我独到的技术见解:LLM的演进与发展
原创
2024年已经过去快两个月了,是时候对2023年get的新技术进行一次的沉淀和总结了。
在2023年,大语言模型(LLM)无疑是AI领域中最热门的话题。在我的专栏中,已经陆陆续续发表了几篇文章,这些文章零星地记录了关于LLM的实践和思考。本文主要是对LLM的想法进行一次全面的梳理和整合。我希望这次的技术沉淀不仅是我个人的梳理和沉淀,也能为刚踏入AI领域的新手以及已在AI行业工作的同行们提供一些参考和帮助。
下面会从以下几个方面进行梳理:
1. 什么是LLM?
2. LLM为什么会出现?openAI是偷偷摸摸憋大招,让LLM横空出世,还是一步步在大家眼皮底下茁壮成长起来的起来的?
3. LLM为什么起作用?为什么大模型如此牛逼?是科技还是玄学?
4. 我们应该如何使用LLM?好好写prompt就行?还是不管三七二十一,有钱任性!买卡!训练!?
5. LLM的未来方向是什么?
1 什么是LLM?
铺天盖地的LLM新资讯,LLM到底是什么?
首先,大模型和大语言模型是两回事。
我们通常说的LLM是Large Language Model。
先不关心large不large,我们先了解语言模型主要能解决哪些问题?

LLM也是语言模型,他其实同样也是解决这些问题,只不过之前是一个模型解决一个问题,LLM是一个模型可以解决上面所有问题。
算法解决方案的进阶:
all in one?这又是什么玄学思路?相信科学!其实LLM也不是突然出现的,万事都有因可归,看一下语言模型算法的timeline:

(1)在1966年,语言模型就已经出现了,ELIZA是基于模版匹配的一个“智能系统”。模版匹配这个思路即使是现在有些问答系统中也会使用;
(2)1980s~1990s只要是基于统计的语言模型;
(3)2000s硬件发展起来,算法也有新的突破神经网络开始发展,前期神经网络在CV应用上十分火热,NLP相对发展缓慢,主要技术是RNN以及各种变体优化来解决NLP任务;
(4)快进到2017年,Transformer出现, 2018年BERT出现,NLP开始崛起;
(5)接下来就是快速迭代的GPT系列:
在GPT2论文中openAI就提出GPT2具有zero_shot能力,也就是说具体下游任务任务相关的信息,可以通过具体下游任务任务无关的无监督预训练过程学习,而不需要去通过有监督学习下游任务。在执行下游任务是,给出提示词就可以。只不过当时GPT2的效果不太好。另外openAI还发现一个很重要的现象,随着模型参数的增加,Zero-Shot 的性能一直是在上升的。说明提升参数规模是有正向作用的;
GPT3提出了一个重要概念in-context learning,ICL上下文学习:
ICL 包含三种分类:
Few-shot learning,允许输入数条示例和一则任务说明;
One-shot learning,只允许输入一条示例和一则任务说明;
Zero-shot learning,不允许输入任何示例,只允许输入一则任务说明。
结果显示 ICL 不需要进行反向传播,仅需要把少量标注样本放在输入文本的上下文中即可诱导 GPT-3 输出答案。ICL可以理解为一种隐式的学习,在输入中就已经给了LLM一定的信息。ICL就是一种prompt。
模型 | 发布时间 | 参数量 | 预训练数据量 |
|---|---|---|---|
GPT | 2018 年 6 月 | 1.17 亿 | 约 5GB |
GPT-2 | 2019 年 2 月 | 15 亿 | 40GB |
GPT-3 | 2020 年 5 月 | 1,750 亿 | 45TB压缩->570G |
ChatGPT | 2022年3月 | 千亿级别? | 百T级别? |
通过GPT系列也能看出,openAI一直在增加参数量和训练数据量。为什么?因为他们发现提升这两个因素,模型效果有提升啊。
其实这段时间除了openAI,其他很多公司也在逐步推出LLM。
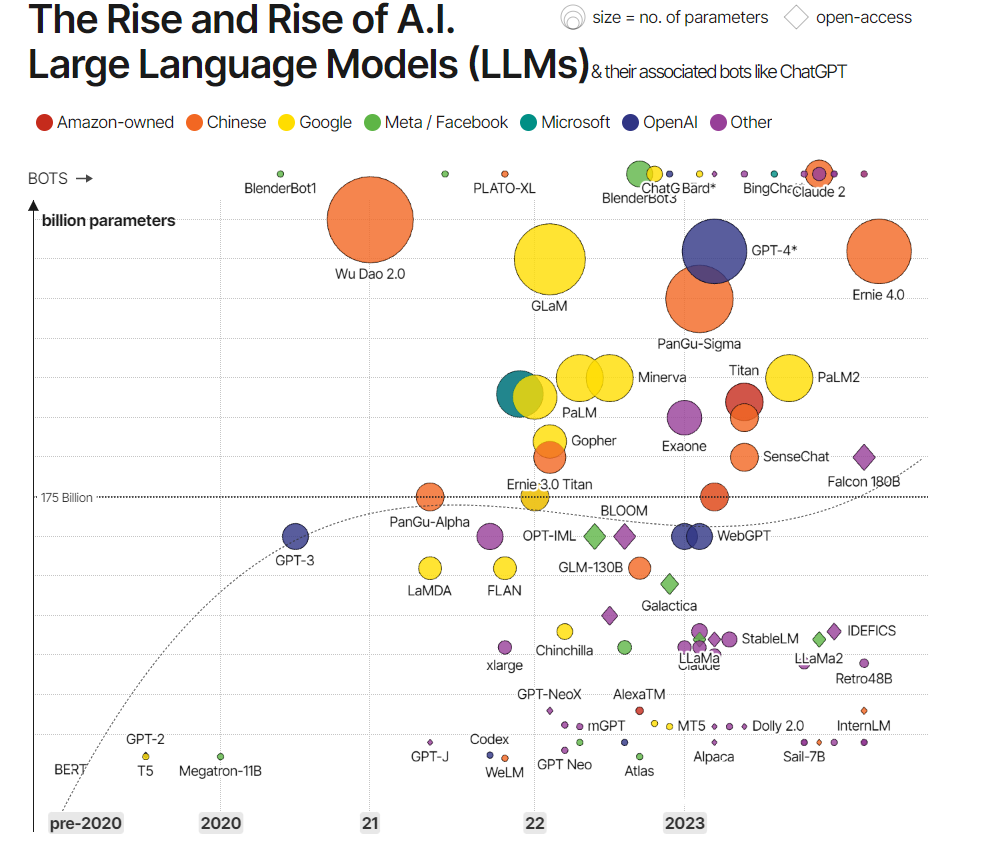
我认为openAI的语言模型模型成了爆款,除了技术外,另外一个重要原因是他将GPT转成了ChatGPT,产品形式让所有人都可以方面的进行对话体验,再加上大力宣传,将LLM推到了大家眼前,让大家都认知了LLM。
2 LLM为什么能出现?
所有人都知道LLM成本高,为什么openAI愿意持续投入人力财力呢?什么原因让openAI押注这条路一定会成功?
我们先一起看看训练,以175B的模型为例:

175B*6是训练Flops(每秒浮点运算数),分母是每台机器(TPUv4芯片,FLOPS利用率为46.2%)*每台机器每小时成本8.12美元 * 数据集是300B个token。
我们可以假设ChatGPT是175B的模型,来预算下模型成本。
国盛证券估算,今年1月平均每天约有1300万独立访客使用ChatGPT,对应芯片需求为3万多片英伟达A100GPU,初始投入成本约为8亿美元,每日电费在5万美元左右:
英伟达DGXA100 | 单机搭载8片A100GPU | 19.9万美元/台 |
|---|---|---|
标准机柜 | 约7个DGXA100服务器 | 140万美元 |
假设每日约有2.5亿次咨询量,每个问题平均30字,单个字在A100GPU上约消耗350ms,则一天共需消耗729,167个A100GPU运行小时,对应每天需要729,167/24=30,382片英伟达A100GPU同时计算,才可满足当前ChatGPT的访问量。也就是需要30,382/8=3,798台服务器,对应3,798/7=542个机柜。为满足ChatGPT当前千万级用户的咨询量,初始算力投入成本约为542*140=7.59亿美元。
再看能源消耗:542*45.5kw*24h=591,864kwh/日。参考HashrateIndex统计,假设美国平均工业电价约为0.08美元/kwh。则每日电费约为2,369,640*0.08=4.7万美元/日。

所有抛开其他比如人力成本,商业宣传等成本,仅仅说训练接训练这块,openAI准备了8亿美元。
当然微调成本就降低很多,也可以大致估算:
使用价格:GPT-3.5 Turbo的微调成本分为初始训练成本和使用成本两部分。一个包含100K tokens训练文件的微调工作,预计成本为2.4美元。具体来说,
训练:$0.008 / 1K tokens;
使用输入:$0.012 / 1K tokens;
使用输出:$0.016 / 1K tokens。
投入至少8亿欢迎chatGPT,openAI哪来来的自信一定会大力出奇迹?为什么相信投入这么多钱的模型一定有效果呢?因为有GPT系列模型的验证,以及scaling law理论和实践给的底气。所以从GPT1出现,openAI就已经在为今年的GPT4或者即将出现的GPT5,或者LLM OS,或者更大的产品做准备了,他绝对不是突然出现。
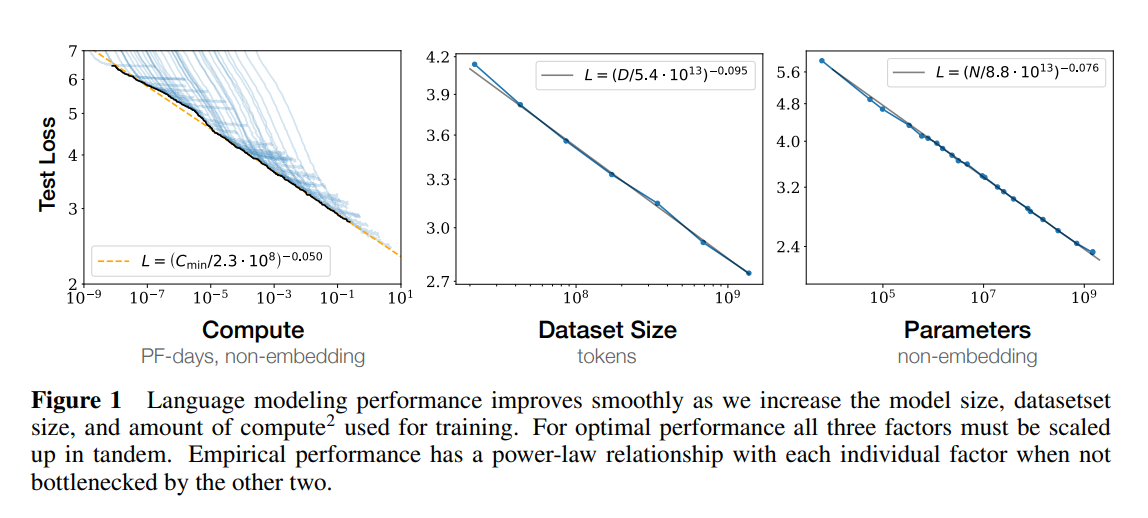
在论文Scaling Laws for Neural Language Models中,OpenAI提出了大语言模型遵循scaling law。如上图,OpenAI通过研究证明,当我们增加参数规模、数据集规模和延长模型训练时间,大语言建模的性能就会提高。并且,如果独立进行,不受其他两个因素影响时,大模型性能与每个单独的因素都有一个幂律关系,体现为Test Loss的降低,也就是模型性能提升。(GPT系列也认证了这一点)
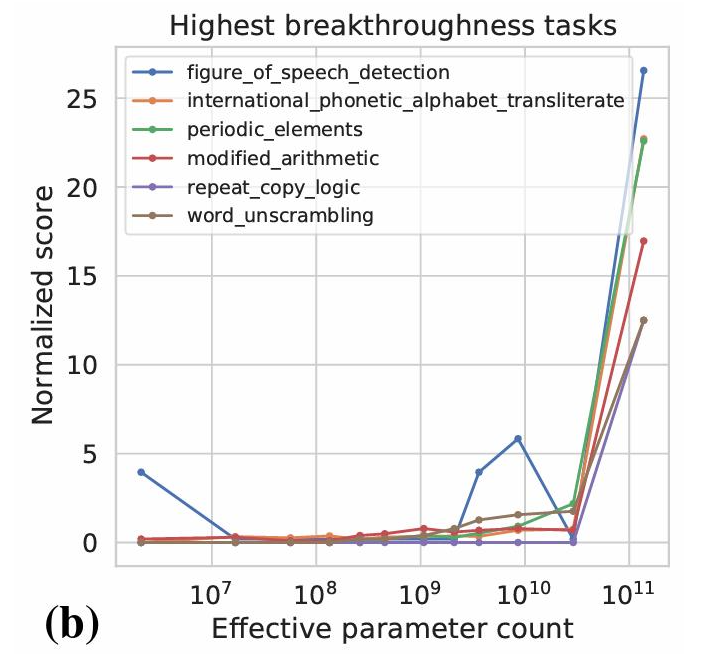
在上一步的基础上,第二类就是涌现出新能力。具体体现为,在模型参数规模不够大时,AI的能力表现非常一般,准确性几乎是随机的。但是当模型规模和计算力都推进到一定规模之后,AI的能力突然急剧增长。经过分析,这类能力也有一个共性,就是这类任务都是由多个步骤构成的一个复杂任务,比如语词检测、国际音标音译、周期性运算、修正算术、单词解读等等。
3 LLM为什么能起作用?
前面讨论过LLM是能够一个模型解决多种任务,如果GPT3存在很多一本正经的胡说八道的问题,chatGPT在幻觉方面已经有很大改善。根据openAI的研究也证实,数据,参数规模,训练时长能够给LLM带来正向效果。那为什么LLM能够起作用呢?我们可以看看instructGPT的训练流程。

这里我们还可以看出,LLM还是和人类标准的对齐的 过程,还没有自主学习超越人类的能力。

第0步,爬取10TB的高质量文本数据,在6000多张GPU卡上消耗200W美元,无监督学习训练12天,得到一个语言模型。这个模型相当于获取了各个领域的基础知识,他看了很多书,但是还不懂怎么和人对话交流。这个基础模型的训练成本很高,但是他的知识是有时效性的,所以间隔一段时间需要更新一次。
第1步,编写大约10W条高质量指令问答对,基于语言模型进行微调,教会模型如何将知识通过问答方式和人类交流。通过验证集重复这个过程,迭代优化数据分布和问答数据,让模型更懂如何推理和回答。
第2步,收集一些问题,让微调过得懂得交流的模型重复生成多个答案,然后让数据标注人员给生成答案进行打分,训练一个奖励模型,让模型和人类喜好对齐。
第3步,基于强化学习和PPO2策略迭代优化模型,让模型学习人类。
所以,大规模的训练数据(知识),大规模的参数量(记忆),强大的Transformer算法(推理和决策),像人类对齐(LR),不断学习(算力)多种因素让LLM强大,同时它还在不断的迭代优化。
庆幸的是,openAI的创始人也指出目前LLM还只具备学习人类,并没有自主学习超越人类的能力,这里我在后面会解释。
4 如何使用LLM?
那我们应该使用大模型呢?不管是之前的机器学习,还是后来的深度学习模型,不管是小模型还是大模型,模型都只是一个工具。我们首先要学会的是如何使用工具。
对于这个工具的使用,我认为可以按如下流程选择使用方案

4.1 prompt工程
不需要每个人都要有AI知识,但是每个人都需要学习如何使用这个工具。
LLM的呈现形式就是对话,你提问,他回答。你随口一问,他随口一答,你告诉他详细的需求,他可能给出满意的回复。所以如何利用好这个工具也是一大难题。
prompt就是给AI的指令,引导模型生成响应的回答,最大化挖掘LLM的能力。
prompt工程就是开发和优化提示词,一种在大模型中使用的技巧,通过提供清晰、简洁的指令或问题,充分发挥大模型的能力,让模型更好地理解我们的需求,从而得到更好的模型输出。
吴恩达教授在提示语工程公开课中提出四大元素,两大原则:


prompt工程也有很多方法论,我们简单介绍几种常用思路:
思维链(CoT)

思维树
以树状形式展开思维链。 允许回溯,探索从一个基本想法产生的多个推理分支。
思维树提示方法,通过主动维护了一个思维树,其中每个“思维”都是一个连贯的语言序列,作为解决问题的中间步骤。
它允许语言模型(LM)通过一种用语言实例化的谨慎推理过程,来自我评估不同中间思维在解决问题方面的进展。
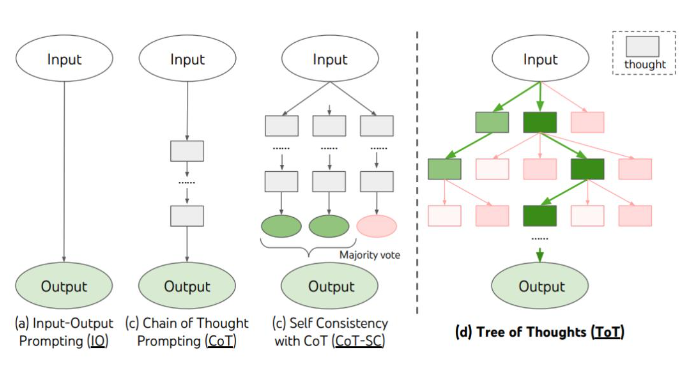
思维图
将思想概念化为有向无循环图(DAG)中的顶点。 能够对这些想法进行转换(聚合、精化、生成)。
在进行思考时,人类不会像 CoT 那样仅遵循一条思维链,也不是像 ToT 那样尝试多种不同途径,而是会形成一个更加复杂的思维网。举个例子,一个人可能会先探索一条思维链,然后回溯再探索另一条,然后可能会意识到之前那条链的某个想法可以和当前链结合起来,取长补短,得到一个新的解决方案。类似地,大脑会形成复杂的网络,呈现出类似图的模式,比如循环模式。算法执行时也会揭示出网络的模式,这往往可以表示成有向无环图。
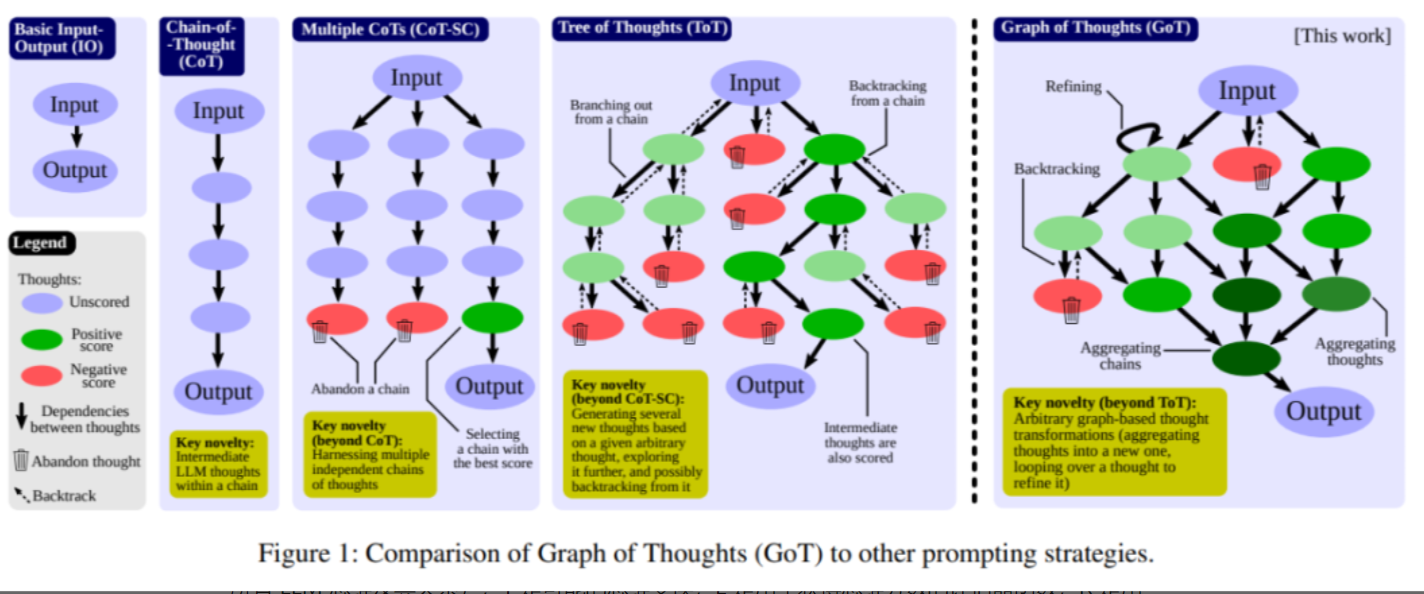
思维算法
通过不断演化和改进思考过程 维持一个单一的不断发展的思维上下文链。
如何不是AI行业的从事人员,我们至少要学会如何写prompt,如何使用好这个工具。更多模型微调这些事情就交给算法研究员去干就好,但是大家拿到工具后至少也需要了解如何使用~
4.2 RAG
当然prompt只能解决一些通用知识,我们是通过prompt挖掘LLM的能力,如果他并没有某方面认知的知识,那我们再怎么写prompt,他也是无法给你回答的。
这种情况我们有两个解决方案,一种相对简单有效的方案--RAG。这种方法将检索(或搜索)的能力集成到LLM文本生成中。它结合了一个检索系统和一个LLM,前者从大型语料库中获取相关文档片段,后者使用这些片段中的信息生成答案。本质上,RAG 帮助模型“查找”外部信息以改进其响应。
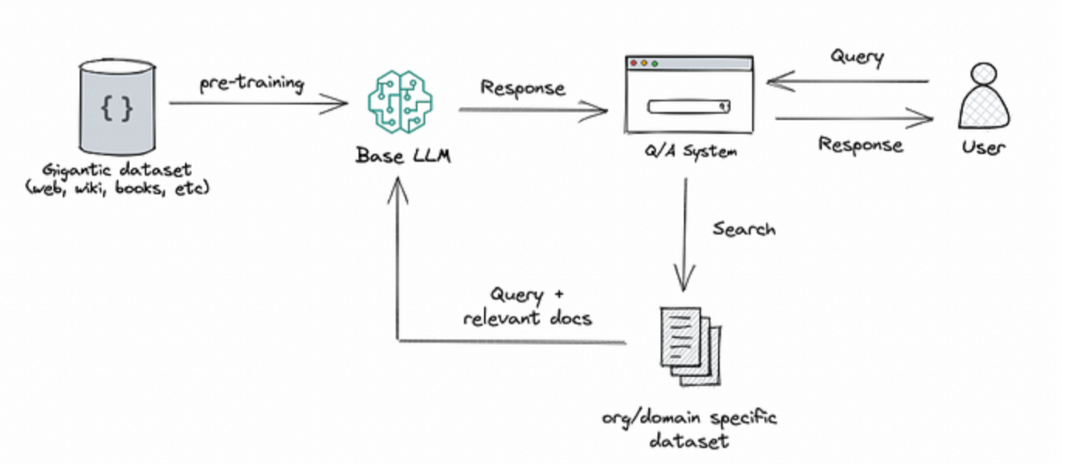
大家最熟悉的应该是下图,知识库检索。
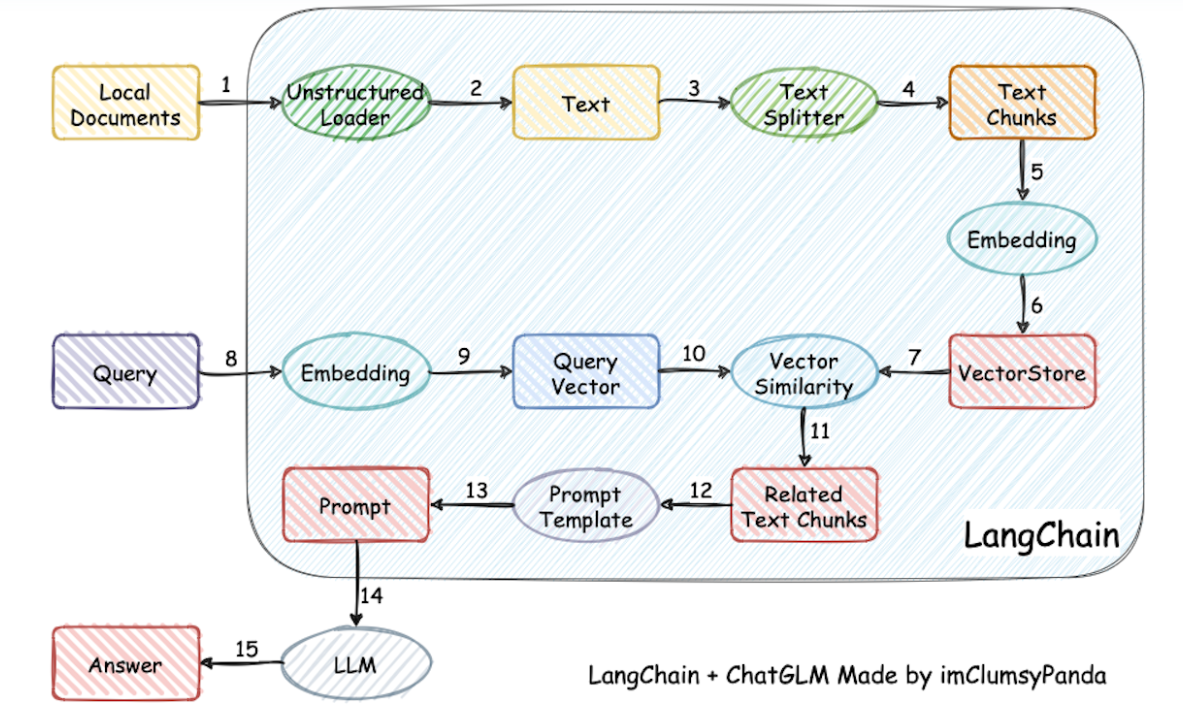
面对这张看似简单,清晰步骤的流程图,其实每一个步骤都需要我们进行很多工程逻辑。
我们可能遇到的问题:
面对各种文档格式,以及文档内的非结构化数据,我们需要如何处理?
面对没有章节的大段文章,我们需要如何处理?面对有章节的文章,我们如何进行分段?
文本块应该如何切分,每个块大小多少合适,文本块是否需要带上下文?
embedding算法应该如何选型?
数据库和向量存储框架如何选型?
如何提升文本的召回和排序,尽可能准确且无冗余的获取用户问题相关文本?
是否需要根据意图类别构建不同提示语?提示语应该如何构建?
如何判断回复是否满足用户需求,如果不满足用户需求应该如何引导用户?
对于RAG的技术细节就太多了,这篇文章就不做过多介绍~
4.3 微调
使用RAG还是直接微调大模型?
对于通用模型无法解决的垂直领域除了RAG这个方案外,另一种方案就是微调。那什么情况使用RAG,什么情况需要微调呢?我个人建议,能RAG就RAG,行业太过垂域,或者就需要一个自己的大模型再去微调。另外可以考虑以下几个方面。
1. 是否需要访问外部数据源
2. 知识库是不是只有短期时效性
3. 是否需要修改模型的输出格式或回复需要特定领域专业术语
4. 是否对幻觉很敏感,必须在指定知识内回答
5. 是否有足够多高质量的指令数据
6. 是否需要提供回复数据源
简单总结几个常用的微调算法,了解思路后在自己业务中可以根据特点自行选择:
4.3.1 Prefix Tuning
论文地址:https://arxiv.org/pdf/2101.00190.pdf
在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而PLM中的其他部分参数固定。不同的任务有自己的一份Prefix参数。
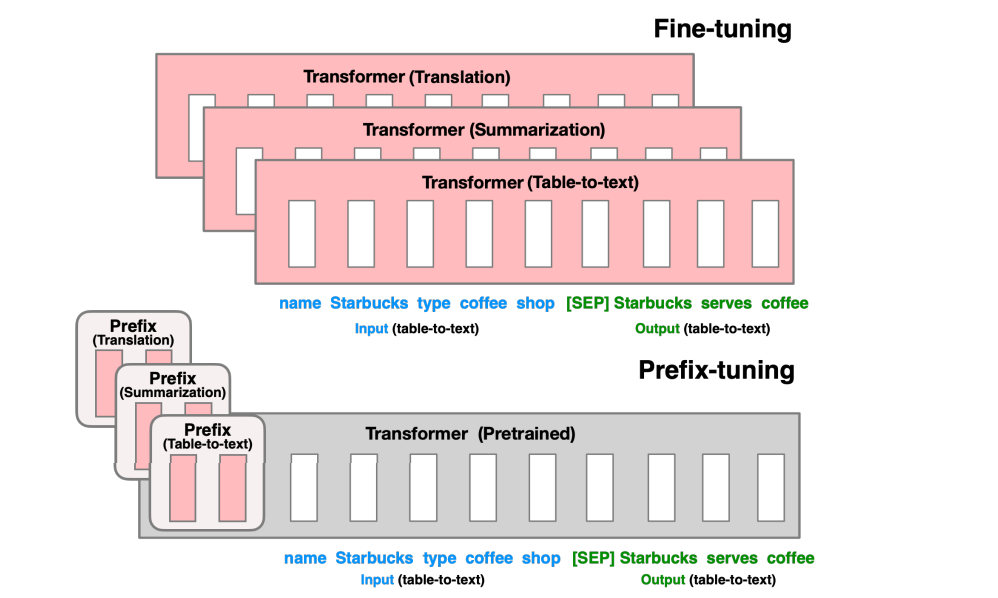
该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。
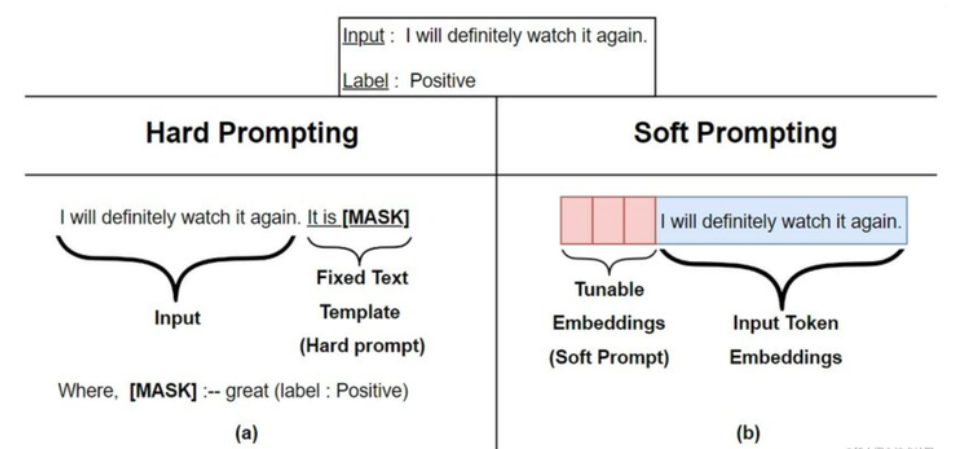
4.3.2 Prompt Tuning
论文地址:https://arxiv.org/pdf/2104.08691.pdf
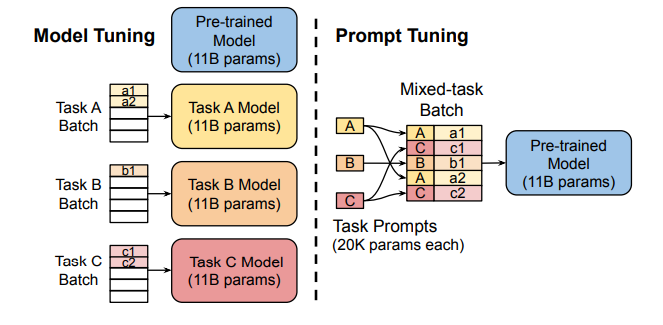
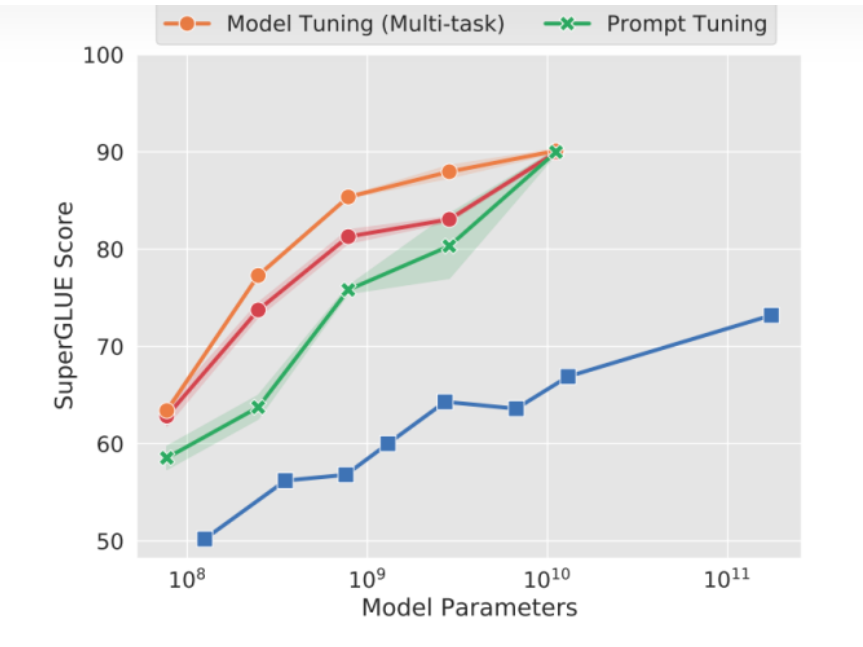
Prefix Tuning的简化版本,它给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,但只在输入层加入prompt tokens,并且不需要加入 MLP 进行调整来解决难训练的问题,训练过程中将任务进行混合。而且通过实验发现,随着预训练模型参数量的增加,Prompt Tuning的方法会逼近全参数微调的结果。
4.3.3 P-Tuning
论文地址:https://arxiv.org/pdf/2103.10385.pdf
prompt工程这种人工构建的离散token,效果很不稳定,结果也不一定是最优的。

P-Tuning是设计了一种连续可微的virtual token(同Prefix-Tuning类似)。
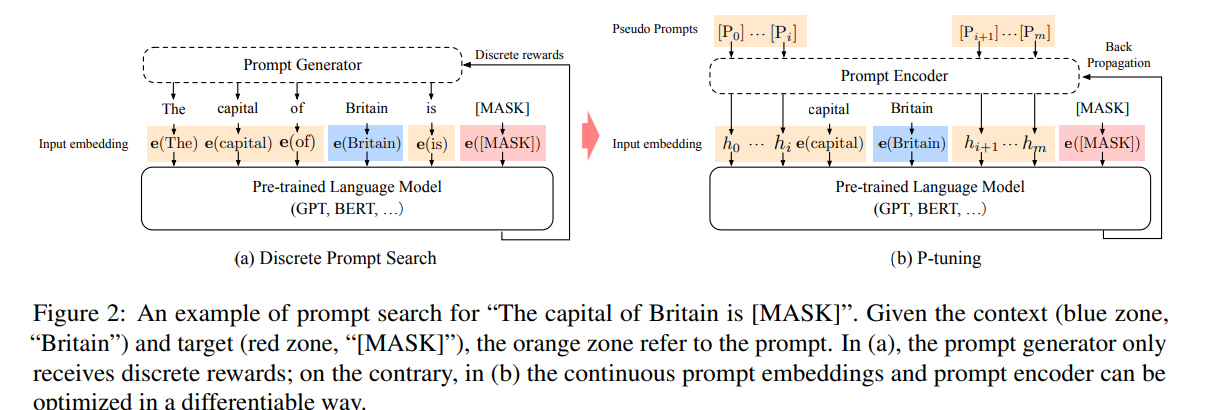

相比Prefix Tuning,P-Tuning加入的可微的virtual token,但仅限于输入层,没有在每一层都加;另外,virtual token的位置也不一定是前缀,插入的位置是可选的。这里的出发点实际是把传统人工设计模版中的真实token替换成可微的virtual token。另外作者通过实验发现用一个prompt encoder来编码会收敛更快,效果更好。即用一个LSTM+MLP去编码这些virtual token以后,再输入到模型。
4.3.4 P-Tuning v2
论文地址:https://arxiv.org/pdf/2110.07602.pdf
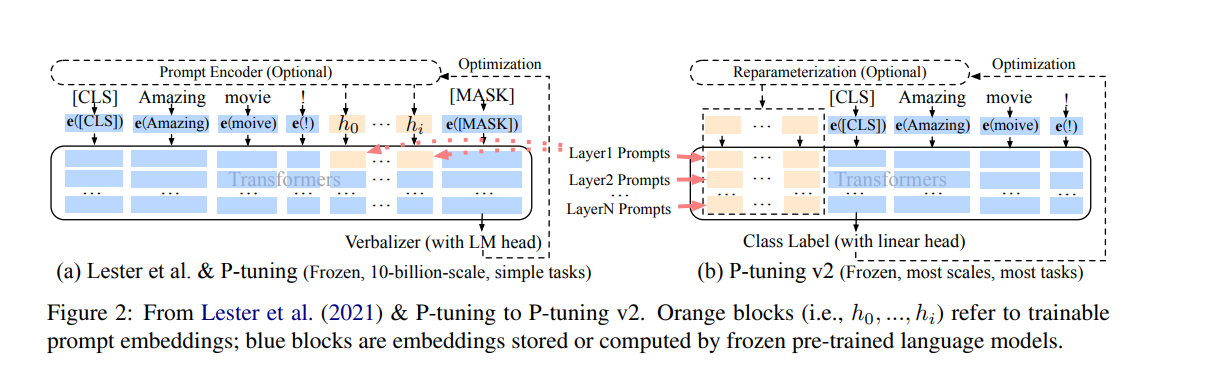
该方法在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这带来两个方面的好处:
更多可学习的参数(从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%),同时也足够参数高效。
加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
可以简单的将P-Tuning认为是针对Prompt Tuning的改进,P-Tuning v2认为是针对Prefix Tuning的改进。
4.3.5 LoRA
论文地址:https://arxiv.org/pdf/2106.09685.pdf
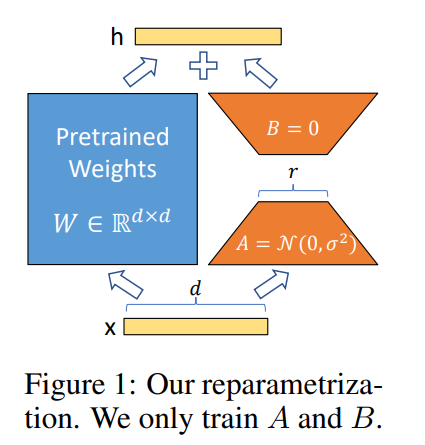
该方法的核心思想就是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
第一个矩阵的A的权重参数会通过高斯函数初始化,而第二个矩阵的B的权重参数则会初始化为零矩阵,这样能保证训练开始时新增的通路BA=0从而对模型结果没有影响。在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原本PLM的W即可,对于推理来说,不会增加额外的计算资源。
此外,Transformer的权重矩阵包括Attention模块里用于计算query, key, value的Wq,Wk,Wv以及多头attention的Wo,以及MLP层的权重矩阵,LoRA只应用于Attention模块中的4种权重矩阵,而且通过消融实验发现同时调整 Wq 和 Wv 会产生最佳结果。
4.3.6 MAM Adapter
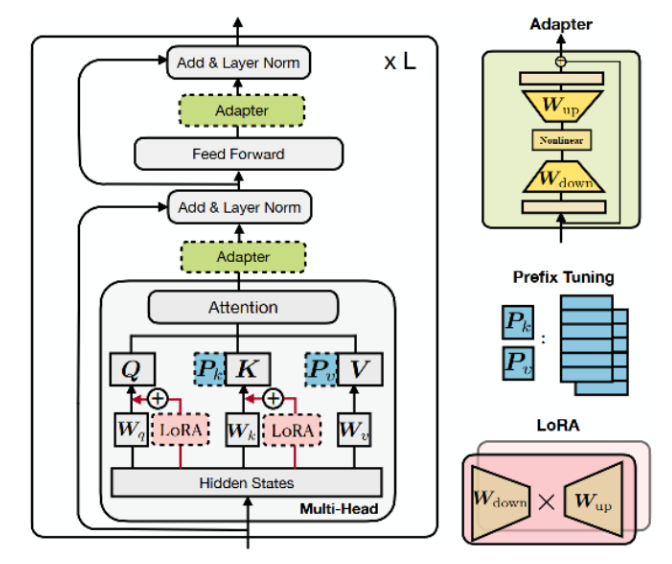
4.3.7 UniPELT
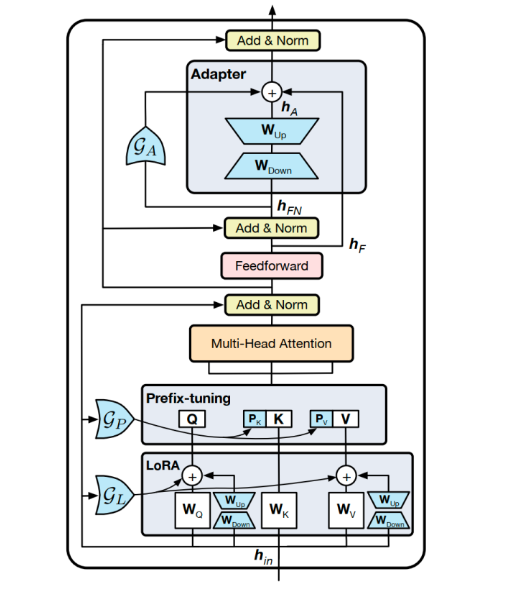
UniPELT就有点组合拳了。更具体地说,LoRA 重新参数化用于 WQ 和 WV 注意力矩阵,Prefix Tuning应用于每一Transformer层的key和value,并在Transformer块的feed-forward子层之后添加Adapter。 对于每个模块,门控被实现为线性层,通过GP参数控制Prefix-tuning方法的开关,GL控制LoRA方法的开关,GA控制Adapter方法的开关。图中蓝色的参数是可训练参数。
微调当然不仅仅是算法,更重要的是数据:

再次强调强调数据安全
3H(Helpful, Honest, Harmless)原则来让大模型和人的普世价值对齐。
5 未来方向
Andrej Karpathy 发布 LLM 入门课里面有提到LLM的未来方向:思维方式(系统1/2)、LLM对工具使用(Agent)、多模态、 GPTs 应用商店,以及LLM OS。
5.1 思维方式(系统1/2)
先总结下他提到的人类思维方式:
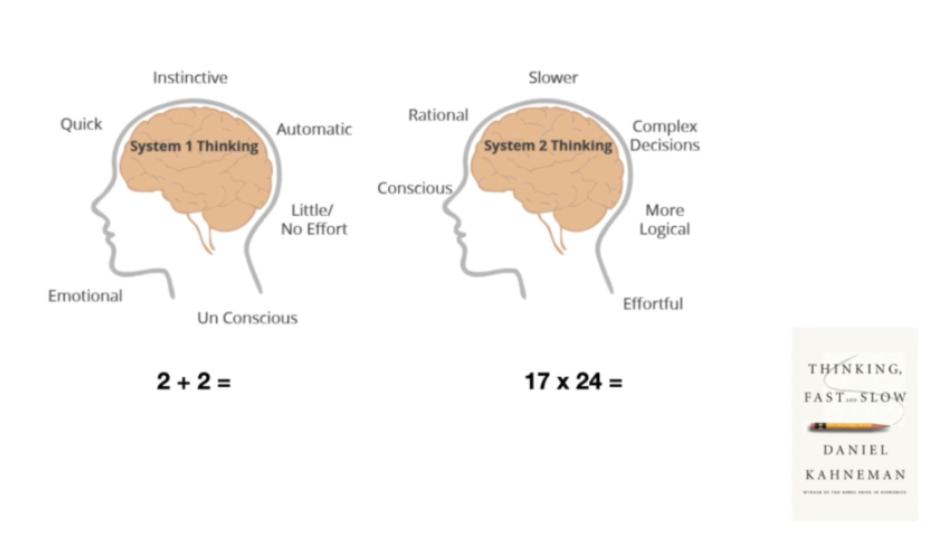
system1: 大脑的快速、本能和自动化的思维模式。
system2: 大脑另一个思维模型更加理性,更加缓慢,进行复杂的决策,感觉更有意识。
LLM本身只有system1的能力。CoT,ToT这种方式能够赋予 LLM 系统 2 的能力,需要给他们更多的时间,让它们更深入地思考问题,反思和重新表述。
那alphaGo为什么能超越人类?
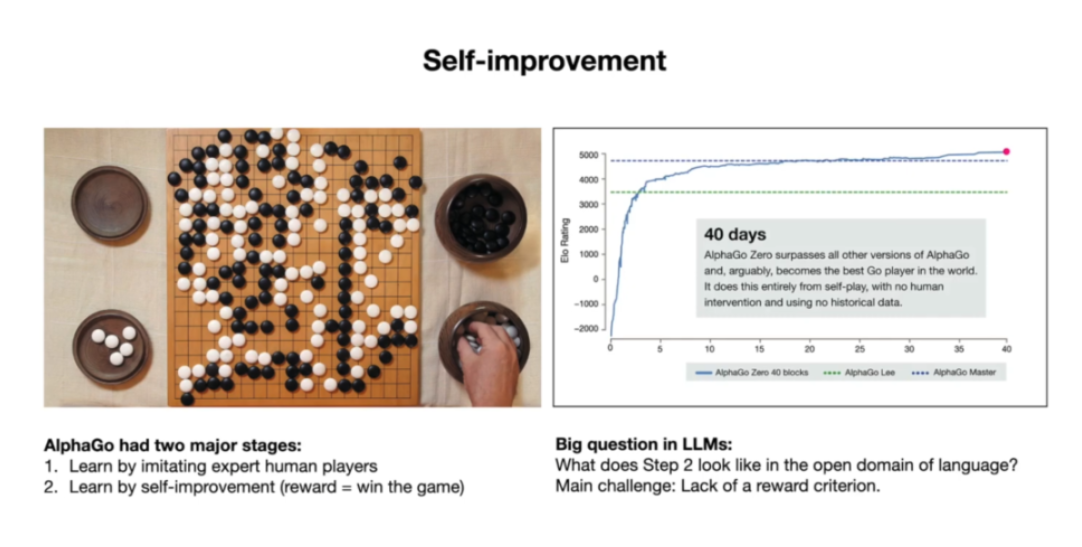
主要是因为是他有检测的评测标准,先学习人类,然后自主学习根据reward函数来评测,最后超越人类。LLM目前还是学习人类(人类打分),对齐人类的标准。但是自主学习的reward就很困难。
从根本上说,没有简单的奖励函数可以让你判断你的答案是好是坏。
网络不管大事小事,底下的评论都有不同的声音,每个人的标准是不一样的。反而垂直领域,比如代码,能运行就认为正向,反之负向;对响应式的,能反馈就是正向。但是对于通用对话,就没有一个绝对的标准。这也是为什么目前很多公司对于LLM的应用都是先做代码提效工具,因为代码是有衡量标准的。
5.2 多模态
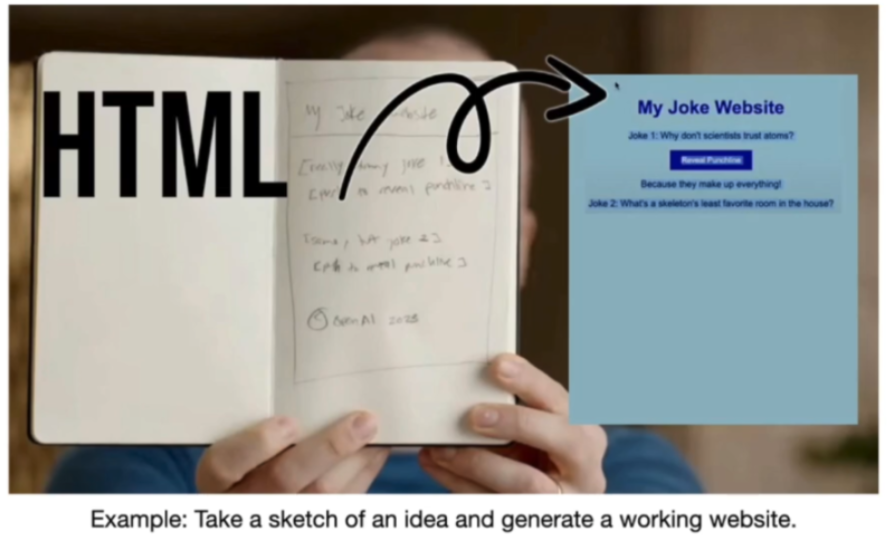
多模态肯定是 LLM 变得更强大的一个重要方向。在 Greg Brachman (openAI创始人之一)的著名演示中,他向 ChatGPT 展示了一个他用铅笔草绘的一个小笑话网站示意图,而 chat apt 可以看到这个图像,并基于它为这个网站编写一个运行的代码,所以它写了 HTML 和 JavaScript。
所以以后LLM应用肯定不限于文本,还有图片,音频,视频的embedding对齐,以及多个模态之间的转换。对多模态就不得不提google的Gemini了,虽然他发布会的视频遭到了质疑,但是Gemini和GPT-4-Turbo不一样,他是天成的多模态大模型,在训练阶段他就是输入多模态,输出多模态。希望Gemini有更好发展, 毕竟Transformer和Bert都是谷歌的并且是开源的,谁现在的大模型不用Transformer,都得像google说一声谢谢你...
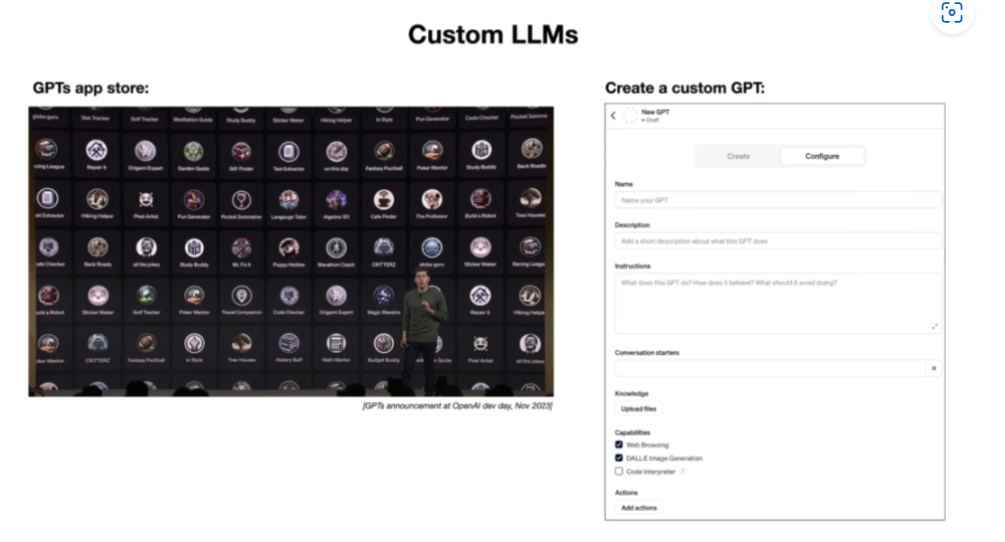
5.3 GPTs应用
11月6号,OpenAI召开了首次开发者大会,隆重发布GPT-4的增强版Turbo,提供了辅助开发的GPT Assistant API,并且上线了GPT应用商店—GPTs。
它省去了从收集需求,开发应用,发布应用等一系列过程。用户可以根据自己的需求打造自己的GPT,调用它的LLM接口就好,其他不用操心LLM使用Agent思路去给帮你规划,找工具,决策和执行。(看到过一个犀利评论:甲方爸爸的终极幻想,也是乙方搬砖狗的末日)。
比如Zapier App:一个自动化部署的插件,用于将GPT和上百种App联用起来。你可以用自然语言给GPT下指令,然后GPT通过Zapier来操作你的App进行执行。
一个应用,基于LLM规划我的需求,拆分为任务,然后还能自己去搜索能用的其他工具,完成任务。像不像我们在操控一个PC。
5.4 Agent
Agent我之前有总结过,这里就不再过多介绍。
5.5 LLM OS
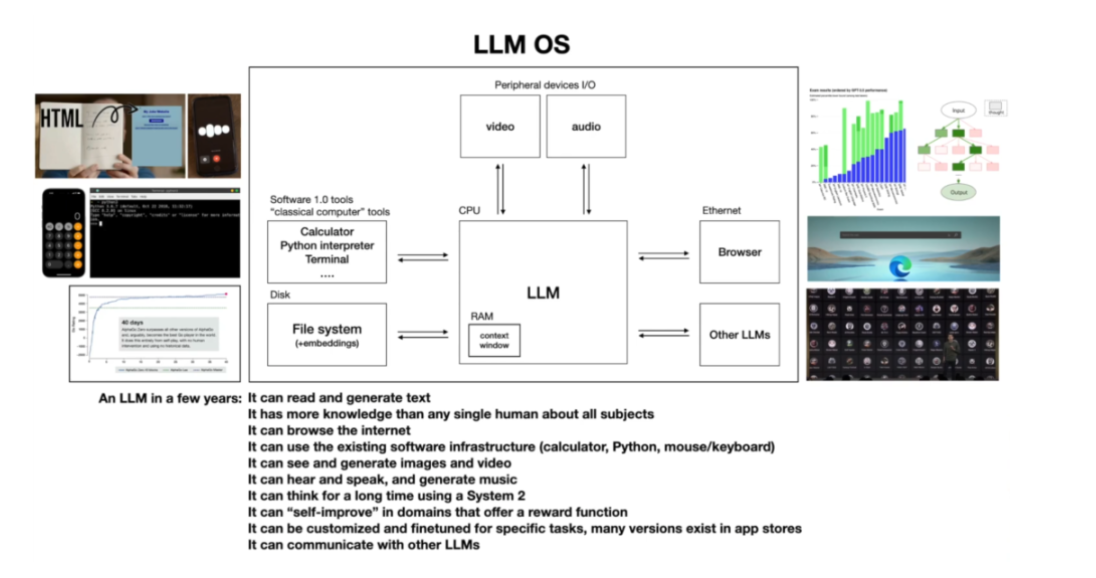
Andrej分享过下面的LLM OS概念,他将LLM类比为一个操作系统。
windows拥有很多app应用;
LLM也有了自己的GPTs, 他也能使用计算器,用IDE编写和生成应用,浏览互联网,看音视频,使用其他LLM应用。
window可以随机访问内存或 RAM;
LLM 模型本身就是一堆知识数据的压缩,它也有历史信息存储--上下文窗口,当然和内存一样也是有限的;但是他可以有RAG外挂知识库,他可以用搜索引擎工具。
所以我个人认为LLM未来的发展方向:
(1)迭代优化:大模型本身的自我进化,逐步拥有系统2的能力,特别是对于垂域场景,后续会在各领域出现"超级企业"
(2)多模态:LLM后续会优化为多模态大模型,让纯NLP问题变为多模态问题
(3)大模型应用:应用号好大模型工具,提供自己的思路让AI去完成你的想法,后续会出现更多的"超级个人"
(4)Agent:我认为Agent不是一个应用框架,他是思路框架,是给如何应用大模型提供一个框架,可以认为LLM OS就是一个Agent。
我正在参与2024腾讯技术创作特训营第五期有奖征文,快来和我瓜分大奖!
参考:
https://wallstreetcn.com/articles/3681850
https://foresightnews.pro/article/detail/47922
https://36kr.com/p/2347804548669059
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。