配置Hive实验环境(一)内嵌部署
原创
hive setup with derby
1. 安装JDK 8
yum -y install java-1.8.0-openjdk*2. 安装配置Hadoop
2.1 下载压缩档
cd ~ # 如果切到别的目录了就先切换到家目录
# wget "http://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz" --no-check-certificate
wget https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-2.10.2/hadoop-2.10.2.tar.gz2.2 解压缩
假设 /opt 是所有程序的安装路径
tar -xzvf ~/hadoop-2.10.2.tar.gz -C /opt
mv /opt/hadoop-2.10.2 /opt/hadoop # 重命名2.3 配置SSH
ssh-keygen -t rsa #按回车,密码留空不用输入passwd # 重置密码,如果记得密码的话可以跳过这个命令ssh-copy-id localhost
# 输入yes进入下一步,输入刚刚设定的密码设置完毕后,ssh localhost 不提示输入密码就表示已经设置好了公钥验证登陆
2.3 设置环境变量
# export JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.402.b06-1.el7_9.x86_64"
echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile
echo "export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.402.b06-1.el7_9.x86_64" >> /opt/hadoop/etc/hadoop/yarn-env.sh
echo "export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.402.b06-1.el7_9.x86_64" >> /opt/hadoop/etc/hadoop/hadoop-env.sh2.4 使用vi编辑配置文件
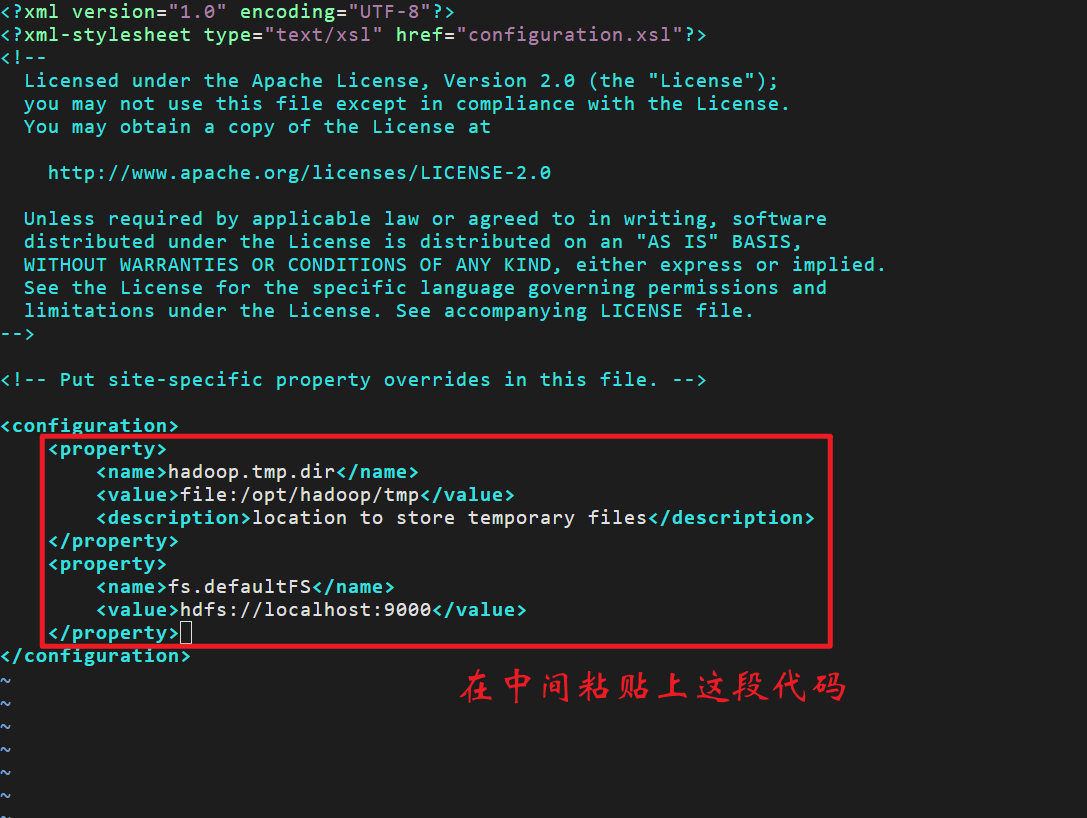
vim /opt/hadoop/etc/hadoop/core-site.xml按
G定位光标到最后一行,然后按k上移一行,然后按小写字母o新建一行开始粘贴:
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
<description>location to store temporary files</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>按esc输入:wq保存(没有进到底行模式的话多按几次冒号)
参考效果:
按ESC会光标变成空心,就用鼠标点一下光标附近,让光标变成实心就可以按冒号了,注意使用英文冒号 如果不小心粘错了,舍弃掉修改(按
esc输入:q!按回车)然后重新用vi打开
第二个文件的配置方式相同:
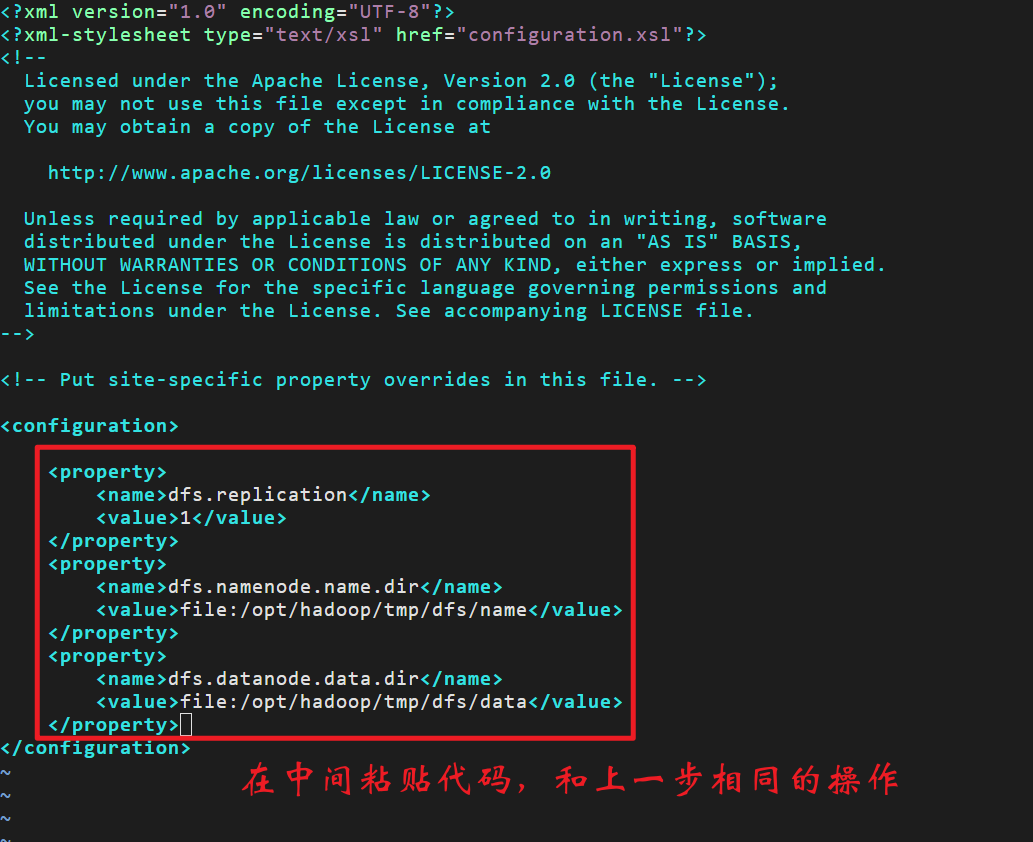
vim /opt/hadoop/etc/hadoop/hdfs-site.xml按
G定位光标到最后一行,然后按k上移一行,然后按小写字母o新建一行开始粘贴:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/tmp/dfs/data</value>
</property>按esc输入:wq保存(没有进到底行模式的话多按几次冒号)
2.5 启动HDFS
初始化HDFS名称节点:
hdfs namenode -format这一步如果出现异常了就重复一下上面的步骤,看看是否有漏掉的过程,成功执行的话是不会出现java exception之类的提示的
启动必要的进程:
start-dfs.sh
start-yarn.shjps 查看进程:

2.6 在HDFS中创建目录
hadoop fs -mkdir /tmp
hadoop fs -mkdir -p /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse3. 安装配置Hive
3.1 下载解压
wget https://mirrors.bfsu.edu.cn/apache/hive/hive-2.3.9/apache-hive-2.3.9-bin.tar.gz
tar -xzvf apache-hive-2.3.9-bin.tar.gz -C /opt/
mv /opt/apache-hive-2.3.9-bin/ /opt/hive3.2 设置环境变量
echo 'export HIVE_HOME=/opt/hive/' >> /etc/profile
echo 'export PATH=$PATH:$HIVE_HOME/bin' >> /etc/profile
source /etc/profile
echo "export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.402.b06-1.el7_9.x86_64" >> /opt/hive/conf/hive-env.sh运行 hive --version 命令验证程序是否已安装
3.3 使用vi修改配置文件
cd /opt/hive
cp conf/hive-default.xml.template conf/hive-site.xml
vi conf/hive-site.xml按冒号后输入命令%s/\${system:java.io.tmpdir}/\/tmp\/hive/g 完成查找替换
再次按冒号后输入命令%s/\${system:user.name}/root/g
3.4 初始化、连接
# 初始化元数据库:
schematool -initSchema -dbType derby成功后会提示completed:

# 新建连接:
beeline -u jdbc:hive2:// -n scott -p tiger使用SQL语法查看已有的数据库:
show databases;4. 使用数据库
create database if not exists z3;
-- 查看已有的数据库:
show databases;
-- 查看某个数据库的信息:
desc database z3; -- 或者 desc schema z3;
-- 删除某个数据库:
drop database z3;建库建表:
create database if not exists z3;
create table if not exists z3.mate(
id int,
name string,
age int,
gender string,
birthday string
) comment '张三用来记录朋友生日的表'
row format delimited fields terminated by ',';查看表:
use z3;
-- 查看z3库内的表:
show tables;
-- 查看某个表的表结构:
desc mate;原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录