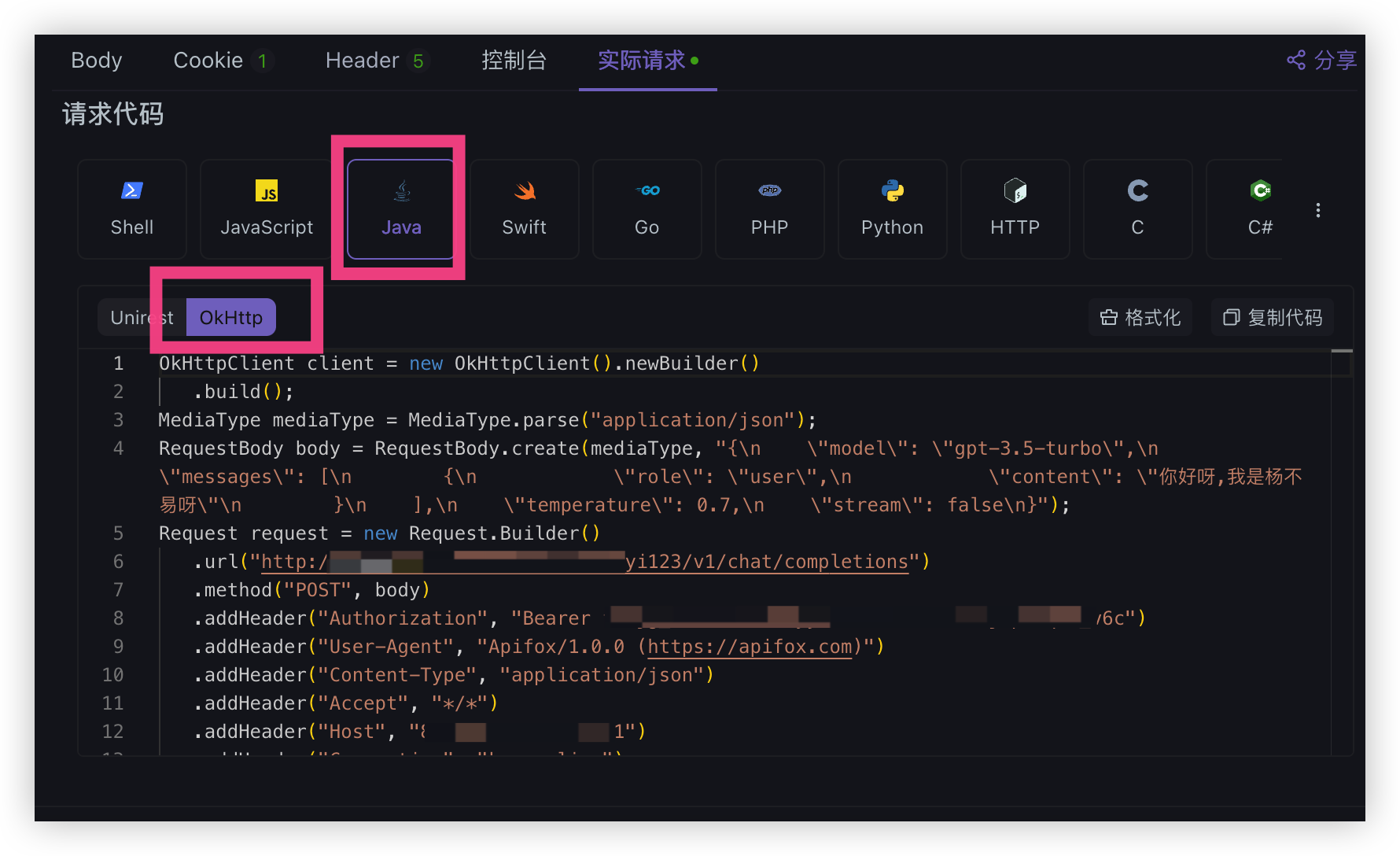
将代码复制到单元测试当中即可
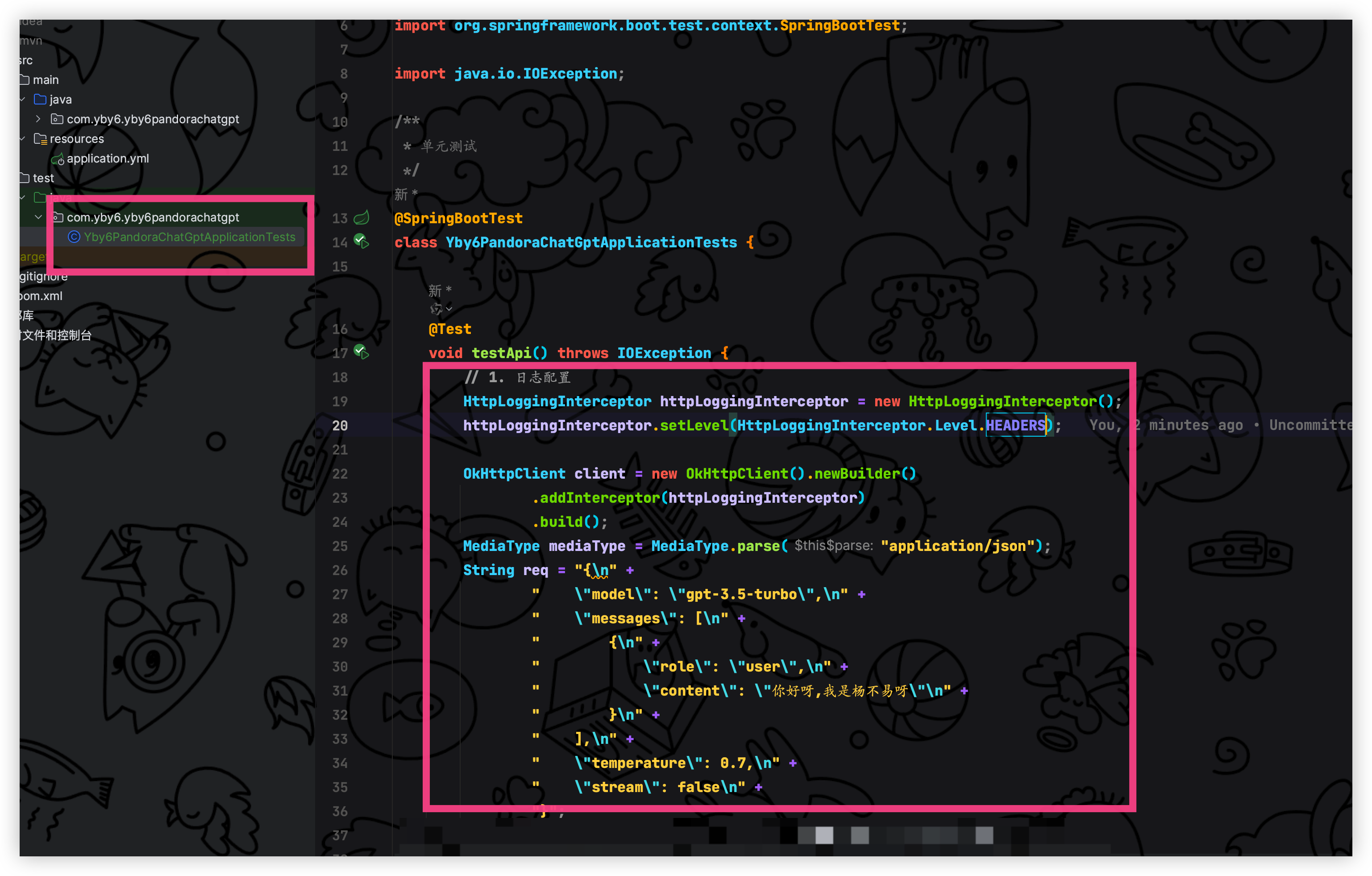
然后我偷偷的加上了请求日志,紧接着导入 okhttp 的依赖
<!-- https://mvnrepository.com/artifact/com.squareup.okhttp3/okhttp -->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.12.0</version>
</dependency>
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>logging-interceptor</artifactId>
<version>4.12.0</version>
</dependency>/**
* 单元测试
*/
@SpringBootTest
class Yby6PandoraChatGptApplicationTests {
@Test
void testApi() throws IOException {
// 日志配置
HttpLoggingInterceptor httpLoggingInterceptor = new HttpLoggingInterceptor();
httpLoggingInterceptor.setLevel(HttpLoggingInterceptor.Level.HEADERS);
// 建造请okhttp客户端
OkHttpClient client = new OkHttpClient().newBuilder()
.addInterceptor(httpLoggingInterceptor)
.build();
MediaType mediaType = MediaType.parse("application/json");
String req = "{\n" +
" \"model\": \"gpt-3.5-turbo\",\n" +
" \"messages\": [\n" +
" {\n" +
" \"role\": \"user\",\n" +
" \"content\": \"你好呀,我是杨不易呀\"\n" +
" }\n" +
" ],\n" +
" \"temperature\": 0.7,\n" +
" \"stream\": false\n" +
"}";
RequestBody body = RequestBody.create(req, mediaType);
Request request = new Request.Builder()
.url("http://IP:8181/前缀/v1/chat/completions")
.method("POST", body)
.addHeader("Authorization", "Bearer FK token")
.addHeader("Content-Type", "application/json")
.addHeader("Accept", "*/*")
.addHeader("Host", "IP:8181")
.addHeader("Connection", "keep-alive")
.build();
Response response = client.newCall(request).execute();
System.out.println(response.body().string());
}
}测试 OkHttp 调用
可以看到我们也成功点亮没有任何毛病,毕竟是生成的嘛哈哈哈

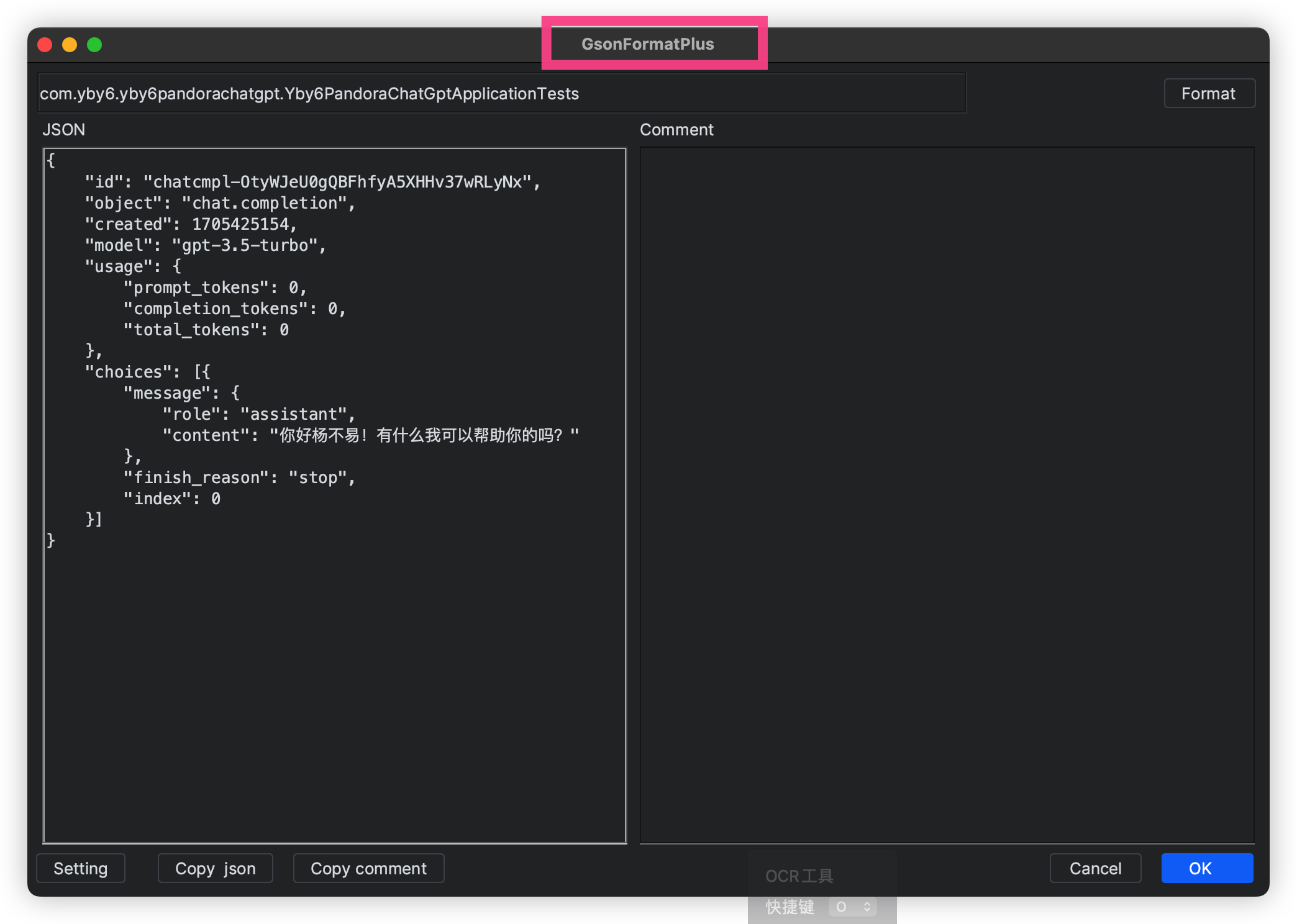
看一下返回的数据结构,现在我们接收到的是一个字符串我们需要进行创建对应的响应接收,方便操作属性,这里直接 IDEA 的插件 GsonFormatPlus 使用 JSON 转实体类就完事了
{
"id": "chatcmpl-OtyWJeU0gQBFhfyA5XHHv37wRLyNx",
"object": "chat.completion",
"created": 1705425154,
"model": "gpt-3.5-turbo",
"usage": {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0
},
"choices": [
{
"message": {
"role": "assistant",
"content": "你好杨不易!有什么我可以帮助你的吗?"
},
"finish_reason": "stop",
"index": 0
}
]
}

package com.yby6.yby6pandorachatgpt;
import com.fasterxml.jackson.annotation.JsonProperty;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
/**
* ../
*
* @author Yang Shuai
* Create By 2024/01/17
*/
@Data
public class ChatGPTResponse {
/**
* 身份证件
*/
@JsonProperty("id")
private String id;
/**
* 对象
*/
@JsonProperty("object")
private String object;
/**
* 创建
*/
@JsonProperty("created")
private Integer created;
/**
* 模型
*/
@JsonProperty("model")
private String model;
/**
* token用量
*/
@JsonProperty("usage")
private UsageDTO usage;
/**
* 回复信息
*/
@JsonProperty("choices")
private List<ChoicesDTO> choices;
@NoArgsConstructor
@Data
public static class UsageDTO {
@JsonProperty("prompt_tokens")
private Integer promptTokens;
@JsonProperty("completion_tokens")
private Integer completionTokens;
@JsonProperty("total_tokens")
private Integer totalTokens;
}
@NoArgsConstructor
@Data
public static class ChoicesDTO {
@JsonProperty("message")
private MessageDTO message;
@JsonProperty("finish_reason")
private String finishReason;
@JsonProperty("index")
private Integer index;
@NoArgsConstructor
@Data
public static class MessageDTO {
@JsonProperty("role")
private String role;
@JsonProperty("content")
private String content;
}
}
}点击 ok 后可以看到给我们按照 JSON 生成了实体类这样子我们就可以使用 JSON 转实体来映射,我们需要 JSON 工具来操作,我们引入 Java 强大的工具库 Hutool
<!-- 强大的Java工具库 -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.25</version>
</dependency>这样子我们就可以很方便的操作属性数据了可以看到回复的数据存在 MessageDTO 当中,我们到时候就只需要用这个返回给公众号即可其它的 雨我无瓜~

目前最基本我们已经完成了 DDD 架构搭建、完成 OkHttp 单元测试对接成功,接下来就是对接微信公众号文本回复,冲冲冲我手把手带大家搞!
公众号搭建(有则跳过)
适用于个人我们就选择它了进行注册,后面的就跟着注册逻辑一步步来即可,创建完毕之后就进行扫码登录
被动回复用户消息
我们先查看文本回复的文档需要什么配置参数
文档: 被动回复用户消息
当用户发送消息给公众号时(或某些特定的用户操作引发的事件推送时),会产生一个POST请求,开发者可以在响应包(Get)中返回特定XML结构,来对该消息进行响应(现支持回复文本、图片、图文、语音、视频、音乐)。严格来说,发送被动响应消息其实并不是一种接口,而是对微信服务器发过来消息的一次回复。
微信服务器在将用户的消息发给公众号的开发者服务器地址(开发者中心处配置)后,微信服务器在五秒内收不到响应会断掉连接,并且重新发起请求,总共重试三次,如果在调试中,发现用户无法收到响应的消息,可以检查是否消息处理超时。关于重试的消息排重,有msgid的消息推荐使用msgid排重。事件类型消息推荐使用FromUserName + CreateTime 排重
根据官方的说明我做了一个流程图如下

主要就是用户发送消息到公众号,那么微信就会来根据我们配置的服务器地址(后面细说)访问我们的一个 POST 接口(自定义)在里面接收 xml 参数处理自己的业务就行啦
在编写代码之前我们直接一气呵成把配置全部搞好吧,反正就是这套流程不会变死死的就这样子操作,接下来我先介绍需要一些什么参数
- 需要获取开发者微信号(原始 ID)

- 服务器配置用于微信服务器调用我们的 post 接口(自定义)

?? 因为我们是本地调试,所以需要内网穿透来转发请求到我们本地的服务,这里我使用花生壳来操作
接下来我们就进行操作配置公众号
公众号配置
进入公众号管理面板点击菜单栏 设置与开发拿到原始 ID ,回复的时候需要用到开发者微信号这个就是


复制到项目当中的配置文件 application.yml
# 微信公众号配置信息
wx:
config:
originalid: 你的原始ID
token: token服务器配置
进入公众号管理面板点击菜单栏 设置与开发点击基本配置,看到修改配置了吗继续点进去

配置 URL、Token、EncodingAESKey 即可
URL 是自定义的: 比如我的 ip 是 公网 IP/wx/gzh/我的公众号的 appid

线上的时候我们就需要替换成我们服务器 IP 即可
那么现在我们是本地需要被微信服务器调用到我这里就使用花生壳来进行内网穿透
我目前的域名是: https://34330745e8.picp.vip/ 代理到了本地的 9632 端口 待会我们的项目服务端口就是这个,你改成别的都可以

那么我的配置如下,注意这些配置都是敏感信息别写漏了

紧接着我们点击提交,会进行报错,这是为什么?
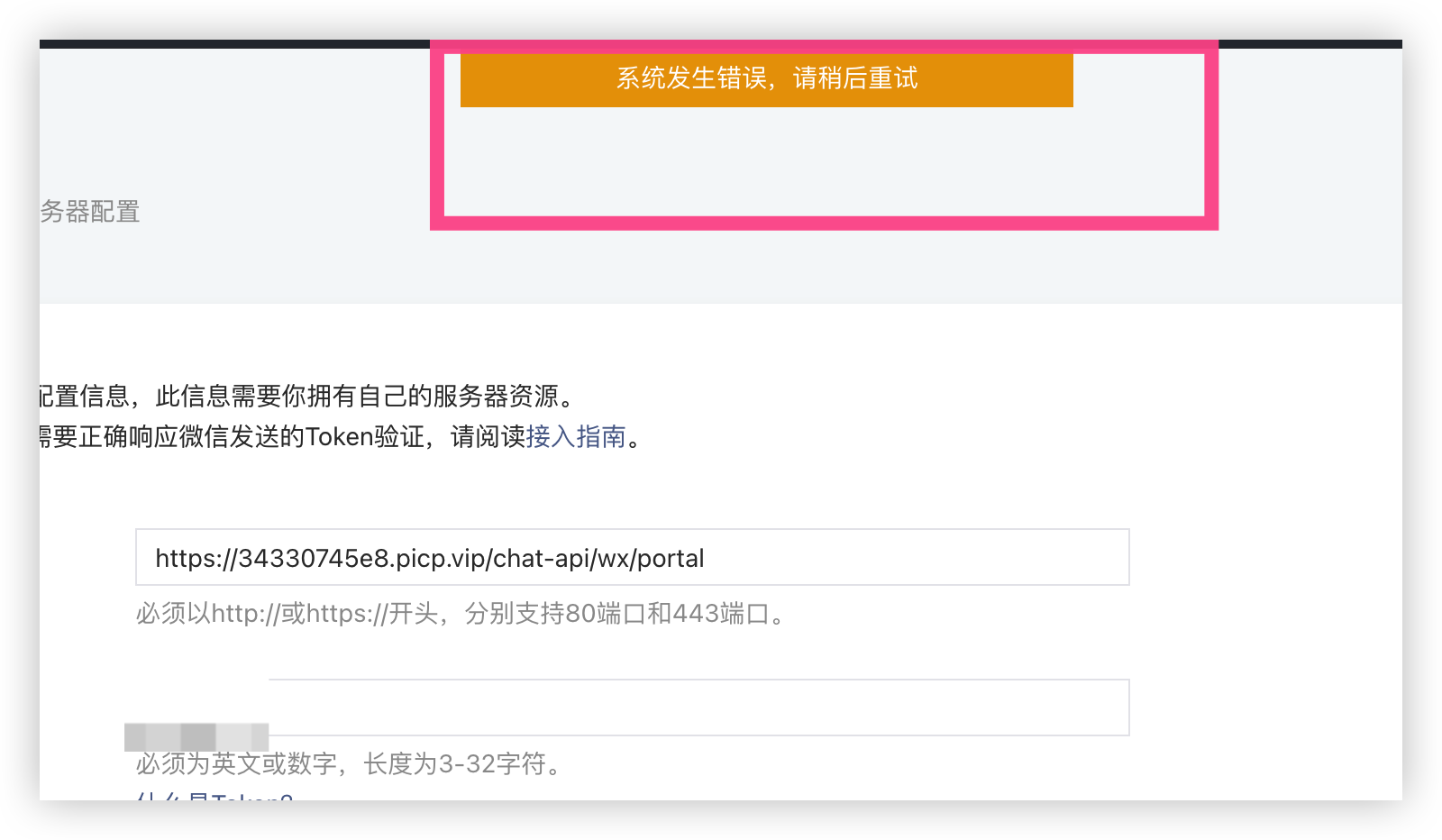
这是因为微信需要验证你给到的请求地址是否调用的通,并且里面进行校验,文档如下感兴趣的可以详细看看 文档: 验证消息的确来自微信服务器
那么我们就直接进行编写微信公众号代码
装修后端服务
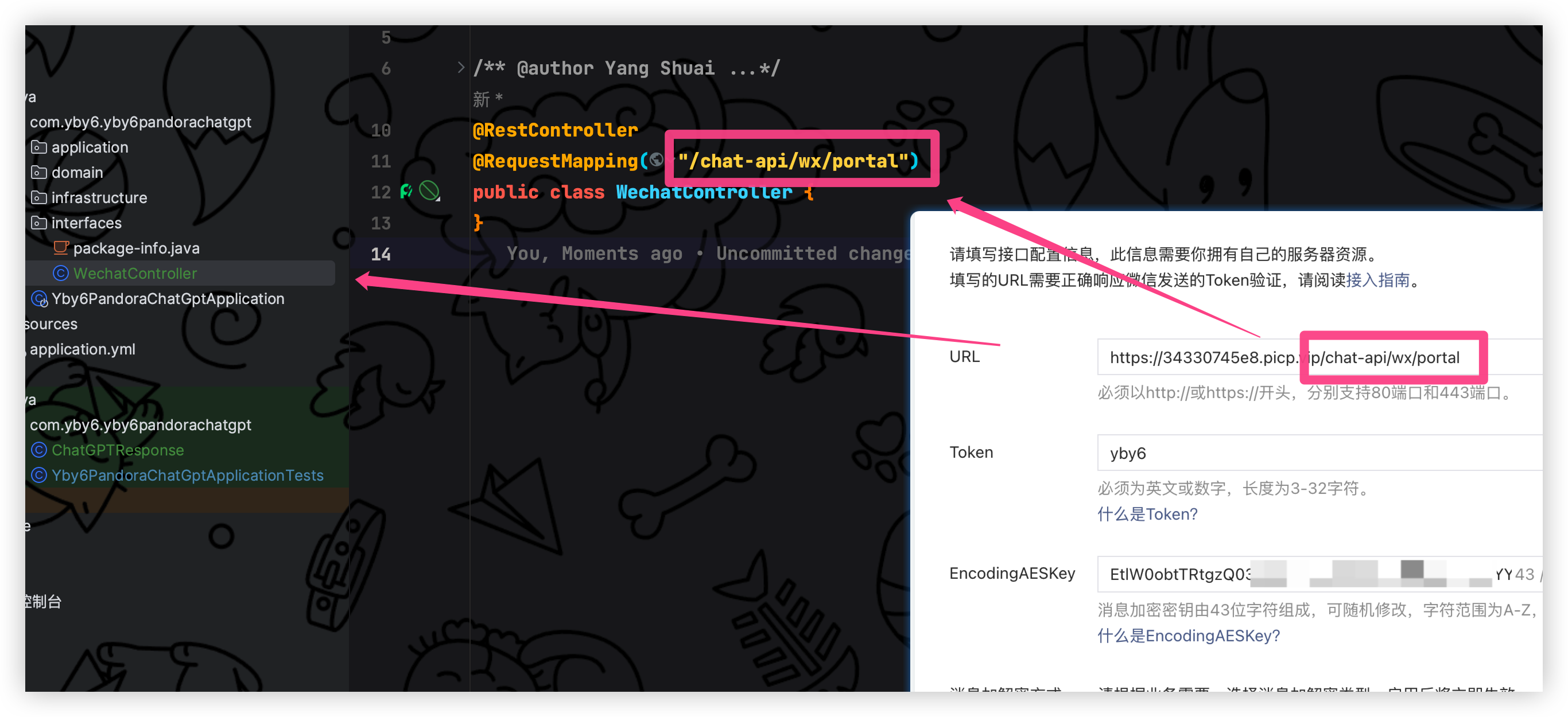
前往项目工程在 DDD 架构的 interface目录下新增 WechatController控制器,请求前缀为你自己配置的.自己注意看嗷
验证消息
开发者提交信息后,微信服务器将发送GET请求到填写的服务器地址URL上,GET请求携带参数如下表所示:
参数 | 描述 |
|---|---|
signature | 微信加密签名,signature结合了开发者填写的token参数和请求中的timestamp参数、nonce参数。 |
timestamp | 时间戳 |
nonce | 随机数 |
echostr | 随机字符串 |
签名
然后我们需要进行验证签名防止请求被伪造,官方给出的操作方式
开发者通过检验signature对请求进行校验(下面有校验方式)。若确认此次GET请求来自微信服务器,请原样返回echostr参数内容,则接入生效,成为开发者成功,否则接入失败。加密/校验流程如下:
1)将token、timestamp、nonce三个参数进行字典序排序
2)将三个参数字符串拼接成一个字符串进行sha1加密
3)开发者获得加密后的字符串可与signature对比,标识该请求来源于微信
我这里给大家写好了直接用这个来进行验证签名,没必要手动去写,知道有这个东西即可
在 DDD 架构当中的 infrastructure -> util 新增 wechat 文件夹将验签工具类创建进去

package com.yby6.yby6pandorachatgpt.infrastructure.util.wechat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
/**
* 微信签名util
*
* @author Yang Shuai
* Create By 2024/01/13
*/
public class WechatSignatureUtil {
private static final Logger logger = LoggerFactory.getLogger(WechatSignatureUtil.class);
/**
* 验证签名
*/
public static boolean check(String token, String signature, String timestamp, String nonce) {
String[] arr = new String[]{token, timestamp, nonce};
// 将token、timestamp、nonce三个参数进行字典序排序
sort(arr);
StringBuilder content = new StringBuilder();
for (String s : arr) {
content.append(s);
}
MessageDigest md;
String tmpStr = null;
try {
md = MessageDigest.getInstance("SHA-1");
// 将三个参数字符串拼接成一个字符串进行sha1加密
byte[] digest = md.digest(content.toString().getBytes());
tmpStr = byteToStr(digest);
} catch (NoSuchAlgorithmException e) {
logger.error(e.getMessage());
}
// 将sha1加密后的字符串可与signature对比,标识该请求来源于微信
return tmpStr != null && tmpStr.equals(signature.toUpperCase());
}
/**
* 将字节数组转换为十六进制字符串
*/
private static String byteToStr(byte[] byteArray) {
StringBuilder strDigest = new StringBuilder();
for (byte b : byteArray) {
strDigest.append(byteToHexStr(b));
}
return strDigest.toString();
}
/**
* 将字节转换为十六进制字符串
*/
private static String byteToHexStr(byte mByte) {
char[] Digit = {'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F'};
char[] tempArr = new char[2];
tempArr[0] = Digit[(mByte >>> 4) & 0X0F];
tempArr[1] = Digit[mByte & 0X0F];
return new String(tempArr);
}
/**
* 进行字典排序
*/
private static void sort(String[] str) {
for (int i = 0; i < str.length - 1; i++) {
for (int j = i + 1; j < str.length; j++) {
if (str[j].compareTo(str[i]) < 0) {
String temp = str[i];
str[i] = str[j];
str[j] = temp;
}
}
}
}
}配置验签参数 修改 application.yml 配置文件
# 微信公众号配置信息
wx:
config:
originalid: 原始ID
token: 服务器配置里面的token 刚刚设置的嗷编写验证消息代码
这里我也给大家一条龙编写完毕非常简单都可以看的懂,就没要你们来写了
package com.yby6.yby6pandorachatgpt.interfaces;
import com.yby6.yby6pandorachatgpt.infrastructure.util.wechat.WechatSignatureUtil;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
/**
* @author Yang Shuai
* Create By 2024/1/18
*/
@RestController
@RequestMapping("/chat-api/wx/portal")
public class WechatController {
private final Logger logger = LoggerFactory.getLogger(WechatController.class);
// 服务器 Token
@Value("${wx.config.token}")
private String token;
/**
* 处理微信服务器发来的get请求,进行签名的验证
*
* <p>
* appid 微信端AppID
* signature 微信端发来的签名
* timestamp 微信端发来的时间戳
* nonce 微信端发来的随机字符串
* echostr 微信端发来的验证字符串
*/
@GetMapping(produces = "text/plain;charset=utf-8")
public String validate(
@RequestParam(value = "signature", required = false) String signature,
@RequestParam(value = "timestamp", required = false) String timestamp,
@RequestParam(value = "nonce", required = false) String nonce,
@RequestParam(value = "echostr", required = false) String echostr) {
try {
logger.info("微信公众号验签信息{}开始 [{}, {}, {}]", signature, timestamp, nonce, echostr);
if (StringUtils.isAnyBlank(signature, timestamp, nonce, echostr)) {
throw new IllegalArgumentException("请求参数非法,请核实!");
}
boolean check = WechatSignatureUtil.check(token, signature, timestamp, nonce);
logger.info("微信公众号验签: {}", check);
if (!check) {
return null;
}
return echostr;
} catch (Exception e) {
logger.error("微信公众号验签信息{}失败 [{}, {}, {}]", signature, timestamp, nonce, echostr, e);
return null;
}
}
}测试
启动内网穿透、启动后端服务,紧接着我进行了提交测试 直接提交成功,查看后端控制台也打印了验证前面成功


紧接着我们需要启用服务器配置,否则公众号发送消息我们接收不到的

开启后需要等待五六分钟,给微信服务器缓缓,刚刚好我吗继续下面的操作往下看
那么到这里,基本的我们就已经完成,进度直接飙升百分之八十,接下来就剩下 post 接口编写我们一步步来编写 但是如何编写? 往下看
被动回复用户消息
我们继续看文档,说了会访问 post 接口(我们设置的) 但是没有说给我们什么参数啊? 直到我看到了 XML 数据包那不就是字符串嘛那就直接用字符串来接收就行
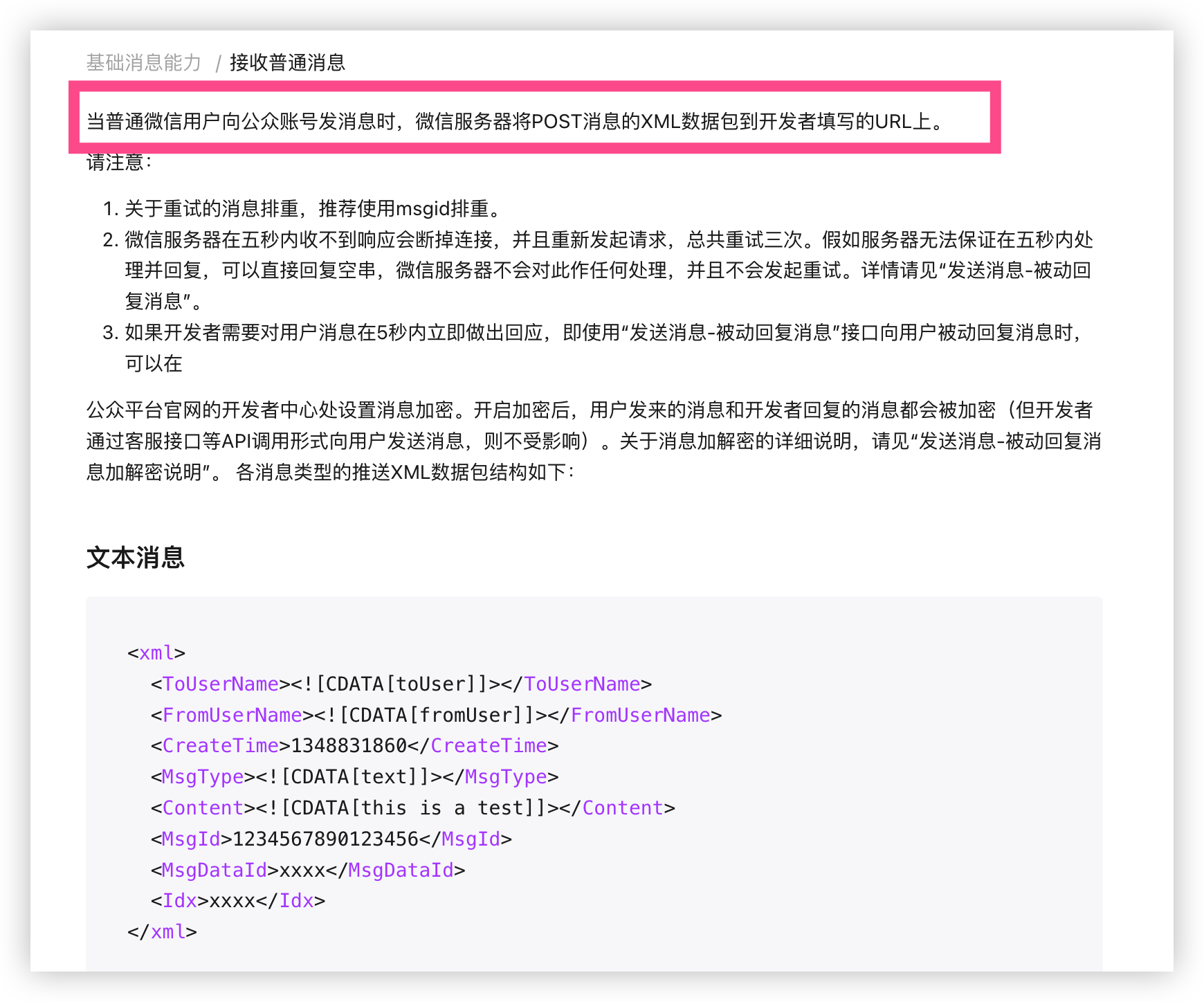
/**
* 此处是处理微信服务器的消息转发的
*/
@PostMapping(produces = "application/xml; charset=UTF-8")
public String post(@RequestBody String requestBody) {
logger.info("接收参数:{}", requestBody);
return "正在开发中....";
}测试
启动内网穿透、启动后端服务,然后打开你自己的公众号进行发送消息测试后端是否接收到参数
?? 服务器配置要开启使用否则无法接收到消息,如果开启了还是无法接收到那就在等待一会吧我等了 10 分钟差不多......
可以看到我通过公众号进行发送消息,微信服务器返回了一个 xmk 字符串给我,那么我们就需要对 xml 进行解析转成我们的 Java Bean

改造普通消息文本数据
新增依赖 xstream 用于映射 xml 字段,它还有作用是可以配置 restful 接口 进行请求调用,中间配置一个拦截器注入一些请求参数等配置
<!-- 对接微信公众号,需要解析xml -->
<!-- https://mvnrepository.com/artifact/com.thoughtworks.xstream/xstream -->
<dependency>
<groupId>com.thoughtworks.xstream</groupId>
<artifactId>xstream</artifactId>
<version>1.4.20</version>
</dependency>编写 xml 对应的 JavaBean ,在 DDD 架构当中的 Domain 领域层新增 Wechat 文件夹编写 MessageTextEntity 实体

package com.yby6.yby6pandorachatgpt.domain.wechat;
import com.thoughtworks.xstream.annotations.XStreamAlias;
import lombok.Getter;
/**
* 回复消息文本实体
*
* @author Yang Shuai
* Create By 2024/01/18
*/
@Getter
public class MessageTextEntity {
@XStreamAlias("MsgId")
private String msgId;
@XStreamAlias("ToUserName")
private String toUserName;
@XStreamAlias("FromUserName")
private String fromUserName;
@XStreamAlias("CreateTime")
private String createTime;
@XStreamAlias("MsgType")
private String msgType;
@XStreamAlias("Content")
private String content;
@XStreamAlias("Event")
private String event;
@XStreamAlias("EventKey")
private String eventKey;
public MessageTextEntity() {
}
public void setMsgId(String msgId) {
this.msgId = msgId;
}
public void setToUserName(String toUserName) {
this.toUserName = toUserName;
}
public void setFromUserName(String fromUserName) {
this.fromUserName = fromUserName;
}
public void setCreateTime(String createTime) {
this.createTime = createTime;
}
public void setMsgType(String msgType) {
this.msgType = msgType;
}
public void setContent(String content) {
this.content = content;
}
public void setEvent(String event) {
this.event = event;
}
public void setEventKey(String eventKey) {
this.eventKey = eventKey;
}
}紧接着我们把 xml 解析为我们的 MessageTextEntity Bean ,在 DDD 架构当中的 Domain 继续新增 XmlUtil 工具类

package com.yby6.yby6pandorachatgpt.infrastructure.util.wechat;
import com.thoughtworks.xstream.XStream;
import com.thoughtworks.xstream.core.util.QuickWriter;
import com.thoughtworks.xstream.io.HierarchicalStreamWriter;
import com.thoughtworks.xstream.io.xml.DomDriver;
import com.thoughtworks.xstream.io.xml.PrettyPrintWriter;
import com.thoughtworks.xstream.io.xml.XppDriver;
import org.apache.commons.lang3.StringUtils;
import java.io.Writer;
/**
* XmlUtil
*
* @author yangbuyiya
* Create By 2024/01/18
*/
public class XmlUtil {
/**
* xstream扩展,bean转xml自动加上![CDATA[]]
*/
public static XStream getMyXStream() {
return new XStream(new XppDriver() {
@Override
public HierarchicalStreamWriter createWriter(Writer out) {
return new PrettyPrintWriter(out) {
// 对所有xml节点都增加CDATA标记
final boolean cdata = true;
@Override
public void startNode(String name, Class clazz) {
super.startNode(name, clazz);
}
@Override
protected void writeText(QuickWriter writer, String text) {
if (cdata && !StringUtils.isNumeric(text)) {
writer.write("<![CDATA[");
writer.write(text);
writer.write("]]>");
} else {
writer.write(text);
}
}
};
}
});
}
/**
* bean转成微信的xml消息格式
*/
public static String beanToXml(Object object) {
XStream xStream = getMyXStream();
xStream.alias("xml", object.getClass());
xStream.processAnnotations(object.getClass());
String xml = xStream.toXML(object);
if (!StringUtils.isEmpty(xml)) {
return xml;
} else {
return null;
}
}
/**
* xml转成bean泛型方法
*/
public static <T> T xmlToBean(String resultXml, Class clazz) {
// XStream对象设置默认安全防护,同时设置允许的类
XStream stream = new XStream(new DomDriver());
XStream.setupDefaultSecurity(stream);
stream.allowTypes(new Class[]{clazz});
stream.processAnnotations(new Class[]{clazz});
stream.setMode(XStream.NO_REFERENCES);
stream.alias("xml", clazz);
return (T) stream.fromXML(resultXml);
}
}logger.info("接收参数:{}", requestBody);
MessageTextEntity messageTextEntity = XmlUtil.xmlToBean(requestBody, MessageTextEntity.class);
logger.info("解析XML数据:{}", messageTextEntity);然后我们继续测试看看是否映射成功

成功的解析完毕,那么最后一步就是被动回复用户消息, 我们组装下面的 XML 返回给微信服务器即可

我这里也直接写好了没什么东西就不需要大家操作了
为了安全,我们使用我们自己配置文件当中的原始ID

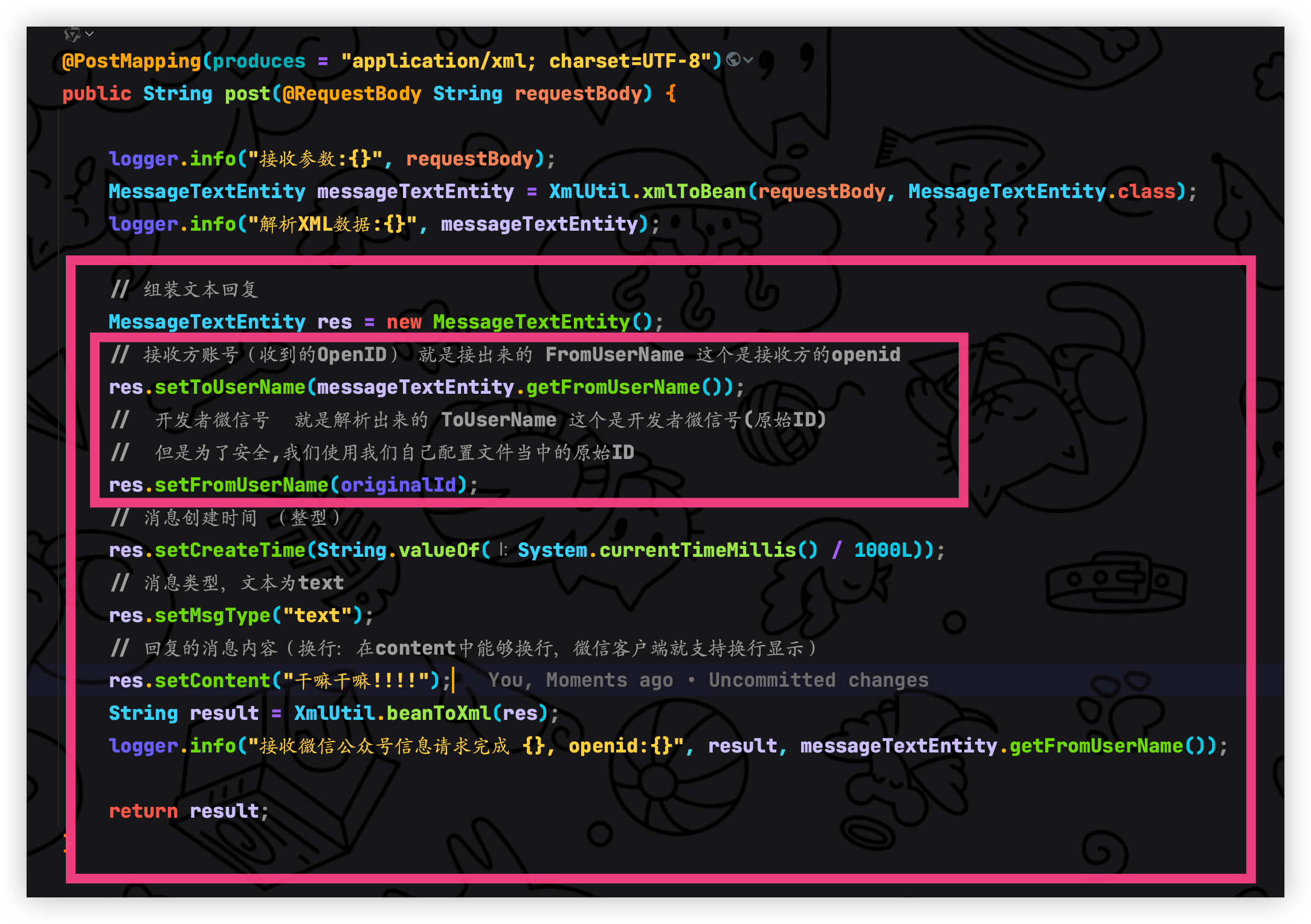
@PostMapping(produces = "application/xml; charset=UTF-8")
public String post(@RequestBody String requestBody) {
logger.info("接收参数:{}", requestBody);
MessageTextEntity messageTextEntity = XmlUtil.xmlToBean(requestBody, MessageTextEntity.class);
logger.info("解析XML数据:{}", messageTextEntity);
// 组装文本回复
MessageTextEntity res = new MessageTextEntity();
// 接收方账号(收到的OpenID) 就是接出来的 FromUserName 这个是接收方的openid
res.setToUserName(messageTextEntity.getFromUserName());
// 开发者微信号 就是解析出来的 ToUserName 这个是开发者微信号(原始ID)
// 但是为了安全,我们使用我们自己配置文件当中的原始ID
res.setFromUserName(originalId);
// 消息创建时间 (整型)
res.setCreateTime(String.valueOf(System.currentTimeMillis() / 1000L));
// 消息类型,文本为text
res.setMsgType("text");
// 回复的消息内容(换行:在content中能够换行,微信客户端就支持换行显示)
res.setContent("干嘛干嘛!!!!");
String result = XmlUtil.beanToXml(res);
logger.info("接收微信公众号信息请求完成 {}, openid:{}", result, messageTextEntity.getFromUserName());
return result;
}测试
启动花生壳、启动后端服务,在公众号发送消息观察是否回复了文本消息

那么到这里我们就已经完成基本的操作啦,接下来就是对接 ChatGPT 问答操作
我们可以直接把我们单元测试的 OkHttp 请求拿过来,相当于可以完成问答回复了,我们可以先演示一下
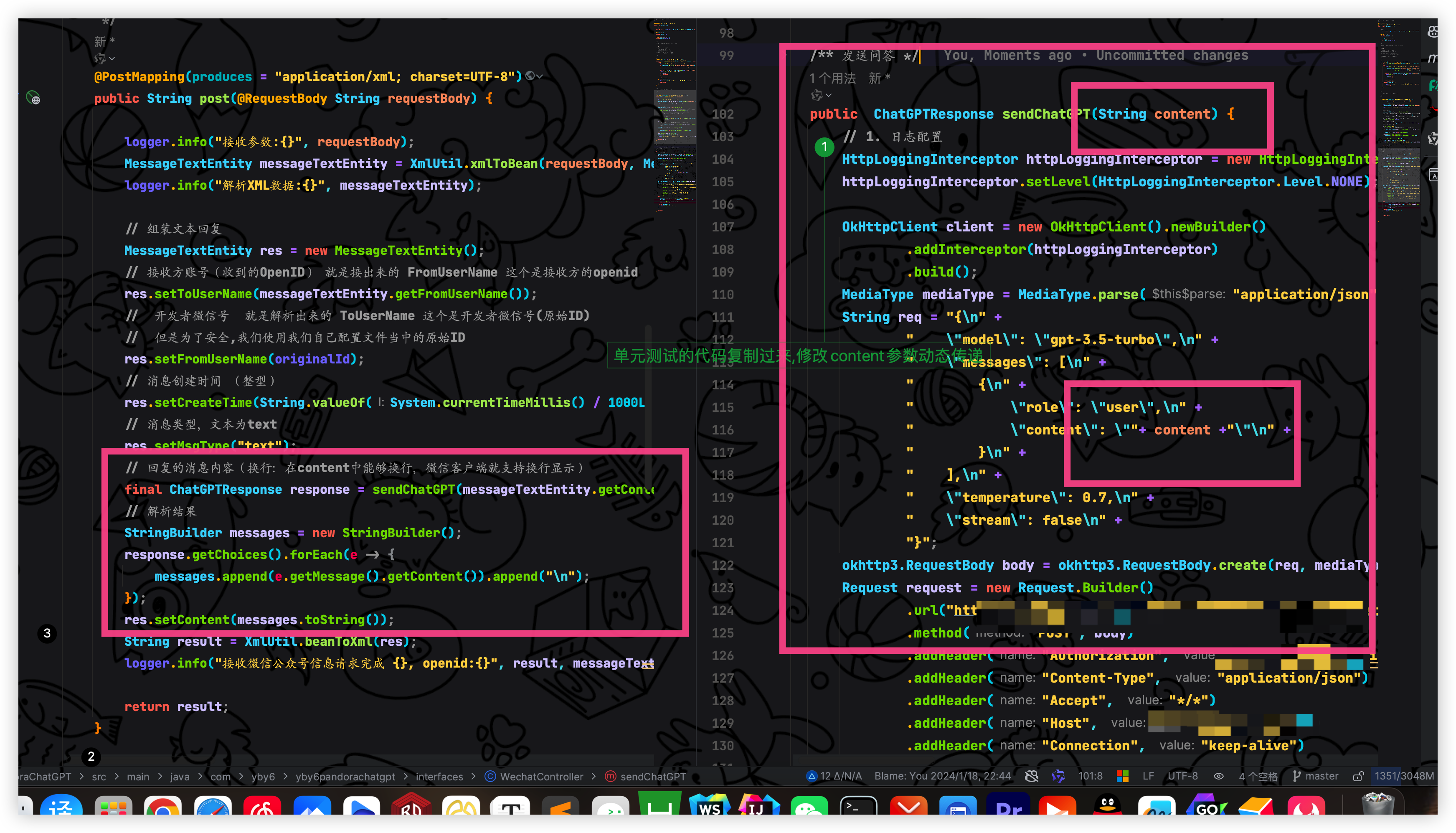
然后进行测试,查看效果,开启内网穿透、开启后端服务、测试查看控制台是否输出调用 ChatGPT 返回的参数
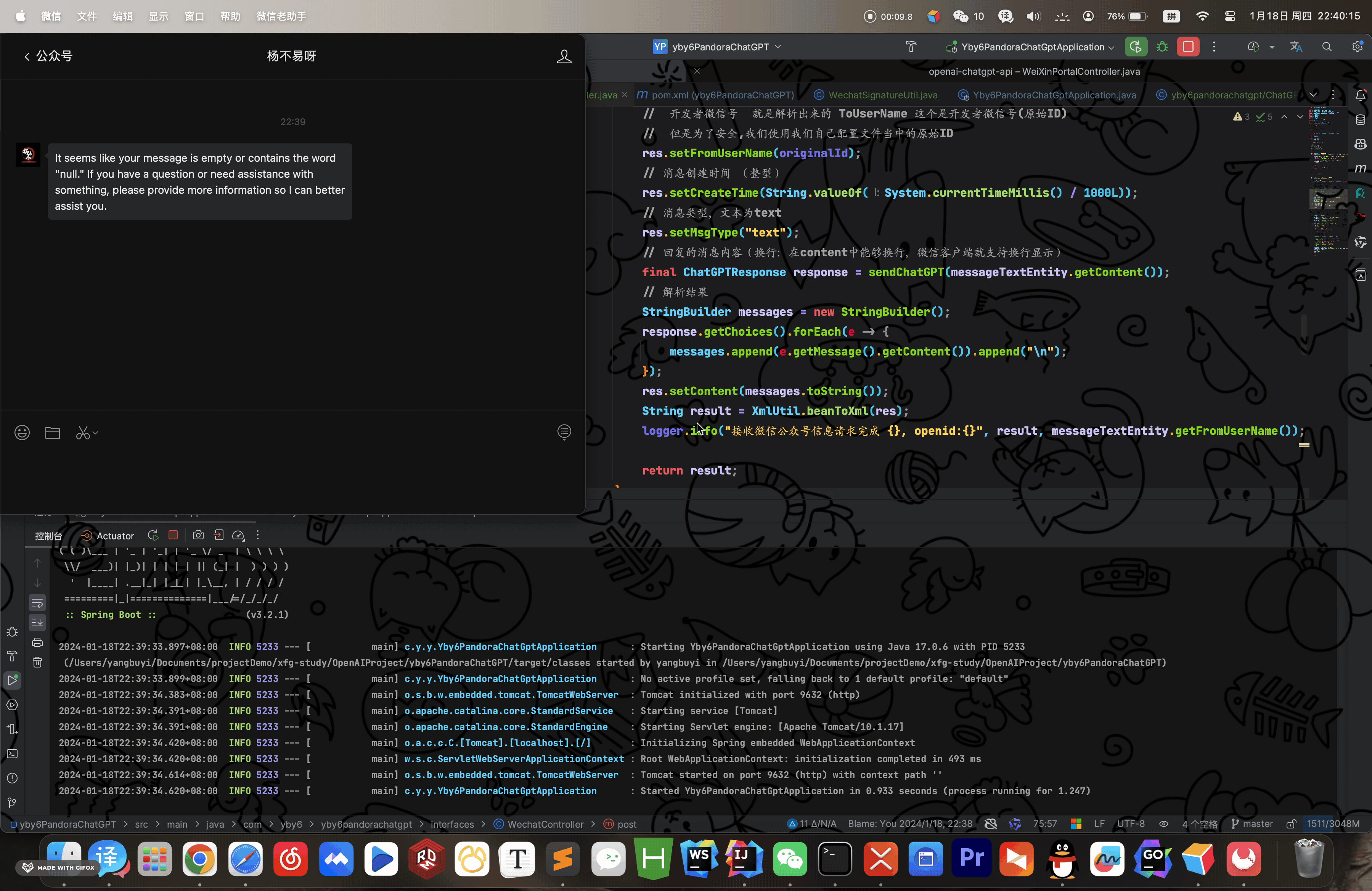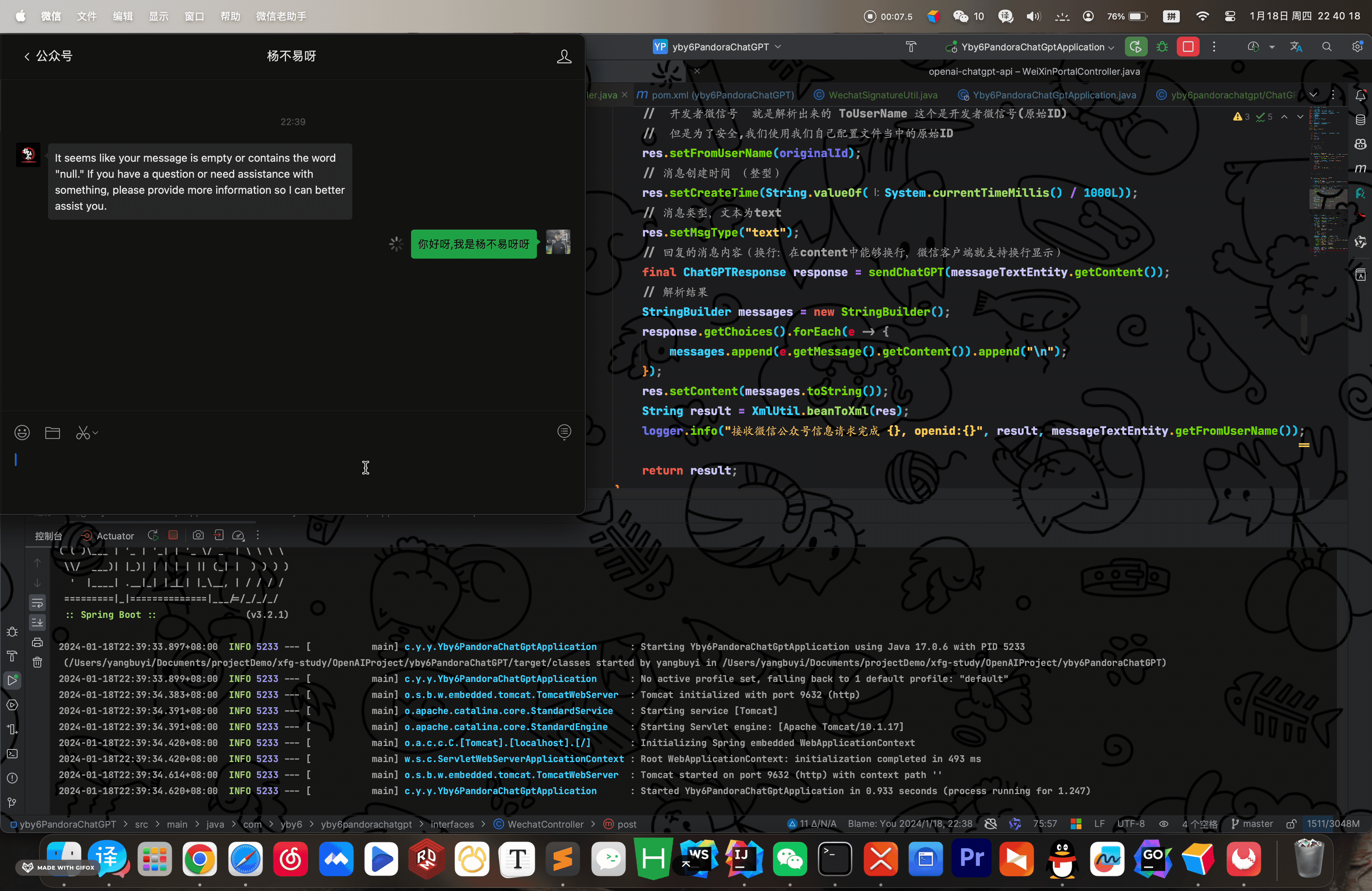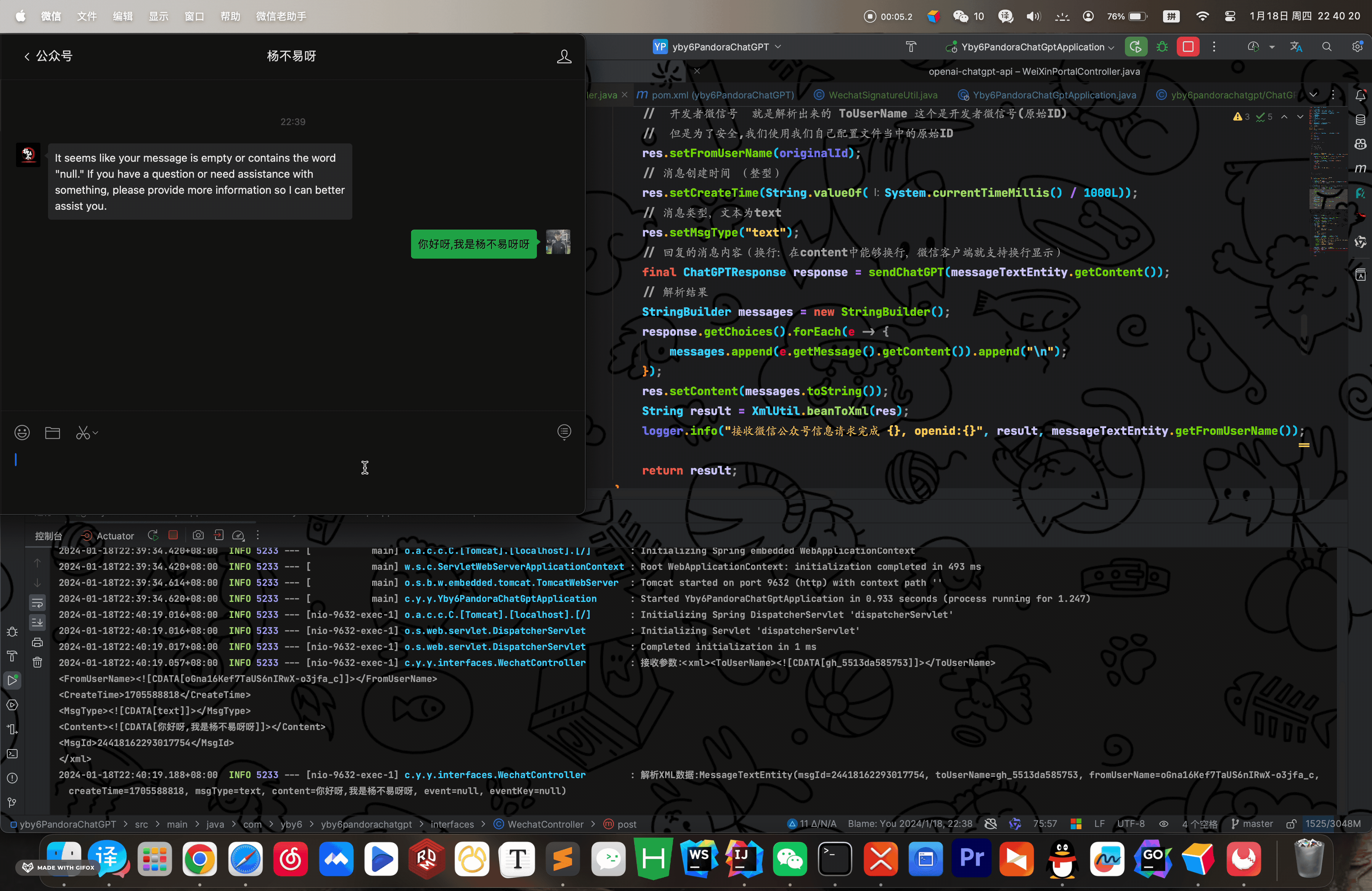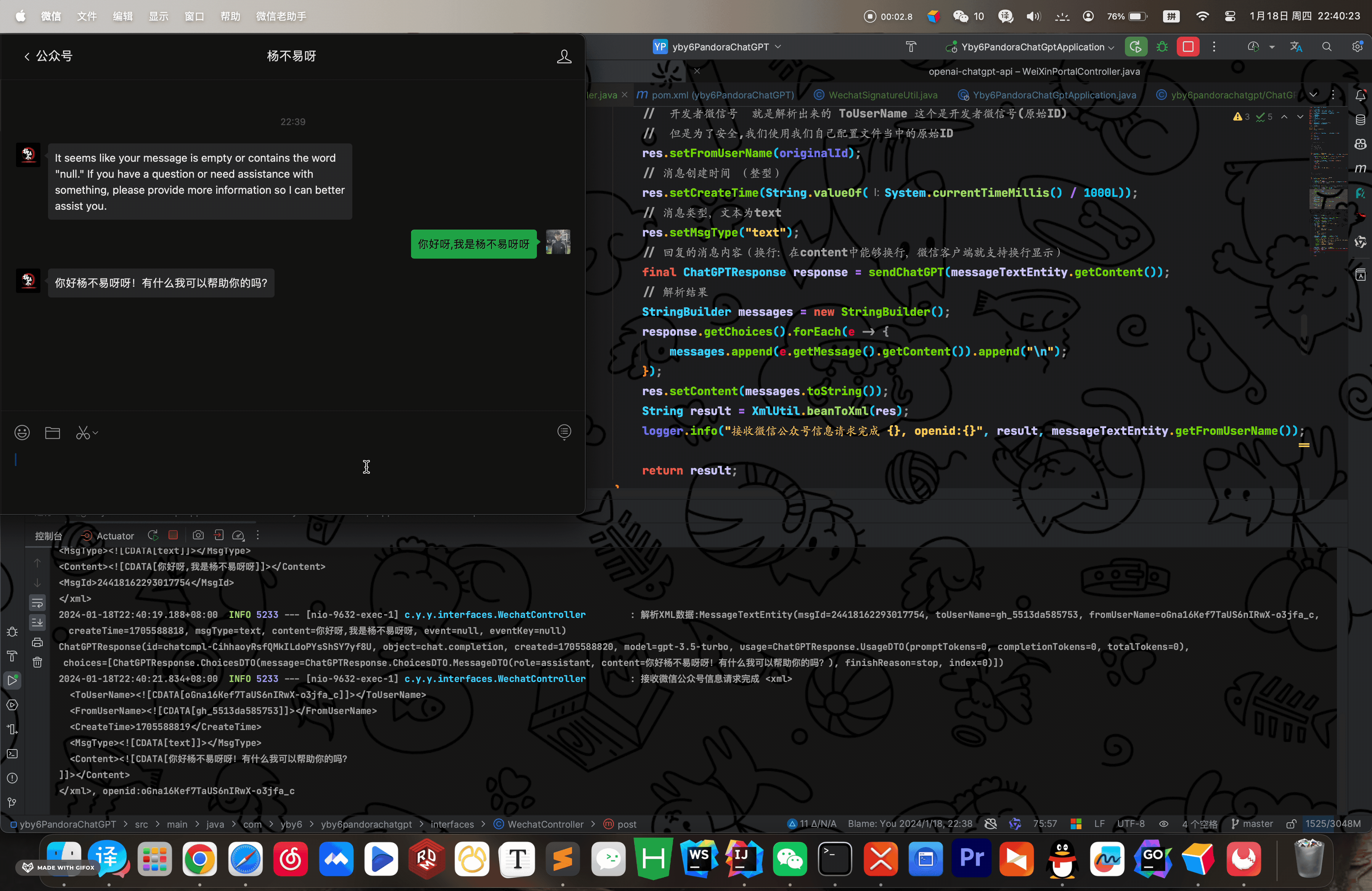
这里其实就可以完结,如果您追求完美继续往下看!
可以看到我们已经完美的实现问答交互功能,是不是感觉非常简单? 真的就是 切菜一样,这样子编写请求虽然说很舒服,但是会大量消耗性能,我们没发送一条信息都要重新创建一条全新请求 例如:
OkHttpClient client = new OkHttpClient().newBuilder().build();这个新的 OkHttpClient 实例与之前创建的实例是独立的,它们之间不会共享相同的配置或连接池频繁创建新的 OkHttpClient 实例可能会导致性能问题,因为每个实例都会创建自己的连接池和线程池,这可能会导致资源浪费和性能下降.
因此我们就需要解决这个潜在的问题,使用会话工厂模式,这里我参考 mybatis 的实现方式,接下来我就简单的说一下冲冲冲!
会话工厂实现
Mybatis 源码包查看 包路径:org.apache.ibatis.session

如果之前有学习过mybatis源码的大佬就知道,mybatis的核心就是SqlSessionFactory
通过idea可以才看到 SqlSessionFactory 的实现对象是 DefaultSqlSessionFactory 和 SqlSessionManager
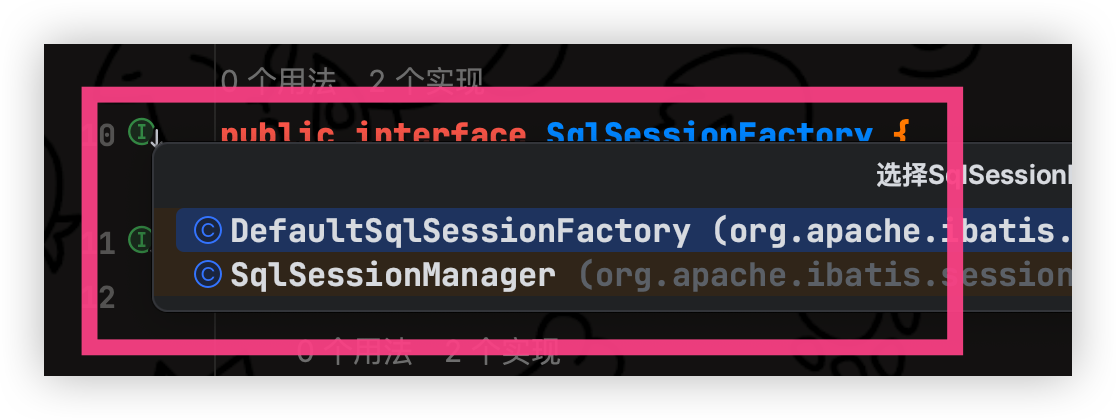
那么我们就点击 DefaultSqlSessionFactory 进入源码看看他操作了什么
实现了 SqlSessionFactory 接口 openSession 方法 开启会话 非常多的重载
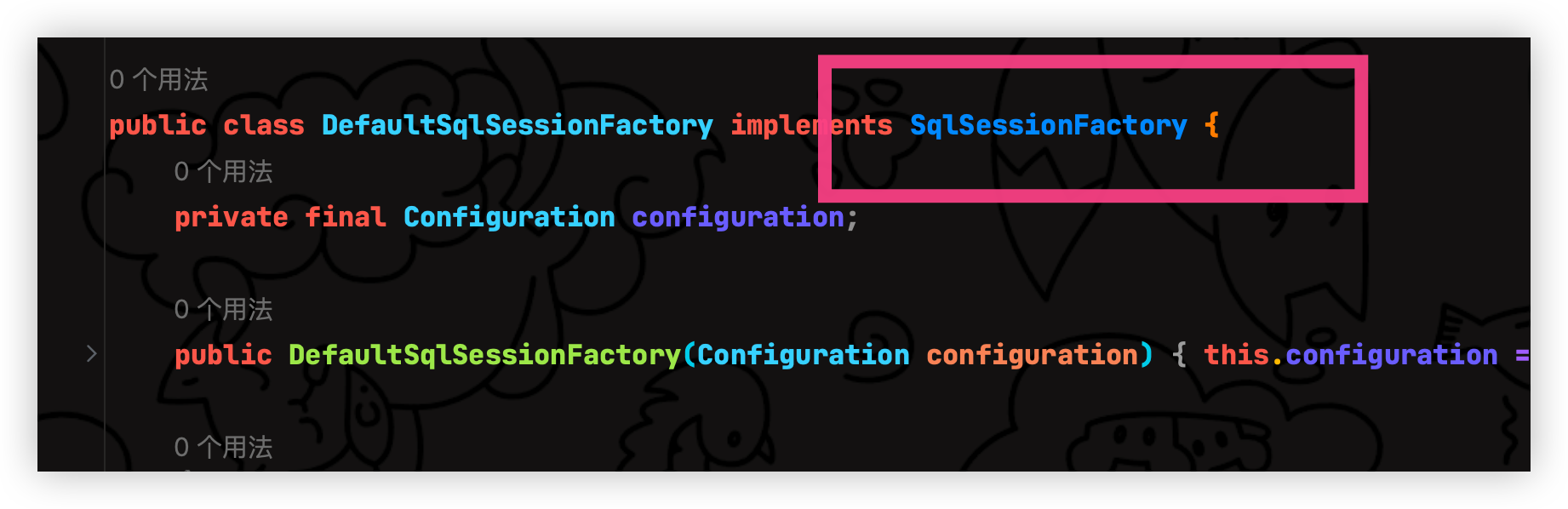
在openSession 方法当中可以看到调用 openSessionFromDataSource 创建了 DefaultSqlSession 默认的会话
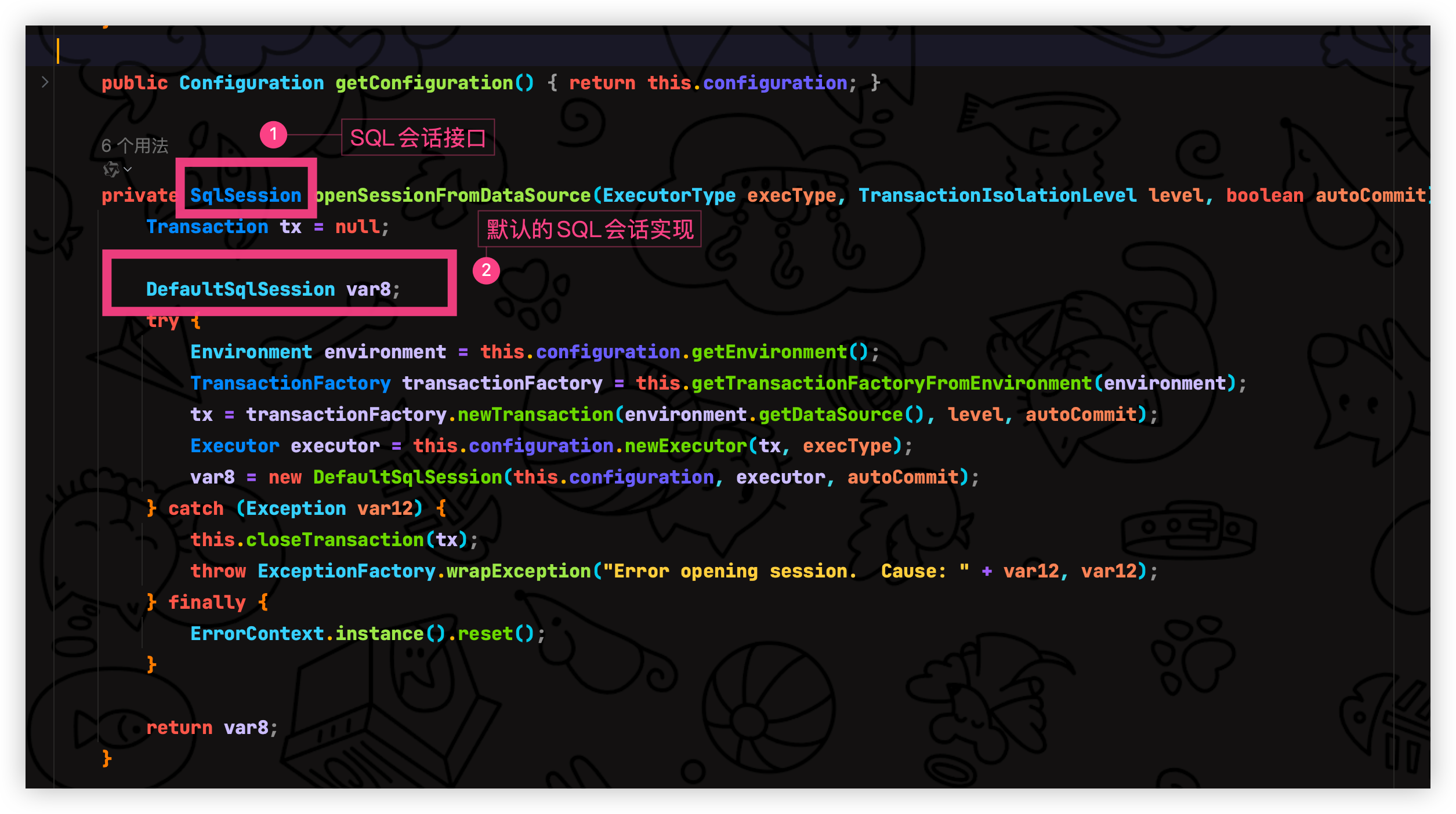
那么我们继续点 DefaultSqlSession 进去看看操作了什么?
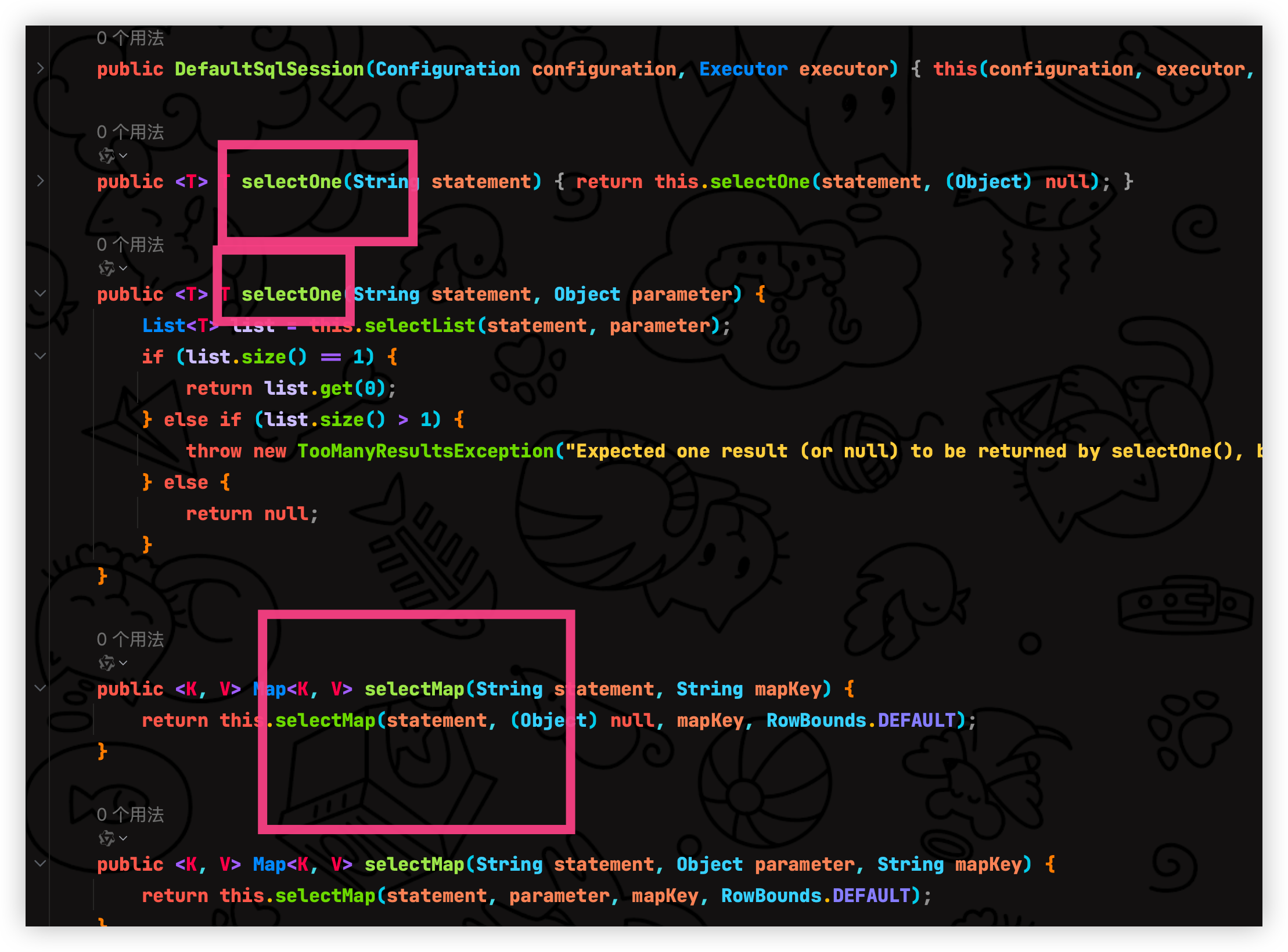
在 DefaultSqlSession 里面实现了 SqlSession 接口的方法
DefaultSqlSession 就相当于是最终实现功能的类, 我解析的就很简单,大佬们感兴趣的可以去看看源码
接下来我就根据mybatis的会话工厂模式来实现一个
参考 mybatis 结构,先定义出来在看看具体的关系

创建 OpenAiSessionFactory
- 首先我们需要一个会话工厂接口 OpenAiSessionFactory 里面有一个方法 openSession 返回参数为OpenAiSession接口(先看下面会提到)
在外层新增 session 文件夹表示会话功能

/**
* OpenAI会话工厂
*
* @author yangs
* @date 2024/01/18
*/
public interface OpenAiSessionFactory {
/**
* 开启会话
*
* @return {@link OpenAiSession}
*/
OpenAiSession openSession();
}请求参数构建参考官方的请求

我已经为大家搞好了 没必要自己再去操作
package com.yby6.yby6pandorachatgpt.domain.chatgpt;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonProperty;
import lombok.*;
import lombok.extern.slf4j.Slf4j;
import java.io.Serializable;
import java.util.List;
import java.util.Map;
/**
* 建造者模式 构建请求信息
* 请求信息依照;OpenAI官网API构建参数;<a href="https://platform.openai.com/playground">...</a>
*
* @author yangs
* @date 2024/01/18
*/
@Data
@Builder
@Slf4j
@JsonInclude(JsonInclude.Include.NON_NULL)
@NoArgsConstructor
@AllArgsConstructor
public class ChatGPTRequest implements Serializable {
/**
* 默认模型
*/
private String model = Model.GPT_3_5_TURBO.getCode();
/**
* 问题描述
*/
private List<ChatGPTResponse.ChoicesDTO.MessageDTO> messages;
/**
* 控制温度【随机性】;0到2之间。较高的值(如0.8)将使输出更加随机,而较低的值(如0.2)将使输出更加集中和确定
*/
private double temperature = 0.2;
/**
* 多样性控制;使用温度采样的替代方法称为核心采样,其中模型考虑具有top_p概率质量的令牌的结果。因此,0.1 意味着只考虑包含前 10% 概率质量的代币
*/
@JsonProperty("top_p")
private Double topP = 1d;
/**
* 为每个提示生成的完成次数
*/
private Integer n = 1;
/**
* 是否为流式输出;就是一蹦一蹦的,出来结果
*/
private boolean stream = false;
/**
* 停止输出标识
*/
private List<String> stop;
/**
* 输出字符串限制;0 ~ 4096
*/
@JsonProperty("max_tokens")
private Integer maxTokens = 2048;
/**
* 频率惩罚;降低模型重复同一行的可能性
*/
@JsonProperty("frequency_penalty")
private double frequencyPenalty = 0;
/**
* 存在惩罚;增强模型谈论新话题的可能性
*/
@JsonProperty("presence_penalty")
private double presencePenalty = 0;
/**
* 生成多个调用结果,只显示最佳的。这样会更多的消耗你的 api token
*/
@JsonProperty("logit_bias")
private Map logitBias;
/**
* 调用标识,避免重复调用
*/
private String user;
@Getter
@AllArgsConstructor
public enum Model {
/**
* gpt-3.5-turbo
*/
GPT_3_5_TURBO("gpt-3.5-turbo"),
/**
* GPT4.0
*/
GPT_4("gpt-4"),
/**
* GPT4.0 超长上下文
*/
GPT_4_32K("gpt-4-32k"),
;
private final String code;
}
}创建 OpenAiSession
- 定义OpenAiSession接口里面定义方法completions这个方法就是我们调用ChatGPT的方法 请求参数为 ChatGPTRequest 返回参数为我们之前定义的 ChatGPTResponse 用来接收返回的数据

package com.yby6.yby6pandorachatgpt.session;
import com.yby6.yby6pandorachatgpt.domain.chatgpt.ChatGPTRequest;
import com.yby6.yby6pandorachatgpt.domain.chatgpt.ChatGPTResponse;
/**
* OpenAi 会话接口
*
* @author yangs
* @date 2024/01/11
*/
public interface OpenAiSession {
/**
* 默认 GPT-3.5 问答模型
*
* @param chatGPTRequest 请求信息
* @return 返回结果
*/
ChatGPTResponse completions(ChatGPTRequest chatGPTRequest);
}创建DefaultOpenAiSessionFactory
- 接着我们实现 OpenAiSessionFactory 工厂接口 创建 DefaultOpenAiSessionFactory 默认会话工厂类 进行实现功能
我们看 mybatis 的结构把默认的单独管理起来 我们也一样 新增一个 defaults 文件夹

新增 DefaultOpenAiSessionFactory 实现类 实现 openSession 方法功能 这里的就是来管理会话开启

实现 openSession 方法功能, 该方法功能用于构建 okhttp 请求 创建 API 服务 并且创建默认会话统一返回,这样子一来我们就只需要开启一次会话即可避免重复创建 okhttp 请求, 思路如下
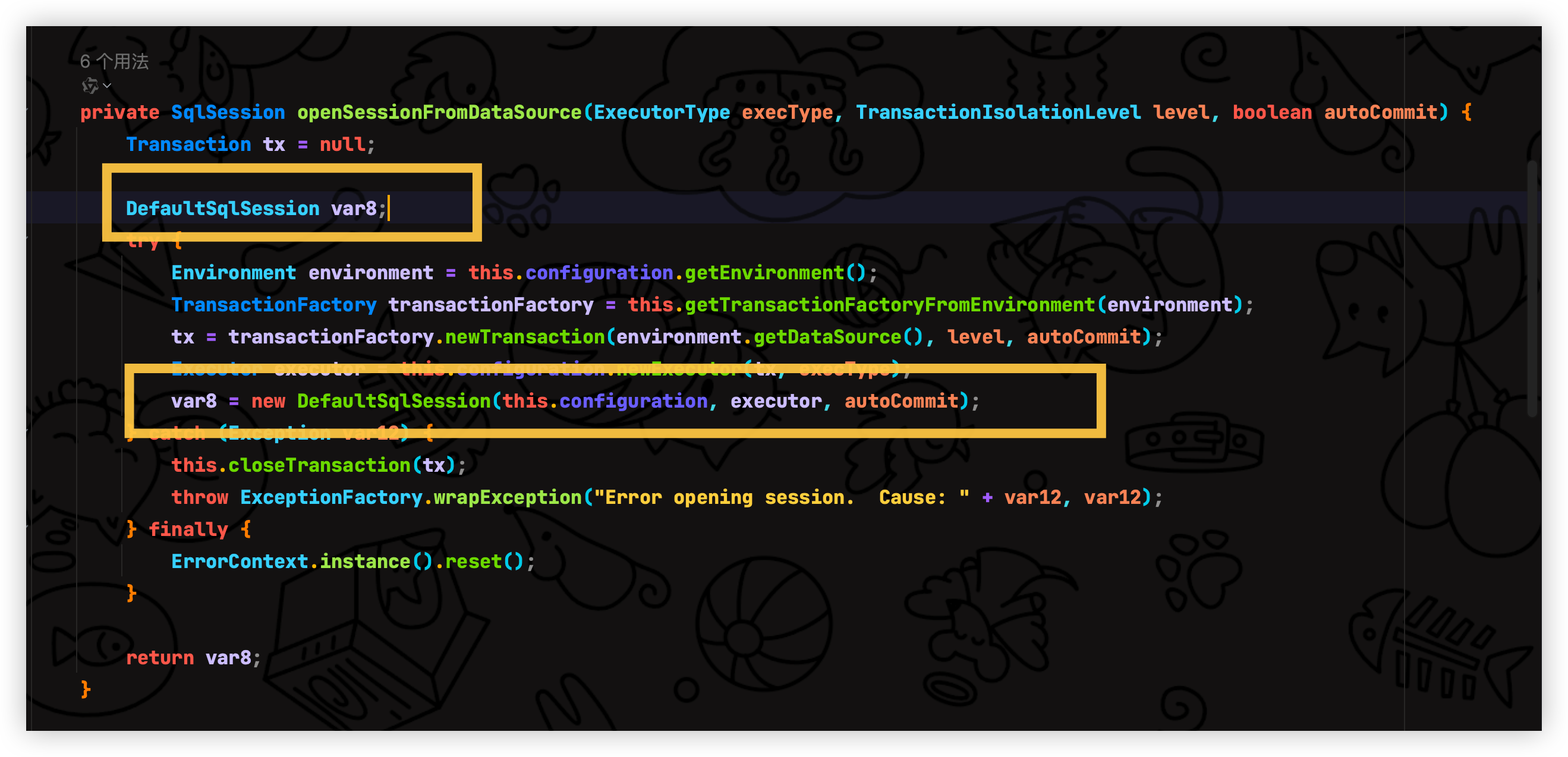
实现 openSession
我们首先实现 构建 OkHttpClient 并且需要进行拦截 okhttp 的请求给请求新增鉴权等一些请求参数
新增 OpenAiInterceptor OkHttp 请求拦截器
在infrastructure(基础设施)当中新增 interceptor 文件夹 新增 OpenAiInterceptor 拦截器
需要 open Session 传递apiKey 用于构建请求鉴权参数

package com.yby6.yby6pandorachatgpt.infrastructure.interceptor;
import cn.hutool.core.util.ObjectUtil;
import cn.hutool.http.ContentType;
import cn.hutool.http.Header;
import okhttp3.HttpUrl;
import okhttp3.Interceptor;
import okhttp3.Request;
import okhttp3.Response;
import org.jetbrains.annotations.NotNull;
import java.io.IOException;
/**
* 自定义 OpenAI 拦截器
*
* @author yangs
* @date 2024/01/18
*/
public class OpenAiInterceptor implements Interceptor {
/**
* OpenAi apiKey 需要在官网申请
*/
private final String apiKey;
public OpenAiInterceptor(String apiKey) {
this.apiKey = apiKey;
}
/**
* 拦截okhttp请求
* @param chain 链
* @return 是否继续执行
*/
@NotNull
@Override
public Response intercept(Chain chain) throws IOException {
return chain.proceed(this.auth(apiKey, chain.request()));
}
/**
* 构建认证请求对象
*
* @param apiKey api密钥
* @param original 起初
* @return {@link Request}
*/
private Request auth(String apiKey, Request original) {
HttpUrl.Builder builder = original.url().newBuilder();
// 构建新的请求地址
HttpUrl url = builder.build();
// 创建请求
return original.newBuilder()
.url(url.url())
.header(Header.AUTHORIZATION.getValue(), "Bearer " + apiKey)
.header(Header.CONTENT_TYPE.getValue(), ContentType.JSON.getValue())
.method(original.method(), original.body())
.build();
}
}构建 OkHttpClient 并且添加拦截器配置请求参数

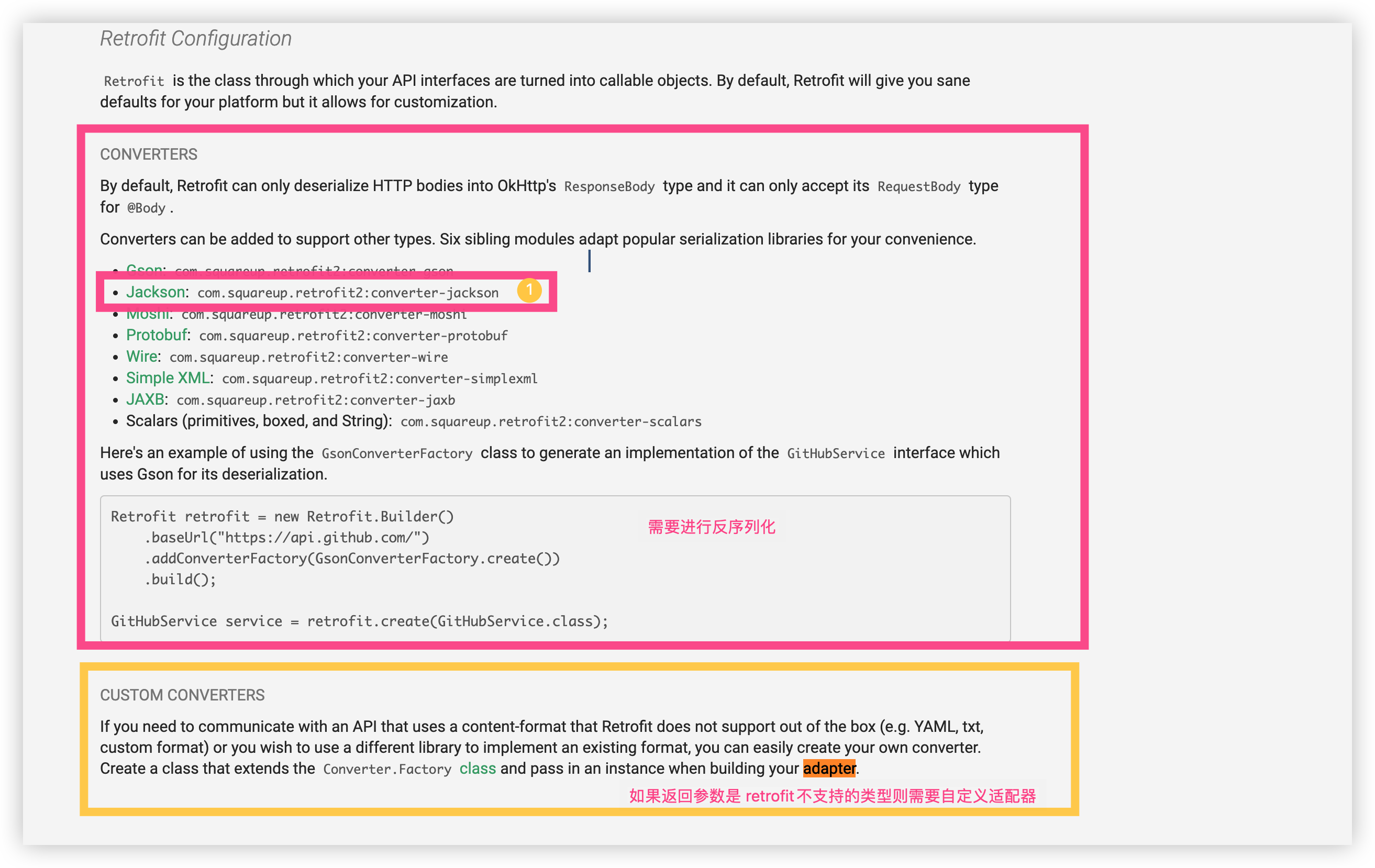
基本的配置我们已经编写完毕,接下来就是编写 创建 API 请求服务, 我们需要使用 Retrofit 2 来配合 OKHTTP 那么接下来我详细介绍 Retrofit 2 是什么以及基础用法
认识Retrofit 2
Retrofit2 是一个用于 Android 和 Java 的类型安全的 HTTP 客户端,它可以轻松地实现 RESTful API 的调用
github 地址: https://github.com/square/retrofit
官方文档使用方法 地址: https://square.github.io/retrofit/

引入 Retrofit2 依赖
<!-- http api 转 Java 接口 -->
<dependency>
<groupId>com.squareup.retrofit2</groupId>
<artifactId>retrofit</artifactId>
<version>2.9.0</version>
</dependency>
<!-- 序列化用 -->
<dependency>
<groupId>com.squareup.retrofit2</groupId>
<artifactId>converter-jackson</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>com.squareup.retrofit2</groupId>
<artifactId>adapter-rxjava2</artifactId>
<version>2.9.0</version>
</dependency>根据上面的图片当中定义了 GithubService 接口 我们也一样 定义 OpenAiService 接口 ,在 DDD架构当中的应用层新增接口

/**
* ChatGPT 请求接口 API
* 官网:<a href="https://platform.openai.com/playground">...</a>
*
* @author Yang Shuai
* Create By 2024/1/19
*/
public interface OpenAiService {
/**
* 默认 GPT-3.5 问答模型
*
* @param chatGPTRequest 请求信息
* @return 返回结果
*/
@POST("v1/chat/completions")
Call<ChatGPTResponse> completions(@Body ChatGPTRequest chatGPTRequest);
}
创建 API 服务请求
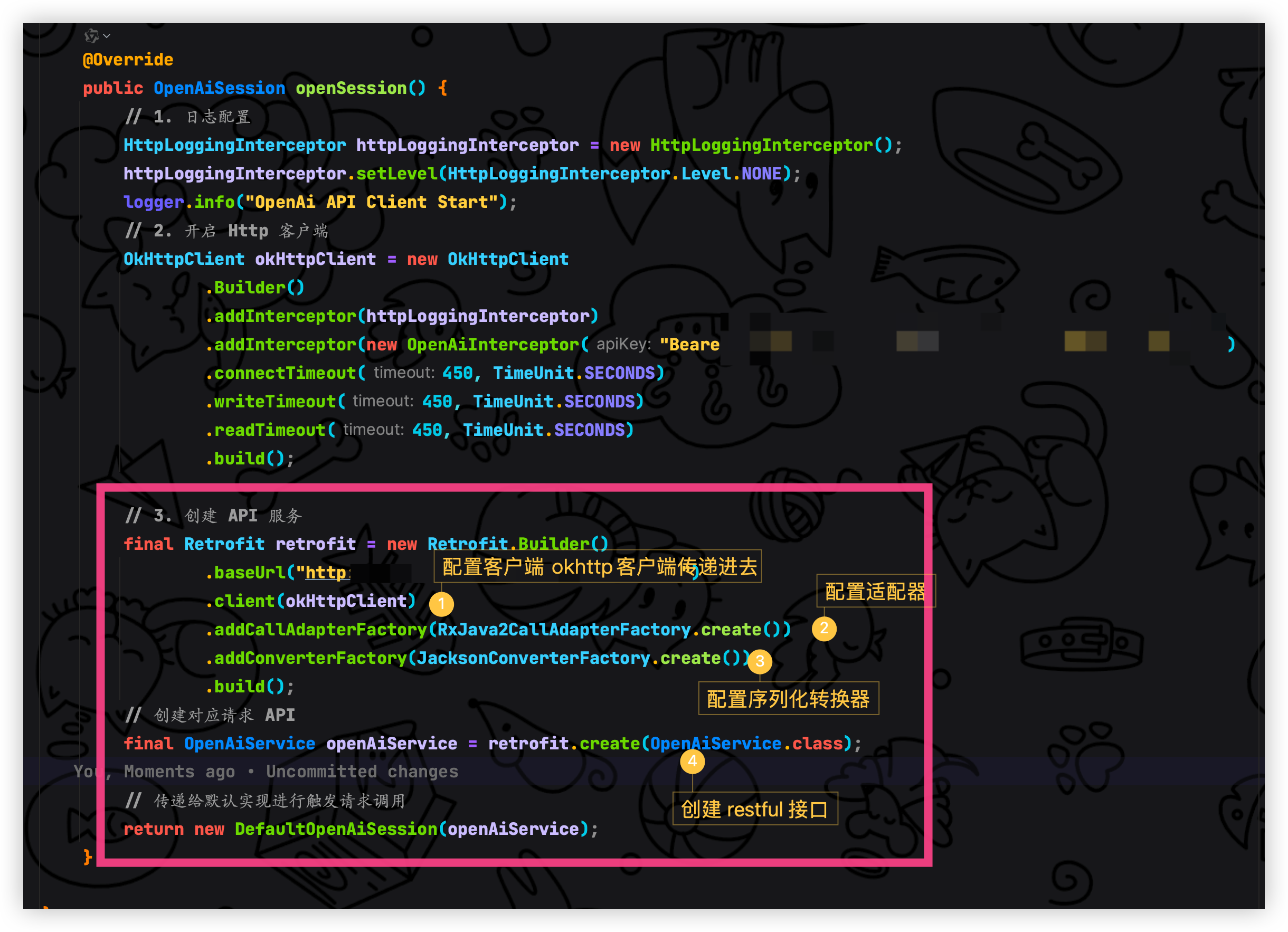
/**
* 开启会话
*
* @return {@link OpenAiSession}
*/
@Override
public OpenAiSession openSession() {
// 1. 日志配置
HttpLoggingInterceptor httpLoggingInterceptor = new HttpLoggingInterceptor();
httpLoggingInterceptor.setLevel(HttpLoggingInterceptor.Level.NONE);
logger.info("OpenAi API Client Start");
// 2. 开启 Http 客户端
OkHttpClient okHttpClient = new OkHttpClient
.Builder()
.addInterceptor(httpLoggingInterceptor)
.addInterceptor(new OpenAiInterceptor("你的api key"))
.connectTimeout(450, TimeUnit.SECONDS)
.writeTimeout(450, TimeUnit.SECONDS)
.readTimeout(450, TimeUnit.SECONDS)
.build();
// 3. 创建 API 服务
final Retrofit retrofit = new Retrofit.Builder()
.baseUrl("IP") // 你的潘多拉访问IP
.client(okHttpClient)
.addCallAdapterFactory(RxJava2CallAdapterFactory.create())
.addConverterFactory(JacksonConverterFactory.create())
.build();
// 创建对应请求 API
final OpenAiService openAiService = retrofit.create(OpenAiService.class);
// 传递给默认实现进行触发请求调用
return new DefaultOpenAiSession(openAiService);
}ok 了初始化 openSession 编写完毕接下来就是实现默认的会话支持,该方法当中就是进行业务层调用东西处理逻辑(相当于 service)
创建DefaultOpenAiSession 默认会话
创建一个默认的会话来实现 OpenAiSession 接口方法提供请求调用

并且把 session 文件夹全部移动到 domain , session 应该是属于 domian 领域层实现业务

实现请求发起

/**
* 默认的 OpenAI 会话实现OpenAiSession
*
* @author Yang Shuai
* Create By 2024/1/19
*/
@RequiredArgsConstructor
public class DefaultOpenAiSession implements OpenAiSession {
private final OpenAiService openAiService;
/**
* 默认 GPT-3.5 问答模型
*
* @param chatGPTRequest 请求信息
* @return 返回结果
*/
@Override
public ChatGPTResponse completions(ChatGPTRequest chatGPTRequest) throws IOException {
return openAiService.completions(chatGPTRequest).execute().body();
}
}初始化 OpenAI 会话工厂开启会话

/**
* @author Yang Shuai
* {@code @create} 2024/1/16:17:48
* {@code @desc} |
**/
@Configuration
@RequiredArgsConstructor
public class initializeOpenAISession {
private final Logger logger = LoggerFactory.getLogger(initializeOpenAISession.class);
/**
* 初始化会话工厂
*/
@Bean("openAiSession")
public OpenAiSession openAiSession() {
logger.info("初始化请求配置文件");
// 2. 会话工厂
OpenAiSessionFactory factory = new DefaultOpenAiSessionFactory();
// 3. 开启会话
logger.info("开启会话 openAiSession");
return factory.openSession();
}
}最终的实现
- 构建消息
在 messageDto 当中新增了建造者模式
@NoArgsConstructor
@Data
public static class MessageDTO {
@JsonProperty("role")
private String role;
@JsonProperty("content")
private String content;
/**
* 构造器 构建角色、内容
*/
private MessageDTO(MessageDTO.Builder builder) {
this.role = builder.role;
this.content = builder.content;
}
public static MessageDTO.Builder builder() {
return new MessageDTO.Builder();
}
/**
* 建造者模式
*/
public static final class Builder {
private String role;
private String content;
public Builder() {
}
public MessageDTO.Builder role(Constants.Role role) {
this.role = role.getCode();
return this;
}
public MessageDTO.Builder content(String content) {
this.content = content;
return this;
}
public MessageDTO build() {
return new MessageDTO(this);
}
}
}- 构建请求参数
新增常量类 Constants 定义请求角色
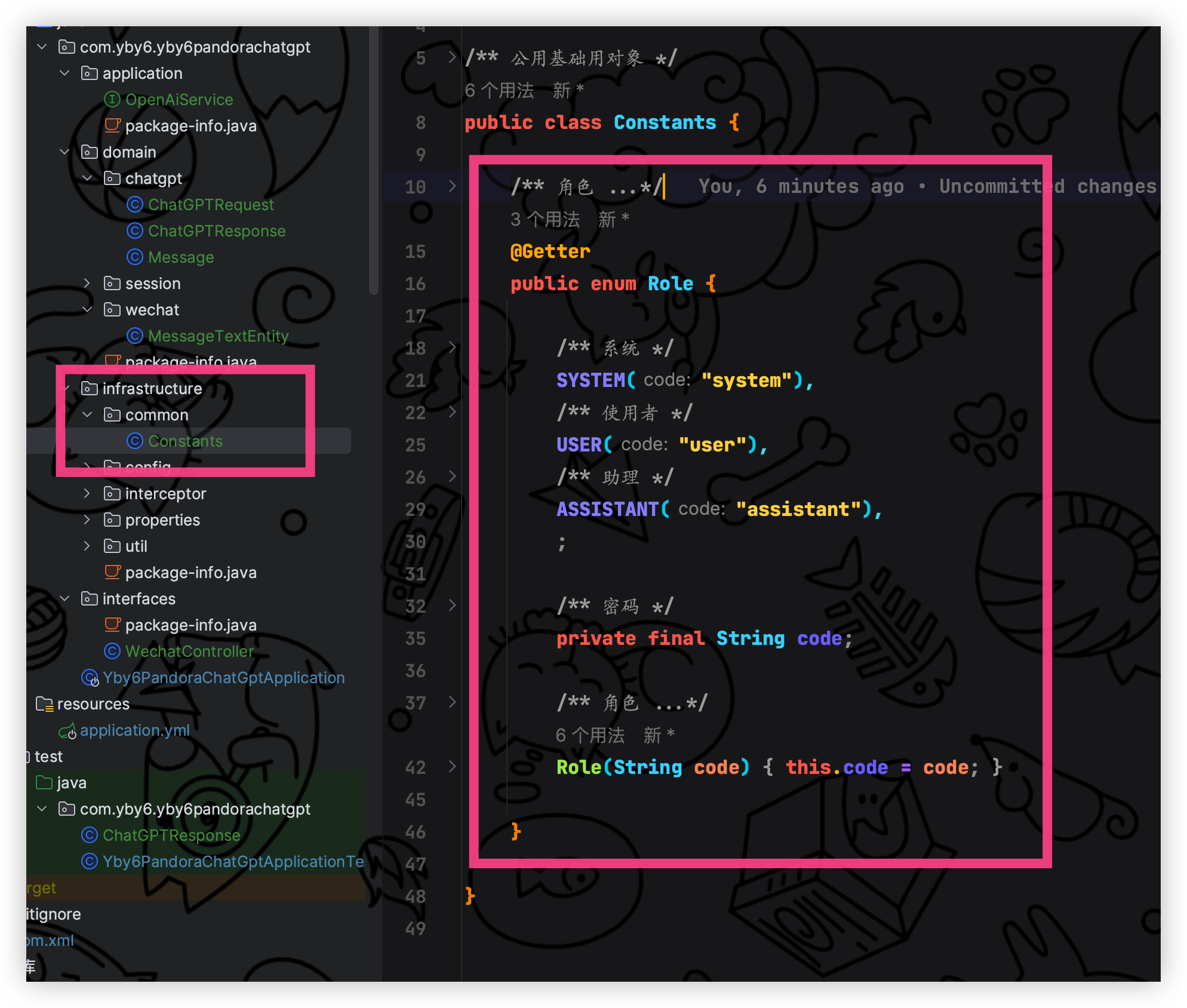
/**
* 公用基础用对象
*/
public class Constants {
/**
* 角色
* 官网支持的请求角色类型;system、user、assistant
* <a href="https://platform.openai.com/docs/guides/chat/introduction">...</a>
*/
@Getter
public enum Role {
/**
* 系统
*/
SYSTEM("system"),
/**
* 使用者
*/
USER("user"),
/**
* 助理
*/
ASSISTANT("assistant"),
;
/**
* 密码
*/
private final String code;
/**
* 角色
*
* @param code 密码
*/
Role(String code) {
this.code = code;
}
}
}- 拿到 gpt 返回的结果并且进行转为 XML 返回给微信服务器发送给用户
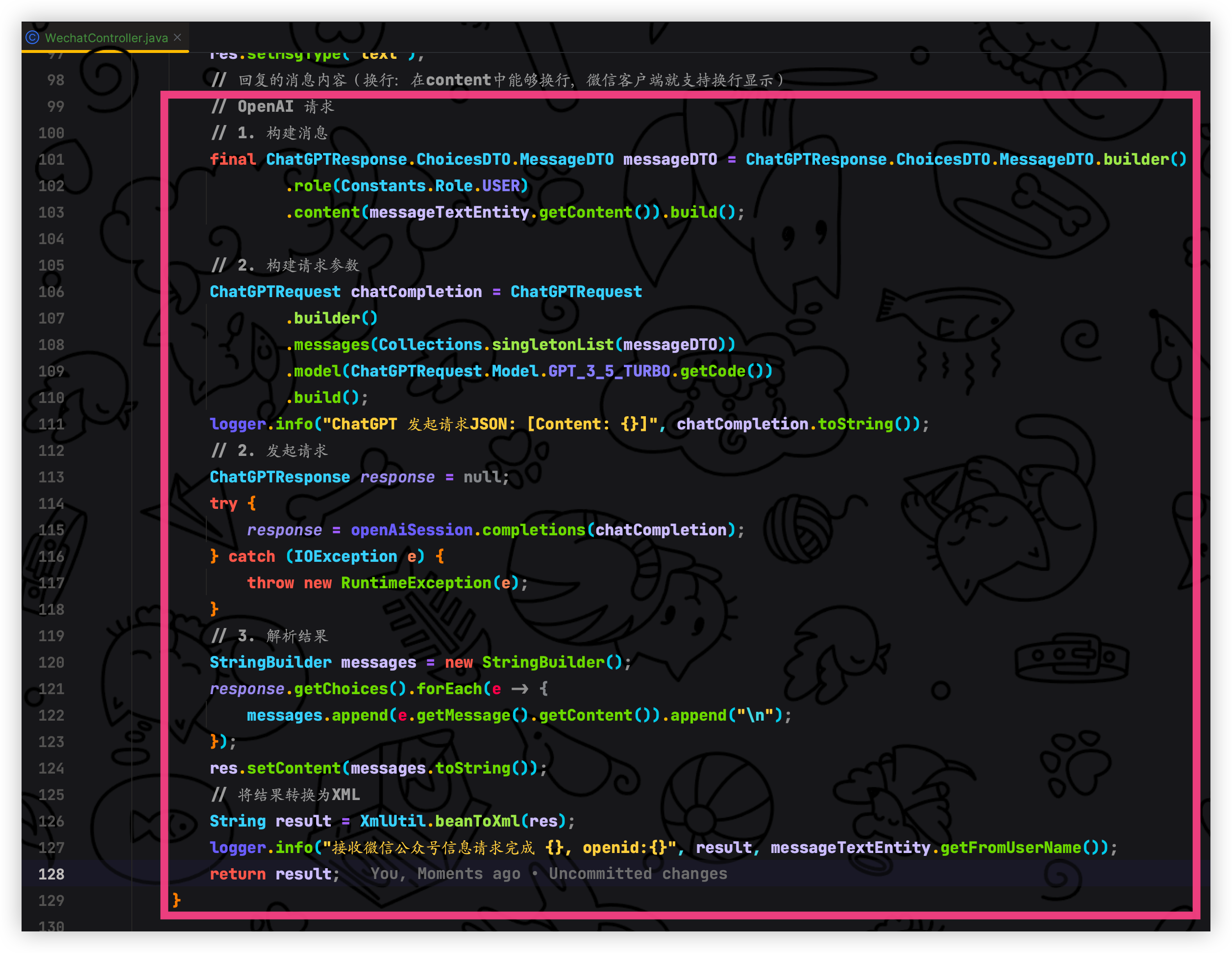
可以把 sendChatGPT 代码删除了
测试
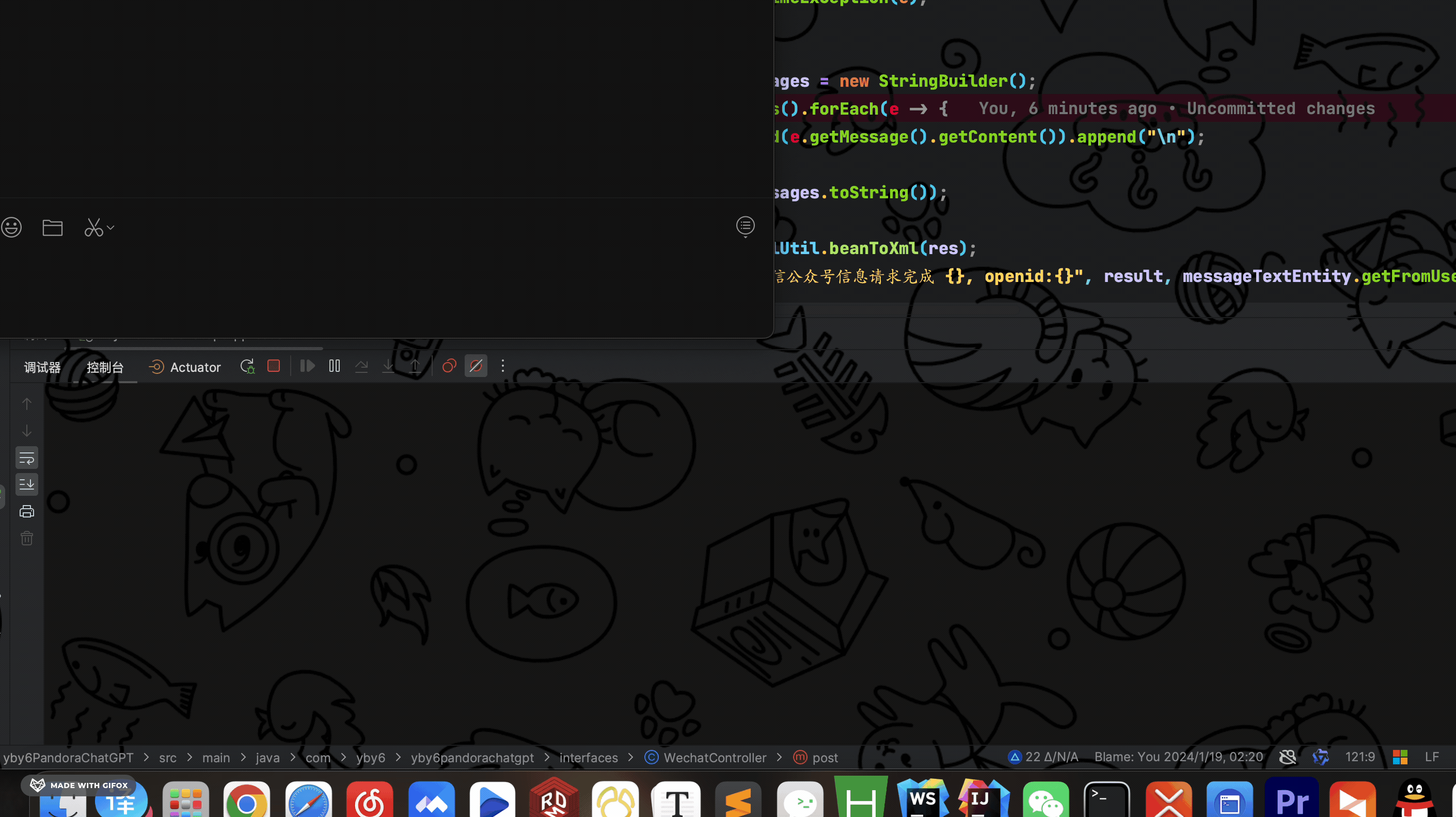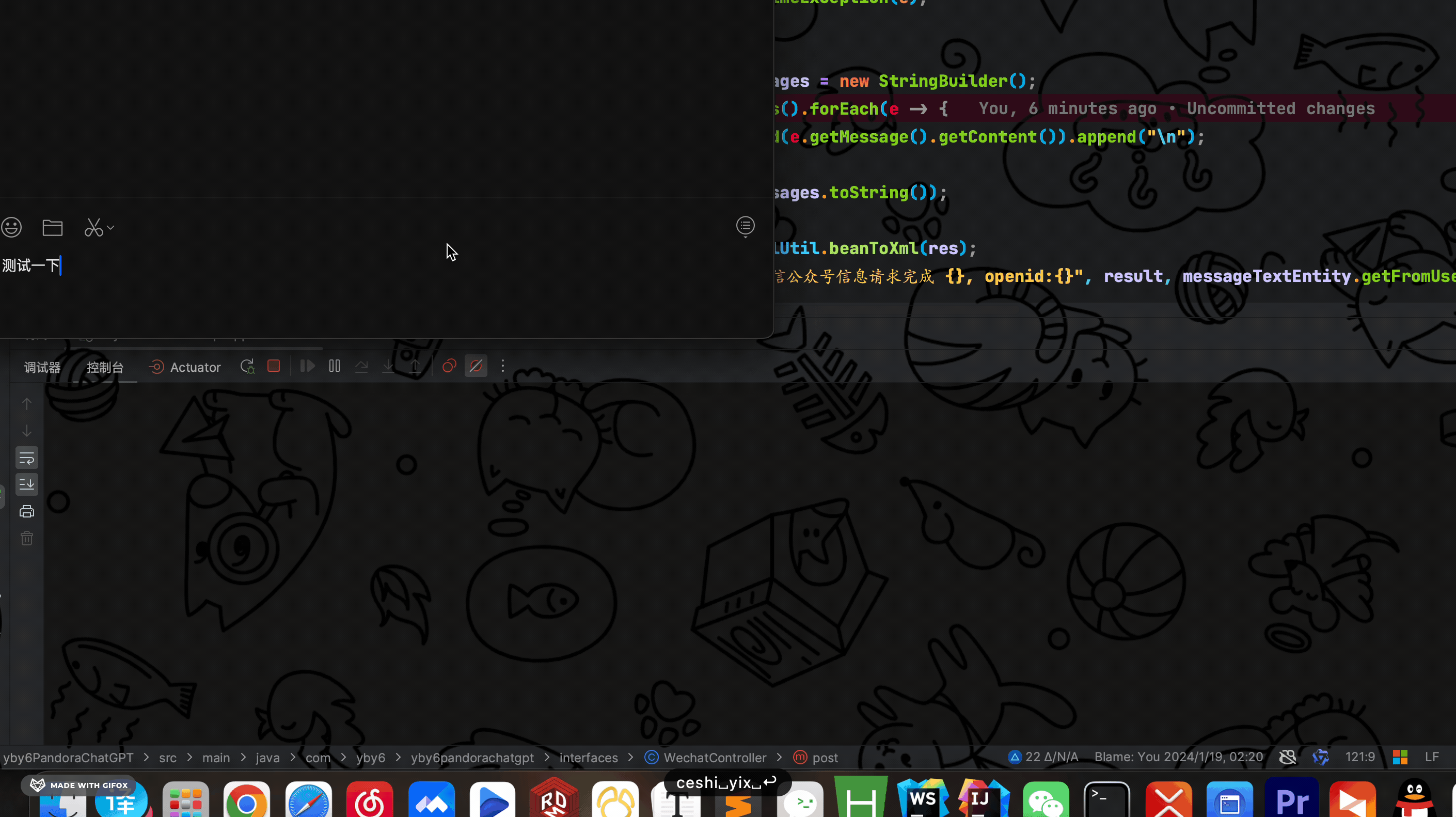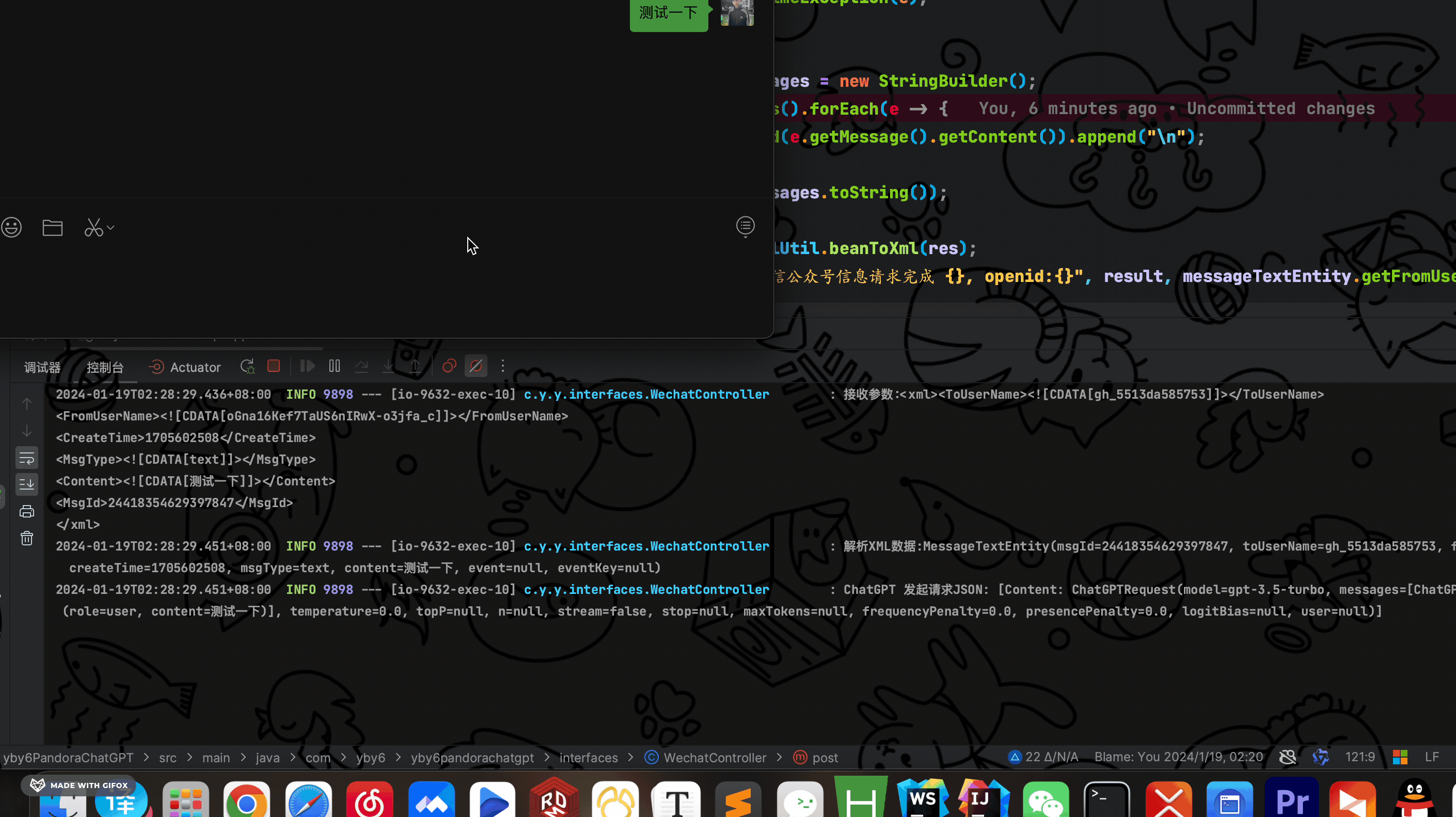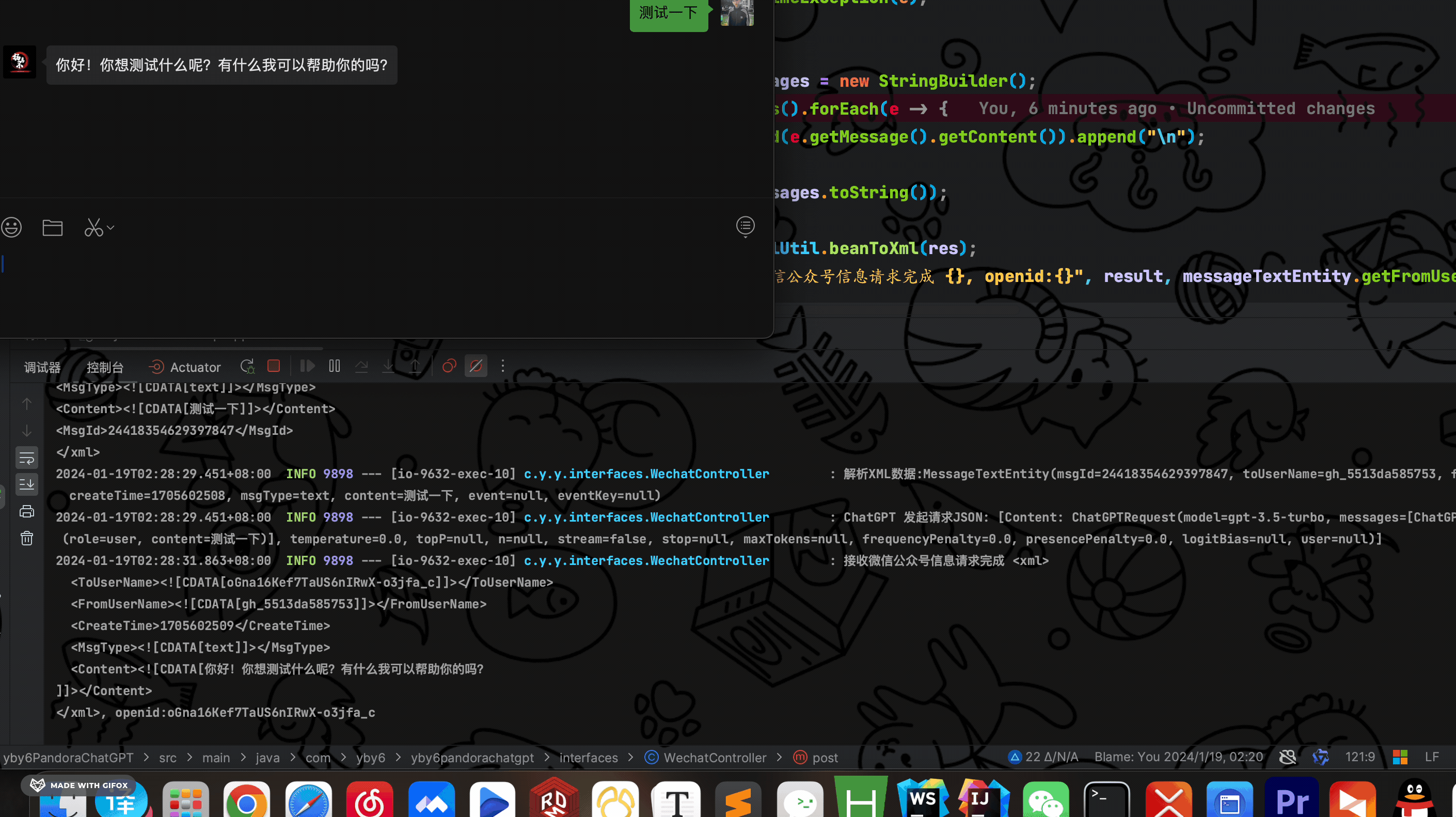
开启内网穿透、开启后端服务,测试 Retrofit 是否调用成功
此时是凌晨 2 点 30 分累死啦,看到这里啦麻烦点个赞支持一下! 谢谢啦
ok, 现在就大功告成! so easy to happy 真的就切菜一样
此时是凌晨 2 点 30 分累死啦,看到这里啦麻烦点个赞支持一下! 谢谢啦
最后
不要觉得这就完毕啦, 目前虽然是可以正常但是如果提问的东西 GPT 回复的很慢超过了微信回复的重试阶段就会报错,那么这里就需要在进行调整啦,不过也很简单,在本地新增一个缓存,缓存当中进行保存任务Future<String>,这个任务由线程池管理,任务执行完毕之后返回String结果.但是在执行的过程中可能会发生微信超时所以我们需要判断一下是否超过了微信的重试次数一共是三次每次五秒那么实在是超过了三次则返回用户让他在输入任意文字后继续之前的操作, 相当于重新进来了,这个时候在判断一层已经存在这个问题任务则不创建新的任务等待上一个任务完成返回给用户.
? 关注我不迷路,如果本篇文章对你有所帮助,或者你有什么疑问,欢迎在评论区留言,我一般看到都会回复的。大家点赞支持一下哟~ ?
图片
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。