生信技能树七天学习小组 Day6笔记——学习R包
原创生信技能树七天学习小组 Day6笔记——学习R包
原创
可乐同学与生信死磕到底
发布于 2024-03-28 21:27:32
发布于 2024-03-28 21:27:32
呜呜今天是补昨天的内容 昨天临床任务太多只看了一下要学习的内容没有做笔记T T
1 安装和加载R包
1.1 镜像设置
1.2 安装
install.packages()/BiocManager::install()
取决于包是来源于CRAN网站还是Bioconductor
1.3 加载
library/require
options("repos" = c(CRAN="[https://mirrors.tuna.tsinghua.edu.cn/CRAN/](https://mirrors.tuna.tsinghua.edu.cn/CRAN/)"))
options(BioC\_mirror="[https://mirrors.ustc.edu.cn/bioc/](https://mirrors.ustc.edu.cn/bioc/)")
install.packages("dplyr")
library(dplyr)2 dplyr的五个基础函数
test <- irisc(1:2,51:52,101:102),2.1 mutate(),新增列
mutate(test, new = Sepal.Length * Sepal.Width)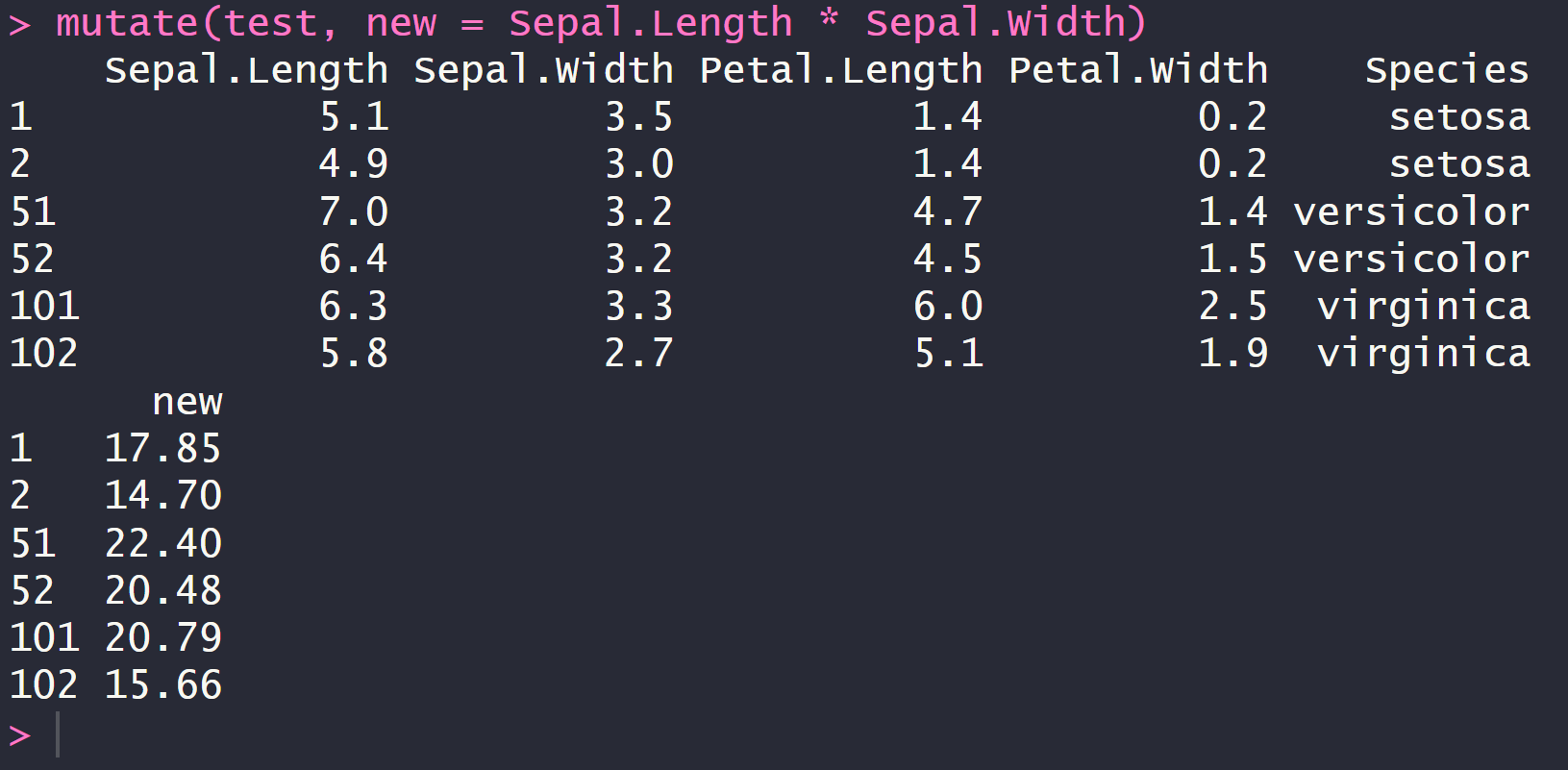
2.2 select(),按列筛选
2.2.1 按列号筛选
select(test,1)
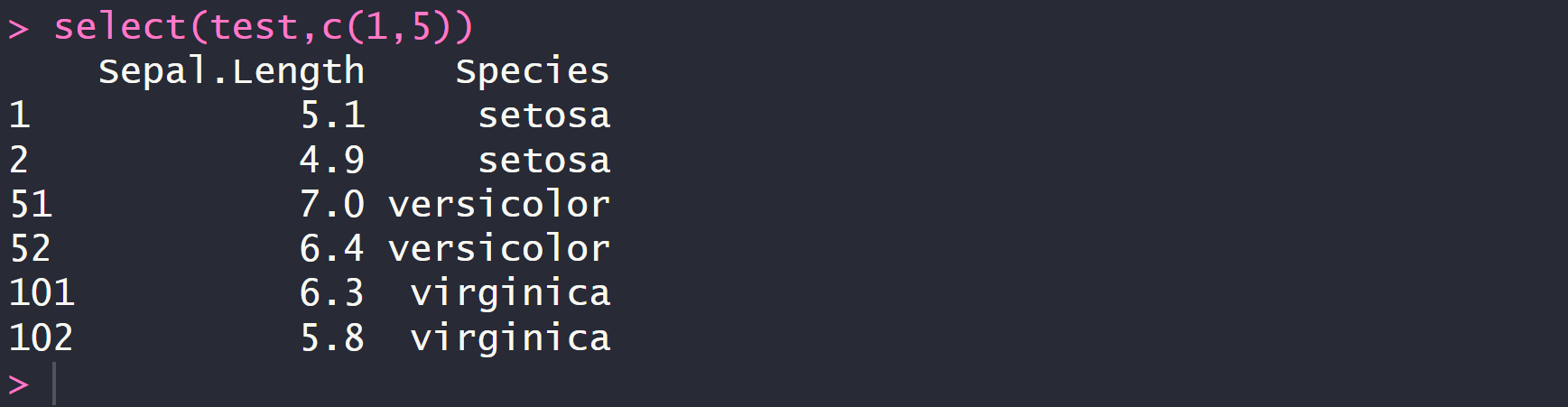
select(test,c(1,5))
2.2.2 按列名筛选
select(test, Petal.Length, Petal.Width)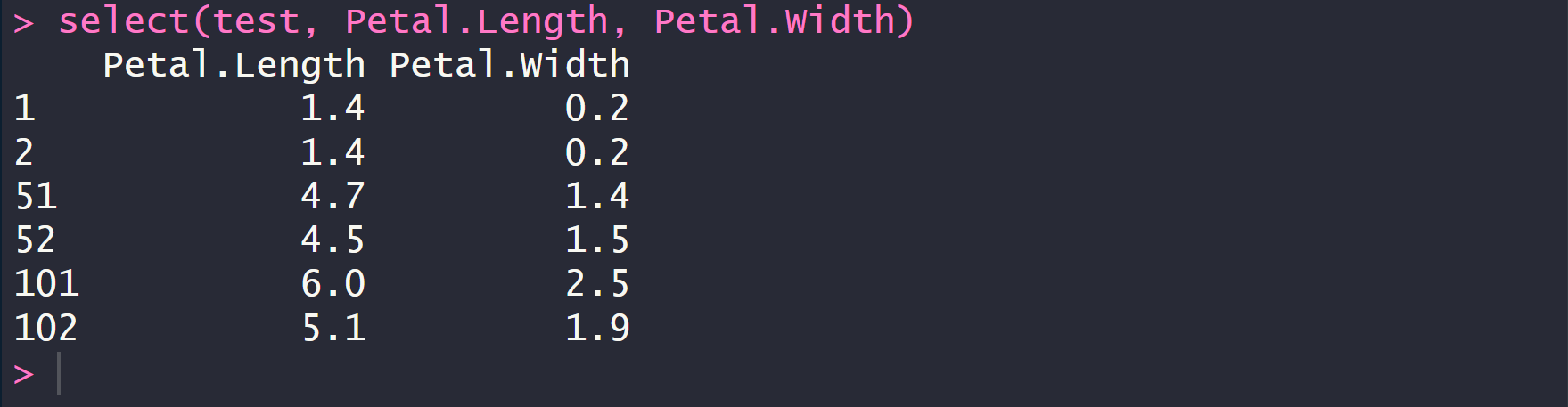
2.3 filter()筛选行
filter(test, Species **==** "setosa")
filter(test, Species == "setosa"&Sepal.Length > 5 )
filter(test, Species %in% c("setosa","versicolor"))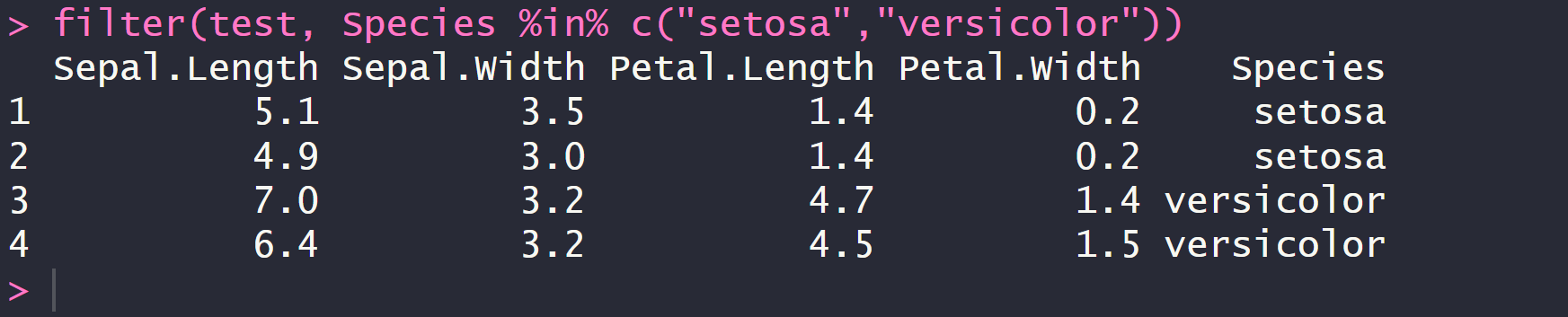
2.4 arrange()按照某1列/某几列对整个表格进行排序
arrange()默认从小到大排序
arrange(test, Sepal.Length)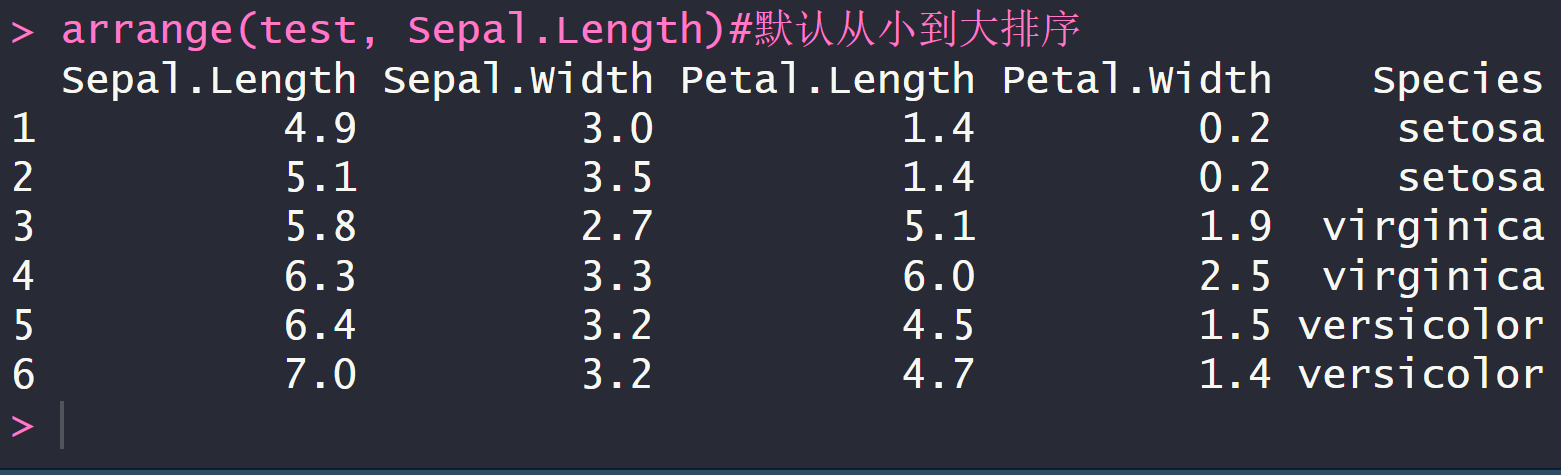
用desc()从大到小排序
arrange(test, desc(Sepal.Length))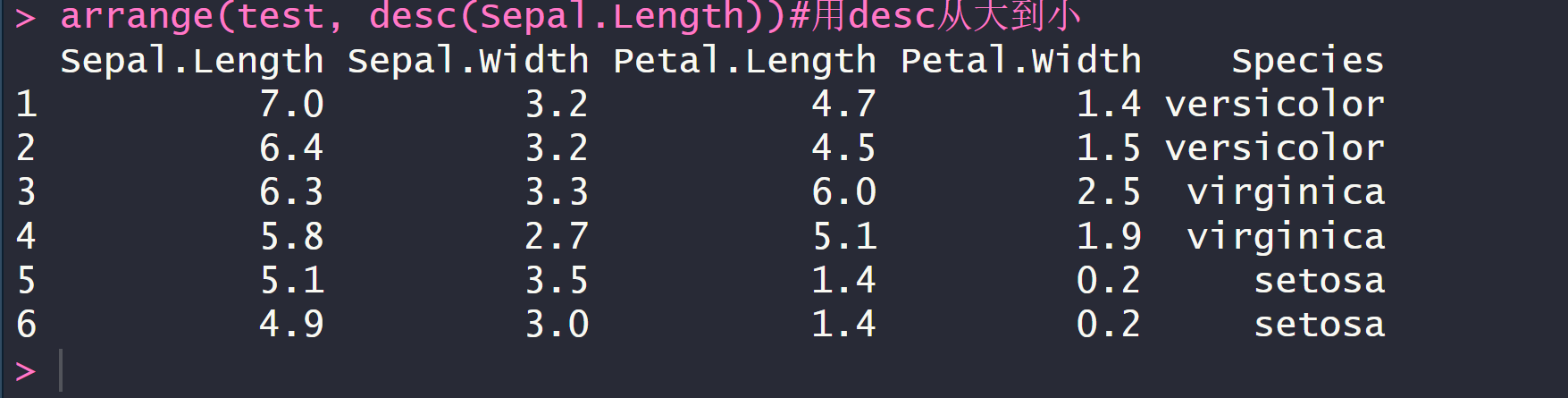
2.5 summarise()汇总
对数据进行汇总操作,结合group_by使用实用性强
summarise(test, mean(Sepal.Length), sd(Sepal.Length))
group_by(test, Species)
summarise(group_by(test, Species),mean(Sepal.Length), sd(Sepal.Length))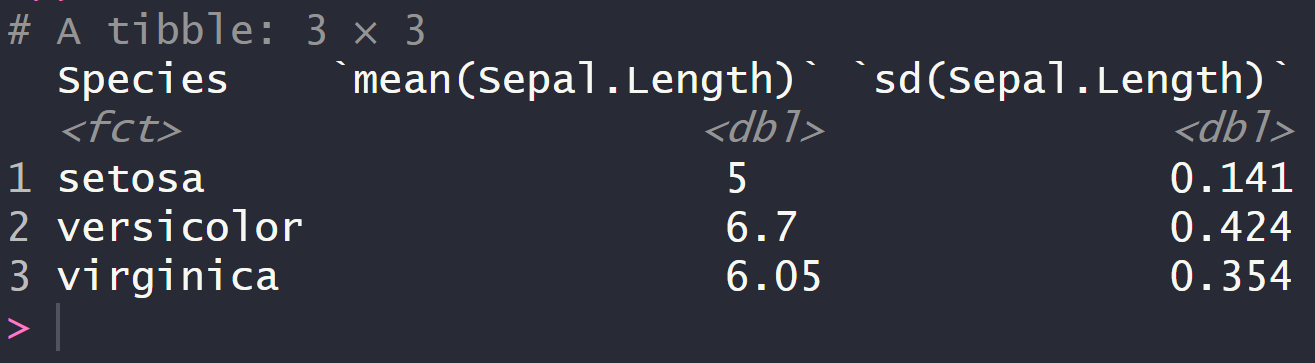
3 dplyr的两个实用技能
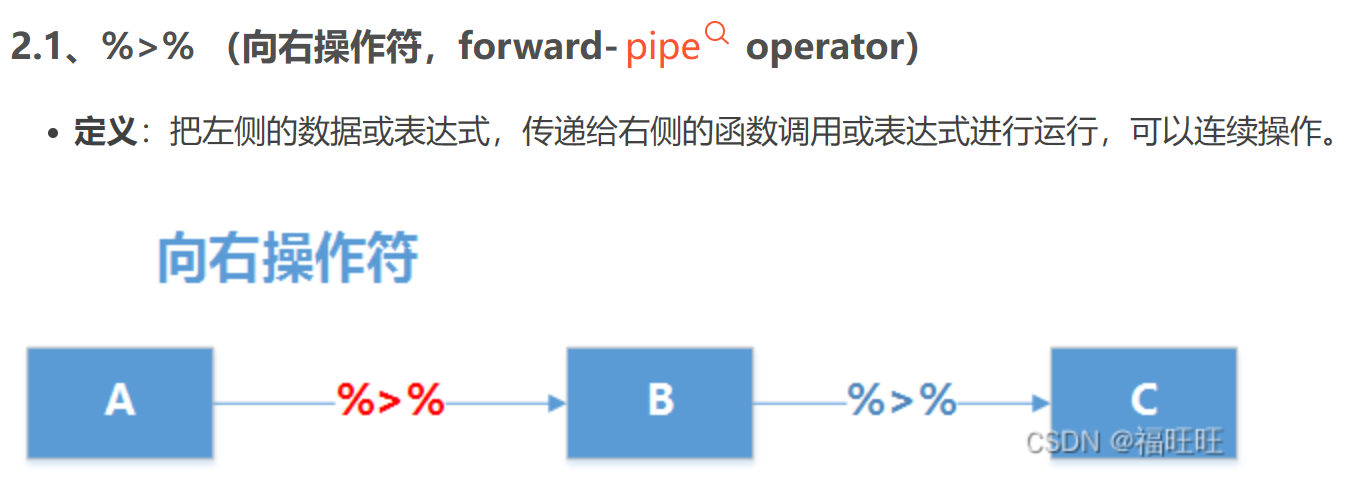
3.1 管道操作 %>% (ctr + shift + M)
可以在 R 中使用管道运算符 ( %>% ) 将一系列操作“通过管道”连接在一起,该运算符最常与 R 中的dplyr包一起使用,以对数据帧执行一系列操作。
管道运算符只是将一个操作的结果传递到其下面的下一个操作。
使用管道运算符的优点是它使代码非常易于阅读。
https://statorials.org/cn/%E7%AE%A1%E5%AD%90/ https://blog.csdn.net/qq_45794091/article/details/127770633
test %>%
group_by(Species) %>%
summarise(mean(Sepal.Length), sd(Sepal.Length))
3.2 count统计某列的unique值
count(test,Species)
4 dplyr处理关系数据——将两个表进行连接
4.1 內连inner_join,取交集
test1 <- data.frame(x = c('b','e','f','x'),
z = c("A","B","C",'D'))
test1
test2 <- data.frame(x = c('a','b','c','d','e','f'),
y = c(1,2,3,4,5,6))
test2 生成test1、test2两个数据框
inner_join(test1, test2, by = "x")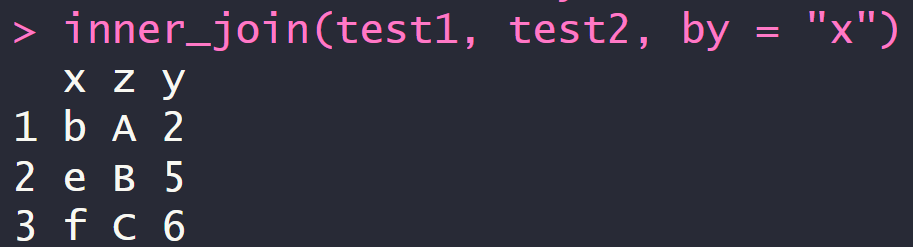
4.2 左连 left_join
以左侧的那个数据框为准
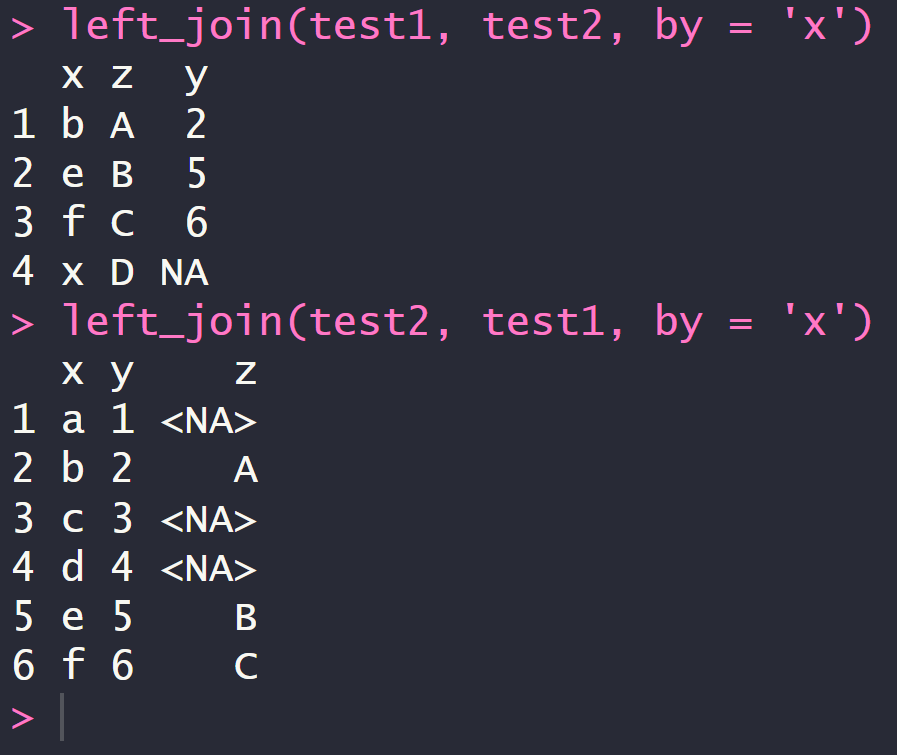
4.3 全连 full_join
full_join( test1, test2, by = 'x')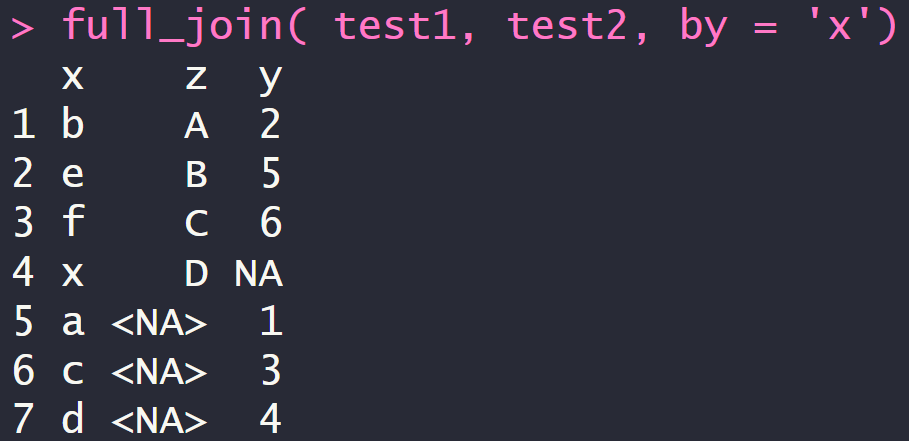
4.4 半连接:返回能够与y表匹配的x表所有记录semi_join
定义x表与y表
semi_join(x = test1, y = test2, by = 'x')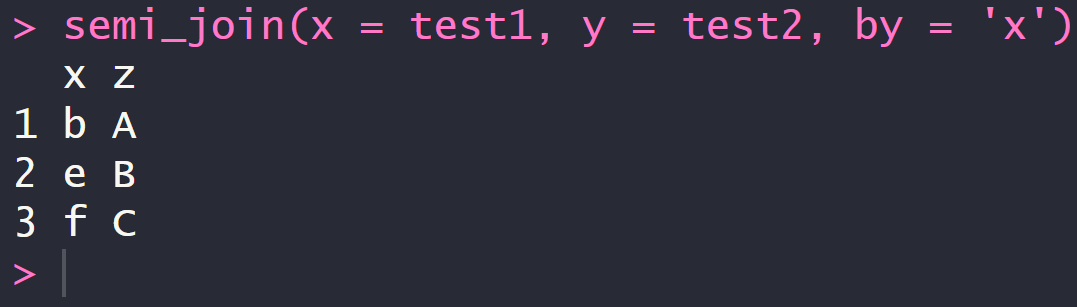
4.5 反连接:返回无法与y表匹配的x表的所记录anti_join
定义x表与y表
anti_join(x = test2, y = test1, by = 'x')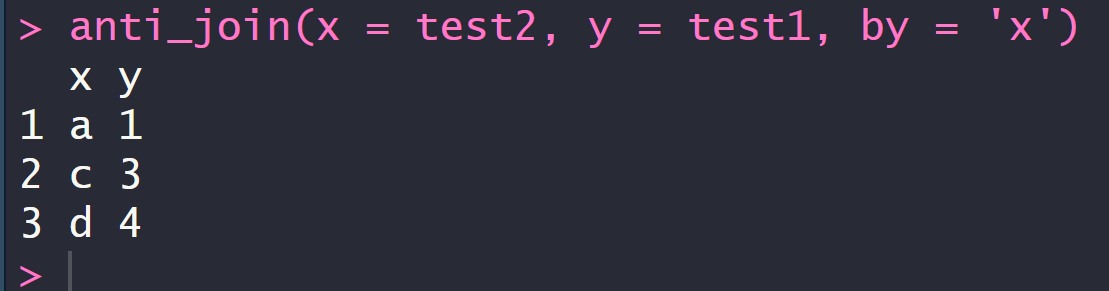
4.6 简单合并
bind_rows()函数需要两个表格列数相同
bind_cols()函数则需要两个数据框行数相同
test1 <- data.frame(x = c(1,2,3,4), y = c(10,20,30,40))
test1
test2 <- data.frame(x = c(5,6), y = c(50,60))
test2
test3 <- data.frame(z = c(100,200,300,400))
test3
bind_rows(test1, test2)
bind_cols(test1, test3)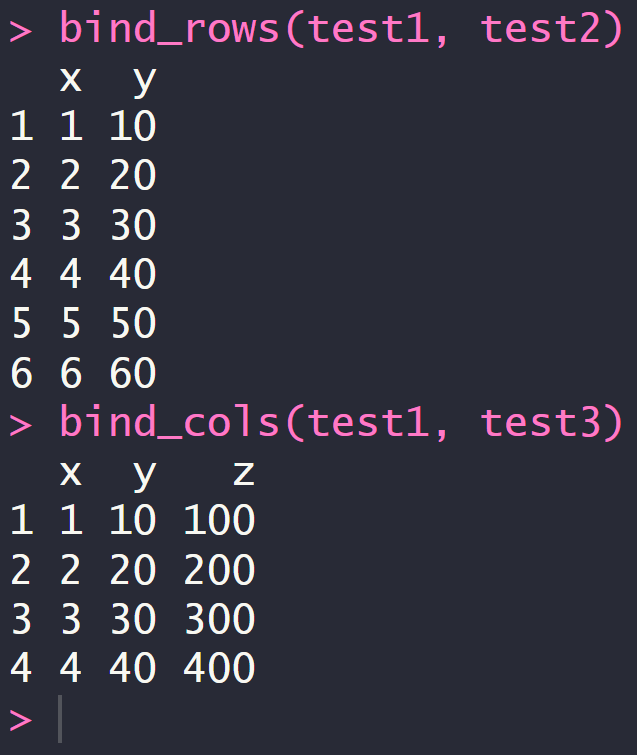
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录