java-hashMap
原创java-hashMap
原创
Get
发布于 2024-03-10 20:45:56
发布于 2024-03-10 20:45:56
https://blog.csdn.net/tuke_tuke/article/details/51588156
HashMap实现原理:
HashMap是基于哈希算法实现的,我们通过put(key,value)存储,get(key)来获取数据。
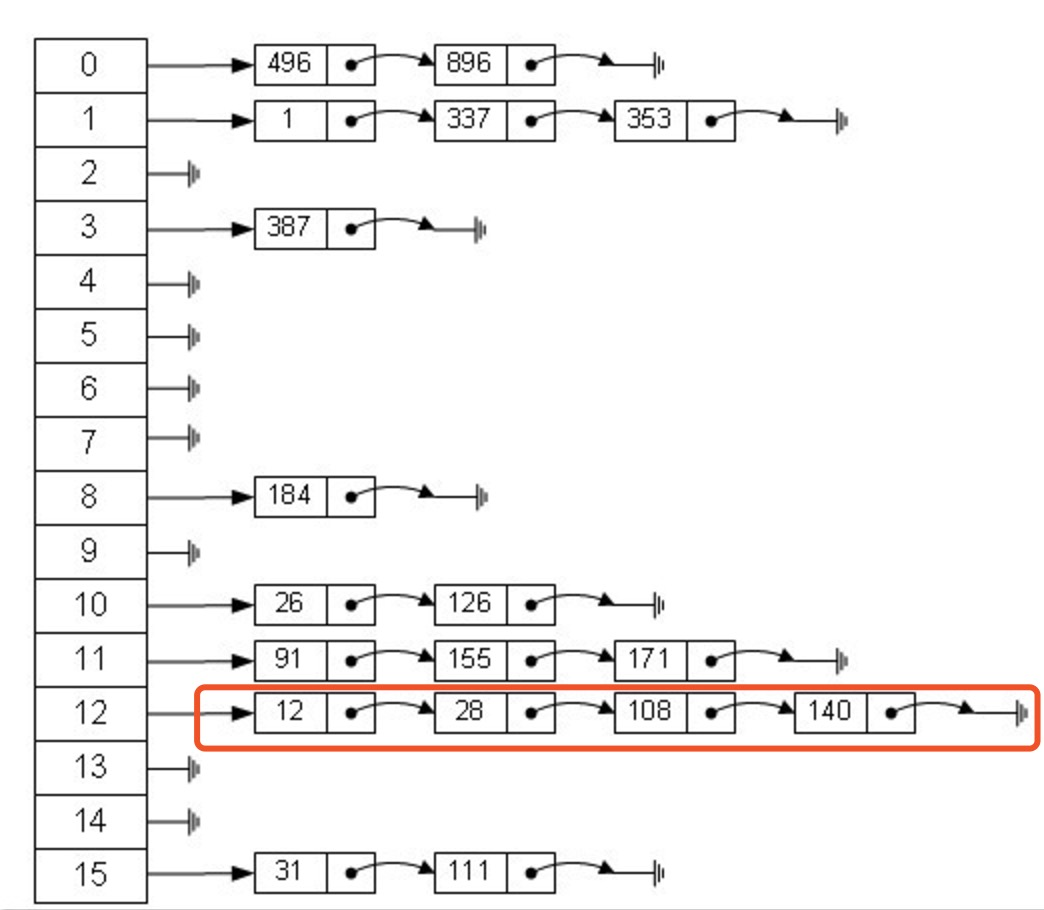
当传入key时,HashMap会根据 key.hashCode()计算出key的hash值,根据hash值将value保存在bucket里。
当计算出的hash值相同时,我们称之为hash冲突,HashMap的做法是用"链表和红黑树"存储相同hash值得value。
当hash冲突的个数较少时,就使用链表,否则使用红黑树。
HashMap是由数组+链表组成
对于hash值冲突,会调用equals()来检查它们之间的关系,会有相应有以下两种处理方法:?
1. 如果相等,系统就不再存入第二个对象;?
2. 如果不等,系统视它们为纯粹的下标冲突,将它们放在同一条链上;什么是哈希(hash)?
最简单形式的 hash,是一种在对任何变量/对象的属性应用任何公式/算法后, 为其分配唯一代码的方法。
Java 中所有的对象都有 Hash 方法,Java中的所有对象都继承?Object?类中定义的?hashCode()?函数的默认实现。
此函数通常通过将对象的内部地址转换为整数来生成哈希码,从而为所有不同的对象生成不同的哈希码。为什么链长度为8时,链表转成树;长度为6时,树转成链表?
还是不太明白
因为红黑树的平均查找长度是long(n),长度为8时,平均查找长度为3; log8=long2(3)=3
而链表的平均查找长度为n/2,当长度为8时,平均查找长度为8/2=4。
所以当长度大于等于8的时候,树的查找效率更高。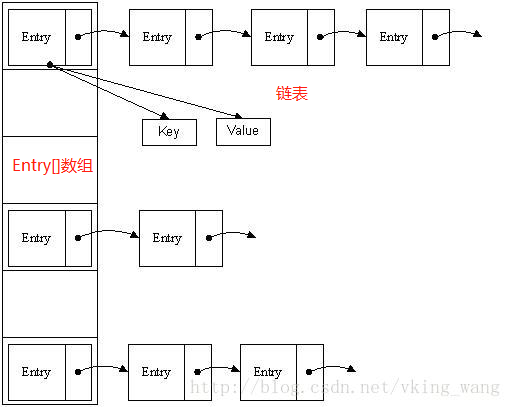
clipboard.png
clipboard.png
HashMap存取代码:
0、HashMap源码基本属性:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; "默认初始容量为16 (2^4)"
static final float DEFAULT_LOAD_FACTOR = 0.75f; "默认负载因子为0.75 (12/16=0.75),当元素数量大于12时,则就发生扩容"
transient?Node<K,V>[]?table;? "Hash数组table中存放指向链表的引用,table 它在resize()方法中初始化,并不是在构造方法里面初始化的"?
transient int size; "HashMap数组中的元素个数"
int threshold; "容量阈值(元素个数超过该值会自动扩容),初始时默认为0"??
"threshold = 数组长度 * loadFactor(负载因子),当元素个数超过threshold(容量阈值)时,HashMap 会进行扩容操作"1、Node 静态内部类:存储键值对
//table 数组里面存放的是 Node 对象,Node 是 HashMap 的一个内部类
transient?Node<K,V>[]?table;
static?class?Node<K,V>?implements?Map.Entry<K,V>?{
????final?int?hash;?//?记录hash值,?以便重hash时不需要再重新计算
????final?K?key;? //Key-value结构的key
????V?value; //存储值
????Node<K,V>?next; //指向下一个链表节点
????...//?其余的代码
}2、数组下标计算:通过哈希码计算数组下标,在该下标中存储键值对
1、通过名为 tableSizeFor() 方法来确保 HashMap 数组长度永远为2的幂次方:
"该算法让最高位的 1 后面的位全变为 1。最后再让结果 n+1,即得到了 2 的整数次幂的值了"
static?final?int?tableSizeFor(int?cap)?{ // table数组长度永远为2的次幂
????int?n?=?cap?-?1; "// tableSizeFor 的功能(不考虑大于最大容量的情况)是返回大于等于输入参数且最近的 2 的整数次幂的数"
????n?|=?n?>>>?1; "// 比如 10,即 2^4 则返回 16"
????n?|=?n?>>>?2;
????n?|=?n?>>>?4;
????n?|=?n?>>>?8;
????n?|=?n?>>>?16;
????return?(n?<?0)???1?:?(n?>=?MAXIMUM_CAPACITY)???MAXIMUM_CAPACITY?:?n?+?1;
}
为什么要保证数组长度为2的次幂?
因为键(key)所计算出的哈希码有可能大于数组容量,老办法是通过简单的求余运算来获得数组下标,但此方法效率太低。
2、HashMap通过以下方法保证哈希值计算后都小于数组容量:"与操作"
(n?-?1)?&?hash;
"n 是 2的次幂,为数组容量;(n-1) 类似于一个低位掩码,通过与操作,高位的hash值全部归零,保证低位才有效,从而保证获得的值都小于n"
// 在下一次 resize() 操作时(重新调整大小时), 重新计算每个 Node 的数组下标将会因此变得很简单。
例:以默认的初始值16为例
????01010011?00100101?01010100?00100101
&???00000000?00000000?00000000?00001111
-----------------------------------------
????00000000?00000000?00000000?00000101????"高位全部归零,只保留末四位。保证了计算出的值小于数组的长度?n=5 < 16"
3、解决hash碰撞(冲突)严重的问题:"扰动函数"
//?因为使用了步骤2功能之后, 由于只取了低位, 因此 hash 碰撞会也会相应的变得很严重。这时候就需要使用 「扰动函数」
"该函数通过将key的哈希码的高 16 位右移后与原哈希码进行异或而得到数组下标"?
static?final?int?hash(Object?key)?{
????int?h;
????return?(key?==?null)???0?:?(h?=?key.hashCode())?^?(h?>>>?16);
}
例:以以上例子为例进行异或运算:
????01010011?00100101?01010100?00100101 //原哈希码
^? 00000000?00000000?01010011?00100101 //哈希码右移16位
-----------------------------------------
????01010011?00100101?00000111?00000000? "此方法保证了高16位不变,低16位根据异或后的结果改变。计算后的数组下标将会从原先的 5 变为 0"
使用了 「扰动函数」 之后,hash 碰撞的概率将会下降。
有人专门做过类似的测试,虽然使用该 「扰动函数」 并没有获得最大概率的避免 hash 碰撞,
但考虑其计算性能和碰撞的概率,JDK 中使用了该方法,且只 hash 一次。3、数组动态扩容:
HashMap 每次扩容都是建立一个新的 table 数组,长度和容量阈值都变为原来的两倍,然后把原数组元素重新映射到新数组上,具体步骤如下:
1. 首先会判断 table 数组长度,如果大于 0 说明已被初始化过,那么按当前 table 数组长度的 2 倍进行扩容,阈值也变为原来的 2 倍。
2. 若 table 数组未被初始化过,且 threshold(阈值)大于 0 说明调用了 HashMap(initialCapacity, loadFactor) 构造方法,那么就把数组大小设为 threshold。
3. 若 table 数组未被初始化过,且 threshold 为 0 说明调用 HashMap() 构造方法,那么就把数组大小设为 16,threshold 设为 16*0.75。
4. 接着需要判断如果不是第一次初始化,那么扩容之后,要重新计算键值对的位置,并把它们移动到合适的位置上去,如果节点是红黑树类型的话则需要进行红黑树的拆分。
1、先判断是初始化还是扩容, 两者在计算 newCap和newThr 时会不一样
2、计算扩容后的容量,临界值。
3、将hashMap的临界值修改为扩容后的临界值
4、根据扩容后的容量新建数组,然后将hashMap的table的引用指向新数组。
5、将旧数组的元素复制到table中。在该过程中, 涉及到几种情况, 需要分开进行处理(只存有一个元素, 一般链表, 红黑树)
JDK1.8 HashMap 扩容阶段重新映射元素时不需要像 1.7 版本那样重新去一个个计算元素的 hash 值,
而是通过 hash & oldCap 的值来判断,若为 0 则索引位置不变,不为 0 则新索引=原索引+旧数组长度,为什么呢?具体原因如下:
因为我们使用的是 2 次幂的扩展(指长度扩为原来 2 倍),所以,元素的位置要么是在原位置,要么是在原位置再移动 2 次幂的位置。
因此,只需要看看原来的 hash 值新增的那个 bit 是 1 还是 0 就好了,是 0 的话索引没变,是 1 的话索引变成 "原索引 +oldCap(原容量)"
(n?-?1)?&?hash;
A.hashCode:????01010011?00100101?01010100?0010'0101' A.hashCode:??01010011?00100101?01010100?001'00101'
n-1: &?00000000?00000000?00000000?0000'1111' new (n-1) :&?00000000?00000000?00000000?000'11111' "新容量-1=32-1"
------------------------------------------------------扩容 ==> ------------------------------------------------------
A.hash:???00000000?00000000?00000000?0000'0101'??? A.new hash:??00000000?00000000?00000000?000'00101'???
只需要看倒数第5位即可:因此等价于:
A.hashCode:????01010011?00100101?01010100?001'0'0101
原容量: &?00000000?00000000?00000000?000'1'0000' "原容量16"
------------------------------------------------------
A.new hash:???00000000?00000000?00000000?000'0'0000???
"得出结果:通过hash与原容量的与运算,只要倒数第5位等于0,则元素索引还存在,否则:元素索引=原索引+原容量"4、哈希冲突及其处理:
clipboard.png
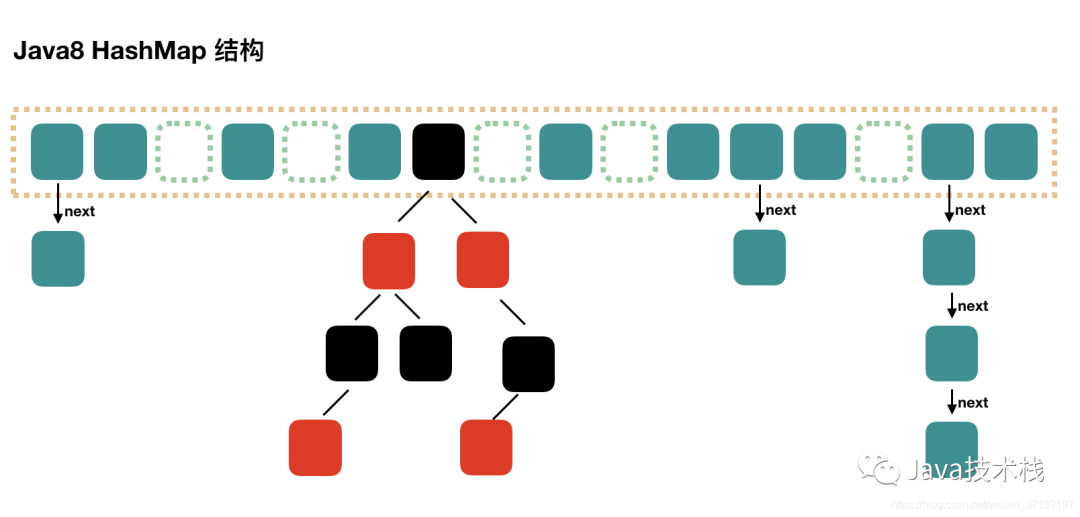
在 Java 的?HashMap?中,采用"数组+链表+红黑树"来解决冲突。
链表树化:指的就是把链表转换成红黑树,树化需要满足以下两个条件:
1、链表长度大于等于 8
2、table 数组长度大于等于 64
为什么 table 数组容量大于等于 64 才树化?
因为当 table 数组容量比较小时,键值对节点 hash 的碰撞率可能会比较高,进而导致链表长度较长。这个时候应该优先扩容,而不是立马树化。
红黑树拆分:拆分就是指扩容后对元素重新映射时,红黑树可能会被拆分成两条链表。原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读