Mysql-事务执行过程(两阶段提交)
原创Mysql-事务执行过程(两阶段提交)
原创
Get
发布于 2024-03-10 21:23:12
发布于 2024-03-10 21:23:12
如果不使用"两阶段提交",那么数据库的状态就有可能和用它的日志恢复出来的库的状态不一致:
一、先写 redolog 后写 binlog 会丢失数据
1、先写 redolog 后写 binlog。假设在 redolog 写完,binlog 还没有写完的时候,
MySQL 进程异常重启,这时候 binlog 里面就没有记录这个语句。
2、如果需要用这个 binlog 来恢复临时库的话,由于这个语句的?binlog 丢失,
这个临时库就会少了这一次更新,则丢失数据,与原库的值不同。
二、先写 binlog 后写 redolog 会多一条数据
1、先写 binlog 后写 redolog。如果在 binlog 写完之后 crash(崩溃),由于 redolog 还没写,
崩溃恢复以后这个事务无效。
2、但是 binlog 里面已经记录了这个日志。所以在之后用 binlog 来恢复的时候就多了一个事务出来,与原库的值不同。
两阶段提交:
1、将新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于"prepare状态"。
然后告知执行器执行完成了,随时可以提交事务。
2、执行器生成这个操作的 binlog,并把 binlog?写入磁盘。
3、执行器调用引擎的"提交事务"接口,引擎把刚刚写入的 redo log 改成"提交(commit)状态",更新完成
https://blog.csdn.net/weixin_43189971/article/details/126437659
两阶段提交如何保证数据一致性:
情况一:一阶段提交之后崩溃了,即 写入 redo log,处于 prepare 状态 的时候崩溃了,
此时:由于 binlog 还没写,redo log 处于 prepare 状态还没提交,所以崩溃恢复的时候,
这个事务会回滚,此时 binlog 还没写,所以也不会传到备库。
情况二:假设写完 binlog 之后崩溃了,
此时:redolog 中的日志是不完整的,处于 prepare 状态,还没有提交,那么恢复的时候,
首先"检查 binlog 中的事务是否存在并且完整",
"如果存在且完整,则直接提交事务,如果不存在或者不完整,则回滚事务"。
情况三:假设 redolog 处于 commit 状态的时候崩溃了,那么重启后的处理方案同情况二。
由此可见,两阶段提交能够确保数据的一致性。
1、binlog(归档日志):将执行完的增删改SQL语句的具体操作记录到binlog中,MySQL 自带的日志模块
2、undo_log(回滚日志):支持事务原子性,数据更改前的快照,可以用来回滚数据(记录旧数据)
3、redo_log(更新、重做日志):支持事务持久性,记录修改操作的日志,用来崩溃后的数据恢复(记录新数据),
InnoDB 引擎自带了日志模块。
redo_log 采用两阶段提交的方式:
redo_log(prepare):记录新数据,更新redo_log状态为预提交状态。
redo_log(commit):更新redo_log状态为提交状态。
SQL 语句执行过程分为两类:
1、查询过程:连接器 -> 查询缓存 -> 分析器 -> 优化器 -> 执行器 -> 存储引擎
2、更新过程:连接器 -> 查询缓存 -> 分析器 -> 优化器 -> 执行器 -> 存储引擎 ->
redo_log(prepare) -> binlog -> redo_log(commit)
redo_log 写成功 && binlog 写成功 == commit,缺一不可。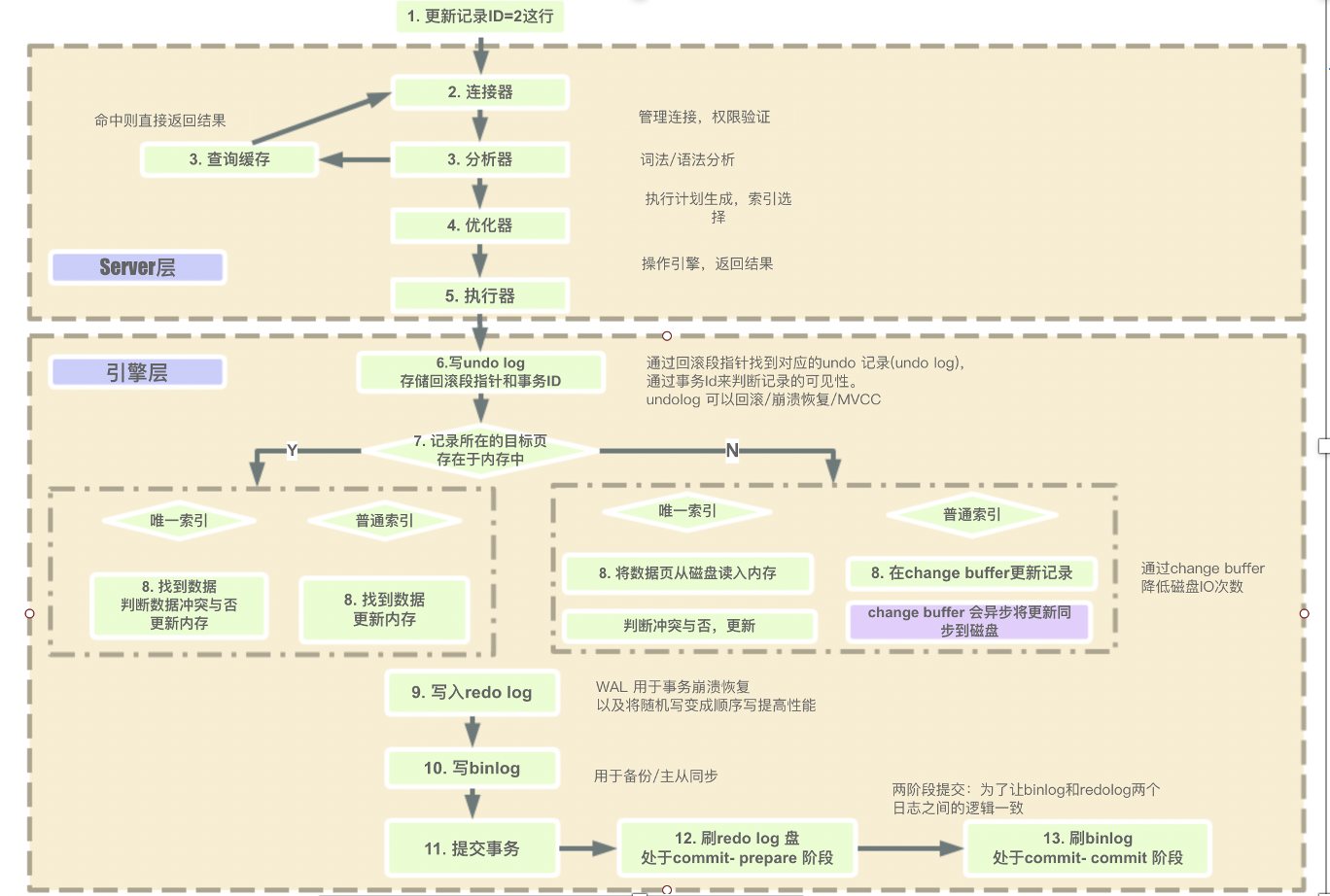
clipboard.png
更新语句:update tb_student A set A.age='19' where A.name='张三';
1、查询缓存:查询缓存中是否有张三这条数据(tb_student.name='张三'),有返回,
无则通过优化器、执行器、存储引擎查询到张三这条数据放入缓存中。
2、执行器:更新操作,会先将数据的旧值写入undo log,以便回滚(记录旧数据,回滚日志,保证原子性);
拿到引擎给的行数据,把 age 改为 19,得到新的一行数据,再调用引擎 API 接口写入这行新数据,
InnoDB 引擎这行新数据更新到内存中,同时将这个更新操作记录到 redolog(记录新数据,重做日志,保证持久性) 里面,
此时 redolog 处于 prepare 状态,然后告知执行器执行完成了,随时可以提交事务。
执行器收到通知后记录 binlog(记录具体操作的语句,归档日志),然后调用引擎接口,提交 redo log 为提交状态。
3、更新完成
update T?set c=c+1?where?ID=2;
1、执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。
如果 ID=2这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
2、执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,
得到新的一行数据,再调用引擎接口写入这行新数据。
3、引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redolog 处于 prepare 状态。
然后告知执行器执行完成了,随时可以提交事务。
4、执行器执行的具体操作记录到 binlog,并把 binlog 写入磁盘。
5、执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
这里我给出这个 update 语句的执行流程图,图中浅色框表示是在 InnoDB 内部执行的,深色框表示是在执行器中执行的。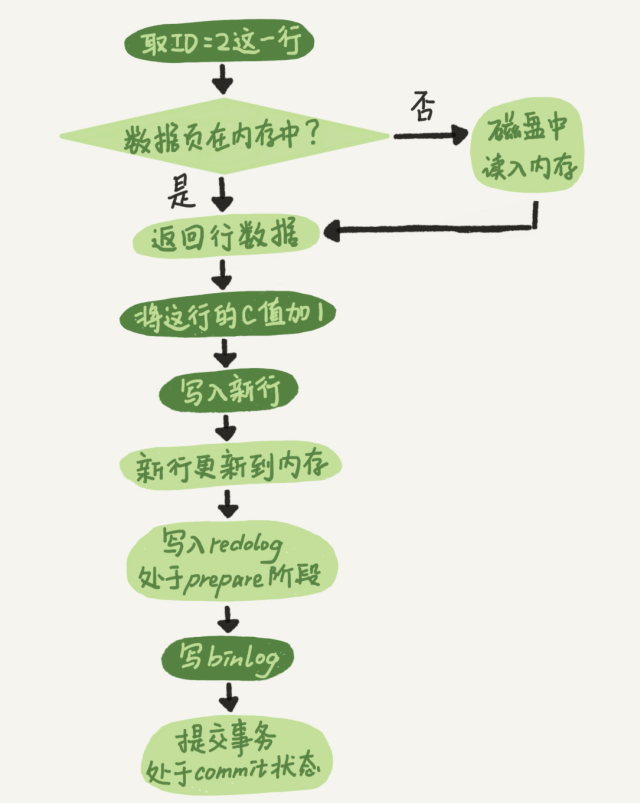
clipboard.png
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
相关产品与服务
云数据库 MySQL
腾讯云数据库 MySQL(TencentDB for MySQL)为用户提供安全可靠,性能卓越、易于维护的企业级云数据库服务。其具备6大企业级特性,包括企业级定制内核、企业级高可用、企业级高可靠、企业级安全、企业级扩展以及企业级智能运维。通过使用腾讯云数据库 MySQL,可实现分钟级别的数据库部署、弹性扩展以及全自动化的运维管理,不仅经济实惠,而且稳定可靠,易于运维。