【SQL】Mysql中一条sql语句的执行过程

体系结构
先来看下MySQL的体系结构,下图是在MySQL官方网站上扒下来的,所以有很高的权威性和准确性。
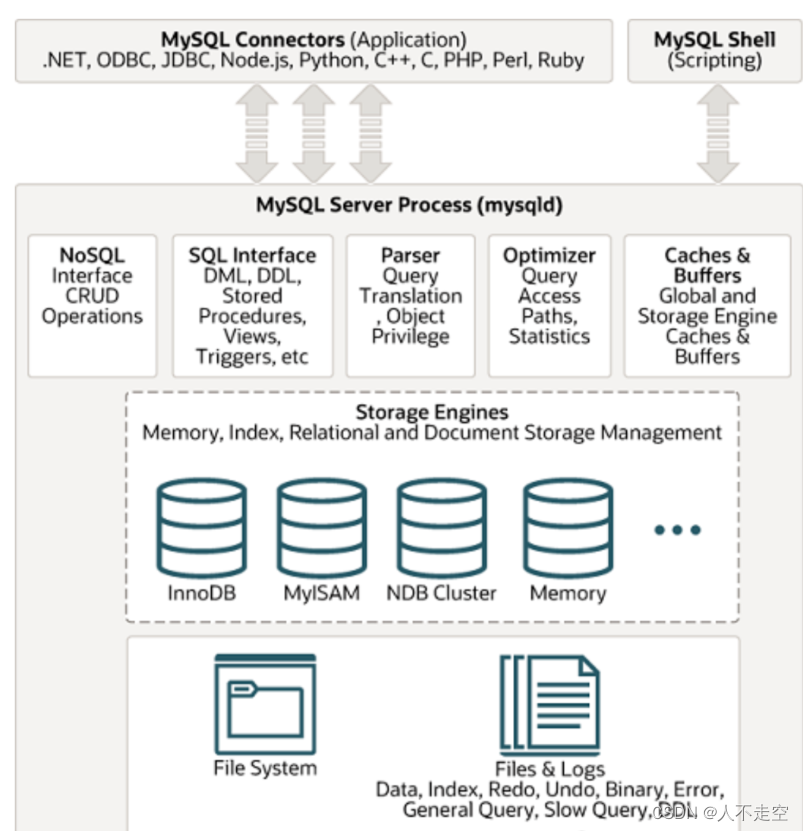
通过这张图,我们可以直观的看到MySQL的内部结构,包括连接器、缓存、解析器、优化器、存储引擎以及支持DDL、DML、存储过程、视图等功能的SQL接口。接下来,通过一条sql语句的执行来深入了解MySQL各个组件功能以及其作用。
一、SQL语句的执行流程
1、连接MySQL
通常我们会编写sql语句通过某个客户端来执行并且接受执行结果,比如命令行、JDBC、navicat。但是在执行前肯定需要先和MySQL服务成功建立连接,这个就是「连接器」的工作。
这里通过命令行的方式MySQL服务建立连接,命令如下:
命令连接的是本地的MySQL服务,在输入密码后,连接器会验证用户和密码,如果验证失败会给客户端响应拒绝访问的信息。
MySQL客户端连接
验证成功后,连接器会与该客户端成功建立连接并且读取该用户的权限,用户之后的操作都会基于权限进行控制。
那么用户名和密码以及权限在哪存储呢?
在MySQL中,除了开发人员创建的业务库,还有支撑自己运行的系统库,包括mysql、sys、perfermance_schema、information_schema,用户信息就存储在mysql这个库。
MySQL系统库
当然,MySQL的连接数也是有限制的,这个可以通过max_connections参数控制。
MySQL [mysql]> show variables like 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 1215 |
+-----------------+-------+也可以通过 show processlist 查看当前连接的客户端。
MySQL [mysql]> show processlist;
+------+------+-----------------+-------+---------+------+----------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+------+------+-----------------+-------+---------+------+----------+------------------+
| 1156 | root | 127.0.0.1:61223 | mysql | Query | 0 | starting | show processlist |
+------+------+-----------------+-------+---------+------+----------+------------------+2、查询缓存
当成功建立连接后,客户端就可以向MySQL服务发送sql语句了,「SQL接口」就像我们写的Controller一样会接收到sql语句,如果是 select 语句,将会去「缓存」中检索结果响应给客户端。
有些博客的说法是在解析后才查询缓存,这种说法是不严谨的,这里抛出官方的说明“如果收到相同的语句,服务器将从查询缓存中检索结果,而不是解析并再次执行该语句”
同时在该说明中可以看到“从MySQL 5.7.20开始,查询缓存已被弃用,并在MySQL 8.0中被删除。”这个注释。按照官方的说法是“缓存只适用于表数据不会经常变动的场景,如果表数据经常更新(很明显大多是这个场景),缓存命中率低下,加上频繁的维护缓存,有时候造成的问题比解决的问题还要多,缓存的功能就显得比较鸡肋了。”
3、解析SQL语句
在经过缓存后,就由「解析器」开始工作了,解析器的目的是检查sql语句是否正确以及将sql语句解析成MySQL能够理解的结构,也就是sql语法树。
像 select1 id from table1 这条sql语句就会在解析时报错,因为没有识别到 select 这个关键字(对列名、表名的检查和验证是在预处理阶段)。

SQL解析报错
而像 select id from table1 这条sql语句会被解析成下图:
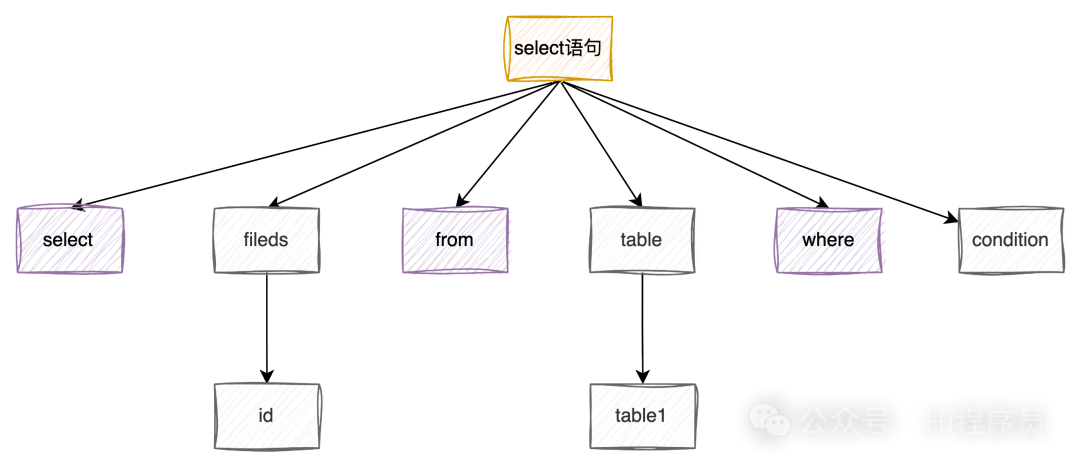
解析树
如果想了解具体的解析过程可以参考这篇博客
4、优化SQL语句
通过解析器生成sql语法树后就到了「优化器」阶段了,sql如何执行、使不使用索引、使用哪个索引都是在这个阶段处理,《MySQL优化的底层逻辑》中有写到,这里不过多赘述。
5、执行SQL语句
经过「优化器」后最终生成一个最优的执行计划交给「执行器」来执行,执行器通过调用「存储引擎」的接口来获取数据。
这里先不展开执行器与存储引擎的交互,后面的文章会详细阐述一下。
至此,一条查询语句的执行流程已经非常清晰了,同时也认识了MySQL的整个体系结构以及各组件的作用。最后用一张图来收尾本文的核心内容并做总结。
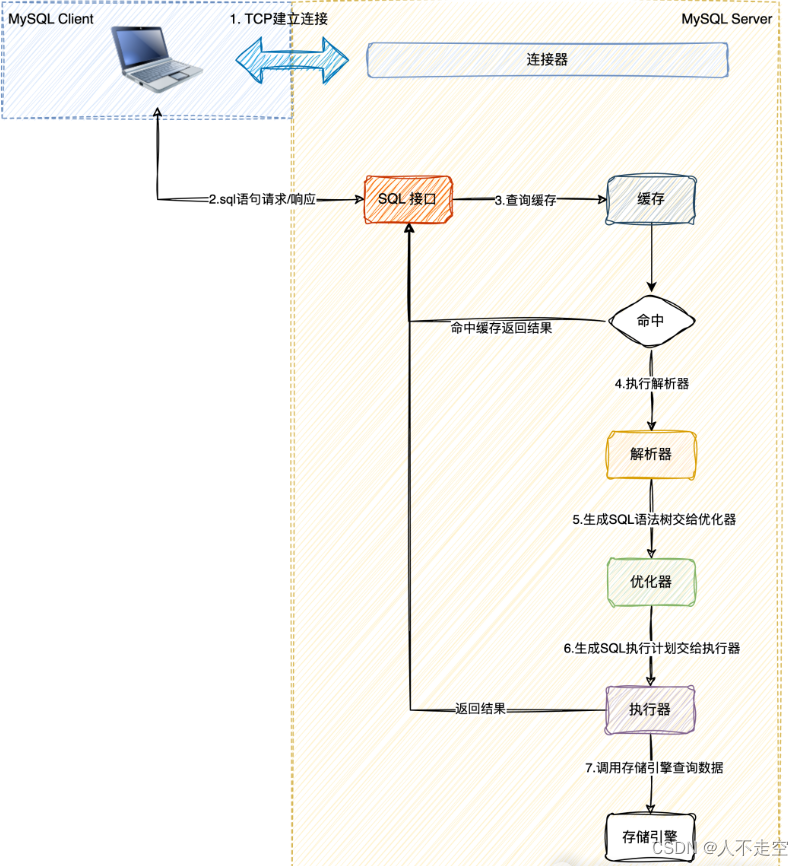
一条查询SQL语句的执行流程:
- 客户端通过连接器连接MySQL服务。
- 连接成功后向SQL接口发送SQL语句请求。
- SQL接口接收到SQL查询语句会先去缓存查询,如果命中返回给客户端,否则交给解析器。
- 解析器在拿到SQL语句后会判断语法是否正确,正确会生成sql语法树交给优化器,否则报错给客户端。
- 优化器会根据sql语法树生成一个最优的执行计划交给执行器执行。
- 执行器拿到执行计划调用存储引擎来获取数据响应给客户端。
- 完成!!!
二 语句分析
2.1 查询语句
说了以上这么多,那么究竟一条 sql 语句是如何执行的呢?其实我们的 sql 可以分为两种,一种是查询,一种是更新(增加,更新,删除)。我们先分析下查询语句,语句如下:
select * from tb_student A where A.age='18' and A.name=' 张三 ';结合上面的说明,我们分析下这个语句的执行流程:
- 先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限,在 MySQL8.0 版本以前,会先查询缓存,以这条 sql 语句为 key 在内存中查询是否有结果,如果有直接缓存,如果没有,执行下一步。
- 通过分析器进行词法分析,提取 sql 语句的关键元素,比如提取上面这个语句是查询 select,提取需要查询的表名为 tb_student,需要查询所有的列,查询条件是这个表的 id='1'。然后判断这个 sql 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步。
- 接下来就是优化器进行确定执行方案,上面的 sql 语句,可以有两种执行方案: a.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18。 b.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生。 那么优化器根据自己的优化算法进行选择执行效率最好的一个方案(优化器认为,有时候不一定最好)。那么确认了执行计划后就准备开始执行了。
- 进行权限校验,如果没有权限就会返回错误信息,如果有权限就会调用数据库引擎接口,返回引擎的执行结果。
2.2 更新语句
以上就是一条查询 sql 的执行流程,那么接下来我们看看一条更新语句如何执行的呢?sql 语句如下:
update tb_student A set A.age='19' where A.name=' 张三 ';我们来给张三修改下年龄,在实际数据库肯定不会设置年龄这个字段的,不然要被技术负责人打的。其实条语句也基本上会沿着上一个查询的流程走,只不过执行更新的时候肯定要记录日志啦,这就会引入日志模块了,MySQL 自带的日志模块式 binlog(归档日志) ,所有的存储引擎都可以使用,我们常用的 InnoDB 引擎还自带了一个日志模块 redo log(重做日志),我们就以 InnoDB 模式下来探讨这个语句的执行流程。流程如下:
- 先查询到张三这一条数据,如果有缓存,也是会用到缓存。
- 然后拿到查询的语句,把 age 改为 19,然后调用引擎 API 接口,写入这一行数据,InnoDB 引擎把数据保存在内存中,同时记录 redo log,此时 redo log 进入 prepare 状态,然后告诉执行器,执行完成了,随时可以提交。
- 执行器收到通知后记录 binlog,然后调用引擎接口,提交 redo log 为提交状态。
- 更新完成。
这里肯定有同学会问,为什么要用两个日志模块,用一个日志模块不行吗?
这是因为最开始 MySQL 并没与 InnoDB 引擎( InnoDB 引擎是其他公司以插件形式插入 MySQL 的) ,MySQL 自带的引擎是 MyISAM,但是我们知道 redo log 是 InnoDB 引擎特有的,其他存储引擎都没有,这就导致会没有 crash-safe 的能力(crash-safe 的能力即使数据库发生异常重启,之前提交的记录都不会丢失),binlog 日志只能用来归档。
并不是说只用一个日志模块不可以,只是 InnoDB 引擎就是通过 redo log 来支持事务的。那么,又会有同学问,我用两个日志模块,但是不要这么复杂行不行,为什么 redo log 要引入 prepare 预提交状态?这里我们用反证法来说明下为什么要这么做?
- 先写 redo log 直接提交,然后写 binlog,假设写完 redo log 后,机器挂了,binlog 日志没有被写入,那么机器重启后,这台机器会通过 redo log 恢复数据,但是这个时候 binlog 并没有记录该数据,后续进行机器备份的时候,就会丢失这一条数据,同时主从同步也会丢失这一条数据。
- 先写 binlog,然后写 redo log,假设写完了 binlog,机器异常重启了,由于没有 redo log,本机是无法恢复这一条记录的,但是 binlog 又有记录,那么和上面同样的道理,就会产生数据不一致的情况。
如果采用 redo log 两阶段提交的方式就不一样了,写完 binglog 后,然后再提交 redo log 就会防止出现上述的问题,从而保证了数据的一致性。那么问题来了,有没有一个极端的情况呢?假设 redo log 处于预提交状态,binglog 也已经写完了,这个时候发生了异常重启会怎么样呢? 这个就要依赖于 MySQL 的处理机制了,MySQL 的处理过程如下:
- 判断 redo log 是否完整,如果判断是完整的,就立即提交。
- 如果 redo log 只是预提交但不是 commit 状态,这个时候就会去判断 binlog 是否完整,如果完整就提交 redo log, 不完整就回滚事务。
这样就解决了数据一致性的问题。