如何一键展示全平台信息?Python手把手教你搭建自己的自媒体展示平台
原创如何一键展示全平台信息?Python手把手教你搭建自己的自媒体展示平台
原创
前言
灵感源于之前写过的Github中Readme.md中可以插入自己的js图片和动态api解析模块,在展示方面十分的美观:
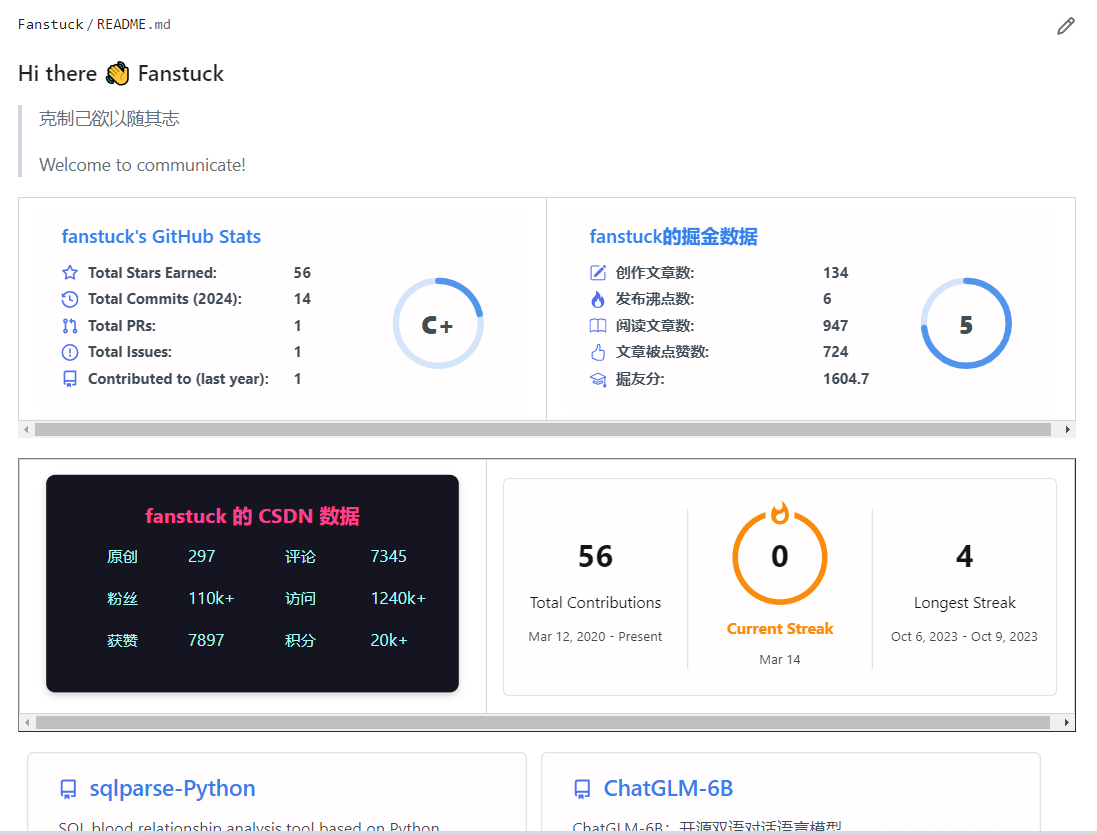
这方面原理可以简化为,在Markdown中,你可以使用HTML标签来添加图像,就像这样:
<tr>
<td><img src="https://github-readme-stats.vercel.app/api?username=fanstuck&show_icons=true&count_private=true&theme=vue-light&hide_border=true" alt="fanstuck's GitHub stats" style="zoom:100%;" align="left"/></td>具体来说,你可以使用<img>标签来嵌入图像,并使用src属性指定图像的URL。我们可以通过访问这个API端点,可以获取到一张包含指定GitHub用户统计信息的图像,然后可以在GitHub的README文件中使用这个图像来展示用户的GitHub统计信息。那么如果我们想要像大家展示我们其他媒体的数据,只需要开发出每个平台的相应的展示接口就可以集成到一个markdown文件展示了。
博主承诺每篇文章我都会尽可能将简化涉及到垂直领域的专业知识,转化为大众小白可以读懂易于理解的知识,将繁杂的程序创建步骤逐个拆解,以逐步递进的方式由难转易逐渐掌握并实践,欢迎各位学习者关注博主,博主将不断创作技术实用前沿文章。
拆解开发步骤
首先我们需要明白一点:https://github-readme-stats.vercel.app/api?username=fanstuck&show_icons=true&count_private=true&theme=vue-light&hide_border=true 这个https是一个GitHub API端点,用于生成用户的GitHub统计数据图像,通常用于在GitHub的README文件中展示用户的GitHub统计信息。参数username指定了用户的GitHub用户名(这里是"fanstuck"),其他参数用于指定要显示的统计信息,如图标、私有库数量等。
通过访问这个API端点,可以获取到一张包含指定GitHub用户统计信息的图像,然后可以在GitHub的README文件中使用这个图像来展示用户的GitHub统计信息。所以说我们需要开发对应解析获取不同平台主体信息的API,然后集成即可。这里我们以开发腾讯云社区博主用户为例,具体流程可以分为:
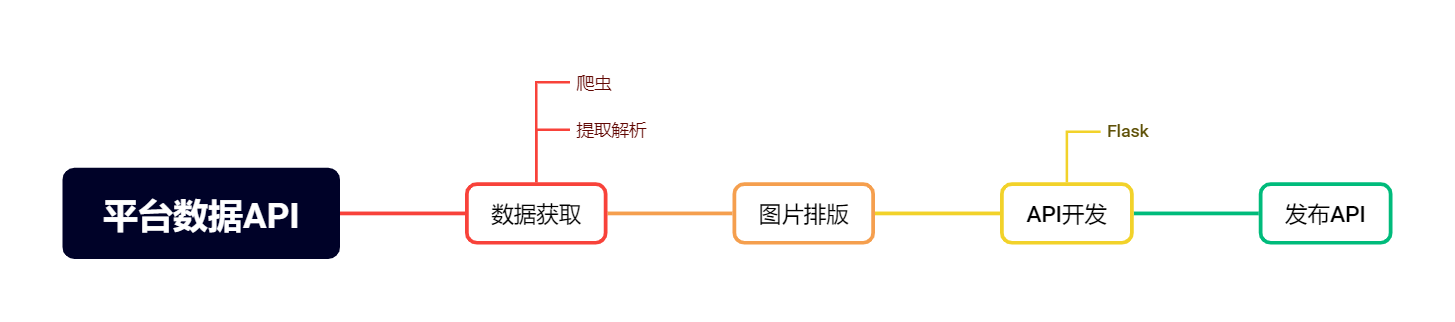
数据获取
一般来说一个账户都有对应UID,相当于就是用户识别码,通过这个用户识别码可以访问到用户的主页:

主页链接访问:/developer/user/9822651,也是基于这个UID来访问,因此我们可以从网页参数直接访问获取,获取个人成就模块:
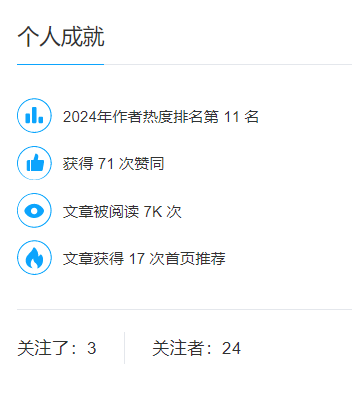
获取这些数据的方法有很多种,我这里直接使用selenium方便:
def get_info(url):
# 打开登录页面
driver.get(url)
user_articles_click=driver.find_elements(By.CSS_SELECTOR,"div.com-tab:nth-child(1) > div:nth-child(1) > ul:nth-child(1) > li:nth-child(3) > a:nth-child(1)")
user_articles_click[0].click()
list_articles=driver.find_elements(By.CSS_SELECTOR,"div.com-weak-section-bd > ul.com-3-article-panels > li.panel-cell")
num_articles=len(list_articles)
print("fanstuck的腾讯云数据:")
data["创作文章数"] = num_articles
print("创作文章数:{}".format(num_articles))
?
user_info=driver.find_elements(By.CLASS_NAME, 'uc-achievement')
for i in range(len(user_info)):
if i == 0:
text_elements =(user_info[i].find_elements(By.CSS_SELECTOR, 'a.uc-achievement-text'))
rank_text = text_elements[0].text
rank_number =re.search(r'第\s*(\d+)\s*名', rank_text).group(1)
data["2024年作者热度排名"] = int(rank_number)
print(text_elements[0].text)
else :
text_elements = (user_info[i].find_elements(By.CSS_SELECTOR, 'span.uc-achievement-text'))
if i == 1:
text_1 = text_elements[0].text
thumbs_up = re.search(r'\d+', text_1).group()
data["获得赞同次数"] = int(thumbs_up)
elif i == 2:
text_2 = text_elements[0].text
read_count = re.search(r'\d+\.?\d*', text_2).group()
if "K" in text_2:
read_count = float(read_count) * 1000
data["文章阅读次数"] = int(read_count)
elif i == 3:
text_3 = text_elements[0].text
recommend = re.search(r'\d+', text_3).group()
data["文章首页推荐次数"] = int(recommend)
?
print(text_elements[0].text)大家可以看到展示结果:

数据可视化
这里我推荐大家可以试试echarts,我这里直接用pyechart开发:
def picture_data(data):
# 提取排名数字
rank_value = data.pop("2024年作者热度排名", None) # 使用 pop 方法直接删除并返回排名值
if rank_value:
rank_text = "2024年作者热度排名: 第 {} 名".format(rank_value)
else:
rank_text = "2024年作者热度排名: 未知"
# 创建柱状图
bar = (
Bar()
.add_xaxis(list(data.keys()))
.add_yaxis("", list(data.values()), color="#5470C6")
.set_global_opts(title_opts=opts.TitleOpts(title=f"fanstuck腾讯云数据 - {rank_text}"), # 将排名信息加入标题
legend_opts=opts.LegendOpts(is_show=False))
)
# 创建网格布局
grid = Grid(init_opts=opts.InitOpts(width="1600px", height="800px"))
grid.add(bar, grid_opts=opts.GridOpts(pos_left="10%", pos_right="60%"))
# 使用 make_snapshot 保存为 PNG
make_snapshot(snapshot, grid.render(), "fanstuck_data.png")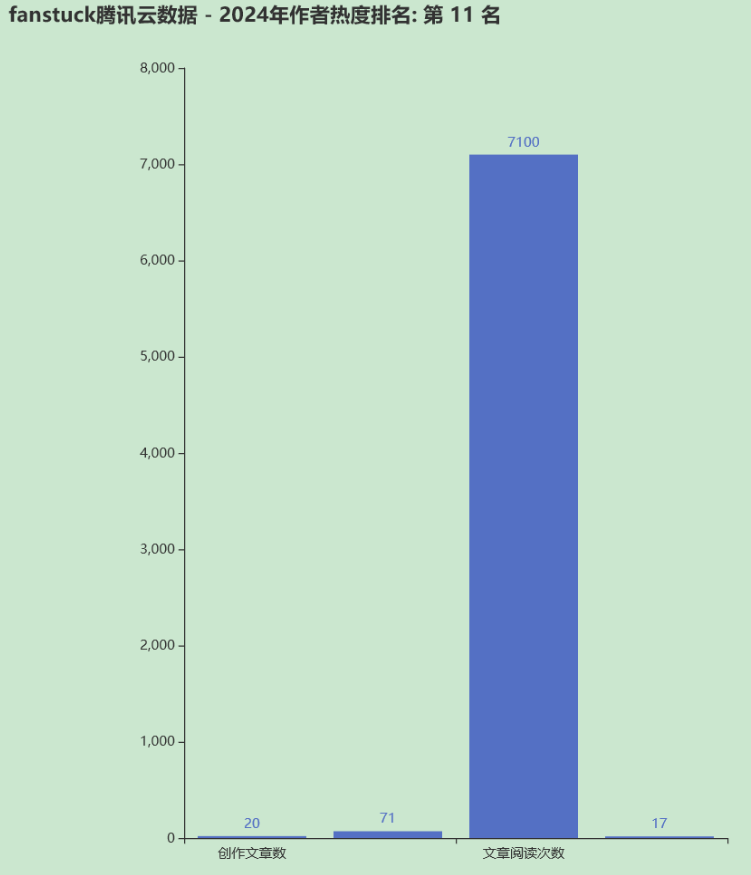
大家可以不用我这个模板,条形图不太美观,数据维度不匹配,或者大家就直接可以展示直观描述也行:
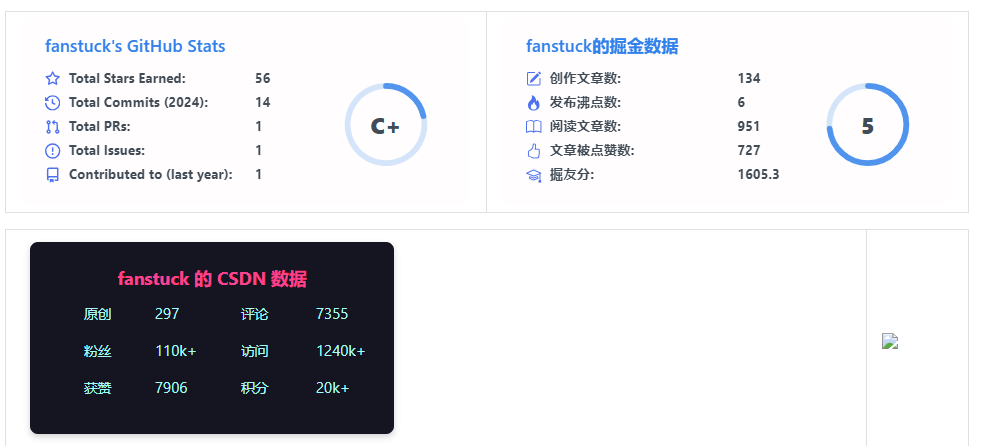
二者都是一致的。之后集成到我们的markdown文件就可以展示了,只需要将对应的markdown文件移植到不同的地点就可以完成全平台的展示。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。