VFP:公有云主机 SDN 的虚拟交换平台 [NSDI'17]
VFP:公有云主机 SDN 的虚拟交换平台 [NSDI'17]


关于作者:
译者:张帅,云网络从业人员
博客:www.flowlet.net
公有云的 Host vSwitch 由于涉及的业务场景复杂(几乎所有的业务场景都跟 vSwitch 有关,例如:VPC、Nat、EIP、LB、NFV、容器场景等等),配置变更频繁,性能要求极高。同时由于国内公有云业务极其内卷,Iaas 服务基本上就是比拼价格,事实上已经沦为卖铁。VM 超卖严重,分配给 Host 用于网络处理的 CPU 与内存资源极其有限。
Host vSwitch 的设计就如同带着镣铐跳舞,基于开源的 Open vSwitch 并不能满足超大规模云网络的技术指标(单 Region 支持百万级 VPC,单 VPC 支持百万级计算节点)要求,因此国内的 Top 级互联网云厂商 Host vSwitch 都采用了自研架构。从 0 到 1 设计 vSwitch 需要熟悉所有的公有云网络业务场景,并且需要极强的技术功底与网络架构能力。
本文翻译自 NSDI’17 论文《VFP: A Virtual Switch Platform for Host SDN in the Public Cloud》,该文章介绍了微软 Azure 云在设计 Host vSwitch(VFP:Virtual Filtering Platform)方面的经验。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
0、摘要

许多现代可扩展云网络架构都依赖主机网络来实施 VM 网络策略 ———— 例如,用于虚拟网络的隧道、用于负载均衡的 NAT、带状态的 ACL、QoS 等。我们推出虚拟过滤平台 (VFP:Virtual Filtering Platform) ———— 为 Microsoft Azure(大型公共云)提供该网络策略支持的一种可编程虚拟交换机。根据我们的运营经验我们为可编程虚拟交换机定下了以下几个主要目标,包括支持多个独立的网络控制器、基于连接而不是仅仅基于数据包的网络策略、通过高效缓存和分类算法来提高性能以及将流策略高效的卸载到可编程 NIC,并演示 VFP 是如何实现这些目标的。VFP 已部署在超过 100 万台运行 IaaS 和 PaaS 工作负载的主机上超过 4 年。我们将介绍 VFP 及其 API 设计、用于流处理的流语言和编译器、性能结果以及多年来在 Azure 中部署和使用 VFP 的经验。
1、介绍
Amazon Web Services(AWS)、Microsoft Azure(Azure) 和 Google Cloud Platform(GCP) 等公有云工作的兴起造就了超大规模的数据中心,根据云服务供应商的公开资料显示服务器数量已经达到数百万台。这些云服务供应商不仅要为客户提供弹性伸缩和高性能的虚拟机(VM),还必须提供丰富的网络语义,例如,为客户提供的独立网络地址空间的专用虚拟网络、可扩展的四层 LB、安全组和 ACL 、虚拟路由表、限速(bandwidth metering)、QoS 等等。
这些策略非常复杂,通常无法非常经济地在传统硬件核心路由器上大规模部署。相反,一种常见的方法是在 VM 所在主机上的软件中实施这些策略(在将 VM 连接到外部网络的虚拟交换机 (vswitch) 中实施),该方法可以随着服务器数量而扩展,并使得物理网络简单、可扩展。由于该模型将集中式控制面与主机上的数据面分开,因此它被广泛认为是软件定义网络 (SDN) 的一个示例,特别是基于主机的 SDN。
作为大型公共云服务供应商,Azure 基于主机 SDN 构建其云网络,使用主机 SDN 来实现我们所提供的几乎所有的虚拟网络功能。近年来围绕 SDN 的大部分关注焦点一直都集中在致力于构建可扩展且灵活的网络控制器,虽然这一点至关重要,但是可编程 vswitch 的设计同样重要。因为云中的工作负载对成本和性能十分敏感,因此高度可编程数据面具有高性能和低开销的要求,高性能与低开销本身就是相互冲突的两个需求。
在本文中,我们提出虚拟过滤平台(VFP:Virtual Filtering Platform)———— 我们在所有主机上运行的云级虚拟交换机。VFP 之所以如此命名,是因为它充当 VM 上每个虚拟 NIC 的过滤引擎,允许控制器对其 SDN 策略进行编程。我们的目标是展示 VFP 的设计思路以及在大规模生产环境中运行 VFP 的经验。
1.1 相关工作
在本文中,我们通过文献中的两个例子,来展示如何通过 VFP 支持示例中的策略。第一个示例是 VL2,它通过使用主机间的无状态隧道创建虚拟网络 (VNET)。第二个示例是 Ananta,一个可扩展的 4 层 LB(Layer-4 load balancer),它通过在终端主机的 vswitch 中运行 LB-NAT(load balancing NAT)来进行扩展,使网络内的 LB 无状态且可扩展。
此外,我们还对 OpenFlow 和 OpenVswitch(实现 OpenFlow 协议的开源 vswitch )进行了参考比较,这是 SDN 领域的两个开创性的项目。我们从公有云的角度指出了两者之间的核心设计差异,我们希望能在更广泛的社区分享这些经验教训。
2、设计目标与基本原理
VFP 的设计根据我们运行大型公有云平台的经验随着时间而不断的发展。VFP 并不是我们最初的 vswitch,在主机网络中实现 vswitch 也不是什么开创性的想法(早在 VL2 和 Ananta 中就已经提出了在主机网络中实现 vswitch 的想法)。
最初,我们在 Windows Hyper-V Hpervisor(虚拟机管理程序)之上为每个主机功能构建了网络过滤驱动(用于 ACL 的状态防火墙驱动、用于 VL2 VNET 的隧道驱动、用于 Ananta LB 的 NAT 驱动、 QoS 驱动等),并将其链接到 vswitch 中。随着主机网络成为我们虚拟化策略的主要工具,在得出为主机网络功能新构建固定过滤驱动程序不可扩展的结论后,我们决定在 2011 年创建 VFP。相反,我们创建了一个基于匹配动作表(MAT:Match-Action Table)模型的单一平台。这就是我们针对 VFP client 而设计的 VFP API 编程模型的由来。
VFP 的核心设计思想是从构建和运行过滤器(filter)以及在这些过滤器之上的控制器(network controllers)和代理(agent)的经验中得到的。
2.1 最初的目标
以下是 VFP 项目创立之初的目标:
- 提供一个同时允许多个独立的网络控制器对网络应用进行编程的编程模型,最大限度地减少跨控制器的依赖性。
OpenFlow 和与此类似的 MAT 模型通常假设单一分布式网络控制器负责对交换机进行编程(也可能从其他控制器中获得输入)。我们的经验是,这种模型并不适合云中 SDN 的开发 ———— 相反,相互独立的开发团队经常为这些不同的网络应用构建不同的控制器和 agent。与通过向现有控制器添加逻辑相比,该模型减少了复杂的依赖关系,可以提供更好地可扩展性(scales better)和可维护性(more serviceable)。我们需要有一种设计,不仅允许控制器能够独立创建流表并对其进行编程,还要它们之间能够有良好的分层和边界(例如,不允许规则像 OpenFlow 中的那样随意的 GOTO 到其他表),以便可以通过开发新控制器来添加新功能,无需考虑旧控制器的行为逻辑。
- 提供一个能够使用连接(带状态的规则)而不仅仅是数据包作为基本原语的 MAT 编程模型。
OpenFlow 的原始 MAT 模型历史上源自可编程交换机或路由器的 ASIC,因此假设由于硬件资源有限,数据包分类必须是无状态的。然而,我们发现我们的控制器需要基于连接,而不仅仅是基于数据包的策略 ———— 例如,最终用户经常发现通过使用有状态的访问控制列表(ACL)(例如,允许出站连接,但不允许入站连接)比在商用交换机中使用无状态的 ACL 来保护其虚拟机安全更加有用。控制器同样还需要 NAT(例如,Ananta)和其他有状态的策略。在软件 vswitch 中比在 ASIC 中更容易实现有状态的策略处理,我们的 MAT 模型应该利用这一点优势。
- 提供一个允许控制器自定义自己的策略(policy)和动作(action)的编程模型,而不仅仅是提供只针对预定义场景的固定策略集。
由于 OpenFlow 提供的 MAT 模型的局限性(一组有限的 aciton 集、rule 有限的可扩展性、无表类型),OpenFlow 交换机(例如,OVS)在 MAT 模型之外添加了虚拟化功能。例如,通过 OVSDB 中的 VTEP(虚拟隧道端点:virtual tunnel endpoint)模式构建虚拟网络,而不是通过规则指定要封装(encap)和解封装(decap)哪些数据包以及如何执行此操作。
相反,我们更喜欢所有功能都基于 MAT 模型实现,并尝试将尽可能多的业务逻辑上移到控制器,vswitch 只保留核心的数据面逻辑。例如,可以通过匹配适当条件的可编程封装和解封规则来实现 VNET,而不是通过定义什么是 VNET 的模式,将 VNET 定义保留在控制器中,这大大减少了每次 VNET 定义发生变化时都需要不断对数据面进行扩展的次数。
P4 语言尝试为交换机或 vswitch 实现类似的目标,P4 语言非常的通用,例如,允许动态(on the fly)定义新的报文头。由于我们更新 vswitch 的频率远高于在网络中定义新报文头的频率,因此我们更喜欢预编译形式的快速报文头解析库,以及面向有状态连接处理而构建的编程语言。
2.2 在生产环境中学到的目标
根据 VFP 最初部署的经验教训,我们对 VFPv2 增加了以下目标(这是 13 到 14 年里的一次重大更新,该目标主要围绕可维护性(serviceability)和性能两方面):
- 提供允许无需重启或中断虚拟机状态流连接即可实现频繁部署和更新的可维护模型以及提供强大的服务监控能力。
随着我们的规模急剧增长(dramatically)(主机规模从 O(10K) 到 O(1M) ),随着越来越多的控制器基于 VFP 构建,以及越来越多的工程师加入,我们对频繁更新(功能和错误修复)的需求比以往任何时候都多。在基础设施即服务(IaaS:Infrastructure as a Servic)模型中,我们还发现客户不能容忍对单个 VM 进行停机更新。使用我们的有状态流模型(stateful flow model)来实现这一目标更具有挑战性,尤其是在跨版本更新(across update)时更不容易。
- 通过大量的缓存(extensive cache)设计,在即使存在大量表项和规则的情况下,也能够提供非常高的包速率。
随着时间的推移,我们发现越来越多的控制器通过主机 SDN 模型进行构建,主机 SDN 变得越来越流行。很快我们就部署了大量流表(10+),每张流表都有许多规则,因为数据包必须遍历每张表,这大大降低了转发性能。与此同时,主机上的 VM 密度不断增加,促使我们网卡速率逐步从 1G 到 10G 再到 40G,甚至更高速率。我们需要找到一种在不影响性能的情况下能够容纳更多策略的方法,并得出结论,我们需要跨表执行流动作(flow action)的编辑(compilation),并使用大量的流缓存设计,以便现有流上的数据包能够与预编辑的动作(precompiled action)相匹配,而不必遍历表。针对具有大量规则和表的情况提供快速数据包分类算法。
虽然目标 #5 显着的提升了现有流的性能(例如,SYN 报文后的所有 TCP 报文),但我们发现一些应用将数千条规则推送到其流表中(例如,BGP peer 是客户的分布式路由器,使用 VFP 作为它的 FIB 表),这减慢了我们的流编译器的速度。我们需要设计一个高效的数据包分类器来处理该情况下遇到的性能问题。
- 实施一种将流策略卸载到可编程 NIC 的有效机制,无需考虑(assuming)复杂规则的处理。
当我们使用 40G+ NIC 时,我们希望将策略卸载到 NIC 以支持 SR-IOV 场景,让 NIC 对相关 VM 的数据包直接执行相关的 VFP 策略。然而,随着控制器创建许多具有更多规则的流表,我们得出的结论是,直接卸载这些表 服务器 NIC 需要付出极其昂贵的硬件资源(例如,大 TCAM 表、串联匹配)。因此,对比将分类操作进行 offload,我们更想得到一个能够与预编辑精确匹配流很好配合的卸载模型,要求硬件只支持访问 DRAM 中的大缓存流表,并支持我们相关的动作语义。
2.3 非目标
以下是我们在其他项目中看到的目标,根据我们的经验,我们选择不支持(pursue)这些目标:
- 跨平台可移植。
在内核的高性能数据路径中很难实现跨平台移植。OVS 等项目通过将其分为内核态快速路径和可移植的用户态慢速路径来实现此目的,但这样做的代价是,当数据包采用慢速路径时,速率会降低一个数量级。我们只在一种主机操作系统上运行,所以跨平台可移植不是我们的目标。
- VFP 自身支持远程配置协议。
OpenFlow 既包含网络编程模型,也包含通过远程配置协议。OVS 和 OVSDB 协议也是如此。为了支持管理策略不同的控制器模型(例如,规则推送(push)模型或 VL2 目录系统拉取(pull)模型),我们将 VFP 解耦为 vswitch 与实现远程配置协议的 agent,该 agent 专注于提供高性能的 host API。
- 提供检测或防止控制器编程策略冲突的机制
许多文献描述了检测或防止策略在流表或规则匹配系统中的冲突方法。尽管我们的第一个目标就是支持多个控制器对 VFP 进行并行编程而不会互相干扰,但我们很早就得出结论,由于种种原因,显式的进行冲突管理既不可行也非必要。对 VFP 进行编程是一项受保护的操作,只有我们的控制器才能执行,因此我们不必担心恶意控制器。此外,我们得出的结论是,不可能区分错误编程(misprogrammed)的流表(意外的覆盖另一个流表的动作)和一个流表被设计用于过滤另一个表的输出,它们之间的区别。相反,我们专注于开发用于帮助开发人员验证其策略的工具。
3、概述与比较
本文的第一个示例,我们考虑一个简单的场景,需要 4 个用于云中 O(1M) 个 VM 的 Host 策略。每个策略均由其自己的 SDN 控制器进行编程,并且需要高性能和支持 SR-IOV offload:VL2 型 VNET、Ananta 型 LB、带状态防火墙以及用于计费目的的目的地(per-destination)流量统计。我们首先根据现有解决方案对此进行评估,以证明需要我们所描述的不同方法。第 4-7 节将详细介绍 VFP 的核心设计。
3.1 现有解决方案:Open vSwitch
虽然 Linux 和 Windows 支持将多个接口进行桥接(可用作 vswitch),但这种网桥不适用于 SDN 策略。其他公共云厂商(例如,Google)描述了其如何使用主机 SDN 策略,但详细信息并未公开。OVS 是当今提供基于 vswitch SDN 的主要解决方案,因此其是我们的主要比较对象。
我们相信 OVS 在让可编程主机网络方面有着巨大的影响力。OVS 的许多设计都是由于 OVS 特定目标(例如,支持跨平台,并随 Linux 内核一起发布)导致的。结合 OVS 对 OpenFlow 的使用,这么设计的目的是控制器能够通过相同的协议同时管理虚拟交换机和物理交换机,但这并不是我们主机网络模型的目标。OVS 还支持许多对物理交换机有用的协议(例如 STP、SPBM、BFD 和 IGMP Snooping),但我们并不使用这些协议。
OpenFlow 与 OVS 在某些方面并不适用于我们的工作场景:
- OVS 本身并不支持真正的多控制器模型,而当我们的 VL2 和 Ananta 应用需要单独控制时则需要这种模型。OpenFlow 的底层表模型并不适用于多控制器场景 ———— 表规则显示的指定 GOTO 到对下一张表,导致控制器将这些表的策略绑定在一起。另外,表只能正向遍历,在多控制器的场景下要求出站报文与入站报文相反的方向遍历表,以便报文在任一方向匹配该控制器策略时都处于一致的状态。VFP 通过显式的将表进行分层解决这个问题(§5.2)。
- OVS 本身在其 MAT 模型中并不支持 NAT 之类的有状态 action,而我们的 Ananta 示例需要这种操作(我们的防火墙也是有状态的)———— 在这两种情况下,控制器需要将连接(而不是数据包)作为基本操作原语。然而,OpenFlow 仅提供数据包模型。OVS 最近新添加了将数据包发送到 Linux 连接跟踪以支持有状态防火墙,但它没有作为 MAT 模型进行公开,并且并不容易支持 NAT,这需要显式的双向有状态表,以便 NAT 在流的返回路径上进行反转。VFP 通过状态层解决这个问题(§5.2)。
- OVS 的 VTEP 模式(schema)需要通过显式隧道接口来实现 VL2 风格的 VNET,而不是允许控制器指定自己的 encap/decap action(OpenFlow 本身并不支持这种类型的 action)。在数据面中硬编码 VNET 模型,而不是允许控制器定义 VNET 如何工作(目标 3)。在此模式中添加复杂的 VNET 逻辑(例如,ECMP 路由)可能很困难,并且需要对 vswitch 进行修改,而不仅仅是更改策略。VFP 通过将 encap/decap 建模为 action,直接在其 MAT (§5.3) 中就能支持。
- OVS 不支持动态查找客户地址到物理地址映射所需的 VL2 样式目录系统。OpenFlow 的设计在以这种方式支持大型 VNET 方面缺乏可扩展性 ———— OpenFlow 的异常报文必须全部返回到中央控制器,并且在 OVS 中,所有主机上的 VTEP 都应在映射发生变化时进行更新。这对于支持最多 1000 个主机的 NSX/vSphere 来说是没问题的,但我们发现这在公有云这个规模量级上是不可用的。VFP 通过将无模式(schema-free) MAT 模型与高效的异步I/O 异常请求(§5.5.1)相结合来解决这一问题,agent 可以将这些请求重定向到与控制器分离的处理模块。
- OVS 没有通用的卸载 action 语言或 API 来支持策略组合(例如,Ananta NAT 加 VL2 encap)。虽然 NIC 供应商已在 OVS 构建之上针对特定工作负载(例如,VTEP 模式)实施了 SR-IOV 卸载,但执行通用卸载需要硬件支持原始策略的复杂多表查找,我们发现其在实践中成本相当高。VFP 的协议头转换语言(Header Transposition language)(§6.1.2, 9.3)只需在硬件中进行一次表查找即可为所有策略提供 SR-IOV 支持。
因此,我们的策略需要不同的设计。
3.2 VFP 设计

图 1 展示了 VFP 的设计模型,后续部分将对此进行描述。VFP 在 Hyper-V 可扩展交换机(Hyper-V extensible switch)之上运行,如第 4 节过滤模型中所述。VFP 将 MAT 作为支持多控制器模型的层来实现,编程模型在第 5 节中介绍。第 6 节描述了 VFP 的包处理器,包括通过统一流表的快速路径以及用于匹配 MAT 层中的规则的分类器。第 7 节介绍了 VFP 桥的交换模型。
4、过滤模型(Filter Model)
VFP 通过 MAT 流表策略对操作系统中经过的报文进行过滤。下面介绍过滤模型:
4.1 端口与网卡(Ports and NICs)
核心 VFP 模型假设 switch 具有多个连接到虚拟 NIC(VNIC)的端口。VFP 过滤从 VNIC 到 switch 以及从 switch 到 VNIC 的流量。所有 VFP 策略都附属(attached to)于特定的端口。从 VM 的角度来看(具有连接到端口的 VNIC),switch 的 ingress 流量被认为来自 VM 的 outbound 流量,switch 的 egress 流量则被视为 VM 的 inbound 流量。VFP API 及其策略基于 inbound/outbound 模型。
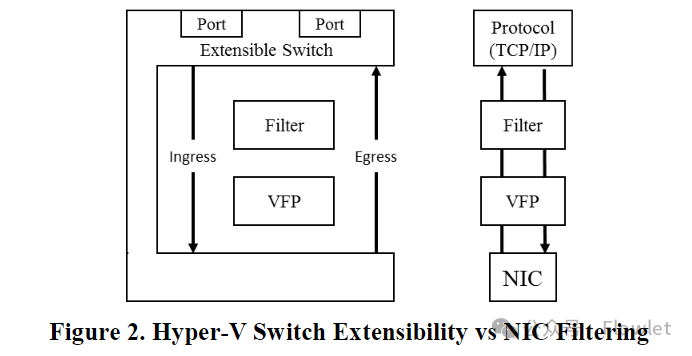
VFP 实现了一个 switch 抽象接口来抽象出不同的环境,其实例化提供了 port、VNIC 和关联对象的管理逻辑(例如,创建/删除/连接/断开连接)。该接口支持 Hyper-V switch 和本机主机过滤器,如图 2 所示。
4.2 Hyper-V switch 可扩展性
Hyper-V 包括一个基本的 vswitch,用于将 VNIC 桥接到物理 NIC。该 switch 是可扩展的,允许插入过滤器并过滤进出 VNIC 的流量。VFP 充当 Hyper-V vswitch 的转发扩展 ———— 它只是通过自身简单的替换整个 switch 逻辑。使用此模型使我们能够将策略模块和 VFP 与 Hyper-V 基础设施中分开,以将报文传送到 VM 或从 VM 发送报文,从而提高其模块化和可维护性。
这种模式下的 VFP 支持 PacketDirect,它允许 client 以非常低的开销轮询 NIC。
5、编程模型(Programming Model)
VFP 的核心编程模型基于 VFP 对象的层次结构,控制器可以创建这些对象并对其 SDN 策略进行编程。这些对象是:
- Ports(端口),VFP 策略过滤的基本单位。
- Layers(层),保存 MAT 策略的有状态流表。
- Groups(组),用于管理和控制 Layer 内 rule 组的 entry。
- Rules(规则),match action 表的 entry。

5.1 Ports(端口)
VFP 的策略是基于端口实施的 ———— 每个端口都有 match action 表,其可以在端口的 inbound 或 outbound 路径上充当过滤器。由于我们的控制器通常希望代表 VM 或 VNIC 对策略进行编程,因此这种干净的端口分离允许控制器独立管理不同 VM 上的策略,并仅在需要的端口上进行实例化和管理流表 ———— 例如,虚拟网络中的 VM 可能具有用于将隧道中流量进行封装和解封装的表,而另一个不在虚拟网络中的 VM 则不需要该表(VNET 控制器甚至可能不知道其他的 VM,它不需要管理该 VM)。
VFP 上的策略对象按固定的对象层次结构排列,用于指定给定 API 调用正在引用哪个对象,例如,Layer/Group/Rule。所有对象都按照优先级被编程,rule 匹配将按照该顺序处理它们。
5.2 Layers(层级)
VFP 将端口的策略分为几个层级(Layers)。Layer 是控制器用来指定其策略的基本匹配动作表(Match Action Tables)Layer 可以由不同的控制器单独创建和管理,或者一个控制器可以创建多个 Layer。每一层都包含 inbound 和 outbound 规则和可以过滤和修改数据包的策略。从逻辑上讲,数据包逐层通过每一层,根据上一层执行 action 后数据包的状态来匹配每层中的规则。控制器可以指定端口 pipeline 中各层相对于其他层的顺序,并在操作期间动态创建和销毁层。

重要的是,数据包在 inbound 和 outbound 时以相反的顺序遍历各层。当控制器在层的任一侧实施相反的策略时,这会给它们带来“分层(layering)”效果。以实现 Ananta NAT 的 LB 层为例,在 inbound 方向,NAT 层将指向 VIP 的连接,转换为指向 VIP 后面的 DIP ———— 在本例中 DIP 为 VM IP。在 outbound 方向,NAT 层将数据包从 DIP 还原为 VIP。因此,该层实现了地址空间边界 ———— 其上方的所有数据包都在 “DIP 地址空间”,而其下方的所有数据包都在 “VIP 地址空间”。其他控制器可以选择在 NAT 层之上或之下创建层,并且可以分别创建匹配 VIP 或 DIP的规则 ———— 所有这些都无需与 NAT 控制器进行协调。
图 4 展示了我们的 SDN 部署层级。VL2 由虚拟网络控制器编程的 VNET 层实现,对客户地址(CA:Customer Addresses) 进行隧道封装,以便数据包可以穿过物理网络。该层通过在 outbound 路径上的封装规则和 inbound 路径上的解封装规则来创建CA/PA(Physical Address) 边界。此外,实现有状态防火墙的 ACL 层位于 Ananta NAT 层之上。安全控制器可以在 CA 地址空间对匹配 VM 的 DIP 的策略进行编程。最后,用于计费的 Meter 层位于最顶部紧邻 VM,它可以准确的计量流量(流量计量与 VM 中看到的流量统计一样 ———— 进出 VM 的所有流量)。
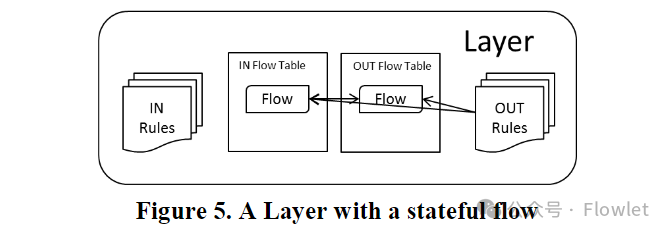
分层还为我们提供了一个实施有状态策略的良好模型。由于给定连接的数据包在 inbound 和 outbound 路径上应具有相同的 IP/Port 状态,因此我们可以通过假设 TCP 或 UDP 5 元组(SrcIP、DstIP、IP Proto、SrcPort、DstPort)在该层的两侧相反来保持流的状态,并将任一方向上所有连接编码到哈希表中。当匹配上有状态规则时,会在该层的流表中创建 inbound 流和 outbound 流,匹配了 rule 的流会执行该 rule 的 action ,相反方向的流执行相反的 action,以保持分层。这些 inbound 和 outbound 流被认为是一对(paired) ———— 这些 rule 的 action 只是将数据包修改为该 paired 的相反状态,而不是携带自己的 action 内容。
在处理数据包时,VFP 通过在层内的 rule group 中搜索匹配的规则,然后对该数据包执行该规则的 action ———— 在给定层中只有一个规则可以匹配给定的数据包(其他优先级低的匹配规则将被忽略)。
5.3 Rules(规则)
规则是对 MAT 模型中匹配的数据包执行 action 的实体。根据目标 #3,规则可以让控制器最大限度地减少数据平面中的固定策略的数量。规则由两部分组成:条件列表(condition list)和通过条件列表指定的动作(action)。
5.3.1 Conditions(条件)
当 client 通过 VFPAPI 编写规则时,它会提供带有条件列表的描述符。条件由类型/type(例如,源 IP 地址)和匹配值列表/match value(每个 match value 可以是单个值、范围/rang 或前缀/prefix)组成。
匹配数据包的 condition:只要有一个 match value 匹配即匹配(OR)。匹配规则的 condition:rule 中的所有 condition 都匹配才匹配(AND)。
5.3.2 Actions(动作)
规则描述符也有一个 action。该 action 包含类型/type和特定于该类型的数据结构,以及执行 rule 所需的数据(例如,报文封装 rule 将 src/dst IP、src/dst MAC以及数据包的封装格式和密钥作为输入数据)。action 接口可扩展 ———— 图 6 中列出了示例 Condition 和 Action。
rule 通过简单的回调接口实现(初始化、报文处理、初始化注销),从而使基础 VFP 平台很容易进行扩展。如果 rule type 支持有状态(stateful)实例,处理程序会在 layer 中创建一对流(a pair of flows) ———— 流也被类型化,并且具有与规则类似的回调接口。有状态规则包括 flow 的生存时间,这是流被创建后,当最后一个数据包匹配后将保留在流表中的时间(除非由§6.4.2 中描述的 TCP 状态机显式过期)。

5.3.3 User Defined Actions(用户自定义 action)
除了我们创建的大量 action 之外,在 VFPv2 中,我们添加了用户自定义 action 来进一步实现目标 #3 ———— 允许控制器使用协议头字段操作语言创建自己的规则类型(Header Transpositions 协议头转换,请参阅 §6.1.2)。这允许扩展 VFP action 集,而无需数据面编写代码来实现对应的 action。
5.4 Groups(组)
出于管理目的,layer 上的 rule 被组织成逻辑 group。group 是 VFP 中策略的基本单元(atomic unit) ———— client 可以通过事务(transactionally)的方式更新它们。在对数据包进行分类时,VFP 会遍历 layer 中的 group,以查找每个 group 中与数据包匹配的优先级最高 rule。默认情况下,VFP 将选择列表中最后一 group 中匹配的 rule。规则可以标记为“终止(terminating)”,如果该 rule 匹配将立即被应用,而无需遍历其他 group。group 可以有像 rule 一样的 Conditions(条件) ———— 如果 group 的 condition 不匹配,VFP 将跳过它。
- 对于具有 Docker 式容器的 VM,每个容器都有自己的 IP,可以通过设置每个容器的 IP condition 来创建和管理 group。
- 对于有状态防火墙,基础设施 ACL 和客户 ACL 可以表示为 layer 中的两个 group。阻塞(Block)规则将被标记为终止(terminating) ———— 如果任意 group 阻塞(block)它,则数据包将被丢弃。只有当两个 group 的规则都允许数据包通过时,数据包才会通过。
除了基于优先级的匹配之外,各个 group 还可以根据 condition 类型(例如,dst IP)进行最长前缀匹配,以支持路由场景。最长前缀匹配通过压缩 trie 树实现(compressed trie)。
5.5 Resources(资源)
MAT 是用于通用网络策略编程的良好模型,但其并不适合所有场景,尤其是存在异常事件的场景。VNET 需要 outbound 流量进行 CA->PA 查找(使用目录系统/Directory System)。对于如此大的映射表来说,直接对每条 rule 进行映射(mapping)并不是最优的。因此,我们支持通用资源的可扩展模型 ———— 在本例中,通过哈希表进行映射。另一个例子是范围列表(range list),它可以实现 Ananta 中描述的动态源 NAT 规则。
5.5.1 Event Handling / Lookups(事件处理/查找)
许多 SDN 应用在查找未命中时都需要快速事件 API。我们通常在资源上下文处理事件 ———— 例如,通过 PA/CA 映射资源查找 encap 规则,未找到(miss)。VFPAPI client 可以使用异步 I/O 和事件注册有效的回调机制。我们对 Ananta NAT 端口耗尽使用了该机制。
6、报文处理与Flow编译器(Packet Processor & Flow Compiler)
随着我们 VFP 在生产环境部署不断扩大,并且 SDN 得到广泛的使用,有必要编写新的 VFP 数据路径,以提高性能及跨多个 rule 和 layer 可扩展性。在不失去 VFPAPI 灵活性和可编程性的前提下提高性能的工作如下所述:
6.1 Metadata pipeline 模型
VFP 最初的 2012 版本,虽然该版本设计下工作负载具有良好的性能,但当主机 SDN 模型的发展速度比我们预期的要快时并且当控制器创建了许多新 layer 时,它的扩展性就不佳。VFP rule 和 flow 以回调的形式实现,回调将数据包作为输入并修改其 buffer ———— 下一层/layer 必须重新解析该数据包。最初的 rule 分类逻辑是线性匹配(有状态流加速了这一点)。在 10+ layer 并且 rule 达到数千条时,我们需要性能更好的数据面。
VFPv2 的主要创新是引入了中央数据包处理器(central packet processor)。我们从常见的网络 ASIC pipeline 设计中获得灵感,例如 ———— 解析数据包中的相关元数据,并对元数据而不是数据包进行操作,只有当所有决策都已经抉择完成之后,在 pipeline 末端操作数据包。我们在看到数据包时编辑并存储 flow。我们的即时(JIT:just-in-time)流编译器包括解析器、动作语言(action language)、用于操作解析元数据和 action 的引擎以及流缓存(flow cache)。
6.1.1 统一 FlowID(Unified FlowIDs)

VFP的数据包处理器从解析开始。要解析的相关字段是所有可以在条件(conditions)中匹配的字段(§5.3.1)。L2/L3/L4 头(如:表1定义)各组成一个 header group,header group 的相关字段形成一个 FlowID。数据包的所有 FlowID 组成的元组是统一 FlowID(UFID),解析器的输出是 UFID。
6.1.2 协议头转换(Header Transpositions)

我们的 action 原语,协议头转换(HT:Header Transpositions),之所以这么叫是因为它们改变或移动整个数据包中的字段,是可参数化 header action 的列表,每个 header 都有一个。Actions(在表 2 中定义)包括 push header(将其添加到 header stack)、modify header(更改给定 header 中的字段)、pop header(将其从 header stack 中删除)或 ignore header(跳过它)。HT 通过将 header 中可以匹配的所有字段进行参数化(以便创建完整的语言 ———— 任何有效的 VFP flow 都可以通过一个 HT 转换为任何其他有效的 VFP flow)。HT 中的 action 被分组为 header group。表 3 展示了 Ananta 使用的 NAT HT 和 VL2 使用的 encap/decap HT 的示例。

作为 VFPv2 的一部分,所有 rule 处理程序都进行了更新,以 FlowID 作为输入并输出对应的转换。这使得使用新 rule 扩展 VFP 变得很容易,因为实施 rule 不需要操纵数据包 ———— 只是纯粹的操作元数据。
6.1.3 转换引擎(Transposition Engine)
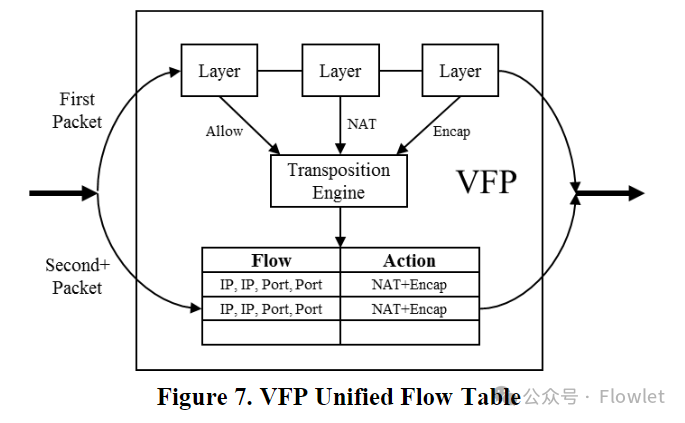
VFP 通过每层中的匹配规则组合而成的 HT 来创建 UFID 匹配 action,如伪代码 1 中所示。例如,数据包通过示例中的 Ananta NAT 层和 VL2 VNET encap 层可能会如表 3 所示,以综合 Encap + NAT 转换结束。该转换引擎还包含通过将最终转换分解为可由数据包修改器应用的一系列步骤(NAT、encap、decap)来将转换应用于实际数据包的逻辑。
6.1.4 统一流表和缓存(Unified Flow Tables and Caching)
我们的流编译器背后的直觉是,UFID 操作在流的生命周期内相对稳定 ————因此我们可以将 UFID 与引擎生成的 HT 一起缓存。像 Ananta 这样的应用已经创建了每个连接状态,因此为每个 TCP/UDP 流缓存整个统一流 (UF:unified flow) 并不会带来过多消耗。编译器缓存 UF 结果的流表称为统一流表(UFT:Unified Flow Table)。

通过 UFT,我们将数据路径分为快速路径和慢速路径。对于 TCP 流的第一个数据包,我们采用慢速路径,运行转换引擎并根据规则在每一层进行匹配。对于后续数据包,VFP 采用快速路径,通过 UFID 匹配 unified flow,并直接应用转换。该操作与VFP 中的 layer 或 rule 无关。
UFT 的使用方式与 OVS 通过 microflow cache 来跳过其他表的查找类似,并且可以很好的随着 CPU 数量进行扩展,因为 match 不需要 write lock。然而,我们工作负载的一个关键区别是 HT,它将 encap/decap 与 header 修改结合在一起。这使我们能够对所有操作使用单个 flow,而不是在隧道口之前一个 flow 和隧道口之后一个 flow,并且对于只通过单个硬件表来卸载 flow 的设备来说至关重要(§9.3)。
6.2 action 上下文(Action Contexts)
某些 rule action 除了 header 修改之外还有副作用,或者对数据包有效负载执行 action。示例包括用于计量的全局计数器(以支持我们的示例中的 meter layer)或对数据包有效负载进行加密。对于这类 action,HT 可以使用 Action Contexts (动作上下文)进行扩展,Action Contexts 可以通过回调实现任意逻辑。可以通过 rule 将 Action Contexts 添加到 HT(以及由此产生的 UF)。这允许 rule 扩展数据包 action 本身,即使它并不与每个数据包匹配。
6.3 流对账(Flow Reconciliation)
VFP flow compiler 要求对 VFPAPI client 透明。这意味着,如果控制器改变了 layer 中的 rule,即使存在 UF,也应将新 rule 应用于后续数据包。
对账引擎(reconciliation engine)在每个端口上维护一个全局生成的编号。创建 UF 时,它会用在创建时生成的编号进行标记。每当策略更新,端口生成的编号会增加。VFP 实现惰性对账(lazy reconciliation),仅当 match UF 的编号小于端口当前编号时才进行 UF 对账。然后,通过转换引擎运行其 UFID,根据端口上的当前 rule 模拟 UF,并确定生成的 HT 是否已更改。
6.4 流状态跟踪(Flow State Tracking)
默认情况下,UF 的过期策略:在配置的超时时间到期后过期。然而,这对于短流(short flow)来说效率不高,并会导致 UFT 中大量 UF 闲置。相反,对于 TCP 流,我们可以通过跟踪 undelay 连接的状态来使其过期。这需要确定 UF 应该与相反方向的哪个 UF 是一对(pair)以形成双向连接。
6.4.1 Flow Pairing
与 layer flow 不同,我们不能仅通过反转 FlowID 来配对 UF ———— UF pair 可能是不对称的,例如,连接在 inbound 时通过隧道封装传送到 VM,但在 outbound 时没有通过隧道传输,而直接返回(例如,Ananta 中的直接返回服务器功能)。我们解决方案的关键思想是在 VFP pipeline 的 VM 侧而不是网络侧配对连接(例如,对于连接的 UFID,在 inbound 路径处理后的 UFID 应与 outbound 路径处理前的 UFID 相反)。
当 inbound 数据包创建 inbound UF 时,我们通过在 inbound action 后反转数据包的 UFID 来创建 outbond UF 与之配对,并通过该端口的 outbond 路径进行模拟,为连接生成完整的 UF 对。对于新的 outbound UF,我们等待 inbound 数据包来尝试创建 inbound UF ———— 当新的 UF 查找反向 UFID 时,它将找到现有流并自行配对。
6.4.2 TCP 状态跟踪
一旦我们建立了 UF 对,我们使用 VFP 中的简单 TCP 状态机来跟踪 tcp 连接。例如,新流是在半开放状态(half-open state)下创建的 ———— 带有正确序列号的三次握手(three-way handshake)验证通过时,它才会成为完整流(这有助于防止 SYN flood)。我们还可以使用此状态机来跟踪 FIN 和 RST,以跟踪提前到期的流。我们还可以跟踪处于 TIME_WAIT 中的连接,允许 NAT rule 确定它们何时可以安全地进行端口重用。VFP 跟踪端口范围的统计数据,如平均 RTT、重传和 ECN 标记,这在诊断出现网络问题的 VM 时非常有用。
6.5 数据包分类(Packet Classification)
在实践中,VFPv2 的 UFT 数据路径解决了大多数数据包的性能和可扩展性问题(即使是短暂流:通常至少有 10 个数据包)。但是,对于具有数千条规则的场景(例如,复杂的 ACL 或路由),规则匹配仍然是一个影响性能的因素。我们针对这类情况实施了更好的分类算法。
我们支持 4 种分类器(assifier)类型:压缩 trie 树(compressed trie)、线段树(interval tree)、哈希表和列表。每种分类器都可以针对 §5.3.1 中每个 condition type 进行实例化。我们根据《virtual Switch Packet Classification. In Microsoft TechReport, MSR-TR-2016-66, 2016.》启发的方法将每个规则分配给分类器,以优化 VFP group 中的总匹配时间。在实践中,我们发现这可以成功处理用户设置的各种规则类型,例如,带有 IP range 的 5 元组 ACL 和大型路由表。
7、交换模型(Switching Model)
除了 SDN filter 之外,VFP 还将流量转发到端口。下面介绍 VFP 的转发面。
7.1 数据包转发(Packet Forwarding)
VFP 实现一个简单的网桥,根据 dst MAC 地址将数据包转发到使用该 MAC 地址创建的 VNIC。对于在虚拟化模式下运行的 VM,这可以是外部 MAC,也可以是 VXLAN/NVGRE 封装数据包内的内部 MAC。
7.2 Hairpinning 与 Mirroring
网关 VM 通常用于桥接不同路由域的地址空间或不同 tunnel。为了加速这些工作负载的处理,我们在 VFP layer 中支持 hairpin rule,它可以通过 VFP ingress 处理(在相同或不同 VNIC 上)将数据包重定向到 VNIC。这可以无需付出向 VM 发送数据包开销的前提下实现高速网关。该策略还支持可编程端口镜像。
7.3 QOS
VFP 支持对交换机上的端口或端口组的传输和接收应用最大容量(max cap)策略。这是通过使用原子操作更新令牌桶计数器和互锁数据包队列以获得高性能来实现的。还支持跨端口的带宽预留。我们基于测量的加权公平共享算法在《Measurement Based Fair Queuing for Allocating Bandwidth to Virtual Machines. In HotMiddlebox, 2016.》中进行了描述。
8、操作注意事项(Operational Considerations)
作为云服务供应商,VFP 的设计必须考虑可维护性(serviceability)、监控(monitoring)和诊断(diagnostics)。
8.1 免重启更新(Rebootless Updates)
更新时,我们首先暂停数据路径,然后从 stack 中分离 VFP,卸载 VFP(充当可加载内核驱动程序),安装新的 VFP,将其加载到 stack,然后重启数据路径。此操作通常在 <1s 内完成,看起来就像是 VM 的短暂连接问题(blip),而 NIC 保持运行状态。
8.2 状态保存/恢复(State Save/Restore)
由于我们支持 ACL 和 NAT 等有状态策略,默认情况下,VFP 更新会强制 VM 重置所有的 TCP 连接,因此流状态会丢失。由于我们的更新越来越频繁,因此我们需要构建状态保存/恢复(State Save/Restore (SSR) )功能,以消除 VFP 更新对虚拟机的影响。
我们支持端口 VFP 所有策略和状态的序列化和反序列化。每个 VFP 对象都有一个序列化和反序列化处理程序,包括 layers/groups/rules/flows、rule 上下文、aciton 上下文、UF、HT、资源和资源 entry 等等。所有对象都有版本控制,因此如果该结构更新,SSR 可以支持多个源对象版本。
8.2.1 虚机热迁移(VM Live Migration)
VFP 还支持 VM 热迁移。在这种情况下,端口状态会在 VM 中断时间(blackout time)内从原始 host 上序列化迁出并在新 host 上反序列化迁入。如果迁移过程中有更改的策略(例如,VM 物理地址),则所有 VFPAPI client 都会在新 host 上更新 VFP 策略/规则。然后,VFP flow 对账(§6.3)处理并更新 flow,保持 TCP 连接处于 active 状态。
8.3 监控(Monitoring)
VFP 在每个 port、每个 layer 和每个 rule 库上实现 300 多个性能计数器和 flow 统计。这些信息不断上传到中央监控服务(central monitoring service),我们可以通过其提供的仪表板(dashboard)监控 VM 或 cluster/node/VNET 的 flow 利用率、丢包、连接 reset 等。
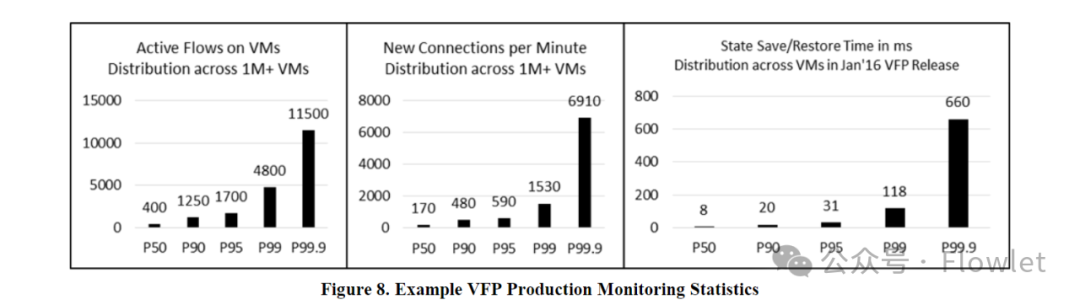
图 8 显示了在生产环境中测量的每个 VM 的 active flow 数量和连接新建速率以及最近 VFP 更新的 SSR 时间。
8.4 诊断(Diagnostics)
VFP 为生产环境下的调试提供诊断功能,包括 VFP 本身和 VFPAPI client。可以查询任意 UFID 的转换引擎模拟路径,以跟踪该 UFID 在 VFP 中的所有 rule/flow 中的行为方式。这使得可以远程调试不正确的 rule 和 policy。VFP trace 启用后,会提供在数据路径和控制路径上执行 action 的详细日志。
如果我们需要跟踪 VFP 的逻辑错误,SSR 可以在生产环境中 snapshot 端口状态,并可以将在本地测试机器上恢复,然后可以在 kernel debugger 下使用上述诊断方法来模拟数据包。
9、硬件 Offload 与性能
随着云服务器规模的不断扩大,我们对性能和成本非常敏感(sensitiv)。VFP 实现了多种硬件卸载机制:
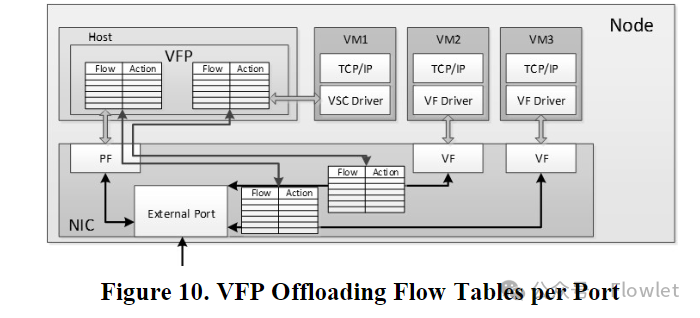
9.1 无状态隧道卸载(Stateless Tunneling Offloads)
商用 NIC 自 2013 年推出以来就能够解析 NVGRE/VXLAN 隧道,并支持无状态 checksum、分段。VFP 对 NIC tunnel offload 进行编程,这广泛部署在我们的数据中心中。这很大程度上消除了我们平台 encap/decap 的性能开销 ———— 我们 NIC 可以支持 40Gbps 线速的 encap。
9.2 QoS 卸载
许多商业 NIC 支持跨队列(across transmit queue)传输的最大容量(max caps)和带宽预留。我们已经实现了一个接口来卸载 §7.3 中的端口级 QoS 策略。这消除了通过软件实现 QoS 的开销。
9.3 卸载 VFP 策略
许多 SDN 卸载策略以及实现目标 #7 的 SR-IOV 的卸载数据包分类,以便没有数据包通过 Host。我们发现这在服务器 NIC 上不切实际,因为在连续查找 10+ 表时,通常需要大容量 TCAM、很多 CPU 核或其他专用硬件。
然而,事实证明,卸载 §6 中定义的统一流(Unified Flows)要容易得多。这些是代表系统上每个连接的精确匹配流,因此可以通过大容量的哈希表来实现(通常是在廉价的 DRAM 中实现)。在此模型中,新 flow 的第一个数据包通过软件分类来确定 UF,然后将其卸载,以便后续数据包通过硬件路径。
我们使用此机制在我们的数据中心中启用 SR-IOV,并在我们部署在所有新 Azure 服务器上的自研硬件(custom hardware)上卸载 VFP 策略。我们的 VM VNIC 达到 25Gbps+ 线速,并且 Host CPU 消耗几乎为零,VNET 内的 e2e TCP 延迟低于 25μs。
9.4 性能

10、经验
自 2012 年以来,我们已经部署过 21 个 VFP release 版本。VFP 在全球 30 多个 region 的数百个数据中心的所有 Azure 服务器上运行,为数百万个 VM 的每秒 PB(petabits) 流量提供支持,并为 EB(exabytes) 级存储提供 LB。此外,我们还将 VFP 作为 Windows Server 2016 的一部分,以便为本地工作负载提供服务。
10.1 结果
我们已经实现了 §2 中的所有目标:
1. 我们拥有多个独立的控制器对 VFP 进行编程。新的控制器通过插入新的 layer 来部署新的 SDN 应用,而无需更改其他控制器。
2. 我们数据中心中的每个连接都被 VFP 视为有状态的 ———— 所有连接都通过有状态 ACL,并且许多连接都通过有状态 NAT。
3. 随着不断的实现更丰富的语义,VNET、LB 和其他策略的定义随着时间的推移而发生变化。其中大部分是 policy 变化,VFP 没有任何变化。
4. 我们已经向 VFP 推送了数十个无需重启的更新。
5. UFT 的引入极大地提高了 VFP 的性能,特别是对于有大量 layer 的场景。这帮助我们将服务器 NIC 扩展到 40G+ ,并能拥有更多 VM。
6. VFP 数据包分类算法在实际生产环境工作负载的情况下,比线性搜索速度提高了 1-2 个数量级。
7. 我们已成功将 VFP flow 卸载到流可编程硬件(flow-programmable hardware)并部署了 SR-IOV。
10.2 得到教训
在开发和支持 VFP 的 5 年多的时间里,我们学到了许多其他有价值的经验教训:
- L4 flow cache 就足够了 我们没有发现多层 flow(multi-tiered flow) 缓存(例如 OVS megaflows)的用途。有两个主要原因:完全在内核中实现使我们能够拥有更快的慢速路径,并且我们使用有状态 NAT 为每个 L4 flow 创建了一个 action,因此降低了三元流缓存(ternary flow cache)的实用性 。
- 从第一天开始就进行有状态的设计 对有状态连接的支持必须在 MAT 设计之初就进行各个方面的考虑。
- 分层至关重要 我们的一些策略可以作为 OpenFlow 表的特殊情况来实现,使用自定义 GOTO 将它们链接在一起,并使用单独的 inbound 和 outbound 表。然而,我们发现,我们的控制器需要清晰的分层语义,否则它们无法相对于其他控制器正确地撤销(reverse)其策略。
- GOTO 被认为是有害的:控制器开发人员将以解决问题所需的最简单的方式实施策略,但这可能与未来添加策略的控制器不兼容。我们需要保持警惕,不仅要提供分层,还要强制防止此类情况发生。与 OpenFlow 的 GOTO 表模型相比,我们认为这种分层实施并不是一种限制,而是能够让多控制器连续运行 4 年的关键。
- IaaS 无法处理停机时间(downtime):我们发现客户 IaaS 工作负载非常关心每个 VM 的正常运行时间,而不仅仅是整个服务的可用性。我们需要对所有更新进行设计以最大限度地减少停机时间。
- 可维护性(serviceability)设计:SSR(§8.2)是另一个设计点,它渗透到我们所有的逻辑中 ———— 为了定期更新 VFP 而不影响 VM,我们需要考虑任何新的 VFP 特性或 action type 的可维护性。
- 将配置下发协议(wire protocol)与数据面解耦:我们已经看到足够多的控制器/agent 使用不同的分布式系统模型实现配置下发协议(wire protocol)来支持 O(1M) 规模,因此我们相信将 VFPAPI 与任何配置下发协议(wire protocol)分开是 VFP 成功的关键。例如,带宽 meter rule 由控制器 push 策略,但 VNET 需要 VL2 样式的目录系统(agent 了解该策略来自于不同的控制器并采用 pull 拉取策略)才能进行扩展。
从架构上讲,将 “智能 agent” 视为分布式控制器应用的一部分而不是数据面的一部分将会有所帮助,并且我们认为 VFP 的 OS 级 API 是我们 SDN stack 中真正常见的南向 API(Southbound API),能够满足不同的应用。
- 不需要解决冲突:在 §2.3 中我们选择不解决控制器之间冲突,因为当我们强制在控制器之间执行干净的分层时,这从来都不是真正的问题。帮助控制器开发人员了解其策略能够产生的影响更为重要。
- 一切都是 action(Everything is an action):将 VL2 风格的 encap/decap 建模为 action 而不是将 tunnel 接口建模为 action。所有数据包只进行单张表查找 ———— 无需在报文通过 tunnel 接口前后遍历表。由此产生的 HT 语言将encap/decap 与 header 修改相结合,实现了单表硬件卸载。
- MTU 不是主要问题:最初有人担心使用 action 而不是 tunnel 接口会导致 MTU 问题。我们发现这不是一个真正的问题 ———— 物理网络通过巨帧 MTU 来支持封装,或者使用 TCP MSS(Maximum Segment Size)和非 TCP 帧分片(在不支持巨帧 MTU 的情况下)。
- MAT 规模:在我们的部署中,我们通常会看到多达 10-20 个 layer,每个 layer 内最多有数百个 group。我们发现每个 group 最多有 O(50k) 条 rule(当支持客户的分布式 BGP 路由时)。我们支持每个端口最多 500k 个并发 TCP 连接(当超过该值后状态跟踪将付出更高的代价)。
- 保持转发简单。:§7.1 描述了我们基于 MAC filter 的转发面。我们只是考虑基于 MAT 模型的可编程转发平面,但是,我们没有发现更复杂的转发策略场景。我们得出的结论是:可编程转发面对于云工作负载没有用处,因为 VM 需要一个声明性模型(declarative model)来创建具有已知 MAC 的 NIC。
- 端到端监控设计:尽管无法直接访问 VM,但确定 VM 的网络运行状况是一项挑战。我们发现使用数据包注入的带内(in-band)监控有许多用途,实现 VFP rule action 的自动响应器。我们使用这些来构建监控,跟踪 VM host 边界开始的端到端(E2E)路径。例如,我们为 VL2 VNET 实现了类似 Pingmesh 的监控。
- 商用 NIC 硬件并不适合 SDN:尽管 NIC 供应商多年来对使用 SR-IOV 卸载 SDN 策略很感兴趣,但我们还没有看到 NIC ASIC 供应商支持卸载我们策略的成功案例。相反,经常使用大型多核 NPU。我们使用自研 FPGA NIC 硬件在 Azure 中部署(ship) SR-IOV 特性,我们发现该方案延迟更低且效率更高。