AAAI 2024 | 深度引导的快速鲁棒点云融合的稀疏 NeRF
AAAI 2024 | 深度引导的快速鲁棒点云融合的稀疏 NeRF

题目:Depth-Guided Robust and Fast Point Cloud Fusion NeRF for Sparse Input Views 作者:Shuai Guo, Qiuwen Wang, Yijie Gao, Rong Xie and Li Song(SJTU MediaLab) 来源:AAAI 2024 论文链接:https://arxiv.org/abs/2403.02063 内容整理:郭帅 本文在神经辐射场的框架中提出了一种新的点云表示方式,并且首次将点云表示、点云融合与神经辐射场相结合,帮助解决深度引导的神经辐射场经常面临的深度值不准确、引导效果差的问题。实验结表明,与其他稀疏输入的NeRF相比,我们的方法具有更好的合成效果,更高的时间效率,和更小的模型。
引言
具有稀疏输入视图的新视角合成方法对于AR/VR和自动驾驶等实际应用非常重要。大量该领域的工作已经将深度信息集成到用于稀疏输入合成的NeRF中,利用深度先验协助几何和空间理解。然而,大多数现有的工作往往忽略了深度图的不准确性,或者只进行了粗糙处理,限制了合成效果。此外,现有的深度感知NeRF很少使用深度信息来创建更快的NeRF,总体时间效率较低。为了应对上述问题,引入了一种针对稀疏输入视图量身定制的深度引导鲁棒快速点云融合NeRF。这是点云融合与NeRF体积渲染的首次集成。具体来说,受TensoRF的启发,将辐射场视为一个的特征体素网格,由一系列向量和矩阵来描述,这些向量和矩阵沿着各自的坐标轴分别表示场景外观和几何结构。特征网格可以自然地被视为4D张量,其中其三个模式对应于网格的XYZ轴,第四个模式表示特征通道维度。利用稀疏输入RGB-D图像和相机参数,我们将每个输入视图的2D像素映射到3D空间,以生成每个视图的点云。随后,将深度值转换为密度,并利用两组不同的矩阵和向量将深度和颜色信息编码到体素网格中。可以从特征中解码体积密度和视图相关颜色,从而促进体积辐射场渲染。聚合来自每个输入视图的点云,以组合整个场景的融合点云。每个体素通过参考这个融合的点云来确定其在场景中的密度和外观。
本文的主要贡献如下:
- 首次提出了一种用于稀疏输入视角的深度引导鲁棒快速点云融合NeRF,最大限度地减少了不准确深度值的影响;
- 提供了NeRF框架下的点云表示方法,是首个与点云融合的NeRF模型;
- 与同类方法相比,提高了时间效率,减小了模型,并提供了更好的合成结果。
方法
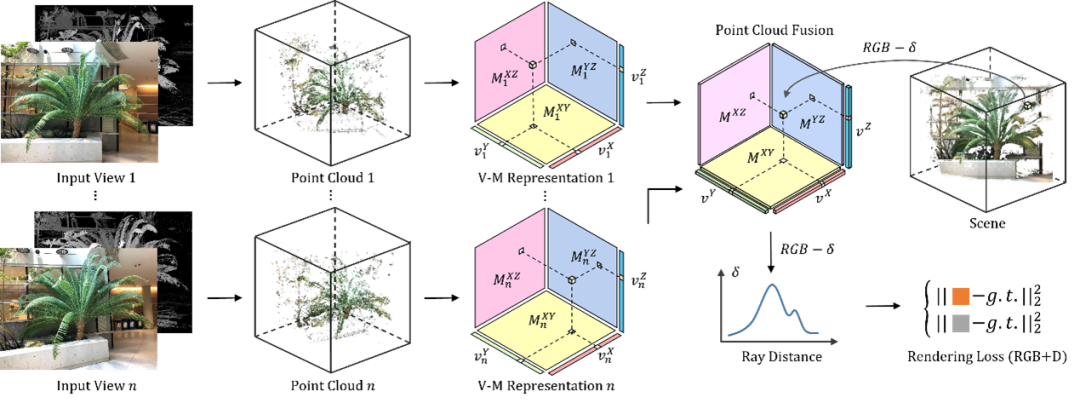
图1. 模型整体结构图
场景和点云表示
用一个3D 网格
来表示场景,用
和
表示体密度和颜色,
是颜色特征的通道数。用 V-M 分解的方式,
可以表示为:
而
可以表示为:
这里所有的
都是可学习的二维矩阵,所有的
都是可学习的一维向量。基于这种场景描述方式,任一三维点的
和
都可以通过下式计算:
为了给每个输入视角构建一个点云,我们将深度值映射到 NDC 空间,以确保所有可见位置在预定的三次空间内归一化并表示。随后,我们将输入视图的所有像素映射到3D空间以生成点云。所有 3D 点都向
,
,
上和
,
,
上进行投影,被任意3D点投影覆盖的矩阵和向量的元素设置为1,而所有其他元素被指定值0。这种方法可以有效地指示几何体网格中存在点,进而作为点云体积密度的表示方法。与此类似,把所有3D点向
,
,
进行投影,这些矩阵的元素的值分别设置为覆盖该元素的3D点的R, G, B值,
,
,
都赋随机值,进而作为点云颜色的表示方式。
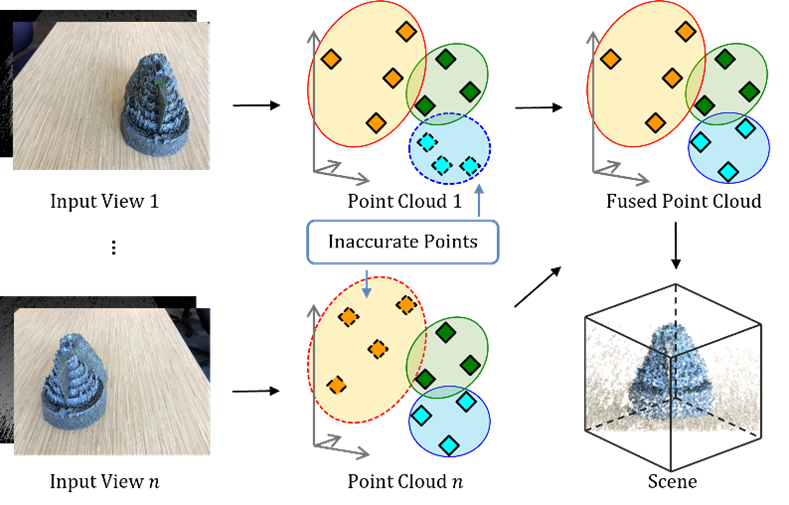
图2. 点云构建和融合
这提供了点云的粗略表示。在训练过程中,点云的表示将被细化,克服不准确的深度值的影响,并且将被融合在一起以表征整个场景。
优化
模型的损失函数包括常见的RGB损失函数,深度损失函数和L1正则化项:
正则化项的定义为:
正则化损失用于鼓励张量因子参数的稀疏性。此外为了实现由粗到细的重建,3D网格的大小在训练过程中也会进行若干次放大。集成了一个用于特征解码的两层MLP,该MLP采用我们的张量因子提取的观察方向和特征,而不包含XYZ位置。对于神经特征,采用了具有两个FC层的紧凑MLP,每个FC层具有128个通道,并通过ReLU激活函数进行增强。还使用MLP中的Sin和Cos函数对视角方向和特征进行编码。
实验
本文在LLFF,DTU等数据集上进行了实验,对于每个场景,选择包含2、3或4个训练视图的子集进行测试。深度图是根据数据集提供的相机参数,使用COLMAP生成的。
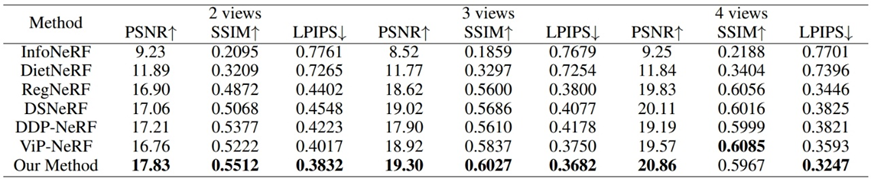
表1. LLFF数据集上的客观指标比较

图3. LLFF数据集上采用两个输入视角进行合成的效果对比
表1和图3展示了LLFF数据集上两个输入视角合成效果的比较。可以看到,DSNeRF和DDP-NeRF的预测显示出明显的浮动伪影(蓝色箭头)。RegNeRF努力捕捉骨骼结构中更精细的细节(品红色箭头)。相比之下,本文方法显著减少了这些缺陷。在第二个和第四个例子中,可以看到DDP-NeRF合成结果的颜色变化(青色箭头)。本文模型的合成结果没有上述伪影。

图4. DTU数据集上采用两个输入视角的合成效果对比
图4展示了DTU数据集上采用两个输入视角的合成效果对比。DDP-NeRF和ViP-NeRF的合成结果显示明显的浮云伪影。本文方法产生了更逼真、更自然的新视角图像。
分析
在本文的模型中,3D空间中的每个体素通过参考整个场景的点云来确定其密度和外观。尽管点云的初始表示是基本的和不精确的,但融合和训练过程会细化深度值的不精确性,或者用其他视图的值替换它们。点云的这种新表示也可以作为优化的有效初始化。
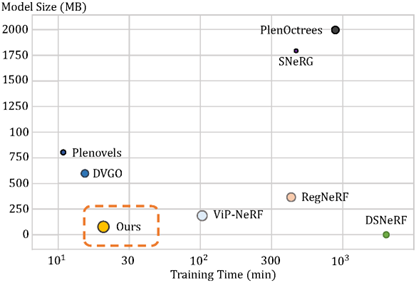
图5. 渲染质量(PSNR)和模型大小比较(点的大小对应于PNSR)
如图5所示,本文方法具有较小的模型大小和更少的重建时间,原因是使用一些向量和矩阵有效地呈现了为每个输入视图构建的点云。例如,对于具有 通道(加上一个密度通道)的 特征网格,密集网格中的参数总数为756M,而本文方法所使用的参数数量仅约为0.36M(四个视图输入),可以实现大约0.05%的压缩率。

图6. 输入输出深度图质量对比
如图6所示,本文方法输出的深度图质量远高于输入的深度图质量,对于不准确的深度值和空洞能够进行有效优化。