卡内基梅隆大学提出CSC-Tracker|一种新的视觉分层表示范式,用于多目标跟踪
卡内基梅隆大学提出CSC-Tracker|一种新的视觉分层表示范式,用于多目标跟踪


Abstract
作者提出了一种新的视觉分层表示范式,用于多目标跟踪。通过关注目标的组合性视觉区域并与背景上下文信息进行对比,而不是仅依赖于如边界框这样的语义视觉线索,来区分目标更为有效。这种组合性语义上下文层次结构可以灵活地整合到不同的基于外观的多目标跟踪方法中。作者还提出了一种基于注意力的视觉特征模块,用于融合分层视觉表示。在多个多目标跟踪基准测试中,所提方法在基于 Query 的方法中取得了最先进的准确性和时间效率。
I Introduction
判别性视觉表示可以有助于在多目标跟踪中的基于外观的关联中避免不同目标之间的不匹配。作者提出了一种新的视觉表示范式,通过在层次结构中融合来自不同空间区域的视觉信息。作者认为,与仅使用边界框特征的传统范式相比,所提出的层次化视觉表示更具判别性,且不需要额外的标注。
在现代计算机视觉中,作者通常使用边界框或实例 Mask 来定义感兴趣物体的区域。由于被圈定的像素区域与某一物体类别相关联,这种表示通常被认为是语义的。然而,作者发现不仅仅是语义线索可以为视觉识别产生信息丰富的表示。作者可以从另外两个角度生成更具辨别力的视觉表示来定义物体的存在:组合性和上下文性。组合性线索描述了目标各部分的外观,对比线索描述了目标与其他物体的区别。例如,如图1所示,多只火烈鸟对作者来说几乎无法区分。但如果作者关注某些个体的可区分部分,比如翅膀上的红斑形状,作者就能轻松找出个体组合性。如果作者能够在时间步骤之间比较所有个体,作者还可以更有信心地区分实例对比。

因此,作者从三个角度构建了判别性的视觉表示:组合的、语义的、上下文的。在语义层面,例如一个紧密的边界框或者实例分割 Mask ,定义了具有特定视觉存在和语义概念的目标的占有区域。组合层面指出了目标实例的显著视觉区域,理想情况下,即使没有看到它的全身,作者也能追踪它。上下文信息有助于通过与背景像素和其他实例的对比来突出主体。例如,作者通常很难判断两个目标实例是否是同一个。然而,通常更容易判断一个实例比另一个更有可能是同一个。受到这一洞见的启发,作者 Proposal 通过一个三级层次来表示一个目标,即组合的、语义的和上下文的_。
作者采用了在视频多目标跟踪中提出的视觉层次结构,以避免不同目标之间的不匹配。作者发现,如何将来自各个层次的特征表示结合在一起至关重要。简单的堆叠或拼接它们并不能显著提高性能。相反,作者提出了一种基于注意力的模块,称为CSC-Attention,用于融合特征。CSC-Attention的核心思想是利用基于注意力的机制,通过与附近背景像素的对比,关注目标主体上的显著区域。通过融合特征来区分目标,作者构建的多目标跟踪器被称为CSC-Tracker。它通过一个 Transformer 进行全局关联,有效地跟踪随时间变化的物体。在多个多目标跟踪数据集上的实验表明,CSC-Tracker在基于 Transformer 的方法中达到了最先进的准确性,并且在抗噪性、时间效率以及计算经济性方面表现更佳。
作者的贡献有三个层面。首先,作者提出了一种视觉层次结构,在不增加额外标注的情况下,使视觉表示更具辨识性。其次,作者提出了一种基于注意力的模块,以利用层次特征。最后,作者构建了一个基于 Transformer 的追踪器,并使用这两项创新展示了其在基于外观的多目标追踪中的高准确性和时间效率。
II Related Works
深度视觉表示。 作者通常使用一个基础网络从一个特定区域提取特征,比如边界框,作为视觉感知的视觉表示。然而,边界框是有噪声的,因为它总是包含背景或其他目标实例的像素。为了更细粒度的视觉表示,常见的方法是使用预定义的区域,比如人头[36],[31]或人体关节[2, 44]。然而,这些选择需要额外的数据标注和指定的感知模块。在没有要求额外标注的情况下,多区域CNN [16] 提出将边界框箱的特征堆叠起来构建组合视觉表示。然而,这种范式不能生成实例级的判别表示,尽管它在语义级识别中显示出了有效性。此外,简单地堆叠特征不能强调判别的视觉区域。
层次视觉表示。 “层次视觉表示”一词已被不加选择地用于(1)来自同一区域不同分辨率的融合特征,例如CNN特征金字塔[24, 20]和(2)来自不同像素区域的融合特征。作者提出的层次视觉表示属于第二种类型。作者的想法受到David Marr对人体层次建模[26](计算、算法和实现)以及视觉认知层次[13](语义、句法、物理)的启发。与这两种视觉层次相比,作者提出的三级层次(组合、语义、上下文)专注于为多目标跟踪构建具有辨识力的视觉表示。在重新识别领域,一些先前的工作利用基于部分的层次特征构建视觉表示。但它们大多数通常需要额外的身体部位标注[32]。它们从不同区域融合特征的方式[14]在多目标跟踪案例中并不有效,在这些案例中,目标边界框区域的背景噪声通常更加严重,这是因为快速移动的目标和非静止的摄像机。
基于 Query 的多目标跟踪。 在Transformer [39] 原本应用于自然语言处理之后,它被引入到视觉感知 [7] 中。后来,提出了基于 Query 的多目标跟踪方法。早期方法 [35, 27] 在相邻时间步上局部关联目标。一些最近的方法在视频片段中全局关联目标 [55, 49]。GTR [55] 移除了位置编码等次要模块,提供了一个干净的 Baseline 来评估特征区分性。大多数最近的方法通过收集长时间内的信息来提高性能 [4, 49]。然而,一个缺点是对计算资源的极高要求,例如,需要 8xA100 GPUs [4]。相比之下,作者方法的改进来自于所提出的分层表示。作者展示了它在基于 Query 的方法中的最先进的有效性和效率。
III Method
在本节中,作者首先介绍CSC-Tracker的整体架构。然后描述所提出的CSC-Attention模块,以融合来自视觉层次结构中的特征。最后,作者详细阐述CSC-Tracker的训练和推理过程。
Overall Architecture
作者遵循时空全局关联范式[42, 55]来构建CSC-Tracker,其流程如图2所示。现在,作者解释它的三个阶段。符号表示依赖于一个一般的时间步
,这是最后一次完成轨迹的时间步。
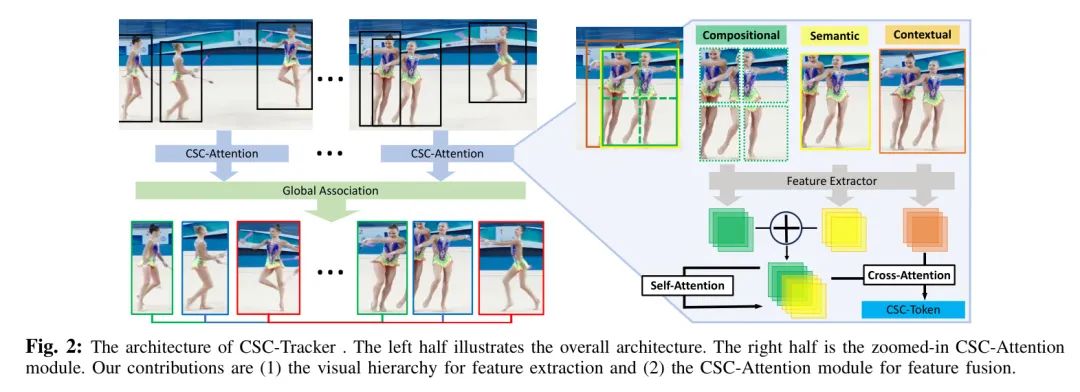
检测与特征提取。 对于一个由
帧组成的视频片段,即
,作者有相应的图像集
。给定一个检测器,作者可以并行地推导出所有帧上感兴趣目标的检测结果,记为
。
是检测的数量,而
(
) 是第
个检测,即
,被检测到的时间步。然后,作者通过一个基础网络提取每个检测到目标的特征。
通过CSC-Attention生成 Token 。 作者提出了CSC-Attention(下一节将详细说明)来生成特征 Token 。通过CSC-Attention,作者将获得目标CSC Token
,其中
是特征维度。如果作者旨在将新出现的检测与现有的轨迹相关联,作者也需要 Token 来表示现有的
轨迹,即
。与资源密集型的迭代 Query 传递[49]或长时间的特征缓冲[4]不同,作者利用轨迹上目标的CSC Token 来表示它。在时间范围
内,作者通过结合历史检测的CSC Token 来表示轨迹
,用 Token
。而所有轨迹 Token 是
。
全局关联。 通过交叉注意力机制,作者可以得到检测集合与某一路径之间的关联分数,即
,表示为
。实际上,因为作者的目标是关联所有
个路径和
个检测结果,作者同时对所有的目标 Query 和跟踪 Query 执行交叉注意力,即
。通过在时间视野内的
步骤上平均分数,作者得到了全局关联分数
。然后,作者通过softmax对同一时间步骤中路径与目标之间的关联分数进行归一化:
其中,二元指示函数
表示第
次检测和第
次检测是否在同一个时间步上。
是最终的全球关联矩阵。其维度为
,因为每次检测都可以与一个“空轨迹”相关联以开始新的跟踪。"空轨迹"的 Query 是通过从先前的未关联目标中随机抽取一个标记来表示的。此外,关联后,未关联的轨迹将被认为是相应帧上不存在。通过这种方式,作者可以并行地训练大量检测和轨迹集,并通过滑动窗口在线进行推理。作者使用统一格式的 Query 来表示目标和轨迹。因此,全局关联可以发生在检测之间,或者发生在检测与轨迹之间。这两种关联方案因此被实现为相同的,并共享所有模型模块。对于在线推理,作者将来自新到来时间步(
)的检测与现有轨迹进行关联。
CSC-Attention
现在,作者解释一种注意力机制,用以融合来自 复合语义上下文 视觉层次结构中的特征。作者将其命名为CSC-Attention(图2的右半部分)。
层级构建。 在构建层级结构时有不同的选择。为了与一个接近的 Baseline 方法 [16] 进行公平的比较,作者使用边界框箱(bins)来表示目标的部分。对于一个检测目标
,作者将边界框划分为
个箱(以适应GPU内存),形成一个身体部分的集合,记为
。另一方面,从全局范围来看,还有其他与
相互作用的目标,在关联阶段很可能会出现不匹配的情况。作者裁剪包含
以及所有与它有重叠的其他目标的联合区域。作者把这个联合区域记为
。到目前为止,作者已经得到了三元组
作为视觉层级结构的基础材料。
特征融合。 在这三个层次中,语义信息是定义视觉边界的必要条件。组成性(compositional)和上下文线索作为对最终表示判别性的增强。对于提取的区域
,作者使用共享特征提取器来获取它们的特点,即组成性、语义和上下文特征。为了融合这些特征,作者首先将组成性和语义特征进行拼接。然后,应用一个自注意力模块(self-attention module)以帮助关注判别性区域。最后,上下文特征和自注意力输出通过一个交叉注意力模块(cross-attention module)处理,以获得最终的CSC标记(CSC-tokens)。在发送到全局关联之前,这些标记会被投射到统一维度
上。
Training and Inference
训练。 作者通过最大化属于相同轨迹的检测之间的关联概率来训练关联模块,如公式1所示。作者同时在全球范围内对所有
帧采样视频片段计算关联得分。因此,目标转向如下:
其中,
是在
-th时间步与第
-th轨迹相关联的检测的真实索引。通过将此目标应用于所有轨迹,训练损失为:
另一方面,由于遮挡或目标消失,某些时间步长上也可能不存在轨迹。因此,方程式3包含了将轨迹与无检测(即“空”)关联的情况。空检测的标记是任意负样本。作者还有一个Triplet Loss,用来拉大负样本对之间的特征距离,与正样本对之间的特征距离相比较:
其中
是用于投射CNN特征的共享层,
是部分块的数量(在作者默认设置中
)。Att
是交叉注意力操作。
是用来控制正负对之间距离的边缘值。
和
(
)是语义和组合特征。
是联合区域
中背景区域的特征。作者通过将
在
区域内的像素设置为0来获得背景特征,并将 Mask 后的联合区域传递给共享特征编码器
。作者设计方程4以鼓励(1)特征编码器在关注目标上的显著和独特区域时,减少对背景区域的关注;(2)使联合框中背景区域的特征能够从前景物体中具有区分性。
其中
是一个可选的检测损失项。
推理。 作者通过使用步长为1的滑动窗口遍历视频来实现在线推理。在第一帧上,每个检测初始化一个轨迹。通过将检测与轨迹之间的检测-检测关联分数取平均,作者得到检测-轨迹关联分数,其负值作为关联分配中成本矩阵的条目。作者采用匈牙利匹配来确保一对一的映射。只有当关联分数高于
时,这对才能够关联。在随后帧上所有未关联的检测将开始新的轨迹。
IV Experiments
Experiment Setups
数据集。 在本文中,作者专注于行人跟踪,因为这是最流行的场景,并且有一系列先前的工作可用于比较关联准确性。在一些其他的跟踪数据集上,例如TAO [10],跟踪的主要难点在于检测阶段而不是关联。这导致在评估特征的可区分性时存在无法控制的数据噪声。为了有效评估视觉表示的可区分性,作者选择了三个数据集,即MOT17 [28],MOT20 [11]和DanceTrack [34]。DanceTrack具有最大的数据规模并提供了官方验证集。DanceTrack包含的大多数目标位于前景,但存在严重的遮挡、复杂的运动模式和相似的外观。在DanceTrack上,检测并不是瓶颈,而模型的外观辨识能力成为跟踪的关键。
评估指标。 CLEAR评估协议[3]在多目标跟踪评估中很受欢迎,但它偏向于单帧关联质量[23]。MOTA是CLEAR[3]协议的主要指标。但它也偏向于检测质量。为了更准确地感知关联准确性,作者强调最近提出的HOTA[23]指标集,该指标基于视频 Level 的真实值与预测值(默认为边界框形式)之间的关联计算。在指标集中,AssA强调关联性能,而DetA强调检测质量。HOTA是主要指标,因为它考虑了检测和关联质量。对于结果表格,作者使用下划线数字来表示整体最佳值,用粗体数字表示基于最佳 Query 的方法。所有基于 Query 的方法都用

列出。
实现方法。 作者采用ResNet-50 [17] 作为基础网络,该网络首先在Crowdhuman [31] 数据集上进行预训练。尽管先进的检测器 [50] 被证明是提升跟踪性能的关键,但作者希望作者的贡献更多来自于关联阶段的改进。因此,在MOT17上,作者遵循GTR [55] 的做法,使用经典的CenterNet [54, 53] 作为检测器以进行公平的比较。CenterNet检测器与基础网络一同在Crowdhuman上进行预训练。对于在MOT17上关联模块的微调,作者使用了MOT17-train和Crowdhuman的1:1混合数据。对于在MOT20上的评估,作者仅使用MOT20-train进行微调。对于DanceTrack,作者使用其官方训练集作为微调期间唯一的训练集。训练期间图像大小设置为1280
1280。测试时,较长边的图像大小为1560。在微调期间,也微调了检测Head。在MOT17/MOT20上的训练迭代设置为20k,在DanceTrack上为80k。作者使用BiFPN [37] 进行特征上采样。在 Transformer 实现方面,作者使用两层“线性+ReLU”作为投影层,以及一层编码器和解码器。作者使用AdamW [22] 优化器进行训练,其基础学习率设置为5e-5。视频片段的长度设置为
用于训练,以及
在滑动窗口中进行推理,以便与GTR [55] 进行公平的比较。作者将4
V100 GPU 作为默认的训练设备,但作者将看到,即便只使用一个RTX 3090 GPU 进行训练,作者的方法仍然能够实现可比较的性能。在MOT17或MOT20上的训练需要4小时,在DanceTrack上需要11小时。
Benchmark Results
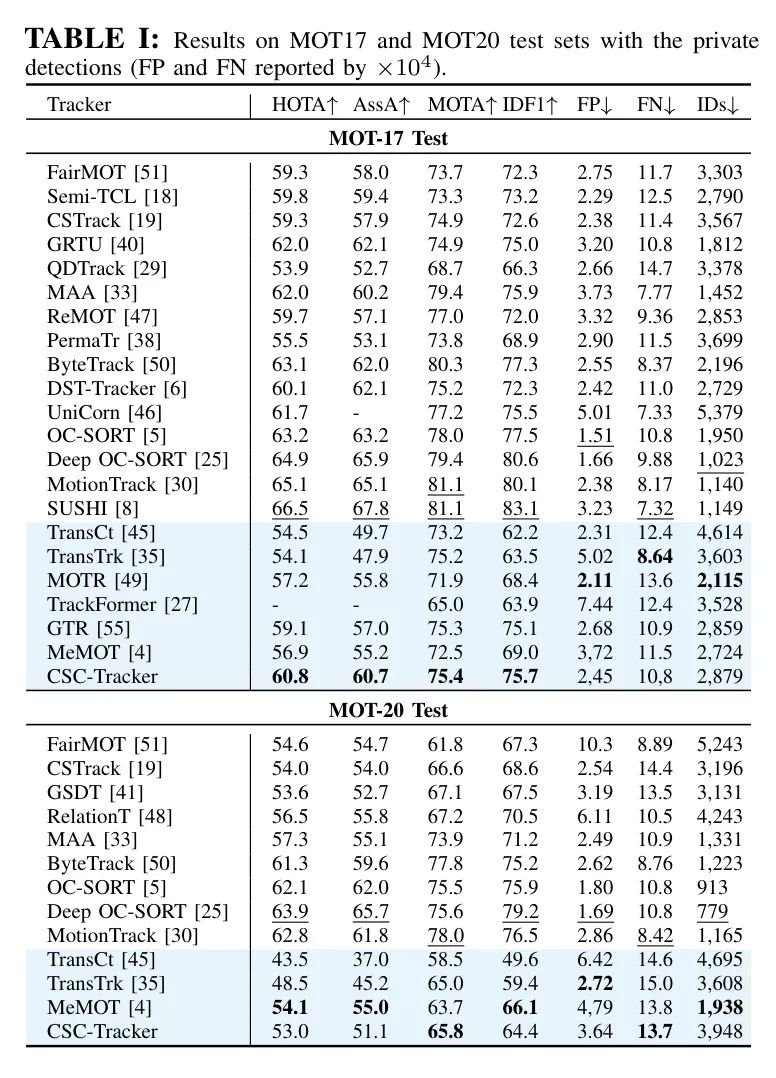
为了基准测试,作者只报告在线跟踪算法的性能,因为离线后处理[12, 52]会带来不公平的优势,并模糊关于视觉表示判别性的讨论。作者首先在表1中对MOT17和MOT20进行基准测试。在MOT17上,CSCTracker在基于 Transformer 的方法中获得了最高的HOTA和AssA得分。MOT20是一个更具挑战性的数据集,其中有拥挤的行人流。尽管CSC-Tracker在MOT17上的表现优于MeMOT[4],但在MOT20上的性能却较差。这可能与MOT20上的长时间严重且频繁的遮挡有关。为了解决这个问题,MeMOT中的历史目标外观的长时缓冲区显示出了有效性。然而,MeMOT需要8倍A100 GPU进行训练以支持如此长的缓冲区(22帧对比CSC-Tracker的8帧),并且使用COCO[21]数据集作为额外的预训练数据,这使得它并非完全对等的比较。
作者在表2中对DanceTrack-test也进行了基准测试。CSC-Tracker在基于Transformer的方法中达到了最先进的表现。同时,CSC-Tracker也显示出高级的时间效率。例如,在MOT17上进行训练,MOTR [49]需要8
V100 GPU的2.5天时间,而作者的 Proposal 方法仅在4
V100 GPU上需要4个小时。在相同的机器(V100 GPU)上,MOTR的推理速度为6.3FPS,而作者的方法为21.3FPS。与GTR [55]相比,CSC-Tracker在DanceTrack上实现的超越比在MOT17上更为显著。由于严格控制了其他变量和设计选择,这表明作者提出的视觉层次表示在遮挡更严重时比简单的边界框特征更为强大。

鉴于上述结果,作者已经证明轻量级设计的CSC-Tracker是基于Transformer的方法中的前沿技术。更重要的是,作者显示所提出的分层表示在判别性地区分物体方面更加有效和高效。CSC-Tracker为这一方法线上的未来研究建立了新的 Baseline 。常用的 Query 传播和迭代技术[27, 35, 49],可变形注意力[35, 4]和长时间特征缓冲[4]都可以与CSC-Tracker兼容集成。与整体前沿方法相比,例如OC-SORT[5]和SUSHI[8],CSC-Tracker的性能仍然显得略逊一筹。但它们的性能是在更先进的检测器,即YOLOX[15]上报告的。这使得公平比较难以呈现。但即便如此,SOTAs和基于Transformer的方法之间仍然存在性能差距。对于推理速度,在MOT17上给定检测结果,OC-SORT的运行速度为300FPS,SUSHI的运行速度为21FPS,而CSC-Tracker的运行速度为93FPS。
Ablation Study
作者现在消融了关键变量在设计实施中对CSC-Tracker性能的贡献。多目标跟踪领域中的许多先前研究遵循在MOT17 [28]上的CenterTrack [53]的做法,使用训练视频序列的后半部分作为验证集。然而,这使得在验证集上的消融研究变得不公平,因为训练集和验证集的数据分布如此接近,以至于在验证集上反映的性能差距可能在测试集上降低甚至消失。因此,作者转向DanceTrack [34] 进行消融研究,因为提供了一个独立的验证集。对于以下表格,作者用
突出显示作者默认的实施选择,这对应于先前在基准测试中报告的条目,以便与其他方法进行比较。
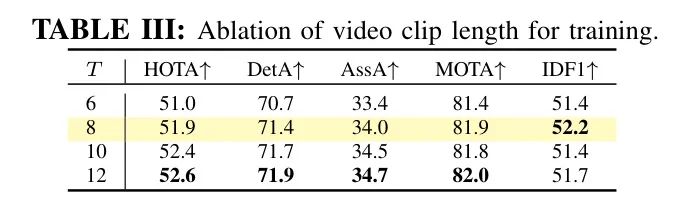
视频长度。 表3和IV分别展示了视频片段长度在训练和推理阶段的影响。结果表明,使用更长的视频片段训练关联模型可以持续提升性能。由于GPU内存的限制,作者无法将视频片段长度增加到超过12帧。相反,在推理阶段,滑动窗口的大小对性能没有显著影响。当窗口大小超出平台期后继续增加,甚至会对性能产生负面影响。

CSC层次结构中的三个层次。作者在表5中研究了CSC层次结构中每一层的贡献。在这里,仅语义信息对于使用基于边界框的 GT 标注进行评估是必要的,作者可以通过在生成CSC Token 时不添加相应的特征来操纵CSC层次结构中的另外两个层次。这里作者注意到,添加组合特征和上下文特征只会带来微小的计算开销,因为所需的自注意力和交叉注意力操作是高度并行的。与仅使用_语义_特征相比,CSC-Tracker通过更高的HOTA和AssA得分表明了显著的性能提升。同时,集成联合区域的特征比单独集成身体部位的特性更有效。这可能是因为目标主体与联合区域之间的交叉关注可以提供关键信息,以比较目标目标与其相邻目标,防止潜在的失配。另一方面,集成身体部位的特征无法明确避免与其他实例的失配。融合所有层次的特性被证明是最佳选择。

输入大小。 在表6中,作者尝试了不同的参数配置,包括输入剪辑长度和图像大小。仅使用一个RTX 3090 GPU进行训练和推理的情况下,其性能仍然可以与默认配置的4
V100 GPUs相媲美。这使得基于Transformer的方法所面临的计算障碍不再那么可怕了。

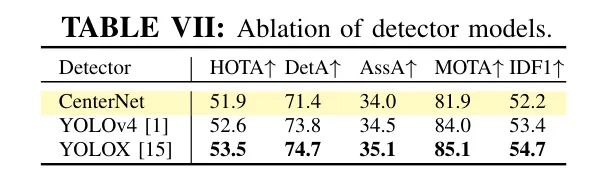
检测器。 实验的最高优先级是验证作者提出的表示的有效性,而不是在排行榜上竞速。为了与最近的 Baseline GTR [55] 进行公平的比较,作者遵循它选择CenterNet [54] 作为默认的检测器。但是CSC-Tracker是一种通过检测进行跟踪的方法,它可以灵活地与不同的检测器集成。作者在表7中比较了CenterNet与其他检测器,即YOLOv4 [1] 和YOLOX [15](被ByteTrack、OC-SORT、SUSHI等使用)。先进的检测器可以提升跟踪性能。
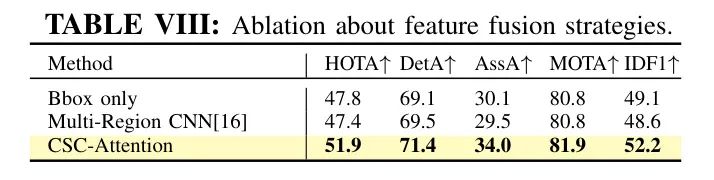
分层特征融合策略。 作为本文的主要贡献,作者提出了CSC-Attention模块来融合来自CSC层次结构中的特征。在一种朴素的方法中,多区域CNN采用了一种“分割与拼接”的策略来融合边界框内不同分区内的特征。作者在表8中与多区域CNN [16] 进行了比较。尽管多区域CNN在目标检测上相对于原始边界框表示取得了改进,但这种优势对于多目标跟踪不再明显。它与通过CSC-Attention融合的特征的性能差距甚至比单独使用边界框还要大。这个实验表明了所提出的三层层次结构的有效性,以及使用所提出的CSC-Attention模块进行融合的有效性。
Robustness to Detection Noise
在实施了部分区域(组合)特征后,作者期望CSC-Tracker在面对检测中的噪声时展现出更好的鲁棒性。这种直觉是基于,即使边界框不够精确,只要能够识别出一个独特的部分,模型就应能够持续跟踪目标。为了验证这一点,作者在检测位置中加入噪声,并观察它对跟踪性能的影响。作者通过随机移动和随机调整大小来添加噪声。对于随机移动,作者有25%的概率将边界框独立地向四个方向移动,移动的步长是取值范围在
中的一个随机值,其中
是边界框的宽度或高度。作者独立地用比例
和
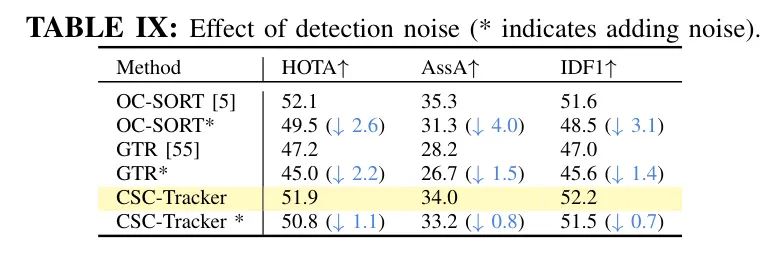
调整边界框的宽度或高度,这两个比例都是在[0.9, 1.1]范围内的随机值。在Dancetrack-val上的结果展示在表9中。与基于运动的方法 Baseline OC-SORT和仅基于全框的 Baseline GTR相比,CSC-Tracker如预期那样,展现了对检测噪声更好的鲁棒性。
Time Efficiency
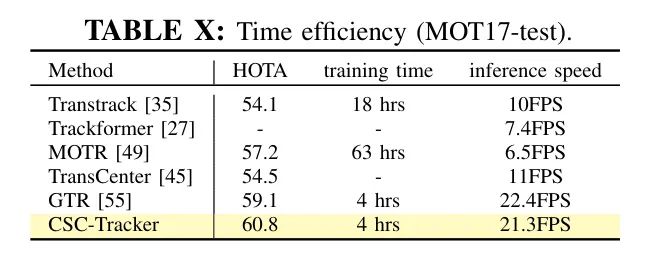
时间效率是基于 Query 方法的一个瓶颈,尤其是对于那些使用图网络[9],长历史缓冲区[4]或时间聚合[49]的方法。在收集了报告时间效率或开源实现的方法后,作者在MOT17上通过默认设置,在表10中报告了所需的训练时间和推理速度。速度在Nvidia V100 GPU上进行测试,训练时间在4xV100 GPUs上进行评估。CSC-Tracker在训练时间和推理速度方面都达到了最佳的时效性之一,同时保持了最佳的准确性。
V Conclusion
在本文中,作者提出通过一个结合不同视觉线索来区分目标的_组合语义上下文_视觉层次结构来构建判别性视觉表示。为了充分利用它们,作者提出了CSC-Attention来收集和融合视觉特征。这两点是本文的主要贡献。作者已经证明了它们之间的联系能够显示出强大的能力。这些设计被整合到CSC-Tracker中,用于多目标跟踪。在多个数据集上的结果表明了其效率和有效性。作者希望本文的研究能为目标的视觉表示提供新的知识,并为解决多目标跟踪问题提供一个先进的基准模型。该方法对检测噪声也更具鲁棒性,且计算经济。
参考
[1].Multi-Object Tracking by Hierarchical Visual Representations.