【大厂面试演练】听说你很懂ZooKeeper?那我考考你
原创【大厂面试演练】听说你很懂ZooKeeper?那我考考你
原创

面试官:咳咳咳,看你简历写了精通ZooKeeper,那我就随便考考你吧
面试官:不用慌尽管说,错了也没关系?。。。
每日分享大厂面试演练,感兴趣就关注我吧??
面试官:知道ZooKeeper有什么应用场景吗
嗯嗯,主要有这几种。
- 数据发布/订阅。可以用来实现配置中心
- 命名服务。类似于UUID,可以生成全局唯一的ID
- 集群管理。每一个服务器是一个子节点,可以用来检测到集群中机器的上/下线情况
- 分布式锁
面试官思考中…
面试官:你挑一个你比较熟悉的场景讲讲
嗯嗯好的,那我讲下分布式锁。
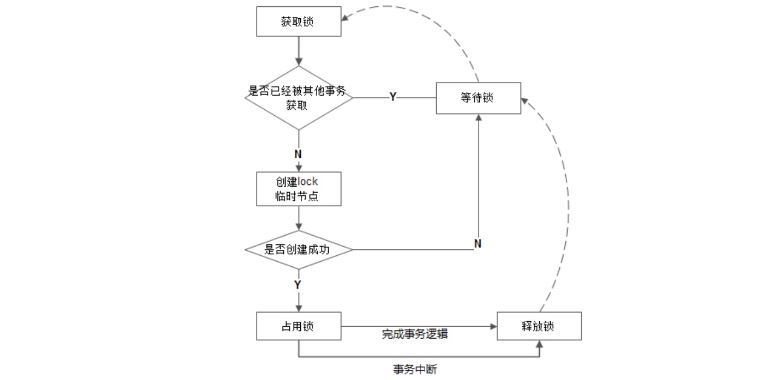
是这样的,ZooKeep的获取锁时会在/exclusive_lock节点下创建子节点,如果创建成功则获得锁。如果失败,则客户端会在该节点注册一个子节点变更的Watcher监听。
同样,释放锁则删除该子节点,此时Watcher监听就会通知客户端可以重新获取了。
面试官思考中…
面试官:你说的是排他锁,共享锁呢
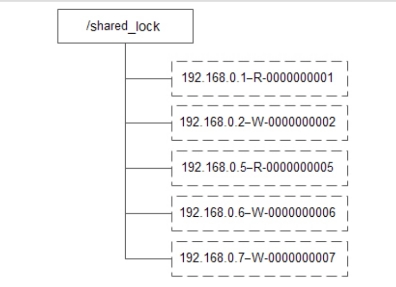
好的面试官。共享锁也是类似的场景。
每次读、写请求同样是创建子节点,是一个类似于“/shared_lock/Hostname-请求类型-序号”的临时顺序节点。
接着会获取子节点列表,同时注册Watcher监听。
- 获取读锁的话,如果前面比自己小的序号没有写请求,则可以读
- 获取写锁的话,只有在自己是序号最小的情况下,才可以读
而共享锁的释放锁和排他锁都是一样的。
面试官:emmmm有没听说过共享锁的羊群效应
噢噢知道的面试官,这个问题主要是出现在集群规模比较大的场景下。
其实共享锁的特别之处,在于每次读、写请求都要注册Watcher监听来获取子节点列表,特别是数量更多的读请求。
子节点列表每次变动都要通知所有的服务器客户端,造成了短时间大量的事件通知,给ZooKeeper带来很大性能消耗。
面试官思考中…
面试官:那怎么解决呢
我认为要两方面来看吧。
首先我上面说的共享锁实现方式如果在集群不大的情况下是可行的,而且他实现简单实用。而如果在集群规模大的场景下,可以这样改进。
读、写请求首先获取子节点列表,但都不注册Watcher监听。
- 读请求:只向比自己序号小的最后一个写请求节点注册Watcher监听
- 写请求:只向比自己序号小的最后一个节点注册Watcher监听
这样就可以避免羊群效应,主要是从监听子节点列表,改进为只监听某个子节点。
面试官心想,还不错嘛..
面试官:Kafka应用场景呢,知道Kafka是怎么利用ZooKeeper吗
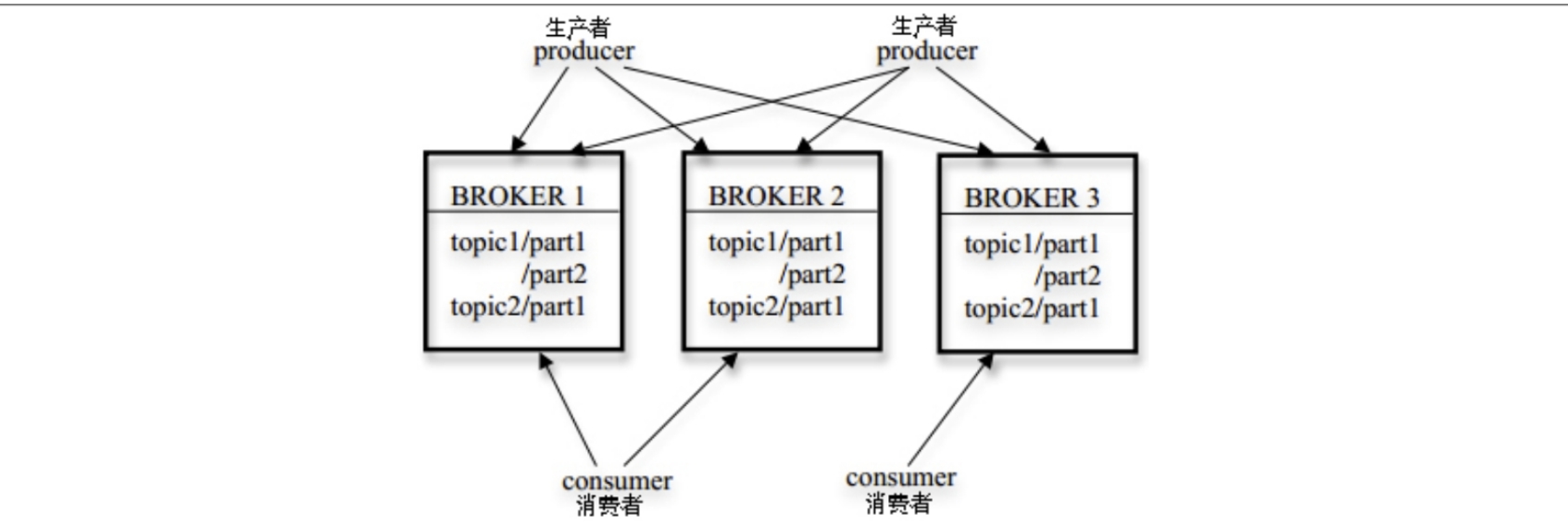
嗯嗯好的,我了解到的主要有3方面。
- 使用ZooKeeper来对所有Broker服务器、Topic进行管理
Broker启动后都会到ZooKeeper上创建属于自己的临时节点,其节点路径为/broker/ids/0…N,注册Topic节点也是一样。
- 另外在Kafka生产者负载均衡方面
Kafka消息生产者会通过监听Broker节点列表,负载均衡地分发到某一个Broker。
- 而在Kafka防消费重复消费方面
消费者消费消息后,都会在消息分区写入临时节点,代表该消息已消费。
面试官思考中…
面试官:你刚刚说到Kafka生产者负载均衡,那消费者负载均衡知道吗
哦哦说欠了,消费者负载均衡有两方面。
- 一方面,每一个消费者服务器都会在ZooKeeper创建消费者节点。当有新消息时,Kafka就可以通过ZooKeeper的消费者节点列表负载均衡地通知某个消费者
- 另一方面,Kafa将一个Topic分成了多个分区,多个分区由不同的Brocker处理,这是实现对Brocker的负载均衡
面试官抓抓脑袋,继续看你的简历......得想想考点你不懂的?
未完待续。。。。。。
好了,今天的分享就先到这,我们下期继续。
创作不易,不妨点赞、收藏、关注支持一下,各位的支持就是我创作的最大动力??
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。