每日论文速递 | 使用对比Reward改进RLHF
每日论文速递 | 使用对比Reward改进RLHF

深度学习自然语言处理 分享 整理:pp

摘要:来自人类反馈的强化学习(RLHF)是将大语言模型(LLM)与人类偏好相匹配的主流范式。然而,现有的 RLHF 在很大程度上依赖于准确、翔实的奖励模型,而奖励模型对各种来源的噪声(如人类标签错误)很脆弱、很敏感,从而使管道变得脆弱。在这项工作中,我们通过在奖励上引入惩罚项来提高奖励模型的有效性,该惩罚项被命名为contrastive rewards。我们的方法包括两个步骤:(1) 离线采样步骤,获取对提示的回应,作为计算基线;(2) 使用基线回应计算对比奖励,并将其用于近端策略优化 (PPO) 步骤。我们的研究表明,对比奖励使 LLM 能够惩罚奖励的不确定性、提高鲁棒性、鼓励改进基线、根据任务难度进行校准以及减少 PPO 中的差异。通过 GPT 和人类的评估,我们的实证结果表明,对比性奖励可以大幅提高 RLHF,而且我们的方法始终优于强基线。
https://arxiv.org/abs/2403.07708
Q1: 这篇论文试图解决什么问题?
A:这篇论文试图解决的问题是强化学习从人类反馈(Reinforcement Learning from Human Feedback, RLHF)中存在的奖励模型(reward model, RM)质量问题。具体来说,现有的RLHF方法在很大程度上依赖于准确且信息丰富的奖励模型来引导学习过程,但这些奖励模型容易受到来自多种来源的噪声的影响,例如人类标注错误,这使得整个流程变得脆弱。为了解决这一问题,论文提出了一种通过引入惩罚项来改进奖励模型有效性的方法,称为对比奖励(contrastive rewards)。
主要问题可以总结为以下几点:
- 奖励模型的准确性和信息丰富性:设计一个准确且信息丰富的奖励模型是一个重大挑战,因为奖励模型的质量受到偏好数据的质量和标注的固有模糊性的影响。
- 奖励模型训练的敏感性:奖励模型训练对于训练细节非常敏感,这可能导致奖励黑客(reward hacking)问题,即模型学会操纵奖励函数以获得更高的奖励,而不是真正地提高性能。
- 奖励模型的泛化能力:在实际部署环境中,奖励模型往往表现出有限的泛化能力,尤其是在面对与训练数据分布不同的新情况时。
为了应对这些问题,论文提出了一种简单的修正方法,通过使用对比奖励来显著提高RLHF的性能。这种方法明确承认了奖励模型的不完美性,并使用对比奖励中的惩罚项来校准RLHF过程。
Q2: 有哪些相关研究?
A:这篇论文中提到的相关研究主要集中在以下几个方面:
- LLM Alignment (大型语言模型对齐): 对齐大型语言模型(LLMs)与人类偏好的方法,其中包括使用奖励模型的强化学习(RLHF)方法,以及不使用强化学习的偏好学习方法,如RSO、RRHF和RAFT。
- Reward Modeling (奖励建模): 设计和训练奖励模型来捕捉人类偏好,这通常涉及到使用人类标注的数据来训练模型,以便模型能够区分好的和不好的语言模型输出。
- Noisy Label Literature (噪声标签文献): 处理带有噪声的标签是机器学习中的一个常见问题,论文提出的方法受到这一领域的启发,特别是在处理不完美监督信号时的分析和学习。
- Contrastive Learning in RLHF: 使用对比学习来增强奖励模型的排名或比较能力,例如通过对比正负样本来提高区分能力,或者使用相对反馈来更新策略。
- Preference Learning (偏好学习): 直接从人类偏好中学习策略的方法,而不依赖于奖励模型,例如直接偏好优化(DPO)和自奖励语言模型(Self-rewarding Language Models)。
- Policy Learning with Weak Supervision (弱监督下的政策学习): 在标签不完全准确或存在噪声的情况下学习有效策略的方法。
- Reinforcement Learning (强化学习): 强化学习算法的一般理论和应用,特别是在与人类反馈结合时的挑战和方法。
这些相关研究表明,如何有效地从人类反馈中学习并改进大型语言模型的行为是一个多方面、跨学科的研究领域,涉及强化学习、机器学习、自然语言处理和人工智能安全等多个领域。
Q3: 论文如何解决这个问题?
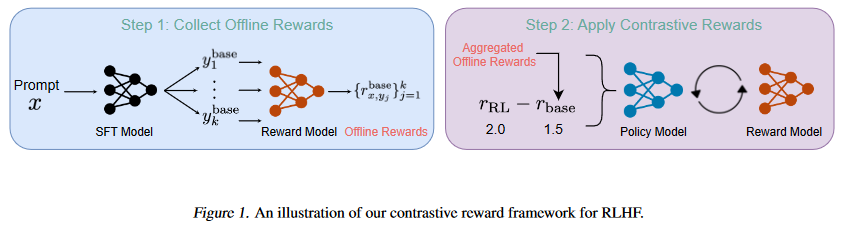
A:论文通过引入对比奖励(contrastive rewards)的方法来解决强化学习从人类反馈(RLHF)中存在的奖励模型质量问题。具体来说,这个方法包括以下几个关键步骤:
- 离线采样(Offline Sampling):

首先,对于将在近端策略优化(Proximal Policy Optimization, PPO)阶段使用的提示(prompts),使用基础模型(Supervised Fine-tuning, SFT模型)生成响应。这些响应作为基线响应。通过这种方法,可以减少在RL阶段进行额外采样的同步时间开销。
- 计算对比奖励(Computing Contrastive Rewards):

使用采样得到的基线响应,计算对比奖励。在RL训练期间获得的奖励与相应的对比奖励进行比较,从而在RL阶段建立了一个隐式的比较奖励框架。这个“惩罚”奖励信息使得RL策略能够基于观察到的差异进行自我改进。
- 性能分析(Performance Analysis):
论文分析了对比奖励项在简化设置中的优势,包括惩罚不确定实例、在给定RM不完美情况下改进RLHF管道的鲁棒性、根据任务难度进行校准以及减少PPO中的方差。
- 实验验证(Experiments):
通过广泛的实验,包括使用GPT模型自动化评估和精心收集的人类评估,来证明所提出方法的有效性。论文展示了对比奖励能够显著提高RLHF的性能,并且该方法在各种任务中一致地超越了强基线。
总结来说,论文通过引入对比奖励来明确地校准奖励模型的错误,并提出了一个简单且高效的实现方法。通过离线采样收集基线响应,并使用这些响应来定义对比奖励,这种方法在对齐大型语言模型与人类反馈方面表现出了一致的性能提升和鲁棒性增强。
Q4: 论文做了哪些实验?
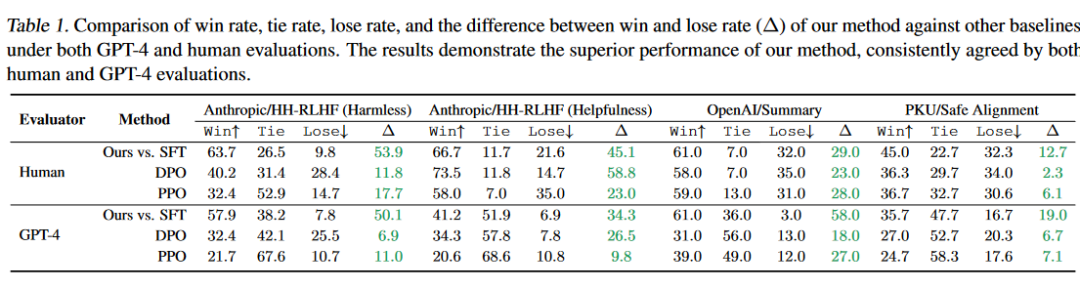
A:论文进行了一系列实验来评估所提出方法的有效性,这些实验主要分为以下几个方面:
- 算法性能比较:
- 使用三个广泛使用的RLHF数据集(Anthropic/HH-RLHF Dataset、OpenAI/Summary Dataset、PKU/Safety Alignment Dataset)进行实验。
- 将提出的算法与几个流行的基线进行比较,包括仅进行监督式微调(SFT)、近端策略优化(PPO)和直接偏好优化(DPO)。
- 使用两个第三方奖励模型(UltraRM13B和PairRM)和人类评估来衡量生成策略的性能。
- 离线采样样本数量的影响:
- 研究了在离线采样中使用不同数量的样本(1个、3个、5个)对性能的影响。
- 分析了样本数量对于减少噪声和提高基线响应估计的鲁棒性的作用。
- 对比奖励在细粒度水平上的作用:
- 根据平均离线奖励将提示分为低离线奖励组和高离线奖励组,以研究对比奖励在不同难度提示上的性能提升。
- 计算了PPO阶段前后的奖励差距,以评估方法在具有挑战性的提示上的性能改进。
- 基准测试性能:
- 在MT-Bench和RED-EVAL基准测试上评估了方法的性能,这些基准测试涵盖了多种任务和挑战性场景。
- 使用Mistral-7B-Instruct模型作为基础模型进行对齐,并在基准测试中评估了不同模型的性能。
- 实现细节:
- 提供了使用Llama 7B模型作为基础模型的详细设置,包括监督式微调、奖励模型训练和RL优化的具体参数和设置。通过这些实验,论文全面地展示了所提出方法在不同设置和评估标准下的性能,并通过与基线的比较证明了其有效性。实验结果表明,使用对比奖励的方法在各种任务和评估标准下均能显著提高RLHF的性能。
Q5: 有什么可以进一步探索的点?
A:论文在结论和讨论部分提出了一些可以进一步探索的点,包括:
迭代应用对比奖励:论文提到的方法目前只应用于SFT模型,但这种方法有潜力在迭代设置中实施。即在第一轮策略优化后,可以使用得到的策略作为基础模型,再进行一轮对比奖励的RL优化,以进一步提高性能。
与噪声标签文献的联系:论文的工作受到噪声标签问题研究的启发,提出了在RLHF中处理不完美奖励模型的方法。未来可以更深入地探索噪声标签问题中的技术和理论,以改进RLHF中奖励模型的鲁棒性。
对比奖励在其他RLHF方法中的应用:虽然对比奖励是在RLHF中提出的,但这种方法也可以适用于其他使用奖励模型的RLHF方法。未来的研究可以探索如何将对比奖励集成到这些方法中,以及它们对性能的潜在影响。
对比奖励的长期影响:论文的实验主要集中在短期内的性能提升上。未来的研究可以探讨在长期应用对比奖励后,模型的行为和性能是否会有持续的改进或新出现的挑战。
对比奖励在不同任务和领域中的应用:论文在几个数据集上验证了方法的有效性,但还有更多的任务和领域可以探索。例如,可以考虑将对比奖励应用于多模态任务、机器人控制、游戏环境等。
对比奖励的可解释性和透明度:对比奖励如何影响模型的决策过程,以及这些决策是否可以被人类理解和解释,是未来研究的一个重要方向。提高模型的可解释性可以帮助我们更好地理解和信任AI系统。
对比奖励与其他正则化技术的结合:探索将对比奖励与其他正则化技术(如知识蒸馏、正则化项等)结合使用,可能会进一步提高模型的鲁棒性和泛化能力。这些方向为未来的研究提供了丰富的思路,旨在进一步增强RLHF方法的性能和可靠性。
Q6: 总结一下论文的主要内容?
A:这篇论文的主要内容可以总结如下:
问题定义:论文针对强化学习从人类反馈(RLHF)中存在的奖励模型(RM)质量问题进行研究。现有RLHF方法依赖于准确的奖励模型,但这些模型容易受到噪声的影响,导致学习过程脆弱。
方法提出:为了解决上述问题,论文提出了一种名为对比奖励(contrastive rewards)的方法。该方法通过引入奖励惩罚项来改进奖励模型的有效性。
方法步骤:
离线采样:使用基础模型(SFT模型)对提示进行采样,生成基线响应。
对比奖励计算:利用基线响应计算对比奖励,并在PPO阶段使用这些奖励。
理论分析:
论文分析了对比奖励的优势,包括惩罚不确定实例、提高鲁棒性、鼓励改进、根据任务难度校准以及减少PPO中的方差。
实验验证:
论文通过在多个数据集上的实验,包括使用GPT模型和人类评估,证明了对比奖励方法能够显著提高RLHF的性能,并一致超越了强基线。
主要贡献:
提出了一种新的对比奖励方法来改进基于人类反馈的RLHF对齐。
提供了一个简单且高效的实现方法,通过离线采样和对比奖励定义。
通过广泛的实验测试,证明了该方法在不同任务上的性能提升和鲁棒性增强。
未来工作:
论文讨论了未来可能的研究方向,包括迭代应用对比奖励、与噪声标签问题的进一步连接、对比奖励在其他RLHF方法中的应用、对比奖励的长期影响、在不同任务和领域中的应用、对比奖励的可解释性以及与其他正则化技术的结合。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文