【云原生进阶之PaaS中间件】第四章RabbitMQ-4.3-如何保证消息的可靠性投递与消费
【云原生进阶之PaaS中间件】第四章RabbitMQ-4.3-如何保证消息的可靠性投递与消费

1 引言
根据RabbitMQ的工作模式,一条消息从生产者发出,到消费者消费,需要经历以下4个步骤:

- 生产者将消息发送给RabbitMQ的Exchange交换机;
- Exchange交换机根据Routing key将消息路由到指定的Queue队列;
- 消息在Queue中暂存,等待消费者消费消息;
- 消费者从Queue中取出消息消费。
通过这种工作模式,很好地做到了两个系统之间的解耦,并且整个过程是一个异步的过程,producer发送消息后就可以继续处理自己业务逻辑,不需要同步等待consumer的消费结果。
但任何一项技术的引入,除了带来它自身的优点之外,必然也会带来其他的一些缺点。MQ消息中间件虽然可以做到系统之间的解耦以及异步通信,但可能会存在消息丢失的风险。
2 消息可靠性投递的实现
2.1 该工作模式存在的问题——消息可能丢失
什么是消息丢失呢?简单来说,就是producer发送了一条消息出去,但由于某种原因(比如RabbitMQ宕机了),导致consumer没有消费到这条消息,最终导致producer与consumer两个系统的数据与期望结果不一致。
那消息是如何丢失的呢?既然在RabbitMQ的工作模式中,一条消息从producer到达consumer要经过4个步骤,那么在这4步中,任何一步都可能会把消息丢掉:
(1)生产者将消息发送给Exchange交换机:假如producer向Exchange发送了一条消息,由于是异步调用,所以producer不关心Exchange是否收到了这条消息,就继续向下处理自己的业务逻辑。如果在Exchange收到消息之前,RabbitMQ宕机了,那这条消息就丢了。
(2)Exchange交换机接收到消息后,会根据producer发送过来的Routing key将消息路由到匹配的Queue队列中。一般情况下,这一步不会出现什么问题,因为这一步是在RabbitMQ内部实现的,并且Exchange与Queue之间的Routing key都会在开发之前约定好,所以,只要保证producer发送消息时使用的Routing key是真实存在的即可正确地路由到指定的Queue队列。但万一小明在复制代码的时候,手一抖,导致发送消息时的Routing key多了个数字,此时,消息发出去后,Exchange虽然能收到消息,但由于匹配不到Routing key,所以无法将消息路由到Queue队列,那这条消息也算是变相消失了。

(3)消息到达Queue中暂存,等待consumer消费:如果消息成功被路由到了Queue中,此时这条消息会被暂存在RabbitMQ的内存中,等到consumer消费,假如在consumer消费这条消息之前,RabbitMQ宕机了,那么这条消息也会丢失。
(4)consumer从Queue中取走消息消费:如果前面一切顺利,并且消息也成功被consumer从Queue中取走消费,但consumer最后消费发生异常失败了。由于默认情况下,当一条消息被consumer取走后,RabbitMQ就会将这条消息从Queue中直接删除,所以,即使consumer消费失败了,这条消息也会消失,这样也会导致producer与consumer两个系统的数据不一致。
2.2 解决方法——问题分解,逐个击破
分析完了消息可能发生丢失的几个步骤,接下来就可以针对这几个步骤进行逐个解决,来保证消息不会丢失,也就是消息的可靠性投递与消费。
2.2.1 保证producer发送消息到RabbitMQ broker的可靠性
通过上面的分析,我们知道,producer发送消息到broker的过程中,丢失消息的原因是producer发送完消息之后,就主观认为消息发送成功了,即使RabbitMQ发生故障导致没有接收到消息,producer也是无法知道的。所以,要保证producer发出去的消息100%被broker接收成功,我们需要让producer发送消息后知道一个结果,然后根据这个结果再做相应的处理。
RabbitMQ提供了两种方式来达到这一目的:一种是Transaction(事务)模式,一种是Confirm(确认)模式。
(1)Transaction模式
Transaction模式类似于我们操作数据库的操作,首先开启一个事务,然后执行sql,最后根据sql执行情况进行commit或者rollback。
在RabbitMQ中实现Transaction模式时,首先要用Channel对象的txSelect()方法将信道设置成事务模式,broker收到该命令后,会向producer返回一个select-ok的命令,表示信道的事务模式设置成功;然后producer就可以向broker发送消息了。在消息发送完成后,producer要调用Channel对象的commit()方法提交事务。整个流程可以用下图表示:

在Transaction模式中,producer只有收到了broker返回的Commit-Ok命令后才能提交成功,若在commit执行之前,RabbitMQ发生故障抛出异常,producer可以将其捕获,然后通过Channel对象的txRollback()方法回滚事务,同时可以重发该消息。

Transaction模式虽然可以保证消息从producer到broker的可靠性投递,但它的缺点也很明显,它是阻塞的,只有当一条消息被成功发送到RabbitMQ之后,才能继续发送下一条消息,这种模式会大幅度降低RabbitMQ的性能,不推荐使用。
(2)Confirm模式(推荐)
针对Transaction模式存在的浪费RabbitMQ性能的问题,RabbitMQ推出了Confirm模式。Confirm模式是一个异步确认的模式,producer发送一条消息后,在等待确认的过程中可以继续发送下一条消息。
要使用Confirm模式,首先要通过Channel对象的confirmSelec()方法将当前Channel设置为Confirm模式,然后,通过该Channel发布消息时,每条消息都会被分配一个唯一的ID(从1开始计数),当这条消息被路由到匹配的Queue队列之后,RabbitMQ就会发送一个确认(ack)给producer(如果是持久化的消息,那么这个确认(ack)会在RabbitMQ将这条消息写入磁盘之后发出),这个确认消息中包含了消息的唯一ID,这样producer就可以知道消息已经成功到达Queue队列了。
当RabbitMQ发生故障导致消息丢失,也会发送一个不确认(nack)的消息给producer,nack消息中也会包含producer发布的消息唯一ID,producer接收到nack的消息之后,可以针对发布失败的消息做相应处理,比如重新发布等。

了解了原理后,接下来看下代码层面实现Confirm模式的三种方式:
(1)单条确认方式
单条确认模式中,每发送一条消息后,通过调用Channel对象的waitForConfirms()方法等待RabbitMQ端确认,主要代码如下:

这种方式实际上是一种同步等待的方式,只有当一条消息被确认之后,才能发送下一条消息,所以,实际使用中不推荐这种方式。
(2)批量确认方式
批量确认方式与单条确认方式使用方法类似,只是将确认的步骤放到了最后,可以一次性发送多条消息,最后统一确认,主要代码如下:

waitForConfirmsOrDie()方法会等最后一条消息被确认或者得到nack时才会结束,这种方式虽然可以做到多条消息并行发送,不用互相等待,但最后确认的时候还是通过同步等待的方式完成的,所以也会造成程序的阻塞,并且当有任意一条消息未确认就会抛出异常,实际使用中不推荐这种方式。
(3)异步确认方式(推荐)
异步确认方式的实现原理是在将Channel设置为Confirm模式后,给该Channel添加一个监听ConfirmListener,ConfirmListener中定义了两个方法,一个是handleAck,用来处理RabbitMQ的ack确认消息,一个是handleNack,用来处理RabbitMQ的nack未确认消息,这两个方法会在RabbitMQ完成消息确认和发生故障导致消息丢失时回调,producer接收到回调时可以执行对应的回调处理。主要代码如下:

异步确认的方式效率很高,多条消息既可以同时发送,不需要互相等待,又不用同步等待确认结果,只需异步监听确认结果即可,所以,实际使用中推荐使用这种方式。
2.2.2 保证Exchange路由消息到Queue的可靠性
上面分析了,当producer发送消息时,由于小明手抖,导致消息的Routing key是一个不存在的key,从而变相丢失的情况,要如何提前规避掉呢?有两种方式:ReturnListener和使用备胎Exchange交换机。
(1)ReturnListener
ReturnListener是一个监听器,作用于Channel信道上,当producer发送一条消息给RabbitMQ后,如果由于Routing key不存在导致消息不可成功到达Queue队列,RabbitMQ就会将这条消息发送回producer的ReturnListener,在ReturnListener的handleReturn方法中,producer可以针对退回的消息做处理。
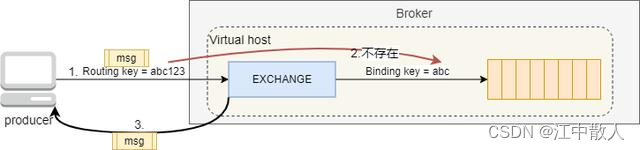
要使用ReturnListener,在发送消息时要注意,在basicPublish的方法中有一个mandatory的入参,只有将该参数值设置为true才可以正常使用ReturnListener,否则,当Routing key不存在时,消息会被自动丢弃。核心代码如下:
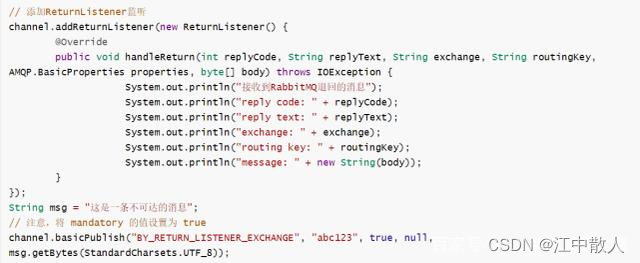
producer运行上述代码之后,就会打印出ReturnListener中的信息,此时,producer可以针对这条消息做业务处理,比如发送提醒信息给相关人员处理,或者更新状态等。但要注意,这里最好不要重发ReturnListener中的消息,因为导致消息被回退的原因就是消息不可达,如果在ReturnListener中重发这条消息的话,那么就有可能进入一个死循环,重发->退回->重发->退回......
(2)备胎Exchange交换机
除了使用ReturnListener,我们还可以使用备胎交换机的方式来解决Routing key不存在导致消息不可达的问题。所谓备胎交换机,是指当producer发送消息的Routing key不存在导致消息不可达时,自动将这条消息转发到另一个提前指定好的交换机上,这台交换机就是备胎交换机。备胎交换机也有自己绑定的Queue队列,当备胎交换机接到消息后,会将消息路由到自己匹配的Queue队列中,然后由订阅了这些Queue队列的消费者消费。
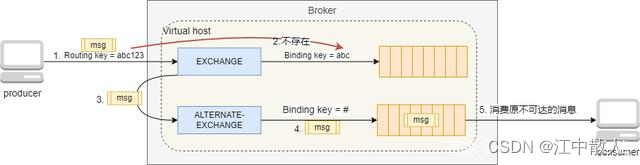
在开发时,如果要使用备胎交换机,也要在发送消息时,将mandatory参数值设置为true,否则,消息就会由于不可达而被RabbitMQ自动丢弃。核心代码如下:
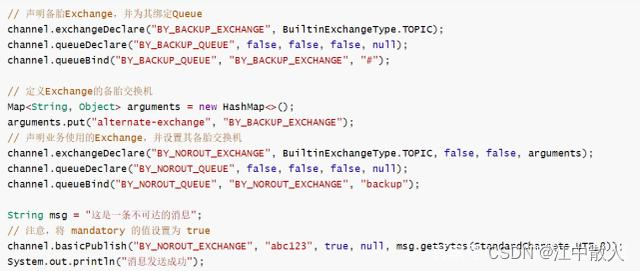
然后我们运行该程序,然后可以在RabbitMQ控制台看到,消息被成功路由到了备胎交换机绑定的Queue队列:
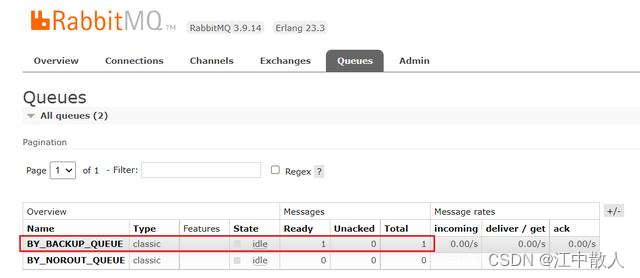
然后我们开启一个消费者消费该Queue,也可以正常消费到这条原本不可达的消息:
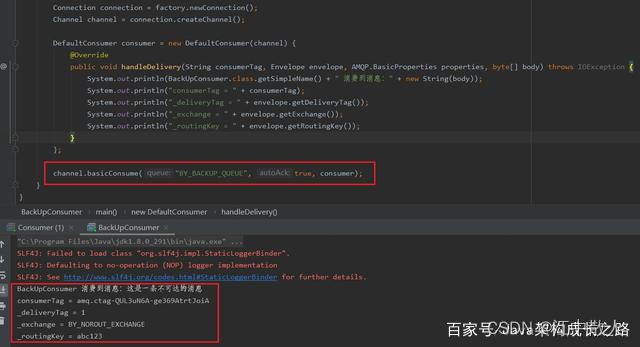
2.2.3 保证Queue消息存储的可靠性
消息到达Queue队列之后,在消费者消费之前,RabbitMQ宕机也会导致消息的丢失,所以,为了解决这种问题,我们需要将消息设置成持久化的消息。持久化消息会写入RabbitMQ的磁盘中,RabbitMQ宕机重启后,会恢复磁盘中的持久化消息。
但消息是存储于Queue队列中的,所以,只把消息持久化也不行,也要把Queue也设置成持久化的队列,这样,RabbitMQ宕机重启之后,Queue才不会丢失,否则,即使消息是持久化的,但Queue不是持久化的,那么RabbitMQ重启之后,Queue都不存在了,那么消息也就无处存放,也就相当于没了。
通过代码设置消息持久化和队列持久化很简单,首先看队列持久化:

Channel对象在声明队列的时候,第二个参数 durable 就代表该队列是否持久化队列,设置为 true 表示当前队列是持久化队列。
然后看下消息持久化:

Channel对象在发送消息时,有一个BasicProperties类型的参数,该参数中可以设置一些消息的属性,其中就包括是否持久化的 deliveryMode 属性,2表示持久化消息。
将队列和消息进行持久化可以保证大部分场景下RabbitMQ宕机重启后消息不丢失,但并不能100%保证,因为RabbitMQ接收到持久化消息之后,并不会立刻将消息存入磁盘,而是有一个缓冲buffer,只有当buffer写满了或者每25ms一次才会将数据写入磁盘中,所以,在这之前,消息还是会存在丢失的可能,想要更大程度地保证这种情况下消息不丢失,可以搭建RabbitMQ镜像集群,这个我在以后章节会讲。
上面介绍了队列和消息的持久化,其实Exchange交换机也可以持久化,不过交换机是否持久化对消息的可靠性并没有什么影响,只是非持久化的交换机在RabbitMQ重启之后也会消失,那么producer向该交换机发送消息时就可能会有问题,所以,一般情况下,建议也将交换机持久化:

Channel对象在声明交换机时,有一个durable的参数,该参数设置为true即表示该交换机为持久化交换机。
2.2.4 保证consumer消费消息的可靠性
consumer消费消息时,有一个ack机制,即向RabbitMQ发送一条ack指令,表示消息已经被成功消费,RabbitMQ收到ack指令后,会将消息从本地删除。默认情况下,consumer消费消息是自动ack机制,即消息只要到达consumer,就会向RabbitMQ发送ack,不管consumer是否消费成功。所以,为了保证producer与consumer数据的一致性,我们要使用手动ack的方式确认消息消费成功,即在消息消费完成后,通过代码显式调用发送ack。
首先,我们一起看下实现手动ack的核心代码:

consumer向RabbitMQ发送ack时有三种形式:
(1)reject:表示拒收消息。发送拒收消息时,需要设置一个 requeue 的参数,表示拒收之后,这条消息是否重新回到RabbitMQ的Queue之后,设置为true表示是,false表示否(消息会被删除)。若 requeue 设置为 true,那么消息回归原Queue之后,会被消费者重新消费,这样就会出现死循环,消费->拒绝->回Queue->消费->拒绝->回Queue......所以,一般设置为false。如果设置为true,那么最好限定消费次数,比如同一条消息消费5次之后就直接丢掉。
(2)nack:一般consumer消费消息出现异常时,需要发送nack给MQ,MQ接收到nack指令后,会根据发送nack时设置的requeue参数值来判断是否删除消息,如果requeue为true,那么消息会重新放入Queue队列中,如果requeue为false,消息就会被直接删掉。当requeue设置为true时,为了防止死循环性质的消费,最好限定消费次数,比如同一条消息消费5次之后就直接丢掉。
(3)ack:当consumer成功把消息消费掉后,需要发送ack给MQ,MQ接收到ack指令后,就会把消费成功的消息直接删掉。
2.2.5 补偿机制
经过上面这几个步骤的改造优化,我们的应用程序已经能够保证99.99%场景下消息的可靠性投递与消费了,但由于某些不可控因素,也并不能保证100%的消息可靠性,只有producer明确知道了consumer消费成功了,才能100%保证两边数据的一致性。
因为MQ是异步处理,所以producer是无法通过RabbitMQ知道consumer是否消费成功了,所以,如果要保证两边数据100%一致,consumer在消费完成之后,要给producer发送一条消息通知producer自己消费成功了。
但producer不能一直在那干等着,如果consumer过了1小时还没有发送消息给producer,那么很可能是consumer消费失败了,所以,producer与consumer之间要根据业务场景定义一个反馈超时时间,并在producer后台定义一个定时任务,定时扫描超过指定时间未接收到consumer确认的消息,然后重发消息。重发消息的逻辑中,最好定义一个重发最大次数,比如重发3次后还是不行的话,那可能就是consumer有bug或者发生故障了,就停止重发,等待问题查明再解决。
既然producer可能会重发消息,所以,consumer端一定要做幂等控制(就是已经消费成功的消息不再次消费),要做到幂等控制,消息体中就需要有一个唯一的标识,consumer可以根据这个唯一标识来判断自己是否已经成功消费了这条消息。