go爬虫项目

go爬虫项目
爬虫步骤
- 明确目标(确定在哪个网站搜索)
- 爬(爬下内容)
- 取(筛选想要的内容)
- 处理数据(按照你的想法进行处理)
发送请求
构造客户端
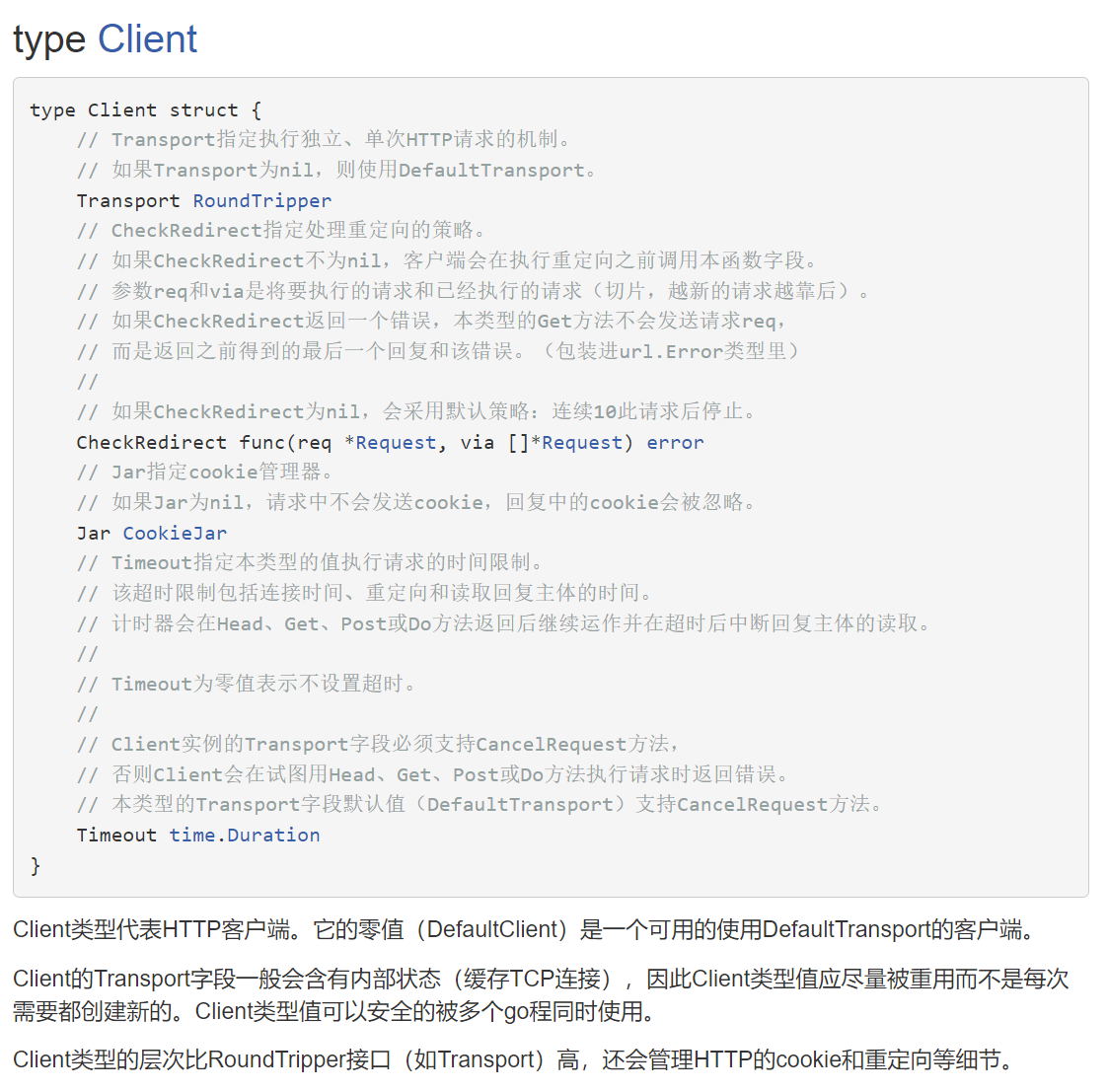
var client http.Client
//Client类型代表HTTP客户端。它的零值(DefaultClient)是一个可用的使用DefaultTransport的客户端。构造get请求
reqList, err := http.NewRequest("GET", URL, nil)
//返回值是Request包和一个错误类型的值,Request中包含了请求头,请求体(get请求没有请求体),host值等信息添加请求头,为了防止浏览器检测到爬虫访问,添加一些请求头来伪造成浏览器访问
req.Header.Set("Connection", "keep-alive")
req.Header.Set("Pragma", "no-cache")
req.Header.Set("Cache-Control", "no-cache")
req.Header.Set("Upgrade-Insecure-Requests", "1")
req.Header.Set("Content-Type", "application/x-www-form-urlencoded")
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36")
req.Header.Set("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9")
req.Header.Set("Accept-Language", "zh-CN,zh;q=0.9")发送请求
resp,err := client.Do(req) //client的Do方法,将接收一个request类型的参数,发送request请求,返回http回复,第一个参数接收,接收的参数自动为Response类型
if err != nil {
fmt.Println("请求失败",err)
}
defer resp.Body.Close() //程序在使用完回复后必须关闭回复的主体,defer关键字类似于其它语言的析构函数,释放对应内存,Close()函数关闭
解析网页
docDetail ,err := goquery.NewDocumentFromReader(resp.Body)
//NewDocumentFromReader函数将从response的body内返回一个文档,解析为html并返回给第一个参数,如果不能解析为html,则返回错误作为第二个值
//docDetail接收的是解析后的html文件
if err != nil {
fmt.Println("解析失败",err)
}
获取节点信息

github.com/PuerkitoBio/goquery包内内置了Find函数,”Find 获取当前匹配元素集中每个元素的后代,由选择器过滤。,它返回一个包含这些匹配元素的新选择对象。”
内置了Each函数,“每个迭代一个 Selection 对象,为每个匹配的元素执行一个函数。它返回当前的 Selection 对象。函数 f 为选择中的每个元素调用,该选择中元素的索引从 0 开始,*Selection 仅包含该元素”
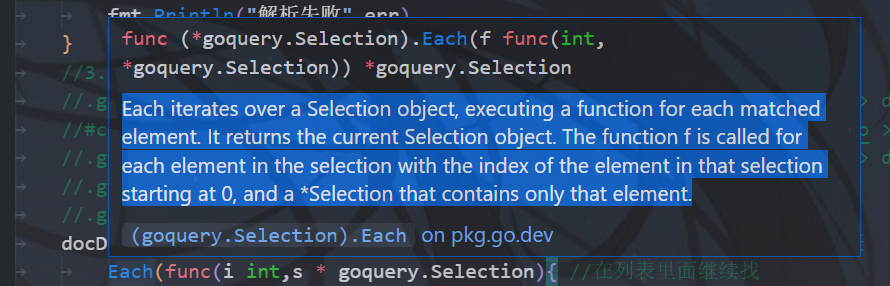
```go docDetail.Find(“#content > div > div.article > ol > li > div”). //列表,使用Document.Find创建初始选择,然后用类似jQuery的可链接语法和方法进行操作
Each(func(i int,s * goquery.Selection){ //在列表里面继续找,第一个参数代表的是索引
title := s.Find("div.info > div.hd > a > span:nth-child(1)").Text()
img := s.Find("div.pic > a > img") //img标签 -> src属性里面
imgTmp , ok := img.Attr("src")
info := s.Find("div.info > div.bd > p:nth-child(1)").Text()
score := s.Find("div.info > div.bd > div > span.rating_num").Text()
quote := s.Find("div.info > div.bd > p.quote > span").Text()
if ok {
fmt.Println("title",title)
fmt.Println("imgTmp",imgTmp)
fmt.Println("info",info)
fmt.Println("score",score)
fmt.Println("quote",quote)
}
}) ## 利用正则去区分不同内容
1. ```go
func infoSpite(info string) (director string,actor string,year string) {
//directory
directoryRe , _ := regexp.Compile(`导演:(.*)主演:`)
director = string(directoryRe.Find([]byte(info)))
//actor
actorRe , _ := regexp.Compile(`主演:(.*)`)
actor = string(actorRe.Find([]byte(info)))
//year
yearRe,_ := regexp.Compile(`(\d+)`)
year = string(yearRe.Find([]byte(info)))
return
}定义结构体去存储不同的信息
//结构体的定义
type MovieData struct {
Title string
Director string
Picture string
Actor string
Year string
Score string
Quote string
}
//给不同的变量传参
if ok {
director,actor,year := infoSpite(info)
data.Title=title
data.Director=director
data.Picture=imgTmp
data.Actor=actor
data.Year=year
data.Score=score
data.Quote=quote
fmt.Println("data%v\n",data) //打印一下检测是否正确存储
}修改参数
每一页的传参是通过get传参,给start变量传参
```go req,err := http.NewRequest(“GET”,”https://movie.douban.com/top250?start="+page,nil)
## 链接数据库
```go
//数据库初始化
func InitDB() {
//链接数据库
DB , err := sql.Open("mysql",USERNAME + ":" + PASSWORD + "@tcp(" + HOST + ")/" + DBNAME)
if err != nil {
panic(err.Error())
}
DB.SetConnMaxLifetime(10)
DB.SetMaxIdleConns(5)
if err := DB.Ping() ; err != nil {
fmt.Println("open database fail")
return
}
fmt.Println("connect success")
}连接数据库用来保存爬下来的数据
将爬下来的数据插入到数据库中,定义插入函数
//插入数据
func InsertData(moviedata MovieData) bool {
//新建事务
tx , err := DB.Begin()
if err != nil {
fmt.Println("begin err",err)
return false
}
stmt , err := tx.Prepare("INSERT INTO movie_data(Title,Director,Picture,Actor,Year,Score,Quote) VALUES(?,?,?,?,?,?,?)")
if err != nil {
fmt.Println("prepare fail err",err)
return false
}
_ , err =stmt.Exec(moviedata.Title,moviedata.Director,moviedata.Picture,moviedata.Actor,moviedata.Year,moviedata.Score,moviedata.Quote)
if err != nil {
fmt.Println("exec fail",err)
}
_ = tx.Commit()
return true
}综上,没有实现高并发的代码
package main
import (
"database/sql"
"fmt"
"net/http"
"regexp"
"strconv"
_ "github.com/go-sql-driver/mysql"
"github.com/PuerkitoBio/goquery"
)
//数据库配置
const (
USERNAME = "root"
PASSWORD = "20030729a"
HOST = "127.0.0.1"
PORT = "3306"
DBNAME = "movie"
)
var DB *sql.DB
func main() {
InitDB()
for i:=0 ; i < 10;i++{
fmt.Printf("正在爬取第%v页信息\n",i)
Spider(strconv.Itoa(i*25))
}
}
type MovieData struct {
Title string
Director string
Picture string
Actor string
Year string
Score string
Quote string
}
func Spider(page string) {
//1. 发送请求
var client http.Client
var data MovieData
req,err := http.NewRequest("GET","https://movie.douban.com/top250?start="+page,nil)
if err != nil {
fmt.Println("req.err",err)
}
//防止浏览器检爬虫访问,所以加一些请求头伪造成浏览器访问
req.Header.Set("Connection", "keep-alive")
req.Header.Set("Pragma", "no-cache")
req.Header.Set("Cache-Control", "no-cache")
req.Header.Set("Upgrade-Insecure-Requests", "1")
req.Header.Set("Content-Type", "application/x-www-form-urlencoded")
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36")
req.Header.Set("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9")
req.Header.Set("Accept-Language", "zh-CN,zh;q=0.9")
resp,err := client.Do(req)
if err != nil {
fmt.Println("请求失败",err)
}
defer resp.Body.Close()
//2. 解析网页
docDetail ,err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
fmt.Println("解析失败",err)
}
//3. 获取节点信息,copy css selector
//.grid_view > li:nth-child(1) > div:nth-child(1) > div:nth-child(2) > div:nth-child(1) > a:nth-child(1)
//#content > div > div.article > ol > li:nth-child(1) > div > div.info > div.hd > a > span:nth-child(1)
//.grid_view > li:nth-child(1) > div:nth-child(1) > div:nth-child(2) > div:nth-child(1) > a:nth-child(1)
//.grid_view > li:nth-child(3)
//.grid_view > li:nth-child(4)
docDetail.Find("#content > div > div.article > ol > li > div"). //列表
Each(func(i int,s * goquery.Selection){ //在列表里面继续找
title := s.Find("div.info > div.hd > a > span:nth-child(1)").Text()
img := s.Find("div.pic > a > img") //img标签 -》 src属性里面
imgTmp , ok := img.Attr("src")
info := s.Find("div.info > div.bd > p:nth-child(1)").Text()
score := s.Find("div.info > div.bd > div > span.rating_num").Text()
quote := s.Find("div.info > div.bd > p.quote > span").Text()
//4. 保存信息
if ok {
director,actor,year := infoSpite(info)
data.Title=title
data.Director=director
data.Picture=imgTmp
data.Actor=actor
data.Year=year
data.Score=score
data.Quote=quote
if InsertData(data) {
fmt.Println("插入成功")
} else {
fmt.Println("插入失败")
return
}
// fmt.Println("data%v\n",data)
}
})
return
}
func infoSpite(info string) (director string,actor string,year string) {
//directory
directoryRe , _ := regexp.Compile(`导演:(.*)主演:`)
director = string(directoryRe.Find([]byte(info)))
//actor
actorRe , _ := regexp.Compile(`主演:(.*)`)
actor = string(actorRe.Find([]byte(info)))
//year
yearRe,_ := regexp.Compile(`(\d+)`)
year = string(yearRe.Find([]byte(info)))
return
}
//数据库初始化
func InitDB() {
//链接数据库
DB , err := sql.Open("mysql","root:20030729a@tcp(localhost:3306)/movie")
if err != nil {
panic(err.Error())
}
DB.SetConnMaxLifetime(10)
DB.SetMaxIdleConns(5)
if err := DB.Ping() ; err != nil {
fmt.Println("open database fail")
return
}
fmt.Println("connect success")
}
//插入数据
func InsertData(moviedata MovieData) bool {
//新建事务
tx , err := DB.Begin()
if err != nil {
fmt.Println("begin err",err)
return false
}
stmt , err := tx.Prepare("INSERT INTO movie_data(Title,Director,Picture,Actor,Year,Score,Quote) VALUES(?,?,?,?,?,?,?)")
if err != nil {
fmt.Println("prepare fail err",err)
return false
}
_ , err =stmt.Exec(moviedata.Title,moviedata.Director,moviedata.Picture,moviedata.Actor,moviedata.Year,moviedata.Score,moviedata.Quote)
if err != nil {
fmt.Println("exec fail",err)
}
_ = tx.Commit()
return true
}实现结果

出现问题及解决方法
too many connection
tx, err := DB.Begin()
if err != nil {
fmt.Println("tx fail",err)
return false
}当启动数据库时报错:too many connection ,1040错误
默认情况下,同时处理100个链接
但是,由于爬虫爬取速度太高,无法同时处理多个链接,会报错1040
此时可以调高mysql的最大链接数量
set global max_connections = 合适的链接数量;爬取内容超出了数据类型所能容纳的

- 当爬取内容的长度超出了数据类型所能容纳的,可以调高varchar的最高容纳长度
高并发爬虫
package main
import (
"database/sql"
"fmt"
"github.com/PuerkitoBio/goquery"
_ "github.com/jinzhu/gorm/dialects/mysql"
"log"
"net/http"
"regexp"
"strconv"
"strings"
"time"
)
const (
USERNAME = "root"
PASSWORD = "root"
HOST = "127.0.0.1"
PORT = "3306"
DBNAME = "douban_movie"
)
var DB *sql.DB
type MovieData struct {
Title string `json:"title"`
Director string `json:"director"`
Picture string `json:"picture"`
Actor string `json:"actor"`
Year string `json:"year"`
Score string `json:"score"`
Quote string `json:"quote"`
}
func main() {
InitDB()
start := time.Now()
//for i := 0; i < 10; i++ {
// Spider(strconv.Itoa(i*25))
//}
ch := make(chan bool)
for i := 0; i < 10; i++ {
go Spider(strconv.Itoa(i*25), ch)
}
for i := 0; i < 10; i++ {
<-ch
}
elapsed := time.Since(start)
fmt.Printf("ChannelStart Time %s \n",&elapsed)
}
func Spider(page string,ch chan bool) {
client := &http.Client{}
req, err := http.NewRequest("GET", "https://movie.douban.com/top250?start="+page, nil)
if err != nil {
log.Fatal(err)
}
req.Header.Set("Connection", "keep-alive")
req.Header.Set("Cache-Control", "max-age=0")
req.Header.Set("sec-ch-ua-mobile", "?0")
req.Header.Set("Upgrade-Insecure-Requests", "1")
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36")
req.Header.Set("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9")
req.Header.Set("Sec-Fetch-Site", "same-origin")
req.Header.Set("Sec-Fetch-Mode", "navigate")
req.Header.Set("Sec-Fetch-User", "?1")
req.Header.Set("Sec-Fetch-Dest", "document")
req.Header.Set("Referer", "https://movie.douban.com/chart")
req.Header.Set("Accept-Language", "zh-CN,zh;q=0.9")
resp, err := client.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
docDetail, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Fatal(err)
}
docDetail.Find("#content > div > div.article > ol > li > div").
Each(func(i int, s *goquery.Selection) {
var movieData MovieData
//#content > div > div.article > ol > li:nth-child(16) > div > div.info > div.hd > a > span:nth-child(1)
title := s.Find("div.info > div.hd > a > span:nth-child(1)").Text()
img := s.Find("div.pic > a > img")
imgTmp, ok := img.Attr("src")
info := strings.Trim(s.Find("div.info > div.bd > p:nth-child(1)").Text(), " ")
director, actor, year := InfoSpite(info)
score := strings.Trim(s.Find("div.info > div.bd > div > span.rating_num").Text(), " ")
score = strings.Trim(score, "\n")
quote := strings.Trim(s.Find("div.info > div.bd > p.quote > span").Text(), " ")
if ok {
movieData.Title = title
movieData.Director = director
movieData.Picture = imgTmp
movieData.Actor = actor
movieData.Year = year
movieData.Score = score
movieData.Quote = quote
fmt.Println(movieData)
InsertSql(movieData)
}
})
if ch != nil{
ch <- true
}
}
func InfoSpite(info string) (director ,actor , year string) {
directorRe, _ := regexp.Compile(`导演:(.*)主演:`)
if len(director) < 8 {
director = string(directorRe.Find([]byte(info)))
} else {
director = string(directorRe.Find([]byte(info)))[8:]
}
director = strings.Trim(director, "主演:")
actorRe, _ := regexp.Compile(`主演:(.*)`)
if len(actor) < 8 {
actor = string(actorRe.Find([]byte(info)))
} else {
actor = string(actorRe.Find([]byte(info)))[8:]
}
yearRe, _ := regexp.Compile(`(\d+)`)
year = string(yearRe.Find([]byte(info)))
return
}
func InitDB(){
DB, _ = sql.Open("mysql", "root:20030729a@tcp(localhost:3306)/movie")
DB.SetConnMaxLifetime(10)
DB.SetMaxIdleConns(5)
if err := DB.Ping(); err != nil{
fmt.Println("opon database fail")
return
}
fmt.Println("connnect success")
}
func InsertSql(movieData MovieData) bool {
tx, err := DB.Begin()
if err != nil {
fmt.Println("tx fail",err)
return false
}
stmt, err := tx.Prepare("INSERT INTO movie_data (`Title`,`Director`,`Actor`,`Year`,`Score`,`Quote`) VALUES (?, ?, ?,?,?,?)")
if err != nil {
fmt.Println("Prepare fail", err)
return false
}
_, err = stmt.Exec(movieData.Title, movieData.Director, movieData.Actor, movieData.Year, movieData.Score, movieData.Quote)
if err != nil {
fmt.Println("Exec fail", err)
return false
}
_ = tx.Commit()
return true
}
高并发爬虫爬取同等内容需要1s左右
package main
import (
"database/sql"
"fmt"
"github.com/PuerkitoBio/goquery"
_ "github.com/jinzhu/gorm/dialects/mysql"
"log"
"net/http"
"regexp"
"strconv"
"strings"
"time"
)
const (
USERNAME = "root"
PASSWORD = "root"
HOST = "127.0.0.1"
PORT = "3306"
DBNAME = "douban_movie"
)
var DB *sql.DB
type MovieData struct {
Title string `json:"title"`
Director string `json:"director"`
Picture string `json:"picture"`
Actor string `json:"actor"`
Year string `json:"year"`
Score string `json:"score"`
Quote string `json:"quote"`
}
func main() {
InitDB()
start := time.Now()
for i := 0; i < 10; i++ {
Spider(strconv.Itoa(i*25))
}
// ch := make(chan bool)
// for i := 0; i < 10; i++ {
// Spider(strconv.Itoa(i*25), ch)
// }
// for i := 0; i < 10; i++ {
// <-ch
// }
elapsed := time.Since(start)
fmt.Printf("ChannelStart Time %s \n",&elapsed)
}
func Spider(page string) {
client := &http.Client{}
req, err := http.NewRequest("GET", "https://movie.douban.com/top250?start="+page, nil)
if err != nil {
log.Fatal(err)
}
req.Header.Set("Connection", "keep-alive")
req.Header.Set("Cache-Control", "max-age=0")
req.Header.Set("sec-ch-ua-mobile", "?0")
req.Header.Set("Upgrade-Insecure-Requests", "1")
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36")
req.Header.Set("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9")
req.Header.Set("Sec-Fetch-Site", "same-origin")
req.Header.Set("Sec-Fetch-Mode", "navigate")
req.Header.Set("Sec-Fetch-User", "?1")
req.Header.Set("Sec-Fetch-Dest", "document")
req.Header.Set("Referer", "https://movie.douban.com/chart")
req.Header.Set("Accept-Language", "zh-CN,zh;q=0.9")
resp, err := client.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
docDetail, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Fatal(err)
}
docDetail.Find("#content > div > div.article > ol > li > div").
Each(func(i int, s *goquery.Selection) {
var movieData MovieData
//#content > div > div.article > ol > li:nth-child(16) > div > div.info > div.hd > a > span:nth-child(1)
title := s.Find("div.info > div.hd > a > span:nth-child(1)").Text()
img := s.Find("div.pic > a > img")
imgTmp, ok := img.Attr("src")
info := strings.Trim(s.Find("div.info > div.bd > p:nth-child(1)").Text(), " ")
director, actor, year := InfoSpite(info)
score := strings.Trim(s.Find("div.info > div.bd > div > span.rating_num").Text(), " ")
score = strings.Trim(score, "\n")
quote := strings.Trim(s.Find("div.info > div.bd > p.quote > span").Text(), " ")
if ok {
movieData.Title = title
movieData.Director = director
movieData.Picture = imgTmp
movieData.Actor = actor
movieData.Year = year
movieData.Score = score
movieData.Quote = quote
fmt.Println(movieData)
InsertSql(movieData)
}
})
// if ch != nil{
// ch <- true
// }
}
func InfoSpite(info string) (director ,actor , year string) {
directorRe, _ := regexp.Compile(`导演:(.*)主演:`)
if len(director) < 8 {
director = string(directorRe.Find([]byte(info)))
} else {
director = string(directorRe.Find([]byte(info)))[8:]
}
director = strings.Trim(director, "主演:")
actorRe, _ := regexp.Compile(`主演:(.*)`)
if len(actor) < 8 {
actor = string(actorRe.Find([]byte(info)))
} else {
actor = string(actorRe.Find([]byte(info)))[8:]
}
yearRe, _ := regexp.Compile(`(\d+)`)
year = string(yearRe.Find([]byte(info)))
return
}
func InitDB(){
DB, _ = sql.Open("mysql", "root:20030729a@tcp(localhost:3306)/movie")
DB.SetConnMaxLifetime(10)
DB.SetMaxIdleConns(5)
if err := DB.Ping(); err != nil{
fmt.Println("opon database fail")
return
}
fmt.Println("connnect success")
}
func InsertSql(movieData MovieData) bool {
tx, err := DB.Begin()
if err != nil {
fmt.Println("tx fail",err)
return false
}
stmt, err := tx.Prepare("INSERT INTO movie_data (`Title`,`Director`,`Actor`,`Year`,`Score`,`Quote`) VALUES (?, ?, ?,?,?,?)")
if err != nil {
fmt.Println("Prepare fail", err)
return false
}
_, err = stmt.Exec(movieData.Title, movieData.Director, movieData.Actor, movieData.Year, movieData.Score, movieData.Quote)
if err != nil {
fmt.Println("Exec fail", err)
return false
}
_ = tx.Commit()
return true
}
而没有实现并发的爬虫爬取相同内容的时间达到了3s,比实现了并发的爬虫时间延长了三倍左右
数据分析阶段
- 该项目主要分析不同导演作品的数量,不同主演作品的数量和不同导演作品的得分
数据筛选
select count(*),Director from movie.movie_data group by Director;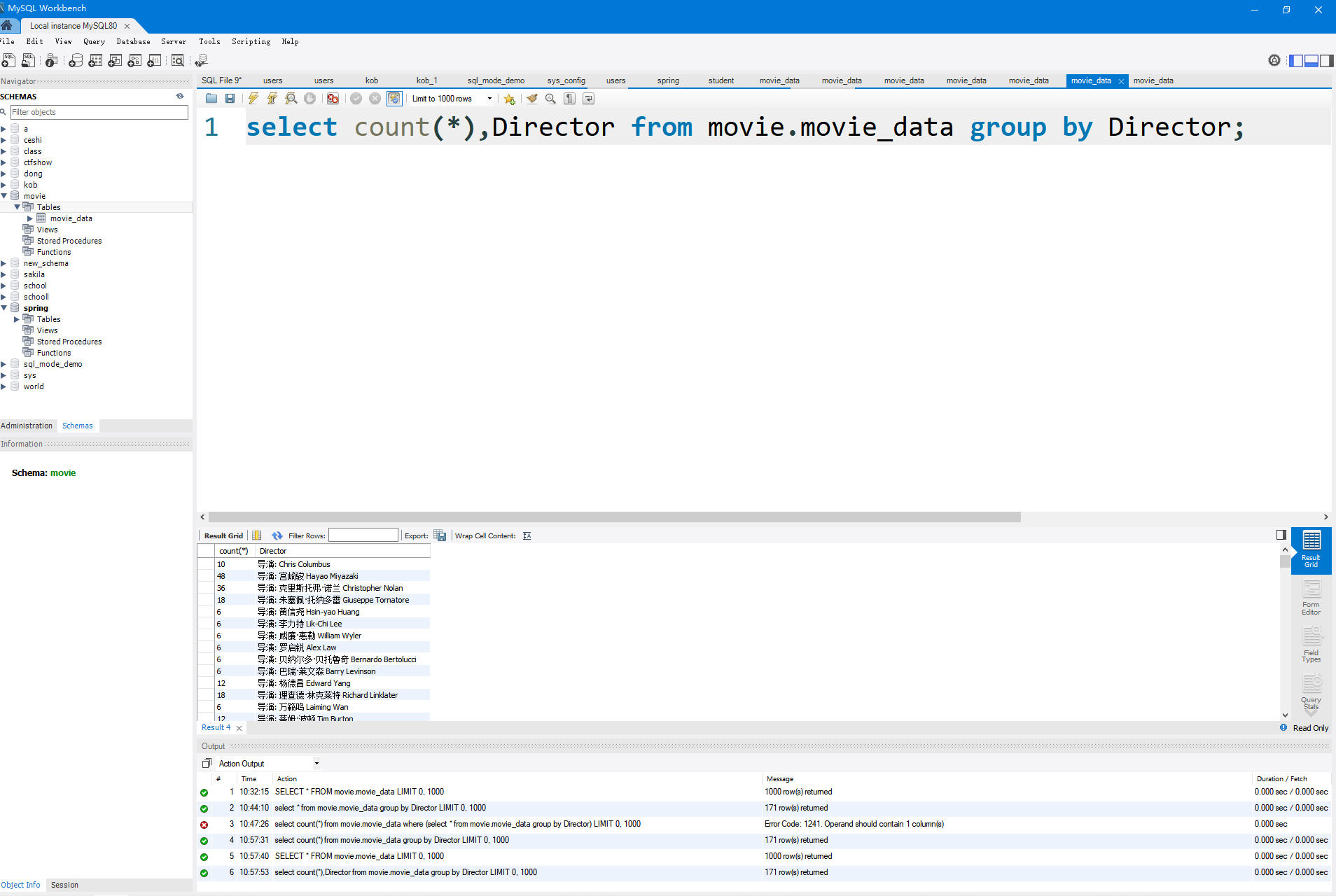

select count(*),Actor from movie.movie_data group by Director;python实现mysql数据统计及可视化
链接数据库
db = pymysql.connect(host='localhost', port=3306, user='root',password='20030729a', database='movie')
cursor = db.cursor()
'''
链接数据库 pymysql.connect的参数
connection = pymysql.connect(host='localhost',
user='user',
password='passwd',
database='db',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
'''数据处理阶段
sql = "select count(*) cnt,Director from movie.movie_data group by Director order by cnt desc;"
cursor.execute(sql)
res1 = cursor.fetchall()
name = list()
cnt = list()
count = list()
Score = list()
i = 0
for row in res1:
i += 1
count.append(i)
name.append(row[1])
cnt.append(row[0])
Score.append(row[2])画图像阶段
# 画图像阶段
plt.rcParams['font.family'] = 'SimHei'
# 建立图标
fig = plt.figure(num=1,figsize=(100,100),dpi=45)
# 设置坐标轴阶段
# 设置坐标轴的范围
plt.xlim((0,100))
plt.ylim((0,70))
# 隐藏无用轴
ax = plt.gca()
# 将上边的坐标轴颜色设置为空,不显示
ax.spines['top'].set_color('none')
# 将x轴设置为底部bottom,将y轴设置为顶部top
ax.xaxis.set_ticks_position('bottom')
# ax.xaxis.set_ticks_position('left')
# 将x轴和y轴(底轴和左轴的位置设置为坐标原点)
ax.spines['bottom'].set_position(('data',0))
ax.spines['left'].set_position(('data',0))
# 设置坐标轴的名字
plt.xlabel('Director',fontsize=30)
plt.ylabel('Number',fontsize=30)
x = MultipleLocator(10) # x轴每10一个刻度
y = MultipleLocator(15) # y轴每15一个刻度
new_ticks = np.linspace(0,100,100)
plt.xticks(count,name,rotation=90)
l1 = ax.plot(name,cnt,color='blue',linewidth=10.0,linestyle="-")
ax2 = ax.twinx()
# ax2.xaxis.set_ticks_position('bottom')
# ax2.xaxis.set_ticks_position('right')
plt.ylim(15)
l2 = ax.plot(name,Score,color='red',linewidth=10.0,linestyle='--')
ax2.set_ylabel('Score',fontsize=30)
ax2.spines['top'].set_color('none')
ax.legend(['Number','Score'],title='图例',)
plt.show()完整实现代码
分析Director的作品数量和整体分数之间的关系
import pymysql
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.pyplot import MultipleLocator
# 从数据库中获取数据阶段
db = pymysql.connect(host='localhost', port=3306, user='root',password='20030729a', database='movie')
cursor = db.cursor()
sql = "select count(*) cnt,Director,Score from movie.movie_data group by Director order by Score desc;"
cursor.execute(sql)
res1 = cursor.fetchall()
name = list()
cnt = list()
count = list()
Score = list()
i = 0
for row in res1:
i += 1
count.append(i)
name.append(row[1])
cnt.append(row[0])
Score.append(row[2])
# 画图像阶段
plt.rcParams['font.family'] = 'SimHei'
# 建立图标
fig = plt.figure(num=1,figsize=(100,100),dpi=45)
# 设置坐标轴阶段
# 设置坐标轴的范围
plt.xlim((0,100))
plt.ylim((0,70))
# 隐藏无用轴
ax = plt.gca()
# 将上边的坐标轴颜色设置为空,不显示
ax.spines['top'].set_color('none')
# 将x轴设置为底部bottom,将y轴设置为顶部top
ax.xaxis.set_ticks_position('bottom')
# ax.xaxis.set_ticks_position('left')
# 将x轴和y轴(底轴和左轴的位置设置为坐标原点)
ax.spines['bottom'].set_position(('data',0))
ax.spines['left'].set_position(('data',0))
# 设置坐标轴的名字
plt.xlabel('Director',fontsize=30)
plt.ylabel('Number',fontsize=30)
x = MultipleLocator(10) # x轴每10一个刻度
y = MultipleLocator(15) # y轴每15一个刻度
new_ticks = np.linspace(0,100,100)
plt.xticks(count,name,rotation=90)
l1 = ax.plot(name,cnt,color='blue',linewidth=10.0,linestyle="-")
ax2 = ax.twinx()
# ax2.xaxis.set_ticks_position('bottom')
# ax2.xaxis.set_ticks_position('right')
plt.ylim(15)
l2 = ax.plot(name,Score,color='red',linewidth=10.0,linestyle='--')
ax2.set_ylabel('Score',fontsize=30)
ax2.spines['top'].set_color('none')
ax.legend(['Number','Score'],title='图例',)
plt.show()- 实现效果

分析Actor作品数量和平均分数之间的关系
实现代码
import pymysql
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.pyplot import MultipleLocator
# 从数据库中获取数据阶段
db = pymysql.connect(host='localhost', port=3306, user='root',
password='20030729a', database='movie')
cursor = db.cursor()
sql = "select count(*) cnt,Actor,avg(Score) from movie.movie_data group by Actor order by avg(Score) desc;"
cursor.execute(sql)
res1 = cursor.fetchall()
name = list()
cnt = list()
count = list()
Score = list()
i = 0
for row in res1:
i += 1
count.append(i)
name.append(row[1])
cnt.append(row[0])
Score.append(row[2])
# 画图像阶段
plt.rcParams['font.family'] = 'SimHei'
# 建立图标
fig = plt.figure(num=1, figsize=(100, 100), dpi=45)
# 设置坐标轴阶段
# 设置坐标轴的范围
plt.xlim((0, 100))
plt.ylim((0, 70))
# 隐藏无用轴
ax = plt.gca()
# 将上边的坐标轴颜色设置为空,不显示
ax.spines['top'].set_color('none')
# 将x轴设置为底部bottom,将y轴设置为顶部top
ax.xaxis.set_ticks_position('bottom')
# ax.xaxis.set_ticks_position('left')
# 将x轴和y轴(底轴和左轴的位置设置为坐标原点)
ax.spines['bottom'].set_position(('data', 0))
ax.spines['left'].set_position(('data', 0))
# 设置坐标轴的名字
plt.xlabel('Actor', fontsize=30)
plt.ylabel('Number', fontsize=30)
x = MultipleLocator(10) # x轴每10一个刻度
y = MultipleLocator(15) # y轴每15一个刻度
new_ticks = np.linspace(0, 100, 100)
plt.xticks(count, name, rotation=90)
l1 = ax.plot(name, cnt, color='blue', linewidth=10.0, linestyle="-")
ax2 = ax.twinx()
# ax2.xaxis.set_ticks_position('bottom')
# ax2.xaxis.set_ticks_position('right')
plt.ylim(5,10)
l2 = ax.plot(name, Score, color='red', linewidth=10.0, linestyle='--')
ax2.set_ylabel('Score', fontsize=30)
ax2.spines['top'].set_color('none')
ax.legend(['Number', 'Score'], title='图例',)
plt.show()- 分析年份和评分之间的关系的完整实现代码
import pymysql
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.pyplot import MultipleLocator
# 从数据库中获取数据阶段
db = pymysql.connect(host='localhost', port=3306, user='root',
password='20030729a', database='movie')
cursor = db.cursor()
sql = "select count(*) cnt,Year,avg(Score) from movie.movie_data group by Year order by Year;"
cursor.execute(sql)
res1 = cursor.fetchall()
name = list()
cnt = list()
count = list()
xu = list()
Score = list()
i = 0
for row in res1:
i += 1
count.append(i)
name.append(row[1])
cnt.append(row[0])
Score.append(row[2])
# 画图像阶段
plt.rcParams['font.family'] = 'SimHei'
# 建立图标
fig = plt.figure(num=1, figsize=(100, 100), dpi=45)
# 设置坐标轴阶段
# 设置坐标轴的范围
plt.xlim((0, 100))
plt.ylim((8, 12))
# 隐藏无用轴
ax = plt.gca()
# 将上边的坐标轴颜色设置为空,不显示
ax.spines['top'].set_color('none')
# 将x轴设置为底部bottom,将y轴设置为顶部top
ax.xaxis.set_ticks_position('bottom')
# ax.xaxis.set_ticks_position('left')
# 将x轴和y轴(底轴和左轴的位置设置为坐标原点)
ax.spines['bottom'].set_position(('data', 8))
ax.spines['left'].set_position(('data', 0))
# 设置坐标轴的名字
plt.xlabel('Year', fontsize=30)
plt.ylabel('Score', fontsize=30)
x = MultipleLocator(10) # x轴每10一个刻度
y = MultipleLocator(1) # y轴每15一个刻度
new_ticks = np.linspace(0, 100, 100)
plt.xticks(count, name, rotation=90)
l1 = ax.plot(name,Score, color='blue', linewidth=10.0, linestyle="-")
x = np.linspace(0,60,256,endpoint=True)
y = x*0.0112*(-1) + 9.3
plt.plot(x,y,color='red',linewidth='10',linestyle='--')
plt.show()根据上述图表进行数据分析

本文参与?腾讯云自媒体分享计划,分享自作者个人站点/博客。
原始发表:2022-11-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读