kafka-Пы·СХЯЖ«ТЖБү__consumer_offsets_Па№ШҢвОц
ФөөОДХВ/өр°ё/әәКхөуЕӘ
·ұІә
kafka-Пы·СХЯЖ«ТЖБү__consumer_offsets_Па№ШҢвОц
Фөө
Get
·ұІәУЪ 2024-03-10 20:33:45
·ұІәУЪ 2024-03-10 20:33:45
https://blog.csdn.net/z69183787/article/details/109810468
ФЪkafkaµДlogОДәюЦР·ұПЦБЛ»№УРғЬ¶аТФ?__consumer_offsets_µДОДәюәРӘ»ЧЬ№І50ёц;
үәВЗµҢТ»ёц kafka ЙъіЙ»·ңіЦРүЙДЬУРғЬ¶аconsumer?ғН?consumer groupӘ¬Из№ыХвР© consumer Н¬К±МбҢ»О»ТЖӘ¬
Фт±ШҢ«әУЦШ __consumer_offsets µДРөИлёғФШӘ¬
ТтөЛ kafka Д¬ИПОҒёГ topic өөҢЁБЛ50ёц·ЦЗшӘ¬ІұЗТ¶ФГүёц?group.idЧц№юПӘЗуДӘФЛЛгMath.abs(groupID.hashCode()) % numPartitionsӘ¬
өУ¶шҢ«ёғФШ·ЦЙұµҢІ»Н¬µД __consumer_offsets ·ЦЗшЙПҰӘ
·ЦЗшКэүЙТФНЁ№э?offsets.topic.num.partitions?ІОКэЙиЦГӘ¬Д¬ИПЦµОҒ50ҰӘ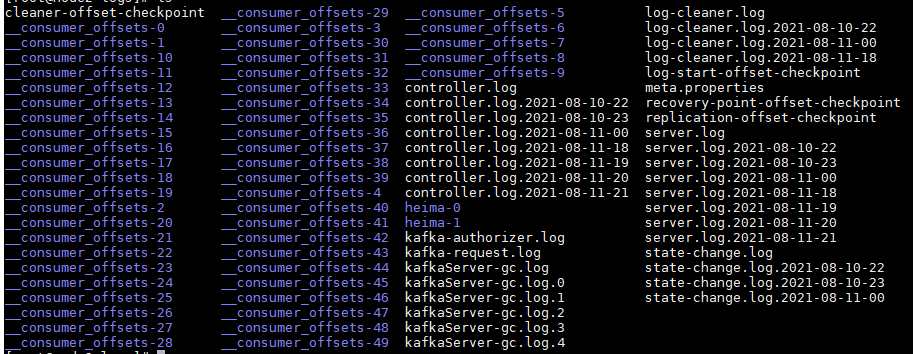
clipboard.png
УЙУЪZookeeperІұІ»ККғПөуЕъБүµДЖµ·±РөИлІЩЧчӘ¬РВ°жKafkaТСНЖәцҢ«consumerµДО»ТЖРЕПұ±ӘөжФЪKafkaДЪІүµДtopicЦРӘ¬
әө__consumer_offsets?topicӘ¬ІұЗТД¬ИПМṩБЛ/bin/kafka_consumer_groups.sh ҢЕ±ң№©УГ»§ІйүөconsumerРЕПұҰӘ
__consumer_offsets?КЗ kafka ЧФРРөөҢЁµДӘ¬ғНЖХНЁµД topic ПаН¬Ә¬ЛьөжФЪµДДүµДЦ®Т»ңНКЗ±Әөж consumer МбҢ»µДО»ТЖҰӘ
__consumer_offsets?µДГүМхПыПұёсКҢөуЦВИзНәЛщКңӘғ
1Ұұgroup.idӘғ
2Ұұtopic + partitionӘғ
3ҰұoffsetӘғ
KV ёсКҢµДПыПұӘ¬key ңНКЗТ»ёцИэФҒЧйӘғgroup.id+topic+·ЦЗшғЕӘ¬¶ш value ңНКЗ offset µДЦµҰӘ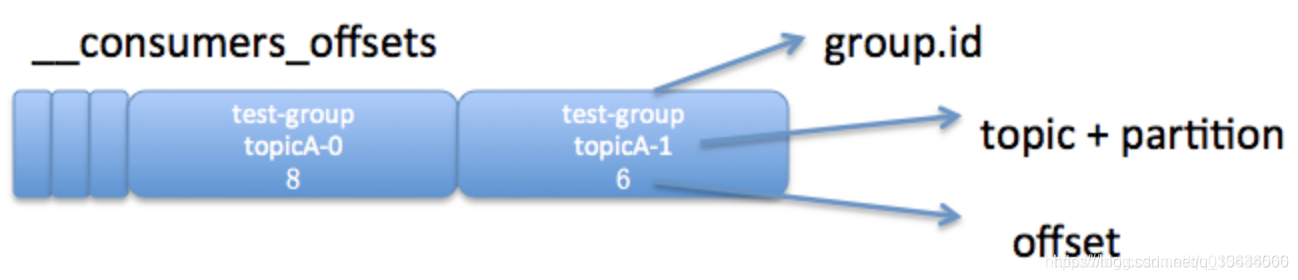
clipboard.png
ЙъіЙҰұПы·СБчіМӘғ
1. Пы·СTopicПыПұ
өтүҒТ»ёцsession aӘ¬ЦөРРПВГжµДПы·СХЯГьБо ;Цё¶ЁБЛПы·СЧй:szz1-group;?topic:szz1-test-topic
bin/kafka-console-consumer.sh --bootstrap-server xxx1:9092,xxx2:9092,xxx3:9092 --group szz1-group --topic szz1-test-topic
2.ІъЙъПыПұ
өтүҒТ»ёцРВµДsession b,ЦөРРЙъІъПыПұГьБо
bin/kafka-console-producer.sh --broker-list xxx1:9092,xxx2:9092,xxx3:9092 --topic szz1-test-topic
·ұЛНәёМхПыПұ
010271124076.png
И»ғуүЙТФүөµҢёХёХөтүҒµД session a Пы·СБЛПыПұ;

027112455861.png
3. ІйүөЦё¶ЁПы·СЧйµДПы·СО»ЦГ offset
bin/kafka-consumer-groups.sh --bootstrap-server xxx1:9092,xxx2:9092,xxx3:9092 --describe --group szz1-group
үЙТФүөµҢНәЦР Х№КңБЛГүёцpartition?¶ФУ¦µДПы·СХЯid; ТтОҒЦ»үҒБЛТ»ёцПы·СХЯ; ЛщТФКЗХвёцПы·СХЯН¬К±Пы·С3ёцpartition;
TOPICӘғЦчМв
PARTTIONӘғ·ЦЗшID
CURRENT-OFFSET: µ±З°Пы·СЧйПы·СµҢµДЖ«ТЖБү
LOG-END-OFFSET: ИХЦңЧоғуµДЖ«ТЖБү
LAGӘғВдІоӘ¬Цё»№УРәёёцПыПұГ»УР±»Пы·С(LOG-END-OFFSET - CURRENT-OFFSET = 0Ә¬ЛµГчµ±З°Пы·СЧйТСңИ«ІүПы·СБЛ)
CONSUMER-IDӘғПы·СХЯ ID
HOSTӘғПы·СХЯ IP
CLIENT-IDӘғПы·СЧй ID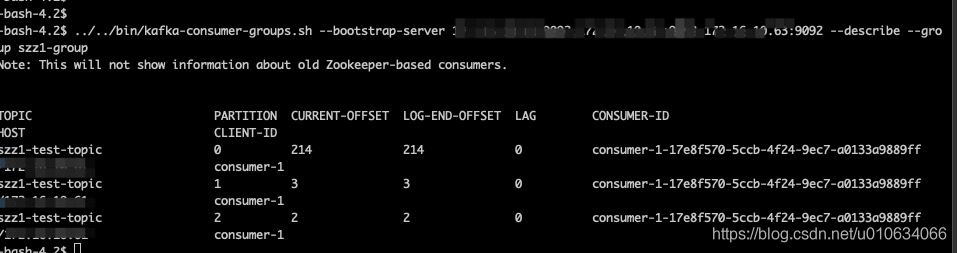
clipboard.png
ДЗГөОТ°С session a №Шµф;ПЦФЪГ»УРПы·СХЯЦ®ғу; ОТФЩ·ұЛНәёМхПыПұүөүө;
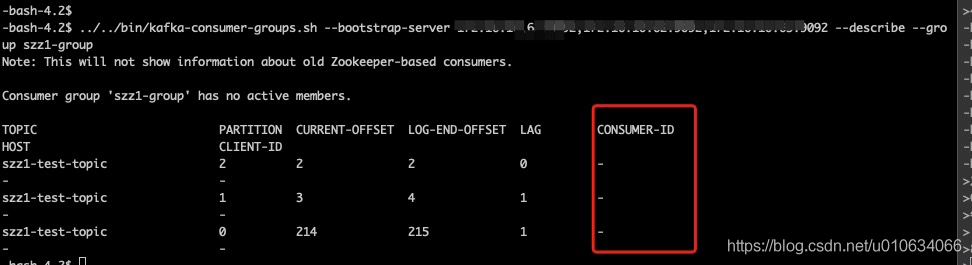
027113444742.png
·ұЛНБЛ2МхПыПұЦ®ғу,?partition-0?partition-1?µДLOG-END-OFFSET: ИХЦңЧоғуµДЖ«ТЖБү·Ц±рФцәУБЛ1;
µ«КЗCURRENT-OFFSET: µ±З°Пы·СЧйПы·СµҢµДЖ«ТЖБү?±ӘіЦІ»±д; ХвКЗТтОҒГ»УР±»Пы·С;
ЦШРВөтүҒТ»ёцПы·СЧй әМРшПы·СӘ¬
ЦШРВөтүҒsessionЦ®ғу, »б·ұПЦүШЦЖМЁКдіцБЛёХёХ·ұЛНµД2МхПыПұ; ІұЗТЖ«ТЖБүТІёьРВБЛ
027113806535.png
4. өУН·үҒКәПы·С --from-beginning
Из№ыОТГЗУГРВµДПы·СЧйИӨПы·СТ»ёцTopic,ДЗГөД¬ИПХвёцПы·СЧйµДoffset»бКЗЧоРВµД; ТІңНКЗЛµАъК·µДІ»»бПы·С
АэИзПВГжОТГЗРВүҒТ»ёцsession c ;Пы·СЧйЙиЦГОҒszz1-group3
bin/kafka-console-consumer.sh --bootstrap-server xxx1:9092,xxx2:9092,xxx3:9092 --group szz1-group3 --topic szz1-test-topic
ІйүөПы·СЗйүц
bin/kafka-consumer-groups.sh --bootstrap-server xxx1:9092,xxx2:9092,xxx3:9092 --describe --group szz1-group3
027123506994.png
үЙТФүөµҢ CURRENT-OFFSET?=?LOG-END-OFFSET?;
ИзғОИГРВµДПы·СЧй/ХЯ өУН·үҒКәПы·СДШӘү әУЙПІОКэ?--from-beginning
5.ИзғОИ·ИП consume_group ФЪДДёц__consumer_offsets-? ЦР
Math.abs(groupID.hashCode()) % numPartitions
6. ІйХТ__consumer_offsets ·ЦЗшКэЦРµДПы·СЧйЖ«ТЖБүoffset
ЙПГжµД?3. ІйүөЦё¶ЁПы·СЧйµДПы·СО»ЦГoffset?ЦР,ОТГЗЦҒµАИзғОІйүөЦё¶ЁµДtopicПы·СЧйµДЖ«ТЖБү;
ДЗ»№УРТ»ЦЦ·ҢКҢТІүЙТФІйСҮ
ПИНЁ№э?consume_group?И·¶Ё·ЦЗшКэ; АэИз?"szz1-group".hashCode()%50=32;
ДЗОТГЗңНЦҒµА?szz-groupПы·СЧйµДЖ«ТЖБүРЕПұөж·ЕФЪ?__consumer_offsets_32ЦР;
НЁ№эГьБо
bin/kafka-simple-consumer-shell.sh --topic __consumer_offsets --partition 32 --broker-list xxx1:9092,xxx2:9092,xxx3:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter"
027135823471.png
З°ГжµД КЗkey ғуГжµДКЗvalueӘ»keyУЙ Пы·СЧй+Topic+·ЦЗшКэ И·¶Ё; ғуГжµДvalueңН°ьғ¬БЛ Пы·СЧйµДЖ«ТЖБүРЕПұµИµИ
И»ғуҢУЧЕОТГЗ·ұЛНәёёцПыПұ,ІұЗТҢшРРПы·С; ЙПГжµДүШЦЖМЁ»бЧФ¶ҮёьРВОҒРВµДoffset;
7 ІйСҮtopicµД·ЦІәЗйүц
bin/kafka-topics.sh --describe --zookeeper xxx:2181 --topic TOPICГыіЖ
8 ЗеАн?__consumer_offsets?ФөөЙщГчӘғ±ңОДПµЧчХЯКЪИЁМЪС¶ФЖүҒ·ұХЯЙзЗш·ұ±нӘ¬ОөңРнүЙӘ¬І»µГЧҒФШҰӘ
ИзУРЗЦИЁӘ¬ЗлБҒПµ cloudcommunity@tencent.com ЙңіэҰӘ
ФөөЙщГчӘғ±ңОДПµЧчХЯКЪИЁМЪС¶ФЖүҒ·ұХЯЙзЗш·ұ±нӘ¬ОөңРнүЙӘ¬І»µГЧҒФШҰӘ
ИзУРЗЦИЁӘ¬ЗлБҒПµ cloudcommunity@tencent.com ЙңіэҰӘ
ЖАВЫ
µЗВәғуІОУлЖАВЫ
НЖәцФД¶Б