ImagicұКјЗ - plus studio
ImagicұКјЗ - plus studio

ImagicұКјЗ
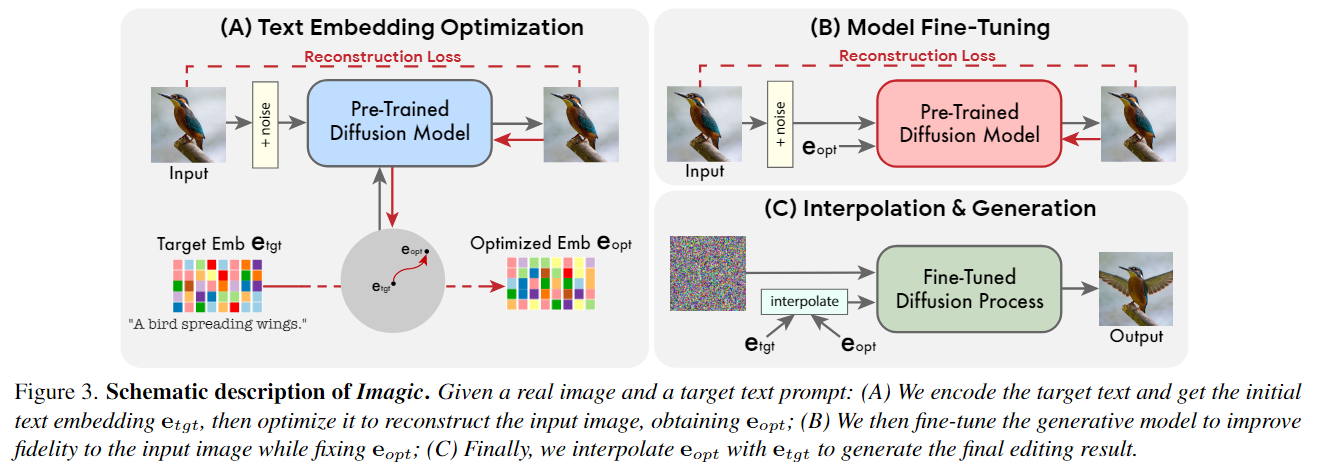
ПИЗ°өД№ӨЧчҙу¶аКэ·Ҫ·ЁДҝЗ°ҪцПЮУЪТФПВТ»ЦЦ:МШ¶ЁөДұајӯАаРН(АэИзЈ¬¶ФПуөюјУЈ¬СщКҪЧӘ»»)Ј¬әПіЙЙъіЙөДНјПсЈ¬»тРиТӘТ»ёц№ІН¬¶ФПуөД¶аёцКдИлНјПсЎЈОДХВЧчХЯХ№КҫБЛҪ«ёҙФУөД»щУЪОДұҫөДУпТеұајӯУҰУГУЪөҘёцХжКөНјПсөДДЬБҰЎЈУлЦ®З°өД№ӨЧчПа·ҙЈ¬ХвЖӘОДХВМбіцөД·Ҫ·ЁЦ»РиТӘТ»ёцКдИлНјПсәНТ»ёцДҝұкОДұҫ(ЛщРиөДұајӯ)ЎЈЛьЙъіЙТ»ёцУлКдИлНјПсәНДҝұкОДұҫТ»ЦВөДОДұҫЗ¶ИлЈ¬Н¬КұОўөчА©ЙўДЈРНТФІ¶»сМШ¶ЁУЪНјПсөДНв№ЫЎЈ
А©ЙўДЈРНКЗТ»ЦЦЗҝҙуөДЧоПИҪшөДЙъіЙДЈРНЈ¬ДЬ№»ҪшРРёЯЦКБҝөДНјПсәПіЙЎЈФЪЧФИ»УпСФОДұҫМбКҫөДМхјюПВЈ¬ЛьГЗДЬ№»ЙъіЙУлЛщЗлЗуөДОДұҫәЬәГөШ¶ФЖлөДНјПсЎЈФЪ№ӨЧчЦРК№УГЛьГЗАҙұајӯХжКөөДНјПсЈ¬¶шІ»КЗәПіЙРВөДНјПсЎЈОДХВЧчХЯНЁ№эТ»ёцјтөҘөД3ІҪ№эіМАҙКөПЦХвТ»өгЈ¬ИзНјЛщКҫ:КЧПИУЕ»ҜОДұҫЗ¶ИлЈ¬К№ЖдЙъіЙУлКдИлНјПсПаЛЖөДНјПсЎЈИ»ә󣬶ФФӨСөБ·өДЙъіЙА©ЙўДЈРН(ТФУЕ»ҜөДЗ¶ИлОӘМхјю)ҪшРРОўөчЈ¬ТФёьәГөШЦШҪЁКдИлНјПсЎЈЧоәуЈ¬ФЪДҝұкОДұҫЗ¶ИләНУЕ»ҜәуөДОДұҫЦ®јдҪшРРПЯРФІеЦөЈ¬өГөҪТ»ёцҪбәПБЛКдИлНјПсәНДҝұкОДұҫөДұнКҫЎЈИ»әуҪ«ХвЦЦұнКҫҙ«өЭёшҙшУРОўөчДЈРНөДЙъіЙА©Йў№эіМЈ¬КдіцЧоЦХұајӯөДНјПсЎЈ
ЧчХЯХвҪшТ»ІҪөГөҪБЛТ»ПоИЛАаёРЦӘЖА№АСРҫҝөДЦ§іЦЈ¬ФЪТ»ПоГыОӘTEdBench -ОДұҫұајӯ»щЧјөДРВ»щЧјІвКФЦРЈ¬ЖА·ЦХЯЗҝБТЗгПтУЪНјПс¶шІ»КЗЖдЛы·Ҫ·ЁЎЈ
·Ҫ·Ё
ЧчХЯҪ«Хыёц№эіМ·ЦіЙИэёцІҝ·Ц
- УЕ»ҜОДұҫЗ¶ИлЈ¬ТФФЪДҝұкОДұҫЗ¶ИлёҪҪьХТөҪУлёш¶ЁНјПсЧоЖҘЕдөДОДұҫЗ¶Ил
- ОўөчА©ЙўДЈРНЈ¬ТФёьәГөШЖҘЕдёш¶ЁөДНјПс
- ФЪУЕ»ҜөДЗ¶ИләНДҝұкОДұҫЗ¶ИлЦ®јдҪшРРПЯРФІеЦөЈ¬ТФХТөҪТ»ёцјИДЬҙпөҪКдИлНјПсөДұЈХж¶ИУЦДЬҙпөҪДҝұкОДұҫ¶ФЖлөДөгЎЈ
Text embedding optimization
ДҝұкОДұҫКЧПИНЁ№эОДұҫұаВлЖчЈ¬ЛьКдіцЖд¶ФУҰөДОДұҫЗ¶Ил\(\textbf{e}_{tgt}\in\mathbb{R}^{T\times d}\) Ј¬ЖдЦР\(T\)КЗёш¶ЁДҝұкОДұҫЦРөДұкјЗКэЈ¬\(d\)КЗұкјЗЗ¶ИлО¬КэЎЈИ»әу¶іҪбЙъіЙА©ЙўДЈРН\(f_\theta\)өД ІОКэЈ¬ІўК№УГ[[DDPM]]Дҝұк\[\mathcal{L}(\mathbf{x},\mathbf{e},\theta)=\mathbb{E}_{t,\epsilon}\left[\left\|\epsilon-f_{\theta}(\mathbf{x}_{t},t,\mathbf{e})\right\|_{2}^{2}\right]\]УЕ»ҜДҝұкОДұҫЗ¶Ил\(E_{tgt}\).ЖдЦР\(t\sim Uniform[1,T]\) , \(x_t\)КЗК№УГ\(\boldsymbol{\epsilon}{\sim}\mathcal{N}(0,\text{I})\)әН·ҪіМ1»сөГөДx(КдИлНјПс)өДФлЙщ°жұҫЈ¬\(\theta\)КЗФӨСөБ·өДА©ЙўДЈРНИЁЦШЎЈХвҪ«ІъЙъУлКдИлНјПсҫЎҝЙДЬЖҘЕдөДОДұҫЗ¶ИлЎЈЧчХЯФЛРРХвёц№эіМөДІҪЦиПа¶ФҪПЙЩЈ¬ТФұЈіЦҪУҪьЧоіхөДДҝұкОДұҫЗ¶ИлЈ¬»сөГ\(E_{opt}\)ЎЈХвЦЦҪУҪьРФФЪЗ¶ИлҝХјдЦРКөПЦБЛУРТвТеөДПЯРФІеЦөЈ¬¶ш¶ФУЪТЈФ¶өДЗ¶ИлІ»ұнПЦіцПЯРФРРОӘЎЈ

Model fine-tuning
ЗлЧўТвЈ¬өұҫӯ№эЙъіЙА©Йў№эіМКұЈ¬өГөҪөДУЕ»ҜЗ¶Ил\(E_{opt}\)ІўІ»Т»¶Ё»бөјЦВКдИлНјПс\(X_{exactly}\)Ј¬ТтОӘЧчХЯөД·Ҫ·ЁУЕ»ҜФЛРРБЛЙЩБҝІҪЦи(јыНј7ЦРөДЧуЙПҪЗНјПс)ЎЈТтҙЛЈ¬ФЪ·Ҫ·ЁөДөЪ¶юҪЧ¶ОЈ¬НЁ№эК№УГ№«КҪ2ЦРЛщКҫөДПаН¬ЛрК§әҜКэУЕ»ҜДЈРНІОКэ\(\theta\)АҙЛхРЎХвТ»ІоҫаЈ¬Н¬Кұ¶іҪбУЕ»ҜөДЗ¶ИлЎЈХвёц№эіМТЖ¶ҜДЈРНТФККУҰКдИлНјПс\(x\)ФЪөг\(E_{opt}\)ҙҰөДО»ЦГЎЈН¬КұЈ¬ОўөчөЧІгЙъіЙ·Ҫ·ЁЦРіцПЦөДИОәОёЁЦъА©ЙўДЈРНЈ¬АэИзі¬·ЦұжВКДЈРНЎЈЧчХЯУГПаН¬өДЦШ№№ЛрК§¶ФЛьГЗҪшРРОўөчЈ¬ө«ТФ\(E_{tgt}\)ОӘМхјюЈ¬ТтОӘ\(E_{opt}\)ҪцХл¶Ф»щұҫДЈРНҪшРРБЛУЕ»ҜЎЈХвР©ёЁЦъДЈРНөДУЕ»ҜИ·ұЈБЛұЈБф»щұҫ·ЦұжВКЦРІ»ҙжФЪөД\(x\)өДёЯЖөПёҪЪ
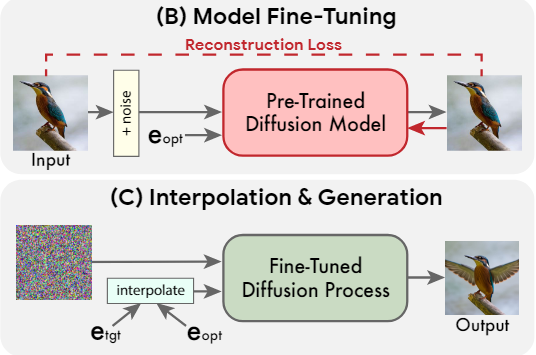
Text embedding interpolation
УЙУЪЙъіЙА©ЙўДЈРНұ»СөБ·ОӘФЪУЕ»ҜөДЗ¶Ил\(E_{opt}\)ҙҰНкИ«ЦШҪЁКдИлНјПсЈ¬ЧчХЯК№УГЛьАҙУҰУГЛщРиөДұајӯЈ¬ҙУ¶шСШЧЕДҝұкОДұҫЗ¶ИлөД·ҪПтЗ°ҪшЎЈёьХэКҪөШЛөЈ¬өЪИэҪЧ¶ОКЗ\(E_{tgt}\)әН\(E_{opt}\)Ц®јдөДјтөҘПЯРФІеЦөЎЈ¶ФУЪёш¶ЁөДі¬ІОКэ\(\eta\in[0,1]\)Ј¬ҫНөГөҪБЛ\[\bar{\mathbf{e}}=\eta\cdot\mathbf{e}_{tgt}+(1-\eta)\cdot\mathbf{e}_{opt}\] ХвКЗұнКҫЖЪНыұајӯНјПсөДЗ¶ИлЎЈИ»әуЈ¬УҰУГ»щҙЎЙъіЙА©Йў№эіМК№УГОўөчДЈРНЈ¬МхјюКЗ\(\bar{\mathbf{e}}\)ЎЈХвҪ«өјЦВөН·ЦұжВКөДұајӯНјПсЈ¬И»әуК№УГОўөчёЁЦъДЈРНЈ¬ТФДҝұкОДұҫОӘМхјюҪшРРі¬·ЦұжЎЈХвёцЙъіЙ№эіМКдіцЧоЦХөДёЯ·ЦұжВКұајӯНјПс\(x\)ЎЈ
КөСй
ПыИЪКөСй
ЧчХЯФЪПыИЪСРҫҝЦР·ўПЦОўөч»бЗҝЦЖТэИлАҙЧФКдИлНјПсөДПёҪЪЈ¬і¬іцБЛҪцУЕ»ҜөДЗ¶ИлЈ¬К№ЛыГЗөД·Ҫ°ёДЬ№»ұЈБфХвР©ПёҪЪУГУЪЦРјдөДҰЗЦөЈ¬ҙУ¶шКөПЦУпТеЙПУРТвТеөДПЯРФІеЦөЎЈТтҙЛЧчХЯөГіцҪбВЫЈ¬ДЈРНОўөч¶ФЖд·Ҫ·ЁөДіЙ№ҰЦБ№ШЦШТӘЎЈ
ЧчХЯіўКФБЛіўКФБЛОДұҫЗ¶ИлУЕ»ҜІҪЦиөДКэБҝЎЈЧчХЯНЁ№эКөСйұнГчНЁ№эҪПЙЩөДІҪЦиУЕ»ҜОДұҫЗ¶ИлҪ«ПЮЦЖДЈРНөДұајӯДЬБҰЈ¬¶шНЁ№эі¬№э100ІҪөДУЕ»ҜјёәхГ»УР¶оНвөДјЫЦөЎЈ
ҫЦПЮРФ
ЧчХЯФЪСРҫҝЦР·ўПЦБЛБҪЦЦ·Ҫ·ЁК§°ЬөДЗйҝцЈәТ»ЦЦКЗЛщРиұајӯөДР§№ы·ЗіЈОўИхЈЁИз№ыУРөД»°Ј©Ј¬ТтҙЛУлДҝұкОДұҫІ»М«ЖҘЕдЈ»БнТ»ЦЦКЗұајӯР§№ыәЬәГЈ¬ө«»бУ°ПмөҪНвІҝНјПсПёҪЪЈ¬ИзЛх·Е»тЙгПс»ъҪЗ¶ИЎЈЧчХЯФЪөЪ10ХЕНјЦР·ЦұрХ№КҫБЛХвБҪЦЦК§°ЬЗйҝцөДКҫАэЎЈөұұајӯР§№ыІ»№»ЗҝБТКұЈ¬ФцјУҰЗНЁіЈҝЙТФКөПЦЖЪНыөДҪб№ыЈ¬ө«ФЪЙЩКэЗйҝцПВ»бөјЦВФӯКјНјПсПёҪЪөДПФЦш¶ӘК§ЈЁ¶ФУЪЛщУРІвКФөДЛж»ъЦЦЧУЈ©ЎЈЦБУЪЛх·ЕәНЙгПс»ъҪЗ¶ИөДұд»ҜЈ¬ХвНЁіЈ·ўЙъФЪОТГЗҙУөНҰЗЦөЦрҪҘФцјУөҪҪПҙуЦөКұЈ¬ТтҙЛәЬДСұЬГвЎЈЧчХЯФЪёҪВјЦРХ№КҫБЛХвТ»өгЈ¬ІўФЪTEdBenchЦР°ьә¬БЛ¶оНвөДК§°Ь°ёАэЎЈХвР©ҫЦПЮРФҝЙДЬҝЙТФНЁ№эІ»Н¬өД·ҪКҪУЕ»ҜОДұҫЗ¶Ил»тА©ЙўДЈРНАҙ»әҪвЈ¬»тХЯАаЛЖУЪHertz etal.өДҪ»Іж№ШЧўҝШЦЖЎЈЧчХЯҪ«ХвЩѡПоБфёшОҙАҙөД№ӨЧчЎЈ

ҙЛНвЈ¬УЙУЪёГ·Ҫ·ЁТААөУЪФӨСөБ·өДОДұҫөҪНјПсА©ЙўДЈРНЈ¬ТтҙЛјМіРБЛДЈРНөДЙъіЙПЮЦЖәНЖ«јыЎЈТтҙЛЈ¬өұЛщРиұајӯЙжј°ЙъіЙөЧІгДЈРНөДК§°Ь°ёАэКұЈ¬»бІъЙъІ»ұШТӘөДОұПсЎЈАэИзЈ¬ImagenФЪИЛБі·ҪГжөДЙъіЙРФДЬІ»јС
ҪбВЫәНОҙАҙөД№ӨЧч
ЧчХЯИПОӘПВТ»ІҪөД№ӨЧчЦчТӘУРБҪёц·ҪГж - Т»КЗҪшТ»ІҪМбёЯЛг·Ё¶ФКдИлНјПсөДЧјИ·РФәН¶ФЙн·ЭөДұЈ»ӨЈ¬Н¬КұФцЗҝ¶ФЛж»ъЦЦЧУәНІеЦөІОКэ ҰЗ өДГфёРРФЈ» - ¶юКЗҝӘ·ўЧФ¶ҜСЎФсГҝёцЗлЗуұајӯөД ҰЗ ЦөөД·Ҫ·Ё
Йз»бУ°Пм·ҪГжЧчХЯФтИПОӘДЈРНИЭТЧКЬөҪ»щУЪОДұҫөДЙъіЙДЈРНөДЙз»бЖ«јыөДУ°ПмЈ¬ХвР©јјКхҝЙДЬұ»¶сТв·ҪУГУЪәПіЙРйјЩөДНјПсТФОуөј№ЫЦЪЎЈОӘБЛ»әҪвХвЦЦЗйҝцЈ¬РиТӘҪшТ»ІҪСРҫҝИзәОК¶ұрәПіЙұајӯ»тЙъіЙДЪИЭ
ұҫОД·ЦПнЧФ ЧчХЯёцИЛХҫөг/І©ҝН?З°НщІйҝҙ
ИзУРЗЦИЁЈ¬ЗлБӘПө cloudcommunity@tencent.com ЙҫіэЎЈ
ұҫОДІОУл?МЪС¶ФЖЧФГҪМе·ЦПнјЖ»®? Ј¬»¶УӯИИ°®РҙЧчөДДгТ»ЖрІОУлЈЎ