Mac 配置ChatGLM-6B环境
原创
背景
最近要做一些关于NLP相关的工作和比赛,因此要用到语义分析这类模型,ChatGPT虽然很强大,奈何不太适合在工作和国内的环境中使用,因此需要用到一些平替的模型,比如ChatGLM-6B。
什么是ChatGLM-6B
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考我们的博客。
为了方便下游开发者针对自己的应用场景定制模型,我们同时实现了基于 P-Tuning v2 的高效参数微调方法 (使用指南) ,INT4 量化级别下最低只需 7GB 显存即可启动微调。
不过,由于 ChatGLM-6B 的规模较小,目前已知其具有相当多的局限性,如事实性/数学逻辑错误,可能生成有害/有偏见内容,较弱的上下文能力,自我认知混乱,以及对英文指示生成与中文指示完全矛盾的内容。请大家在使用前了解这些问题,以免产生误解。更大的基于 1300 亿参数 GLM-130B 的 ChatGLM 正在内测开发中。
引自官方GitHub
看了一下官方的说明,是支持在消费级显卡上部署的,同时也支持Mac M1,因此今天就和大家先体验一下,后面我们会慢慢的涉及到训练相关的内容。
基础环境准备
为了更好的发挥Mac显卡的作用,我们安装一下PyTorch的PyTorch-Nightly版本
基础的Python管理环境我们依然使用miniconda来管理
conda create -n chat python=3.10.9 -y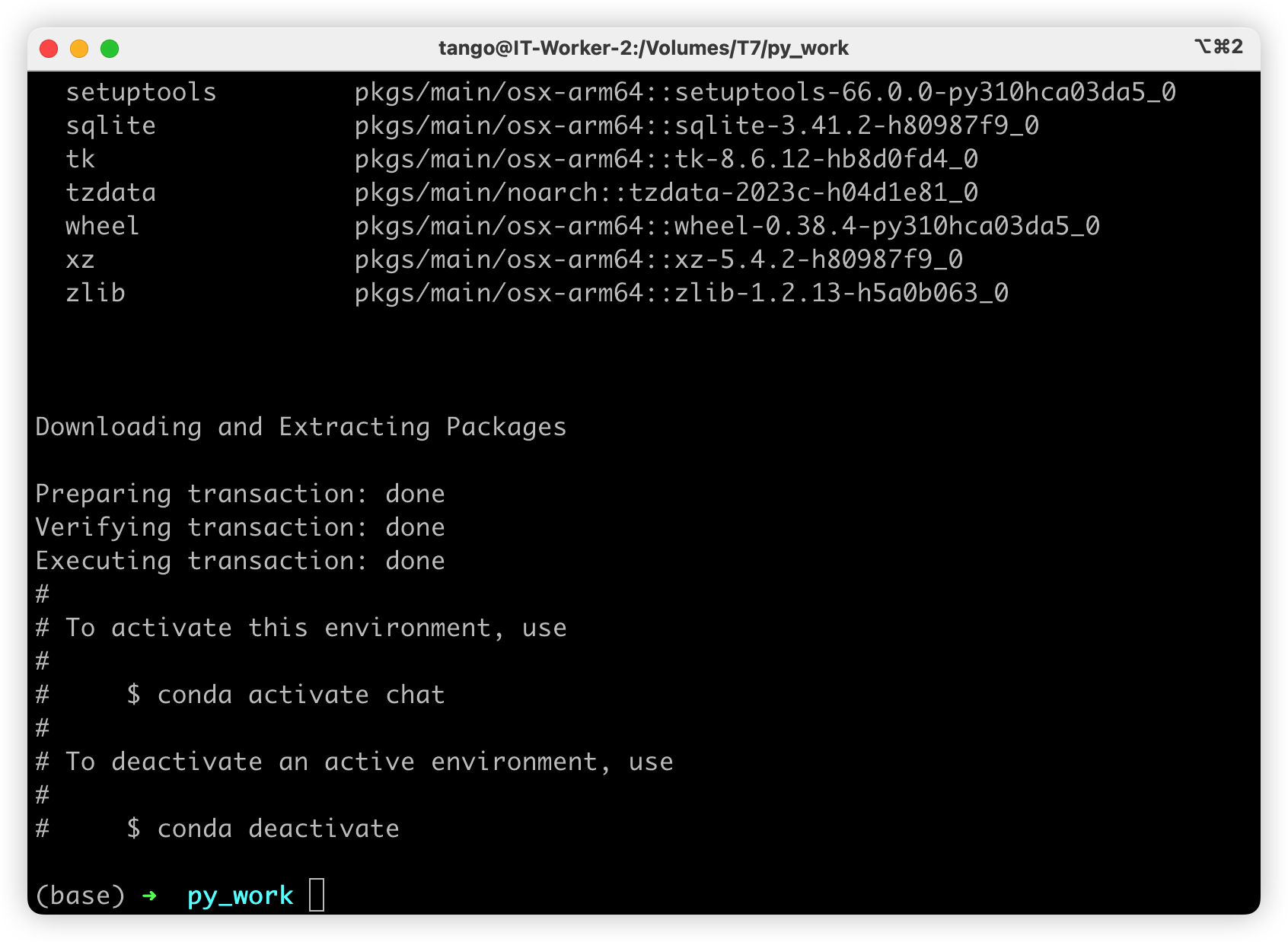
激活环境后我们继续安装PyTorch
conda install pytorch-nightly::pytorch torchvision torchaudio -c pytorch-nightly -y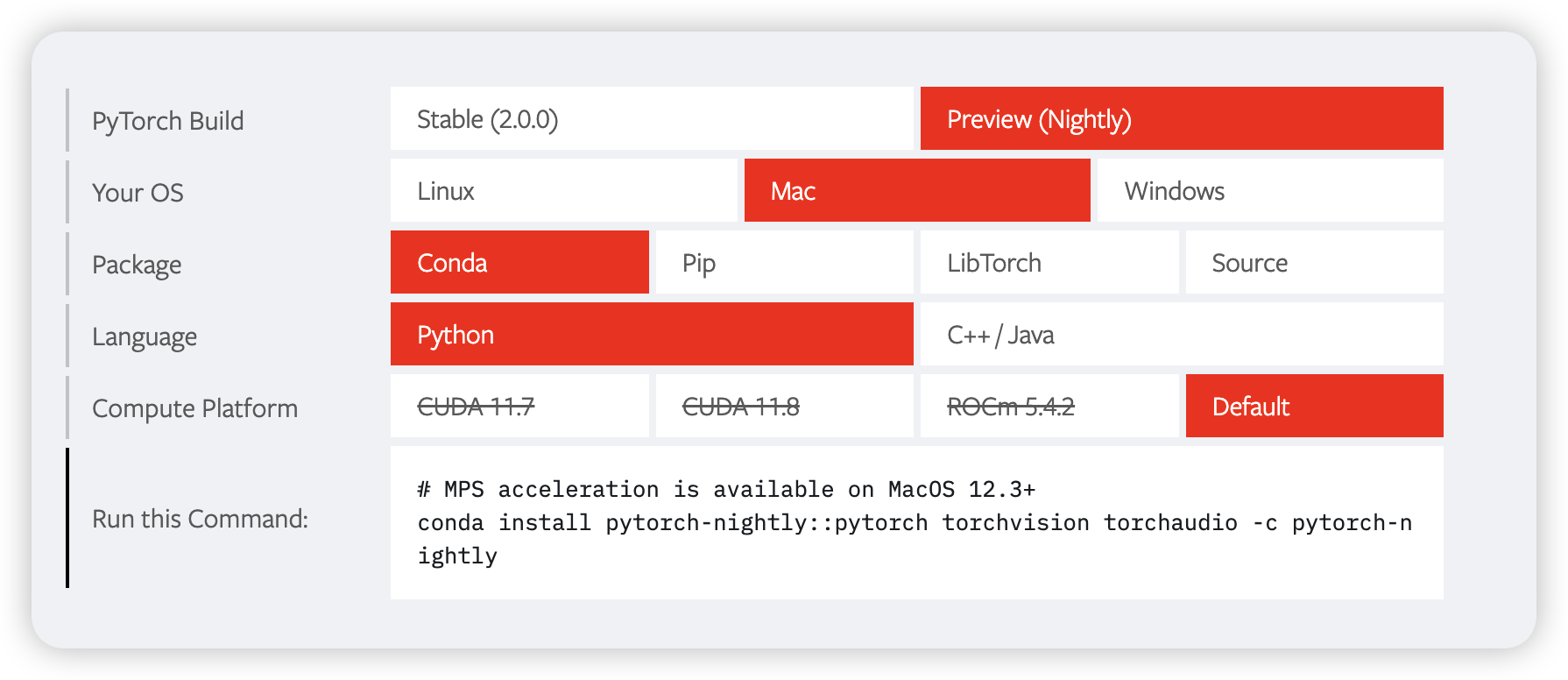
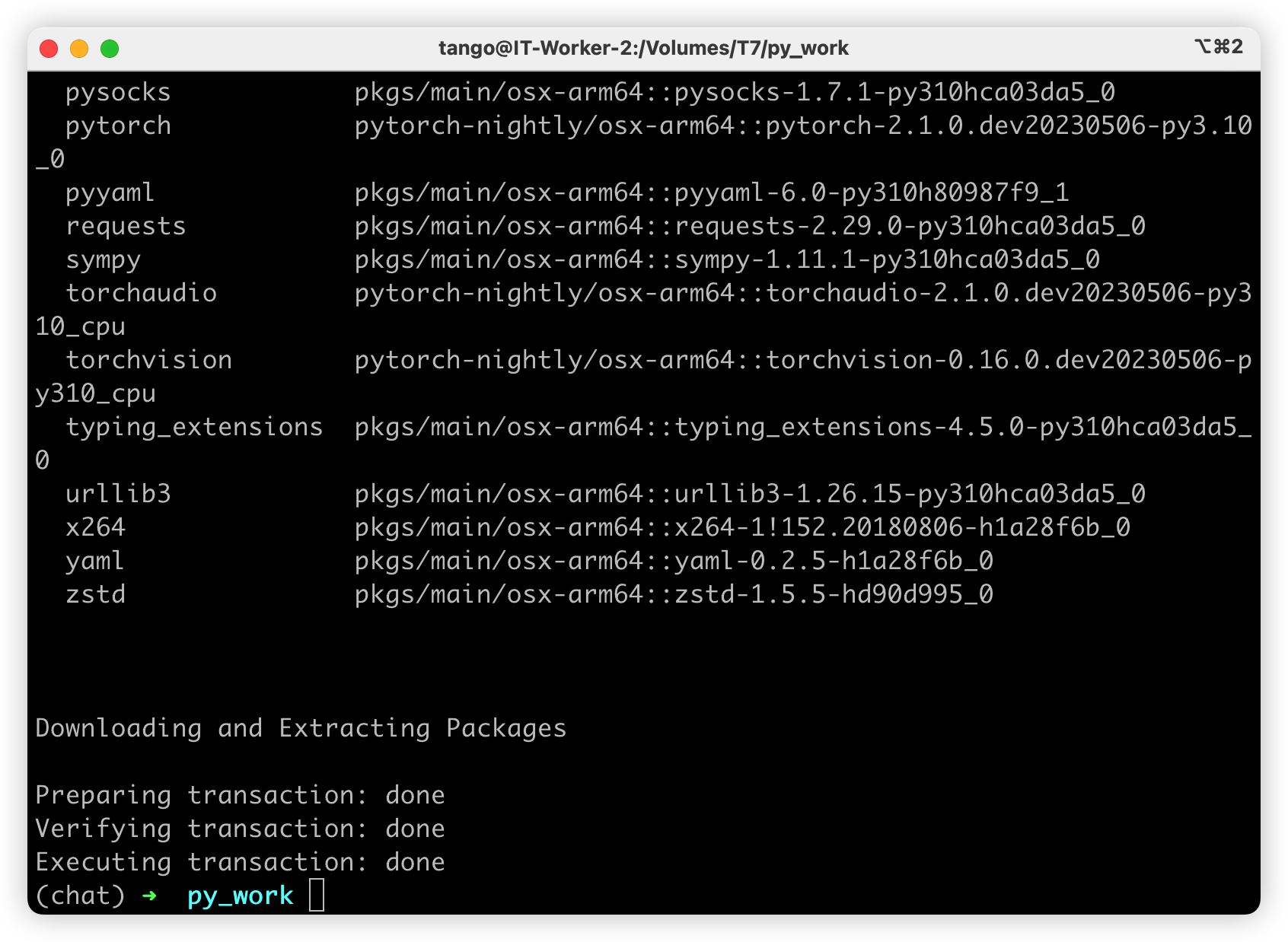
克隆项目到本地电脑
我将项目依然是保存在我的T7移动硬盘中(它最近承受的有点多,哈哈哈)
然后安装依赖包
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
看看效果
我们先在终端中启动一下Python环境,看看效果如果,在当前的虚拟环境中输入python,进入交互界面
按照官方提示一次输入一下内容
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好?!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。我们在输入第二行的代码是,会发现要去huggingface这个网站下载个模型
我们可以用git直接clone,但是在这之前需要安装git-lfs,这个是用来克隆大文件用的。
brew install git-lfs
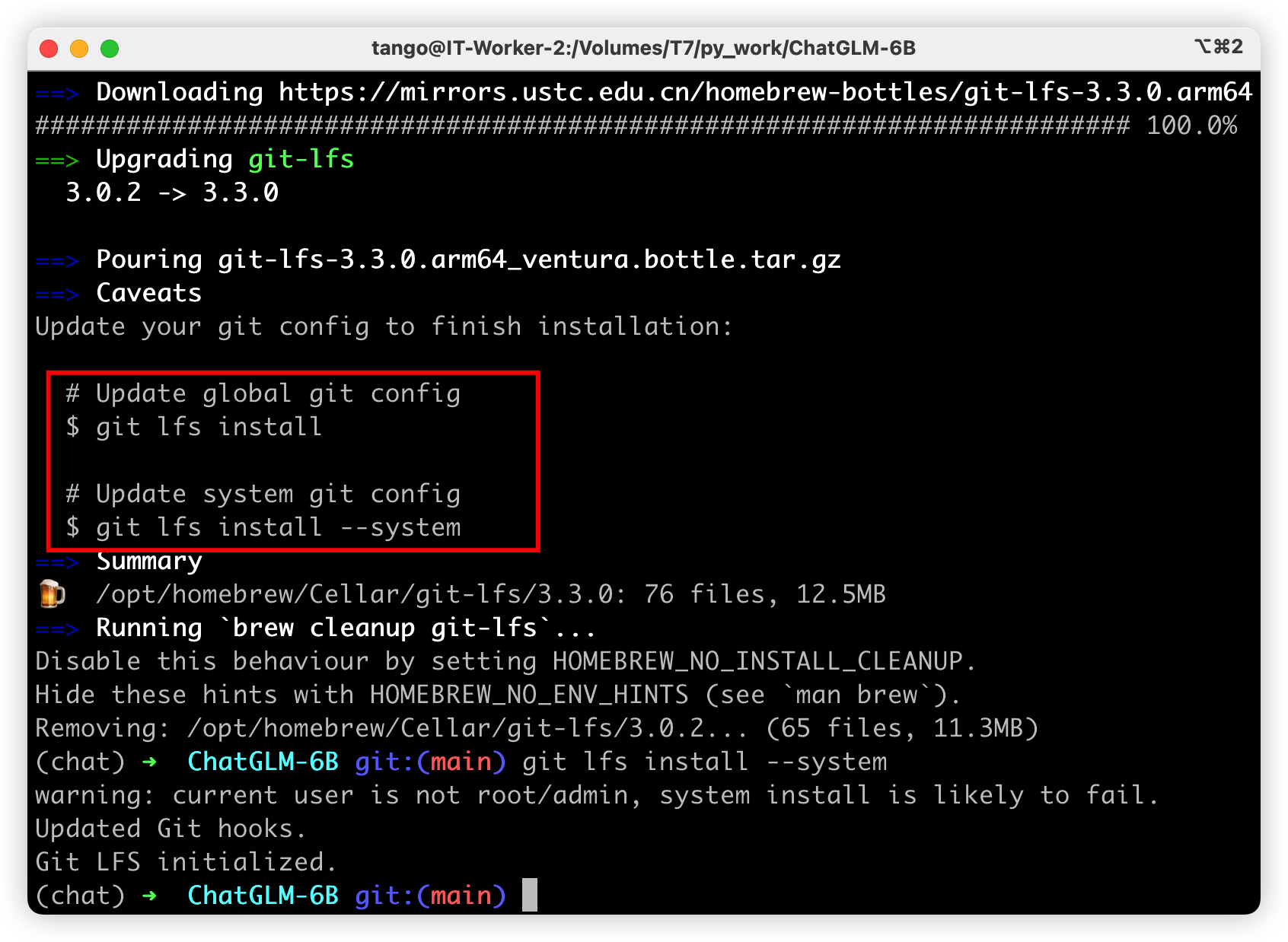
按照提示更新一下即可
我们开始正式的克隆需要的模型
git clone https://huggingface.co/THUDM/chatglm-6b
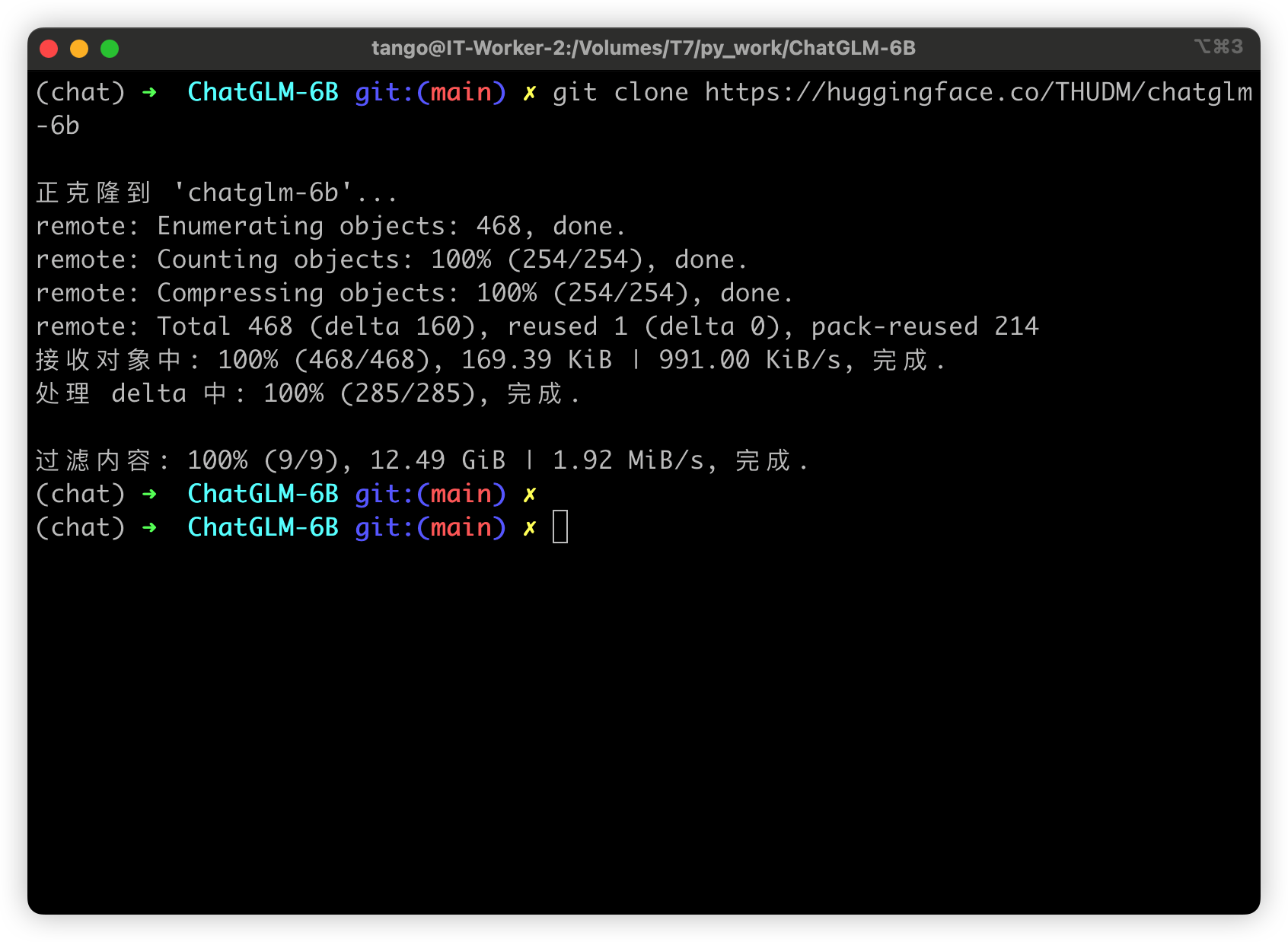
将模型下载到本地之后,将以上代码中的 THUDM/chatglm-6b 替换为你本地的 chatglm-6b 文件夹的路径,即可从本地加载模型。
我这边是直接将模型放在了ChatGLM的目录下了
好了今天的内容就是这些了,我是Tango一个热爱分享技术的程序猿我们下期见。
我正在参与2024腾讯技术创作特训营第五期有奖征文,快来和我瓜分大奖!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。