CVPR 2023 | 使用混合 Transformer-CNN 架构学习图像压缩
CVPR 2023 | 使用混合 Transformer-CNN 架构学习图像压缩

题目:Learned Image Compression with Mixed Transformer-CNN Architectures 作者:Jinming Liu, Heming Sun, Jiro Katto 来源:CVPR 2023 原文链接:https://openaccess.thecvf.com/content/CVPR2023/html/Liu_Learned_Image_Compression_With_Mixed_Transformer-CNN_Architectures_CVPR_2023_paper.html 内容整理:刘潮磊 与经典图像压缩标准相比,学习图像压缩(LIC)方法已经展现出有希望的进步和卓越的率失真性能。现有的LIC方法大多数是基于卷积神经网络(CNN)或基于Transformer,它们具有不同的优点。利用两者的优势是一个值得探讨的点,它有两个挑战:1)如何有效地融合这两种方法;2)如何以合适的复杂度实现更高的性能。在本文中,提出了一种复杂度可控的高效并行 Transformer-CNN 混合(TCM)模块,将 CNN 的局部建模能力和 Transformer 的非局部建模能力结合起来,以改善图像压缩模型的整体架构。此外,受熵估计模型和注意力模块最新进展的启发,通过使用通道压缩,提出了一种具有参数高效的基于 swin-transformer 的注意力(SWAtten)模块的通道熵模型。实验结果表明,与现有的 LIC 方法相比,提出的方法在三个不同分辨率数据集(即 Kodak、Tecnick、CLIC Professional Validation)上实现了最先进的率失真性能。
介绍
研究问题:
- 如何将CNN-based、Transformer-based图像压缩方法相结合
- 能否在结合之后保证模型复杂度不会太高
SOTA 工作与所属团队:
- Learned image compression with discretized Gaussian mixture likelihoods and attention modules——Z. Cheng, H. Sun, M. Takeuchi, and J. Katto,早稻田大学。
- Two-Stage Octave Residual Network for End-to-End Image Compression——Fangdong Chen, 海康威视研究院。
- ELIC: Efficient Learned Image Compression With Unevenly Grouped Space-Channel Contextual Adaptive Coding——Dailan He, Ziming Yang, 商汤科技。
动机:
CNN-based图像压缩方法能较好地提取局部信息,Transformer-based图像压缩方法能较好地提取全局信息,于是想将这两者的优势相结合。
贡献:
- 提出一个将CNN、Transformer结合的模块TCM block。
- 设计了一个熵模型,引入另一个CNN、Transformer结合的模块SWAtten(swin-transformer-based attention module)。
方法
模型框架
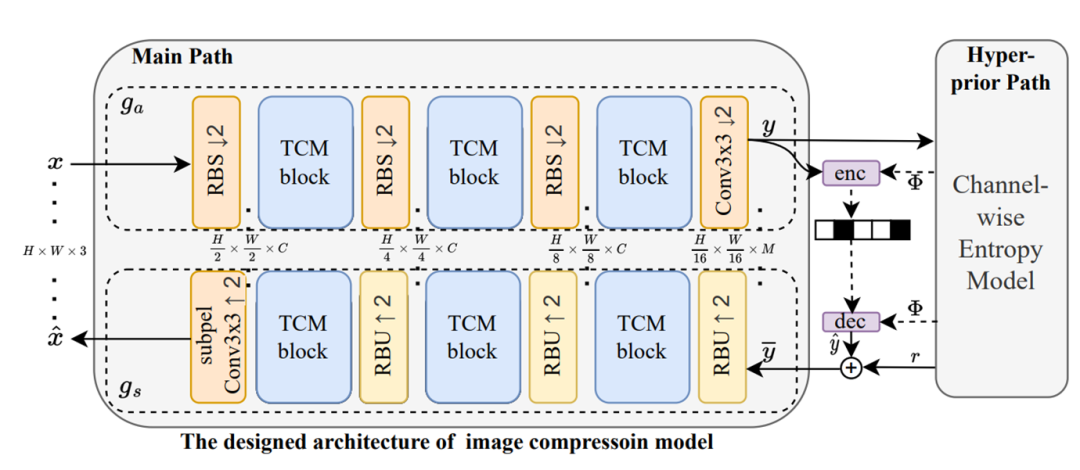
图1. 模型架构
- 在main path中插入了很多TCM block。
- 设计了一个引入SWAtten的Entropy Model。
TCM block 结构
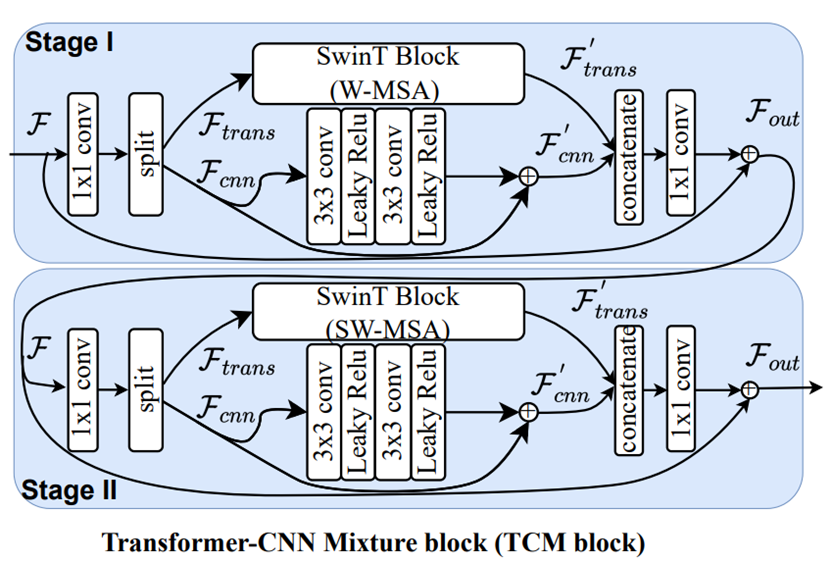
图2. TCM block 结构
TCM block 分为两个阶段,各阶段中不同模块的效果如下:
- Split:将输入特征图分为大小?/2×?_?×?_?两部分。
- 减少输入通道数,降低复杂度。
- 分别利用Transformer、CNN处理局部、全局信息。
- concatenate:将处理后的特征图拼接。
- 1×1 conv:将局部、全局信息混合。
两阶段基本一致,区别在于采用的SwinT Block不同:
- Stage Ⅰ:window-based multi-head self-attention。
- Stage Ⅱ:shifted window-based multi-head self-attention。
TCM block 用途
TCM block主要用于两个模块中,
- 在main path中,每个RBS/RBU之后都插入一个TCM。
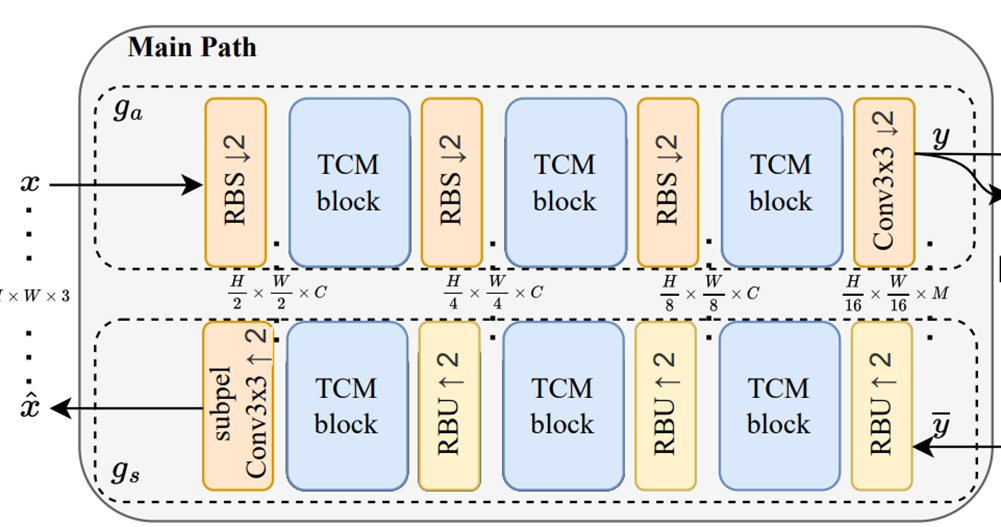
图3. main path
- 在hyper prior path 的
、
中插入TCM。

图4. hyper prior path
TCM block 效果探究
- 通过比较感受野来探究对局部、全局信息的聚合效果。
- 示例:Kodak数据集的图像kodim04的点p = (70, 700)。
- 计算方式:点p对于某个点的梯度的模,超过某个阈值都会被计算进来。
- 可视化结果如下:
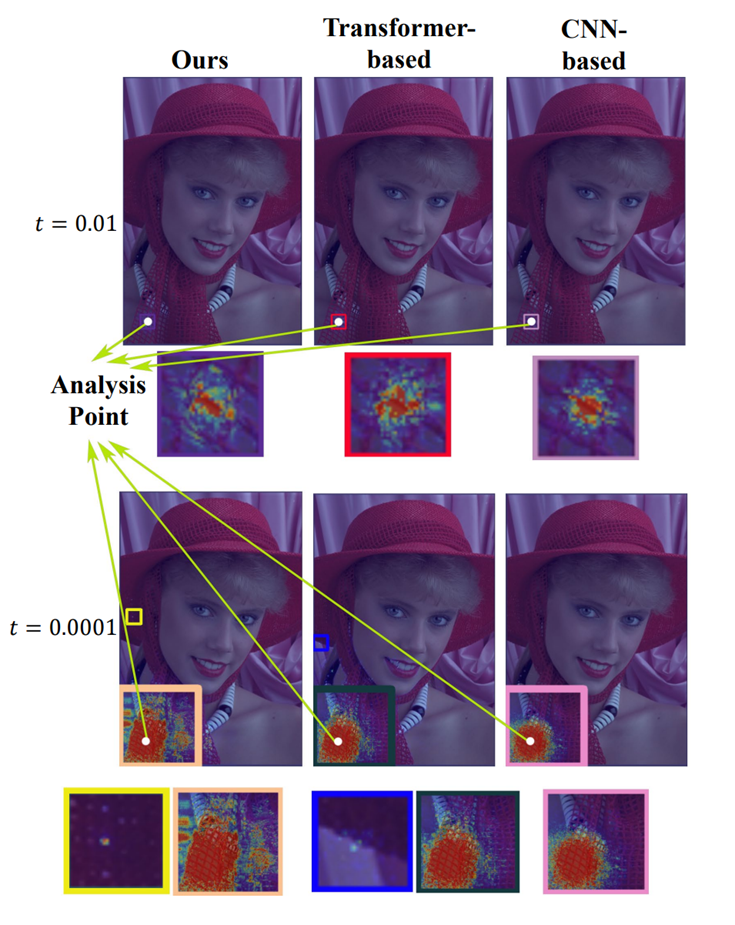
图5. TCM block 效果
文中设置了两个阈值(t=0.01、t=0.0001)。
在t=0.01时,本文提出的方法的感受野与CNN-based方法相差不大,小于Transformer-based方法的感受野,这说明本文方法更多地还是关注相邻像素信息。
在t=0.0001时,本文提出的方法的感受野明显大于CNN-based方法,并且也略大于Transformer-based方法的感受野,并且在小黄色框中,还存在梯度大于阈值的点,这说明本文方法相比于CNN-based方法具有较好的长距离建模能力。
Entropy Model
本文Entropy Model结构如下:
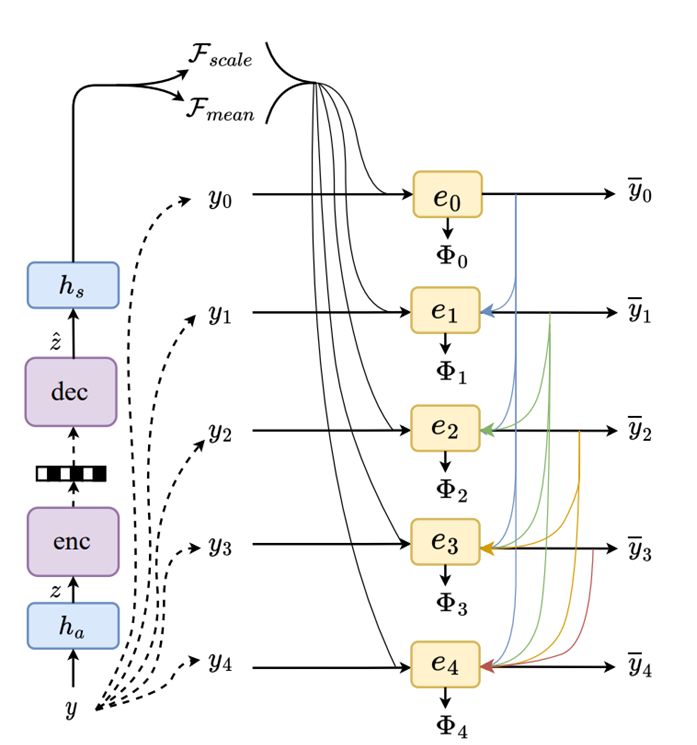
图6. Entropy Model
本文的Entropy Model主要有两个改进:
- 对输入y进行分层:用
来帮助
编码。
- 提出了swin-transformer-based attention module(SWAtten)模块。
分层编码器
结构
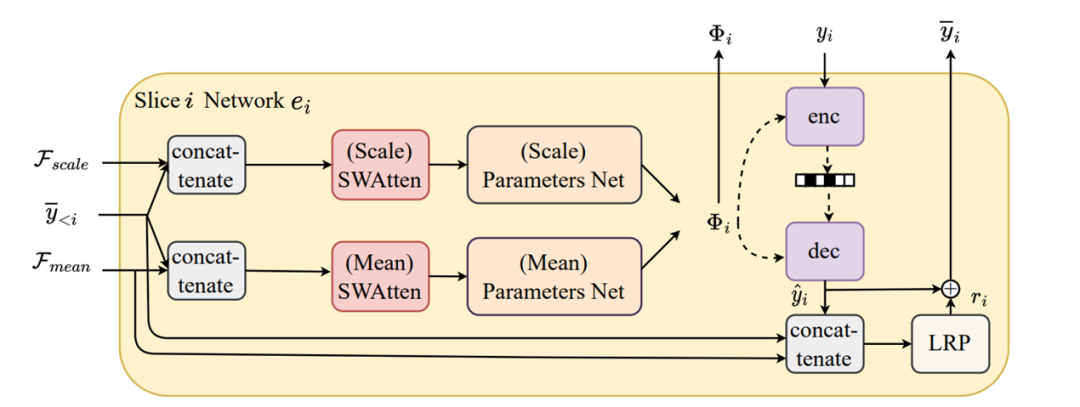
图7
swin-transformer-based attention module (SWAtten)结构
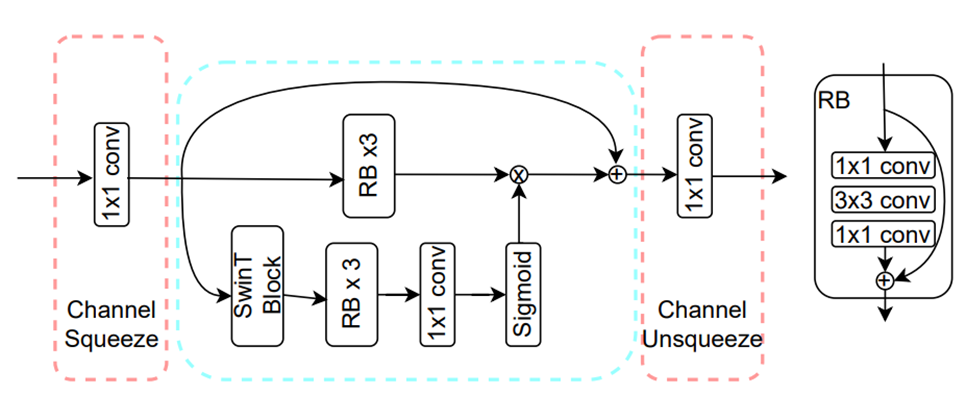
图8
SWAtten也是一个transformer、CNN相结合的模块:
- Channel Squeeze:用于减少输入通道数(减少到128),降低模型复杂度。
- mer block:获取全局信息。
- RB:获取局部信息。
实验设计与验证
RD曲线
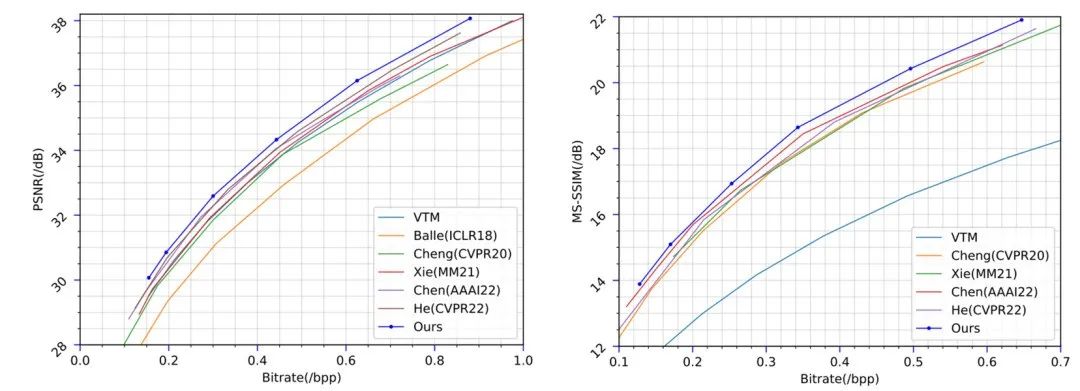
图9
消融实验:分别探究TCM、SWAtten的作用
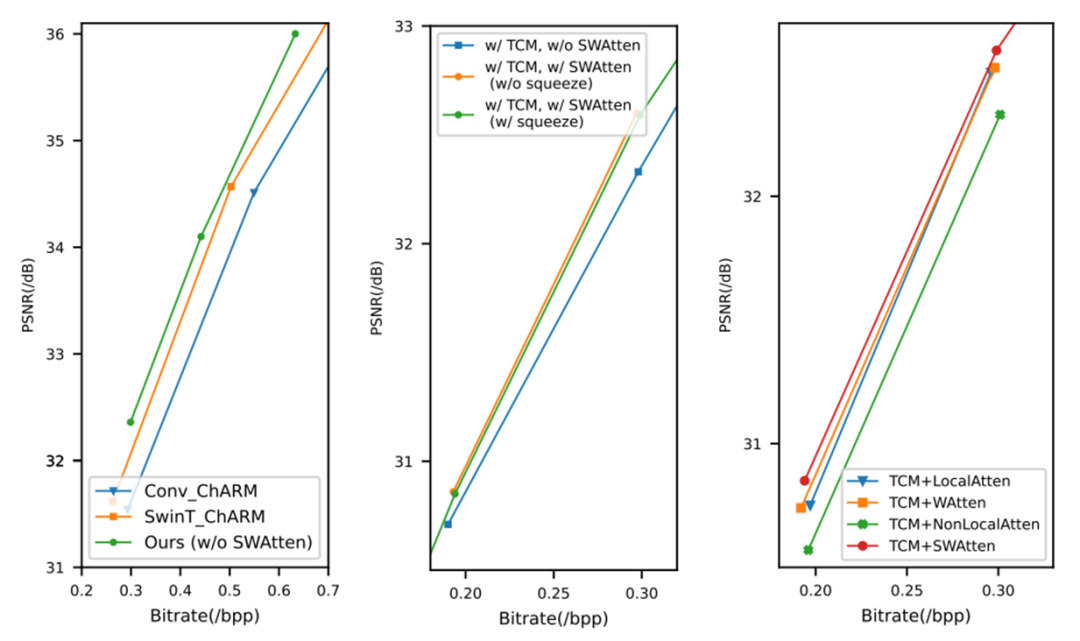
图10
模型复杂度分析
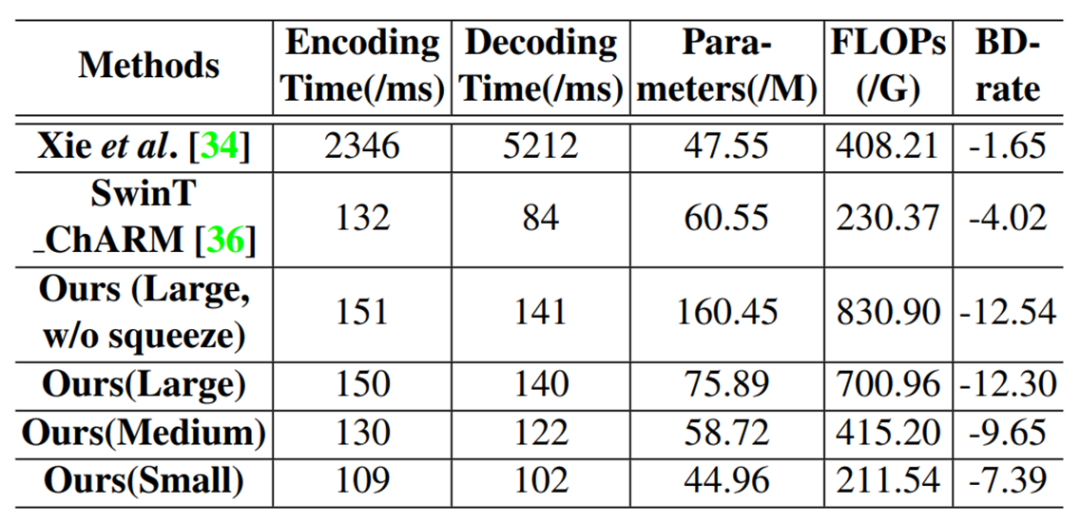
图11
Small、Medium、Large分别表示通道数C=128、192、256。
结论
本文将 Transformer 和 CNN 结合起来,提出了一种高效的并行 Transformer-CNN 混合块,利用了 CNN 的局部建模能力和 Transformer 的非局部建模能力。然后,基于TCM块设计了一种新的图像压缩架构。此外,提出了一个基于 swin-transformer 的注意力模块来改进通道熵模型。实验结果表明,在适当的复杂度下,使用 TCM 块的图像压缩模型优于仅基于 CNN/仅基于 Transformer 的模型。此外,SWAtten 的性能超越了之前为图像压缩设计的注意力模块。最后,本文的方法在三个不同分辨率的数据集(即 Kodak、Tecnick、CLIC Professional Validation)上达到了最好的水平,并且优于现有的图像压缩方法。