使用上下文策略极大提高AI SQL 准确性

拥有一个能够回答商业用户简单的语言问题的自主人工智能智能体的承诺是一个有吸引力的提议,但迄今为止仍难以实现。许多人尝试过让 ChatGPT 进行写入,但成效有限。失败的主要原因是大语言模型对其要求查询的特定数据集缺乏了解。
在本文中, 我们表明上下文就是一切,并且通过正确的上下文,我们可以从约 3% 的准确率提升到约 80% 的准确率 。我们研究了三种不同的上下文策略,并展示了一种明显的获胜者 - 我们将模式定义、文档和先前的 SQL 查询与相关性搜索相结合。
我们还比较了一些不同的 LLM - 包括 Google Bison、GPT 3.5、GPT 4 以及 Llama 2 的短暂尝试。虽然 GPT 4 获得了生成 SQL 的最佳整体 LLM 的桂冠 ,但当有足够的上下文时,Google 的 Bison 大致相当。假如。
最后,我们将展示如何使用此处演示的方法为数据库生成 SQL。

1.为什么要使用AI来生成SQL?
许多组织现在已经采用了某种数据仓库或数据湖——组织的许多关键数据的存储库,可出于分析目的进行查询。这片数据海洋充满了潜在的见解,但企业中只有一小部分人具备利用数据所需的两项技能——
1.对高级 SQL 的深入理解 ,以及
2.对组织独特的数据结构和模式 的全面了解
具有上述两种问题的人数不仅少之又少,而且很可能不是提出大多数问题的人。
那么组织内部到底发生了什么? 产品经理、销售经理和高管等业务用户的数据问题将为业务决策和战略提供信息。他们会首先检查仪表板,但大多数问题都是临时和具体的,并且无法获得答案,因此他们会询问数据分析师或工程师 - 无论谁拥有上述技能的组合。这些人很忙,需要一段时间才能处理请求,一旦得到答复,业务用户就会提出后续问题。
这个过程 对于业务用户(获得答案的准备时间很长)和分析师(分散他们的主要项目)来说都是痛苦的,并导致许多潜在的见解丢失。
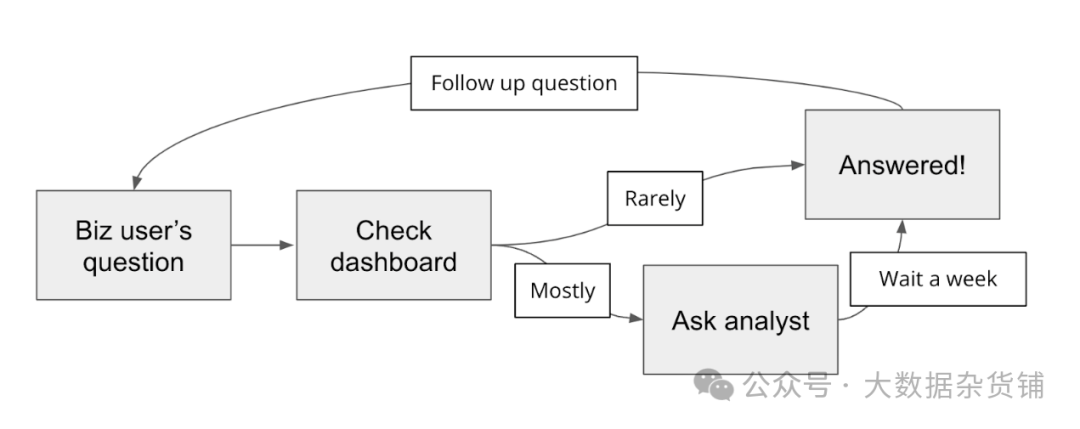
输入生成人工智能! 大语言模型有可能为业务用户提供以简单英语查询数据库的机会(由大语言模型进行 SQL 翻译),我们从数十家公司那里得知,这将改变他们的数据团队甚至业务的游戏规则。
关键的挑战是为复杂而混乱的数据库生成准确的 SQL 。我们采访过的很多人都尝试过使用 ChatGPT 来编写 SQL,但成效有限,而且经历了很多痛苦。许多人已经放弃并恢复到手动编写 SQL 的老式方式。有时,ChatGPT 充其量只是分析师获得正确语法的有用副驾驶。
但还有希望! 在过去的几个月里,我们一直致力于解决这个问题,尝试各种模型、技术和方法来提高大语言模型生成的 SQL 的准确性。在本文中,我们展示了各种 LLM 的性能,以及向 LLM 提供上下文相关的正确 SQL 的策略如何使 LLM 达到 极高的准确性 。
2.设置测试架构
首先,我们需要定义测试的架构。下面是一个粗略的轮廓,分为五个步骤, 伪代码 如下 -

1.问题 - 我们从业务问题开始。
question = "how many clients are there in germany"2.提示 - 我们创建发送给大语言模型的提示。
prompt = f"""
Write a SQL statement for the following question:
{question}
"""3.生成 SQL - 使用 API,我们将提示发送到 LLM 并获取生成的 SQL。
sql = llm.api(api_key=api_key, prompt=prompt, parameters=parameters)4.运行 SQL - 我们将针对数据库运行 SQL。
df = db.conn.execute(sql)5.验证结果 - 最后,我们将验证结果是否符合我们的预期。结果存在一些灰色阴影,因此我们对结果进行了手动评估。 您可以在此处 查看这些结果
3.设置测试杠杆
现在我们已经设置了实验,我们需要弄清楚哪些杠杆会影响准确性,以及我们的测试集是什么。我们尝试了两种杠杆(大语言模型和使用的训练数据),并运行了构成我们测试集的 20 个问题。因此,我们在此实验中总共运行了 3 个大语言模型 x 3 个情境策略 x 20 个问题 = 180 次单独试验。
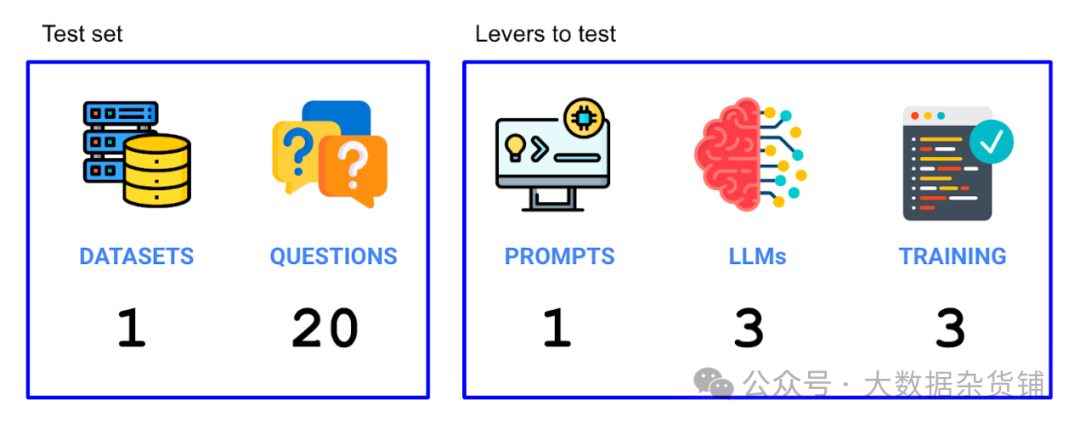
3.1.选择数据集
首先,我们需要 选择一个合适的数据集 进行尝试。我们有一些指导原则 -
1.代表 。企业中的数据集通常很复杂,并且许多演示/示例数据集中没有捕获这种复杂性。我们希望使用一个复杂的数据库,该数据库具有包含真实世界数据的真实用例。
2.无障碍 。我们还希望该数据集能够公开。
3.可以理解 。该数据集应该对广大受众来说是可以理解的——任何过于小众或技术性的东西都将难以破译。
4.保持 。我们更喜欢正确维护和更新的数据集,以反映真实的数据库。
我们发现符合上述标准的数据集是 Cybersyn SEC 文件数据集,该数据集可在 Snowflake 市场上免费获取:https://docs.cybersyn.com/our-data-products/economic-and-financial/sec-filings
3.2.选择问题
接下来,我们需要 选择问题 。 以下是一些示例问题(请在本文件 中查看所有问题 )-
1.数据集中有多少家公司?
2.“ALPHABET INC.”提供哪些年度措施 收入证明?
3.特斯拉的季度“汽车销售”和“汽车租赁”是多少?
4.目前有多少家 Chipotle 餐厅?
现在我们有了数据集+问题,我们需要拿出杠杆。
3.3.选择提示
对于 提示 ,对于这次运行,我们将保持提示不变,尽管我们将进行后续操作以改变提示。
3.4.选择大语言模型(基础模型)
对于 要测试的 大语言模型 ,我们将尝试以下操作 -
1.Bison (Google) - Bison 是 通过 GCP API 提供的 PaLM 2 版本
2.GPT 3.5 Turbo (OpenAI) - 直到最近,GPT 3.5 仍然是 OpenAI 的旗舰模型,尽管由于延迟和成本优势,GPT 3.5 已经可用,并且没有巨大的精度差异(好吧 - 我们将对其进行测试),特别是对于基本任务。
3.GPT 4 (OpenAI) - 更先进但性能较差的 OpenAI 模型。GPT 4 是多模式的,但我们不会使用该功能。
4.Llama 2 (Meta) - 我们真的很想包含一个开源模型 - 领先的模型是 Meta 的 Llama 2。但是我们通过 Replicate 的 设置 很快就崩溃了,我们无法及时修复它以发布此模型。在我们的早期运行中,当它确实起作用时,我们发现性能充其量只是平庸。
3.5.选择上下文
最后,我们将拥有三种类型的 上下文 。上下文是指我们发送给 LLM 的内容,有助于为 LLM 提供有关我们特定数据集的上下文。
1.仅Schema 。我们将Schema(使用 DDL)放在上下文窗口中。
2.静态例子 。我们将静态示例 SQL 查询放在上下文窗口中。
3.上下文相关的示例 。最后,我们将最相关的上下文(SQL / DDL / 文档)放入上下文窗口中,通过基于嵌入的向量搜索找到它。
4.使用 ChatGPT 生成 SQL
本节对 ChatGPT 有点不公平,但它是一个有帮助的入门地方。让我们提出一个问题并要求 ChatGPT 生成 SQL -
提示词
Write Snowflake SQL to answer the following question -
What are the quarterly revenues by business segment for Alphabet?
Return SQL only回复
当然,这是 SQL 查询:
SELECT
EXTRACT(QUARTER FROM date_column) AS quarter,
business_segment,
SUM(revenue) AS quarterly_revenue
FROM
revenue_table
WHERE
company_name = 'Alphabet'
GROUP BY
quarter,
business_segment
ORDER BY
quarter,
business_segment;
-- Replace date_column, business_segment, revenue, revenue_table, and adjust any other identifiers to match your specific database schema.不可避免地,当我们尝试运行它时,我们会遇到错误,因为它虚构了表名,因为我们没有提供它 -
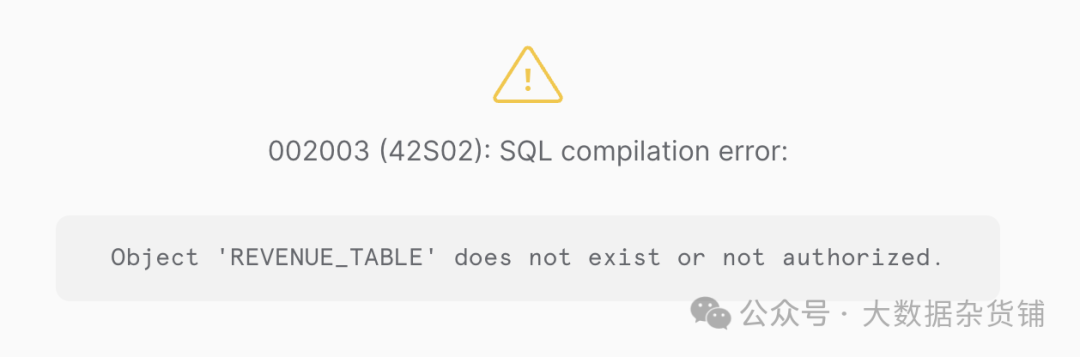
当然,我们对大语言模型不公平——尽管他们很神奇,但他们还不能(不幸?幸运?)知道我们的数据库中有什么。因此,让我们进入测试,提供更多背景信息。
5.仅使用Schema
首先,我们获取数据集的Schema并将其放入上下文窗口中。这通常是我们看到人们使用 ChatGPT 或在教程中所做的事情。
示例提示可能如下所示(实际上,我们使用information schema是因为 Snowflake 共享的工作方式,但这显示了原理)-
The user provides a question and you provide SQL. You will only respond with SQL code and not with any explanations.
Respond with only SQL code. Do not answer with any explanations -- just the code.
You may use the following DDL statements as a reference for what tables might be available.
CREATE TABLE Table1...
CREATE TABLE Table2...
CREATE TABLE Table3...总之,结果很糟糕。在 60 次尝试中(20 个问题 x 3 个模型),只有两个问题被正确回答(都是 GPT 4), 准确率极低,只有 3% 。以下是 GPT 4 成功解决的两个问题 -
1.按频率排列的前 10 个衡量指标描述是什么?
2.报告属性中有哪些不同的陈述?

很明显,仅使用该Schema,我们还无法达到有用的 AI SQL 智能体的标准,尽管它对于成为分析师副驾驶可能有点用处。
6.使用 SQL 示例
如果我们将自己置于第一次接触该数据集的人的立场上,除了表定义之外,他们还会首先查看示例查询以了解 如何 正确查询数据库。
这些查询可以提供架构中不可用的附加上下文 - 例如,要使用哪些列、表如何连接在一起以及查询特定数据集的其他复杂性。
Cybersyn 与 Snowflake 市场上的其他数据提供商一样,在其文档中提供了一些(在本例中为 3 个)示例查询。让我们将它们包含在上下文窗口中。
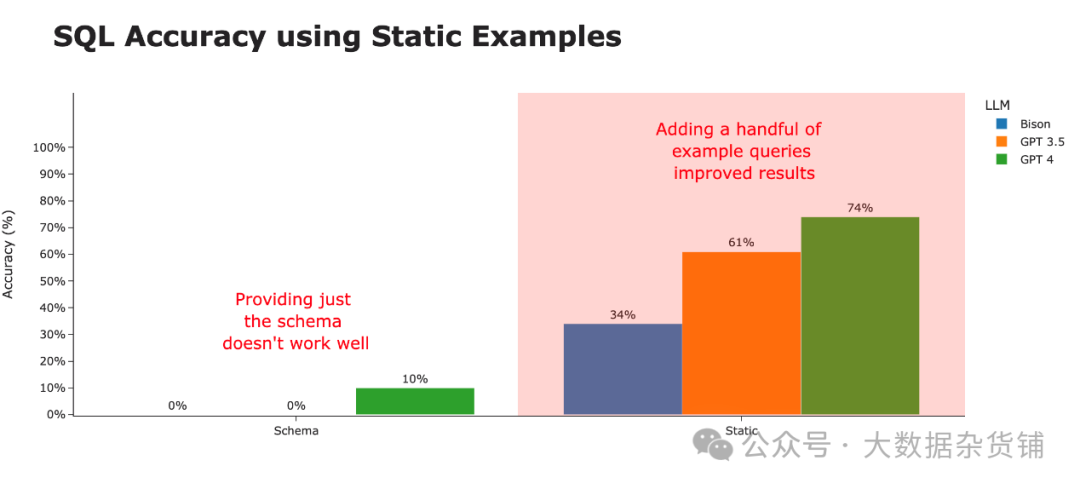
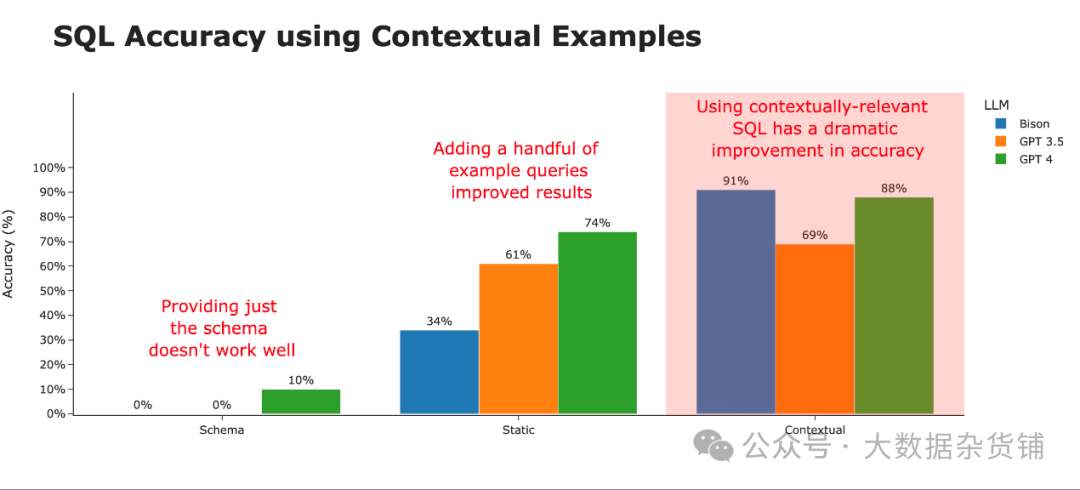
通过仅提供这 3 个示例查询,我们发现生成的 SQL 的正确性得到了显着提高。然而,这种准确性因底层大语言模型的不同而有很大差异。看起来 GPT-4 最能够以生成最准确 SQL 的方式概括示例查询。
7.使用上下文相关的示例
企业数据仓库通常包含数百个(甚至数千个)表,以及更多数量级的查询,涵盖其组织内的所有用例。考虑到现代大语言模型上下文窗口的大小有限,我们不能将所有先前的查询和模式定义都塞到提示中。
我们处理上下文的最终方法是一种更复杂的 ML 方法 - 将先前查询和表模式的嵌入加载到向量数据库中,并且仅选择与所提出的问题最相关的查询/表。这是我们正在做的事情的图表 - 请注意绿色框中的上下文相关性搜索 -
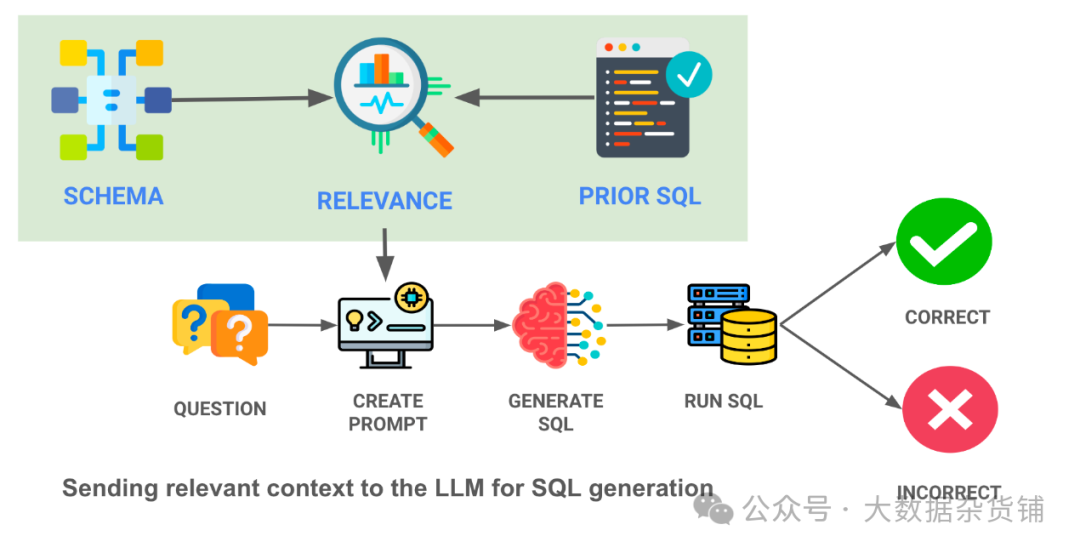
通过向 LLM 提供这些 SQL 查询的最相关示例,我们可以极大地提高能力较差的 LLM 的性能。在这里,我们为大语言模型提供了 10 个与该问题最相关的 SQL 查询示例(来自存储的 30 个示例列表),准确率直线上升。
通过维护可执行的 SQL 语句的历史记录并正确回答用户遇到的实际问题,我们可以进一步提高性能。
8.分析结果
很明显,最大的区别不在于大语言模型的类型,而在于为大语言模型提供适当背景所采用的策略(例如使用的“培训数据”)。

当通过上下文策略查看 SQL 准确性时,很明显这就是造成差异的原因。比当仅使用模式时,我们的准确率从约 3% 提高到智能使用上下文示例时的约 80%。
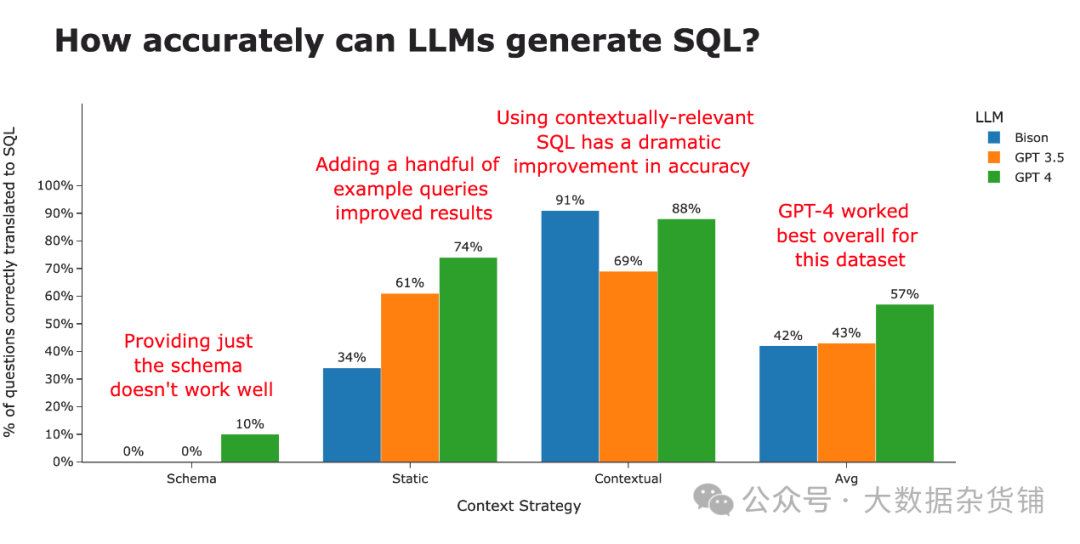
大语言模型本身仍然存在一些有趣的趋势。虽然 Bison 在模式和静态上下文策略中都处于堆的底部,但它通过完整的上下文策略迅速上升到顶部。对三种策略进行平均后, GPT 4 荣获 SQL 生成最佳 LLM 桂冠 。
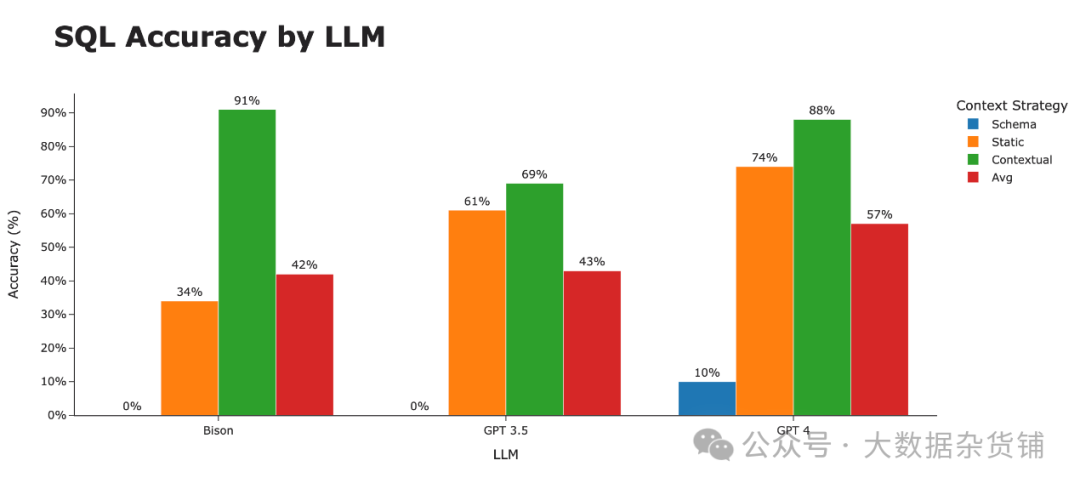
9.进一步提高准确性的后续步骤
我们很快就会对此分析进行跟进,以更深入地了解准确的 SQL 生成。接下来的一些步骤是 -
1.使用其他数据集 :我们很乐意在其他现实世界的企业数据集上尝试这一点。当你达到 100 张表时会发生什么?1000表?
2.添加更多训练数据 :虽然 30 个查询很棒,但是当您将这个数字增加 10 倍、100 倍时会发生什么?
3.尝试更多数据库 :此测试在 Snowflake 数据库上运行,但我们也在 BigQuery、Postgres、Redshift 和 SQL Server 上进行了此测试。
4.尝试更多基础模型: 我们即将能够使用 Llama 2,并且我们很乐意尝试其他大语言模型。
对于上述内容,我们有一些轶事证据,但我们将扩展和完善我们的测试,以包含更多这些项目。
10.使用 AI 为您的数据集编写 SQL
虽然 SEC 数据是一个良好的开端,但您一定想知道这是否与您的数据和组织相关。我们正在构建一个 Python 包 ,它可以为您的数据库生成 SQL 以及附加功能,例如能够为图表、后续问题和各种其他功能生成 Plotly 代码。
以下是其工作原理的概述
import vanna as vn1.使用模式进行训练
vn.train(ddl="CREATE TABLE ...")2.使用文档进行培训
vn.train(documentation="...")3.使用 SQL 示例进行训练
vn.train(sql="SELECT ...")4.生成SQL
开箱即用使用 Vanna 的最简单方法是 返回 SQL、表格和图表,如本 示例笔记本 vn.ask(question="What are the ...") 中所示 。 是, , , , 和 的包装 。这将使用优化的上下文为您的问题生成 SQL,Vanna 将为您调用 LLM。 vn.ask vn.generate_sql vn.run_sql vn.generate_plotly_code vn.get_plotly_figure vn.generate_followup_questions
或者,您可以按照 vn.get_related_training_data(question="What are the ...") 本 笔记本 中所示的方式使用 ,它将检索最相关的上下文,您可以使用它来构建自己的提示以发送给任何 LLM。
本 笔记本 展示了如何使用“静态”上下文策略在 Cybersyn SEC 数据集上训练 Vanna 的示例。
11.关于命名的注释
·基础模型 :这是底层的大语言模型
·上下文模型(又名 Vanna 模型) :这是位于 LLM 之上的一层,为 LLM 提供上下文
·训练 :通常,当我们提到“训练”时,我们指的是训练上下文模型。
原文链接:https://vanna.ai/blog/ai-sql-accuracy.html