Python爬虫之Ajax分析方法与结果提取
Python爬虫之Ajax分析方法与结果提取

爬虫专栏:http://t.csdnimg.cn/WfCSx
Ajax 分析方法
这里还以前面的微博为例,我们知道拖动刷新的内容由 Ajax 加载,而且页面的 URL 没有变化,那么应该到哪里去查看这些 Ajax 请求呢?
1. 查看请求
这里还需要借助浏览器的开发者工具,下面以 Chrome 浏览器为例来介绍。
首先,用 Chrome 浏览器打开微博的链接 https://m.weibo.cn/u/3261134763,随后在页面中点击鼠标右键,从弹出的快捷菜单中选择 “检查” 选项,此时便会弹出开发者工具,如图所示。
此时在 Elements 选项卡中便会观察到网页的源代码,右侧便是节点的样式。
不过这不是我们想要寻找的内容。切换到 Network 选项卡,随后重新刷新页面,可以发现这里出现了非常多的条目,如图所示。
前面也提到过,这里其实就是在页面加载过程中浏览器与服务器之间发送请求和接收响应的所有记录。
Ajax 其实有其特殊的请求类型,它叫作 xhr。在图中,我们可以发现一个名称以 getIndex 开头的请求,其 Type 为 xhr,这就是一个 Ajax 请求。用鼠标点击这个请求,可以查看这个请求的详细信息。
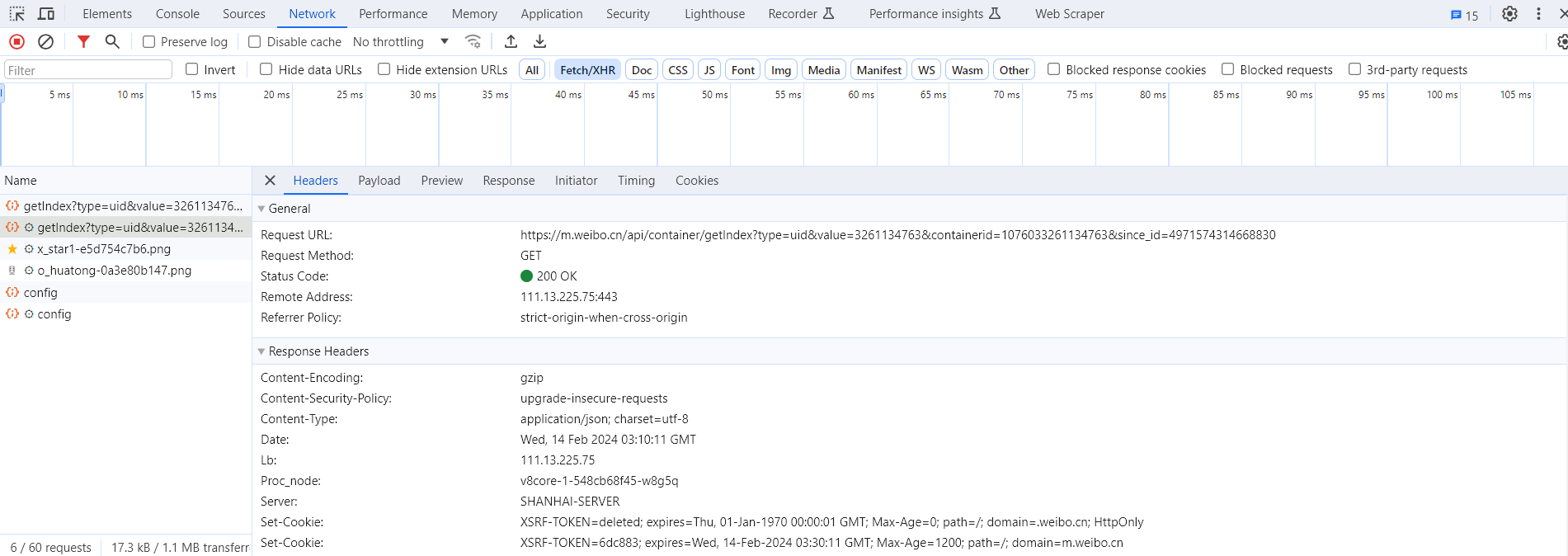
在右侧可以观察到其 Request Headers、URL 和 Response Headers 等信息。其中 Request Headers 中有一个信息为 X-Requested-With:XMLHttpRequest,这就标记了此请求是 Ajax 请求,如图所示。
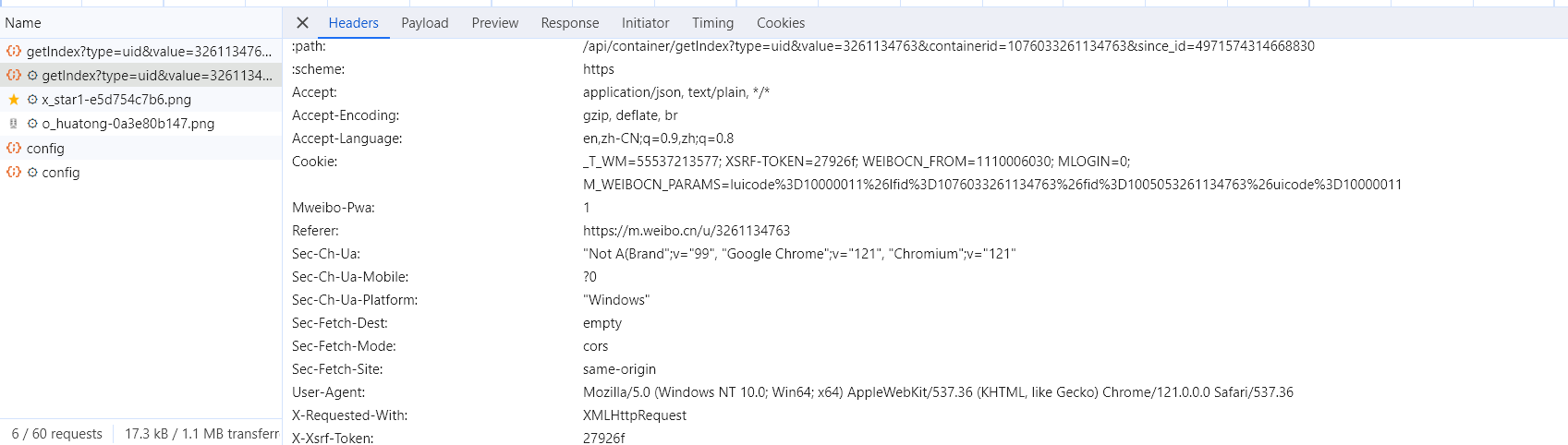
随后点击一下 Preview,即可看到响应的内容,它是 JSON 格式的。这里 Chrome 为我们自动做了解析,点击箭头即可展开和收起相应内容,如图所示。
观察可以发现,这里的返回结果是个人信息,如昵称、简介、头像等,这也是用来渲染个人主页所使用的数据。JavaScript 接收到这些数据之后,再执行相应的渲染方法,整个页面就渲染出来了。
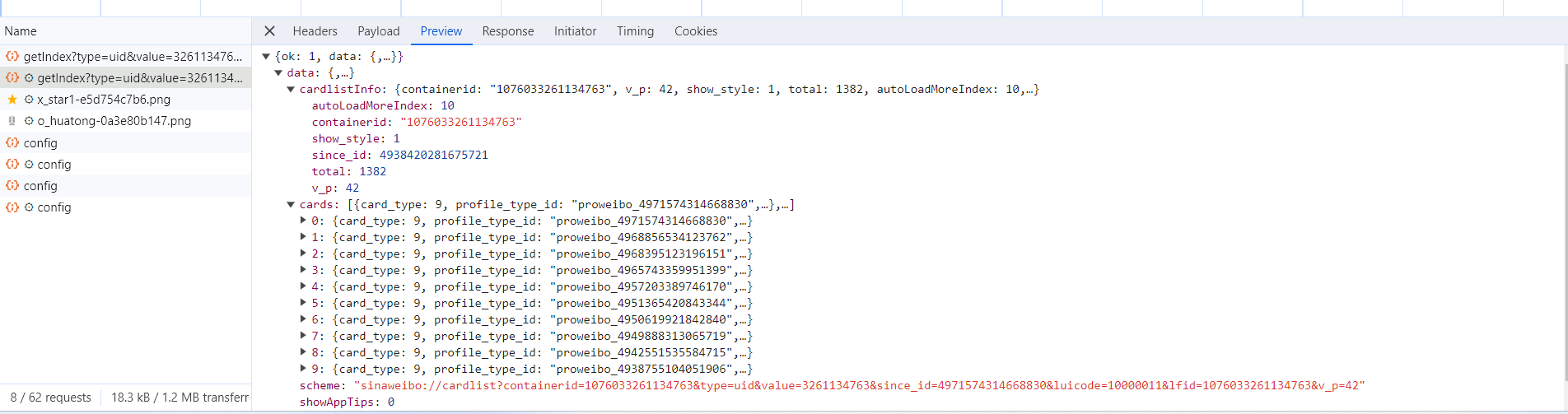
另外,也可以切换到 Response 选项卡,从中观察到真实的返回数据,如图所示。
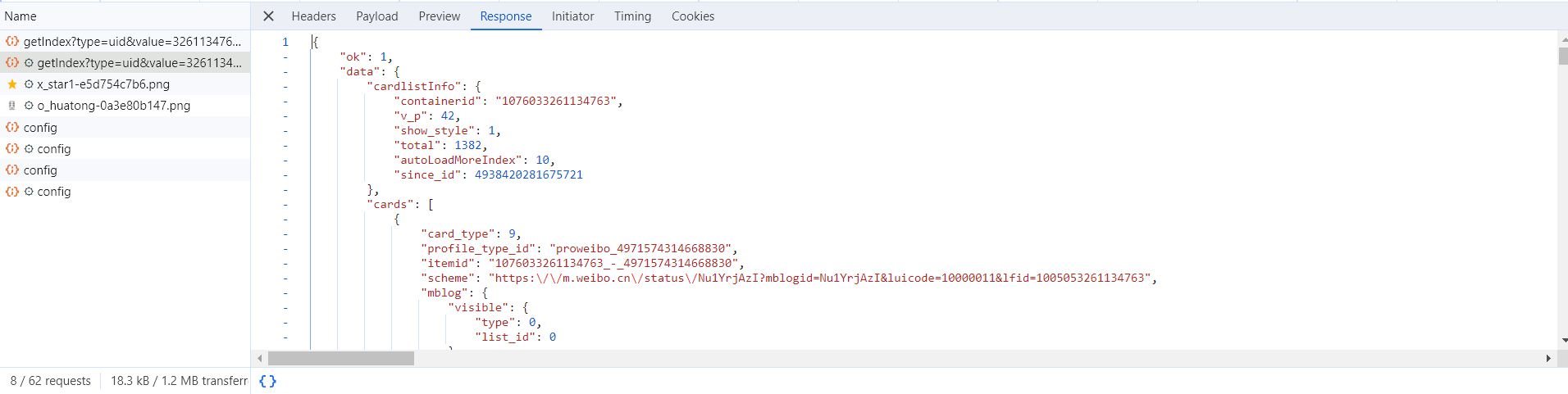
接下来,切回到第一个请求,观察一下它的 Response 是什么,如图所示。
这是最原始的链接 https://m.weibo.cn/u/3261134763 返回的结果,其代码只有不到 50 行,结构也非常简单,只是执行了一些 JavaScript。
所以说,我们看到的微博页面的真实数据并不是最原始的页面返回的,而是后来执行 JavaScript 后再次向后台发送了 Ajax 请求,浏览器拿到数据后再进一步渲染出来的。
2. 过滤请求
接下来,再利用 Chrome 开发者工具的筛选功能筛选出所有的 Ajax 请求。在请求的上方有一层筛选栏,直接点击 XHR,此时在下方显示的所有请求便都是 Ajax 请求了,如图所示。
Ajax 请求
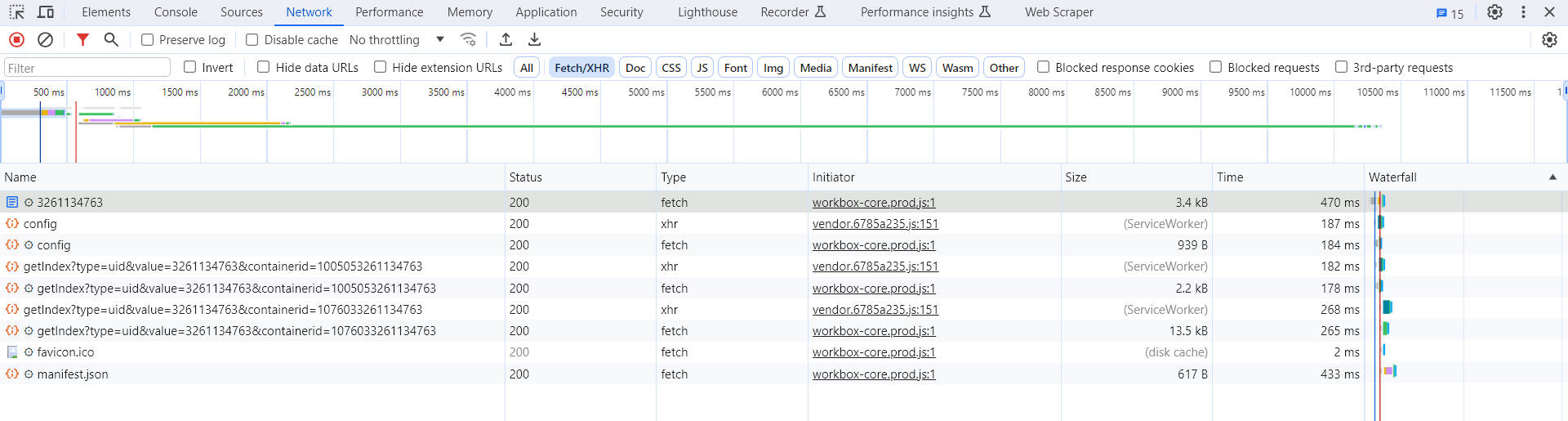
接下来,不断滑动页面,可以看到页面底部有一条条新的微博被刷出,而开发者工具下方也一个个地出现 Ajax 请求,这样我们就可以捕获到所有的 Ajax 请求了。
随意点开一个条目,都可以清楚地看到其 Request URL、Request Headers、Response Headers、Response Body 等内容,此时想要模拟请求和提取就非常简单了。
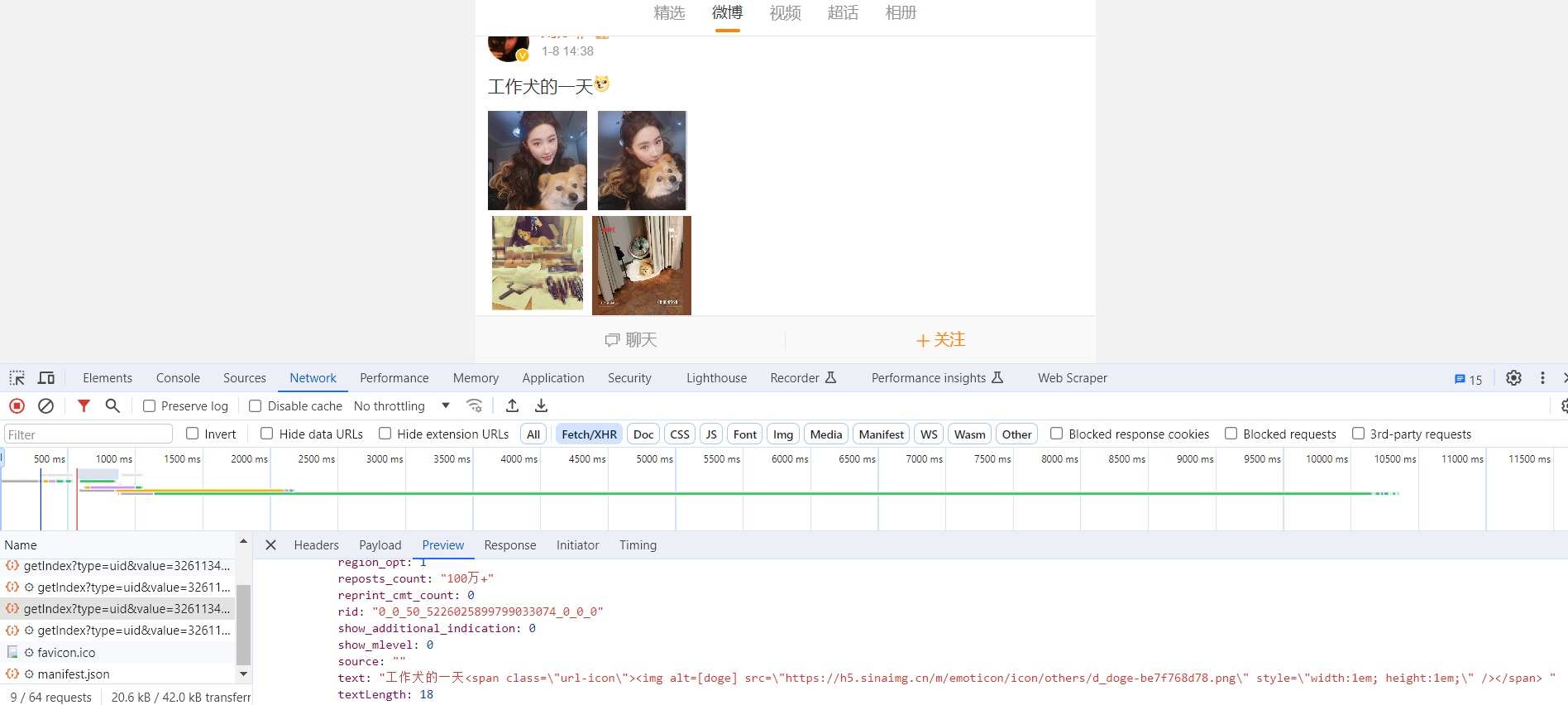
图所示的内容便是某一页微博的列表信息。
微博列表信息
到现在为止,我们已经可以分析出 Ajax 请求的一些详细信息了,接下来只需要用程序模拟这些 Ajax 请求,就可以轻松提取我们所需要的信息了。
接下来,我们用 Python 实现 Ajax 请求的模拟,从而实现数据的抓取。
Ajax 结果提取
这里仍然以微博为例,接下来用 Python 来模拟这些 Ajax 请求,把发过的微博爬取下来。
1. 分析请求
打开 Ajax 的 XHR 过滤器,然后一直滑动页面以加载新的微博内容。可以看到,会不断有 Ajax 请求发出。
选定其中一个请求,分析它的参数信息。点击该请求,进入详情页面,如图所示。
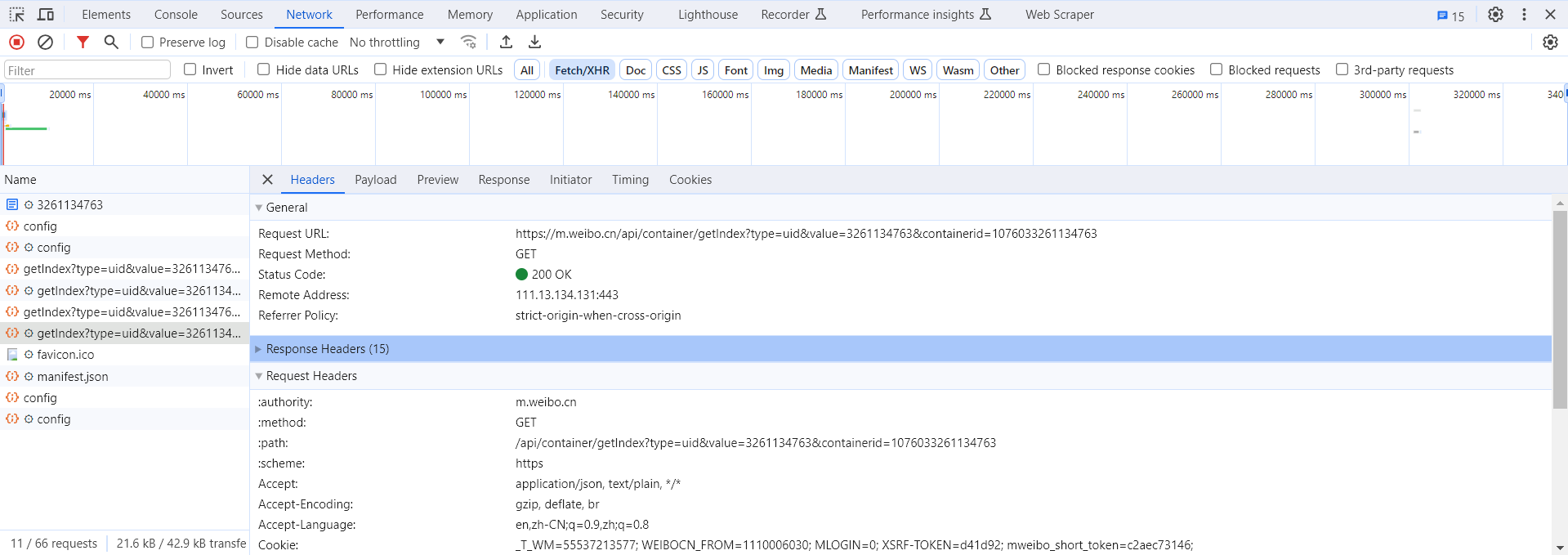
可以发现,这是一个 GET 类型的请求,请求链接为https://m.weibo.cn/api/container/getIndex?type=uid&value=3261134763&containerid=1076033261134763&page=1 ,请求的参数有四个:type、value、containerid、page。
随后再看看其他请求,可以发现,它们的 type、value 和 containerid 始终如一。type 始终为 uid,value 的值就是页面链接中的数字,其实这就是用户的 id。另外,还有 containerid。可以发现,它就是 107603 加上用户 id。改变的值就是 page,很明显这个参数是用来控制分页的,page=1 代表第一页,page=2 代表第二页,以此类推。
2. 分析响应
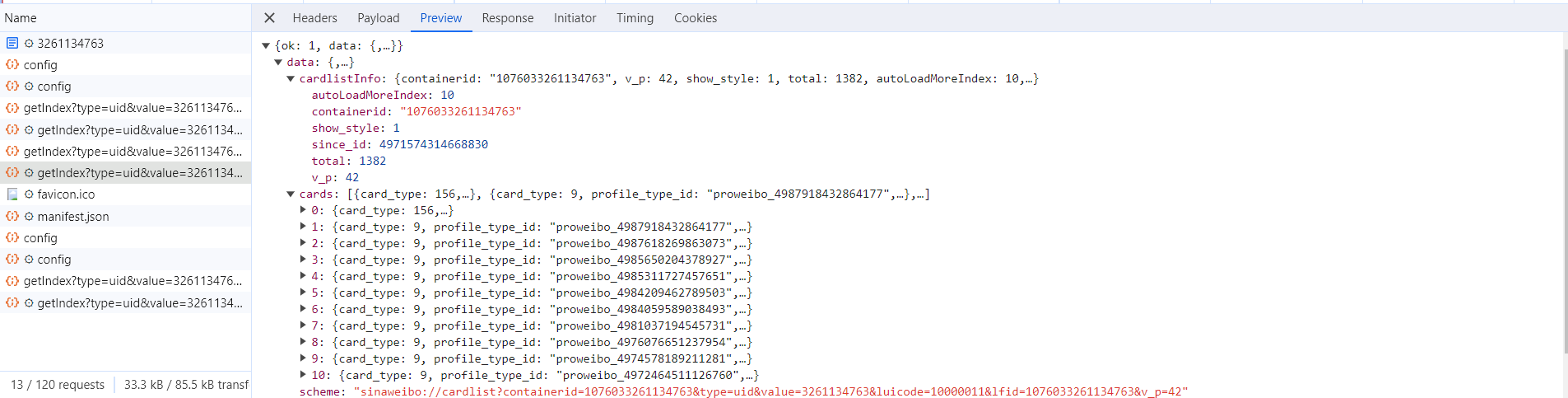
随后,观察这个请求的响应内容,如图所示。
?
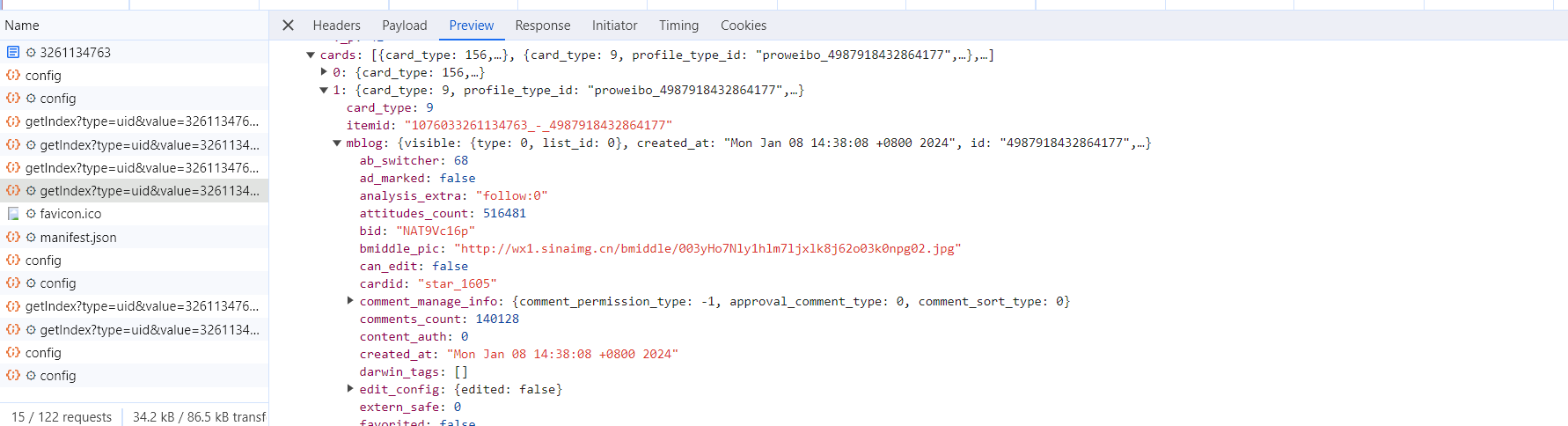
这个内容是 JSON 格式的,浏览器开发者工具自动做了解析以方便我们查看。可以看到,最关键的两部分信息就是 cardlistInfo 和 cards:前者包含一个比较重要的信息 total,观察后可以发现,它其实是微博的总数量,我们可以根据这个数字来估算分页数;后者则是一个列表,它包含 10 个元素,展开其中一个看一下,如图所示。
?
可以发现,这个元素有一个比较重要的字段 mblog。展开它,可以发现它包含的正是微博的一些信息,比如 attitudes_count(赞数目)、comments_count(评论数目)、reposts_count(转发数目)、created_at(发布时间)、text(微博正文)等,而且它们都是一些格式化的内容。
这样我们请求一个接口,就可以得到 10 条微博。
这样的话,我们只需要简单做一个循环,就可以获取所有微博了。
3. 实战演练
这里我们用程序模拟这些 Ajax 请求,将前 10 页微博全部爬取下来。
首先,定义一个方法来获取每次请求的结果。在请求时,page 是一个可变参数,所以我们将它作为方法的参数传递进来,相关代码如下:
from urllib.parse import urlencode
import requests
base_url = 'https://m.weibo.cn/api/container/getIndex?'
headers = {
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/u/3261134763',
'User-Agent': 'Mozilla/5.0 ',
'X-Requested-With': 'XMLHttpRequest',
}
def get_page(page):
params = {
'type': 'uid',
'value': '3261134763',
'containerid': '1076033261134763',
'page': page
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)首先,这里定义了 base_url 来表示请求的 URL 的前半部分。接下来,构造参数字典,其中 type、value 和 containerid 是固定参数,page 是可变参数。接下来,调用 urlencode 方法将参数转化为 URL 的 GET 请求参数,即类似于
type=uid&value=3261134763&containerid=1076033261134763&page=1 这样的形式。随后,base_url 与参数拼合形成一个新的 URL。接着,我们用 requests 请求这个链接,加入 headers 参数。然后判断响应的状态码,如果是 200,则直接调用 json 方法将内容解析为 JSON 返回,否则不返回任何信息。如果出现异常,则捕获并输出其异常信息。
随后,我们需要定义一个解析方法,用来从结果中提取想要的信息,比如这次想保存微博的 id、正文、赞数、评论数和转发数这几个内容,那么可以先遍历 cards,然后获取 mblog 中的各个信息,赋值为一个新的字典返回即可:
from pyquery import PyQuery as pq
?
def parse_page(json):
if json:
items = json.get('data').get('cards')
for item in items:
item = item.get('mblog')
if item is not None:
weibo = {}
weibo['id'] = item.get('id')
weibo['text'] = pq(item.get('text')).text()
weibo['attitudes'] = item.get('attitudes_count')
weibo['comments'] = item.get('comments_count')
weibo['reposts'] = item.get('reposts_count')
yield weibo这里我们借助 pyquery 将正文中的 HTML 标签去掉。
最后,遍历一下 page,一共 10 页,将提取到的结果打印输出即可:
if __name__ == '__main__':
for page in range(1, 11):
json = get_page(page)
results = parse_page(json)
for result in results:
print(result)另外,我们还可以加一个方法将结果保存到 MongoDB 数据库:
from pymongo import MongoClient
?
client = MongoClient()
db = client['weibo']
collection = db['weibo']
?
def save_to_mongo(result):
if collection.insert(result):
print('Saved to Mongo')这样所有功能就实现完成了。运行程序后,样例输出结果如下:
{'id': '4987918432864177', 'text': '工作犬的一天', 'attitudes': 517489, 'comments': 140973, 'reposts': '100万+'}
Saved to Mongo
{'id': '4987618269863073', 'text': '最好的汪小姐', 'attitudes': 221908, 'comments': 20187, 'reposts': 24811}
Saved to Mongo
{'id': '4985650204378927', 'text': '风格如钻,不止一面才更闪耀,坚定如钻,打磨自我耀现辉光。2024新岁序开,和我一起戴上#天梭小美人系列# 臻钻款,向内探索,向外闪耀!\n1月16日起上@天猫 搜【刘亦菲的星卡】参与#龙年集星卡画年画#,听说集齐可解锁我的年画彩蛋哦,猜猜是什么?网页链接\n\n#发光吧小美人#\n...全文', 'attitudes': 165313, 'comments': 42839, 'reposts': 195748}
Saved to Mongo
{'id': '4985311727457651', 'text': '元旦快乐 刘亦菲的微博视频', 'attitudes': 276956, 'comments': 64486, 'reposts': 636746}
Saved to Mongo
{'id': '4984209462789503', 'text': '很高兴成为金典品牌代言人@金典SATINE\n新的一年,和我一起开启有机生活吧~\n#有机生活 有我定义#\n2024年的第一份祝福已送达,点击查收↓ 刘亦菲的微博视频', 'attitudes': 155047, 'comments': 50961, 'reposts': 155759}
Saved to Mongo查看一下 MongoDB,相应的数据也被保存到 MongoDB,保存结果如图所示。
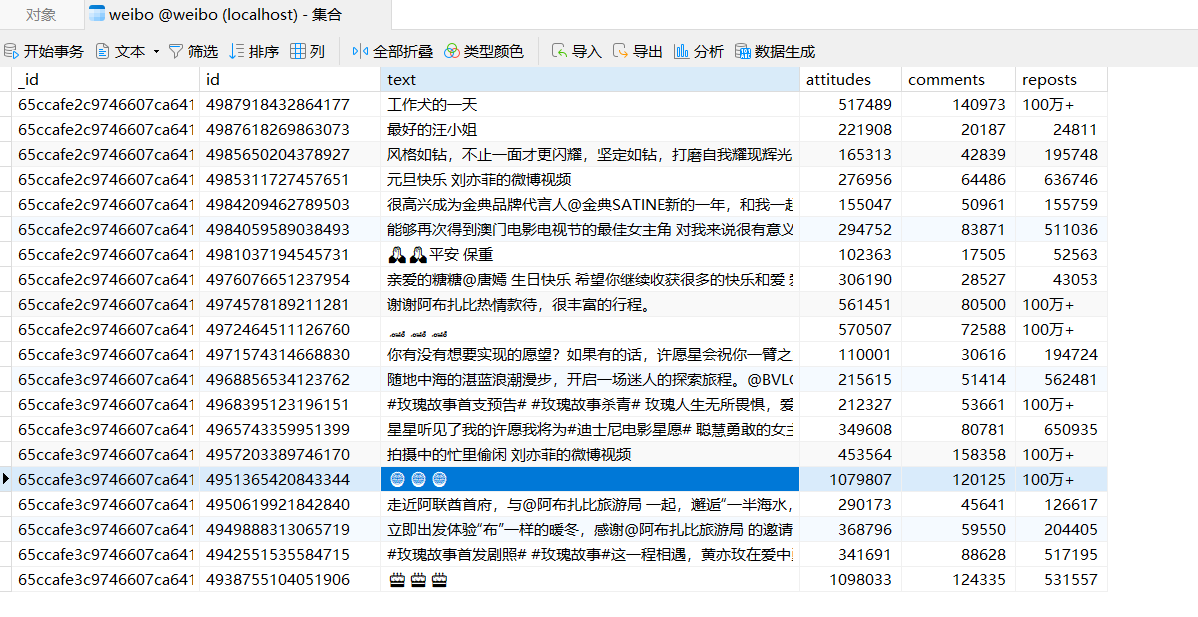
?
这样,我们就顺利通过分析 Ajax 并编写爬虫爬取下来微博列表。
本节的目的是为了演示 Ajax 的模拟请求过程,爬取的结果不是重点。该程序仍有很多可以完善的地方,如页码的动态计算、微博查看全文等,若感兴趣,可以尝试一下。
通过这个实例,我们主要学会了怎样去分析 Ajax 请求,怎样用程序来模拟抓取 Ajax 请求。了解了抓取原理之后,下一节的 Ajax 实战演练会更加得心应手。