Flink基础篇|官方案例统计文本单词出现的次数
原创
前言
从前两节可以看出来,flink官方提供了一些示例,在这里讲讲示例。以来给予大家加深对鱼flink的理解以及后续的使用。本文主要是从flink的批处理的demo中来讲解flink。
准备工作
- IDEA:IntelliJ IDEA 2023.3.4(其他版本亦可)
- JDK:1.8.0_202(其他版本亦可)
- Flink:1.17.0(没有使用最新版本的)
创建项目
首先在IDE中创建一个名为flink-demo的项目,并增加flink需要的依赖。
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<!-- flink-java依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>准备源
在项目根目录下面创建一个目录input,然后创建一个源文件,名称为wordCount.txt,输入一些内容,为了简单这里输入以下内容。
hello flink
hello java
hello python
hello spark-streaming项目的整体结构如下所示:
flink-demo (42.19KB)
├── input (57b)
│ └── wordCount.txt (57b)
├── pom.xml (2.17KB)
└── src (14.32KB)
└── main (7.69KB)
├── resources
└── java (7.69KB)
└── com (7.69KB)
└── aion (7.69KB)
└── App.java (171b)解析步骤
(1)创建执行环境
在flink中使用flink自带的独有执行环境,需要使用org.apache.flink.api.java包下的ExecutionEnvironment类,后续针对不同的流、批需要使用不同的执行环境。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();(2)读取数据
使用环境来读取数据源,达到加载数据的目的。在flink中,可以读取txt文件,也可以读取CSV文件,或者其他文件,读取文件主打的一个格式统一。为了方便演示,读取文件可以使用readTextFile来处理。这里读取我们项目下的wordCount.txt文件中的内容。而readTextFile方法是创建一个数据集,该数据集表示按行读取给定文件所生成的字符串。默认情况下将使用UTF-8字符集读取该文件。返回一个flink自定的数据源的数据,其实是为了在读取数据时可以规范化,所以此处定义了DataSource。
DataSource<String> linesDs = env.readTextFile("input/wordCount.txt");看了官方提供的方法,我们可以使用很多读取文本文件的方法,为了简便演示,我们选择最简单的一个readTextFile(String filePath) 来演示。

其他的方法用途如下:
- readTextFile(String filePath, String charsetName):读取文本文件返回数据集
- 文件路径
- 文件编码(不指定时默认是UTF-8字符集)
- readFile(FileInputFormat<X> inputFormat, String filePath) :读取文件返回数据集
- 文件格式,泛型,主要用于返回数据集使用
- 文件路径
- readFileOfPrimitives(String filePath, Class<X> typeClass):读取文件返回数据类型集
- 文件路径
- 数据类型
- readFileOfPrimitives(String filePath, String delimiter, Class<X> typeClass):读取文件返回数据类型集
- 文件路径
- 分割类型,例如空格、竖线、逗号等
- 数据类型
- readCsvFile(String filePath):读取文件返回数据集,这个就比较简单,主要用于读取CSV类型文件,读取时以读取逗号分隔值(CSV)文件,其实这个就是上面
readFileOfPrimitives一个特定情况的使用。- 文件路径
- readTextFileWithValue(String filePath):读取给定文件所生成的字符串。有点类似于
readTextFile(String),需要注意的是在生成的数据集中包含可变的StringValue对象,而不是Java字符串。默认情况下也是使用UTF-8字符集逐行读取文件。 - readTextFileWithValue(String filePath, String charsetName, boolean skipInvalidLines):同
readTextFileWithValue(String filePath),这里给定了文件路径、文件编码以及是否跳过验证的行。- 文件路径
- 文件编码格式
- 是否跳过验证行
注意??:在读取时如果没有特殊说明,都是按行读取,且读取编码默认为UTF-8字符集。
(3)数据转换
Map算子是Flink 中最简单、最常用的算子之一。它将输入的每个元素通过用户自定义的函数进行转换,得到一个新的元素。底层逻辑是对数据集中的每个元素应用用户定义的函数,并将函数的返回值作为新的数据集。此处我们为了简化,也是将数据转化为Map算子。算子可以执行各种数据处理操作,如过滤、映射、聚合、连接、排序等。Flink提供了许多内置的算子,同时也允许用户自定义算子以满足特定的需求。
为了演示,我们在需要处理的文档中使用空格来分割数据,此时也需要使用空格来解析数据。解析的数据转换使用一个二元组来接收并收集单词。
FlatMapOperator<String, Tuple2<String, Integer>> lineWordsOperator = linesDs.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) {
String[] words = s.split(" ");
for (String word : words) {
Tuple2<String, Integer> tuple2 = Tuple2.of(word, 1);
collector.collect(tuple2);
}
}
});(4)业务处理
首先针对数据集来切分,然后针对数据集聚合。
// index
UnsortedGrouping<Tuple2<String, Integer>> tuple2UnsortedGrouping = lineWordsOperator.groupBy(0);
// position
AggregateOperator<Tuple2<String, Integer>> sum = tuple2UnsortedGrouping.sum(1);注意??:在数据处理时有异常,需要处理。
(5)测试打印输出
最终需要将数据打印到控制台。
sum.print();打印结果如下:

注意??:批处理是为了兼容,目前很少使用批处理,多数情况都是使用流处理。
完整代码示例
package com.aion.word;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class WordCountBatch {
public static void main(String[] args) throws Exception {
// 1、创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2、读取数据
DataSource<String> linesDs = env.readTextFile("input/wordCount.txt");
FlatMapOperator<String, Tuple2<String, Integer>> lineWordsOperator = linesDs.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) {
String[] words = s.split(" ");
for (String word : words) {
Tuple2<String, Integer> tuple2 = Tuple2.of(word, 1);
collector.collect(tuple2);
}
}
});
// 3、业务处理
// index
UnsortedGrouping<Tuple2<String, Integer>> tuple2UnsortedGrouping = lineWordsOperator.groupBy(0);
// position
AggregateOperator<Tuple2<String, Integer>> sum = tuple2UnsortedGrouping.sum(1);
// 4、打印输出
sum.print();
}
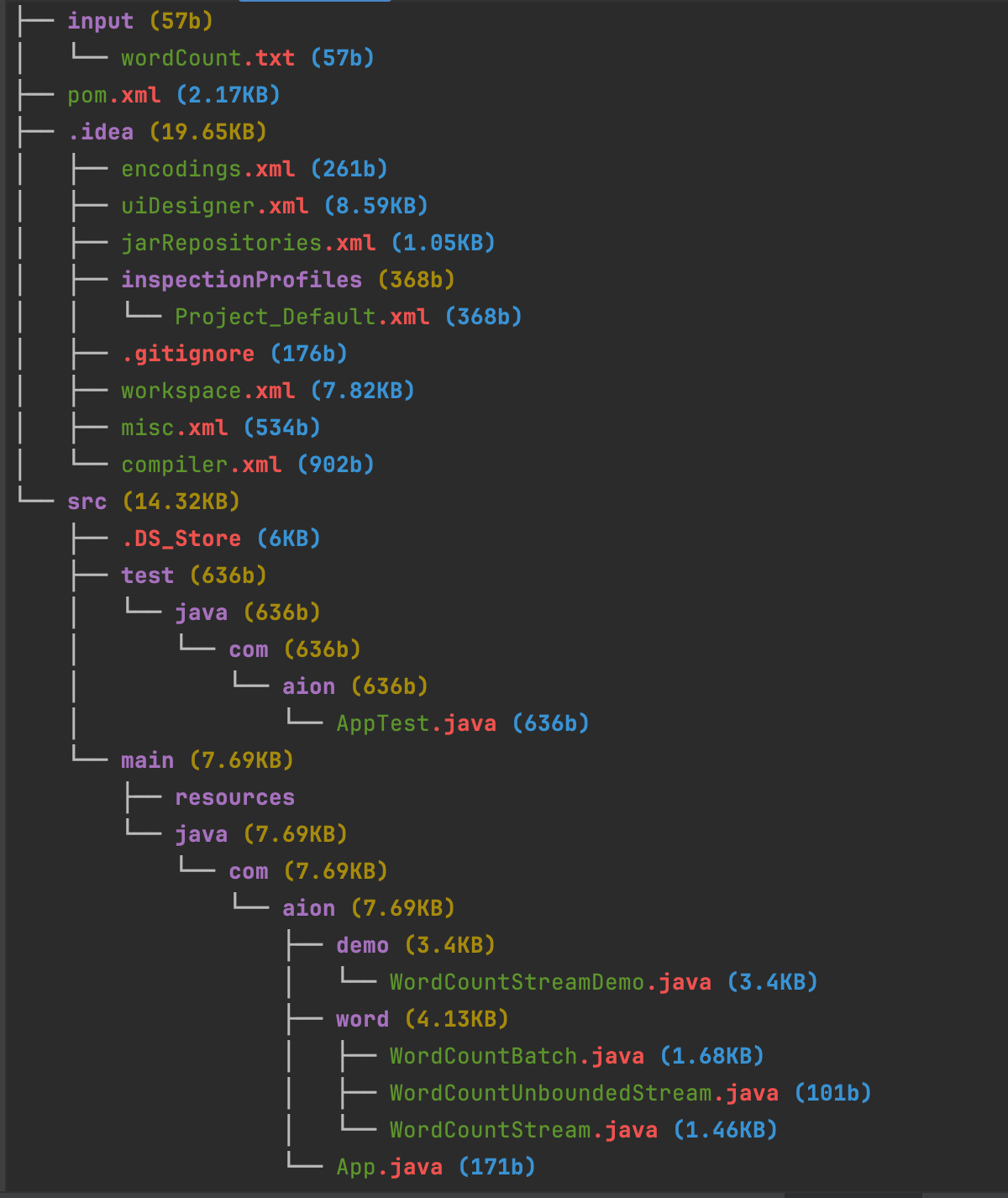
}完整项目结构
完整的项目结构如下所示
结束语
本文简单按照官方提供的案例编写了下flink在批处理时的流程,以及在批处理时需要注意点,在后续的版本中,也有可能会删除一些批处理的方法,在使用时需要格外留意变化并及时应对。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。