我掌握的新兴技术:AIGC的前世今生
原创
/developer/article/2378720?from_column=20421&from=204211.引子:AIGC的例子
AI写诗

AI写月报思考

AI文字生成图片
https://labs.openai.com/ 一个宇航员在骑一匹马


图像编辑
对应位置生成柯基


图像扩充

扩充成

相似图像生成

自动上色
https://petalica.com/index_zh.html

头像生成

2.什么是AIGC?
2.1 AIGC的定义

chatgpt基本回答了什么是AIGC,但目前为止,AIGC尚无明确的定义。国内产学研各界对于AIGC的理解是“继专业内容生成PGC和用户生成内容UGC之后,利用人工智能技术自动生成内容的新型生产方式”。在国际上对于的术语是“人工智能合成媒体(AI-generated Media)”,其定义是“通过人工智能算法对数据或媒体进行生产、操控和修改的统称”。 综上所述,我们认为AIGC既是从内容生产视角进行分类的,又是一种生产方式,还是用于内容自动生成的一类技术集合。
3.AIGC的前世今生
3.1 内容生产上
https://www.vzkoo.com/document/20220907cc987d2511ffc7c895ed6dd4.html
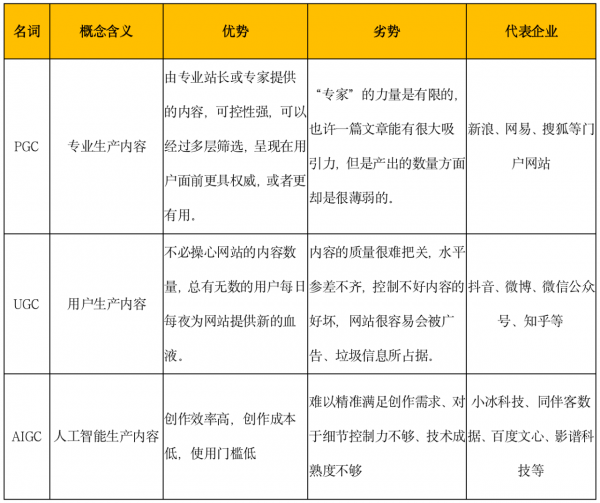
3.1.1 PGC->UGC->AIGC

内容 = 信息 + 载体
当我们听到《菊次郎的夏天》而感到愉悦、看到复仇者们集结而感到振奋、操控英雄斩下五杀而感到刺激时,我们其实都是在用我们的感官不断地接收信息,并通过大脑处理这些信息,进而发出反馈。所以说内容的消费是一个接收并反馈特定信息的过程。 但信息却不能和内容划等号。信息本身即随事物运动而产生,其存在并不依赖于信息的传播方式、路径和对象。也就是说,当我们从真实世界获取信息时,我们仅仅是通过某种合理的方式,获取了原本就存在的信息。在获取、传递与接收信息的过程中,为了提高信息获取的效率,我们使用了各种载体。语言是一种虚拟的载体,文字是一种虚拟的载体,工具是一种实体的载体,物体是一种实体的载体。 同样的信息,可以被打包进一个小盒子(如文字);也可以被打包进大礼盒(如视频)。不同的打包方式,让接收者们在解码信息(拆快递时)也有了不同的感受和理解。可以说,对于接收者而言,信息和载体的组合才是一个完整的可感知对象,是一个不同于信息本身的新事物。 这个新事物就是内容,信息有了载体就成为了内容。内容 = 信息 + 载体。
PGC
既然内容等于信息加载体,那么内容的生产是怎么样的呢?信息自然是不会自己跑到载体中的,是人将信息与载体结合。不同的人在面对同一信息时很有可能会以不同的方式处理,不仅处理的结果不同,最后选择的载体也可能不同。对同一棵绽放的向日葵,有的人会用文字作为载体写“这向日葵真美”,而梵高则通过油画把向日葵的绚烂还原。 早期的互联网时代,用户基数并不大,文本、图像、视频、音乐、游戏等内容都是专业人士创作出来的,这些内容属于专家生成内容(Professionally-Generated Content,PGC)。PGC一般是指由专业化团队操刀、制作门槛较高、生产周期较长的内容,最终用于商业变现,如电视、电影和游戏等。为了保障生成内容的质量,PGC 需要投入大量的技术成本与人力成本。在 PGC 模式下,内容生产和变现的权利掌握在少数人手中,集中程度更高,垄断效应更强,但受限于供给侧的人力资源,PGC 难以满足大规模的内容生产需求。
UGC
生产诸如图像、文本等内容的专业人士,我们称为生产者;对这些内容进行购买、观赏等行为的称为消费者。过去我们在探讨生产与消费两者的关系时,时常以二元对立的角度将两者分割。但实际上,两者之间的界限却并非一直如此清晰,消费者群体也可能参与到生产中,生产出能满足需求的产品。 随着技术的进步、互联网的兴起,越来越多的平台提供了创作工具,降低了生产门槛,让具有创作意识的消费者为平台产生内容,提高了内容生态的繁荣度,如抖音快手短视频、微博、贴吧等。这就是UGC (User-Generated Content,UGC)模式,它在一定程度上降低了生产成本与中心化程度,满足了用户个性化或多样性的需求,同时也提高了产能天花板。 虽然内容的生产规模得到了大幅提升,但由于其对生产者、创作工具和内容主题均未设限,其质量不可避免地遭到反噬。尽管 UGC 改善了 PGC 生产规模受限的问题,但其内容质量参差不齐,导致用户对优质内容的检索成本提升。归根结底,UGC 依然无法满足用户对高质量内容的需求。
AIGC
一个有质量的内容是生产者对信息进行过筛选、处理、加工与整合的,这些流程均是基于创作者经过长年累月地后天学习建立而成,需要耗费大量的时间和脑力。于是长期来看,人工创作的能力必定有限,当 PGC、UGC 的生产潜力消耗殆尽时,AIGC (AI-Generated Content)也许能够弥补内容生态的缺口。 平台通过开放 AI 工具协助用户创作,任何人都可以成为创作者,发出指令使 AI 自动生成内容,指示 AI 完成复杂的代码、绘图与建模等任务,进一步降低了生产门槛,且提高了生产效率。 但受技术发展所累,以上工作中 AI 仅是扮演辅助角色,人类依然需要在关键环节创作内容或输入指令,AI 暂不具备成为创作者进行自主创作的能力。然而,随着数据、算法等核心要素不断地升级迭代,AIGC 可能是未来发展的大方向,其或将突破人工限制,提升到自主创作的水平,创作出更丰富多样的内容。
3.2 算法上
https://server.zhiding.cn/server/2022/1129/3146045.shtml https://www.vzkoo.com/document/20220907cc987d2511ffc7c895ed6dd4.html
3.2.1 出生、蛰伏、一夜爆火
随着人工智能的演进沿革,AIGC的发展历程大致可以分为三个阶段:
早期萌芽阶段-出生
早期萌芽阶段(1950s-1990s),受限于当时的科技水平,AIGC仅限于小范围实验。 1957 年,莱杰伦·希勒和伦纳德·艾萨克森完成历史第一支由计算机创作的弦乐四重奏《伊利亚克组曲》。 1966年,约瑟夫·魏岑鲍姆和肯尼斯·科尔比开发了世界第一款可人机对话的机器人Eliza。 80年代中期,IBM创造了语音控制打字机Tangora。
沉淀积累阶段-蛰伏
沉淀积累阶段(1990s-2010s),AIGC从实验性向实用性逐渐转变。 2006年,深度学习算法、图形处理器、张量处理器等都取得了重大突破。 2007年,世界第一部完全由人工智能创作的小说《1 The Road》问世。 2012年,微软公开展示了一个全自动同声传译系统,可以自动将英文演讲者的内容通过语音识别、语言翻译、语音合成等技术生成中文语音。
快速发展阶段-一夜爆火
快速发展阶段(2010s至今),深度学习模型不断迭代,AIGC突破性发展。 2014年,随着对抗生产网络GAN为代表的提出和迭代更新,AIGC迎来了新时代,生成内容百花齐放,效果逐渐逼真直至人类难以分辨。 2017年,微软人工智能少女“小冰”推出了世界首部100%由人工智能创作的诗集《阳光失了玻璃窗》。 2018年英伟达发布了StyleGAN模型可以自动生成图片,目前已经发展到了第四代模型StyleGAN-XL,其生成的高分辨率图片让人难以分辨真假。 2019 年,DeepMind 发布了 DVD-GAN 模型用以生成连续视频,在草 地、广场等明确场景下表现突出。 2021 年,OpenAI 推出了 DALL-E 并于一年后推出了升级版本 DALL-E-2,主要应用于文本与图像的交互生成内容,用户只需输入简短的描述性文字,DALL-E-2 即可创作 出相应极高质量的卡通、写实、抽象等风格的绘画作品。 2022年,12月OpenAI的ChatGpt火爆全网,在文本生成、代码生成与修改、多轮对话等领域,已经展现了大幅超越过去AI 问答系统的能力。

4.不得不提的预训练模型
在说到AIGC的时候,不得不提的是大规模预训练模型。不管是ChatGPT,还是各种GAN模型,如果要展示出“一夜爆火”的效果,必然都需要依赖大规模数据。如果对这些大规模数据进行标注,那数据集需要各种不同的任务,而不只是简单标个分类就好了,这是一件非常耗人力的事情。但是未标注的图像、文本在生活中随处可见,能否利用这些数据进行模型训练呢?
4.1 图像预训练
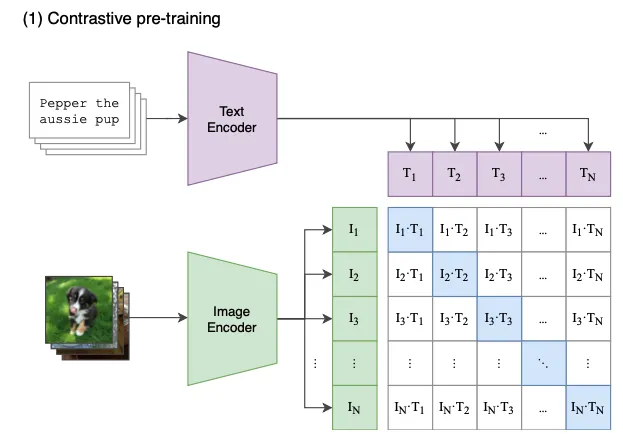
最早将卷积神经网络用于图像分类的网络是2012年Alex Krizhevsky提出的AlexNet(以该作者命名),它用于训练大型图像分类模型ImageNet(ImageNet是包含1000个类别、100多万样本的图像数据)。2014年牛津大学在ILSVRC提出了VGG(Visual Geometry Group)模型,该模型相比以往模型进一步加宽和加深了网络结构,VGG论文中还提出使用预训练好的参数初始化可以加速训练,之后的大多数分类模型应用都采用基于在ImageNet上预训练的模型参数作为模型初始化参数。2015年,何凯明提出了残差网络,让更深的网络也能训练出好的效果,并得到ILSVRC冠军,同时也成为了目前最流行的图像分类网络。 在图像领域里,预训练任务已经是非常成熟了。一般使用由ResNet网络在ImageNet数据集上预训练的模型作为特征提取器,分类层前的卷积网络就是图像包含的所有特征,可以直接用于下游任务如目标检测、图像聚类、语义分割、其他场景的图像分类应用等。数据规模和成熟的卷积神经网络应用,是图像特征解决方案的主要特点:在数据集上图像分类有达100多万张标注的图片,1000多个类别;在模型训练过程中,模型会不断学习如何提取特征,卷积神经网络还可以提取图像的边缘、角、点等通用特征,模型越往上走,特征越抽象。在这种预训练的模型,可以固定住底层的模型参数只训练顶层的参数,也可以对整个模型进行训练,这个过程叫作微调(fine-tuning),最终得到一个可用的模型。对于各种各样的任务都不再需要从头开始训练网络,可以直接拿预训练好的结果进行微调,既减少了训练计算量的负担,也减少了人工标注数据的负担。 2021年,OpenAI提出了CLIP(Contrastive Language-Image Pre-training)图像预训练模型,利用文本-图像进行模型预训练,最终可以直接迁移到ImageNet数据集上,完全不需要imageNet的标签就实现无微调的zero-shot(不再需要imagenet的标签-图像对进行训练)分类,而且精度非常高,达到了ResNet50的TOP1精度76%。 Open AI团队通过收集4亿(400 million) 个文本-图像对((image, text) pairs) ,以用来训练其提出的CLIP模型。文本-图像对的示例如下:

模型非常简单,为了对image和text建立联系,首先分别对image和text进行特征提取,image特征提取的backbone可以是resnet系列模型,text特征提取目前一般采用bert模型,特征提取之后,由于做了normalize,直接相乘来计算余弦距离,同一pair对的结果趋近于1,不同pair对的结果趋近于0,因为就可以采用对比损失loss(info-nce-loss),熟悉这个loss的同学应该都清楚,这种计算loss方式效果与batch size有很大关系,一般需要比较大的batch size才能有效果。
4.2 语言模型预训练
4.2.1 从BERT开始介绍

对比各种图像神经网络,可以发现自然语言处理任务的特点和图像有极大的不同。自然语言处理的输入往往是一句话或一篇文章,所以它有几个特点:输入是一维线性序列,图像中的输入是2维或2维以上的;输入是不定长的,有的长有的短(对于模型处理起来会增加一些麻烦);单词或子句的相对位置关系很重要,两个单词位置互换可能导致完全不同的意思。 处理自然语言处理问题,首先要解决文本的表示问题。虽然人去看文本,能够清楚明白文本中的符号表达什么含义,但是计算机只能做数学计算,需要将文本表示成计算机可以处理的形式。业界最开始的方法是采用one hot,比如假设英文中常用的单词有3万个,那么就用一个3万维的向量表示这个词,所有位置都置0,当想表示apple这个词时,就在对应位置设置1。

但是这样的向量没有任何含义,后来出现了词向量(word vector),用一个低维度稠密向量表示一个词,如[1.45332634, 2.132315345, 1.76233123, -1.3424254, 0.4231324, ......]。相比one hot动辄上万的维度已经低了很多,而且词与词之间的关系可以用相似度或者距离来表示,相似度越高、距离越近,表示两个词更有关联。这种词向量可以根据经典Word2vec算法如CBOW或Skip-Gram学习到,但是这样的词向量表现不出词的语法(syntax)、语义 (semantics)等复杂特性,也无法处理一词多义的问题,因为Word2vec是静态的,而每个词都有不同的意思,如果要用数值表示这个词,那这个词就不应该是固定的某个向量。 之后,自然语言处理开始借鉴图像的预训练模型,一个通用模型在非常大的语料库上进行预训练,然后在特定任务上进行微调,出现了ELMO、Transformer、GPT、BERT等预训练模型,他们都在未标注的数据上使用自监督方法,能够让预训练模型学习到语言本身的特征,其中众所周知的BERT(Bidirectional Encoder Representation from transformer)就是这套方案的集大成者。

BERT是一种基于Transformer的双向编码表征,刷新了各大自然语言处理任务的榜单,在各种自然语言处理任务上都做到业内最先进。为了适配多任务下的迁移学习,BERT设计更通用的输入层和输出层,但是BERT整体模型结构上几乎和Transformer的Encoder层是一样的。 虽然自然语言处理领域没有像ImageNet这样质量高的人工标注数据,但是可以利用大规模文本数据的自监督性质来构建预训练任务。BERT在模型预训练上提出了两个方法Masked Language Model(屏蔽语言模型)、Next Sentence Prediction(预测下一句话),前者随机地掩蔽(使用掩蔽标记[MASK])一定百分比的输入词,然后预测那些被掩蔽的词,完成“双向”编码训练的过程;后者为了训练一个理解句子关系的模型,进行下一个句子预测的二分类任务训练,在为每个预训练样本选择句子A和B时,50%的概率B是A后面的实际句子(标记为IsNext),而50%的概率是随机的来自语料库的句子(标记为NotNext),然后进行二分类的预测。
4.2.2 GPT系列
GPT-1比BERT诞生略早几个月。它们都是采用了Transformer为核心结构,不同的是GPT-1通过自左向右生成式的构建预训练任务,然后得到一个通用的预训练模型,这个模型和BERT一样都可用来做下游任务的微调。GPT-1当时在9个NLP任务上取得了SOTA的效果,但GPT-1使用的模型规模和数据量都比较小,这也就促使了GPT-2的诞生。 对比GPT-1,GPT-2并未在模型结构上大作文章,只是使用了更多参数的模型和更多的训练数据(表1)。GPT-2最重要的思想是提出了“所有的有监督学习都是无监督语言模型的一个子集”的思想,这个思想也是提示学习(Prompt Learning)的前身。GPT-2在诞生之初也引发了不少的轰动,它生成的新闻足以欺骗大多数人类,达到以假乱真的效果。甚至当时被称为“AI界最危险的武器”,很多门户网站也命令禁止使用GPT-2生成的新闻。 这一节主要介绍GPT-3。GPT-3被提出时,除了它远超GPT-2的效果外,引起更多讨论的是它1750亿的参数量。GPT-3除了能完成常见的NLP任务外,GPT-3还能写SQL,JavaScript等语言的代码,进行简单的数学运算上也有不错的表现效果。
GPT-3的结构和任务
https://arxiv.org/pdf/2005.14165.pdf 结构上GPT-3是Transformer的Decoder部分,输入一个句子中的上一个词,模型可以得到句子中的下一个词。

GPT-3的预训练
比较特别的是,GPT-3提出了一种 in-context 学习方式。举个例子:
在问答对话里,我们希望模型输出1或者2;在机器翻译里,我们希望输出4。但我们完全不想要3,3是个什么玩意儿。这时就有了 in-context 学习,也就是,我们对模型进行引导,教会它应当输出什么内容。如果我们希望它输出翻译内容,那么,应该给模型如下输入:
如果是问答:
能够给模型做个示范:
其中 苹果翻译成 apple,是一个示范样例,用于让模型感知该输出什么。只给提示叫做 zero-shot,给一个范例叫做 one-shot,给多个范例叫做 few-shot。再多的话,就成了传统的finetune 模式了。 在 GPT-3 的预训练阶段,也是按照这样多个任务同时学习的。如这里的“做数学加法,改错,翻译”同时进行。这其实就类似前段时间比较火的 prompt,prompt是一种提示性的预训练方法,如MASK填词、预测下一句话等,实际上prompt和in-context边界非常模糊,几乎可以认为是一种东西。
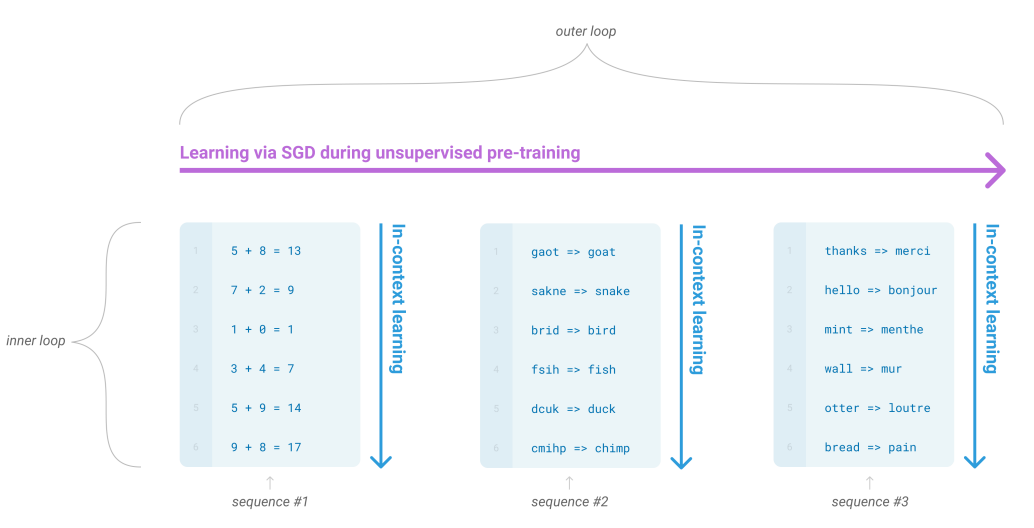
这种引导学习的方式,在超大模型上展示了惊人的效果:只需要给出一个或者几个示范样例,模型就能照猫画虎地给出正确答案。 部分预训练任务训练数据展示:

5. 图生图-GAN介绍
2022年,大量AI绘画工具上线,不乏国内玩家,TIAMAT、盗梦师、意间AI等国内初创公司做出的产品,引起了市场的热烈反响。 今年8月,百度在飞桨、文心大模型的技术基础上,发布了AI绘画平台文心一格。今年12月,文心一格基于民国才女陆小曼未尽稿,邀请著名海派画家乐震文补全,推出同名画作《未完·待续》,并在一场拍卖会上被卖出110万元人民币。 赶在年末,腾讯、字节跳动、美图等更多大厂加入热潮,它们都在旗下主流软件中加入了AI绘画功能。 腾讯上线了“QQ小世界AI画匠”活动,基于Stable Diffusion模型推出了“异次元的我”这一产品。用户在QQ的小程序中可以打开使用,上传照片便可以生成二次元形象。 这里首先介绍下图生图的鼻祖:GAN。
5.1 GAN是啥?能干什么?
GAN(GenerativeAdversarial Networks),生成对抗网络,从字面意思不难猜到它会涉及两个“对手”,一个称为Generator(生成器),一个称为Discriminator(判别者)。最早由Ian Goodfellow于2014年提出,以其优越的性能,在不到两年时间里,迅速成为一大研究热点,各种花式变体Pix2Pix、CYCLEGAN、STARGAN、StyleGAN等层出不穷,到18年、19年达到高峰,几乎1/3的论文都是GAN。

但GAN从字面意思看,貌似还看不出它能干什么。实际上我们上面介绍的,“填色”、“换脸”、“换衣”、“换天地”等场景下生成的图像、视频以假乱真,甚至文生图text2image等应用都和GAN息息相关。 20年时我训练的CycleGAN,不同epoch下不同的输出: https://bbs-img.huaweicloud.com/blogs/img/1596781192824077539.gif




5.2 简单的GAN原理
5.2.1 GAN动物园
这里收集了19年前所有的GAN算法,18年左右是GAN井喷的时期。 https://github.com/hindupuravinash/the-gan-zoo
5.2.2 GAN原理


上面的鸣人佐助、塔矢亮和近藤光,完美阐释了GAN的原理:亦敌亦友、相爱相杀。 这里主要介绍图像生成的“传统”GAN原理,上面介绍到GAN包含了两个结构,一个是生成器generator,一个是判别器Discriminator。
生成器generator
在图像生成的GAN里,那这个generator要做的事情就是:随机一个向量vector,把这个向量丢到生成器里,生成器就要产生一张图像。丢入不同的向量就应该产生不同图像,这个是图像的生成器。于是这个生成器就是一个函数function,他的输入是一个向量,输出就是一张图片。 下面是生成器的网络结构,从一个噪声向量,经过变换、采样、卷积等操作生成一张图,原版的GAN的判别器和生成器使用的都是全连接层,这里的图是DCGAN(深度卷积生成对抗网络),在DCGAN中使用卷积层代替。这样做的好处是卷积网络能够提取图片数据的二维特征,提高图片的生成质量。
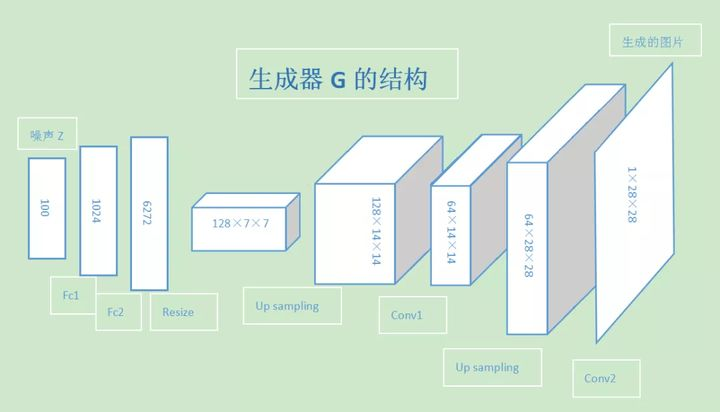
比较有意思的是,假设我们的向量第一个dimension对应的是头发的长度,将vector它的第一个dimension的值从0.1调整到3,generator的output就会是一个长头发的角色;假设vector的倒数第二个dimension对应到头发是不是蓝色的,值越大代表头发越蓝,将这个值从2.4调到5.4,产生出来的角色就会变成蓝头发。当然在这个简单的GAN上面,我们还不能先验的指定哪个维度是头发,哪个是颜色,都是模型训练完之后,调参试出来的。


判别器
GAN里还有个结构是Discriminator(判别器),它也可以当做一个函数function,他的输入是一张图,输出是一个“分数”,判别器主要是判断输入的图片是不是真实的。判别器输出数值越大,就代表产生出来的这张图片的quality越高,那么看起来越像是真实的图片(产生出来的数值越大,就表示输入的图片越真实)。

假设要做二次元人物头像的生成,让机器吃这张图片,因为这张图画的很好所以output就是1.0(假设1.0就是它可以输出最大的值)。假设这张图画的很差,机器就给它0.1分,这个就是discriminator做的事情。

生成器和判别器之间的对抗
在GAN里,生成器和判别器之间的关系就像是猎食者和它的猎物之间的关系。

猎食者和它的猎物之间,不同的对抗阶段:
- 生成器:右上角这个是一只枯叶蝶的祖先,它是彩色的
- 判别器:因为麻雀会吃枯叶蝶,所以枯叶蝶在天择的压力之下就变成棕色的。因为麻雀判断蝴蝶能不能吃的标准就是它是什么颜色。
- 生成器:为了不被麻雀吃掉,枯叶蝶进化成了棕色(如果是彩色就会被吃掉,如果是棕色就不会被吃掉);
- 判别器:但是枯叶蝶的天敌麻雀也是会进化的,麻雀进化成了比比鸟,比比鸟判断一个东西能不能吃的标准并不是看颜色,而是看有没有叶脉的纹路。
- 生成器:枯叶蝶在天择的压力之下就产生了看起来像是叶脉的条纹,它可以骗过比比鸟。
- 判别器:但是比比鸟也会再进化,进化之后它可能有别的标准来判断这个东西是不是可以吃的。
- 生成器:枯叶蝶也会再不断地进化
- .........
猎食者和天敌就会再互相拮抗之中变得越来越强。而这个枯叶蝶就像是生成器,而它的天敌就像是判别器 因为generator和discriminator之间有一种对抗的关系(它们像是天敌与被猎食者之间的关系),所以用adversarial(对抗)这个词汇来命名这个技术(Generative Adversarial Network)。
损失函数的设计
这样的对抗关系也可以用GAN里的损失函数来解释:
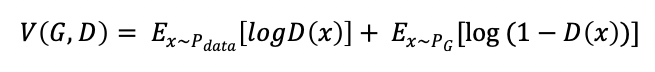

V指损失函数,D指判别器,G指生成器,Pdata指真实数据的概率分布,PG是生成数据的概率分布。
训练方式
将判别器和生成器联合起来看,整个GAN的结构是这样的:

上节的对抗关系可以看出,GAN是一个交替训练的流程,一般来讲是:
- 生成随机向量,生成器输出,固定生成器参数,训练判别器;
- 重新生成随机向量,生成器输出,固定判别器参数,拿到判别器输出,训练生成器;
训练的伪代码如下:
5.3 image2image图生图的CycleGAN算法

5.3.1 CycleGAN简单介绍
上节介绍了从随机向量生成图片的GAN算法,这里简单介绍一个从图片生成图片的GAN:循环生成对抗网络(简称CycleGans),能从一个风格的图像,转换成另一个风格,只是风格的迁移,本身图像内容不会变化。 CycleGAN的结果如下:

包含了两个生成器G、F和两个判别器Dx、Dy,以及两个不同风格的图像数据集X、Y。其中
- G用于X风格图像生成Y风格图像;
- F用于Y风格图像生成X风格图像;
- Dy用于判别从G(x)生成的y和真实Y;
- Dx用于判别从F(y)生成的x和真实X;
5.3.2 CycleGAN的损失函数
单个GAN的损失函数


循环变换一致性
将该损失定义为输入值x与前向预测F(G(x))以及输入值y与前向预测G(F(y ))之间的差异。

完整损失
将上述的三个损失加起来:

5.4 GAN应用落地
5.4.1 和算法相关的应用
自动生成新的训练数据
人工智能的训练是需要大量的数据集的,如果全部靠人工收集和标注,成本是很高的。GAN 可以自动的生成一些数据集,提供低成本的训练数据。

5.4.2 花里胡哨的应用
编辑图片
使用GAN可以生成特定的照片,例如更换头发颜色、更改面部表情、甚至是改变性别。
预测不同年龄阶段
给一张人脸照片, GAN 就可以帮你预测不同年龄阶段你会长成什么样。

高分辨率
给GAN一张照片,他就能生成一张分辨率更高的照片,使得这个照片更加清晰。

图像修复 假如照片中有一个区域出现了问题(例如被涂上颜色或者被抹去),GAN可以修复这个区域,还原成原始的状态。

5.4.3 落地应用
在抖音、小红书等app上爆火的动漫人物生成
6. 文字生成图片
上节GAN中介绍了从随机向量生成图片、图片生成图片,但将输入的随机向量、图片换成文字,是不是就可以自定义一段描述,就生成一张图呢?
6.1 文字+GAN
https://arxiv.org/pdf/1605.05396.pdf 相比image2image,text2text更难,论文《Generative Adversarial Text to Image Synthesis》介绍了如何通过 GAN 进行从文字到图像的转化。比方说,若神经网络的输入是“粉色花瓣的花”,输出就会是一个包含了这些要素的图像。该任务包含两个部分:1. 利用自然语言处理来理解输入中的描述。2. 生成网络输出一个准确、自然的图像,对文字进行表达。

这个模型流程如下:
- 先用文本向量+随机值组成向量,作为生成器的输入;
- 生成器拿到向量生成图片;
- 判别器对图片进行参数空间转换+打平,和文本向量组合后,再进行判别;
6.2 DALL-E 2
- https://mp.weixin.qq.com/s/6F4wnzaYF_EMDgfF_Pwd8A https://zhuanlan.zhihu.com/p/521702011 要说2022年最惊艳的text2image模型,必然是OpenAI的DALL-E 2了。DALL-E 2不仅能按用户指令生成明明魔幻,却又看着十分合理不明觉厉的图片。作为一款强大的模型,目前我们已知DALL-E 2还可以:
- 生成特定艺术风格的图像,仿佛出自该种艺术风格的画家之手,十分原汁原味!
- 保持一张图片显著特征的情况下,生成该图片的多种变体,每一种看起来都十分自然;
- 修改现有图像而不露一点痕迹,天衣无缝。
6.2.1 整体结构
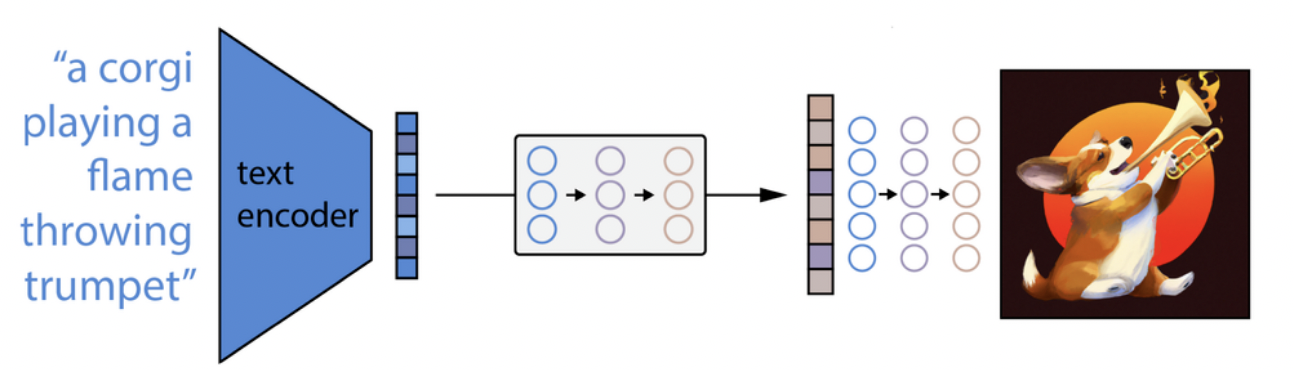
针对图片生成这一功能来说,DALL-E 2的工作原理剖析出来,看似并不复杂:
- 首先,将文本提示输入文本编码器,该训练过的编码器便将文本提示映射到表示空间。
- 接下来,称为先验的模型将文本编码映射到相应的图像编码,图像编码捕获文本编码中包含的提示的语义信息。
- 最后,图像解码模型随机生成一幅从视觉上表现该语义信息的图像。
6.2.2 模型训练
- 但实际上,DALL-E 2处处都是细节。
CLIP-把文本和视觉图像联系起来
- CLIP就是在图像预训练那节介绍的模型,它几乎就是DALL-E 2的心脏,因为CLIP才是那个把自然语言片段与视觉概念在语义上进行关联的存在,这对于生成与文本对应的图像来说至关重要。
GLIDE-从视觉语义生成图像
- CLIP学习了一个表示空间,在这个表示空间当中很容易确定文本编码和视觉编码的相关性。我们需要学会利用表示空间来完成反转图像编码映射这个任务,这个过程就是DALL-E 2的后部分。在这里,OpenAI使用了GLIDE的修改版本来执行图像生成。GLIDE模型学习反转图像编码过程,以便随机解码CLIP图像嵌入,其中为了进行图像生成,GLIDE使用了扩散模型(Diffusion Model)。

先验模型-从文本语义到相应的视觉语义的映射
- 如何将文字提示中的文本条件信息注入到图像生成过程中?除了图像编码器,CLIP还学习了文本编码器。DALL-E 2使用了另一种模型,作者称之为先验模型,以便从图像标题的文本编码映射到对应图像的图像编码。DALL-E 2的作者用自回归模型和扩散模型进行了实验,但最终发现它们的性能相差无几。考虑到扩散模型的计算效率更高,因此选择扩散模型作为 DALL-E 2的先验。

6.3 文字生成图像的应用落地
6.3.1 AI绘画
百度-文心一格

抖音

7.文字上的AIGC:ChatGPT介绍
上面介绍了文生图、图生图,下面介绍最近很火的文生文模型ChatGPT OpenAI 发布的ChatGPT,是一个可以对话的方式进行交互的模型,因为它的智能化,得到了很多用户的欢迎。ChatGPT 也是 OpenAI 之前发布的 InstructGPT 的亲戚,ChatGPT 模型的训练是使用 RLHF(Reinforcement learning with human feedback)也许ChatGPT 的到来,也是 OpenAI 的 GPT-4 正式推出之前的序章。 ChatGPT目前还没有论文放出,但是ChatGPT和2022年初OpenAI提出的InstructGPT相差不大,下面我们将同时介绍ChatGPT/InstructGPT。
7.1 ChatGPT
https://openai.com/blog/chatgpt/ https://beta.openai.com/docs/model-index-for-researchers GPT-3 可以使用精心设计的文本提示执行自然语言任务。 但这些模型也可能产生不真实、有毒或反映有害情绪的输出。 这部分是因为 GPT-3 被训练来预测大型互联网文本数据集上的下一个单词,而不是安全地执行用户想要的语言任务。 换句话说,这些模型与他们的用户不一致。 为了让模型更安全、更有帮助和更一致,在ChatGPT/InstructGPT中使用了一种称为基于人类反馈的强化学习 (RLHF) 的现有技术。
7.1.1 InstructGPT/ChatGPT中的强化学习
强化学习非常像生物进化,模型在给定的环境中,不断地根据环境的惩罚和奖励(reward),拟合到一个最适应环境的状态。而InstructGPT/ChatGPT中的RLHF最早可以追溯到Google在2017年发表的《Deep Reinforcement Learning from Human Preferences》,它通过人工标注作为反馈,提升了强化学习在模拟机器人以及雅达利游戏上的表现效果。
InstructGPT/ChatGPT中还用到了强化学习中一个经典的算法:OpenAI提出的最近策略优化(Proximal Policy Optimization,PPO)。PPO算法是一种新型的Policy Gradient算法,Policy Gradient算法对步长十分敏感,但是又难以选择合适的步长,在训练过程中新旧策略的的变化差异如果过大则不利于学习。PPO提出了新的目标函数可以在多个训练步骤实现小批量的更新,解决了Policy Gradient算法中步长难以确定的问题。
7.1.2 InstructGPT的训练过程

上图为InstructGPT论文里的训练过程,总的来讲,InstructGPT可以分为三步:
- 根据采集的SFT数据集对GPT-3进行有监督的微调(Supervised FineTune,SFT);
- 收集人工标注的对比数据,训练奖励模型(Reword Model,RM);
- 使用RM作为强化学习的优化目标,利用PPO算法微调SFT模型。
第一步-使用人工标注数据微调GPT-3
- 微调的有监督数据集SFT,是用来训练第1步有监督的模型,即使用采集的新数据,按照GPT-3的训练方式对GPT-3进行微调。因为GPT-3是一个基于提示学习的生成模型,因此SFT数据集也是由提示-答复对组成的样本。SFT数据一部分来自使用OpenAI的PlayGround的用户,另一部分来自OpenAI雇佣的40名标注工(labeler)。
第二步-使用人工标注数据训练奖励模型RM
- 如果要用强化学习训练语言模型,那么就需要为InstructGPT的训练设置一个奖励目标。这个奖励目标一定要尽可能全面且真实的对齐我们需要模型生成的内容。 OpenAI通过人工标注的方式来提供这个奖励,通过人工对可以给那些涉及偏见的生成内容更低的分从而鼓励模型不去生成这些人类不喜欢的内容。InstructGPT的做法是先让模型生成一批候选文本,让后通过labeler根据生成数据的质量对这些生成内容进行排序。 奖励模型RM的结构是将SFT训练后的模型的最后的嵌入层去掉后的模型。它的输入是prompt和Reponse,输出是奖励值。具体的讲,对弈每个prompt,InstructGPT会随机生成4-9个输出,然后它们向每个labeler成对的展示输出结果,然后用户从中选择效果更好的输出并进行排序。 奖励模型的损失函数表示如下。这个损失函数的目标是最大化labeler更喜欢的响应和不喜欢的响应之间的差值。其中的r代表模型的输出,x是prompt,y是response。

第三步-强化学习PPO算法微调优化SFT模型
- 第三步的PPO数据没有进行标注,它均来自GPT-3的API的用户。既又不同用户提供的不同种类的生成任务,其中占比最高的包括生成任务(45.6%),QA(12.4%),头脑风暴(11.2%),对话(8.4%)等。 在模型训练上,第三步里的PPO模型,用第二步得到的奖励模型来指导SFT模型的继续训练。
7.2.3 ChatGPT和InstructGPT的区别在哪?
- https://openai.com/blog/chatgpt/ ChatGPT和InstructGPT的训练过程比较相似。

ChatGPT和InstructGPT的对比如下,训练方法是几乎一样的,主要区别在base模型和数据采集方法。其中GPT 3.5是在2022年初就训练完成,整个GPT 3.5系列https://beta.openai.com/docs/model-index-for-researchers,可以看到3.5并不是指一个模型,而是一个系列,InstructGPT也是属于3.5的一类。
base模型 | 数据采集方法 | 训练方法 | |
|---|---|---|---|
InstructGPT | 基于GPT 3finetune | instructGPT通过外包人员进行数据标注 | supervised fine-tuning, RW model, Reinforcement learning |
ChatGPT | 基于GPT 3.5finetune | ChatGPT利用AI训练人员AI trainer进行数据标注,更加专业 | supervised fine-tuning, RW model, Reinforcement learning |
7.3 ChatGPT的应用落地
7.3.1 固定句式的创作
帮我给xxx写一句广告语

7.3.2 文本相似匹配
请问”“和”yyy“这两句话相似吗,只回答相似或者不相似

7.3.3 相似问生成
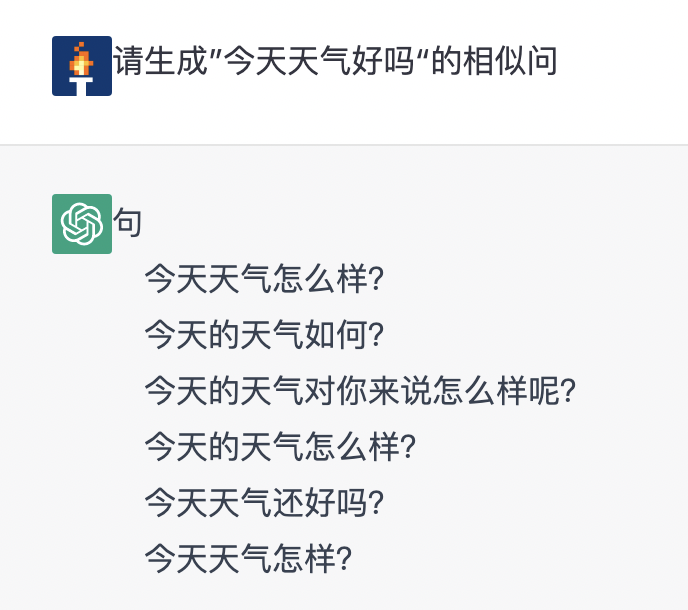
7.3.4 问答匹配
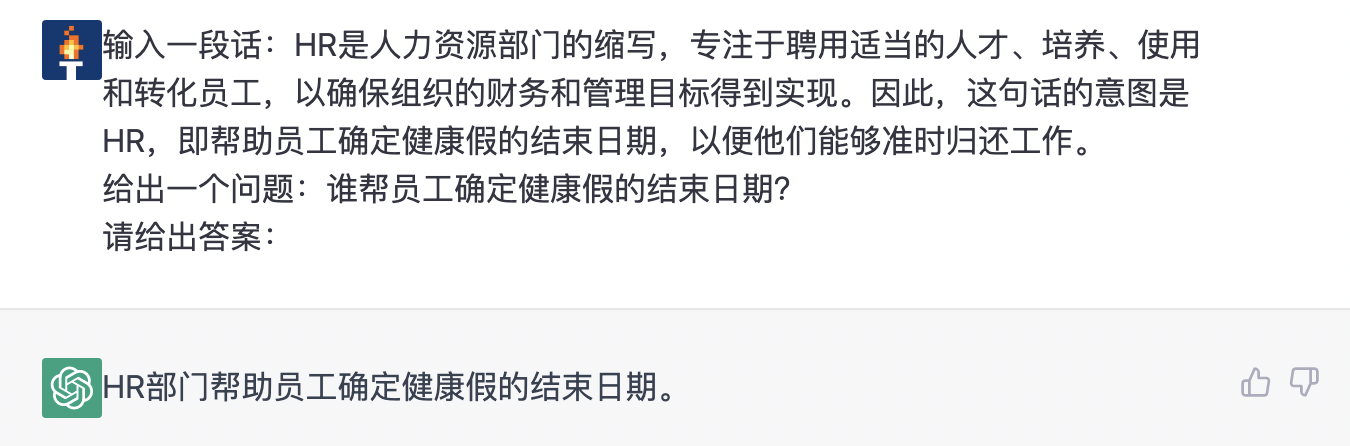
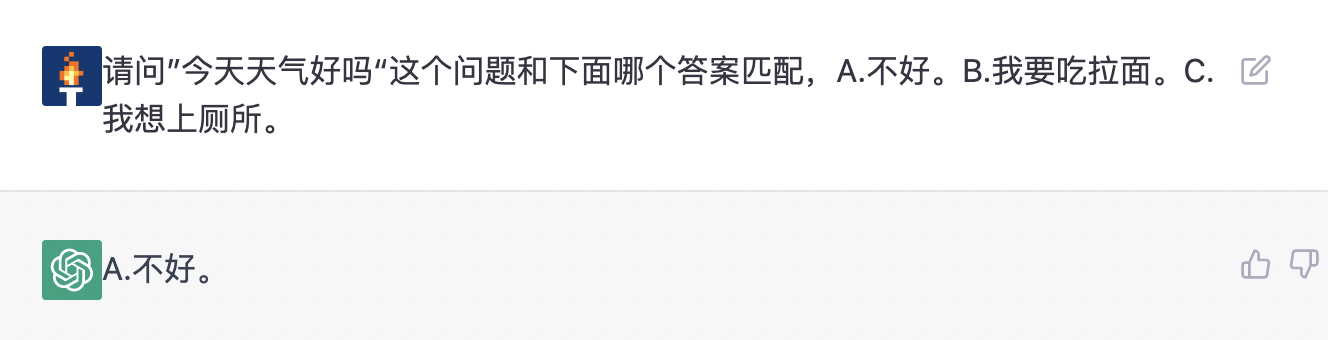
7.3.5 风险识别

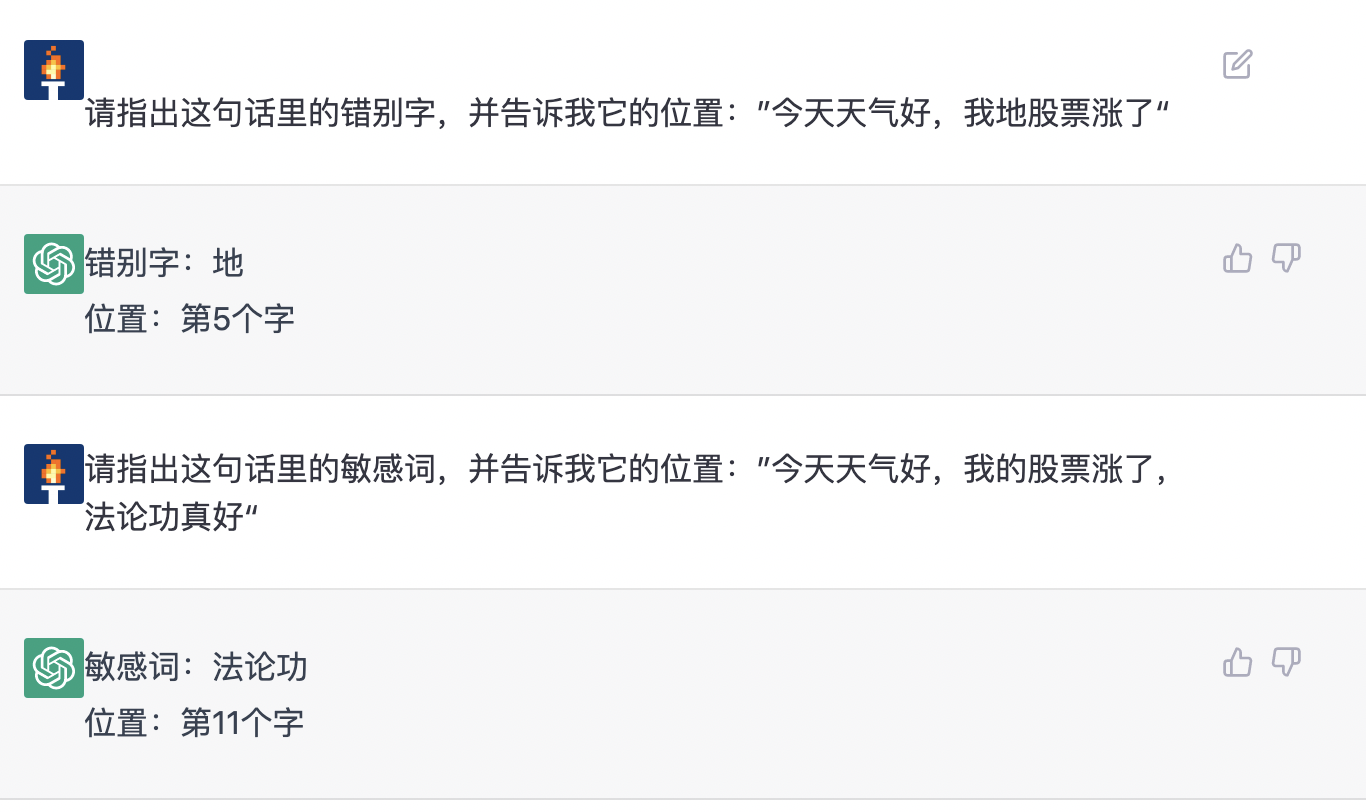
7.3.6 错别字、敏感词识别
7.3.7 实体抽取
7.3.8 意图识别
8. 更多其他AIGC的应用落地
1)AIGC+传媒:写稿机器人、采访助手、视频字幕生成、语音播报、视频锦集、人工智能合成主播等 2)AIGC+电商:商品3D模型、虚拟主播、虚拟货场等 3)AIGC+影视:AI剧本创作、AI合成人脸和声音、AI创作角色和场景、AI自动生成影视预告片等 4)AIGC+娱乐:AI换脸应用(如FaceAPP、ZAO)、AI作曲(如初音未来虚拟歌姬)、AI合成音视频动画等 5)AIGC+教育:AI合成虚拟教师、AI根据课本制作历史人物形象、AI将2D课本转换为3D 6)AIGC+金融:通过AIGC实现金融资讯、产品介绍视频内容的自动化生产,通过AIGC塑造虚拟数字人客服等 7)AIGC+医疗;AIGC为失声者合成语言音频、为残疾人合成肢体投影、为心理疾病患者合成医护陪伴等 8)AIGC+工业:通过AIGC完成工程设计中重复的低层次任务,通过AIGC生成衍生设计,为工程师提供灵感等
9. AIGC 市场服务调研
AIGC类型/应用场景 | 产品/服务名称 | 链接 | 计费方式 | 所属公司 |
|---|---|---|---|---|
文字生成文字 | ChatGPT | 产品链接:https://chat.openai.com/chat订阅服务说明:https://help.openai.com/en/articles/6950777-chatgpt-plus需排队等待邀请,时间不定 | 暂不明确,网传大约20美元每月。其他API:https://openai.com/api/pricing/ | openai |
文字生成文字 | GPT | API使用说明:https://platform.openai.com/docs/guides/completion | 付费说明:https://openai.com/api/pricing/,效果较好的Davinci模型:0.02美元每 1K tokens,速度最快的Ada模型:0.0004美元每1K tokens,1000个tokens大约为750个单词。 | openai |
文生文、文生图 | modelscope | GPT大模型:https://modelscope.cn/models/damo/nlp_gpt3_text-generation_13B/summary各种大模型模型:https://modelscope.cn/models | 开源的模型商用需要遵循开源协议,具体可参考下对应的模型的开源协议。 | 阿里巴巴 |
文字生产图像 | 文心一格 | 官网:https://yige.baidu.com/ | 个人付费,每生产1张消耗2电量。100电量/39元人民币,200电量/69元人民币,800电量/269元人民币,商业合作未知:https://yige.baidu.com/personal/cooperation | 百度 |
文生文、文生图 | 文心大模型ERNIE | 官网:https://wenxin.baidu.com/ | 部分模型开源,合作需咨询:https://wenxin.baidu.com/wenxin/apply | 百度 |
文字生产图像 | DALL·E | 产品链接:https://labs.openai.com/API使用说明:https://platform.openai.com/docs/api-reference/authentication | 付费说明:https://openai.com/api/pricing/,按图片大小0.016-0.020美元每张图 | openai |
文字生产图像 | 达摩院通义文生图大模型 | https://decoder.modelscope.cn/pcIndex | 没找到,需加群联系 | 阿里巴巴 |
文字生产图像 | Midjourney | https://docs.midjourney.com/ | 付费说明:https://docs.midjourney.com/docs/plans | Midjourney |
文字生产图像 | AI 作画 文字生成图片Stable Diffusion | https://developer.huaweicloud.com/develop/aigallery/notebook/detail?id=03aab198-dc21-4974-ab33-352e9f56939c&ticket=ST-193587-MgJGfa1fxl6GFZ77F7vFjRod-sso | 需要自己训练、部署,按照部署标准来收费。 | 华为云 |
文字生产图像 | 6pen | https://6pen.art/ | 价格说明:https://maoxianqiu.feishu.cn/wiki/wikcniQXA8kJYS2Q97E3gL8sCAd | NiucoData |
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。